Abstract
sequence to sequence model을 pretrain 하기 위한 denoising auto encoder인 BART를 제안 하였다.
BART는 표준 Transformer model을 사용한다.
-> BERT가 bidirectional encoder의 성능을 보임
-> GPT가 left to right decoder의 성능을 보임
이러한 이유로 표준 Transformer model을 사용
학습을 하기 위해 원본 문장을 임의로 섞고, 텍스트의 범위가 단일 mask token으로 대체 되는 새로운 in-filling scheme를 사용하여 SOTA방식을 찾는 등의 접근
BART는 text 생성 작업에 특화 되어 있지만 NLU 작업에서도 잘 동작하며, Roberta 랑 비교하여서 일부 항목에서는 SOTA를 달성하였다.
introduction
self-supervised method -> NLP에서 훌륭한 성능을 냈다.
BERT의 MLM은 좋은 성능을 보였고, 그의 파생형들도 여러 이득을 보였다. 하지만 특정 유형의 task에만 초점이 맞춰져 있었다.
BART model의 경우 BERT의 MLM 구조와 GPT의 Auto regressive 방법을 사용한다. 이를 통하여 BART model은 다양한 task를 할 수 있는 sequence to sequence denoising auto-encoder이다.
pretrain은 두가지 단계로 구성
1. Text가 임의의 noise 함수로 손상된다
2. sequence to sequence model이 학습되어 원본 text를 재구성한다.
noise를 통하여 더 많은 유연성이 생기게 되고, 최적의 성능을 찾는 여러 denoising 방식은 모델이 전체 문장 길이에 대해 더 많은 추론을 하고, 입력에 대해 더 긴 범위의 변환을 수행하게끔 한다.
그리고 BART는 text 생성을 위한 fine-tuning에서 훌륭한 성능을 보였다.
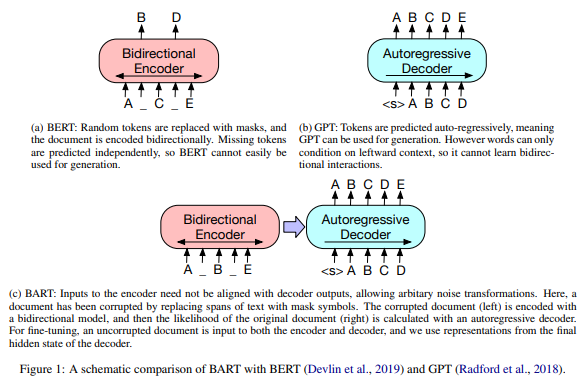
Model
BART는 손상된 문서를 원본 문서에 매핑하는 denoising auto encoder이며, 양방향 encoder와 autoencoder decoder를 사용하는 sequence to sequence model로 구현된다
Architecture
BART는 GPT의 구조에서 ReLU -> GeLUs로 수정하였고, parameter를 N(0,0.02)에서 초기화 하는 것을 제외하고 표준 sequence to sequence transformer를 사용.
기본 모델의 경우 : Encoder, decoder가 각각 6개의 layer
Large model의 경우 : Encdoer, Decoder가 각각 12개의 layer
아키텍처는 BERT에서 사용 되는 것과 관련이 있다.
차이점
1. Decoder의 각 계층은 encoder의 최종 hidden layer에 cross attention을 추가
2. BERT는 단어 예측 하기전에 feed forward network를 사용하지만, BART는 이를 사용하지 않으며, BART는 동일 크기의 BERT model보다 10%더 많은 parameter를 가지고 있다
Pre-training BART
BART는 문서를 손상 -> 재구성 즉 decoder의 출력과 원본 문서의 사잉의 cross entropy를 최적화 한다.
특정 noise를 denoising 하는 기존 방식과 달리 BART는 모든 유형을 적용할 수 있다. -> 극단적인 경우에는 BART는 language model과 동일하다.
