이론 설명
웹 애플리케이션 기술
1) 프론트엔드
사용자로부터 정보를 입력받아 백엔드에서 원하는 규격으로 전달해주고, 백엔드에서 처리한 결과값을 받아 사용자에게 보여줌
- 사용자에게 UI/UX를 제공
- 프로세스의 처음 -> 사용자가 가장 처음 접하는 부분
- ActiveX: 기존 응용 프로그램으로 작성된 문서 등을 웹과 연결 -> 그대로 사용할 수 있도록 하는 기술
- HTML5: 기존 텍스트와 하이퍼링크만 표시하던 HTML -> 다양한 애플리케이션까지 표현/제공하도록 진화
2) 백엔드
클라이언트와 직접 만나지 않고 프론트엔드에서 보낸 데이터를 바탕으로 애플리케이션의 목적이 되는 처리를 수행하는 곳
- 프로세스의 마지막 끝 -> 서버 사이드
- WEB 서버: 클라이언트의 요청 -> HTTP 프로토콜로 HTML, Object을 전송
- WEB 서버만 구축된 경우: 정적 페이지 생성
- WEB 서버 -> 웹 문서, WAS -> JSP 페이지 등을 양분 -> 서버 부담 줄임
- WAS 서버: 웹 상에서 사용하는 컴포넌트를 올려놓고 사용하는 서버 (웹 서버 + 웹 컨테이너)
- 웹과 기업의 시스템 사이에 위치
- 웹 기반 분산 시스템 개발을 쉽게 도와주고 안정적인 트랜잭션 처리 보장
- JSP, 서블릿 이용하는 웹 응용 프로그램 -> JAVA로 작성
- 웹 컨테이너(=서블릿 컨테이너): JSP, 서블릿을 실행할 수 있는 소프트웨어
=> WEB 서버 / WAS 서버 차이: 동적 서버 콘텐츠 수행 여부
- 데이터베이스(Database): 구조화된 Data, DBMS로 관리
- DB 서버에 접속하는 DB 클라이언트 -> 웹 서버에 접속하는 브라우저
- DB 클라이언트: DB를 표현하는 프로그램 -> 쿼리(Query)를 통해 조작
- CRUD 지원: 생성(CREATE), 읽기(READ), 갱신(UPDATE), 삭제(DELETE)
호스팅 및 코로케이션
-
웹 호스팅: 호스팅 회사가 소유한 웹 서버 공간의 일부를 임대 -> 여러 사용자에게 임대하여 웹사이트 운영할 수 있도록 제공
- 사용자는 서버 관리 기술 없어도 웹사이트 운영 가능
- 서버 공간, 리소스를 여러 사용자와 공유 -> 공유 호스팅
- 저렴하며 소규모 웹사이트나 개인 블로그에 적합
=> 책임: 서버 유지, 관리, 보안, 백업 등은 호스팅 회사가 전담
-
서버 호스팅: 호스팅 회사가 소유한 한 대의 단독 서버를 사용 -> 서버 장비 및 네트워크, 기술력을 제공
- 서버의 모든 리소스를 한 사용자가 독점적으로 사용
- 사용자는 서버 운영 환경(ex. 운영체제, 소프트웨어 등) 자유롭게 설정 가능
