정말 좋았던 사이트
https://engineering.linecorp.com/ko/blog/code-obfuscation-compiler-tool-ork-1/#2-5
정말 어썸하다.
C++는 C언어를 기반으로 하고 있는 언어로, C언어에 클래스, 상속 등 객체지향의 특징과 기능을 넣은 객체지향 언어이다.
1. c++ 표준라이브러리란?
C++과 C++ ISO 표준 자체로 쓰여진 클래스들과 함수들의 집합이다
C++ 표준 라이브러리는 표준 템플릿 라이브러리(STL : Standard Template Library)에 의해 도입된 관습에 기반하며, 제네릭 프로그래밍과 STL의 개발자들의 연구에 영향을 받았다.[3][4] 비록 C++ 표준 라이브러리와 STL이 많은 특징들을 공유하지만, 둘 중 어느것도 다른 하나의 상위 집합은 아니다
표준라이브러리에, stl내용이 포함되어있다.
c++ 표준라이브러리 wiki
c++ stl wiki
cppreference
2. STL(Standard Template Library)이란
STL은 표준 C++ 라이브러리의 일부분으로 Standard Template Library의 약자입니다.
STL의 주요 구성 요소는 컨테이너, 할당기, 반복자, 어댑터, 알고리즘, 함수 객체로 이뤄져 있으며, 컨테이너, 알고리즘, 반복자가 가장 중요한 세 요소입니다.
template란? :
- 함수나 클래스를 개별적으로 다시 작성하지 않아도, 여러 자료 형으로 사용할 수 있도록 하게 만들어 놓은 틀. vector 선언할떄와 비슷한구조로 템플릿을 만들수 있다.
- template은 함수나 클래스를 만들 수 있는 틀
- 템플릿은 어떻게? 다형성을 가질까? : 컴파일러는 함수 템플릿 정의문으로부터 앞으로 만들어질 함수의 모양만 기억하며, 실제 함수가 호출될 때 타입에 맞는 함수를 작성한다. 따라서, 헤더에서 함수의 형태까지 같이 정의해두어야! cpp파일 main문에서 호출했을때, 구체화 할 수 있다.
templete 장점
: STL은 결과를 템플릿의 사용을 통해 달성한다. 이 접근법은 전통적인 런타임 다형성에 비해 훨씬 효과적인 컴파일 타임 다형성을 제공한다.
: STL은 컨테이너와 연관 배열 같은 C++을 위한 일반 클래스들의 미리 만들어진 집합을 제공하는데, 이것들은 어떤 빌트인 타입과도 그리고 어떤 사용자 정의 타입과도 같이 사용될 수 있다.
함수형 템플릿
함수를 만들어 낼때, 함수의 기능은 명확하지만, 자료형을 모호하게 두는 것.
아래 예제처럼, 하나의 함수로 여러 자료형에 대한 수행을 할수 있다.
template <typename T>
T sum(T a, T b){
return a + b;
}int main(void) {
int a=1, b =2;
double d1 = 2.2;
double d2 = 3.3;
cout << "int 합 : " << sum<int>(a, b) << endl;
cout << "double 합 : " << sum<double>(d1, d2) << endl;template로 사용하는 변수가 2개 이상일 경우에는 함수이름 뒤에 <> 안에 명확하게 사용하지 않습니다. 예를들면, sum(a, d1);
출처: https://blockdmask.tistory.com/43 [개발자 지망생]
클래스형 템플릿
template<class Type,int N> //class 대신 typename도 가능
class Array {
private:
Type arr[N];
public:
};Array<int,100> arr1;이런식이다.
vector v;
template < class T, class Alloc = allocator > class vector; // generic template
벡터 또한 클래스 템플릿으로 만들어졌다.
STL의 특징으로는
장점
1. 하나의 알고리즘으로 복수개의 컨테이너에 동일한 수행가능(자료형을 바꿔서 여러개 사용가능)
2. 컴파일 타임 매커니즘을 사용하기 떄문에 실행시 효율저하 없음
3. 객체 지향적이지 않다.
