
여러 스레드를 동시에 돌리는 이유?
여러 스레드를 동시에 돌릴때의 어려움?
--- 전반적인 멀티 스레드에 대하여
들어가기 전에
- 프로그램 : 하드 디스크에 저장되어 있는 실행 코드
- 프로세스 : 프로그램을 구동하여 프로그램 자체와 그로그램의 상태가 메모리 상에서 실행되는 작업의 단위
- 스레드 : 프로세스 내에서 실행되는 흐름의 단위
- 멀티스레드 : 프로그램 환경에 따라 하나의 프로세스에서 둘 이상의 스레드를 동시에 실행하는 경우
- 동시성 : 싱글 코어에서 멀티 스레드를 동작시키기 위한 방식으로 멀티 태스킹을 위해 여러 개의 스레드가 번갈아가면서 실행되는 성질을 말한다.

📕 동시성이 필요한 이유?
-
동시성은 결합(coupling)을 없애는 전략
- 무엇(what)과 언제(when)을 분리하는 전략이다.
- 분리 시 애플리케이션 구조와 효율이 좋아진다.
- 구조적인 관점에서 거대한 루프 하나가 아닌 작은 협력 프로그램 여럿으로 구성되는 것으로 보이고, 그로 인해 문제를 분리하여 시스템을 이해하기 쉬워진다.
-
구조적 개선만을 위한 전략은 아니다.
- 응답 시간과 작업 처리량 개선을 위해 사용하기도 한다.
- 응답 시간과 작업 처리량 개선을 위해 사용하기도 한다.

✔ 스레드가 하나인 경우는 무엇과 언제가 서로 밀접하기 때문에 호출 스택을 살피면 상태를 쉽게 알 수 있다.
ex) 단일 스레드 디버깅 : breakpoint 찍어 시스템 상태 파악
* 호출 스택 : 여러 함수들을 호출하는 스크립트에서 해당 위치를 추적하는 인터프리터를 위한 메커니즘 / 현재 어떤 함수가 동작하고있는 지, 그 함수 내에서 어떤 함수가 동작하는 지, 다음에 어떤 함수가 호출되어야하는 지 등을 제어
📍 미신과 오해
- 동시성은 항상 성능을 높여준다.
- 동시성은 때로 성능을 높여준다.
- 대기 시간이 아주 길어 여러 스레드가 프로세서를 공유할 수 있거나, 여러 프로세서가 동시에 처리할 독립적인 계산이 충분히 많은 경우에만 성능이 높아진다.
- 동시성을 구현해도 설계는 변하지 않는다.
- 일반적으로 무엇과 언제를 분리하면 시스템 구조가 크게 달라진다.
- 웹 혹은 EJB 컨테이너를 사용하면 동시성을 이해할 필요가 없다.
- 어떻게 동작하는지, 동시 수정, 데드락 등과 같은 문제를 피할 수 있는 방법을 알아야 한다.
📍 동시성의 진실
- 동시성은 성능 측면에서 부하를 유발한다.
- 코드도 더 짜야 한다.
- 복잡하다.
- 동시성 버그는 재현하기 어렵다.
- 진짜 결함으로 간주되지 않고 일회성 문제로 여겨 무시하기 쉽다.
- 동시성을 구현하려면 근본적인 설계 전략을 재고해야 한다.
📗 난관
예를 들어 아래의 인스턴스가 두개의 스레드에서 공유된다고 할때 getNextId() 메서드를 동시에 호출하면
public class X {
private int lastIdUsed = 42;
public int getNextId() {
return ++lastIdUsed;
}
}위의 getNextId() 메서드는 8개의 자바 byte-code 로 변환되며 두 스레드에서 실행된다.
그 결과
- 43, 44, lastIdUsed = 44
- 44, 43, lastIdUsed = 44
- 43, 43, lastIdUsed = 43
세가지 경우가 나올 수 있다.
-> 객체 하나를 공유한 후 동일 필드를 수정하던 두 스레드가 서로 간섭하므로 예상치 못한 결과를 내놓는다.
-> 두 스레드가 거쳐가는 경로가 많기 때문이다.
* 경로 수 : 명령 N개, 스레드 T개 => (NT)! / N!^T (return ++lastIdUsed 같은 경우 명령 8개, 스레드 2개에 해당되기 때문에 12,870개가 나온다.)
