
오늘 학습 계획
- 통계 : 자료분석 강의 수강
학습 내용
1. 범주형 자료분석(Chi Square)
- 예시
- 대선에서 각 정당의 연령대별 지지율이 지난 대선의 지지율과 동일한가?
- 성별에 따라서 선호하는 핸드폰 회사가 동일한가?
- 적합도 검정
- 관측된 값들이 추론하는 분포를 따르고 있는지 검정 (한 개의 요인 대상)
- , 자유도 = 범주의 개수 -1
* : 관찰 빈도(데이터로부터 수집된 값)
* : 기대 빈도
- 독립성 검정
- 각 요인이 다른 요인에 영향을 끼치는지(독립) 검정
- , 자유도 =(열의수 -1)(행의수 -1)
- 동일성 검정
- 서로 다른 세개 이상의 모집돤으로 관측된 값들이 범주 내에서 동일한 비율을 나타내는지 검정
- 예) 남녀의 통신사 선호도가 동일한지 조사
2. 수치형 자료분석(상관)
- 상관관계
- 두 변수간의 함수관계가 선형적인 관계가 있는지 파악
- 상관계수
* 상관계수가 0이라는 것은 두 변수간에 선형관계가 존재하지 않는 것이지, 상관관계가 없는 것은 아님.
- 표본상관관계
- 가설검정
- 가설 : vs
- 검정통계량 :
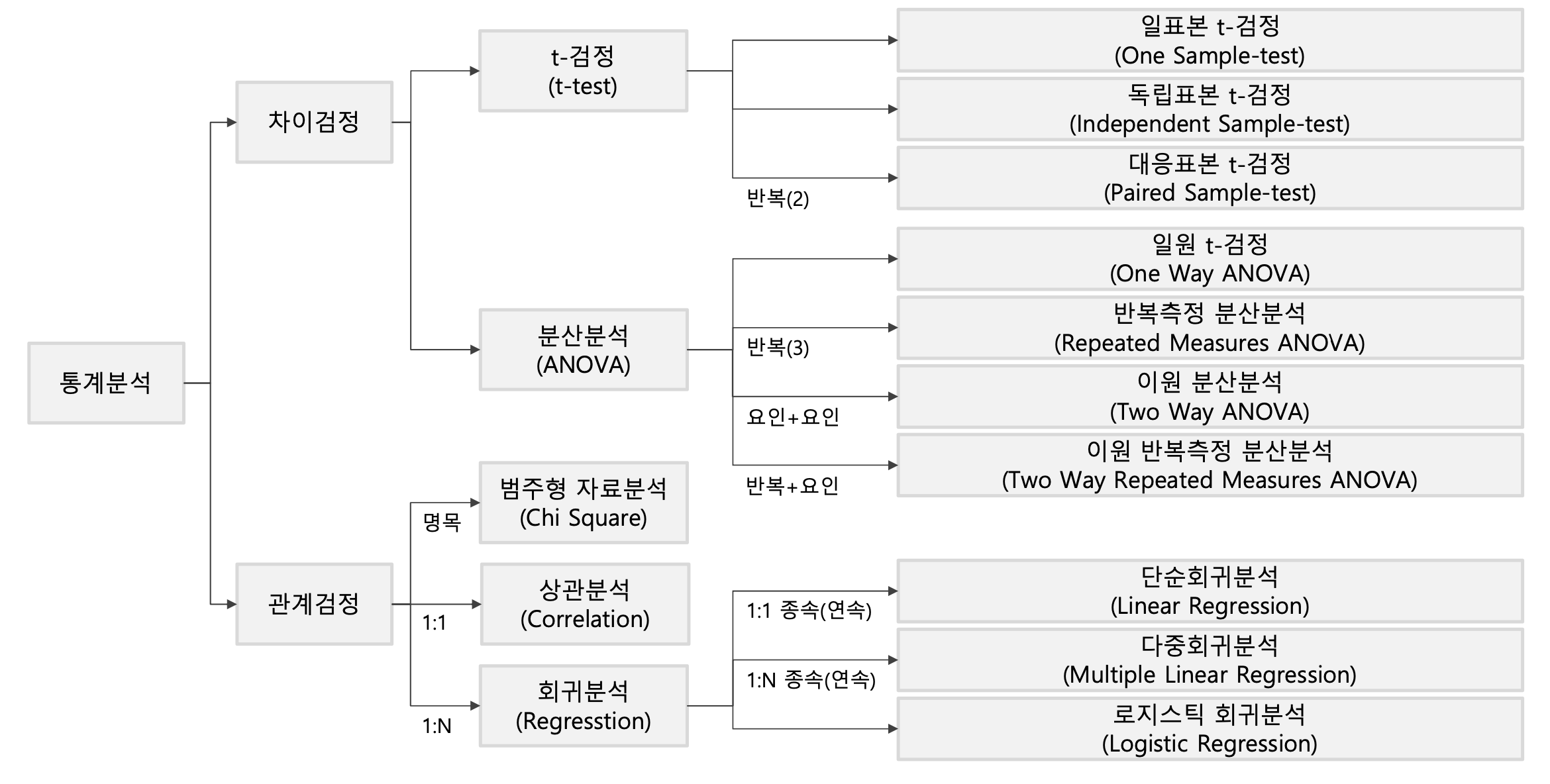
3. 수치형 자료분석(단순 회귀)
- 변수들간의 함수적 관계를 선형으로 추론하는 방법. 독립변수를 통해 종속변수를 예측함.