4. 표준이므로 이식성이 당연히 확보됨(컴파일러 상관없이 가능)
5. 확장가능
단점
1. 템플릿 기반으로 타입마다 함수와 클래스가 매번 구체화되어 있어 코드가 비대해짐. (용량이 커진다는 말인듯)
2. stl로 작성한 코드는 가독성이 떨어짐.
3. 배우기 어려움.
4. 템플릿을 사용하므로 c++예외코드(try-catch구문)와 같이 사용하기 힘들다.
참고 :
https://skmagic.tistory.com/170
추천강의
- stl 쓰는 이유
- stl 구조 정리
- [라이브러리 강의]
https://www.youtube.com/watch?v=Iv2Cz1LemMU&list=PL7mmuO705dG3S9qZfHRJpDYnLETkhwifn&ab_channel=%ED%94%84%EB%A6%AC%EB%A0%89
3. stl 6가지 구조
컨테이너, 반복자, 알고리즘, 어댑터, 할당기, 함수 객체
1. 컨테이너
똑같이 생긴 것들을 모아두는 장소, stl의 타임이 같은 동적인 객체 집합을 저장하는 역활
1) 시퀀스 컨테이너
자료를 저장하는 기본 임무에 충실한 일반적인 컨테이너 - (벡터, 리스트, 데크)
2) 연관 컨테이너
자료를 일정한 규칙에 따라 조직화 하여 관리, 검색 속도가 빠르다. - (셋, 맵)
3) 어댑터 컨테이너
자료를 미리 정해진 일정한 방식에 따라 관리하는것 - (스택, 큐, 우선순위, 큐)
2. 반복자
반복자는 STL의 핵심문법
C언어의 핵심? =>포인터
C+의 핵심? => 다형성
STL의 핵심? => 반복자
반복자란?
포인터와 상당히 비슷하며, vector, deque, set, map, list등과 같은 컨테이너에 저장되어 있는 원소를 참조(접근)할 때 사용됨 (stack, queue에는 iterator가 없음) 컨테이너에 있는 자료형이 다양하니 단순히 포인트 주소값을 바꾸는 걸로 역참조 하기 어렵다. 그래서 포인트 대신 쓰는듯.
ex) vector<int>::iterator iter = v.begin(); 3. 알고리즘
컨테이너의 멤버함수가 아닌 일반 전역 함수로 작성되있다.
전역변수로 정의되있는 이유?
stl의 컨테이너에 대해 적용할수 있는 매
4. 함수객체
객체(클래스)를 함수처럼 사용하는걸 함수 객체 라고 한다.
#include <iostream>
using namespace std;
class Plus{
public:
int operator()(int a, int b)
{
return a + b;
}
};
int main()
{
Plus pls;
cout << "pls(10, 20): " << pls(10, 20) << endl;
return 0;
}
출처: https://blog.hexabrain.net/267 [끝나지 않는 프로그래밍 일기]
5. 어댑터
인터페이스를 제한하여 만든 (기능이 제한 되거나 변형된) 것,
ex) deque의 경우 양쪽으로 입출력이 가능한데, stack 이나 queue 같ㅇ느 경우 한쪽만 입출력이 가능하다. 코드를 보면 deque의 기능을 제한해서 만들었다고 함.
컨테이너 어댑터 : 스택, 큐, 우선순위 큐
반복자 어댑터 : revers+iterator, back_insert_iterator, frong_insert_iterator, insert_iterator
함수 어댑터 : 바인터, 부정자, 함수 포인터 어댑터
6. 할당기
ex)
vector<int> v;
template <class Type, class Allocator = allocator<Type> > class vectorstl에 포함된 벡터 또는 stl컨테이너들은, 할당기라는 객체가 따로 있어서 이런식으로 벡터를 사용할때 타입으로 넣어주면, push를 했을떄 자동으로 크기에 맞게 할당된다고 하네요
4. 과제 키워드
네임스페이스, 클래스, 멤버 함수, stdio 스트림, 초기화 목록, 정적, const 및 많은 기본 항목
1. 네임스페이스
C++에서는 변수, 함수, 구조체, 클래스 등을 서로 구분하기 위해서 이름으로 사용되는 다양한 내부 식별자(identifier)를 가지고 있습니다.
