OpenAI에서 만든 논문입니다.
논문 링크
Abstract
언어 모델이 강해지고 커질 수록 훈련 및 평가에서 병목현상 발생
-> 평가를 두지면 결국은 사람들이 관심을 두는것 결국은 사람의 선호도에 최적화 되도록 모델을 훈련하면 품질이 크게 향상한다.
논문에서의 모델은 참조 요약 및 감독 학습만으로 fine-tuning된 더 큰 모델보다 성능이 더 우수하였다
-> fine-tuning 없이도 사람이 요약한것과 거의 유사한 요약 결과를 만든다.
논문에서는 보상 모델이 새로운 데이터 셋으로 일반화 하고 보상 모델을 최적화 하면 ROUGE를 최적화 하는 것보다 더 나은 요약을 할 수 있다를 보여준다.
Introduction
NLP작업에서 높은 성능을 달성하기 위해 대규모 언어 모델에 pre-training을 진행하였다.
-> 성능이 향상된다
성능은 향상 시키지만, 잘못된 alignment가 있으며, 이에 대해서는 여러가지 원인이 있다.
maximum likelihood는 아래의 것을 구별 못한다.
1. 중요한 오류(making up facts)
2. 중요하지 않은 오류(동의어 집합에서 정확한 단어 선택)
이 뿐 아니라 model은 낮은 품질의 시연을 포함한 사람이 만든것에 확률 질량을 배치하도록 장려되며, 샘플링 중의 분포 이동은 성능을 저하 시킬 수 있다.
빔 검색은 품질 향상에 기여하지만, 바람직하지 않은 결과를 만들기도 한다.
논문의 목표
1. 사람이 관심을 가지는 행동을 면밀하게 포착하는 목표에 대해 훈련하는 방법
2. 강화 학습을 사용하여, 사람 피드백에서 language model을 fine-tuning
2-1 : 요약 쌍 사이의 사람 선호 데이터 셋을 수집하여 reward model을 훈련하여 사람의 선호를 예측
2-2 강화학습을 통해 정책을 훈련하여 reward model이 주는 점수를 최대화
-> reward model의 reward는 PPO 알고리즘을 사용하여 업데이트
본 논문의 기여 4가지
-
We show that training with human feedback significantly outperforms very strong baselines on English summarization.
-> supervised learning을 통해 훈련된 더 큰 정책보다 사람의 피드백을 통한 훈련이 더 선호 된다. -
We show human feedback models generalize much better to new domains than supervised models.
-> 다른 도메인의 데이터로 훈련된 모델에서도 fine-tuning 없이 데이터 셋의 참조 요약 품질과 거의 일치 하였다. 모델이 단순히 길이나 복사량 같은 metric을 최적화하는 것이 아님을 보여준다. -
We conduct extensive empirical analyses of our policy and reward model.
-> reward model이 사람 선호도를 예측하는데 있어서 ROUGE같은 기존의 다른 방식보다 좋으며, reward모델을 사람이 직접 최적화 하는것이 더 나은 요약을 한다는걸 보여준다 -
We publicly release our human feedback dataset for further research.
-> 추가연구를 위한 데이터셋 공개이며, 64832개의 요약 비교와 TL;DR 및 CNN/DM에 대한 평가 데이터가 포함 되어 있다.
Related work
사람 피드백을 사용하여 RL로 요약 모델을 훈련하는 작업이 논문과 관련있는 작업이다.
-> 기존에는 온라인 방식으로 훈련하고 모델이 매우 추출적이였다.
하지만 논문의 방식은 상당히 큰 모델을 사용하고 사람 피드백을 수집하기 위한 배치설정으로 이동하고 labeler와 연구자의 일치도를 높게 보장하며, 몇가지 알고리즘적 수정을 수행한다.
사람 피드백은 여러 다른 영역에서 모델을 훈련하기 위해 사용하였다.