- 대규모 트래픽 처리, 고성능 서버 필요한 경우 적합
=> 책임: 서버 하드웨어, 네트워크는 호스팅 회사 / 소프트웨어와 데이터 등은 사용자가 전담
-
코로케이션: 고객이 소유한 웹 서버와 네트워크 장비를 설치 및 운영할 수 있는 공간과 환경(전력, 냉각, 네트워크 등)을 임대
- 고객이 직접 소유한 장비를 사용 -> 하드웨어, 소프트웨어 선택의 자유 존재
- 데이터센터의 안정적인 환경 이용 가능
- 고객이 장비 관리와 유지보수를 담당 -> 기술력 필요
=> 책임: 데이터센터 시설(공간, 전력, 네트워크 연결 등)은 호스팅 회사 / 서버 장비 및 운영 관리는 사용자가 전담
-
서버 가상화: 물리적인 서버를 여러 개의 작은 가상 서버로 나누어 자원을 할당
- 다수의 서버가 하나의 물리적인 서버 상에서 동작함
- 보통 가상머신 생성 -> 물리적으로 분리된 컴퓨터처럼 동작
=> 가상화 서버, 컨테이너 서버, 클라우드 서버에 대한 취약점 등 대상을 명확히 타겟팅 해야 함
3) 웹 프레임워크
웹에서 사용하는 여러 라이브러리 등을 묶어서 개발을 편하게 해주는 도구
- 동적 웹 페이지, 웹 애플리케이션, 웹 서비스 개발 보조용
- 목적: 웹 페이지를 개발하는 과정에서 겪는 어려움 감소
4) 웹 크롤링과 스크래핑
-
웹 크롤러(Web Crawler): 웹페이지를 방문하여 각종 정보를 자동적으로 수집하는 프로그램
- 검색 엔진의 근간
- URL, 텍스트, 그림, 소리, 영상 등 추출
- 앤트(Ants), 자동 인덱서(automatic indexers), 봇(bots), 웜(worms), 웹스파이더(web spider), 웹 로봇(web robot)라고도 함
-
웹 크롤링(=스파이더링): 웹 크롤러가 하는 작업 -> Surface Web까지만 크롤링 가능 (Deep Web/Dark Web 불가)
- 웹 페이지의 특정 형태의 정보를 수집
- 웹 페이지의 자동 유지 관리 작업
- 검색 엔진과 같은 사이트에서는 데이터의 최신상태 유지를 위해 크롤링함
- Deep Web에 있어야 하는 페이지(ex. 관리자)가 설정을 잘못하여 표면으로(Surface Web) 나오는 경우가 있음 -> 공격 표면 관리(ASM) 필요
-
웹 스크래핑(=스크린 스크래핑): 웹 사이트에서 정보를 추출하는 행위
- 인터넷 상에 보여지는 모든 자료를 검색, 추출 -> 원하는 곳에 저장할 수 있는 기술
=> 크롤링도 스크래핑 활용한 하나의 예시
- 인터넷 상에 보여지는 모든 자료를 검색, 추출 -> 원하는 곳에 저장할 수 있는 기술
5) 봇(Bot)
- 구글봇(=스파이더): Google의 웹 크롤링 봇
