ABSTRACT
Fresh & Tail 콘텐츠를 성공적으로 추천하기 위한 Multi-funnel 추천 시스템을 구축
- coverage를 위한 1) two-tower model 과 relevance를 위한 2) Sequential model을 결합
→ 이를 통해 “coverage”와 “relevance”의 균형을 맞추게 됨
- ‘범위(coverage)'는 추천 시스템이 다양하고 넓은 범위의 콘텐츠를 얼마나 잘 포괄하는지를 나타냄
- '관련성(relevance)'은 추천된 콘텐츠가 사용자의 개인적인 취향이나 필요에 얼마나 부합하는지를 나타냄
→ 두 퍼널을 결합해 새로운 콘텐츠에 대한 초기 노출을 보장하면서 동시에 사용자의 선호도와 관련성이 높은 콘텐츠를 추천
1 INTRODUCTION
- 논문의 목표는 Cold-start 문제를 유발하는 feedback loop를 깨고, 좋은 퀄리티의 새로운 콘텐츠들도 주목받을 기회를 얻는 건강한 플랫폼을 만드는 것
- 기존에도 cold-start 추천을 해결하기 위한 연구가 지속되었지만, 대규모 추천 플랫폼에서 방대한 양의 신규 콘텐츠를 Bootstrap하는 방법은 여전히 연구가 필요하다.
-
GPTBootstrap?
논문의 맥락에서 "bootstrap"은 콘텐츠 추천 시스템에서 신규 콘텐츠가 초기 노출을 얻어 자체적으로 성장할 수 있도록 지원하는 과정을 의미합니다. 즉, 새로운 콘텐츠가 필요한 초기 인지도와 상호 작용을 획득하여 시스템에서 자연스럽게 추천되고 더 많은 관심을 받을 수 있도록 '부팅'하는 것을 뜻합니다. 이는 통계적인 샘플링과는 다른 의미로 사용됩니다.부트스트래핑 과정은 새로운 콘텐츠나 덜 알려진 콘텐츠가 초기 노출을 통해 필요한 주목과 상호 작용을 얻을 수 있도록 지원하는 단계를 말하며, 이 과정을 거친 후 콘텐츠가 특정 수준의 긍정적 반응을 얻었다면, 그 콘텐츠는 "발견 가능한 코퍼스(discoverable corpus)"에 포함됩니다.
-
- 하지만, 딜레마가 있음 1) corpus의 전체 스펙트럼을 탐색할 수 있는 시스템은 장기적인 사용자 경험을 향상시킴 2) 그러나 확실성이 덜한 콘텐츠가 추천될 때, 신규 콘텐츠 추천은 종종 단기적인 사용자 경험의 cost가 됨 → 이를 완화시킬 수 있는 방법을 제안하고자 함.
-
단기적인 유저 경험과 장기적인 유저 경험이 균형을 이루기 위해, 두가지 차원으로 효율성을 평가함
(1) coverage : 사용자에게 신선한 콘텐츠를 더 많이 노출하고 있는지
(2) relevance : 사용자가 관심 가질만 한 콘텐츠들을 추천하고 있는지 -
fresh content recommendation stack을 디자인하는 과정에서 고려할 것들
(1) 기존에 존재하는 추천 스택 구조 중 어디에 위치시켜야 하는가?
: relevance를 위해 따로 분리함(2) stack에 어떤 요소가 필요한가?
: nomination system, graduation filter, ranking system을 포함(3) coverage와 relevance의 balance를 어떻게 유지할 것인가?
: 높은 coverage를 가진 모델과 높은 relevance를 가진 모델 사이에서 사용자 요청을 전환하는 multi-funnel nomination system을 구축(4) 적거나 거의 없는 선행된 engagement data를 가진 contents를 어떻게 모델링 할 것인가?
: two-tower DNN 모델을 활용하여 초기 배포를 부트스트랩 → 사용자 피드백에 대해 거의 실시간으로 업데이트하는 sequence model을 사용하여 관심 있어할 만한 고객군을 빠르게 찾음(5) fresh content recommendation 의 효과를 어떻게 측정할 것인가?
