서론
포탈 프로젝트를 진행하던 중 프론트분이 모바일 페이지의 인피니티 스크롤을 구현한다 하셨다.
1페이지를 조회하고 있는 중 새로운 글이 등록되면 2페이지의 첫 글은 1페이지의 마지막 글이 된다.
인피니티 스크롤 방식에서는 똑같은 데이터를 2번 보는 것과 같은 문제가 생겼다.
이를 해결하고자 찾아보다 Offset 방식과 Cursor 방식을 알게되었다.
Offset 페이징

주로 위 그림과 같이 페이지를 눌러서 이동하는 방식에 사용된다.
Page<Post> findAllByOrderByIdDesc(Pageable pageable);public ListResponseDto getAllPost(String category, String sort, int page){
Pageable pageable = PageRequest.of(page>0?--page:page,8);
Page<Post> dto = postRepository.findAllByOrderByIdDesc(pageable);
}Hibernate:
/* <criteria> */ select
p1_0.id,
p1_0.anonymous,
p1_0.category,
p1_0.content,
p1_0.create_date,
p1_0.good,
p1_0.image_count,
p1_0.member_id,
p1_0.modified_date,
p1_0.number,
p1_0.reply_count,
p1_0.scrap,
p1_0.title,
p1_0.view
from
post p1_0
order by
p1_0.id desc
limit
?, ?위에서 ?, ? 부분에는 limit과 offset이 들어간다.
페이징 요청으로 한 페이지 당 10개의 데이터, 100번째 페이지를 조회할 경우
limit 10 offset 1000 쿼리가 날아가면서 1000번째 데이터 다음의 10개의 데이터를 보여준다.
즉, limit n offset n * k
k는 보여줄 페이지의 번호 n은 한 페이지의 데이터의 갯수이다.
Offset 방식의 문제점
1. 데이터 추가, 삭제 시 페이징 호출 시 데이터 중복 문제
만약 1페이지를 조회 중 새로운 글이 추가된다면, 2페이지를 호출 시 2페이지의 첫 번 째 글이조회했던 1페이지의 마지막 글이 된다.
극단적으로 보면 한 페이지에 10개의 글이 있고 1페이지를 보는 도중 10개의 글이 생성된다면, 2페이지를 넘어가도 1페이지와 똑같은 데이터를 받게 된다.
또한, 1페이지 조회 중 1페이지의 데이터가 n가지 삭제된다면, 2페이지에서는 삭제된 n개의 데이터 만큼 1페이지로 이동 함으로 정보 확인에 대한 누락 문제가 발생한다.
2. 성능의 이슈
limit 10 offset 1000000 이라면 1000000번째 데이터 다음 10개의 데이터를 보여준다.
offset이라는 기능이 1000000번째까지 데이터를 스킵하면서 넘어가기 때문에 1000000번의 데이터를 스캔하기에 O(n) + O(limit)의 시간 복잡도를 가진다.
즉, 데이터의 수가 많고 후반부의 페이지를 조회하려 할 수록 성능이 나빠진다.
Cursor 페이징
//Repository
List<Post> findAllByIdLessThanOrderByIdDesc(Long id, Pageable pageable);
List<Post> findByCategoryAndIdLessThanOrderByIdDesc(String category,Long id,Pageable pageable);@Transactional(readOnly = true)
public List<PostListResponseDto> getPostForInf(Long lastPostId,String category){
Pageable pageable = PageRequest.of(0,8);
if(lastPostId==null&&category==null){
return postRepository.findAllByOrderByIdDesc(pageable).stream().map(this::getPostListResponseDto).collect(Collectors.toList());
}
else if(lastPostId == null){
return postRepository.findAllByCategoryOrderByIdDesc(category,pageable).stream().map(this::getPostListResponseDto).collect(Collectors.toList());
}
else if(category!=null){
return postRepository.findByCategoryAndIdLessThanOrderByIdDesc(category,lastPostId,pageable).stream().map(this::getPostListResponseDto).collect(Collectors.toList());
}
else {
return postRepository.findAllByIdLessThanOrderByIdDesc(lastPostId, pageable).stream().map(this::getPostListResponseDto).collect(Collectors.toList());
}
}Hibernate:
/* <criteria> */ select
p1_0.id,
p1_0.anonymous,
p1_0.category,
p1_0.content,
p1_0.create_date,
p1_0.good,
p1_0.image_count,
p1_0.member_id,
p1_0.modified_date,
p1_0.number,
p1_0.reply_count,
p1_0.scrap,
p1_0.title,
p1_0.view
from
post p1_0
where
p1_0.category=?
and p1_0.id<?
order by
p1_0.id desc
limit
?, ?