* 비선형적인 함수적 관계일 경우 비선형회귀를 사용- 종속변수 : 다른 변수의 영향을 받는 반응 변수. 예측하고자 하는 변수.
- 독립변수 : 종속 변수에 영향을 주는 설명 변수. 예측 하는 값을 설명해주는 변수.
- 단순 회귀분석 vs 다중 회귀분석
- 단순 회귀분석
- 하나의 독립변수로 종속변수를 예측하는 회귀 모형
- 오차를 최소로 하여 을 추정하는 방법 : 최소제곱법
- 하나의 독립변수로 종속변수를 예측하는 회귀 모형
- 다중 회귀분석
- 2개 이상의 독립변수로 종속변수를 예측하는 회귀 모형
- 단순 회귀분석
-
최소 제곱법
- 회귀 모형 모수 / 회귀 계수 :
최소제곱추정량(LSE) : 최소 제곱법을 통해 구한 추정량
OLS(Ordinary Least Square) : 최소제곱을 통해 회귀모형 모수를 추정하는 것 - 회귀 모형의 오차에 대한 기본 가정
- 정규성 가정 : 오차항은 평균이 0인 정규 분포를 따름
- 등분산성 가정 : 오차항 분산은 모든 관측값 에 상관없이 일정함
- 독립성 가정 : 모든 오차항은 서로 독립임
- 유도 (편미분)
- 회귀 모형 모수 / 회귀 계수 :
-
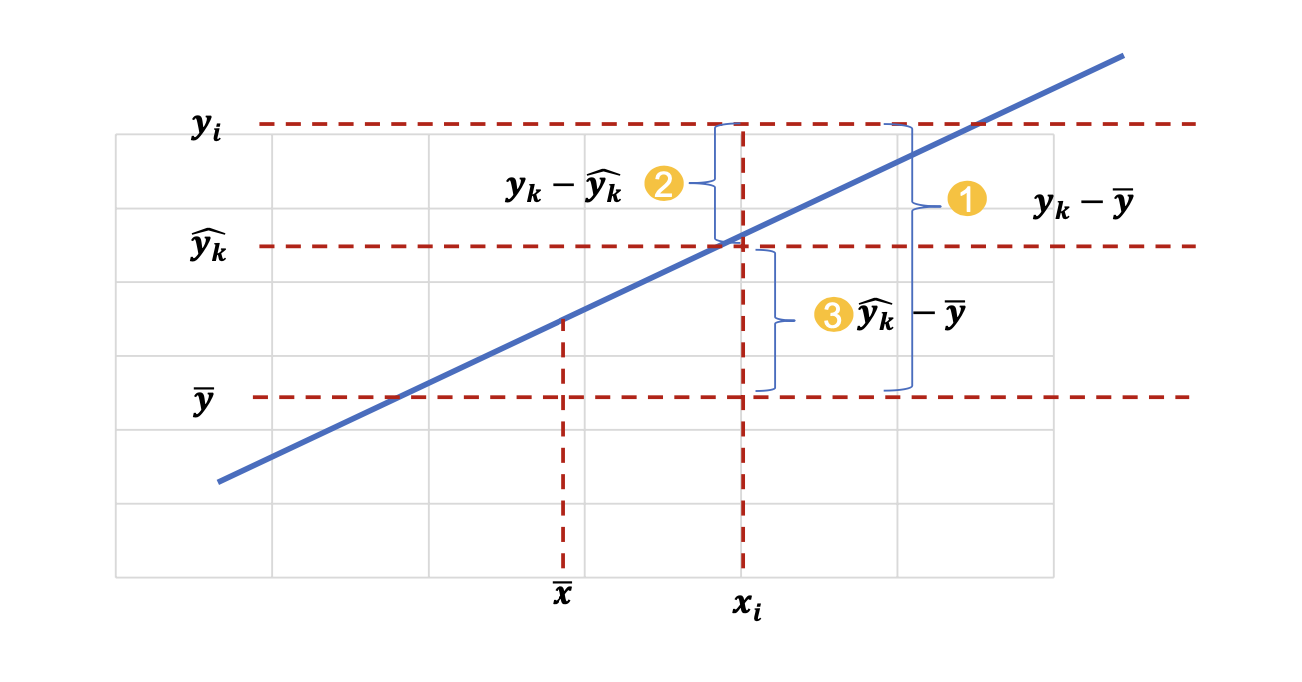
분산분석표
- 추정된 회귀식에 대한 유의성 여부
SST(총제곱합) = SSE(잔차제곱합) + SSR(회귀제곱합)
자유도 :(n-1) = (n-2) + 1

-
가설검정
-
(을 모를 때) -
신뢰구간
-
가설검정
- 가설 : vs
- 검정통계량 :