: user-corpus co-diverted experiment framework를 채택GPTuser-corpus co-diverted experiment framework ? 대조군과 실험군으로 나누어 추천시스템의 성능을 평가
2 FRESH CONTENT RECOMMENDATION
파이프라인 설정
기존의 추천 시스템에서는 Fresh and Tail contents가 발견되기 어려움
→ Fresh(𝑋일 이전에 생성된) & Tail(𝑌개 미만의 긍정적 사용자 상호작용) 컨텐츠에 대해 하나의 (유동적인) 슬롯을 할당
- 나머지 슬롯은 여전히 기존의 생산 추천 시스템을 사용
- Slot? 사용자 인터페이스 상에서 하나의 아이템 또는 컨텐츠를 표시하는 데 할당된 자리 = 아래 Fig2.에서 분홍색으로 표시된 공간
- Slot? 사용자 인터페이스 상에서 하나의 아이템 또는 컨텐츠를 표시하는 데 할당된 자리 = 아래 Fig2.에서 분홍색으로 표시된 공간
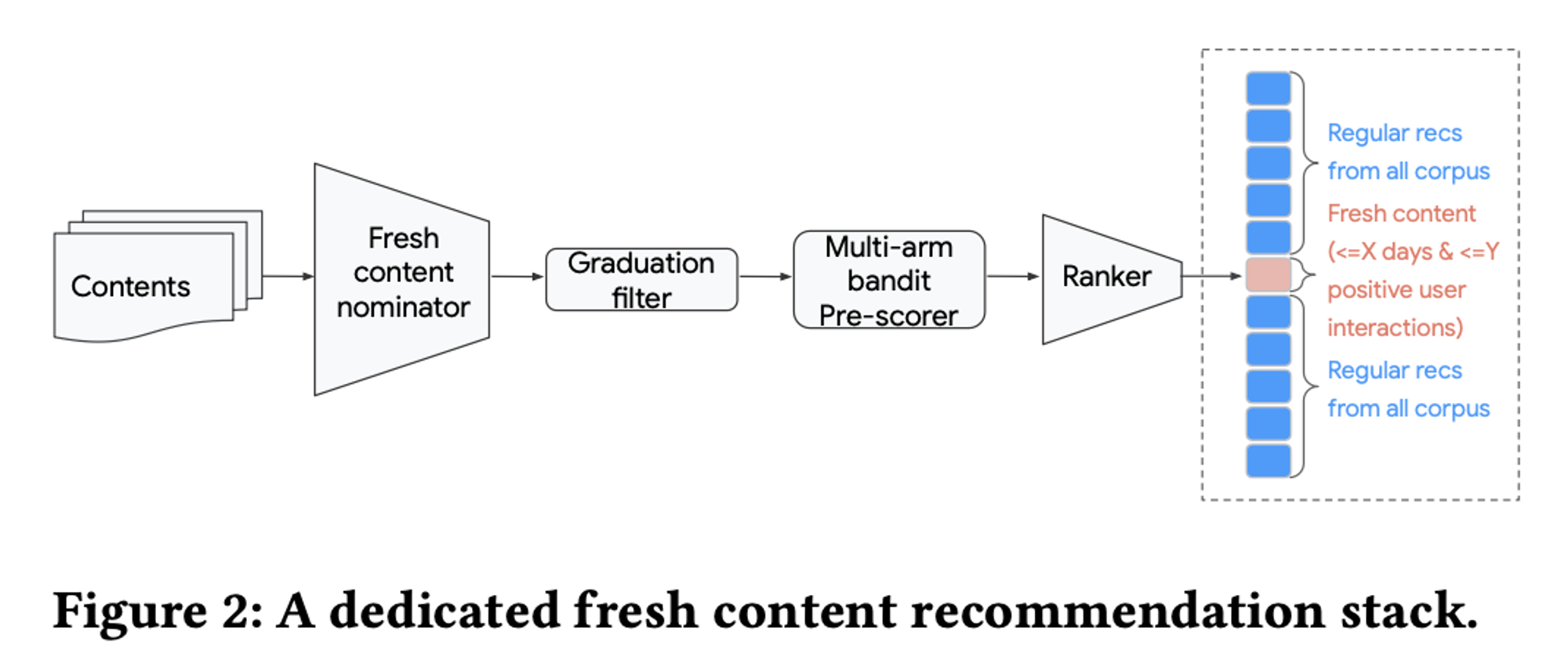
1) Fresh content nominator
Cold-start item recommendation problem을 극복하기 위해 투 타워 모델 사용
- Query Tower: 사용자의 소비 이력을 기반으로 사용자의 특성을 인코딩
- Item Tower: 개별 아이템의 특성을 인코딩(상호작용이 없거나 적은 아이템에 대해서도 일반화 가능)
GPTmultiscale quantization 의 작동 원리 Multiscale quantization은 데이터 포인트(예: 이미지, 텍스트, 사용자 프로필 등의 벡터 표현)를 소수의 대표적인 값(중심, centroids)으로 압축하여 저장하고, 이 중심들을 이용하여 실제 데이터 포인트를 빠르게 근사 검색할 수 있게 합니다. 이 방법은 다음과 같은 단계로 이루어집니다:- 분할: 데이터셋을 여러 개의 레벨 또는 스케일로 분할합니다. 각 레벨에서 데이터의 특성에 따라 서로 다른 정밀도로 정보를 저장합니다.