📙 동시성 방어 원칙
📍 동시성 코드로 인해 발생하는 문제를 방어하는 원칙과 기술
1. 단일 책임 원칙
SRP는 클래스나 모듈을 변경할 이유가 단 하나뿐이어야 한다는 원칙이다. 이를 만족하기 위해서 동시성과 관련된 코드는 다른 코드와 분리해야 한다. 따라서, 아래의 내용을 고려해야 한다.
- 동시성 코드는 독자적인 개발, 변경, 조율 주기가 있다.
- 동시성 관련 코드는 개발, 변경, 조율 시 다른 코드와는 분리된 생명주기를 가진다.
- 동시성 코드에는 독자적인 난관이 있다. 다른 코드에서 겪는 난관과 다르며 훨씬 어렵다.
- 잘못 구현한 동시성 코드는 여러 방식으로 실패한다.
동시성과 관련된 코드는 다른 코드와 분리하라
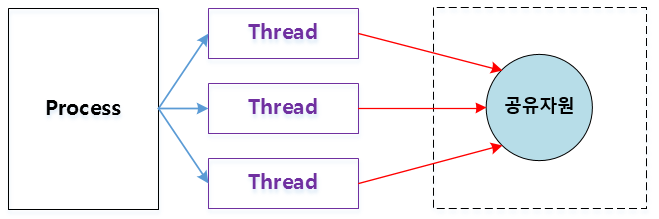
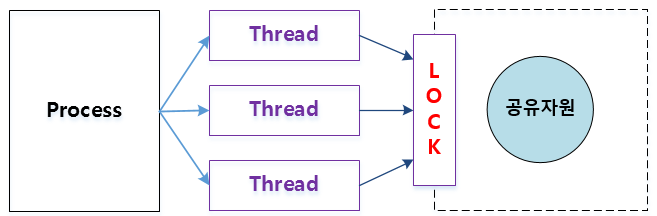
2. 따름 정리 : 자료 범위를 제한하라
두 스레드가 서로 간섭을 하게 되면서 예상치 못한 결과가 발생하는 경우를 볼 수 있었다. (난관 예제 참조)
이를 해결하기 위해 임계 영역을 synchronized 키워드로 보호하는 방법이 권장되지만, 이 임계 영역을 줄이는 기술이 필요하다.
공유 자료를 수정하는 위치가 많을 수록 임계 영역을 빼먹거나, 임계 영역의 보호여부를 확인하는데 오랜 시간이 걸릴 수 있으며 버그를 찾아는데 어려움을 겪을 수 있다.
* 임계 영역 : 둘 이상의 스레드가 동시에 접근해서는 안되는 공유 자원
* 동기화(synchronized) : 임계영역에서 스레드들이 순서를 갖춰 자원을 사용하게 하는 것 / 하나의 스레드가 조작하고 있는 공유자원(변수, 데이터)를 다른 스레드가 조작하지 못하도록 하기 위해 사용하는 방법 -> 하나의 자원을 한번에 하나의 스레드만 사용하도록 하는 기술
* Lock : 공유 자원에 한번에 한 쓰레드만 read, write를 수행 가능하도록 한다.
공유 자료를 캡슐화하고 최대한 줄여라.
3. 따름 정리 : 자료 사본을 사용하라
공유 자원 문제를 해결하는 좋은 방법은 애초에 공유 자원을 활용하지 않는 것이다.
불가능 할 경우에는
- 객체를 복사해 읽기 전용으로 사용
- 각 스레드가 객체를 복사해 사용한 후 한 스레드가 해당 사본에서 결과를 가져옴
-> 공유 자원의 원본 훼손 X
4. 따름 정리 : 스레드는 가능한 독립적으로 구현하라
Servlet은 최초 요청 시 객체가 만들어져 메모리에 로딩되는데,
그 이후 요청부터는 기존의 객체를 재활용하게 된다. ??? 객체 재활용??
스레드 코드를 공유 자원을 사용하지 않는 독자적인 스레드로 만든다면 동기화 문제는 사라지게 된다.
ex) HttpServlet
HttpServlet을 상속받는 클래스는 doGet, doPost와 같은 메서드에서 필요한 파라미터를 받아 처리한다.
대부분의 Servlet들은 데이터베이스 연결과 같은 공유 자원이 필요하지만, 위와 같이 처리하면 각 Servlet이 각자의 세계에 있는 것처럼 작동하게 도와주며, 지역 변수를 사용하는 한 동기화 문제는 발생하지 않게 된다.
독자적인 스레드로, 가능하면 다른 프로세서에서, 돌려도 괜찮도록 자료를 독립적인 단위로 분할하라.