-> 논문에서의 접근법은 순위를 매기는 학습에 대한 이전연구에서 개발되었으며, 명시적 혹은 암묵적 피드백을 이용하였다.
-> 사람 피드백은 모의 실험 환경에서 agents를 훈련하는데 사용 되었으며 ROUGE, BLEU 및 기타 영역에서 자동 metrics를 최적화 하기위해 RL을 사용하였다.
-> 요약 성능을 향상시키기 위한 아키텍처 및 사전 훈련 절차를 수정하는 것에 광범위한 연구가 있었다
Method and experiment details
High-level methodology
데이터 셋에 대한 지도학습을 통해 fine-tuning되는 초기 정책으로 시작한다. 그리고 process는 반복할 수 있는 3가지 단계로 구성된다.
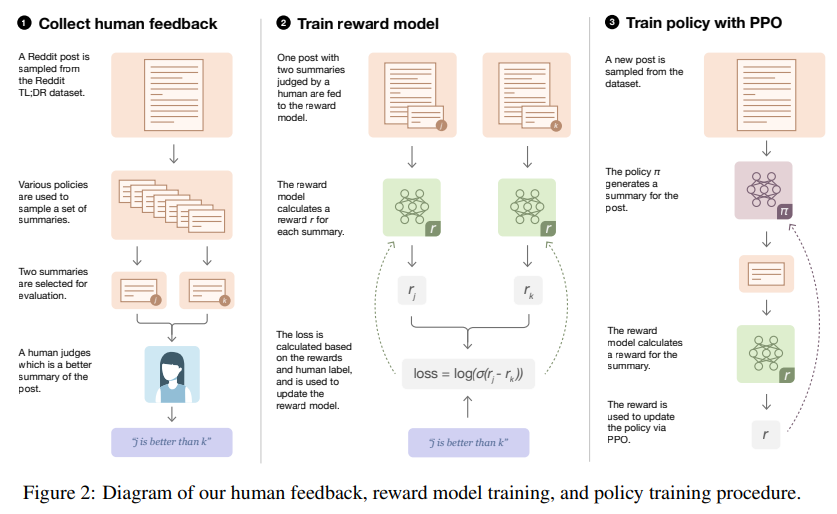
Step 1. Collect samples from existing policies and send comparisons to humans
다양한 기준선을 포함한 여러 출처의 요약을 sampling 한다.
-> 이후 사람 평가자에게 요약 쌍을 일괄 전송한다.
Step 2. Learn a reward model from human comparisons
게시물과 후보 요약이 주어지면 labeler가 판단한 대로 이 요약이 더 나은 Log odds를 예측하기 위해 reward model을 훈련한다.
Step 3. Optimize a policy against the reward model
보상 모델의 logit 출력을 특히 PPO 알고리즘(강화학습)을 사용하여 최적화 하는 보상으로 취급한다.
이 세 단계를 반복하는 것이 아닌 label을 축적하면서 project 과정에서 데이터 수집 및 train 절차를 업데이트 한다.
Datasets and task
Datasets
TL;DR 요약 데이터셋을 사용하는데 이 데이터 셋은 다양한 주제에 걸쳐 reddit에서 300만개의 게시물과 포스터에 의해 작성된 게시물 요약을 포함한다.
-> 해당 데이터셋에서 요약 길이가 품질에 미치는 영향을 최소화 하기위해 사람이 작성된 요약이 24개에서 48개의 token을 포함하는 게시물만 포함하도록 필터링 하였다. (123195개의 게시물, 이중 5%는 validation set)
labeler는 CNN/DM 참조 요약 보다 lead-3를 더 선호하는것을 발견하였다.
low temperature sampling으로 감독된 T5 모델은 기사를 광범위하게 복사하는 동안 이미 기준 요약 품질을 초과한다. 하지만 단순 추출 baseline은 사람 평가에서 TL;DR에서 성능이 좋지 않다.