하지만 프로그램이 복잡해지고 여러 라이브러리가 포함될수록 내부 식별자 간에 충돌할 가능성도 그만큼 커집니다.
이러한 이름 충돌 문제를 C++에서는 네임스페이스(namespace)를 통해 해결하고 있습니다.
using 지시자(directive) : using 지시자는 명시한 네임스페이스에 속한 이름을 모두 가져와 범위 지정 연산자를 사용하지 않고도 사용할 수 있게 해줍니다. - using namespace std;
namespace aa
{
void Display(); // 함수의 원형
int count; // 변수의 선언
}
namespace bb
{
double display; // 변수의 선언
int count; // 변수의 선언
} #include "namespace.h"
aa::count = 4;
bb::display = 3.14;
bb::count = 100;
이런식으로 접근가능하다.
참고 : http://tcpschool.com/cpp/cpp_scope_namespace
2. 클래스
클래스는 C의 구조체에서 확장된 C++의 구조체의 또다른 이름입니다.
구조체 같은 경우는 기본 접근 제한자가 public이며, 클래스의 기본 접근 제한자는 private으로 제한되어 있습니다. 구조체의 기능이 가능하다면 왜, c++에서는 구조체를 지우지 않고, 구조체 클래스 둘다 남겨두었을까? c언어와의 하위 호환을 위해서 이다.
클래스를 생성하는 것을 객체를 생성한다 라고도 표현한다.
접근지정자 - public, private, protected를 이용하면, 좀더 보안성있는 코드를 작성할수 있다.
#include<iostream>
using namespace std;
struct bb{
void init(int amount) { sum = amount; };
void send(int amount) { sum -= amount; };
void receive(int amount) { sum += amount; };
void getSum() { cout << sum << endl; };
int sum;
//static int
}
class Transaction {
public :
void init(int amount) { sum = amount; };
void send(int amount) { sum -= amount; };
void receive(int amount) { sum += amount; };
void getSum() { cout << sum << endl; };
private :
int sum;
};
int main()
{
Transaction A, B;
A.init(1000);
B.init(2000);
//cout << A.sum #지금 sum은 접근지정자가 private상태이므로 접근불가능하다.
int amount = 500;
A.send(amount);
B.receive(amount);
A.getSum();
B.getSum();
return 0;
}결과값
500
2500위의 그림을 보면, class에서 생성한, int는 접근이 불가능 접근하려면, public으로 선언한 함수들을 통해 접근해야한다. 이렇게
3. 멤버 함수
클래스가 데이터를 보유하는것 외에도 함수를 포함할수 있다. 클래스 내부에서 정의된 함수를 멤버함수 라고한다. 때로는 메소드 라고 불리기도한다.
class DateClass {
public:
int m_year;
int m_month;
int m_day;
void print() // defines a member function named print() {
std::cout << m_year << "/" << m_month << "/" << m_day;
}
}
4. stdio 스트림
standard input output
과<stdio.h> 를통해, c함수에서 사용한, printf, fpintf, fopen 등을 호출해서 사용할수 있습니다.
: std라는 namespace
<stdio.h> : global namespace
이지만, c에서 사용해 보았듯, 변수를 변환할 때, %를 입력하고 자료형에 맞게 플래그를 주어야했습니다.
: cpp 스트림을 포함한 헤더. 자료형 따로 정하지 않고 변수를 변환할수 있음.