📘 라이브러리를 이해하라
자바 5로 스레드 코드를 구현하려면 아래의 내용을 고려하자.
- 스레드에 안전한 컬렉션을 사용한다.
-
컬렉션 이름 설명 java.util.concurrent 패키지
(동기화가 필요한 상황에서 사용할 수 있는
다양한 유틸리티 클래스들을 제공)다중 스레드 환경에서 사용해도 안전
좋은 성능ConcurrentHashMap HashMap 보다 좋은 성능을 나타내고
스레드 환경에서 안전하다.ReentrantLock 임계영역의 시작 지점과 종료 지점을 직접 명시 Semaphore 특정 자원이나 특정 연산을 동시에 사용하거나
호출할 수 있는 스레드의 수를 제한하고자 할 때 사용CountDownLatch 지정한 수만큼 이벤트가 발생하고 나서야 대기 중인 스레드를 모두 해제 시키는 락, 모든 스레드에게 공평한 출발선을 제공
-
- 서로 무관한 작업(공유 자원)을 수행할 때는 executer 프레임워크를 사용한다.
- Executor : java.util.concurrent 패키지에서 제공하는 기능 중 하나로,
스레드를 직접적으로 다루는 가장 최상위 API이다.
작업들을 비동기적으로 실행시킬 수 있다.
- Executor : java.util.concurrent 패키지에서 제공하는 기능 중 하나로,
- 가능하면 스레드가 차단(blocking : system stop)되지 않는 방법을 사용한다.
- 일부 클래스 라이브러리는 스레드에 안전하지 못하기 때문에 주의한다.
📒 실행 모델을 이해하라
📍 기본 용어
| 이름 | 설명 |
|---|---|
| 한정된 자원(Bound Resource) | 다중 스레드 환경에서 사용하는 자원으로 크기나 숫자가 제한적 ex) 데이터베이스 연결, 길이가 일정한 읽기/쓰기 버퍼 |
| 상호 배제(Mutual Exclusion) | 한 번에 한 스레드만 공유 자료나 자원을 사용 가능 |
| 기아(Starvation) | 한 스레드나 여러 스레드가 굉장히 오랫동안 혹은 영원히 자원을 기다리는 상태 |
| 데드락(Deadlock) | 여러 스레드가 서로가 끝나기를 기다린다 모든 스레드가 각기 필요한 자원을 다른 스레드가 점유하는 바람에 어느 쪽도 더 이상 진행하지 못한다. |
| 라이브락(Livelock) | 락을 거는 단계에서 각 스레드가 서로를 방해 스레드는 계속해서 진행하려 하지만, 공명(resonance)으로 인해 오랫동안 진행하지 못하는 상태 |
기본 용어에 대한 설명을 보았으니, 실제 다중 스레드 프로그래밍에서 사용하는 실행 모델을 살펴보자
📍 다중 스레드 프로그래밍에서 사용하는 실행 모델
1. 생산자-소비자
Buffer나 대기열(Queue)는 생산자, 소비자 스레드가 함께 사용하는 한정된 자원이다.
- 생산자 스레드
- 정보를 생산해 Buffer나 Queue에 넣는다.
- 빈 공간이 있어야 정보를 넣을 수 있다. -> 빈공간이 생길때까지 대기
- 정보를 생산해 Buffer나 Queue에 넣는다.
- 소비자 스레드
- Buffer나 Queue에서 정보를 가져와 사용한다.
- 정보가 존재해야 사용 가능하다. -> 공간이 채워질때까지 대기
- Buffer나 Queue에서 정보를 가져와 사용한다.
그렇기 때문에 생산자 Buffer나 Queue에 남는 공간이 생길때 까지, 소비자 Buffer나 Queue는 정보가 하나라도 생길때 까지 대기해야 한다.
따라서 자원을 올바르게 사용하기 위해서는 생산자, 소비자 스레드 간의 신호를 적절히 주고받아야 한다.
잘못하면 생산자, 소비자 스레드가 둘 다 진행 가능한 상태임에도 서로에게서 시그널을 기다릴 위험이 있다.
2. 읽기-쓰기
- 읽기 스레드 : 주된 정보원으로 공유 자원을 사용
- 읽는 스레드의 작업 동안 쓰는 스레드의 작업이 기다리면 정보 업데이트가 되지 않는 문제가 있다
- 쓰기 스레드 : 공유 자원을 갱신
- 쓰는 스레드의 작업 동안 읽는 스레드의 작업이 기다리면 이것도 기아 현상의 위험이 있음.
