numpy란? numpy array 정리, numpy array 사용 가능 함수 정리, indexing, slicing, numpy array 완전 정리, (day8-1 네이버 ai부캠 뭐할까?)
네이버 ai 부스트캠프
1. numpy
numpy는 파이썬으로 진행되는 모든 데이터 분석과 인공지능 학습에 있어 가장 필수적으로 이해해야 하는 도구입니다.
numpy는 Numerical Python의 약자로 일반적으로 과학계산에서 많이 사용하는 선형대수의 계산식을 파이썬으로 구현할 수 있도록 도와주는 라이브러리입니다. 기존 가장 대중적으로 쓰이던 도구는 MATLAB인데 MATLAB의 역할을 파이썬의 도구로 생각하면 좋습니다.
numpy는 numpy 자체로도 많이 사용되지만 이후에 사용되는 SciPy나 Pandas의 base 객체로도 사용되며 numpy에서 사용되는 다양한 코드 표현법을 그대로 pytorch와 tensorflow에 사용하는 경우가 많아 numpy의 활용법은 반드시 알아둘 필요가 있습니다.
numpy사용하는 이유.
- numerical python
- 파이선의 고성능 과학 계싼용 패키지
- MAtrix와 Vector 와 같은 Array연산의 사실상 표준
- 한글로 넘파이로 주로 통칭
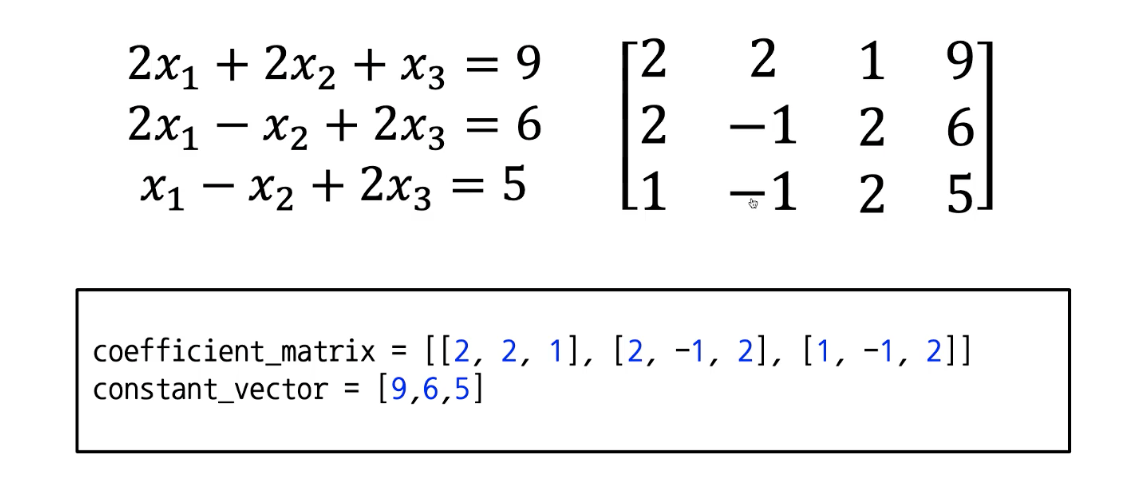
- 첫 사진 처럼 일반 파이썬에서도 메트릭스 구조로 표현을 할수 잇다.
- 하지만 파이썬에서 굉장히 큰 matrix에 대한 표현이 힘듬
- 처리속도 문제 파이썬 언어 인터프리터 라서, 큰 메트릭스를 만들게 되면, 메모리하나하나에, 객체의 주소가 저장된다.
- 메트릭스에 있는 주소값을 확인하고 다시 객체가 있는 값으로 가야하기떄문에 계산 횟수가 늘어나 파이썬에서는 큰 메트릭스를 구현하면 속도가 느려진다는 단점이 있다.