출처 : https://su-m.tistory.com/4
5. 초기화 목록, 정적, const 및 많은 기본 항목
후에 다시 작성할예정객체 지향 프로그래밍
객체 지향 프로그래밍(Object-Oriented Programming) : 객체 지향 프로그래밍에선 객체(Object)가 중심이며, 모든 데이터를 객체로 취급합니다. 이 객체 지향 프로그래밍은, 실세계의 물체, 물건의 행동(behavior)과 상태(state)를 실체화 시키는 형태의 프로그래밍입니다.
특징
캡슐화(Encapsulation) : 데이터(속성)와 데이터를 처리하는 함수를 하나로 묶는 것
정보은닉(Information Hiding) : 클래스에 직접접근자를 두어, 보안해야할 정보를 지킬수 있다.
추상화(Abstarction) : 공통적인 기능을 추출하는것 ( 정확히 아직 모르겟다.)
상속성(Inheritance) : 상위 클래스의 모든걸 하위클래스가 이어받음
다형성(Polymorphism) : 오버로딩이나 오버라이딩이 대표적인 예. 하나의 템플릿으로 여러 함수 생성가능
장점
- 유연하고 변경이 용이하다. (프로그램의 구조를 파악하기 쉬워 개발과 보수가 간편)
단점
- 지나치게 객체화 하는 것은 실제의 개념과 너무 달라서 이해하기가 쉽지 않아질 수 있다.
출처: https://blog.hexabrain.net/167 [끝나지 않는 프로그래밍 일기]
오버로딩
double add(double x, double y) { return x + y; }
int add(int x, int y); // integer version
double add(double x, double y); // floating point versionc++ 은 이렇게 함수의 이름이 같더라도 자료형이 다르면 다른 함수로 인식한답니다.
호출할때 int로 부르면 인트형 함수가 불러와지고, double 를 부르면 double로 불러진 함수가 불러와 진답니다..
연산자 오버로드
여기 진짜 꼭볼것, 연산자 오버로드 쓰는방법 대충이라도 이해하자.
생성자(Constructor)
클래스의 접근지정자가 public일때는
class Foo {
public:
int m_x;
int m_y;
};
int main() {
Foo foo1 = { 4, 5 }; // initialization list
Foo foo2 { 6, 7 }; // uniform initialization (C++11)
return 0;
}생성자는 new 연산자를 통해 객체를 생성할 때 반드시 호출이 되고 제일 먼저 실행되는 일종의 메서드라고 생각하면 편하다.(메서드와 비슷하지 그 의미가 같은 것은 아니다) 생성자는 멤버 변수를 초기화하는 역할을 한다.
class Fraction {
private:
int m_numerator; // 분자
int m_denominator; // 분모
public:
Fraction() // 생성자 생성
{
m_numerator = 0;
m_denominator = 1;
}
};출처: https://boycoding.tistory.com/244 [소년코딩]
참조형 변수 (Reference variable)
c에서는 두 가지 변수타입에 대해 공부했다.
- 일반 변수(normal variable): 직접 값을 보유.
- 포인터(pointer): 다른 값의 주소(또는 null)를 보유.
c++ 에서는 세번쨰 타입변수를 지원한다.
참조형(reference)
참조형 종류
- non-const 값 참조형
- const 값 참조형
- r-value 참조형
사용법
#include <iostream>
int main()
{
int value = 5;
int& ref = value;
value = 6;
ref = 7;
std::cout << value; // prints 7
++ref;
std::cout << value; // prints 8
return 0;
}위의 코드를 살펴보면 참조형은 선언할떄 참조할 변수를 넣어 선언하고, 참조된 변수랑 완전 똑같이 동작하는걸 볼수 있다.
접근방식이 2개로 된다고 생각할 수 있을거 같다.