- 새로운 페이지나 업데이트된 페이지를 찾아 Google 색인에 추가하는 과정
- 다양한 종류의 컴퓨터를 사용하여 수 십억 개의 웹 페이지를 가져옴
- 아래 코드를 robots.txt에 삽입하고 소스코드 상단에 위치
- 모든 검색 봇 차단
User-agent: *
Disallow: / - 구글 봇 차단
User-agent: Googlebot
Disallow: /
- 봇넷(Botnet): 스팸 메일이나 악성 코드를 전파하도록 하는 봇(Bot)에 의해 PC 감염 -> 공격자(Bot Master)가 원하는대로 제어할 수 있는 좀비 PC들로 구성된 네트워크
- 좀비 PC로 감염 -> 공격자의 지속적인 좀비 PC 제어 -> 침해 사고 범위가 무한대로 증가되는 위험성
실습 내용
SQLite3을 이용한 쿼리 실습
SQLite3 설치
1) 데이터베이스 및 테이블 생성
- 이름과 생년월일을 입력으로 받는
user테이블 생성
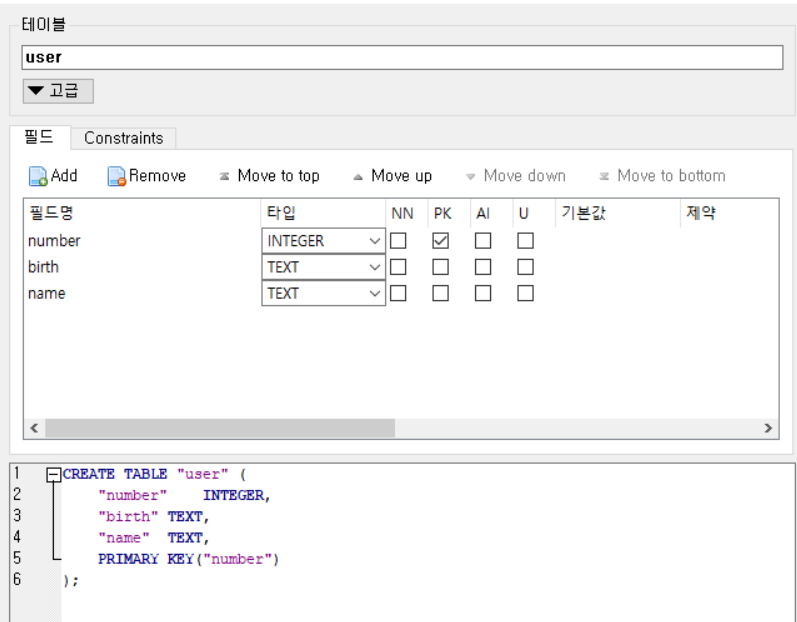
2) CRUD
# CREATE
INSERT INTO user (number, birth, name)
VALUES
(1, "19031228", "Von Neumann"),
(2, "19180511", "Richard Feynman"),
(3, "19120623", "Von Neumann"
# READ
SELECT * from user
# UPDATE
UPDATE user
SET birth="17911226", name="Charles Babbage"
where name="Richad Feynman"
# DELETE
DELETE from user where number=33) 공공 데이터 활용
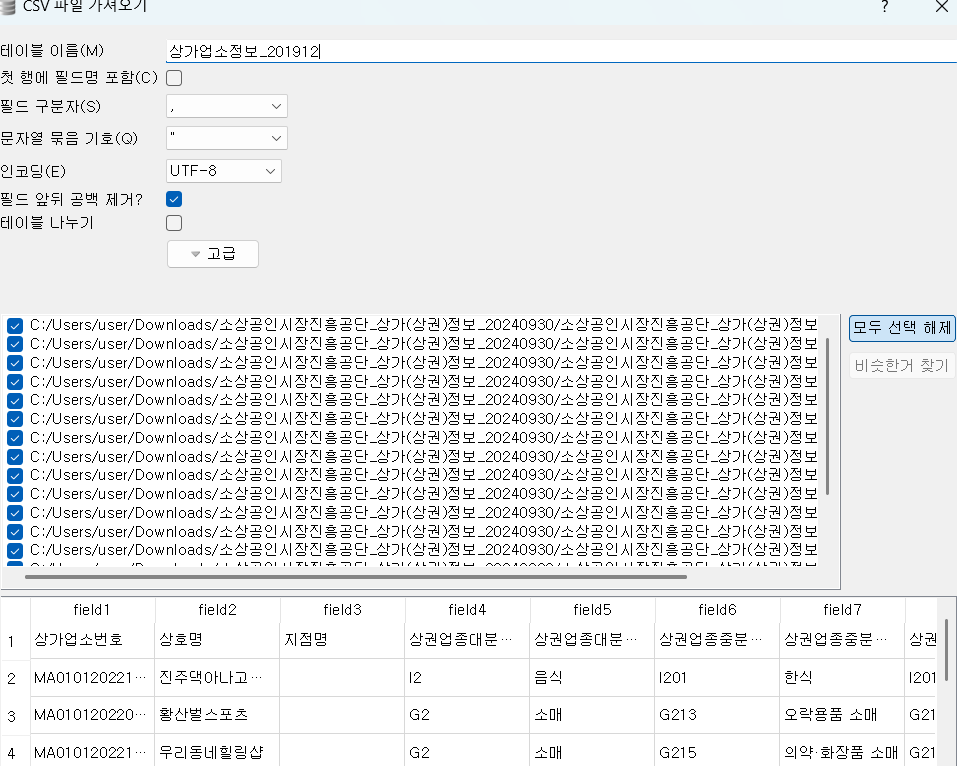 | 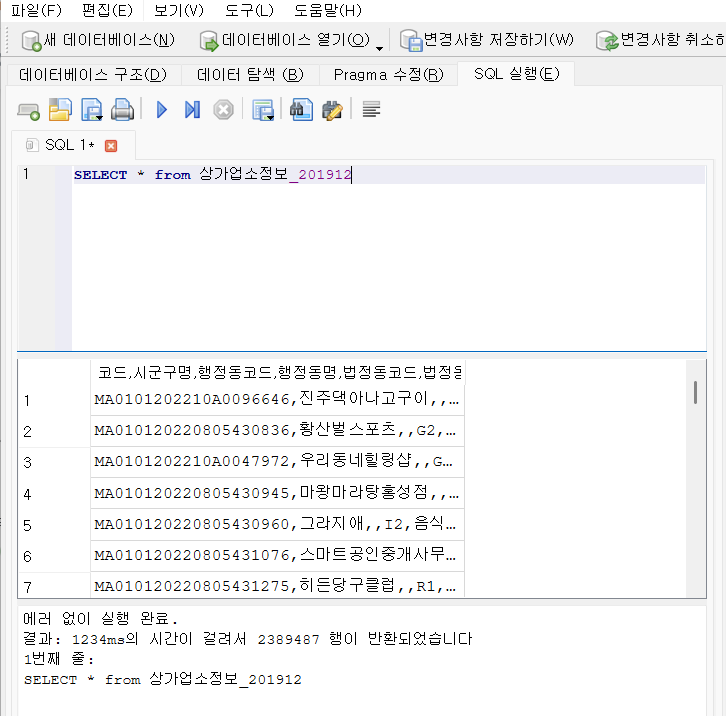 |
|---|
- 다운받은 .zip 파일을 압축 해제하고 CSV 파일을 import
기타 설명
파일 스토리지, 객체 스토리지
- 파일 스토리지: 파일 기반의 저장 방식, 계층 구조로 데이터 저장
- 데이터를 파일 단위로 관리 -> 각 파일에는 이름, 경로, 권한 등의 메타데이터 포함
- 일반적으로 네트워크 파일 시스템(NFS), 서버 메시지 블록(SMB) 프로토콜 사용
- 객체 스토리지: 데이터를 객체 단위로 관리 -> 각 객체는 데이터, 메타데이터, 고유 ID(=Key)로 구성
- Key-Value 타입으로 데이터 저장 -> 필요할 때 Key를 요청하여 데이터 조회
NoSQL