- 검정 : 이면 기각
-
-
결정계수(Coefficient of determination : )
- 추정된 회귀식이 전체 데이터에 대해서 얼마나 적합한지를 수치로 제공하는 값
- 0~1사이 값으로 1에 가까울 수록 적합하다고 볼 수 있음.
-
수정 결정 계수
- 다중 변수가 추가될 수록 증가되기 때문에, 특정 계수를 곱해줌으로서 항상 증가하지 않도록 함
- 모형간의 성능을 비교할 때 사용함
-
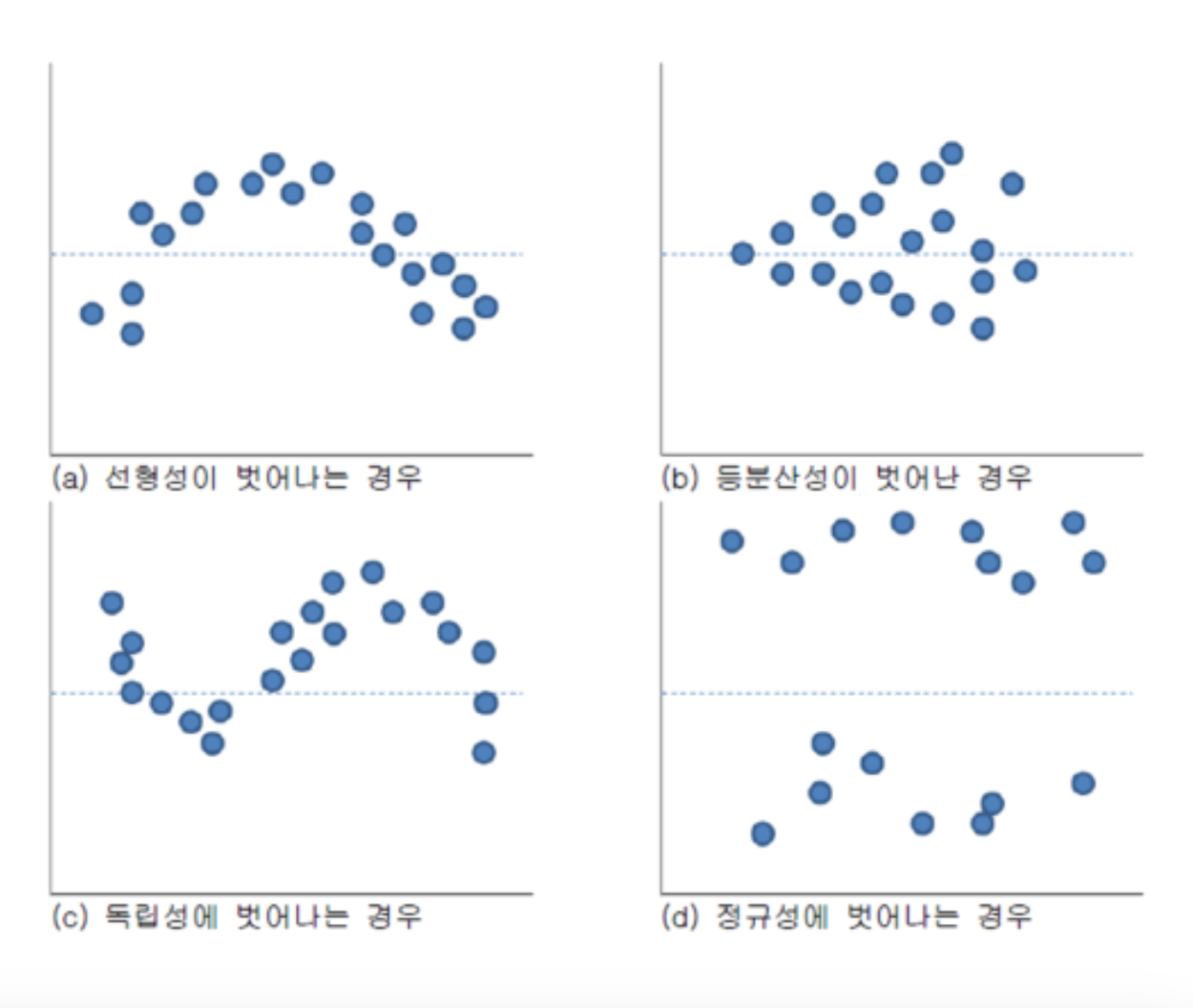
잔차 분석
- 선형성을 벗어나는 경우 : 종속변수와 독립변수가 선형관계가 아님
- 등분산성이 벗어난 경우
- 독립성에 벗어나는 경우: 시계열 데이터에서 독립성을 담보할 수 없음(Durbin-Watson test 실행)
- 정규성을 벗어나는 경우 : 잔차가 -2 ~ +2 사이에 분포해야 함.
4. 수치형 자료분석(다중 회귀)
- 단순 회귀 외 회귀 모형
- 다중 회귀분석
: 2개 이상의 독립변수로 종속변수를 예측하는 회귀 모형
- 로지스틱 회귀분석
: 반응 변수가 범주형(이진형)인 경우 사용하는 모형 - 다항 회귀분석
: 독립 변수가 k개이고 반응 변수와 독립변수가 1차 함수 이상인 회귀분석
- 다중 회귀분석
- 변수 선택법
- 전진선택법
: 독립변수를 1개부터 시작하여 가장 유의한 변수들부터 하나씩 추가하며 모형의 유의성을 판단 - 후진선택법
: 모든 독립변수를 넣고 모형을 생성한 후 하나씩 제거하면서 판단 - 단계접방법
: 전진/후진 방법을 모두 사용하여 변수를 넣고 빼며 판단