=> 처리율의 문제 발생 : 대개 쓰기 스레드가 버퍼를 오래 점유하여 읽기 스레드가 버퍼를 기다리게 된다.
따라서 양쪽 균형을 잡으면서 동시 갱신 문제를 피하는 해법이 필요하다.
3. 식사하는 철학자들
둥근 원탁의 가운데에 스파게티, 철학자의 왼쪽에 포크가 놓여 있다.
철학자는 배가 고파지면 그들은 자신의 양쪽에 놓여 있는 포크 2개를 잡고 스파게티를 먹는다.
철학자는 포크 2개가 있어야만 스파게티를 먹을 수 있다. 만약 포크가 없다면 옆 사람이 포크를 사용할때까지 기다려야 한다.
- 포크 : 공유 자원
- 철학자 : 스레드
- 자원을 놓고 경쟁하는 프로세스
자원은 한정적이고 프로세스는 자원을 얻으려고 경쟁하기 때문에 주의깊게 설계할 필요가 있다.
그렇지 않을 경우 데드락, 라이브락, 처리율 저하, 효율성 저하 등과 같은 문제를 겪는다.
![]()
📕 동기화하는 메서드 사이에 존재하는 의존성을 이해하라
동기화 하는 메서드 사이에 의존성이 존재하면 동시성 코드에 찾아내기 어려운 버그가 생긴다. 그러므로 의존성을 낮추기 위해 공유 객체 하나에는 메서드를 하나만 사용하는 것을 권장한다.
하지만 객체 하나에 여러 메서드가 필요한 경우가 생긴다. 그럴 경우는 아래와 같은 방법을 고려한다.
- 클라이언트에서 잠금
- 클라이언트에서 첫 번째 메서드를 호출하기 전에 서버를 잠근다.
- 마지막 메서드를 호출할 때까지 잠금을 유지한다.
- 모든 클라이언트 코드에서 잠금이 필요하기 때문에 유지보수, 디버깅에 필요한 비용을 높인다.
- 서버에서 잠금
- 서버에 '서버를 잠그고 모든 메서드를 호출한 후 잠금을 해제하는 메서드'를 구현한다.
- 클라이언트는 이 메서드를 호출한다.
- 임계 영역에 접근하는 코드를 최소화한다.
- 연결 서버
- 잠금을 수행하는 중간 단계를 생성한다.
- '서버에서 잠금'방식과 유사하지만 원래 서버는 변경하지 않는다.
* 잠금(Locking) : 하나의 트랜잭션이 실행하는 동안 특정 데이터 항목에 대해서 다른 트랜잭션이 동시에 접근하지 못하도록 상호배제(Mutual Exclusive) 기능을 제공하는 기법
📗 동기화하는 부분을 작게 만들어라
자바에서 synchronized 키워드를 사용하면 락을 설정한다.
같은 락으로 감싼 모든 코드 영역은 한 번에 한 스레드만 실행이 가능하다.
하지만 락은 스레드를 지연시키고 부하를 가중시킨다는 단점이 있다.
💻 synchronized의 잘못된 사용 예시
public class BasicSynchronization {
private String mMessage;
public static void main(String[] agrs) {
BasicSynchronization temp = new BasicSynchronization();
System.out.println("Test start!");
new Thread(() -> {
for (int i = 0; i < 1000; i++) {
temp.callMe("Thread1");
}
}).start();
new Thread(() -> {
for (int i = 0; i < 1000; i++) {
temp.callMe("Thread2");
}
}).start();
System.out.println("Test end!");
}
public synchronized void callMe(String whoCallMe) {
mMessage = whoCallMe;
try {
long sleep = (long) (Math.random() * 100);
Thread.sleep(sleep);
} catch (InterruptedException e) {
e.printStackTrace();
} if (!mMessage.equals(whoCallMe)) {
System.out.println(whoCallMe + " | " + mMessage);
}
}
}
그리고 임계 영역은 반드시 보호해야 하기 때문에 임계 영역의 수를 최소화 해야한다.
but, 하나의 임계영역으로 통일할 경우 이를 사용하고자하는 스레드의 수도 많아지기 때문에 성능 저하를 가져온다.
📙 올바른 종료 코드는 구현하기 어렵다
깔끔하게 종료하는 코드는 데드락 문제로 구현하기 어려울때가 있다.
