Abstract
data 분포의 불균형은 LLM의 성능이 영어에 치우쳐짐
-> 논문은 언어간 sematic alignment를 통해서 영어가 아닌 언어에 대해 pretrain 성능에 힘을 실어준다.
번역 task data와 cross language general task data를 모두 사용해서 LLaMA에서 instruction tuning을 수행하여 X-LLaMA를 얻는다.
-> 실험 결과 6개 언어에서 Alpaca 보다 42.5% 우수한 성능을 얻었다.
출가적으로 중국 benchmark C-EVAL에 추가적 실험으로 X-LLAMA는 중국 인문학 과제에서 Alpaca를 8.2% 능가하는 성능을 향상하였으며, translate data의 대상 측면에 비영어 text를 통합이 비영어 능력을 향상시키는데 효과적인 것을 발견
translate task data가 확장되고 기본 확장 법칙이 정형화 됨에 따라 LLM 내의 semantic alignment가 더욱 강화될 수 있다.
-> translate task dataset FLORES-101에서 X-LLAMA는 모든 방향의 평가에서 이전의 LLAMA base model을 능가하였다.
Introduction
large-scale corpus에에서 train -> LLM은 지식을 습득
단, 이러한 corpus는 대부분이 영어로 구성이됨 -> 영어가 아닌언어는?
그 결과 영어가 아닌 언어, 그리고 영어랑 유사하지 않을수록 LLM은 낮은 성능을 보임
대규모의 단일 언어 데이터를 사용하여 pre-train을 해서 비영어의 능력을 높히면?
-> 대규모의 data와 computing 자원이 필요함
논문에서 하고자 하는말
영어와 비영어 간의 semantic-alignment를 통해서 LLM의 비영어의 능력을 높히는 것
->
1. 두 언어 간의 대응성을 향상하기 위한 번역 작업으로 LLM의 instruction을 tuning
2. cross language generation 작업을 통하여 following instruction 성능을 향상
-> cross language instruction tuning은 비영어를 위한 cross model을 제공한다.

translation task의 training을 위해 이전 연구는 translation data의 확장을 제한하는 high-cost human annotation을 제안
-> 논문에서는 그와 달리 공개된 WIKIMATRIX와 더 많은 언어로 확장 가능한 NEWSCOMMINTARY를 사용
일반 적인 task instruction data의 경우 ALPACA dataset과 해당 언어로 번역된 버전도 쉽게 얻는다.
실험
-> LLaMA-7B를 이용하여 영어와 6개의 target language를 사용
각 언어에 대해 별도의 X-LLaMA를 언어별 데이터로 얻는다.
두 개의 언어간 dataset XQUAD 및 MLQA의 실험 결과는 X-LLaMA가 영어로 tuning된 ALPACA-7B dmoel을 평균 42.50% 능가하엿다,.
-> 영어가 아닌 작업에 대한 정확도가 ALPACA-7B에 가깝다.
-> 중국 인문학 작업에서 ALPACA-7B를 8.2% 능가하였으며, 중국어 ALPACA-7B와 비교하여 X-LLaMA는 동등한 평균 성능을 달성하였다. 하지만 모든 task에서 보면 비영어 수행을 보편적으로 향상시키는것은 어렵다
X-LLaMA가 대규모로 지속적인 pretrain없이 강한 번역 능력을 보여주었다.
다국어 번역 dataset FLORES-101에서 X-LLaMA가 12개의 모든 부분에서 LLaMA 기반의 모델을 능가하고 절반에서 강력한 번역 모델 M2M-12B를 능가하였다.
-> 번역 성능의 확장 가능 법칙에 따라 규모가 증가함에 따라 계속 증가한다.
논문의 주요 기여
-
쉽게 얻은 자원을 cross-lingual instruction-tuning LLM의 비영어 능력을 이끌어냅니다.
-
cross lingual instruction-tuning이 비영어 언어 능력과 translation 능력을 동시에 향상 시킬 수 있다.
-
cross lingual instruction-tuning이 지속적인 pretrain scaling 법칙을 비교하고 cross lingual instruction tuning이 더 효율적임을 보여준다.