- 전진선택법
- 범주형 변수 처리법
- 더미 변수
: 범주형 변수를 사용하기 위해 값이 '0' 또는 '1'의 조합으로 표현하는 더미 변수를 생성함.
ex) 4개의 범주를 표현하기 위해 3개의 변수를 생성함.
- 더미 변수
- 다중공선성
- 상관관계가 높은 독립변수들이 동시에 사용될 때 문제가 발생
- 결정계수 의 값이 높아 회귀모델의 적합도가 높지만, 독립변수의 P-value도 커서 개별 인자들이 유의하지 않는 경우
- 분상팽창요인(Variance Inflation Factor : VIF)이 10 이상일 경우
VIF = : k번째 독립변수를 종속변수로 나머지를 독립변수로 하는 회귀모형의 결정 계수 - 해결방안
- 변수 제거
- 주성분분석으로 변수 재조합 (차원축소)
5. 수치형 자료분석(분산)
-
분산 분석 (Analysis Of Varience : ANOVA)
- 셋 이상의 모집단으로부터 추출한 양적 데이터를 비교하는 통계적 분석 방법
-
분산분석의 개념
- 실험계획법 : 모집단의 특성에 대해 추론하기 위한 특별한 목적성을 가지고, 데이터를 수집하는 실험 설계
- 반응변수 : 관심이 대상이 되는 변수 (연속형)
- 요인/인자 : 실험 환경 또는 조건을 구분하는 변수 / 실험에 영향을 주는 변수 (이산형 또는 범주형)
- 인자수준 : 인자가 취하는 개별 값 (처리)
-
분석분석의 기본 가정
- 각 모집단은 정규분포를 따른다.
- 각 모집단은 동일한 분산을 갖는다.
- 각 표본은 독립적으로 추출되었다.