출처: https://boycoding.tistory.com/207 [소년코딩]
C++ | 변수 초기화 3가지 방법과 차이
- 복사 초기화 (Copy Initialization)
int i = 0; - 직접 초기화 (Direct Initialization)
int i(0);
단순한 데이터 유형(정수와 같은)의 경우 복사 및 직접 초기화는 본질적으로 동일하다. 그러나 일부 고급 유형의 경우 복사 초기화(Copy Initialization)보다 직접 초기화가 더 잘 수행될 수 있다. - C++ 11의 유니폼 초기화 (Uniform initialization in C++11)
int i {0};
() 를 이용한 생성과 {} 를 이용한 생성의 경우 한 가지 큰 차이가 있는데 바로 일부 암시적 타입 변환들을 불허하고 있다는 점입니다.
초기화 3가지 방법 차이
```int a = 4.5; //warnings
int b( 4.5 ); //warnings
int c{ 4.5 }; //errors
```{} 가 Uniform Initialization 가 가장 엄격하다.
clang++ -std=c++11 의경우 컴파일 할때 위와같이 c++버전 11이상을 사용해야한다. 컴파일 4단계
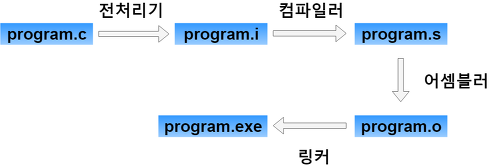
- 전처리기(Preprocessor)
- 컴파일러(Compiler)
- 어셈블러(Assembler)
- 링커(Linker)
1. 전처리기
전처리기 구문(#으로 시작하는 구문)을 처리하는 것이 바로 전처리기라고 하는데요.
아래 명령어로 헤더파일이나, #define정의 해보고 확인해보기.
gcc -E tmp.c -o tmp.i2. 컴파일러
이제 전처리기를 거쳤으니 컴파일러로 컴파일해줍니다.컴파일러는 고수준언어를 저수준언어로 나타내는 역할을 수행합니다.
이렇게 전처리가 끝난 파일을 어셈블리어로 변환해주는 gcc -S program.i -o program.s3. 어셈블러
완전히 기계어로 바꾸어 주는 역할을 합니다. 우리가 읽을 수 없거든요
gcc -c tmp.s -o tmp.o4. 링커
여러개의 오브젝트파일을 하나로 합치거나 라이브러리를 합칠때 링커가 필요하다는 거지요.
gcc tmp.o -o a.out컴파일러
[더 자세한 설명 보기!!!!! 너무 잘 정리해주셨다! 하지만 바로 보면 어려울거 같으니 아래 글을 읽고 보길 추천한다.!](https://engineering.linecorp.com/ko/blog/code-obfuscation-compiler-tool-ork-1/#2-5)컴파일러는 고수준언어를 저수준언어로 나타내는 역할을 수행합니다.
이 글에서는 gcc보다는 clang에 대해 더 자세히 설명한다 .
컴파일러의 기본요소 세가지
-
프론트엔드(front end) : 프로그램 텍스트를 구문 확인, 사용한 프로그래밍 언어의 규약 확인, 파싱단계
-
최적화기(optimizer) : 성능을 가능한 한 최고로 향상 시키고 최대한 바이너리 크기를 줄이는것
-
백엔드(back end) : 최적화기의 의해서 변경된 코드를 가지고 해당 플랫폼에 맞는 어셈블리어를 만들게 된다.
최적화의 경우, 효율성을 위해, 구조를 변경시키곤 한다. 예를 들어 반복문은 부부적으로나 전체적으로 헤체되어, 반복할 코드를 복제해서 연속적으로 수행하는것을 의미ㄹ한다. 이렇게 하면 바이너리 코드는 커지지만, 카운트에 관여 할 필요가 없어지고, 조건에 따라 실행을 분기 시킬 필요가 없다. (어떤 최적화기를 쓰느냐에 따라 같은 구문도 다른 어셈블리어로 변환되는거 같다.)
여기서 프론트엔드에 해당하는게 gcc 와 clang이다.
1. clang 이란?