- 양자화: 각 레벨에서 데이터를 중심(quantization centers)에 매핑하여 데이터를 압축합니다. 높은 레벨에서는 더 넓은 범위를 대표하는 중심을 사용하고, 낮은 레벨에서는 더 세밀한 정보를 포착하기 위해 더 많고 구체적인 중심을 사용합니다.
- 인덱싱: 양자화된 데이터 중심을 기반으로 인덱스를 생성하여, 쿼리가 주어졌을 때 관련 데이터를 빠르게 찾을 수 있습니다.
2) Graduation filter : 실시간으로 사용자에 의해 최소 n회 소비된 컨텐츠를 제거
3) Ranking : pre-scorer을 통해 상위 10개 후보를 추출 → main 추천시스템과 공유하는 ranker를 통해 최종 top-1 콘텐츠를 선택
User corpus co-diverted experiment.
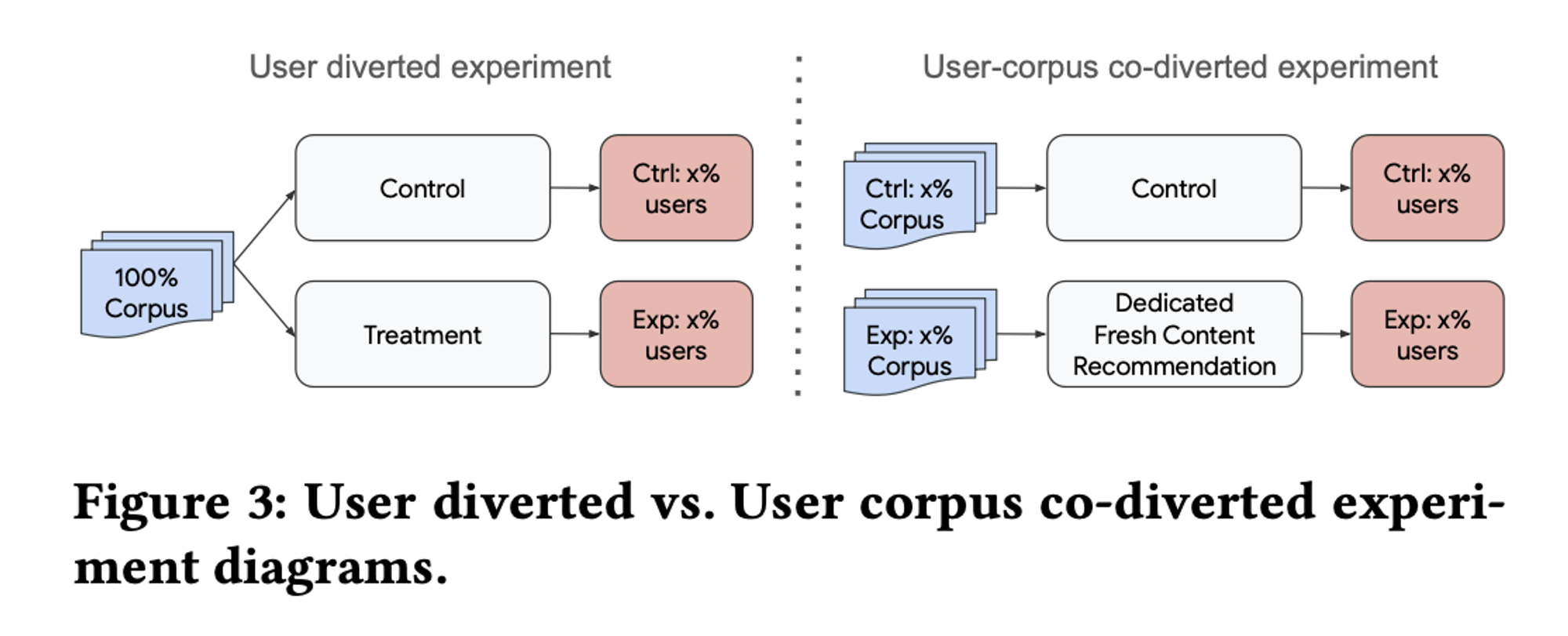
전통적인 A/B Test 방법 (왼쪽 그림)
- 무작위로 실험군과 대조군에 할당되어, 전체 Corpus에 대한 추천을 받음
- 두 그룹이 같은 코퍼스를 공유하기 때문에, 코퍼스에 대한 처리 효과를 측정할 수 없음
(예를 들어, 신규 추천 스택에서 보여주는 콘텐츠가 대조군에 나타날 수도 있음)
논문에서 제안하는 A/B Test 방법 (오른쪽 그림)
- x%의 코퍼스를 대조군에, 그리고 겹치지 않는 다른 x%의 코퍼스를 실험군에 할당
- 대조군 사용자들은 기존의 추천 시스템을 사용해 추천받고, 실험군 사용자들은 “전용 슬롯”이 있는 추천시스템에서 추천받음 (다른 slot은 모두 기존의 추천 시스템을 사용)
Performance Evaluation Metrics.
coverage & relevance 를 측정
-
Daily Unique Impressed Contents at 𝐾 (DUIC@𝐾 ) : 매일 K 번 표출되는 고유 콘텐츠의 수
GPTImpression ?