- 관계형 데이터베이스(RDBMS)와 다른 방식 -> 스키마 없거나 유연
- 데이터 구조에 따른 유형
- Key-Value: 단순 키-값 쌍으로 저장
- Document: JSON과 같은 형식으로 데이터 저장
- Columnar: 데이터를 열 단위로 저장, 대규모 데이터 분석에 최적화된 형태
- Graph: 노드-간선의 관계를 저장, 관계형 데이터를 효율적으로 관리
- 데이터 구조에 따른 유형
- 대규모 데이터 처리에 최적화
- 빠른 읽기/쓰기 가능
- 비정형 데이터 처리 가능
ETL
- 데이터의 형식을 가공하기 위한 정규화 과정
- 데이터 통합 프로세스, 세 단계로 구성됨
- 추출(Extract): 다양한 데이터 소스에서 데이터 가져옴
- 변환(Transform): 데이터를 원하는 형식으로 변환 및 정규화
- 적재(Load): 변환된 데이터를 데이터 웨어하우스나 데이터베이스로 로드
- 온프레미스에서 사용하거나 클라우드 기반으로도 활용 가능
Data Warehouse
- 대량의 데이터 분석 및 관리에 사용되는 중앙 집중형 데이터 저장소
- 다양한 소스에서 데이터를 통합 -> 분석 가능한 형태로 제공
- 클라우드 기반의 SaaS로도 제공 -> 확장성, 사용 편의성 높음
- 정형/반정형 데이터를 효과적으로 처리
합성 데이터
- 실제 데이터를 모방하여 인위적으로 생성된 데이터
- 인공지능에서 사용할 수 있는 데이터가 적음 -> 데이터 부족 문제를 해결하기 위해 사용
- 특히 인공지능, 머신러닝 모델 학습에 활용
=> 합성 데이터 보안도 중요하게 대두됨
합성 데이터가 실제 데이터를 대체하기 때문에 데이터 변조, 유출 등의 보안 위협 방지 필요
모의해킹 보고서 작성 양식
- 대상장비
- 취약점 이름
- 취약점 코드(CVE 항목): 코드, CVE 항목, 위험도 수준
- 취약점으로 발생할 수 있는 영향/사고사례
- 취약점에 대해 방어 코드
- 취약점에 대한 대응방안(솔루션 설계 등)
- 관련 통제항목(주정통 기준, ISMS-P 기준, 개인정보 안정성 확보조치 기준) 맵핑
- 주정통 몇번
- ISMS-P 항목 기준
- 개인정보 안전성 확보 조치
=> 글은 읽는 사람의 입장에서 작성되어야 함
참고자료
🔗 국가사이버안보센터 | 국가 망 보안체계 보안 가이드라인
https://www.ncsc.go.kr/main/cop/bbs/selectBoardArticle.do?bbsId=InstructionGuide_main&nttId=198744&pageIndex=1&searchCnd2=#LINK

예전에 파이썬으로 웹크롤링 실습 재밌게 했던 기억이나네요ㅎ 오늘도 잘 보고 갑니다!