서론
학교 학생들을 위한 팁 게시판 형태를 가진 포탈 서비스를 개발하는 중 검색을 구현했다.
검색에는 제목이나 본문에 해당 검색어가 있으면 선택하는 방식으로 like '%keyword%' 형식이다.
하지만, 데이터가 많아질수록 저 방식을 사용하면 모든 게시글을 처음부터 끝까지 풀 스캔을 하기에 엄청난 성능 저하가 일어난다.
그래서 개선을 위해 검색하던중 MySQL FULL TEXT SEARCH와 엘라스틱 서치 도입이라는 2가지 방법이 있었다.
하지만 엘라스틱 서치는 기존에 만든 구성을 완전히 엎어버려야 하기에 전자의 방식을 선택했다.
MySQL FULL TEXT SEARCH
먼저 MySQL FULL TEXT SEARCH는 단어를 잘라서 인덱스를 생성한다.
기존에는 공백을 기준으로 잘라 저장하는 방식을 사용했다고 한다.
ex) "아빠가 가방에 들어가신다." 라고하면 (아빠가/가방에/들어가신다)로 저장된다.
하지만 ngram 파서를 사용한다면 글자 수에 따라 파싱이 가능해진다.
파싱하는 글자 수는 MySQL 설정을 통해 변경 가능하며 기본값은 2이다.
ex) "아빠가 가방에 들어가신다." 라고하면 (아빠/빠가/가방/방에/들어/어가/가신/신다)의 형태로 저장된다.
후자의 방식을 사용하면 인덱스가 더 많은 용량을 차지하지만 그만큼 얻는 이점이 많기에 이 방식을 선택했다.
이제 검색기능에는 natural language mode 와 boolean mode가 있는데 이것이 무엇인지 알아보자
먼저 이 기능을 사용하기 위해선 테이블의 구조를 바꿔주거나 인덱스를 추가해줘야한다.
필자는 기존 테이블을 변경하려 했지만, NULL관련 오류가 발생해 인덱스를 추가해줬다.
CREATE FULLTEXT INDEX portal_index ON post (title,content) WITH PARSER ngram;
natural language mode
select * from post where match(title,content) against('어느 그림' in natural language mode);먼저 ngram 방식이 아닌 기존 방식을 사용한다면 (어느/그림) 둘 중 하나를 인덱스로 가진 게시글이 찾아진다. 하지만 (어느멋진그림) 처럼 포함형태의 글은 검색되지 않는다. 반드시 어느 또는 그림의 인덱스가 있어야한다.
하지만 ngram 방식을 이용한다면 (어느/느멋/멋진/진그/그림)으로 인덱스가 저장되기에, 이 게시글은 찾아진다.
또한 natural language mode로 검색할 시 게시글이 얼마나 검색어에 적합한지를 계산해주는 기능이 있다.
그래서 select문으로 찾아지는 게시글은 정확도순으로 정렬되어 오며, 같은 정확도에 경우에는 pk 값의 오름차순으로 온다.
정확도의 수치를 확인해보고싶다면 다음과 같이 입력하면된다.
SELECT *, MATCH(title, content) AGAINST('검색어' IN NATURAL LANGUAGE MODE) AS relevance_score
FROM post
WHERE MATCH(title, content) AGAINST('검색어' IN NATURAL LANGUAGE MODE)boolean mode
select * from post where match(title,content) against('어느 그림' in boolean mode);이 방식은 정확도가 높은 검색을 지원한다. ngram의 방식에서 살펴보면 '어느' 또는 '그림'이 있는 게시글을 찾아내고, 검색 조건에 따라 다른 것도 반환이 가능하다.
예를 들면 ('+어느 -그림'in boolean mode) 으로 검색하게 된다면 '어느'는 포함하고 '그림'은 포함하지 않는 게시글을 검색하는 것이다.
이 쿼리의 반환은 pk값의 오름차순이 기본이다.
이 모드의 성능을 natural langauge mode 와 비교해보자면 natural langauge mode에선 정확도를 비교하는 추가작업이 있기에 natural langauge mode에 비해 더 좋은 성능을 보인다.
성능 비교
먼저, 더미데이터셋 10만개가 있는 상태에서 속도를 비교해보겠다.
select * from post where content like '%개발%' or title like '%개발%';
select * from post where match(title,content) against('개발' in natural language mode);
select * from post where match(title,content) against('개발' in boolean mode);like 쿼리

natural language mode

boolean mode

더미데이터가 2만5천개였을 땐 like 쿼리가 가장 빠른 속도를 보여줬지만, 데이터가 늘어날수록 성능이 압도적으로 차이가 난다.
실전 적용
실전 프로젝트에서 적용하기 위해 페이징 기능을 함께 추가했다.