현재 사용자가 조회하고 있는 데이터들 중 마지막 데이터의 cursor 값을 인자로 받으며, cursor의 값보다 높거나 낮은 값 부터 요청한 데이터 갯수 만큼 가져온다.
성능의 장점
인자로 페이지 대신 조회했던 데이터의 마지막 데이터의 cursor 값을 받아 그 값의 이하의 값 만을 불러와 가져오기 때문에 O(1) + O(limit)이라는 시간복잡도를 가진다.
검색 조건에 대한 고려
기본 적으로 정렬 기준이 cursor의 값은 unique한 값을 가지고, 순차적이어야 한다.
예를 들어 pk 값인 id를 cursor로 가진다면 구현은 간단하겠지만, 중복이 가능한 필드를 사용할 경우 원하는 결과가 돌아오지 않을 수 있다.
cursor의 조건이 or 을 사용한 여러 개인 경우 데이터베이스 풀 스캔하는 경우도 생길 수 있어 offset보다 성능이 더 낮아질 수 있다.
여러 Cusor 조건에 대한 개선점
cursor라는 새로운 필드를 추가하여 기존에 필드들의 합을 통해 cursor을 만들어 최적화가 가능하다.
예를 들면 id값과 생성시점이 조건이었다면 id+createdAt를 합친 cursor 필드를 만들어 사용 기준점으로 가능하다.
성능 비교
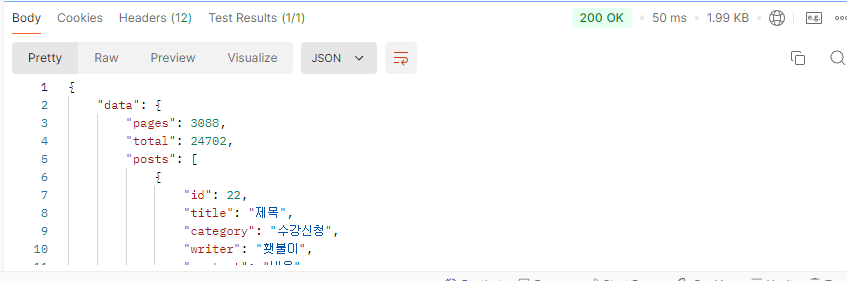
Offset 방식
Cursor 방식
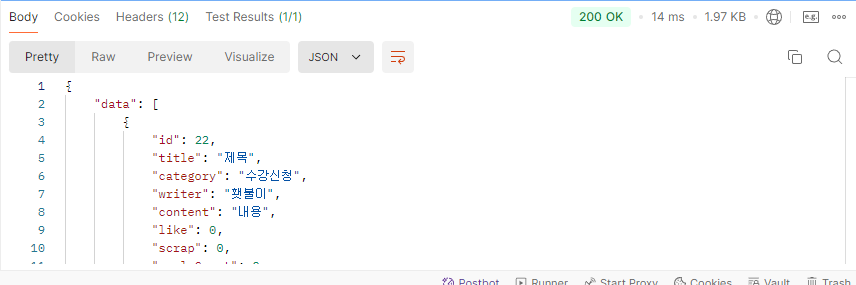
대략 25000개의 데이터에서 3배 이상의 속도 차이를 보인다.
결론
데이터의 수가 적고 페이지를 선택해 들어가는 방식이면 offset을 사용하고,
인피니티 스크롤이나 대량의 데이터에서는 cursor 방식을 사용하면 좋을 것 같다.
하지만, 페이스북에서는 cursor 방식을 강력하게 추천하고, 성능적으로도 offset에 비해 우세하니 앞으로의 페이징 구현은 특별한 경우가 아니라면 cursor 방식으로 구현하는게 좋아보인다.
