Abstract
LLM 모델은 parametric 방법을 통하여 매개변수에 지식을 저장
-> 지식을 업데이트를 하는데 제한, downstream 작업에 대해서 잘한다.
parametric 한 방법과 Non-parametric 한 방법을 결합한 RAG라는 방법을 제안 -> parametric한 방법은 seq2seq model이며, Non-parametric한 model은 retriever를 사용한 모델이다.
이러한 RAG 모델을 두가지 방법을 만들고 이를 fine-tuning 및 평가를 진행한 결과 SOTA parametric-only seq2seq보다 성능이 좋았다.
Introduction
Pretrained LLM
장점 : Parameter화 된 지식 기반으로 외부 메모리를 접근 안해도 잘 답변
단점 : 확장 및 수정의 어려움, hallucination의 문제
-> RAG라는 방법의 제안
특징 : parameter화 된 모델(seq2seq)에 Non-parameter화된 메모리(retriever)를 부여
-> web QA, natural QA 등의 작업에서 SOTA를 달성
Methods
input sequence x를 사용하여서 text document z를 검색하여 y를 생성할때 추가 context를 사용하는 RAG model을 탐색
1. query x가 주어지면 text passage에 대한 top-k를 반환하는 retriver []
2. retrieved된 passage, input을 기반으로 생성하는 generator []
Models
RAG-Sequence Model
동일하게 검색된 document를 사용하여 sequence를 생성하는 모델
top-k approximation을 통해 seq2seq probablility p를 얻기 위한 passage를 marginalized single latent variable로 처리
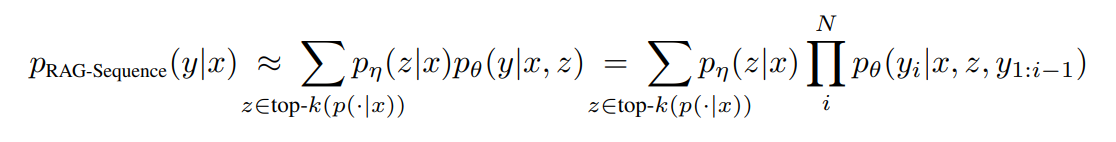
RAG-Token Model
각 token에 대해 다른 latent passage를 사용하며, 이를 통해 generator는 답변 생성이 여러 document의 내용을 선택
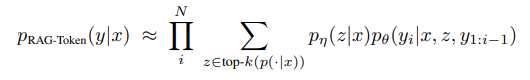
Retriever: DPR
검색 component 는 DPR를 base로 하며, DPR은 bi-encoder구조를 따른다.
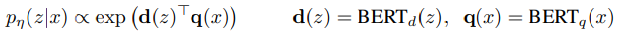
위의 수식에서 d(z)는 BERTbase에 의해 생성된 document를 나타내는 표현이고, q(x)는 query encoder에서 생성된 query 표현이다.
가장 높은 prior probability는 k개의 요소 z list topk를 효율적으로 계산하기 위해 FAISS의 MIPS를 사용한다.
훈련은 TriviaQA, Natural Question을 통해 답변이 포함된 document를 검색하도록 수행
Generator: BART
Generator로 encoder-decoder model인 BART large를 사용
BART에서 생성을 하기 위해 input x와 content z를 결합하는데 이를 위해 단순결합(concatenate)를 수행
Training
어떠한 document를 감독하지 않고 어떻게 검색해야 하는지에 대해 retriever및 generator를 훈련한다.
input-output 쌍이 주어지면 Adam을 사용하여 negative marginal log-likelihood를 minimize를 한다.
학습을 하는데 document encoder를 업데이트를 하면 정기적으로 document indexing도 업데이트 해야하므로 비용이 많이 들어 이는 고정하고 query encoder, generator만 fine-tuning을 진행한다.
Decoding
test할때는 RAG-sequence와 RAG-token이 argmaxy(y|x)를 근사하는 다른 방법이 필요하다.
RAG-Token
transition probability를 가진 seq2seq generator로 볼 수 있다.
decoding할때는 plug : 를 standard beam decoder에 연결하여 한다
RAG-Sequence
각 문서 z에 대해 beam search를 사용하여 에 대해 각 hypothesis에 점수를 부여한다.
모든 beam 집합 hypothesis y의 확률을 추정하기 위해 y beam에 나타나지 않는 각 document z에 대해 추가적으로 forward pass를 실행하고 generator score에 인 경우를 추가로 추정 할 수 있다.
이러한 candidate set Y가 생성된 후에는 추가 forward pass를 할 필요가 없어 fast decoding이라 한다.
Experiments
wikipedia 2018년 12월의 dump를 사용
각 기사를 100-word로 분할되어 21M개의 document를 생성한다.
DPR document retriever를 사용하여서 document emvedding을 계산하고 빠른 검색을 위해 Hierarchical Navigable small world approximation과 FAISS를 통하여 single MIPS index를 만든다.
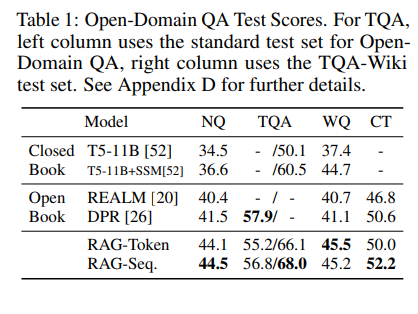
Open-domain Question Answering
knowledge-intensive tasks에 사용되는 경우가 많으며 답변의 negative log likelihood를 최소화 하여 RAG를 훈련한다.