@Query(value = "SELECT * FROM post WHERE MATCH(title, content) AGAINST(?1 IN NATURAL LANGUAGE MODE)", nativeQuery = true)
Page<Post> searchByKeyword(String keyword,Pageable pageable);
@Query(value = "SELECT * FROM post WHERE MATCH(title, content) AGAINST(?1 IN BOOLEAN MODE) ORDER BY good DESC", nativeQuery = true)
Page<Post> searchByKeywordOrderByLikes(String keyword, Pageable pageable);
@Query(value = "SELECT * FROM post WHERE MATCH(title, content) AGAINST(?1 IN BOOLEAN MODE) ORDER BY scrap DESC", nativeQuery = true)
Page<Post> searchByKeywordOrderByScraps(String keyword, Pageable pageable);3가지의 네이티브 쿼리를 만들었으며,
첫 메소드는 natural language mode로 정확도에 대한 정렬을,
두 번째 메소드는 boolean모드로 빠르게 가져온 후 좋아요 순에 대한 정렬을,
세 번째 메소드는 boolean모드로 빠르게 가져온 후 스크랩 순에 대한 정렬을 구현했다.
실전 속도 비교
먼저 offset 페이징 방식으로 구현했기에 포스트맨을 통해 첫 페이지와 마지막 페이지에 대한 속도 비교를 해보겠다.
'개발' 검색 1페이지(natural langauge mode) vs '개발' 검색 1페이지 (like '%keyword%')
대략 80배의 속도 차이가 난다.
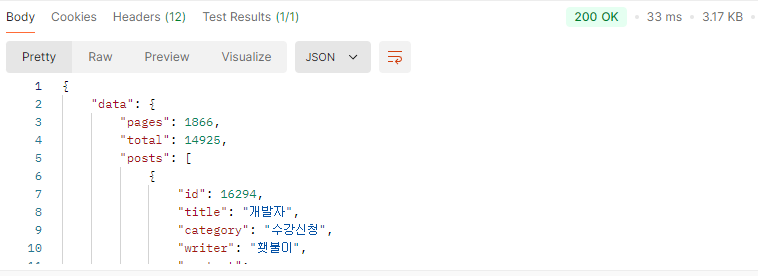
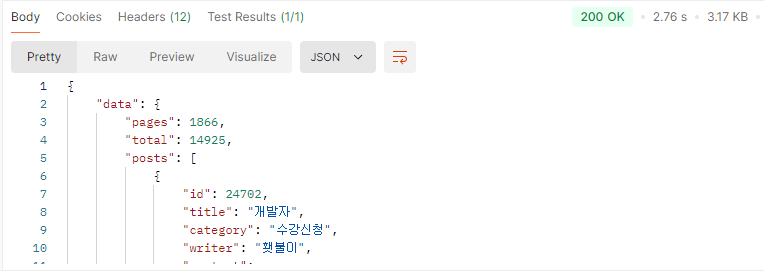
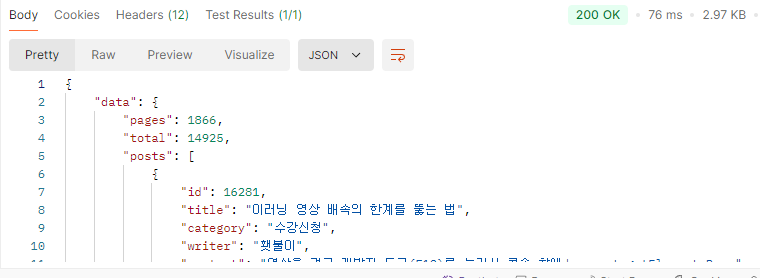
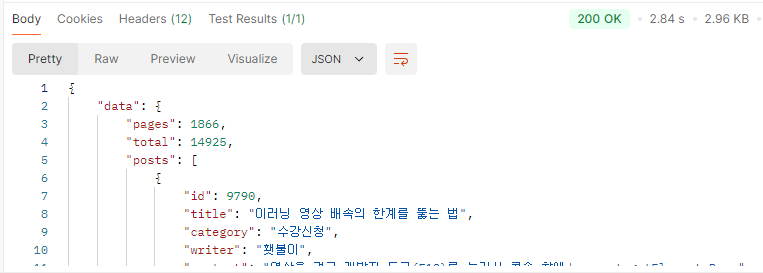
'개발' 검색 마지막 페이지(natural langauge mode) vs '개발' 검색 마지막 페이지 (like '%keyword%')
대략 80배의 속도 차이가 난다.
'개발' 검색 좋아요 정렬 1페이지 (boolean mode / orderBy) vs '개발' 검색 좋아요 정렬 1페이지 (like '%keyword%')
대략 30배의 속도 차이가 난다.