"인상(Impression)"이라는 용어는 디지털 마케팅 및 온라인 광고 분야에서 사용자에게 어떤 콘텐츠나 광고가 화면에 표시되는 것을 의미
중요성
1. coverage 측정: 인상은 특정 콘텐츠나 광고가 얼마나 많은 사람들에게 도달했는지를 측정하는 데 사용됩니다. 이를 통해 마케터와 콘텐츠 제작자는 자신들의 메시지가 얼마나 넓은 범위로 퍼져나가고 있는지 파악할 수 있습니다.
2. 캠페인 효과 분석: 광고 캠페인의 성공을 평가할 때 인상 수는 중요한 지표 중 하나입니다. 많은 인상 수는 캠페인이 많은 사람들에게 노출되었다는 것을 의미하며, 이는 캠페인의 초기 성공을 나타내는 지표로 활용될 수 있습니다.
3. 광고비 책정: 많은 온라인 광고 플랫폼에서는 인상 수를 기반으로 광고비를 책정합니다. 즉, 광고가 노출된 횟수에 따라 광고주가 비용을 지불합니다(CPM, Cost Per Mille, 천 단위 비용).
상대적으로 낮은 K 값에 초점을 맞추어 콘텐츠 coverage의 범위를 측정
( K가 낮은 경우, 시스템이 다양한 콘텐츠를 얼마나 효과적으로 사용자에게 노출시키고 있는지 보여줌)
→ 추천 시스템이 신규 콘텐츠를 효과적으로 홍보하고 있는지를 파악하는 데 유용한 지표GPTK값- K값이 낮을 때:
- 다양성 강조: K값이 낮으면, 예를 들어 K=1이라고 할 때, 한 번이라도 인상된 모든 고유 콘텐츠를 계산합니다. 이는 추천 시스템이 매우 다양한 콘텐츠를 얼마나 노출시키는지를 평가하는 데 유용합니다.
- 보다 포괄적인 평가: 낮은 K값은 시스템이 추천하는 콘텐츠의 전체 범위를 포괄적으로 파악할 수 있게 해 줍니다. 즉, 추천 시스템이 많은 수의 다른 콘텐츠를 한 번 이상 사용자에게 노출시키고 있음을 보여줍니다.
- K값이 높을 때:
- 콘텐츠의 인기도 집중: K값이 높을 때는 여러 번 인상된 콘텐츠만 고려됩니다. 예를 들어 K=10이라면, 하루에 적어도 10번 노출된 콘텐츠만 계산됩니다. 이는 특정 콘텐츠가 사용자에게 반복적으로 얼마나 매력적이었는지를 보여주며, 해당 콘텐츠의 인기나 효과를 더 집중적으로 분석할 수 있습니다.
- 적은 수의 콘텐츠에 초점: 높은 K값은 반복적으로 많이 노출된 콘텐츠만을 대상으로 하기 때문에, 분석 대상 콘텐츠의 수가 상대적으로 적습니다. 이는 추천 시스템이 특정 콘텐츠에 사용자의 관심을 집중시키는 데 효과적이라는 것을 나타낼 수 있습니다.
- K값이 낮을 때:
-
신규 콘텐츠 체류 시간 (DwellTime) : 사용자가 신규 콘텐츠에 머문 시간을 측정
→ 더 긴 체류 시간은 시스템이 사용자의 신규 콘텐츠에 대한 선호도를 더 정확하게 파악하여, 더 높은 관련성(relevance)을 달성하고 있음을 의미
-
콘텐츠 수 X가 Y일 동안 받은 긍정적 상호작용 수 (Discoverable Corpus@X,Ydays):
bootstrapping 이후, 신규 추천 스택에서 받은 상호작용은 제외한 긍정적 상호작용을 측정 (스스로 바이럴되는 콘텐츠를 좋은 콘텐츠라고 생각함)
-
이외에도, 플랫폼 전체에서 사용자가 보내는 총 시간을 측정하는 사용자 지표도 함께 측정
(신규 콘텐츠 추천이 단기적인 사용자 경험을 너무 저해하지 않도록)
2.1 Values of Fresh Recommendation
- 코퍼스 coverage 개선
- 발견 가능한 코퍼스 증가
- 콘텐츠 제작자의 업로드 증가 (콘텐츠 제작자들을 동기부여함)
- 신규 콘텐츠에 대한 사용자의 상호 작용이 증가하였으나, 전체 플랫폼에서의 사용자 체류 시간은 소폭 감소. 그러나 적은 수의 콘텐츠를 제공자하는 계정에 대한 사용자 체류 시간은 상당히 증가
3 MULTI-FUNNEL FRESH CONTENT RECOMMENDATION
RQ1 적은 상호 작용이 있는 신규 콘텐츠의 경우, 효과적으로 사용자의 관련성을 추론하고 콘텐츠를 bootstrap할 수 있는 방법은 무엇일까?