- 좀더 계산을 빨리하기위해 numpy를 사용하기도 하며, 그외에, 다양한 계산기 기능들을 활용하기 위해 numpy를 사용하자.
numpy 특징
- 일반 리스트에 비해 빠르고, 메모리 효율적
- 반복문 없이 데이터 배열에 대한 처리를 지원함
- 선형대수와 관련 된 다양한 기능 제공
- c,c++ 포트란 등의 언어와 통합 가능
conda activate 가상환경
conda install numpy
conda install jupyter
예제 실행할 곳에서 jupyter Notebookndarray
- 엘리어스는 import numpy as np 으로 사용함
test_array = np.array([1, 4, 5, 8], float)
test_array = np.array(['1', 'a', 5, 8], float)- 위의 배열 원소들의 데이터타입은 전부 float으로 나오게 된다
- numpy는 하나의 데이터 type만 배열에 넣을 수 잇음
- list와 가장 큰 차이점 -> 다이나믹 타이핑 지원안함. (c랑 같다.)
배열 생성 차이점(파이썬 vs numpy)
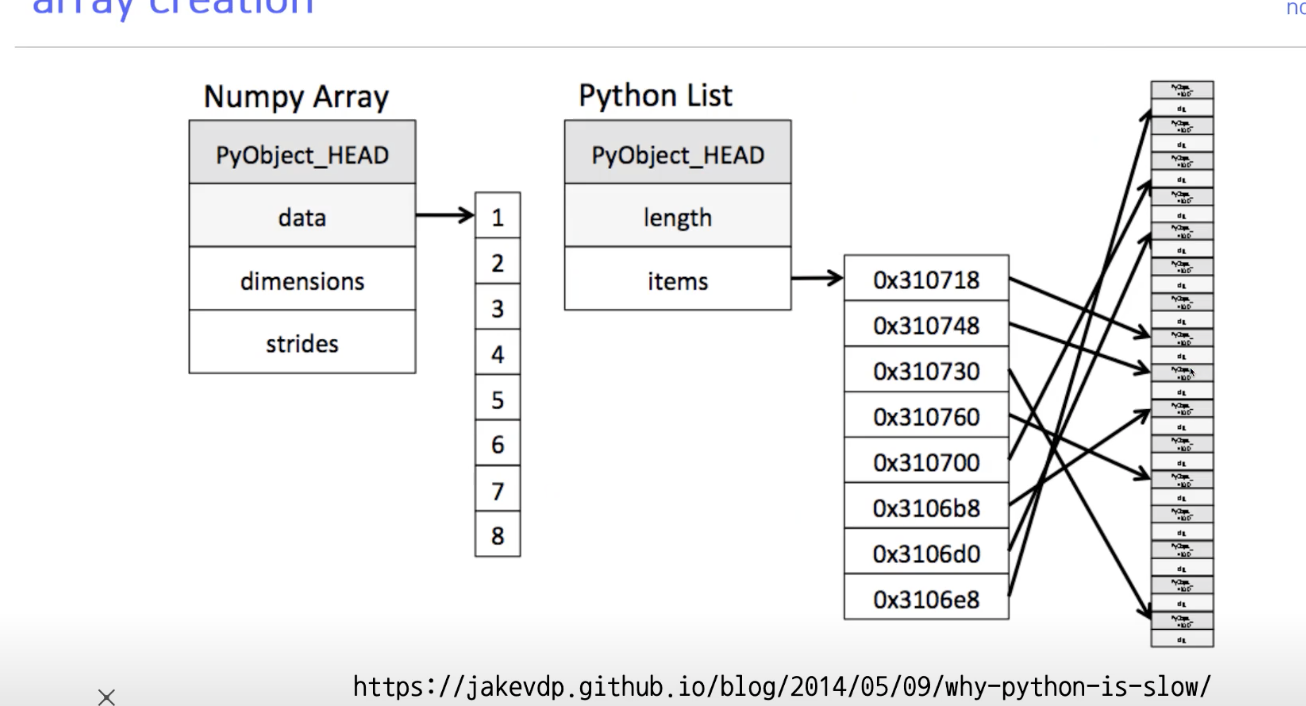
- 파이썬의 경우 배열을 생성하고 a= [7,8,9,10] 이라고 넣게 되면 배열에 7이라는 값이 들어가는게 아니라, 7의 객체에 해당하는 주소 값이 저장된다. 그래서 7로 가려면, 생성한 배열에 접근하고 거기있는 메모리를 통해 다시 7로 접근한다.
- numpy의 경우 배열을 생성하고 a =[7,8,9,9,10]을 넣으면 배열에 있는 그대로 7이라는 값이 들어간다. (강의 다시보기.)