-> 논문에서는 TL;DR로 훈련시킨 모델로 CNN/DM으로의 전이 성능을 연구
논문은 커뮤니티 요약 데이터셋을 바탕으로 뉴스 요약에서의 성능을 연구한다는 의미
Task
논문에서는 요약 작업을 48개의 token보다 적은 길이의 요약을 생성하는 모델로 정의하였다.
-> 독자들에게 얼마나 원본 게시물을 전달하는지로 요약 품질을 평가한다.
--> 논문에서는 비교를 위해 labeler를 고용하였다. 그리고 높은 일치성을 위해 세불 절차를 의존하였다.
Collecting human feedback
- 이전의 논문들의 방식의 결과
사람 피드백에서 언어 모델을 fine-tuning하는 이전 연구는 모델이 학습하기를 원했던 품질과 사람 labeler가 실제로 평가한것 간의 불일치를 보고하여 labeler에 따르면 고품질이지만, 연구자에 따르면 상당히 낮은 요약이였다. - 현재 논문이 이를 개선 시키기 위한 변경 사항
- 전적으로 오프라인으로 설정하여 대량의 데이터 비교를 사람 labeler에게 보내고 누적 데이터에 대해 모델을 재교육
- labeler와 실제 관계를 유지
-> 상세 지침을 그들에게 알려주고, 공유 대화방에서 답변하며, 그들의 성능에 대해 정기적으로 피드백을 제공
--> 높은 일치를 위해 모든 labeler를 교육하고 labeler - researcher 합의를 지속적으로 모니터링한다.
Model
GPT-3 스타일의 디코더를 사용
Pretrained model
큰 텍스트 corpus에서 다음 token을 auto regressive로 예측하도록 pretrained model에서 시작한다.
dataset에서 고품질 요약의 예를 context에 추가하여 이러한 모델을 zero shot baseline으로 사용한다.
Supervised baselines
TL;DR 데이터셋에서 요약을 predict하기 위해 지도학습으로 fine-tuning을 한다. 이러한 지도 모델을 사용하여 초기 요약을 sampling 하고 정책 및 보상 모델을 초기화 하고, 평가를 위한 baseline으로 사용한다.
지도 모델은 CNN/DM 데이터 셋에서 6.7B 모델을 사용하여 10년 중반부터 SOTA모델보다 더 나은 ROUGE 점수를 달성하였다.
Reward models
보상 모델을 훈련하기 위해 post x가 주어졌을때 어떤 요약이 사람이 판단하는 것보다 더 나은지 예측한다. 만약에 사람이 선호하는 요약이 면 다음과 같은 손실 함수를 쓴다
여기서 는 parameter 를 갖는 post x 및 요약 y에 대한 보상 모델의 스칼라 출력이며 D는 사람이 판단하는 데이터 셋이다.
Human feedback policies
논문에서는 위에서 훈련된 reward model을 사용하여 사람이 판단하는대로 더 높은 품질의 출력을 생성하는 정책을 훈련하고자 한다.
주로 강화학습을 사용하여 전체 요약에 대한 보상을 취급하여 수행한다.
각 시간 단계는 BPE token 이며, 논문에서는 TL;DR 데이터셋에 fine-tuning 된 모델이 되도록 policy를 초기화한다. 이전에 수행한것 처럼 학습된 RL 정책과 이 원래 감독 모델 사이의 KL divergence를 penalizes하는 용어를 reward에 포함한다.
수식은 다음과 같습니다.
여기서 KL divergence 항은 두가지 목적을 수행한다
1. 정책이 탐색하도록 장려하고, 단일 모드로 붕괴되는 것을 억제하는 entropy bonus 역할을 한다
2. 정책이 reward model이 훈련 중에 본 것과 너무 다른 출력을 생성하는 것을 배우지 않도록 보장한다.
PPO 값 함수의 경우 정책과 완전히 별개의 매개변수를 가진 트랜스포머를 사용한다.