Background
Large Language Model Pre-training
언어 모델링은 자연어 처리의 오랜 과제로 prefix sequence를 기반으로 다음 token을 predict하기 위해 language model이 필요하다.
대규모 parameter를 가진 model이 대규모의 corpus에 대해 훈련되며, LLM은 지식을 얻을 수 있었다.
-> pre-training corpus는 대부분 영어로 되어 있어 LLM은 일반적으로 비영어보다 영어에 대한 지식을 더 많이 알고 있으며, pre-training corpus에서 parallel data가 부족하기 때문에 영어와 비영어를 잘 이해하는데 방해가 되기도 한다.
Instruction-tuning LLM to Unlock Its Potential
LLM이 획득한 지식으로 downstream을 할 수 있도록 instruction tuning을 하며, 이 단계에서 LLM은 instruction data{(T,X,Y)}를 받으며 T는 작업 요구사항을 설명하는 task instruction이다.
X는 선택적 input이고 y는 주어진 작업에 대한 원하는 output이다. instruction tuning dataset에는 종종 보이지 않는 instruction과 task에 대한 일반화에 유익한 작업을 포함한다.
-> 이 단계에서의 학습 목표는 negative log likelihood를 최소화 하는 것이다.
여기서 는 LLM이 학습 가능한 parameter를 의미하며, 이전 연구에서는 수천 줄의 instruction data로 조정하면 다양한 task를 해결하기 위해 사람의 instruction을 따를 수 있음을 보여주었다.
-> 일반적으로 사용되는 instruction tuning dataset도 영어가 아닌 명령과 작업을 해결하는 LLM의 능력을 제한하는 것을 알게 되었다.
Eliciting LLM’s non-English Ability
많은 언어로 LLM을 강화하는 것은 어렵고 처음부터 각각의 언어에 대해 LLM을 구축하는 것은 비용때문에 금지가 된다.
논문에서는 영어와 대상언어 간의 의미적 alignment를 강화하여 pretrained LLM의 비영어 능력을 도출하고자 한다.
Cross-lingual Instruction-tuning
LLM의 비영어 능력을 끌어내기 위해 cross-lingual instruction-tuning을 수행한다.
mixed translation task instruction data와 cross-lingual instruction data를 사용하여 pretrained LLM을 instruction-tuning을 한다.

General task instruction data
일반적으로 사용되는 instruction tuning dataset이 거의 영어로 되어 있다
-> 번역 엔진이 있는 외국어 버전으로 번역 후 영어 버전과 영어가 아닌 버전을 모두 cross lingual general task instruction data로 사용
이 방식으로 LLM이 다국어 instruction을 더 잘 이해할 수 있다.
Translation task instruction data
번역 데이터는 semantic alignment를 학습하는데 가장 유용한 resource이다.
이전 연구
instruction tuning을 위해 전문가가 지정한 translation data를 사용하여,
LLM의 번역 성능이 향상됨을 보여줌논문에서는 공개적으로 사용가능한 문장 수준의 번역 데이터 set를 사용하여 data를 확장하고, 각 언어의 번역 방법을 확장할 수 있다.
각 번역 데이터 (X,Y)에 대해 후보 번역 명령어와 번역 명령어 와 무작위로 쌍을 이루어 다양성을 유지
EN-X(영어에서 비영어로 번역), X-EN(비영어에서 영어로 번역) 번역 데이터 모두 semantic alignment를 하는데 유용하지만, 번역 데이터의 대상 측에 영어가 아닌 text를 배치하는 것이 source 보다 영어가 아닌 작업에 대한 LLM의 성능을 향상 시킬 수 있다.
즉 둘다 좋지만 대상이 비영어일 경우 작업에 대한 LLM의 성능이 더 올라가더라
Scaling Law of Cross-lingual Instruction-tuning
논문에서는 bilingual 번역 성능을 semantic alignment의 지표로 사용하고 translation task instruction data의 규모가 큰 영향을 미친다.