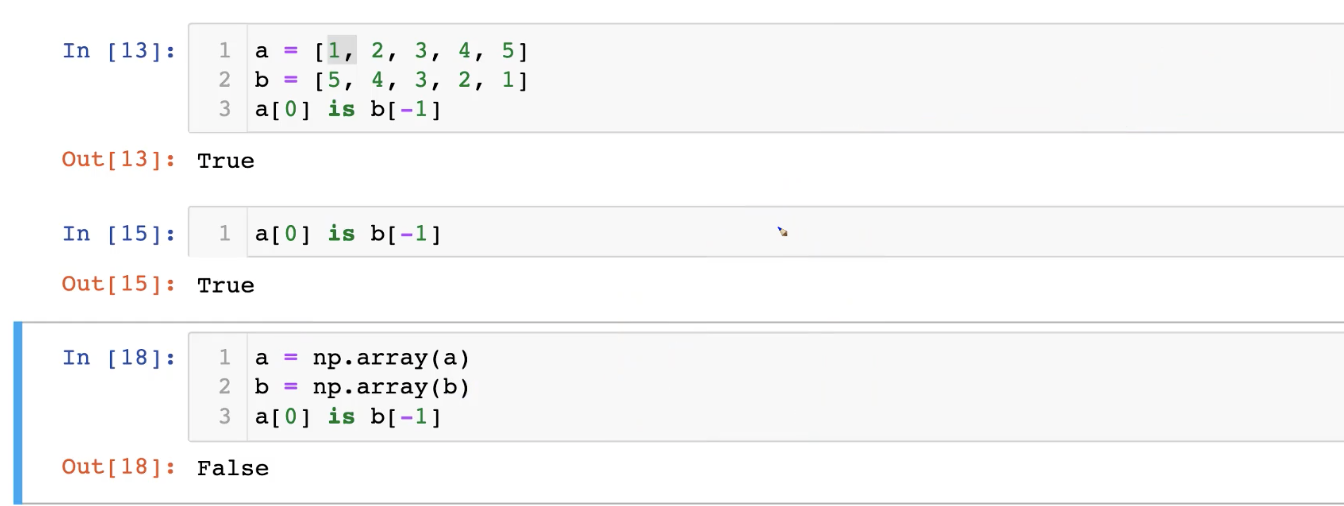
is는 메모리와 값 모두 비교하고 같으면 참(정확하진 않은데, 첫 번째 에선, 파이썬 함수 형태라,a[0],b[-1] 모두 '1' 이라는 객체가 있는 주소값을 가지고 있어서 is하면 True가 나오는데, 두번쨰 넘파이 어레이에서는 a[0],b[-1]은 a의 메모리 주소에 0번쨰 메모리 주소를 가지고 있고, b[-1]은 b라는 array에 마지막 주소값을 가지고 있어서 서로 주소가 다르다. 고로 false 가 나온다.
넘파이 array의 기능
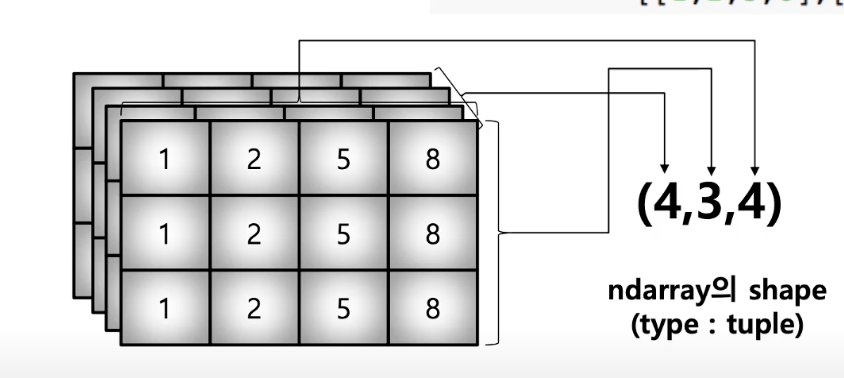
- shape :numpy array 의 dimension을 구성함([1,2,3].[1,2,3].[1,2,3,]) . shape = (3,3)
- ndim : shape에서 나오는게 몇개인지
- dtype : numpy array의 데이터 type을 반환함