예시
부모 스레드가 자식 스레드를 여러 개 만든 후 모두가 끝나기를 기다렸다 자원을 해제하고 종료하는 시스템이 있었다고 가정하자. 만약 자식 스레드 중 하나가 데드락에 걸린다면 부모 스레드는 영원히 기다리게 된다.
종료 코드를 개발 초기부터 고민하고 제대로 동작할 수 있도록 구현하라.
* 데드락 : 모든 스레드가 각기 필요한 자원을 다른 스레드가 점유하는 바람에 어느 쪽도 더 이상 진행하지 못하는 상황
📘 스레드 코드 테스트하기
충분한 테스트는 위험을 낮춘다. 스레드가 하나인 경우는 큰 문제가 되지 않지만, 여러개인 경우 상황이 복잡해지기 때문에 충분한 테스트가 필요하다.
이를 위해 문제를 노출하는 테스트 케이스를 작성하고, 프로그램 설정과 시스템 설정, 부하를 바꿔가며 여러번 테스트하고 원인을 찾아라.
📍 테스트 지침
1. 말이 안 되는 실패는 잠정적인 스레드 문제로 취급하라
다중 스레드 코드는 일반적으로 발생할 리 없어 보이는 문제를 발생시켜 이를 일회성 문제라고 여기는데, 그렇게 되면 잘못된 코드 위에 코드가 계속 쌓여 문제가 생긴다. 따라서 시스템 실패를 일회성이라고 치부하면 안된다.
2. 다중 스레드를 고려하지 않은 순차 코드부터 제대로 돌게 만들자
스레드 환경 밖에서 코드가 제대로 도는지 확인한다.
이는 POJO를 만들어 테스트 하는 것을 의미한다. POJO는 스레드를 모르기 때문에 스레드 밖에서도 테스트가 가능하다.
- 스레드 환경 안과 밖의 버그를 동시에 디버깅 하지말고, 스레드 환경 밖에서 코드를 올바르게 만들어라.
3. 다중 스레드를 쓰는 코드 부분을 다양한 환경에 쉽게 끼워넣을 수 있게 스레드 코드를 구현하라
다중 스레드를 다양한 설정에서 실행할 목적으로 다른 환경에 쉽게 끼워 넣을 수 있도록 구현하라.
- 스레드 수 바꿔보기
- 스레드 실제 환경이나 테스트 환경에서 돌려보기
- 다양한 속도로 돌려보기 -> 여기서 속도란?
- 반복 테스트가 가능하도록 테스트 케이스 작성하기
4. 다중 스레드를 쓰는 코드 부분을 상황에 맞게 조율할 수 있게 작성하라
다양한 설정을 통해 프로그램의 성능 측정 방법을 강구하고, 프로그램의 효율에 따라 스레드의 개수를 조율하기 쉽게 구현한다.
5. 프로세서 수 보다 많은 스레드를 돌려보라
스와핑 시에도 문제는 발생한다. 스와핑이 잦을수록 임계영역을 빼먹은 코드나, 데드락을 일으키는 코드를 찾기 쉬워지기 때문에 프로세서 수보다 많은 스레드를 돌리면 오류를 찾기 쉽다.
* 스와핑 : 시스템이 작업을 전환하는 것
6. 다른 플랫폼에서 돌려보라
운영체제마다 스레드를 처리하는 정책이 다르기 때문에 이에 맞는 테스트를 수행해야 한다.
7. 코드에 보조 코드를 넣어 돌려라. 강제로 실패를 일으키게 해보라
스레드 실행시 실패하는 경우는 수천개의 경로 중 소수로, 실패하는 경로로 실행될 확률이 저조하다. 따라서 보조 코드를 추가하여 코드 실행 순서를 바꿔 다양한 순서로 실행해본다.
보조코드 추가 방법
1. 직접 구현하기
wait(), sleep(), yield(), priority() 함수를 추가한다.
-
yield()
- 메소드를 호출한 스레드는 실행 대기 상태로 돌아가고 동일한 우선순위 또는 높은 우선순위를 가지는 다른 스레드가 실행 기회를 가질 수 있도록 해 준다.
-
sleep()
- 실행 중인 스레드를 주어진 일정 시간동안 일시 정지 시킨다.
- 메소드를 호출하면 스레드는 주어진 시간 동안 일시 정지상태가 되고 다시 실행 대기 상태로 돌아간다.
- 현재 스레드에서 실행된다.
-
wait()
- 실행 중인 스레드를 주어진 일정 시간동안 일시 정지 시킨다.
- 객체에서 실행된다.