-> 함수 업데이트가 훈련 초기에 사전 훈련된 정책을 부분적으로 파괴하는 것을 방지
--> 보상 모델의 매개변수로 값 함수를 초기화 한다.
Results
Summarizing Reddit posts from human feedback
Policies trained with human feedback are preferred to much larger supervised policies
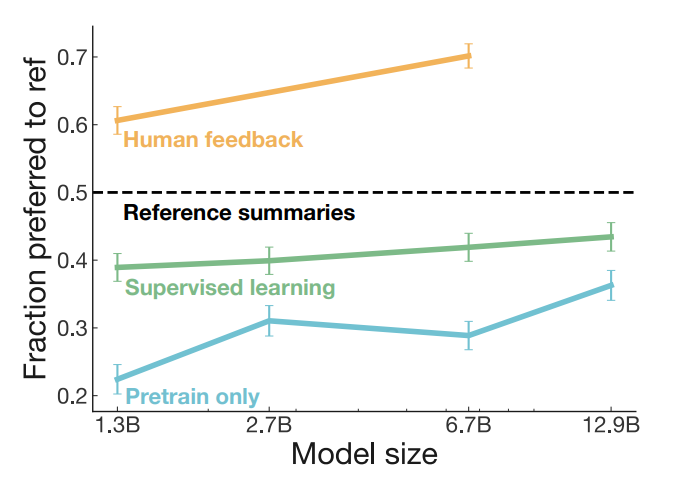
TL;DR에 대한 사람 피드백 정책을 평가하는 결과는 figure1에 나와있다. 논문에서는 사람이 선호하는 정책에 의해 생성된 요약의 백분율로 측정한다.
-> metric에 대한 지도 기준선을 크게 능가하며, 사람 피드백 모델은 지도 모델 크기의 10배를 크게 능가한다.
-> 사람 피드백 모델도 규모의 혜택을 받음을 알 수 있으며, 모두 사람에 의한 데이터셋에 사용된 사람의 묘사보다 우수하다고 판단된다.
Controlling for summary length
요약 품질을 판단할대 요약 길이는 교란의 요인이 된다.
-> 간결성의 범위에 따라 짧거나, 때로는 긴 요약이 더 나을 수 있다. 모델은 더 긴 요약을 생성하는 법을 배웠기에, 품질 개선에 많은 부분을 설명할 수 있다.
--> 길이 제어 이후 사람 피드백 모델 vs 참조 요약의 선호도가 5% 감소함을 발견하였다. 그래도 참조 요약보다 선호되었다.
How do our policies improve over the baselines?
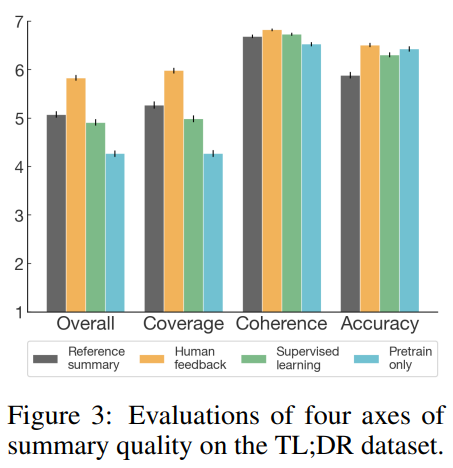
참조 요약 및 지도 기준선과 비교하여 모델 요약의 품질을 더 잘 이해하기 위해 사람 labeler가 7-point Likert scale을 사용하여 4개 차원에 걸쳐 요약 품질을 평가하는 분석을 수행
-> labeler는 품질에 대한 요약 등급을 매겼다. 그 결과 사람 피드백 모델이 모든 품질 차원에서 baseline에서 우수함을 알 수 있다.
Transfer to summarizing news articles
논문에서의 모델은 추가 train없이 CNN/DM 뉴스 기사에 우수한 요약을 생성해 냈다.