번역 성능 Y와 데이터 규모 X 사이의 관계를 정량화 하기 위해 저자들은 근본적인 scaling 법칙을 설명하기 위해 다음과 같은 공식을 고안한다.
위의 수식에서 는 0보다 크며, 이며 이들은 추정 parameter이다.
는 대상 언어와 영어 사이의 유사성을 의미한다.
논문은 세가지 이유로 공식을 설계 하였다.
1. Y의 상한은 100이며, 자주 사용되는 번역 품질 metric의 최대 점수이다.
2. 번역 데이터가 확장 되면 번역 성능이 계속 증가하는 등식이 단조롭게 증가한다.
3. 영어와 덜 유사한 언어의 경우 영어와 유사한 언어보다 semantic alignment를 구축하는데 더 많은 번역 데이터가 필요하다.
-> X를 계속된 pretrain corpus의 규모로 취급하여 공식을 확장 할 수 있다. 실험에서 논문은 cross lingual instruction tuning과 계속된 pretrain의 scaling 법칙을 비교하고 cross-lingual instruction tuning이 semantic alignment를 train하는데 효율적임을 보여준다.
Experiment Setting
Pretrain LLM
논문에서는 수조개의 token에 대해 훈련되고 SOTA LLM과 pretrain LLM으로 LLaMA-7B를 선택하였다.
논문에서는 영어와 알파뱃을 거의 공유하지 않는 아랍, 그리스, 힌디어, 터키어, 베트남어, 중국어로 X-LLaMA를 구성
Baseline LLM
비교를 위해 LLaMA에서 instruction tuning으로 구축된 여러 모델을 포함한다. 영어 instruction으로 조정되는 Alpaca-7B, 사람의 annotation translation data로 조정되는 Parot-7B, 사람 대화형 translation으로 조정되는 Bayling-7B와 비교를 하였다.
또한 중국어 Alpaca-7B 와 Bigtans-13B의 결과를 보여주었다.
-> 두 모델은 대규모 단일 언어 데이터를 사용한다.
Cross-lingual Instruction Data
Translation task instruction data의 경우 공개적으로 사용가능한 문장 수준의 resource인 WIKIMATRIX와 high cost expert-annotated data 보다 접근성과 확장성이 우수한 NEWSCOMORMIAL을 사용
데이터의 통계
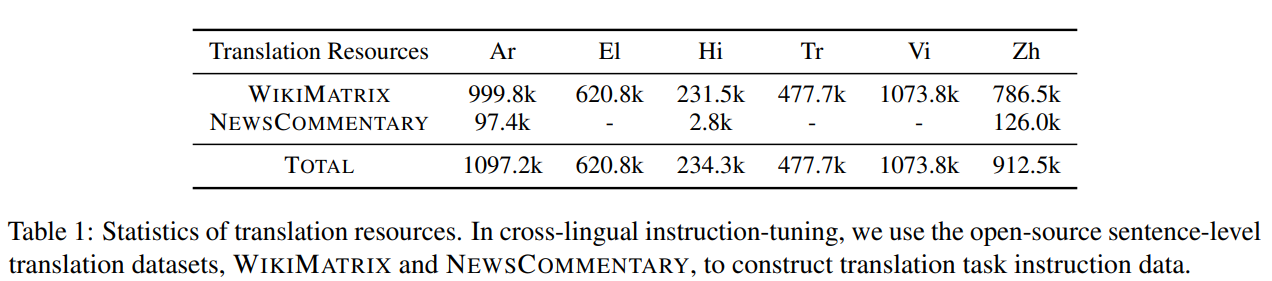
cross lingual general task instruction data의 경우 52K의 영어 질문과
text-davinci-003의 대응 응답을 포함하는 ALPACA dataset을 사용하여 in-house 번역 엔진이 있는 외국어 버전을 얻는다.
Training Details
standard alpaca code vase를 사용
A100 gpu : 8,
epoch : 3
learning rate : 2e-5
batch size : 128
FSDP : train strategy
Evaluation Dataset
비영어 언어에 대한 LLM 성능을 평가하기 위해 두 개의 cross lingual benchmark dataset XQUAD와 MLQA를 사용하여 주어진 context에 대해 추론하고 질문에 답을 한다.