비교대상은 closed book QA 방식과 비교를 하며,
데이터셋은
1. Natural Questions(NQ)
2. TriviaQA(TQA)
3. WebQuestion(WQ)
4. CuratedTrec(CT)
Abstractive Question Answering
자유 형식의 추상적 텍스트 생성
-> Open-domain abstractive QA를 하기 위해서 MSMARCO 작업을 사용
해당 질문들은 wikipedia만으로는 답변 할 수 없으며, hyperparameter knowledge에 의존하여 합리적인 답변을 생성할 수 있다.
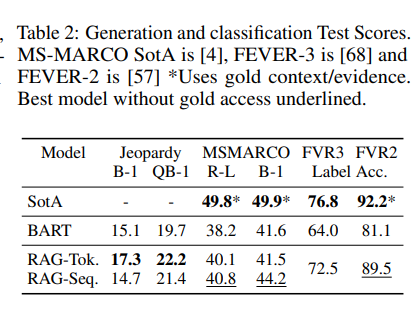
Jeopardy Question Generation
non QA 설정에서 RAG의 생성능력을 평가하기 위해 open-domain question 생성을 연구한다.
-> searchQA를 분할하여 사용, 비교를 위해 BART모델을 훈련
Table2(바로 위의 표에 결과도 같이 존재)
Fact Verification
wikipedia에서 증거를 검색한 다음 wikipedia에서 추론하여 참인지 거짓인지 확인 불가인지 분류해야한다.
standard 3way classification 작업과 2way 작업의 두가지 변형을 탐구하며, 두 경우 모두 정확도를 report한다.
Table2(바로 위의 표에 결과도 같이 존재)
Results
Additional Results
Generation Diversity : RAG model이 BART model 보다 더 사실적이고 구체적임을 보여주며, RAG-sequence의 생성이 RAG-token의 생성보다 diversity-promoting decoding없이도 BART보다 더 다양함을 보여줌
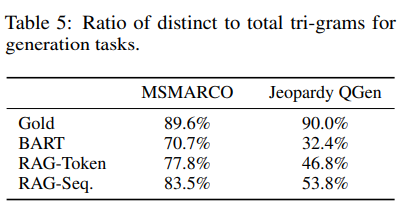
Retrieval Ablations : 검색 매커니즘을 평가하기 위해 BM25와 비교를 하며, RAG의 retriever를 고정 BM25 system을 대체하고 p(z|x)를 계산할때 BM25의 검색 점수를 logit으로 사용
-> FEVER의 경우 단어 오버랩 기반으로 검색하여 BM25가 최상의 성능을 발휘하나, 다른 작업에서는 RAG가 더 좋다.
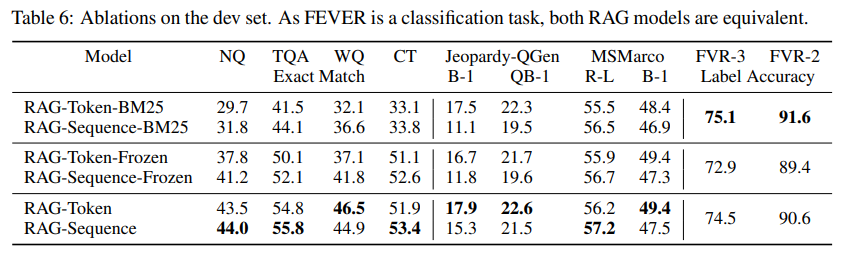
Index hot-swapping
RAG의 특징 : knowledge를 test 할때도 업데이트를 할 수 있다.
leader와 wikipedia dataset을 교체함으로써의 성능의 차이를 확인
16년 leader를 16년 data로 할 경우 70%
18년 leader를 18년 data로 할 경우 68% 정답률을 보여 주었으며, 이는 Non-parametric 한 부분만 교체해도 RAG는 업데이트 됨을 보여줌
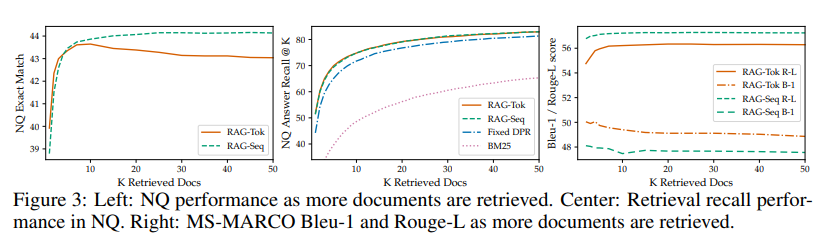
Effect of Retrieving more documents
latent document를 5개또는 10개를 사용하여 학습되며, model간의 성능에는 차이가 없으나, 검색된 document를 조정할 수 있는 유연성이 있다.
많은 문서를 검색시에는 향상되지만 10개 검색된 문서에서 RAG-token에 대한 성능 peak를 찍었음을 볼 수 있으며, 많이 하면 할수록 BLEU-1를 희생하여 ROUGE-L이 더 높아지지만 RAG-Sequence의 경우 효과가 덜 뚜렷함을 보여준다.
Related Work
- Single-Task Retrieval
- General-Purpose Architectures for NLP
- Learned Retrieval
- Memory-based Architectures
- Retrieve-and-Edit approaches