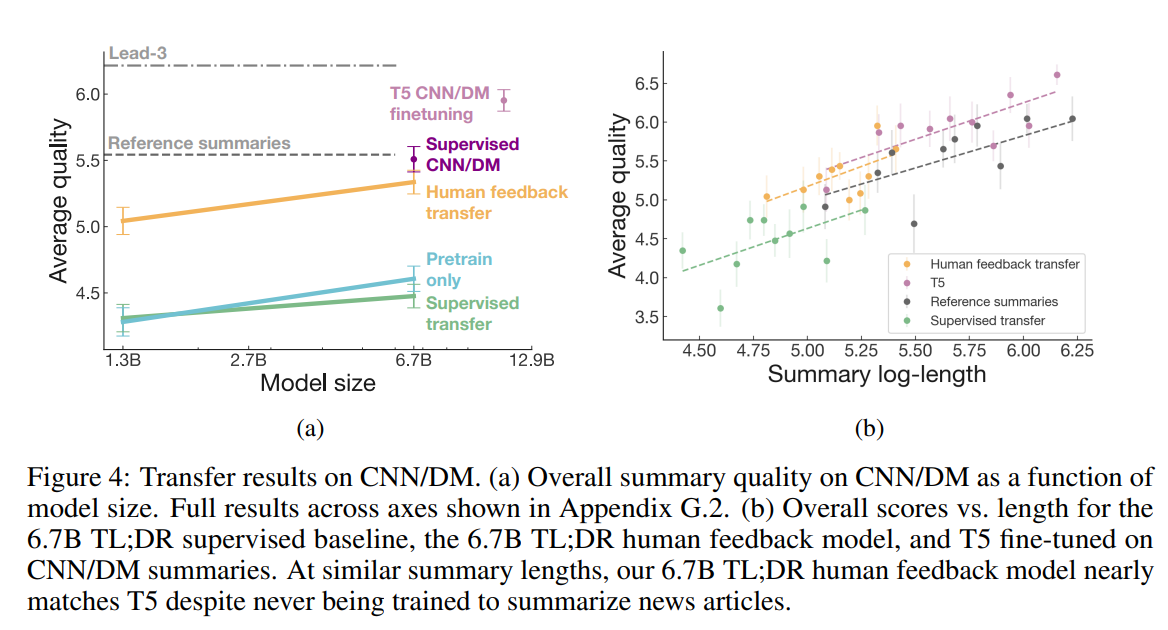
논문에서의 사람피드백 모델은 TL;DR에 대한 지도 학습을 통해 훈련된 모델과 사전 교육 corpus에서만 훈련된 모델을 크게 능가한다. 실제로 더 짧은 요약으로도 CNN/DM 참조 요약에서 fine-tuning된 6.7B 모델과 거의 동일한 성능을 발휘한다.
CNN/DM으로 전이된 사람 피드백 모델은 평균적으로 토큰의 절반 정도가 CNN/DM에서 훈련된 모델과 요약 길이 분포에서 중복이 거의 없어 직접 비교는 어렵다. -> 7 point Likert scale을 사용한다.
--> 긴 요약을 만들 수록 논문에서 제시하는 모델이 성능이 더 좋았다.(Figure 4b를 참고)
Understanding the reward model
What happens as we optimize the reward model?
보상 모델에 대해 최적화 하는 것은 사람 선호도와 일치하도록 만들게 되어 있으나 reward model은 용량이 제한되어 있고 비교적 좁은 요약 분포의 비교 데이터만 보기에 labeler의 선호를 완벽하게 표현X
-> 얼마나 잘 최적화 할지는 불확실 하다.
논문에서는 다양한 수준의 최적화 강도로 이전 버전의 reward model에 대해 최적화된 다양한 정책을 만들었고 비교하였다.