광범위한 주제의 다중 질문으로 구성된 중국어 벤치마크 C-EVAL에 대한 실험
LLM의 번역을 평가하기 위해 FLOES-101 dataset을 사용
Evaluation Metrics
XQUAD와 MLQA dataset에서 chatGPT를 사용하여 답변의 품질을 평가
C-EVAL dataset에서는 one-shot 설정에서 일치 정확도를 측정
번역 작업의 경우 COMET10을 metric으로 사용
Main Results
Evaluation Results on Non-English Ability
x-LLaMA achieves great improvement on non-English QA tasks
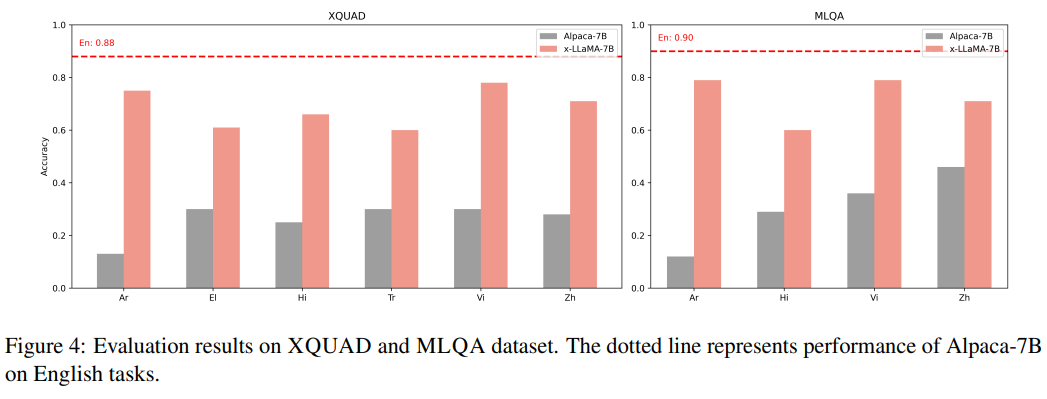
XQUAD와 MLQA에 대한 실험결과
ALPACA-7B는 해당 영어 질문에 대해 90%의 성능 달성
-> 영어가 아닌 질문은 성능이 떨어짐
반면 X-LLaMA는 평균적으로 6개의 비영어 언어에서42.5%만큼 ALPACA-7B를 능가하며, 이는 X-LLaMA의 답변 정확도가 영어 작업에 대한 ALPACA에 근접하고 있으며, cross lingual instruction tuning이 LLM의 비영어 능력을 이끌어 내는 방법임을 보여준다.
Strengthening LLM’s non-English ability on diverse subjects remains challenging

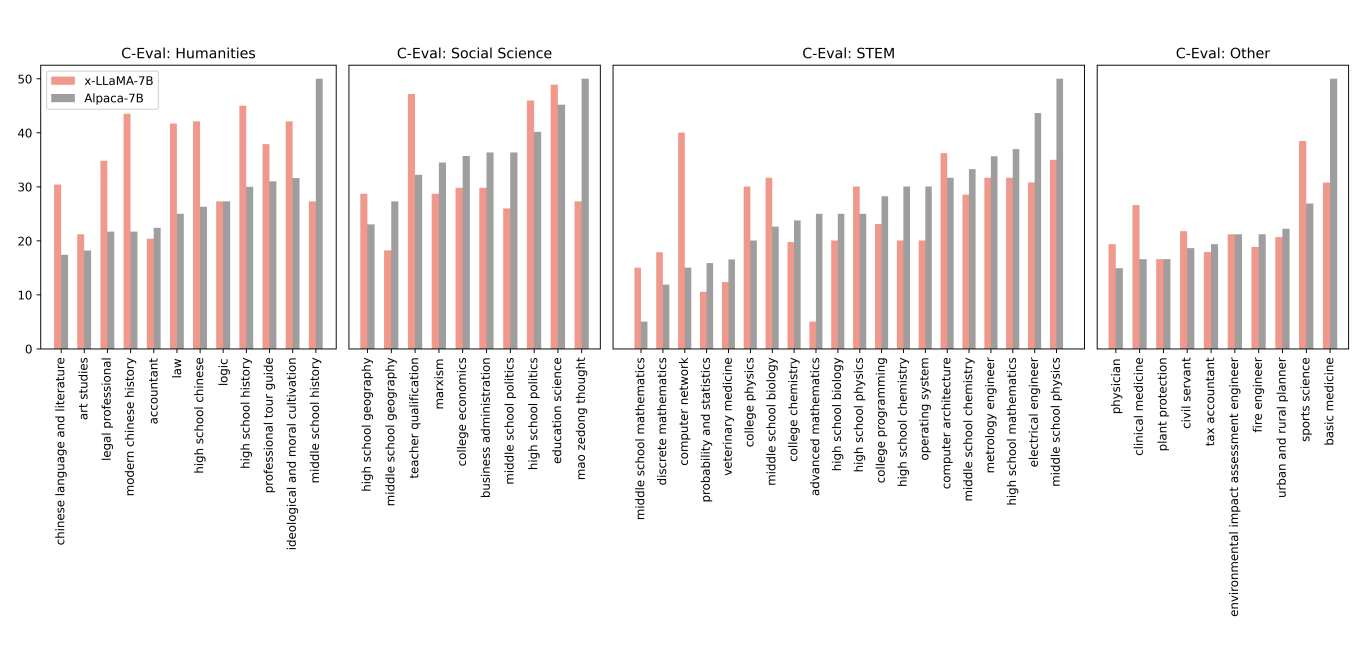
C-EVAL dataset 에 대한 수행 결과
ALPACA-7B를 Chinese Humanities tasks에서 8.2% 능가하며, 번역 데이터로 tuning된 다른 LLaMA 기반 LLM과 비교하여 X-LLaMA가 더 높은 중국어 성능을 발휘