클랭(Clang)(/ˈklæŋ/)[4] 은 C, C++, 오브젝티브-C, 오브젝티브-C++ 프로그래밍 언어를 위한 컴파일러 프론트엔드이다.
아래 사진에서 front ends부분이 clang이라고 생각하면 된다.
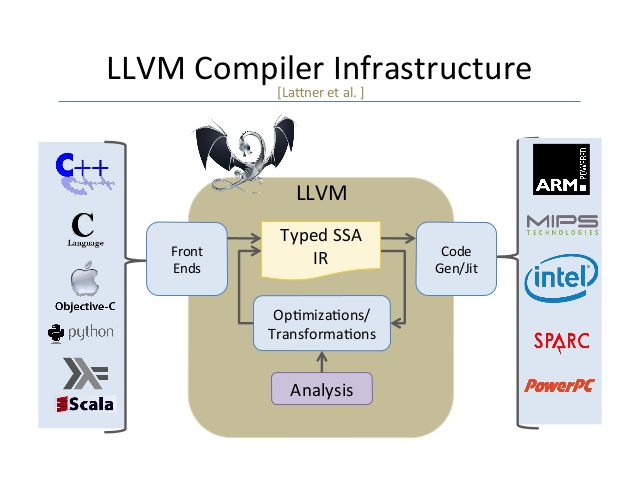
맥에서 기본 컴파일러 구조
컴파일러는 프론트엔드-미들엔드-백엔드의 단계로 구성되어 있다.
Clang(클랭)은 LLVM을 더 효과적으로 사용하기위해 C, C++, Objective-C, Objective-C++를 front end에서 파싱 작업을 거치 IR(Intermdediate Reperesntation)로 만드는 컴파일러이다. (사진에 있는 프론트 엔드가 clang 이라는 말.)
GCC 프론트엔드보다 빠르고, 메모리를 적게 먹고, 깔끔하여 관리하기 쉽고, 더 알기 쉬운 에러 메시지를 내고, 확장하고 사용하기 쉬운 프론트엔드 작성을 목표로 하고 있습니다.
출처: https://zeddios.tistory.com/1175 [ZeddiOS]
https://namu.wiki/w/LLVM
LLVM (low-level virtual machine)
위 사진에서도 보았듯 컴파일러는 LLVM으로 묶여있다.
"LLVM 프로젝트"는 modular / 재사용 가능한 컴파일러(reusable compiler) / 툴체인 기술의 집합체.
LLVM은 컴파일러 프레임워크!
프레임워크란? : 애플리캐이션 개발에 바탕이 되는 템플릿과 같은 클래스들과 인터페이스의 집합
우선 요점부터 말하자면, mac에서는 gcc를 호출하더라도 clang이 사용된다.
clang 추가 설명
-
clang 역사
GCC를 프론트엔드로 하고 LLVM은 미들엔드-백엔드로 사용하는 LLVM-GCC 프로젝트(DragonEgg)가 있었으나, LLVM의 자체 프론트엔드인 Clang이 등장한 이후 컴파일의 전 과정을 LLVM 툴체인으로 진행할 수 있게 되었다. -
clang 장점
GCC IR과 비교하여 LLVM IR의 데이터 구조는 더 간결합니다. 컴파일하는 동안 더 적은 메모리를 차지하며 더 빠른 순회를 지원합니다. 따라서 Clang과 LLVM은 아래 그림과 같이 SPEC 컴파일에서 얻은 데이터로 입증되는 컴파일 시간 면에서 유리합니다. Clang은 GCC에 비해 단일 스레드 컴파일 시간을 5%에서 10%까지 줄입니다 -
gcc 장점
gcc 더 많은 언어 지원,
GCC는 Clang 및 LLVM보다 더 많은 언어 확장과 더 많은 어셈블리 언어 기능을 지원합니다.
어셈블러
컴파일러에서 변환해준 아키텍쳐에 맞는 어셈블리 코드를, 바이너리 코드로 변환시켜준다.