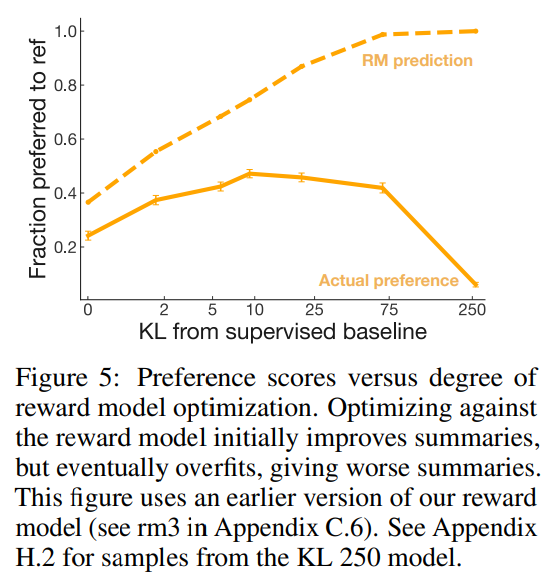
가벼운 최적화에서는 개선되지만, 추가로 최적화 함에 따라 선호도는 떨어지고 반 상관관계가 되버린다.
-> 과도한 최적화는 ROUGE에서도 발생한다.
How does reward modeling scale with increasing model and data size?
모델 및 데이터가 증가할수록 점점 성능이 좋아진다(거의 당연한 것)
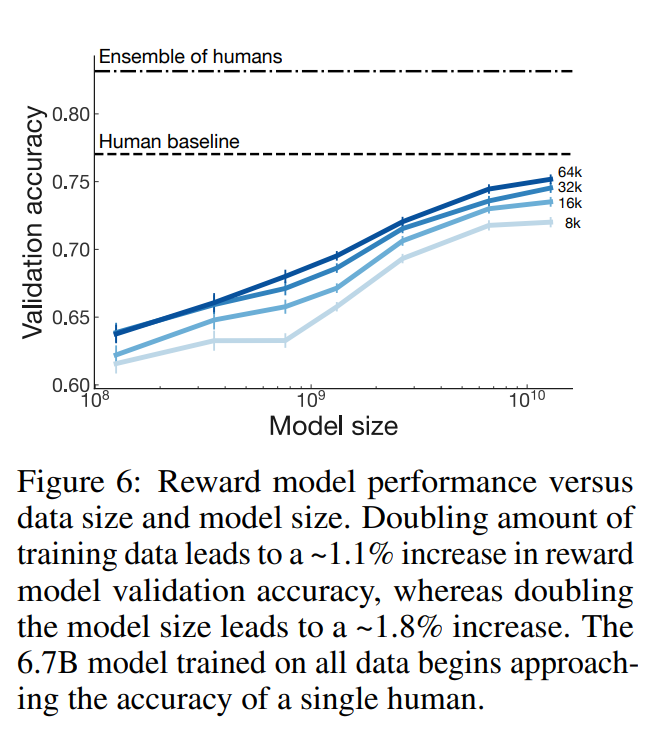
What has the reward model learned?
reward model이 CNN/DM 요약을 평가하는데 일반화 되어 labeler 선호도에 동의한다는것을 발견 -> 6.7B reward model은 labeler의 일치값과 66.9%일치한다.
reward model이 의미론적으로 중요한 세부정보에 민감함을 발견하였다. labeler가 요약을 개선하기 위해 요약을 최소한으로 편집하도록 추가 검증세트를 구성하였다.
Analyzing automatic metrics for summarization
Evaluation
다양한 자동 metric이 사람 선호도에 대한 예측 변수를 얼마나 잘하는지 reward model과 비교한다.
논문에서는 supervised model에서 ROUGE, 요약길이, 게시물 복사량 및 log 확률을 조사한다.
보상 모델이 훈련되지 않은 CNN/DM 데이터 셋에서도 다른 metric보다 일관되게 우수하였으며, 개선됨에 따라 ROUGE가 sample 품질을 추적하지를 못하였다.