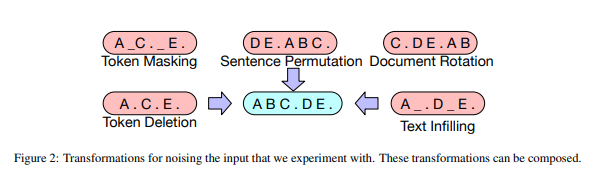
- BART model을 사용한 변환 방법
Token Masking : BERT와 유사하며, random token을 sampling하여 [MASK]로 대체
Token Deletion : input에서 random token을 삭제 -> model은 사라진 위치를 결정해야한다.
Text Infilling : 포아송 분포에서 추출된 span 길이로 여러 text span이 sampling된다.
-> 각 span은 단일 [MASK] token으로 대체
-> 0-length span은 [MASK] token 삽입에 해당한다.
-> infilling은 spanbert에서 영감을 받았으며, span에서 누락된 token의 수를 예측하는 모델을 가르친다.
Sentence Permutation : 문서는 전체 stop을 기준으로 문장으로 분할 되고, 이 문장들은 임의로 섞인다.
Document Rotation : 임의로 token을 일률적으로 선택하고 해당 token으로 시작하도록 문서를 회전 시킨다. -> 모델이 문서의 시작을 식별하도록 훈련
Fine-tuning BART
BART model은 downstream에서 여러가지 방식으로 사용 가능
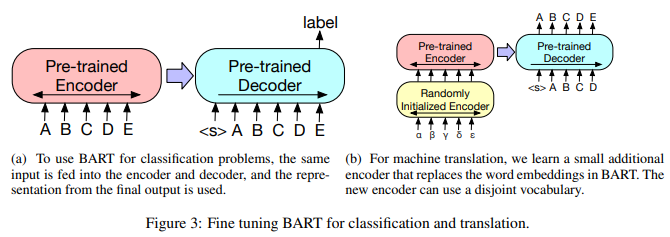
seuqence Calssficication tasks
Figure 3 (a)
동일 입력 -> encoder & decoder -> final decoder token -> multi class linear classifier
BERT의 CLS token과 관련이 있지만, decoder가 전체 입력에서 역할을 할 수 있도록 끝에 추가 token을 추가한다.
Token Classification Tasks
SQuAD에 대한 endpoint classfication 과 token classification 같은 작업에서 encoder와 decoder에 입력하고 decoder의 상위 hidden state를 각 단어에 대한 표현으로 사용 -> 표현은 분류에 사용
Sequence Generation Tasks
BART는 auto regressive decoder를 가지고 있어, 추상적 QnA, 요약 같은 sequence 생성 작업에 대해 fine-tuning이 가능
encoder의 input은 input sequence이고, decoder의 output을 auto regressive 하게 만든다.
Machine Translation
Figure 3 (b)
BART를 사용하여 영어 번역을 위한 decoder를 만들때 논문에서는 bitext에서 학습된 encoder parameter set를 추가하여, 전체 BART model을 기계 번역을 위한 단일 사전 훈련 decoder로 사용할 수 있다.
-> BART의 encoder embedding layer를 무작위로 초기화된 새로운 encoder로 교체한다.
model은 end to end로 훈련되어 BART가 영어에 대한 noise를 제거하고 외국어를 매핑 하도록 encoder를 훈련 시킨다.
source encoder를 두 단계로 훈련하며, BART는 모델의 출력에서 cross entropy loss로 역전파 한다.
1. BART의 parameter 대부분을 동결하고, 무작위로 초기화된 sorce encoder, BART의 position embedding 및 BART encoder의 first layer의 self attention input projection matrix만 update한다.
2. 적은 수의 반복에 대한 모든 모델의 parameter를 train 한다.
Comparing Pre-training Objectives
BART는 이전 작업보다 pre-train 동안 훨씬 더 넓은 범위의 noising scheme를 지원한다.
-> 대규모 실험을 하기 위해서 고려할 작업의 대표적인 하위 집합에서 평가된 기본 크기 모델을 사용하여 다양한 옵션을 비교한다.