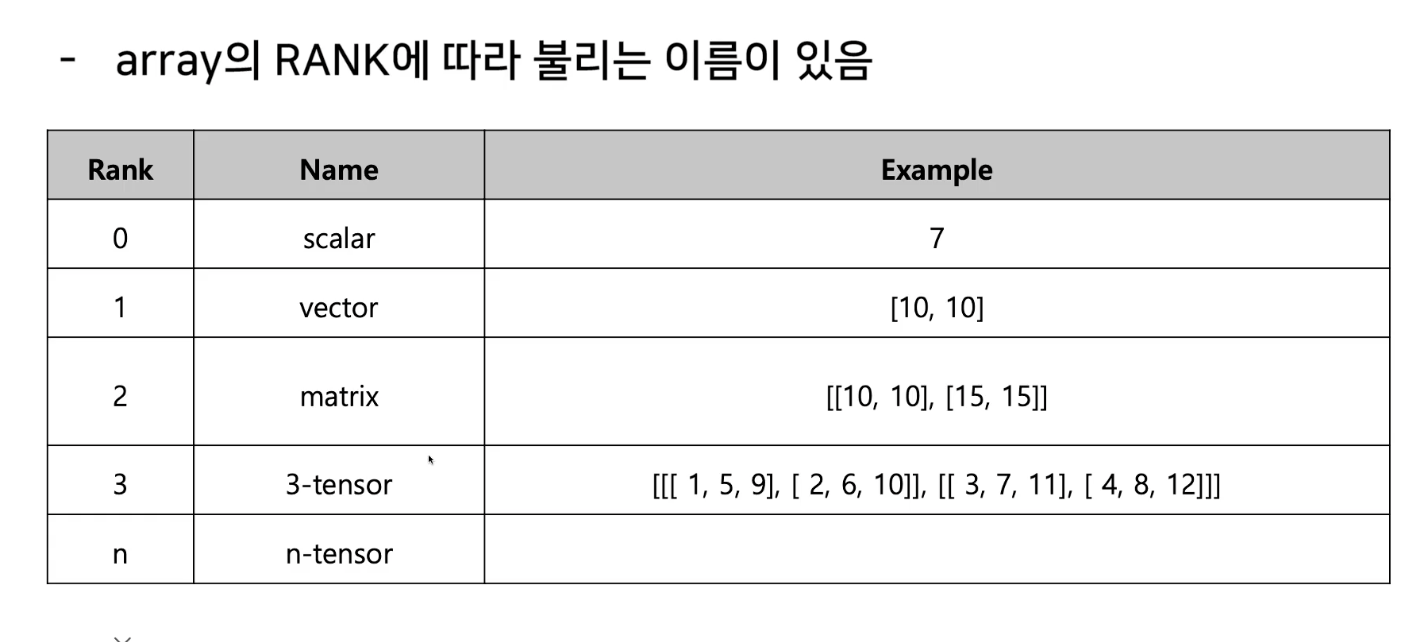
- 사진을 보면 배열의 랭크에 따라 불리는 이름이 다르다. (벡터, 메트릭스, ...)
numpy part 2
위에서는 넘파이의 특징에 대해 살펴보았다. 이번엔 넘파이 array에서 지원 가능한 함수들을 살펴보자.
1. 배열 모양을 바꾸는 함수
reshape
- array의 shape 의 크기를 변경함, element의 갯수는 동일
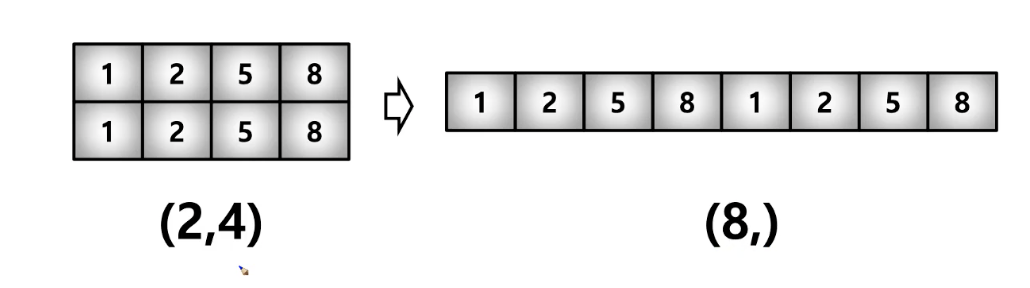
- 사용법 : 배열이름.reshape(2,4)
- 위의 shape(2,4)라는 배열의 요소의 개수는 8개이다. 이 배열을 다시 reshaoe(-1,2)한다면 -1에는 -1 * 2 == 8 이 나오는 숫자가 들어간다. 고로 -1에 4가 들어감.
flatten
- reshape의 기능 을 하나 때와서 만든것(많이 쓰나보다.)