-
실험의 가정
- 반복의 원리 : 실험을 반복해서 실행해야 함
- 랜덤화의 원리 : 각 실험의 순서를 무작위로 해야함
- 블록화의 원리 : 제어해야 할 변수가 있다면 인자에 영향을 받지 않도록 조건을 묶어서 실험해야 함
-
가설
: 각 집단의 평균은 동일하다()
vs : 각 집단의 평균에 차이가 있다. ( or or ) -
분산분석의 종류
-
일원 분산분석 : 한가지 요인을 기준으로 집단간 차이 조사
-
이원 분산분석 : 두 가지 요인을 기준으로 집단간 차이 조사
-
다원 분산분석 : 세 가지 이상 요인을 기준으로 집단간 차이 조사
-
One-way ANOVA
- 한 개의 반응변수와 한 개의 독립인자
- 분산분석표

- 검증
- 가설
: 각 집단의 평균은 동일하다()
vs : 각 집단의 평균에 차이가 있다. 적어도 하나 이상의 평균이 같지 않다. - 검정통계량 :
- 검정 : 이면 을 기각
- 유의확률(p) :
이면 기각
- 가설
- 사후 검정
- 어떤 처리 조건에 따라 평균 차이가 발생하는지 검정하는 것
- Bonferroni., scheffe, Duncan, Dunnet등의 방법이 있음
-
Two-way ANOVA
-
한 개의 반응 변수와 두 개의 독립인자로 분석하는 방법
예) 편의점 브랜드와 상권을 변경하면서 만족도가 다른지 측정 및 분석 -
상호 작용 : 한 독립변수의 main effect가 다른 독립 변수의 level에 따라서 원래의 선형 관계를 비선형 관계로 변하는 경우
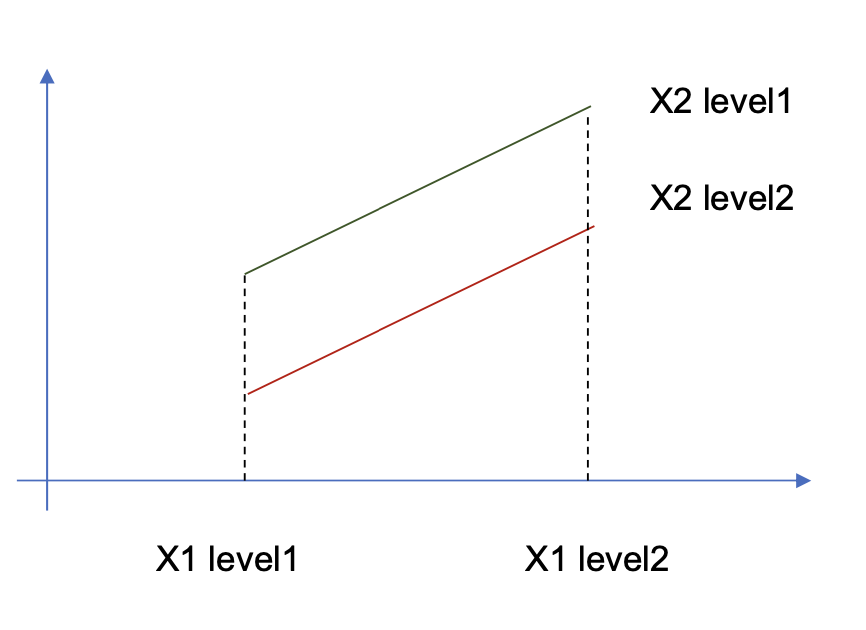

-
가설
- 첫 번째 main effect 가설
vs : 적어도 하나 이상의 평균이 갖지 않다. - 첫 번째 main effect 가설
vs : 적어도 하나 이상의 평균이 갖지 않다 - 상호작용에 대한 가설
: 교호작용이 없다. vs : 교호작용이 있다.
- 첫 번째 main effect 가설
-
-
6. 시계열 분석
- 시계열(시간의 흐름에 따라 기록된 것) 자료를 분석하고 여러 변수간의 인과관계를 분석하는 방법
- 시계계열 분석 방법
- 이동 평균 모형 : 최근 데이터의 평균을 예측치로 사용
- 자기 상관 모형 : 변수의 과거값의 선형조합을 이용하여 예측
- ARIMA(Autoregressive Integrated Moving Average) : 관측값과 오차를 사용해서 모형을 만들어 미래를 예측 (이동 평균 + 자기 상관)
- 지수평활법 : 최근 데이터를 많은 가중치를 주고, 과거 데이터를 낮은 가중치를 주어 미래를 예측하는 방법
- 시계열 요소
- 경향/추세 : 장기적은 증가/감소 추세
- 계절성
- 주기성 : 보통 경기순환과 관련이 있으며 지속 기간은 2년임
- 불규칙 요인 : 예측하거나 제어할 수 없는 요소 (회귀분석의 오차와 같은 항목)
다음 학습 계획
- 통계 : 머신러닝 알고리즘 강의 수강

잘 봤습니다. 좋은 글 감사합니다.