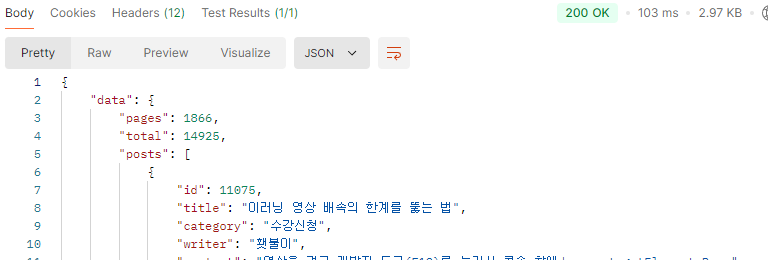
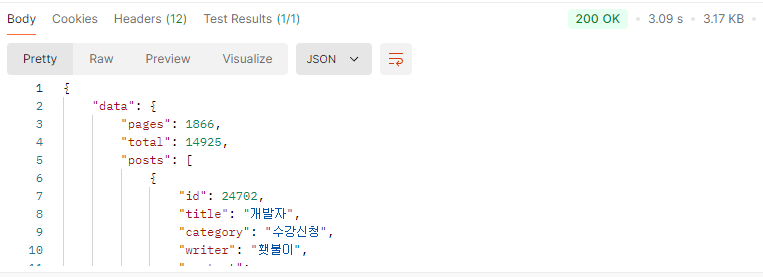
'개발' 검색 좋아요 정렬 마지막 페이지 (boolean mode / orderBy) vs '개발' 검색 좋아요 정렬 마지막 페이지 (like '%keyword%')
대략 30배의 속도 차이가 난다.
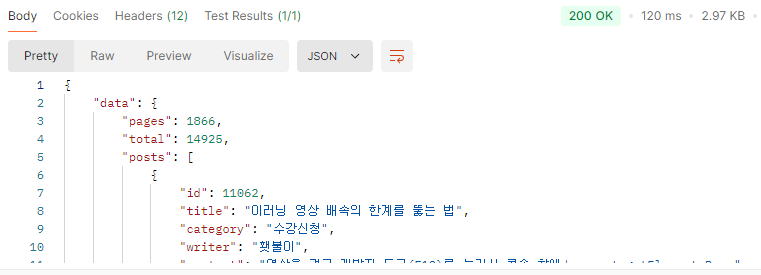
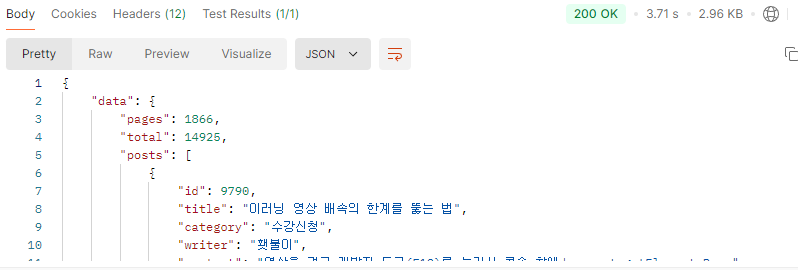
그럼 커서페이징을 하면 어떨까?
본인도 오프셋 페이징보단 커서페이징을 선호하는 편이다.
이 방식에서 커서페이지 방식을 구현하려면 위에서 소개했던 정확도의 값을 가져오는 방식을 사용해야한다.
게시물을 제공할때 같이 정확도의 수치를 전달한다. 그 이후 마지막 게시글의 pk(id값)과 정확도 수치를 이용하여 커서페이징의 구현이 가능하다.
하지만, 기존에 진행하던 프로젝트를 리팩토링 하는 과정임으로 기존에 제공하던 방식에 정확도 수치를 추가해야하고, 프론트에게 그 방식을 적용해 달라고 하기엔 백, 프론트 모두가에 번거로웠기에 추가하지 않았다.
또한, 성능적으로 봤을 때 1페이지와 마지막 페이지의 속도차이가 2배가 났지만 0.03초 차이였고, 검색이기에 기존 게시판 관람에 비해 밀림 현상이 생길 확률이 낮다 판단해, offset 방식을 유지했다.
결론
기존 프로젝트는 팁에 관련한 게시글만 다루기에 많은 데이터가 쌓이지 않을거라 예상해 like 쿼리가 오히려 빠른 모습을 보여줬다.
하지만, 추후에 데이터가 얼마나 쌓을지 모르고 데이터가 쌓일수록 full text search와 like쿼리의 성능 차이는 어마어마했다.
또한, 검색의 정확성에 따라 내림차순으로 제공해주기 때문에 like쿼리를 이용한 검색방식보다 사용자 입장에선 더 좋은 경험으로 작용할 것이다.
그러므로, 검색 기능을 구현하고자 하면 full text search를 도입하도록 하자!

개추