- 다차원의 함수를 일차원의 함수로 변환
- [[1,2,3,4],[5,6,7,8]] 을 flatten시키면 [1,2,3,4,5,6,7,8] 이 나옴
2. indexing과 slicing 해주는 함수
indexing
- 파이선 list와 달리 이차원 배열에서 [0,0] 표기법을 제공함.
- list[0][0] == lists[0,0]
slicing
- numpy slicing 은 메트릭스 구조(또는 다 차원의 배열)를 쉽게 짜를수 있음.
- 메트릭스 스라이싱을 예로 보면
- test = [[1,2,3,4],[5,6,7,8],[9,10,11,12]]
- test배열을 [0:2, 0:1] 이라고 슬라이싱을 하면, [[1],[5]]가 추출된다
- 사진 건너띄기도 가능!
3. 생성함수 (create function)
arange
- np.arange(30) => 0~29까지 배열 생성
- np.arange(0,30, 0.5) => 0,0.5,1~ 29.5까지 배열 생성
random sampling
- 데이터 분포에 따른 sampling 으로 array를 생성
- 사용법 : np.random.uniform(0,1,10).reshape(2,5) 균등하게 분포 시킴
- 0~1사이의 float 값들이 2,5 형태의 배열로 생성됨
ones, zeros and empty
zeros
- zeros : 0으로 가득찬 ndarray생성
- 사용법 : np.zeros(shape=(10,), dtype=np.int8)
ones
- ones : 1로 가득찬 ndarray생성
- 사용법 : np.ones(shape=(10,), dtype=np.int8)
empty
- empty : 메모리 할당은 되는데, 초기화는 안시켜줌
- 사용법 : np.empty(shape=(10,), dtype=np.int8)
4. something_like
- 기존 만들어진 array의 shape형태로 1,0또는 empty array를 반환
- 사용법 : np.ones_like(배열이름) 하면 1로 가득찬 배열
5. 행렬 대각선 함수
identity
- 단위 행령 (i 행령)을 생성함
- 사용법 : np.identity(n=3, dtype=np.int8)
- [1,0,0]
- [0,1,0]
- [0,0,1] 형태로 생섬됨
eye
- identity와 비슷하게 대각선인 1인 행렬을 만드는데, k의 시작 index를 변경가능
- 사용법 : np.eye(3,5,k=2)
- [0,0,1,0,0]
- [0,0,0,1,0]
- [0,0,0,0,1] 형태로 생성됨
diag
- 대각 행렬값 추출 할떄 사용
- 사용법 : 방금전에 eye에서 만든 배열을 np.diag(eye_array, k= 2) 디아그 함수로 쓴다고 한다면
- 출력 : eye_array == [1,1,1]
6. operation functions(조작함수)
sum
- 사용법 : array.sum(dtype=np.float)
list에서 sum(list)랑 비슷하지만, numpy함수는 array.sum()을 사용하자
axis
- 모든 operation function 을 실행할 떄, 기준이 되는 dimension축
- axis 값에 따라 조작 함수의 방향을 설정할수 잇음.
