
오늘은 특정 벡터를 합치거나, 내적을 하거나 등등 다양한 벡터 연산에 사용할 수 있는 zip() 함수를 알아보자.
일단 자세한 설명에 앞서, Zip 함수를 가장 쉽게 이해할 수 있는 방법은 지퍼를 떠올리면 된다.
흩어져있는 열벡터들을 지퍼로 한번에 묶어서 하나의 데이터 테이블로 만든 다음, 행 단위(객체 1개 단위)로 데이터를 재해석할 수 있게 도와주는 함수다.

1. 정의
zip(*iterables, strict=False)
: Iterate over several iterables in parallel, producing tuples with an item from each one.
반복 가능한(iterable) 데이터셋을 수평으로(parallel) 합쳐 새로운 튜플을 만들어내는 것이 zip 함수의 정의이다.
개념적으로는 알겠는데, 구조적으로는 뭔 말인지 잘 모르겠다. 구조적으로 이해해보자.
1.1. Zip 함수의 구조 = 데이터 맵핑하기
1.1.1 데이터 테이블 = 열벡터의 결합 (Or 행벡터의 결합)
일단, 1개의 데이터 테이블은 N개의 열벡터(또는 행벡터)가 합쳐진 구조이다. 쉽게 말하면 컬럼(열 방향)으로 쭉 쌓여있는 꼴이거나, Row(행 방향)로 쭉 샇여있는 꼴이 결국 하나의 데이터 테이블이다. 데이터 테이블의 개별 컬럼(열 1개)은 개별 레코드(객체)를 설명하는 개별 속성들을 말한다.
1.1.2. Zip 함수의 연산 실행 결과
A = [1,2,3], B=['갑', '을', '병'], C=['합격', '합격', '불합격'] 라고 A, B, C 변수를 각각 정의해보자. 이렇게 보면 너무 불친절하지 않은가? 그럼에도 눈에 확 띄는 것은, 똑같은 자리에 있는 원소 끼리는 서로 논리적 대응이 가능하다는 것이다.
이런 논리적 대응이 가능한 속성들을 묶어버리는 것이 결국 객체를 설명하는 행 하나를 계속 완성시키는 과정이다
아무튼, 조금 구조적으로 설명해보자. A~C 각각의 list는 특정 객체를 설명하는 컬럼(열 벡터) 하나에 해당한다. 그리고 이 컬럼들은 개별 객체에 대한 설명 변수가 된다. 이때, 각 리스트의 크기는 모두 같고 리스트 내의 동일 인덱스끼리는 논리적으로 대응(결합)이 가능하다. 이런 상황에서는 당연히 i번째 원소끼리 데이터를 합쳐서 보고싶은 것이 정상이다.
그럼 어떻게 해야 할까? 개별 컬럼의 동일 인덱스끼리만 합쳐서 행벡터 1개로 만들어버리고 그걸 읽으면 된다. 그 프로세스를 수행해주는 함수가 zip 함수다.
2. 구조 이해
아래 그림을 보면 zip 함수의 실행 결과를 바로 이해할 수 있다.
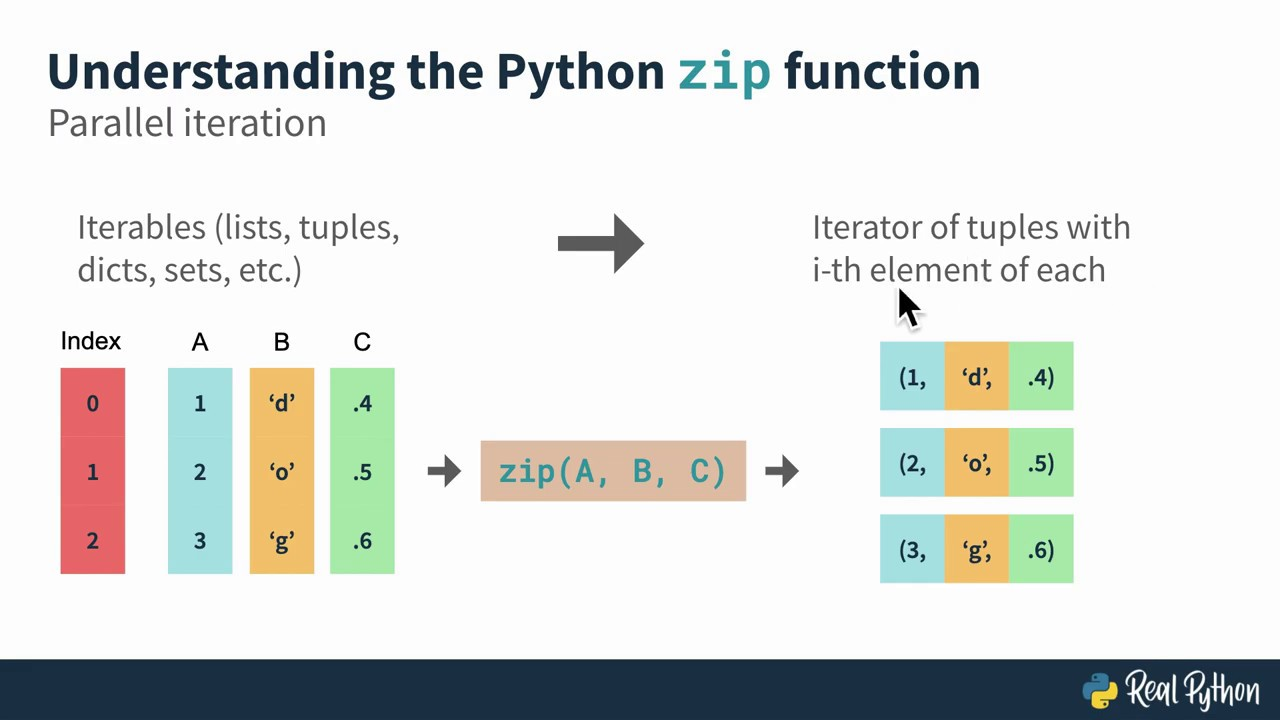
위에서 설명한 열, 행벡터 개념을 빌려서 zip 함수를 쉽게 이해를 하면 아래와 같다.
- 1st. N차원 열벡터 M개를 다 합친다 => 행렬의 데이터 테이블이 된다.
- 2nd. 해당 테이블을 행단위로 쪼개서 튜플로 새롭게 생성한다.
- 3rd. 1개 객체(행 1개)마다 맵핑된 설명 값(컬럼 값)들을 통해 개별 객체 데이터를 편하게 해석한다.
3. Case Study
벡터 내적으로 기댓값(또는 가중평균) 계산하기
- 기댓값 : 개의 서로 다른 확률변수()의 결과값에 대응된 확률값()을 모두 합한 결과
벡터 내적을 사용한 기댓값 계산 함수
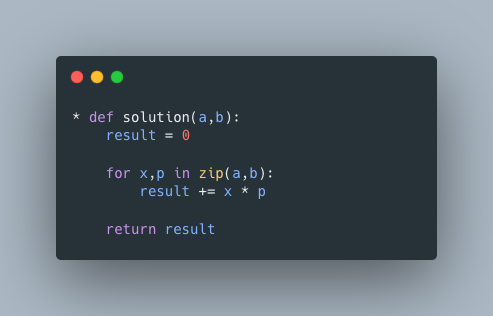
동일 구조로 계산되는 가중평균 값도 구할 수 있다
- 가중평균 : 개의 서로 다른 실수값()을 각 실수값에 대응된 가중치()와 곱하여 전부 합한 값