-> X-LLaMA는 더 적은 resource로 비슷한 평균 점수를 달성하며, 언어간 instruction tuning이 24개 항목에서 성능향상을 가져왔지만 모든 작업에서 보편적으로 향상은 아니다.
Evaluation Results on Translation Ability
x-LLaMA shows impressive translation performance
X-LLaMA는 다른 LLaMA기반 보다 모든 방향에서 더 높은 성능을 보여주고 있다.
특히 X-LLaMA는 4개의 En-X 방향과 2개의 X-EN 방향에서 강한 다국어 supervised baseline인 M2M-12B를 능가하며 구글번역, chatGPT와 강한 번역 방식에 버금갈 정도로 상승하였다.


We reveal the scaling law of cross-lingual instruction-tuning
cross lingual instruction tuning을 더 잘 이해하기 위해 다양한 번역 데이터 척도에서 X-LLaMA의 번역 성능을 연구한다.
일반적으로 번역 데이터의 추가
-> semantic alignment를 강화 -> 확장 가능한 resource를 사용하는 것은 중요하다
위의 수식이 잘 부합함을 보여준다.
번역 data가 확장 되면 번역 성능은 증가하지만, 증가 속도는 점차 느려지며 이는 scaling 법칙에서 추론 가능하다.
Analysis
Using more translation task instruction data usually brings higher non-English Ability
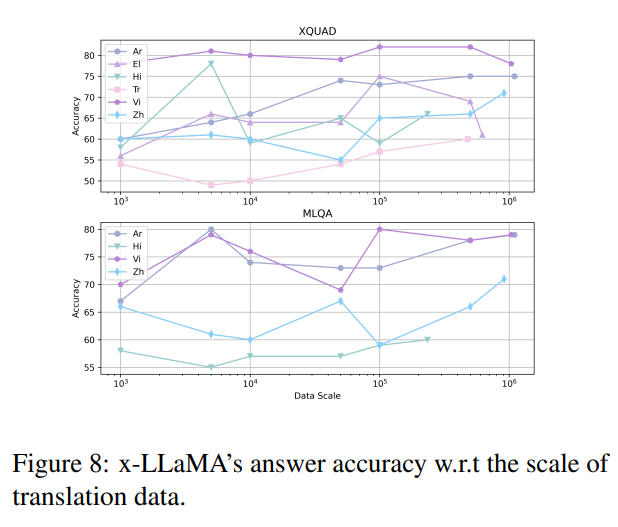
위의 그림에서 다른 규모의 번역 데이터에서 X-LLaMA의 성능을 보여준다.