RQ2 초기 상호 작용 일부를 축적한 후에, 제한된 상호 작용 피드백을 빠르게 활용하여 가치 있는 콘텐츠를 증폭할 수 있는 방법은 무엇일까?
RQ3 콘텐츠 일반화와 실시간 학습 사이의 균형을 어떻게 맞추고, 신규 추천을 위한 user cost를 어떻게 줄일 수 있을까?
3.1 Content Generalization
Two tower architecture 활용
- 사용자와 아이템의 정보를 인코딩하고, 두 타워 사이의 dot product을 학습하여 사용자와 아이템 사이의 선호도를 예측
- 여전히 popularity bias가 있음 → 신규 콘텐츠 추천을 위해 모델을 조정
-
1) Item tower에서 item ID를 제거 : 모델이 개별 아이템에 대한 과거의 선호를 기억하는 것을 방지
-
2) 아이템의 과거의 선호를 나타내는 특성(impression, positive engagement 등)도 제외
→ 인기 있는 콘텐츠와 새로 업로드된 콘텐츠 사이를 일반화할 수 있는 메타 특성만이 학습을 위해 item tower에 포함
-
이러한 변경이 coverage를 개선하는지 확인하기 위해 온라인 A/B 테스팅을 수행
- 대조군: 아이템 타워와 관련된 모든 메타 특성을 포함한 Two tower model
- 실험군: item ID와 item의 인기도를 나타내는 특성을 아이템 타워에서 제외
→ DUIC@𝐾 3.3% 증가, 신규 콘텐츠 체류 시간도 2.6% 증가
Content Features in Used.
대조군과 실험군 모두에서 사용된 콘텐츠 특성은 콘텐츠 자체에서 파생된 다양한 범주의 특성들을 포함
- semantic topic, taxonomic topic, language of the content.
- 낮은 품질의 콘텐츠를 걸러내기 위해 평균 평점(average rating)도 포함