Comparison Objectives
논문에서는 차별적 작업과 생성 작업에 대해 제안도니 강한 pre-train 접근 방식을 다시 구현
훈련 목표와 관련 없는 차이를 제어하는 것을 목표로 한다.
-> 성능향상을 위해 layer normalization의 학습률과 사용률을 약간 변경
language model
GPT와 유사하게 left to right transformer language model을 훈련한다. -> cross attention 없이 BART decoder와 같다
Permuted Language Model
XLNet을 기반으로 token의 1/6을 sampling하고 autoregressive으로 무작위 순서로 생성한다.
-> 다른 model과의 일관성을 위해 XLNet의 segment에 걸쳐 상대적인 position embedding이나 attention을 구현하지 않는다
Masked language model
BERT와 같이 token의 15%를 [MASK] symbol로 교체하고 model을 훈련하여 원래 token을 독립적으로 predict한다.
Multitask Masked Language Model
UniLM에서와 같이 추가 self attention mask로 masking model을 훈련한다.
self attention mask는 left to right: 1/6, right to left : 1/6. mask 미사용 1/3, token의 처음 50%를 mask로 사용하고 나머지는 left to right mask를 사용하여 무작위로 선택한다.
Masked Seq-to-Seq
MASS에서 영감을 받아 token의 50%가 포함된 span을 masking 하고 masking된 token을 예측하기 위해 sequence model을 훈련한다.
- encoder 및 대상에 대한 source 입력이 decoder 출력인 표준 sequecne to sequence 문제로 처리
- decoder에서 대상에 대한 접두사로 source를 추가하여 sequence의 대상 부분에 손실을 입히는 방법
BART의 경우 1번 방법이 잘 동작 하였다.
Tasks
SQuAD : 위키피디아 문단에 대한 추출 QnA 작업 -> 답변은 문서 context에서 추출된 text 범위
MNLI : 하나의 문장이 다른 문장을 포함하는지 여부를 예측하기 위한 bitext classification task
ELI5: 긴 형태의 추상적 QnA 데이터셋
XSum : 매우 추상적인 요약이 포함된 뉴스 요약 데이터셋
ConvAI2 : context와 persona를 조건으로 하는 대화 응답 생성 데이터셋
CNN/DM : 뉴스 요약 데이터 셋
Results
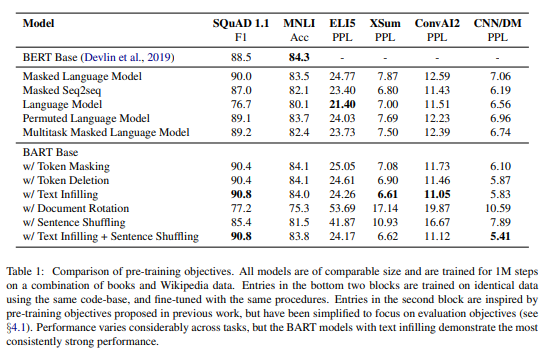
Performance of pre-training methods varies significantly across tasks
-> 작업에 따라 pretrain 방법의 성능이 크게 다르다
Token masking is crucial
-> 문서를 회전하거나 문장의 순열하는 것만으로 pretrain 목표의 수행은 어렵다. 성공적인 방법은 삭제나 masking이며, 삭제의 경우 생성작업에서 masking의 성능을 능가하였다.
Left-to-right pre-training improves generation
-> masking 언어 모델과 permutation 언어 모델은 생성 시 다른 모델 보다 성능이 떨어진다. pretrain동안 left to right로 auto regressive 언어 모델링이 포함 되지 않는다
Bidirectional encoders are crucial for SQuAD
-> BART는 양방향 layer수의 절반만 가지고 좋은 성능을 달성한다.
The pre-training objective is not the only important factor
-> premutation language model은 XLNet보다 성능이 좋지 않다.
--> positional embedding 또는 segment 수준 반복과 같은 아키텍처 개선 사항을 포함하지 않았기 때문에 그럴 수 있다.
Pure language models perform best on ELI5
-> ELI5 데이터 셋은 다른 모델이 BART를 능가하는 유일한 작업이며, 출력이 입력에 의해 느슨하게 제약 될때 BART의 효과가 낮다는 것을 시사한다.