- 사용법 : array.sum(axis=1), array.sum(axis=0)

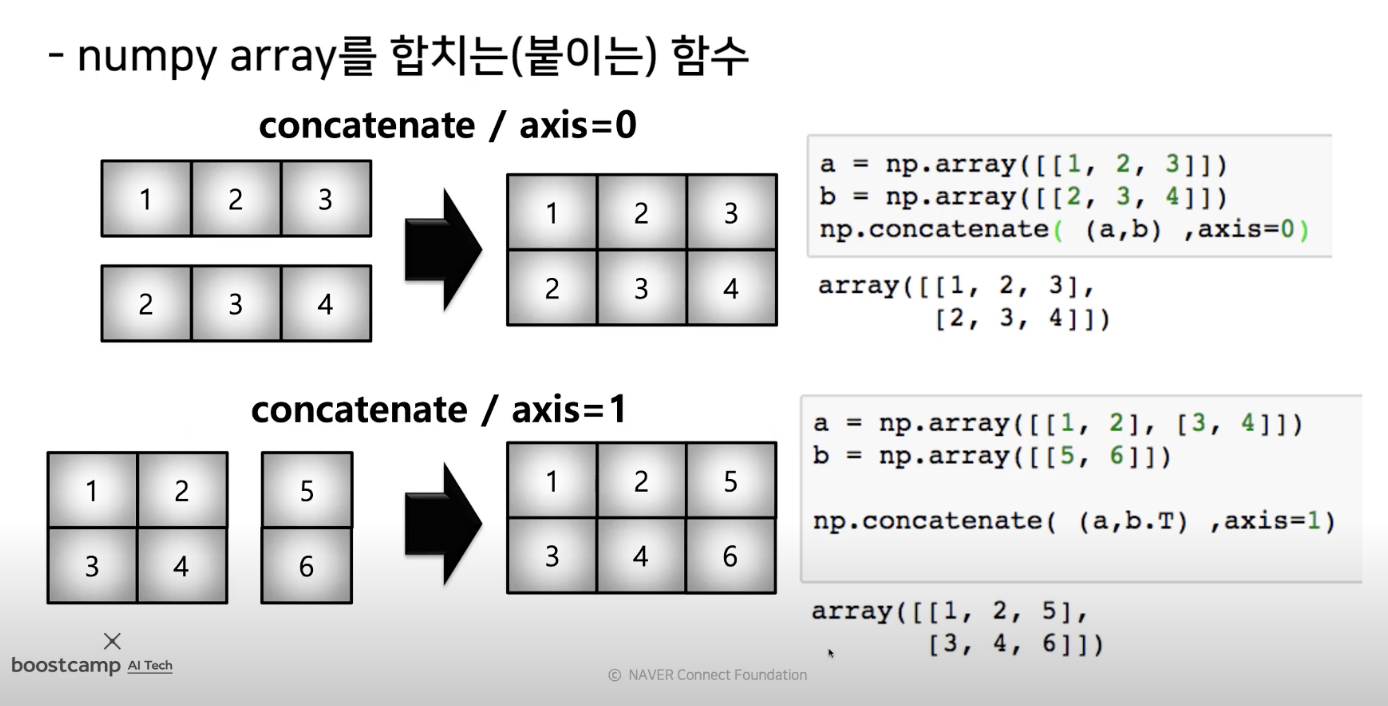
concatenate
- numpy array를 합치는 함수
- vstack, hstack
- vstack은 행을 붙이고 hstack은 열을 붙임
- 사용법 : np.hastack((array1,array2))
operations b/t arrays
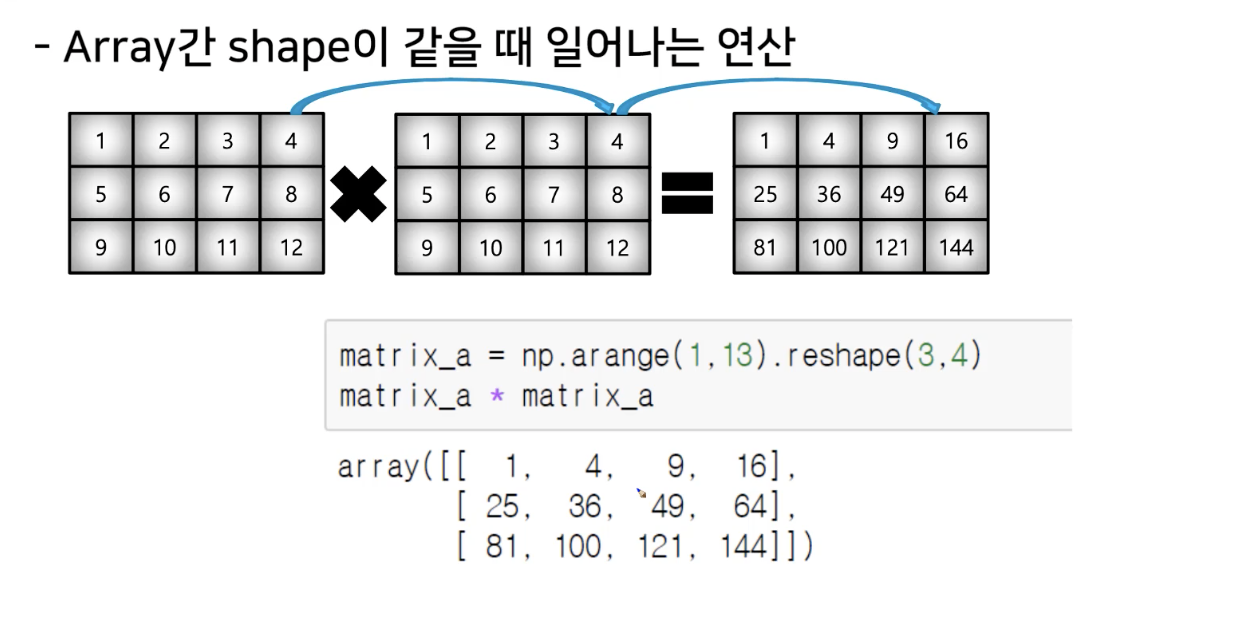
- numpy는 array간의 기본적인 사칙 연산을 지원함.