3.2 Real-Time Learning
일반화를 위해 콘텐츠 특성에 크게 의존하는 nominator는 신규 콘텐츠의 초기 bootstrap에는 효과적이지만, 사용자의 초기 피드백에 빠르게 반응할 기억 능력이 부족함 → 스트리밍 방식으로 새로운 상호작용 데이터가 제공될 때마다 학습하는 real-time nominator가 필요
이를 위해 (i) 실시간에 가까운 사용자 상호작용 데이터를 활용하여 학습
(ii) latency(지연)이 적은 개인화 검색 모델을 구축해야 함 → end-to-end latency를 몇시간 정도로 줄임
콘텐츠 검색을 위해 사용되는 Two-tower 모델( Query tower / item tower) 의 구조
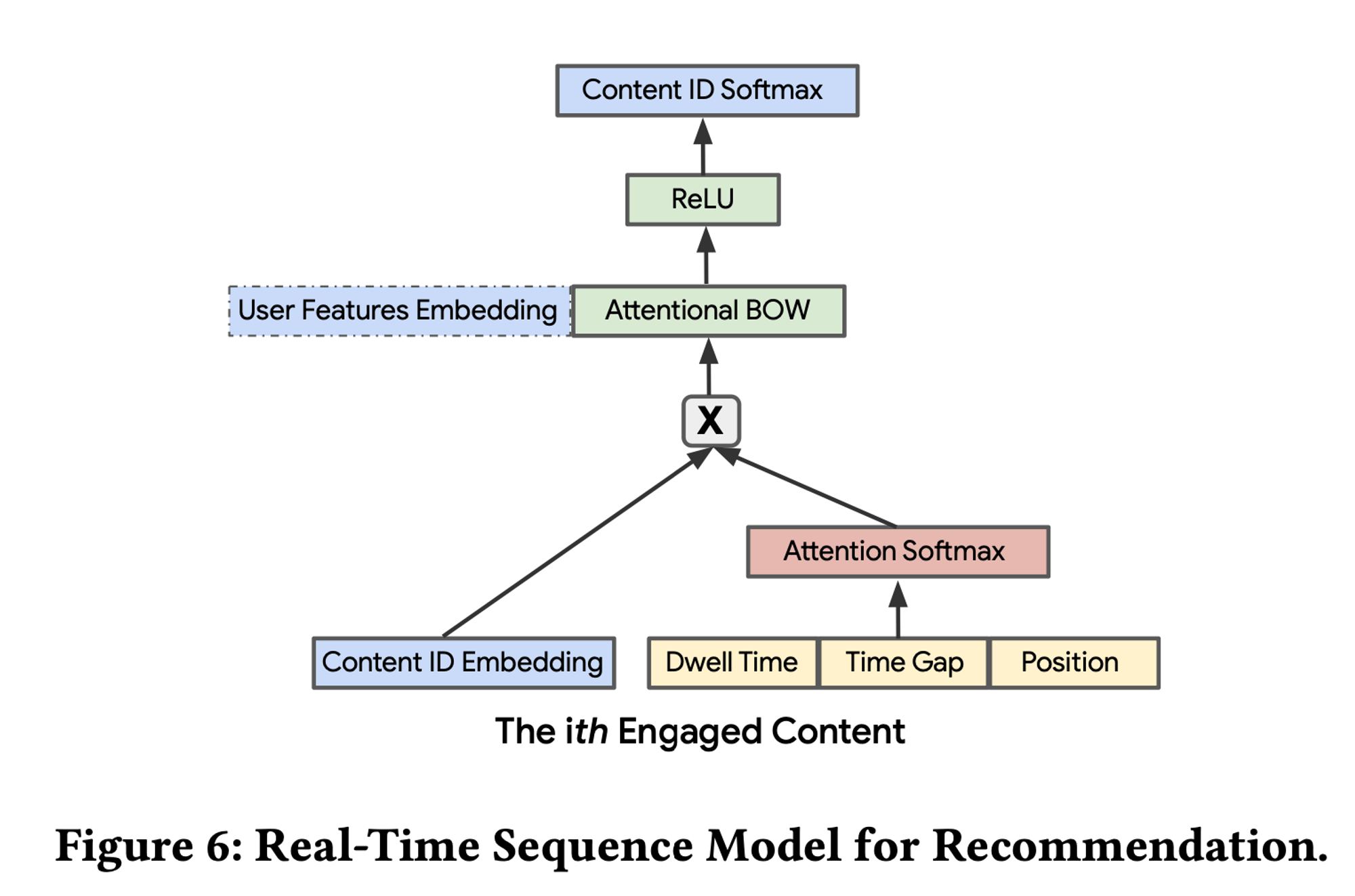
- user/query tower는 사용자 상호작용 시퀀스를 인코딩, item tower는 간단한 ID 임베딩 + 범주적 특성을 사용 → 훈련 시간을 줄이기 위해 모델은 간단한 구조로 설계
- user state는 최근 n번의 상호작용한 content ID 임베딩의 가중합으로 표현되며, 사용자 쿼리 특성과 결합됨
- 구체적으로, 우리는 사용자 상태 표현을 향상시키기 위해 어텐션 메커니즘을 적용
- 주어진 사용자가 가장 최근에 상호작용한 n개의 콘텐츠 [V1, V2, V3, ..., Vn] 대신 단순 평균을 취하는 대신,
- 다음과 같이 최근 n번의 상호작용의 가중합을 사용
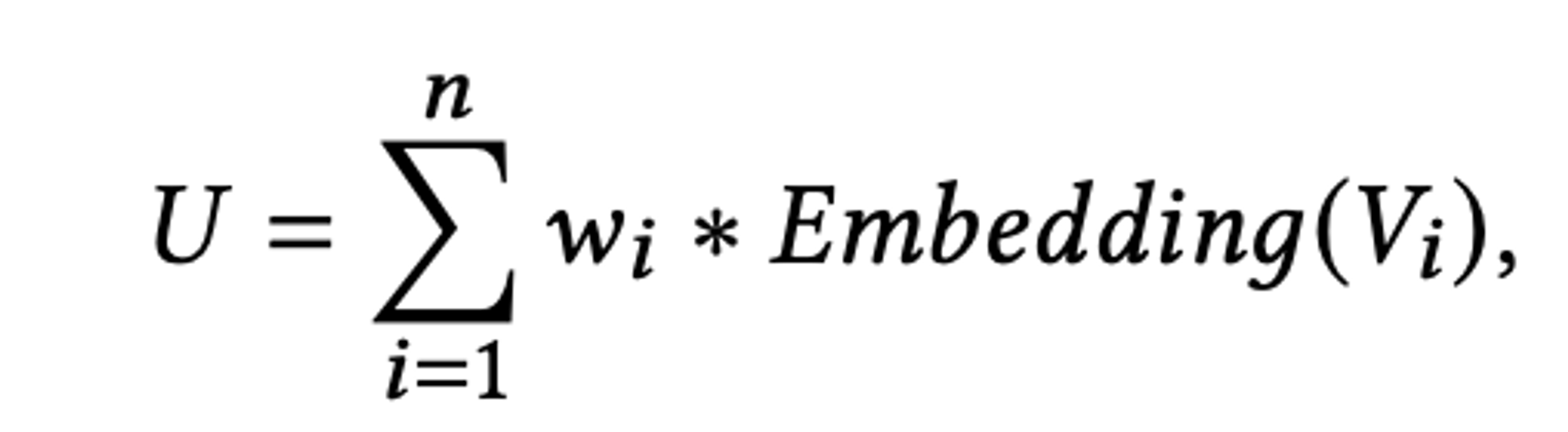
- 여기서 각 콘텐츠 𝑉𝑖에 대한 가중치 𝑤𝑖는 아이템 특성에서 유도 :
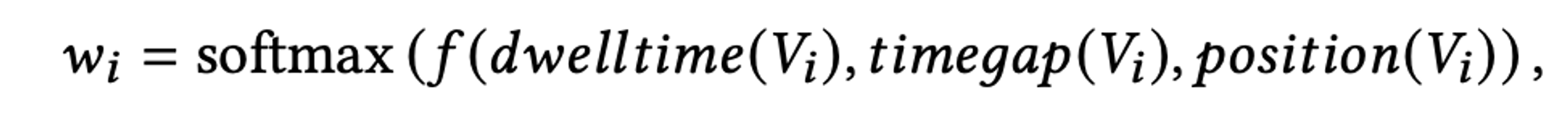
- dwell time : 사용자가 item 𝑉𝑖에 소비한 시간