-
Thread에 우선순위를 설정할 때는 setPriority()
-
설정된 값을 확인할 때는 getPriority()
추가 이후 코드가 실패한다면 그것은 추가 이전에도 잘못된 코드임을 나타낸다.
문제점
- 어디에, 어떻게 보조코드를 삽입할지
- 배포 환경에 보조 코드를 삽입하면 성능 저하를 가져온다
- 무작위적이다. 보조코드를 삽입해도 실패하지 않을 가능성이 더 높다.
위와 같은 문제점이 생기기 때문에 테스트 환경에서도 보조 코드를 실행할 방법이 필요하다.
따라서 스레드를 모르는 POJO를 jig를 통해 보조 코드를 어디에 추가할지에 대한 도움을 받는다.
2. 자동화
public class ThreadJigglePoint {
public static void jiggle() { }
}
public synchronized String nextUrlOrNull() {
if(hasNext()) {
ThreadJiglePoint.jiggle(); // ThreadJigglePoint
String url = urlGenerator.next();
ThreadJiglePoint.jiggle(); // ThreadJigglePoint
updateHasNext();
ThreadJigglePoint // ThreadJigglePoint
return url;
}
return null;
}다양한 위치에 ThreadJigglePoint.jiggle() 을 호출하면 해당 메서드는 무작위로 sleep 이나 yield를 호출한다 (아무것도 하지 않아도 된다.)
이와 비슷한 작업을 수행해 주는 IBM에서 개발한 ConTest라는 툴도 있지만, 더 복잡하다.
이처럼 코드를 흔드는 이유는 스레드를 매번 다른 순서로 실행하기 위해서이다. 여러 경로를 확인하여 스레드의 오류를 잡을 수 있는 가능성이 높아진다.
📒 결론
-
SRP를 준수한다.
-
POJO를 사용해 스레드를 아는 코드와 모르는 코드를 분리한다.
-
스레드를 테스트할때는 전적으로 스레드만 테스트 한다.
스레드는 최대한 집약되고 작아야 한다. -
동시성 오류를 일으키는 원인을 이해해야한다.
-
사용하는 라이브러리와 알고리즘을 이해한다.
-
공유하는 객체의 수를 최대한 줄인다.
-
보조 코드를 추가하면 오류를 확
🧩 더 공부할 부분
- 스레드, 동시성, 병렬성 : https://deveric.tistory.com/104 (예시), https://velog.io/@goban/%EC%8A%A4%EB%A0%88%EB%93%9C%EC%99%80-%EB%8F%99%EC%8B%9C%EC%84%B1,https://velog.io/@chan33344/%EB%8F%99%EC%8B%9C%EC%84%B1-%ED%94%84%EB%A1%9C%EA%B7%B8%EB%9E%98%EB%B0%8D-%EB%B9%84%EB%8F%99%EA%B8%B0-%ED%94%84%EB%A1%9C%EA%B7%B8%EB%9E%98%EB%B0%8D#%ED%94%84%EB%A1%9C%EC%84%B8%EC%84%9C%EB%9E%80, https://chanto11.tistory.com/63
- 서블릿(Servlet) : https://victorydntmd.tistory.com/154
- Java의 concurrent 패키지 : https://zion830.tistory.com/57
- Synchronized vs ReentrantLock : https://theuphill.tistory.com/16
- Synchronized 예시 : https://tourspace.tistory.com/54
- 스와핑 : https://jhnyang.tistory.com/103
- 잠금 예시 코드 : https://github.com/Yooii-Studios/Clean-Code/blob/master/chapter-13.md
📚 Reference
- Clean Code : 애자일 소프트웨어 장인 정신
- 호출 스택 : https://developer.mozilla.org/ko/docs/Glossary/Call_stack
- 동기화 : https://codedragon.tistory.com/3529
- 임계 영역 : https://ko.wikipedia.org/wiki/%EC%9E%84%EA%B3%84_%EA%B5%AC%EC%97%AD
- 잠금 : https://medium.com/pocs/%EB%8F%99%EC%8B%9C%EC%84%B1-%EC%A0%9C%EC%96%B4-%EA%B8%B0%EB%B2%95-%EC%9E%A0%EA%B8%88-locking-%EA%B8%B0%EB%B2%95-319bd0e6a68a
- Executors : https://emong.tistory.com/221
- sleep : https://codedragon.tistory.com/6351?category=44090
- yield : https://codedragon.tistory.com/6074
- sleep vs wait : https://ko.gadget-info.com/difference-between-sleep