- 근데 123의 리스트 두개를 더하면 같은 자리 끼리 더함(성분합 : shape의 모양이 같으면 같은 위치까지 더한다는 말)
transpose
- 행과 열이 전치가 됨(바뀜, 사진으로 보는게 이해잘됨)
- 사진
broadcasting
- shape이 다른 배열 간 연산을 지원하는 기능
- 23 배열이 있다고 가정하고, array 2를 하면 배열의 리스트에 모두 2가 곱해짐
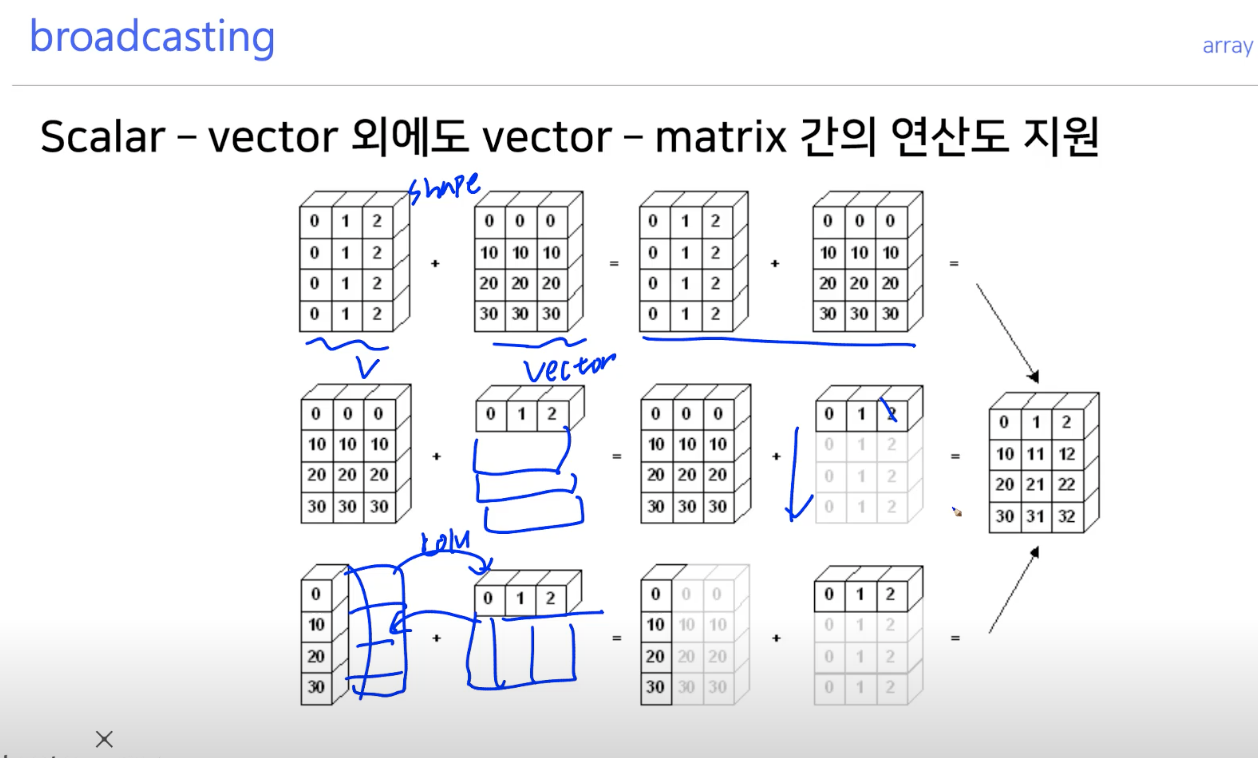
- 사진은 오타가 있음.