>tmi : 예전에 했던 libasm에서는 nasm을 이용해서 변환했었다.
링크
이제 생성한 .o파일을 모두 모아 하나의 프로그램으로 작성한다.
정적할당, 동적할당 차이.
정적할당
정적 메모리 할당은 메모리 할당 방법 중에 하나로, 메모리의 크기가 하드 코딩되어 있기 때문에 프로그램이 실행 될 때 이미 해당 메모리의 크기가 결정되는 것이 특징이다.
장점: 정적 할당된 메모리는 실행 도중에 해제되지 않고, 프로그램이 종료할 때 자동으로 운영 체제가 회수한다.
단점: 프로그램 시작하면 메모리 크기 못바꿈. 스택에 할당된 메모리이므로 동적 할당에 비해 할당 받을 수 있는 최대 메모리에 제약을 받는다
동적할당
동적 메모리 할당 또는 메모리 동적 할당은 컴퓨터 프로그래밍에서 실행 시간 동안 사용할 메모리 공간을 할당하는 것을 말한다.
장점: 상황에 따라 원하는 크기만큼의 메모리가 할당되므로 경제적이며, 이미 할당된 메모리라도 언제든지 크기를 조절할 수 있다. 최대 크기가 스택보다 크다.
단점: 메모리를 직접 해제해주어야 하므로 번거롭고 위험하다.
메모리 영역(code, data, stack, heap)
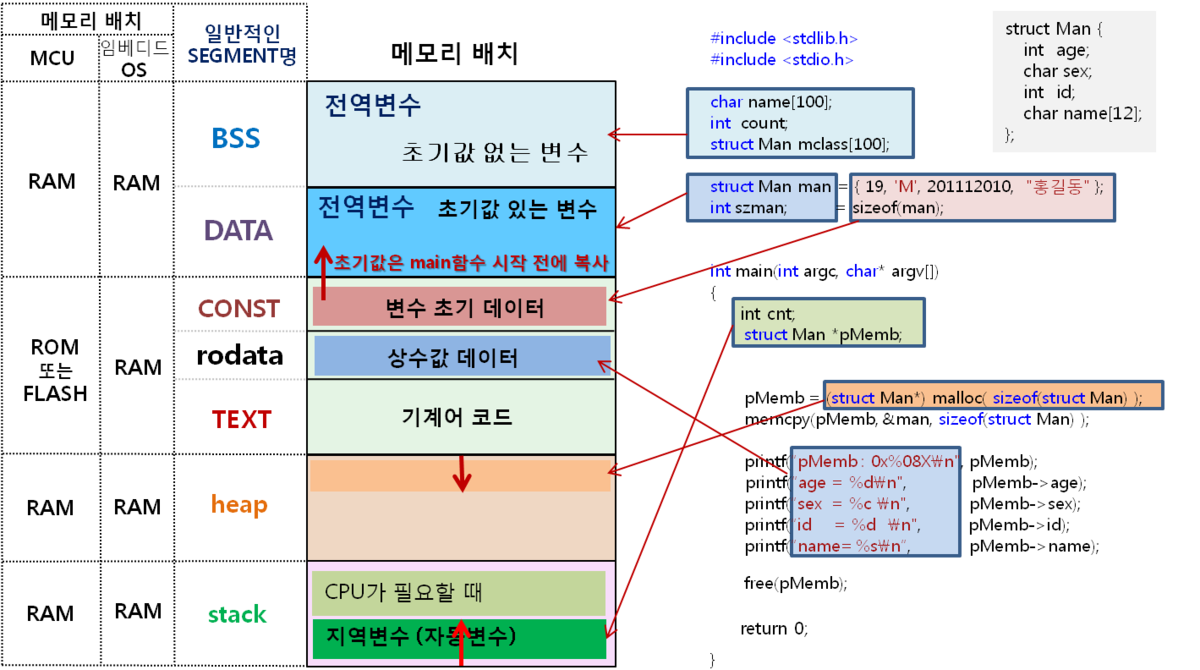
1) code
-
코드 자체를 구성하는 메모리 영역으로 Hex파일이나 BIN파일 메모리다.