ROUGE는 감독된 기본 모델의 샘플을 비교할때 label과 57%일치하지만, 사람 피드백 모델의 샘플의 경우 50%로 떨어진다.
sample 간 비교를 보면 사람과 로그 확률의 일치는 50% 이하로 떨어지지만 RM은 여전히 확률 이상을 수행한다.
-> supervised model의 크기를 확대하는 것은 label과 log확률일치를 신뢰성 있게 개선 못한다.
Optimization
최적화 체계를 사용하여 ROUGE를 최적화 하는 것이 품질을 지속적으로 증가시키지 않음을 보여준다.
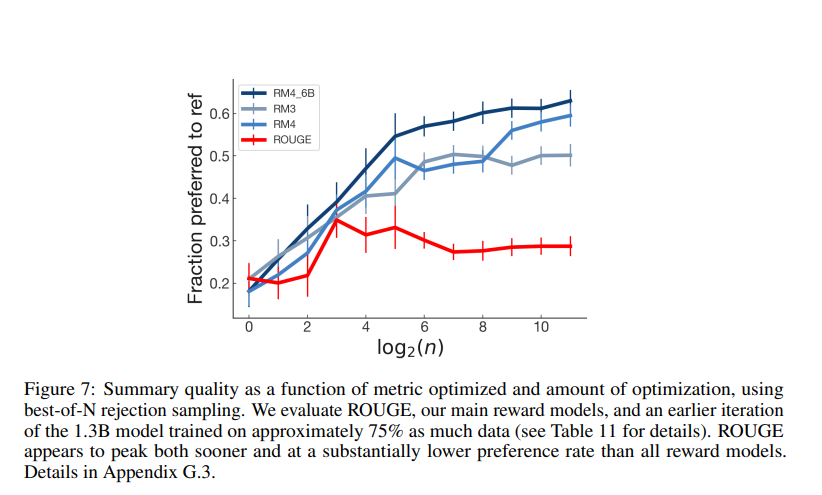
Discussion
Limitations
최종 모델을 생산하는데까지 시간과 비용이 많이든다
RL로 6.7B 모델을 fine-tuning하는데 320 GPU일이 필요하였다.
이전 작업에 비해 데이터 수집 비용도 많이 든다 - 사람이 labeling 하기 때문
-> 고품질의 사람 데이터와 같은 baseline을 수집할 수는 없다.
Future directions
사람이 샘플을 비교할 수 있는 모든 작업에서 적용 될 수 있다.
-> maximum likelihood sample의 분포 이동 및 퇴화가 문제될 수 있는 긴 샘플을 생성하는데 특히 중요할 것이다.
ML 시스템이 사람 설계자의 의도와 일치하는지 식별하기가 어렵다.
-> 사람이 정확하고 빠르게 평가하도록 ML 시스템을 훈련
-> 훈련 탐색을 할 수 있는 사람 피드백의 풍부한 풍경
--> 이 모든 피드백은 reward model의 개선 및 policy 정책을 훈련하기 위한 신호로 사용 가능
Broader impacts
- 모델 출력의 품질을 평가하는 모든 작업에 사용가능
- 기계학습 알고리즘을 설계자의 선호도와 일치시키는 잠재적으로 긍정적인효과
- 장기적인 기계학습의 문제로부터의 위험을 완화하고 사람이 관심을 가지는 것을 더 잘 일치시키기 위한 것
단점
-
악의적인 행위자가 사회적 악을 야기하는 모델을 더 쉽게 학습하게끔 한다.
-
대규모 모델은 많은 그룹에 상당한 영향을 미칠 수 있다. -> 의견을 달리하는 사람도 있을텐데 이런 경우 상당한 주의가 필요하다
-
사람만이 달성할 수 있던 작업이 기게학습 알고리즘의 발전으로 대체될 수 있다.