- timeGap : 상호작용이 발생한 시간과 현재 요청 시간 사이의 간격
- position : 상호작용의 위치 (몇번째 상호작용인지)
- 이러한 가중치는 현재 요청과 더 가까운 내용을 강조하거나, 체류 시간이 긴 내용을 더 강조할 수 있음
Category-centric Reweighting.
Fresh contents라고 하더라도, 상호작용 데이터의 패턴이 다를 수 있음
- 이를 극복하기 위해 item 특성에 따른 categorical feature를 같이 임배딩하지만 : 범주적 특성 역시 long-tail을 가짐
→ item corpus 전체에서의 인기도에 따라 특성을 역가중치하는 IDF 가중치 방식을 도입
- 모델이 구체적인 콘텐츠 특성을 학습하여 일반화 & 동시에 광범위한 특성은 무시할 수 있도록 함.
3.3 Low-funnel VS Middle-funnel Contents
fresh recommendation stack의 콘텐츠는 실제로
(i) 매우 제한적인 상호작용 또는 전혀 상호작용이 없는 low-funnel contents → 콘텐츠 일반화가 필요
(ii) 콘텐츠 일반화를 통해 몇 가지 초기 상호작용 피드백을 수집한 middle-funnel contents로 세분화 가능 → 사용자 피드백을 신속하게 적용할 필요
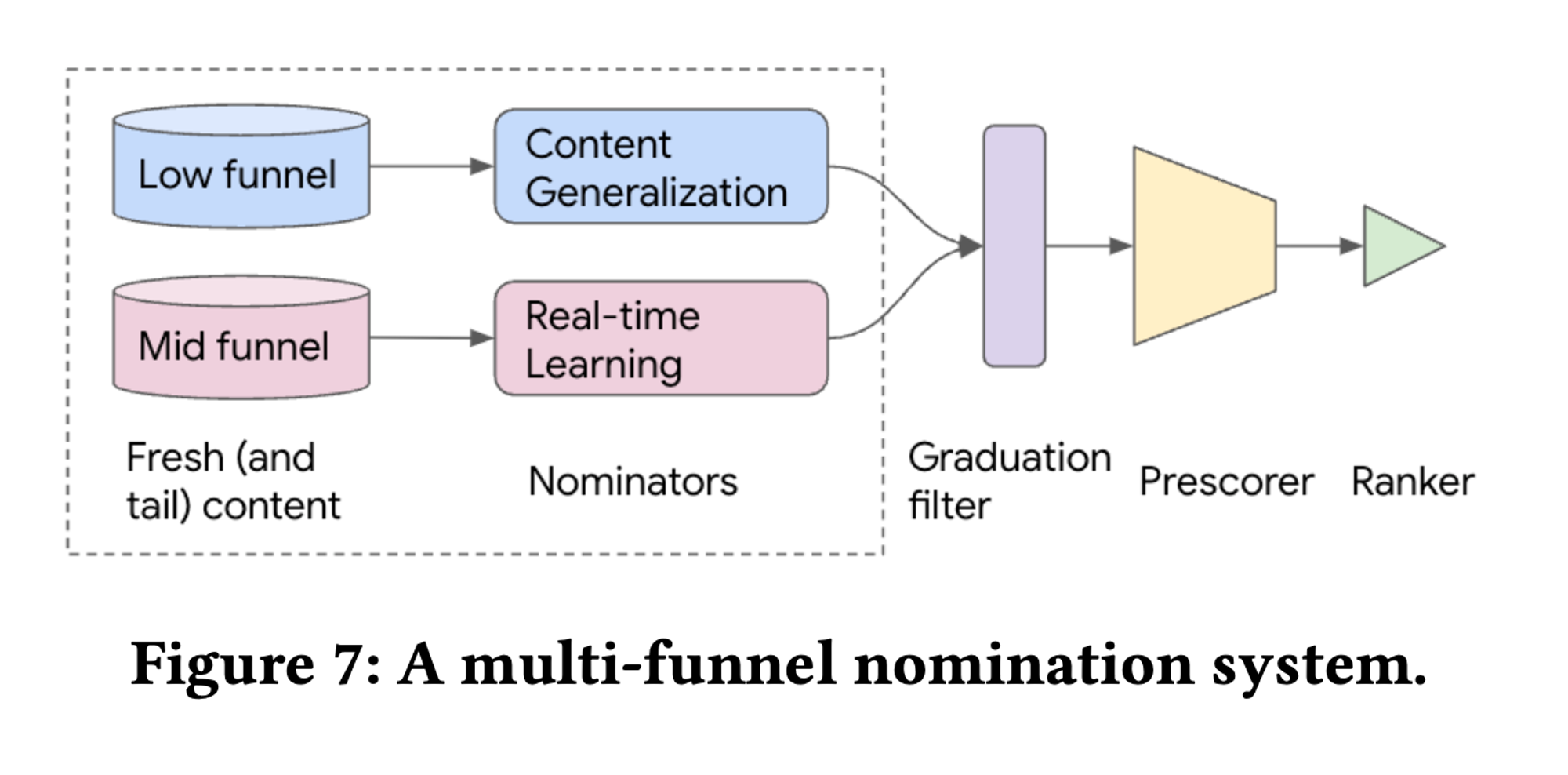
- 콘텐츠가 low-funnel에서 middle-funnel로 전환되는 시점은 콘텐츠가 얻은 초기 상호작용의 양에 따라 결정
- 일정 수준의 상호작용을 확보하면 middle-funnel 퍼널로 전환
Query Division for Multi-funnel Nomination.
하지만 middle-funnel의 콘텐츠를 ranking 과정에서 나타나는 popularity bias를 방지하기 위해