X-LLaMA는 일반적으로 더 많은 번역 데이터가 사용될때 높은 정확도를 달성하며, 비영어 성능을 향상시키기 위해 language alignment의 이점을 보여준다.
Ablation study of cross-lingual instructiontuning

ablation study를 위해 다양한 instruction data 조합을 실험을 수행
-> 중국어 ALPACA data와 LLaMA-7B를 조정하는 것이 중국어 작업에 대한 영어 ALPACA data보다 낫다.
두가지 버전의 데이터를 공동으로 사용시 성능 개선
-> 번역 작업 지시 data만 사용해도 적당한 답변 정확도에 도달 가능 하며 번역 대상 측에 중국어를 넣는 것이 LLM의 비영어 능력을 향상 시킬 수 있음을 보여줌
cross lingual general task instruction data와 En-Zh translation task instruction data를 함께 사용하면 높은 정확도를 보인다.
Using parallel data is far more efficient than monolingual data for building semantic alignment
지속적인 pretrain 훈련을 위해 target language의 단일 말뭉치를 사용하는것은 LLM이 비영어 를 이해하고 번역 성능을 향상하는데 도움이된다.
-> 비교를 위해 중국어 단일 말뭉치 MC4를 사용하고 instruction tuning을 위해 cross language general data를 사용

-> 논문에서는 semantic alignment를 달성하기 위해 단일 언어 data를 사용하는 것 보다 병렬 데이터를 사용하는 것이 더 효율적이다.
Related Work
Empowering LLM’s non-English ability
LLM의 비영어 능력 강화는 실용적인 주제이며 지속적인 pretrain 접근법을 탐구한다.
-> 대규모의 target language corpus가 필요하며 일반적으로는 사용 불가
논문에서의 방식은 corss language instrcution tuning이 유사한 성능을 달성하고, 더 적은 resource를 사용
instruction tuning 중 다중 turn 대화형 번역 데이터를 사용하여 LLM의 영어 능력을 전송하는 방법을 탐구
-> C-EVAL dataset에 대한 평가 결과는 번역된 LLM이 중국어 작업에서 좋은 성능을 발휘 못함을 보여줌
-> 번역 데이터로 LLM의 비영어 data를 향상시키는것은 여전히 어렵다.
Enhancing LLM’s translation ability
번역 능력은 LLM의 다국어 능력의 다른 측면에서 번역 data를 사용하여 instruction tuning을 수행시 LLM의 번역 성능이 향상됨을 보여줌
논문에서는 open source translation resource를 instruction data로 사용하여 접근 방식을 재현하고 확장 가능하여 더 많은 언어로 확장
Cross-lingual transferring
cross-lingual transffering은 model에 encoding된 지식을 언어 간에 전달하는 것을 목표로 한다.
-> 이전에는 masked LM을 전달하기 위해 노력하였다.
반면 논문에서는 큰 LM에 초점을 맞추고 영어 이외의 언어로 전달하는 것을 탐구한다.
Conclusion
- 영어과 비영어 간의 semantic alignment를 구축하여 LLM의 비영어적능력을 활용하는데 중점
- cross lingual general instruction data와 translation task instruction data가 혼합된 LLM에 대한 instruction tuning
- X-LLaMA는 XQUAD, MLQA 및 C-Eval dataset에서 상당한 성능 향상을 달성
- X-LLaMA는 이전의 LLaMA기반 모델을 능가하고 모든 평가 방법 중 절반에서 M2M을 능가
- 영어가 아닌 언어를 위한 더 강력한 LLM을 개발할 수 있는 가능성을 보여줌
