LinearRegression 사용 시
import pandas as pd
from sklearn.datasets import load_diabetes
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
X, y = load_diabetes(return_X_y=True, as_frame=True)
dataset = pd.concat([X, y], axis=1)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
reg = LinearRegression()
reg.fit(X_train, y_train)
preds = reg.predict(X_val)
regression_report(preds, y_val)# 아래의 메서드로 성능 측정
from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_error
import numpy as np
import pandas as pd
from tabulate import tabulate
def regression_report(preds, true):
r2 = r2_score(true, preds)
mae = mean_absolute_error(true, preds)
mse = mean_squared_error(true, preds)
rmse = np.sqrt(mse)
tmp_df = pd.DataFrame({
'R-squared': [r2],
'MAE': [mae],
'MSE': [mse],
'RMSE': [rmse]
})
print('\033[92m' + '\033[1m' + '📃Regression Report📃' + '\033[0m')
print(tabulate(tmp_df, headers='keys', tablefmt='psql'))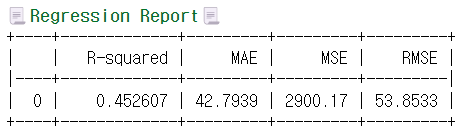
XGBoost 사용 시
from xgboost import XGBRegressor
xgbr = XGBRegressor()
xgbr.fit(X_train, y_train)
y_pred = xgbr.predict(X_val)
regression_report(y_pred, y_val)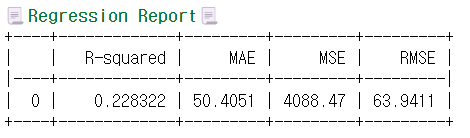
XGBoost로 학습을 시켰을 때 더 좋지 않은 성능이 측정됨을 알 수 있다.

성장 중독 | 서버, 데이터, 정보 보안을 공부합니다.