- 배열의 크기가 똑같지 않아도, 똑같은 위치끼리 곱또는 덧셈할수 있도록 함.
- 예를 들면 3*4배열이랑 1*4배열이 있으면, 1*4 배열을 행을 2개 늘려 배열을 똑같이 만들고 더하거나 곱해짐
넘파이가
대용량 계산을 할떄 속도가 훨씬 빠름...
concatenate처럼 계산이 아닌 할당에서는 연산 속도 차이가 없음.
comparisons
- 위의 장에선, numpy의 특징과 사용가능한 함수에 대해 살펴보았다. 이번 장에선 넘 파이 array간 비교에 대해 살펴보자.
- 넘파이 array 끼리 비교
All & any
- 사용법 : np.any(a>5, np.any(a<0))
- a>5 : a라는 배열의 요소들이 모두 5보다 큰지 비교하고, 크면 트루, 작으면 false인 배열을 만듬
- np.any(a<0) : a의 모든 배열 중 하나라도 0보다 작으면 트루, 요소 모두 0보다 크면 flase
- np.any(a>5,np.any(a<0)) : a가의 요소중 하나라도 5보다 크거나 0보다 작으면 트루 모두 해당하지 않으면 flase
- 근데 앞에 붙은 any는 or이라는 의미고 all은 and 조건이다.
logical
- np.logical_and(a>0, a<3)
- shape이 같고, bool타입의 요소로 설정 된 두배열을, 같은 행렬 위치를 and일떄 값 을 모아 배열로 만듬.
- np.logical_not : 트루또는 페일을 반전
- np.logical_or(arr,arr2) :or형태로 배열 만듬
- 두 배열 비교하는 거라 생각하자.
np.where
- 사용법 : np.where(a>2)
- a라는 배열에서 2보다 큰 값들만 추출해서 배열로 만듬
- 사용법2 : np.where(a>2, 3, 2)
- 형태로 a>2 에서 a보다 크면 3 작으면 2가 들어가게 배열을 만들어라
argmax & argmin
- array내 최 대값 또는 최속값의 index를 반환함.
- np.argmax(a, axis=1)이런식으로도 사용가능
- np.argsort() 으로 배열들의 오름차순으로 인덱스 값을 반환해줄수도 잇따.
boolean & fancy index
boolean index
- 특정 조건에 따른 값을 배열 형태로 추출
- array[array > 3]이런 형태면
- 배열 array 중에 3보다 큰수만 뽑혀 배열이 만들어진다.
fancy index
- 배열에 인덱스 값을 넣어 반환
- 넣게되는 인덱스와 비교 배열과 shape같을 필욘 없지만, a 배열 범위를 b의 원소가 넘어가면 안된다. 예를 들어 b의 원소에 5라는 값이 있으면 a인덱스를 벗어남.
a = np.array([2,4,6,8], float)
b = np.array([0,0,1,3,2,1], int)
a[b]
출력 : array([2., 2., 4., 8., 6., 4.])
numpy data i/o(in,out)
loadtxt & savetxt
loadtxt
- text type의 데이터를 읽고, 저장가능
- 사용법 : a = np.loadtxt("./hi.txt")
- a에 문자열이 들어갑니다~~~ 왜캐 많아;;
- a = np.loadtxt("./hi.txt", delimiter="\t")이런식으로 문자 사이에 스페이스나, 탭등 반복해서 오는 규칙이 잇으면 그 기준으로 짤라 배열을 만들수도 잇음. (split이랑 비슷)
savetxt
- np.save("npy_저장할파일이름", arr=aint_3)
- 피클 형태로 저장이 됨.