→ query division multiflexing 을 제안 : 각 사용자 쿼리는 두 funnel 중 하나에 (p% / 100-p%의 확률로) 랜덤하게 할당
4 EXPERIMENTS
두 가지 추천 모델(S-real-time, S-two-tower)과 다중 퍼널 추천 시스템의 성능을 비교한 실험 결과를 다룬다.
-
Daily unique impressed contents(DUIC):
- S-real-time 모델은 S-two-tower 모델에 비해 일일 고유 인상 콘텐츠 수(DUIC)가 상당히 낮았음
- 다중 퍼널 설정은 두 모델을 조합함으로써 DUIC 값을 증가시킴
- DUIC@1000 (일일 1000회 인상을 받는 콘텐츠 수)에서 0.65%의 향상을 보임
-
발견 가능한 코퍼스(Discoverable Corpus):
= 콘텐츠 수 X가 Y일 동안 받은 긍정적 상호작용 수 (Discoverable Corpus@X,Ydays)
- 다중 퍼널 설정은 다양한 X값에 걸쳐 일관되게 발견 가능한 코퍼스 매트릭을 향상시킴
-
User metrics:
- 다중 퍼널 시스템은 플랫폼 전체의 사용자 체류 시간에 있어 중립적인 결과를 보임 → 다중 퍼널 추천이 contents metric을 향상시킬 수 있으면서도 추가적인 user cost를 발생시키지 않는다는 것을 의미
- 소규모 콘텐츠 제공자를 위한 사용자 체류 시간은 다중 퍼널 시스템에서 0.45% 증가
- 다중 퍼널 시스템은 플랫폼 전체의 사용자 체류 시간에 있어 중립적인 결과를 보임 → 다중 퍼널 추천이 contents metric을 향상시킬 수 있으면서도 추가적인 user cost를 발생시키지 않는다는 것을 의미
→ 이러한 실험 결과는 다중 퍼널 추천 시스템이 신선한 콘텐츠를 더 효과적으로 다루고, 사용자와 콘텐츠 제공자 모두에게 이점을 제공할 수 있음을 입증
