[0] R
: 통계를 분석하고 데이터를 시각화 하기위해 사용하는 프로그램
#을 입력하면 주석을 달 수 있음
[1] 변수
변수명의 기본 원칙
- 영문자, 숫자, _ 혹은 . 으로 구성
- 첫글자는 영문자로 시작
- 대소문자를 구분
- 낙타표기법 (EX) helloWorld, goAway ...
자료형
: 변수 선언 할때 담긴 값의 종류에 따라 자동으로 자료형이 결정된다.
numeric수치형character논리형integer정수형double실수형logical논리형complex복소수형factor범주형data.frame데이터 프레임naNot availablenanNot a number
1) 스칼라 변수 (Scalar)
: 값을 하나만 담는 변수
변수 선언
name <- "value"
2) 벡터 변수 (Vector)
: 같은 자료형의 값을 둘 이상 담는 연속된 선형 구조의 변수
: index가 주어지는데 1부터 시작함
변수 선언
name <- c( "value1", "value2", "value3")
참조
name[2]=>"value2"
:변수명[인덱스]=>해당값
3) Matrix 자료 구조
: 같은 자료형의 값을 행과 열을 가진 표 형태로 담는 변수
: 열을 기준으로 값이 차례로 입력이 됨
: 설정된 행과 열에 비해 값이 모자랄 경우, 처음 값부터 재사용 함
: 설정된 행과 열에 비해 값이 많을 경우, 남는 값은 사용하지 않음
변수 선언
name <- matrix( c( value ) )
:nrow를 지정하면 행의 수를 조절 가능
: 행을 기준으로 하고 싶을 땐byrow = T
참조
name[ r, c ]=>value
:변수명[행 인덱스, 열 인덱스]=>해당값
4) Array 자료 구조
: 같은 자료형의 값을 여러 (표를 가진) 페이지의 형태로 담는 변수
EX) 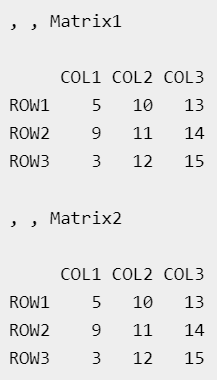
변수 선언
name <- array( value, c( row, col, page ) )
참조
name[ r, c, p ]=>value
:변수명[행 인덱스, 열 인덱스, 페이지]=>해당값
5) DataFrame 자료 구조
: 여러 자료형의 값을 표 형태로 담는 변수
: 열은 같은 자료형이어야 함
: 열의 내용은 벡터형, 이러한 열들을 리스트식으로 담는 구조
변수 선언
name <- data.frame( key1 = data1, key2 = data2, key3 = data3 )
: 여기서key1,key2,key3는 column 명으로 지정됨
name <- read.csv("파일경로" , sep = ",", header = T/F )
: 디렉토리가 파일 있는 곳으로 지정되어있다면 파일명만 써도 가능
: 파일 경로는\가 아니라/를 사용
column 참조
name$column
[2] 함수
1) sum( data, na.rm = T/F )
: data가 계산 가능한 자료형일 경우 그들의 합계를 내주는 함수
:na.rm은 결측치가 있을 경우T로 해두면 결측치를 제외한 값들을 연산 함
2) ls()
: 현재 사용중은 변수명들을 확인할 수 있음
3) is.자료형( data )
: data의 자료형이 입력한 자료형이 맞다면
TRUE, 아니라면FALSE를 반환 함
4) as.자료형( data )
: data의 자료형을 입력한 자료형으로 변환 함
날짜형 변환
as.Date( "년/월/일", "%y/%m/%d" )
: 뒤의 format과 형태만 맞춰준다면 다른 형태도 가능
: 날짜 구조 제어문자
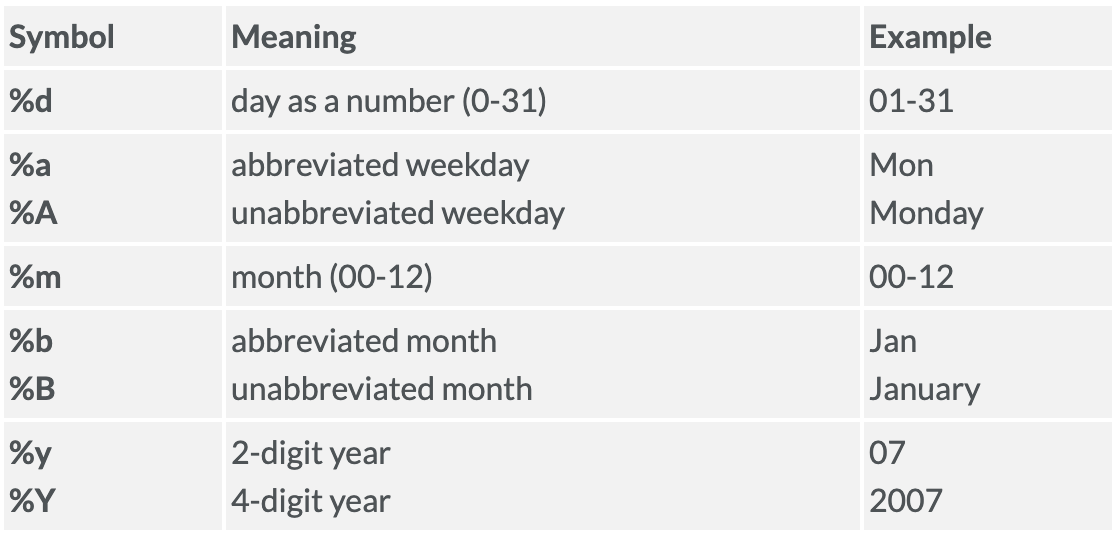
5) striptime( "년/월/일 시:분:초:", "%y/%m/%d %H:%M:%S" )
: 뒤의 format과 형태만 맞춰준다면 다른 형태도 가능
: 시간 구조 제어문자시간 ( 24 / 12 ) ->
%H/%I
분 ->%M
초 ->%S
6) mode( data ) / class( data )
:
mode는 자료의 내용의 자료형을 반환
:class는 자료 구조의 자료형을 반환
7) args( function ) / example( function )
:
args는 함수 사용법을 제공
:example은 함수의 사용 예제를 제공
8) str( data )
: 자료의 구조 확인
: 관측치 ( observation ) -> 행 갯수
: 변수 ( Variables ) -> 열 갯수
: 열의 요소
9) summary( data )
: 열 단위 사분위수, 최소값, 최대값, 중위수, 평균을 반환
10) apply( data, 1/2, function )
: data에 함수를 적용하여 나온 값들을 1은 행 기준, 2는 열 기준으로 반환
11) subset( data, 조건 )
: data에서 조건에 맞는 부분만 반환
12) merge( df1, df2, by.x = "공통요소", by.y = "공통요소" )
: 서로 다른 데이터를 가진 두 데이터 프레임 사이에 공통적인 데이터를 가진 열이 존재할 때 그 요소들을 기준으로 병합해줌