-
프로그램 명령이 위치하는 곳으로 기계어로 제어되는 메모리 영역이다.
2) data
- 전역변수(global), 정적변수(static), 구조체(structure) 등이 저장된다.
가) 초기화 된 데이터는 data 영역에 저장되고,
나) 초기화 되지 않은 데이터는 BSS (Block Stated Symbol) 영역에 저장된다.
3) heap 영역
동적으로 메모리를 할당, 메모리 주소 값에 의해서만 참조되고 사용되는 영역이다.
4) stack
프로그램이 자동으로 사용하는 임시 메모리 영역이다. 지역(local) 변수, 매개변수(parameter), 리턴 값 등 잠시 사용되었다가 사라지는 데이터를 저장하는 영역이다.
번외) 전역변수와 지역변수의 차이.
전역변수는 프로그램을 시작할때 data 공간에, 메모리를 할당한다.
지역변소는 프로그램 시작하면서 stack에 메모리를 할당한다.
따라서 전역변수가 지역변수보다 많은 공간을 할당할수있다.
전역변수로 int arr[100000000]; 할당할 때
#include <iostream>
int arr[100000000];
int main(void)
{
arr[999999] = 1;
std::cout <<arr[999999] << std::endl;
}작동함
지역변수로 int arr[100000000];을 할당할 때
#include <iostream>
int main(void)
{
int arr[100000000];
arr[999999] = 1;
std::cout <<arr[999999] << std::endl;
}세그먼트 에러
클래스, 객체, 인스턴스의 개념
클래스(Class) 란
객체를 만들어 내기 위한 설계도 혹은 틀
연관되어 있는 변수와 메서드의 집합
객체(Object) 란
클래스에 선언된 모양 그대로 생성된 실체
특징
‘클래스의 인스턴스(instance)’ 라고도 부른다.
객체는 모든 인스턴스를 대표하는 포괄적인 의미를 갖는다.
oop의 관점에서 클래스의 타입으로 선언되었을 때 ‘객체’라고 부른다.
인스턴스(Instance) 란
설계도를 바탕으로 소프트웨어 세계에 구현된 구체적인 실체
즉, 객체를 소프트웨어에 실체화 하면 그것을 ‘인스턴스’라고 부른다.
실체화된 인스턴스는 메모리에 할당된다
예시
//클레스
public class Animal {
...
}
public class Main {
public static void main(String[] args) {
Animal cat, dog; // '객체'
// 인스턴스화
cat = new Animal(); // cat은 Animal 클래스의 '인스턴스'(객체를 메모리에 할당)
dog = new Animal(); // dog은 Animal 클래스의 '인스턴스'(객체를 메모리에 할당)
}
}static 변수
클래스의 모든 멤버 변수와 멤버 함수는 정적(static) 멤버로 지정될 수 있다. 정적 멤버 변수는 인스턴스가 생성될 때마다 독립적으로 생기는 멤버 변수와 달리 해당 클래스에 하나만 생성되고 모든 인스턴스에서 공동으로 접근할 수 있는 변수이다.
정적함수에 접근방법 두가지.
Led::iCount ++;객체를 이용해 범위지정자(::)로 접근하는 방법
Led led1(12), led2(11);
led1.iCount = 10;
led2.iCount = 30;인스턴스를 이용해 접근하는 방법.
static 사용예시
class phone_book
{
public:
static std::string kind_list[5];
}이렇게 선언 햇으면, cpp 전역변수에서 초기화 해주면됨.
참고 : https://ghgus0702.tistory.com/11 [hohyunera]
참고 : https://studymake.tistory.com/295 [스터디메이크]
참고 :
https://gmlwjd9405.github.io/2018/09/17/class-object-instance.html
