LLM 논문 읽으며 정리
1.In-Context Retrieval-Augmented Language Models 논문 읽기

논문 링크 논문 코드 Abstract 생성 중에 Corpus에서 관련 문서의 LM을 조건으로 하는 Retrieval-Augmented Language model(이하 RALM)은 언어 모델링을 크게 향상 시키며 Natural source attribution mechanism을 제공한다. 기존의 방식은 LM 아키텍처를 수정하는데 초점을 맞춰 복잡하다 ->...
2.ANALOG BITS: GENERATING DISCRETE DATA USING DIFFUSION MODELS WITH SELF-CONDITIONING 논문 읽기

본 논문은 ICLR2023에서 소개된 논문으로 구글에서 발표한 논문입니다.
3.REALM: Retrieval-Augmented Language Model Pre-Training

Abstract 지금의 LLM은 parameter에 지식을 저장하여, 더 많은 사실을 포함하려면 더 큰 parameter를 가져야 한다. -> 이러한 방식 대신 latent knowledge retriever를 사용하여 LLM을 강화하고 이를 통해 model은 각 task에서 wikipedia 같은 대규모 corpus에서 검색하여 사용 한다. MLM을 ...
4.REPLUG: Retrieval-Augmented Black-Box Language Models
논문 링크 Abstarct LM을 blackbox로 취급하고 조정 가능한 검색 모델로 증강하는 검색 증강 언어 모델링 frame work인 REPUG를 논문에서는 제시 하였다. -> special cross attention 매커니즘을 가진 언어 모델을 훈련하는 이전 LM과 달리 REPUG는 검색된 문서를 동결된 black box model에 대한 입력에...
5.Dense Passage Retrieval for Open-Domain Question Answering
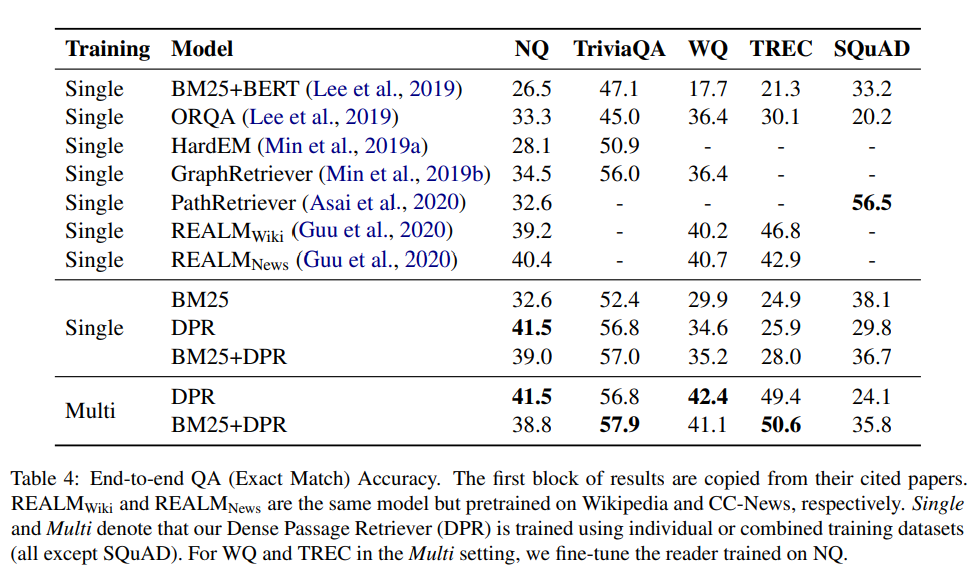
논문 링크 Retrieval 관련 논문에서 나오는 DPR에 관련된 논문 Abstract Open-domain qa에서 후보 context를 선택하기 위해 효율적인 passage retrieval에 의존하며, TF-IDF 또는 BM25와 같은 전통적인 sparse vector space model이 사실상의 방법이였다. -> 논문에서는 간단한 dual en...
6.Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Abstract LLM 모델은 parametric 방법을 통하여 매개변수에 지식을 저장 -> 지식을 업데이트를 하는데 제한, downstream 작업에 대해서 잘한다. parametric 한 방법과 Non-parametric 한 방법을 결합한 RAG라는 방법을 제안 -> parametric한 방법은 seq2seq model이며, Non-parametric...
7.Extrapolating Large Language Models to Non-English by Aligning Languages 논문 읽기
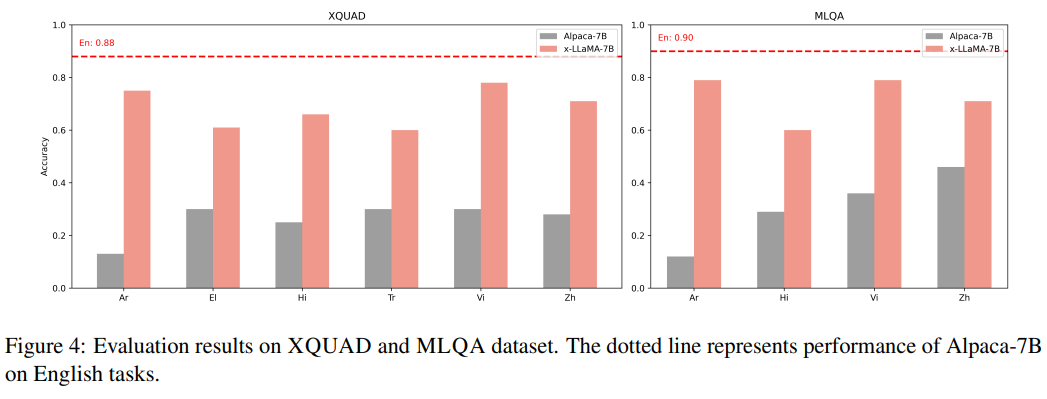
논문 링크 Abstract data 분포의 불균형은 LLM의 성능이 영어에 치우쳐짐 -> 논문은 언어간 sematic alignment를 통해서 영어가 아닌 언어에 대해 pretrain 성능에 힘을 실어준다. 번역 task data와 cross language general task data를 모두 사용해서 LLaMA에서 instruction tuni...