BART achieves the most consistently strong performance.
text infilling 작업에서 BART model은 ELI5를 제외하고 모든 작업에서 잘 수행된다.
Large-scale Pre-training Experiments
Roberta model과 동일한 규모를 사용하여 BART를 훈련
Experimental Setup
encoder & decoder를 각각 12 layers와 1024의 hidden size를 가지며, 8000의 batch size 및 500000step동안 model을 훈련한다.
Discriminative Tasks
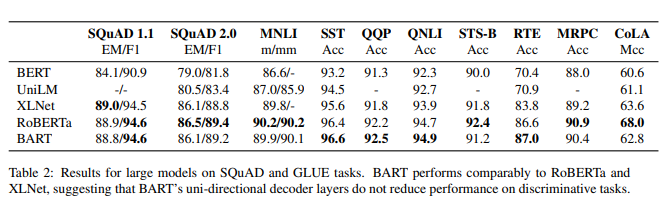
BART의 성능이 잘 연구된 최근의 여러 방식과 비교를 한 것이며, Roberta랑 비슷한 resource를 사용하지만 다른 object를 사용하여 pretrain되었다.
전반적으로 BART는 작은 차이만 있을뿐 유사하게 수행하며, 생성 작업에 대한 BART의 개선이 classification 성능을 희생시키지 않는다.
Generation Tasks
여러 text의 생성 작업을 실험 하였으며, sequence to sequence model로 fine tuning 된다.
fine tuning 동안 smoothing parameter가 0.1로 설정된 label smooth cros entropy loss를 사용한다.
길이를 패널티로 모델을 조정하며, 빔의 크기를 5로하고, 중복 트리거를 제거한다.
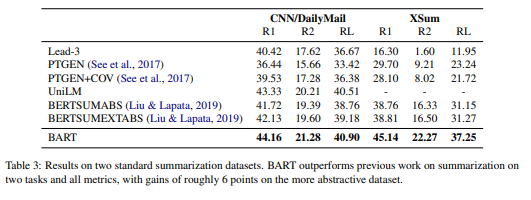
summarization
CNN/dailymail과 XSum 두가지 데이터셋에 대해서 BART는 모든 ROUGE metric에서 BERT를 활용하는 이전의 SOTA model들을 능가하였다.
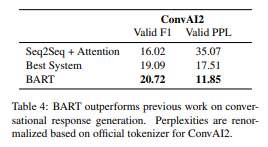
Dialogue
ConvAI2에서 대화 응답 생성을 평가하며, 이에 대해 BART는 2가지의 automated metric에서 이전 모델들을 능가한다.
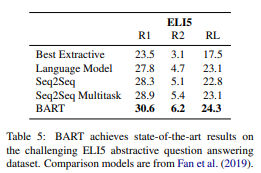
Abstractive QA
최근 제안된 ELI5 데이터셋을 사용하여 긴 자유 형식 답변을 생성하는 부분에서 BART가 1.2 ROUGE-L만큼 이전의 SOTA를 능가하지만, 답이 질문에 의해 지정되어 도전과제이다.
Translation
WMT16 루마니아 영어 변환에 대한 성능을 평가 하였을 때 실험 결과는 다음 과 같다.

해당 결과는 위의 표와 같으며 base model은 기본 Transformer 아키텍처와 비교를 한 것이다.
back-translation data가 없으면 접근법의 효과가 떨어진다.
Qualitative Analysis
BART 는 이전 SOTA model과 비교하여 요약에서 큰 개선을 보여주었다.

위의 표는 BART를 이용한 요약 생성문이며, 이를 통해 알 수 있는 것은 모델의 output은 input에서 복사된 문구가 없이 추상적이지만, 일반적인 사실에 정확하며, 입력 문서 전반의 증거를 배경지식으로 통합하였다.
-> BART가 pretrain이 NLI와 생성의 강한 조합을 학습했음을 보여준다.
Related Work
Conclusions
