pandas II
pandas I 강의에 이어서 pandas 라이브러리의 다음과 같은 기능에 대해 알아봅니다.
groupby
pivot_table
joint method (merge / concat)
Database connection
Xls persistence
grouby
-
여러가지 데이터들 중에 핸들링 하는 방법을 배운다.
-
SQL groupby명령어와같음
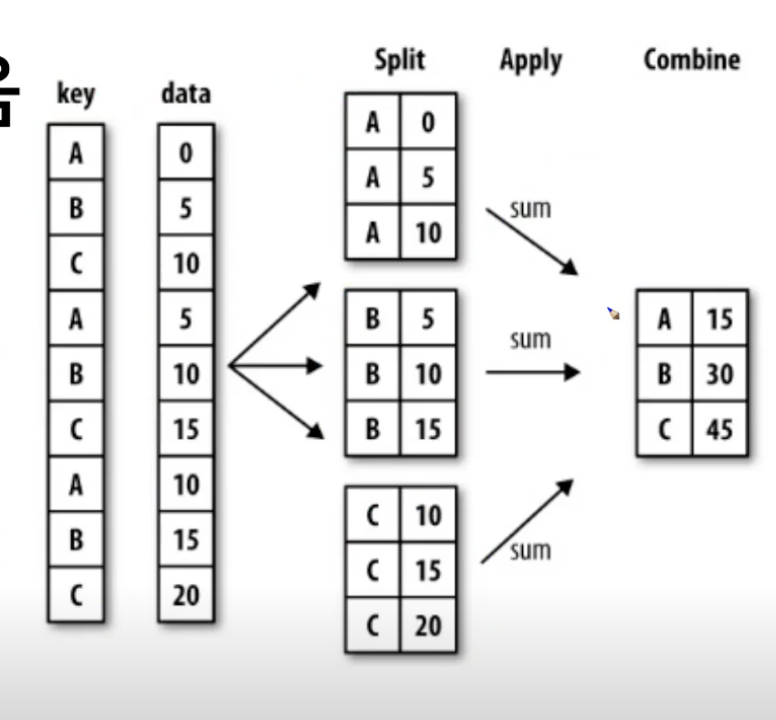
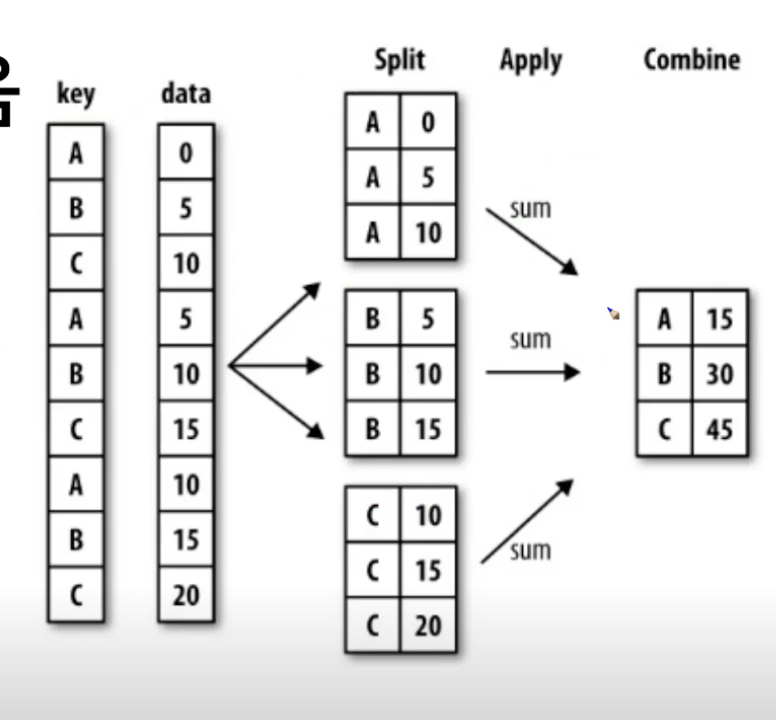
- split -> apply -> combine
- 자르고, 원하는 함수를 적용 시키고,
- 과정을거쳐연산함
-
예를 들면, df.groupby(["Team", "Year"])["Points"].sum()
-
팀별로 묶고, 팀별에서 년도를묶는다. 그리고 년 도별로 points를 더함
-
이렇게 나온 결과 값을, unstack이나, reset_index 같은걸로 데이터를 풀어 줄수 있고,
-
h_index.sort_values()같이 sort를 사용해서 정렬해줄수 있따.
-
h_index.sort_index(level=0)을 해서 원하는 기준점으로 솔트시킬수 있다.
-
여기서 h_index는 데이터 프레임의 모양이지만, 데이터 타입을 찍어보면 series데이터이다.
groupby -groued
- groupby에 의해 split된 상태를 추출가능함.
- grouped = df.groupby("Team")
- list(grouped)
- 위의 사진에서 찍는 group은 타입이 데이터 프레임이다
- gouped.get_group("hi")을 사용해서 원하는 것만 뽑아 올수 잇다.
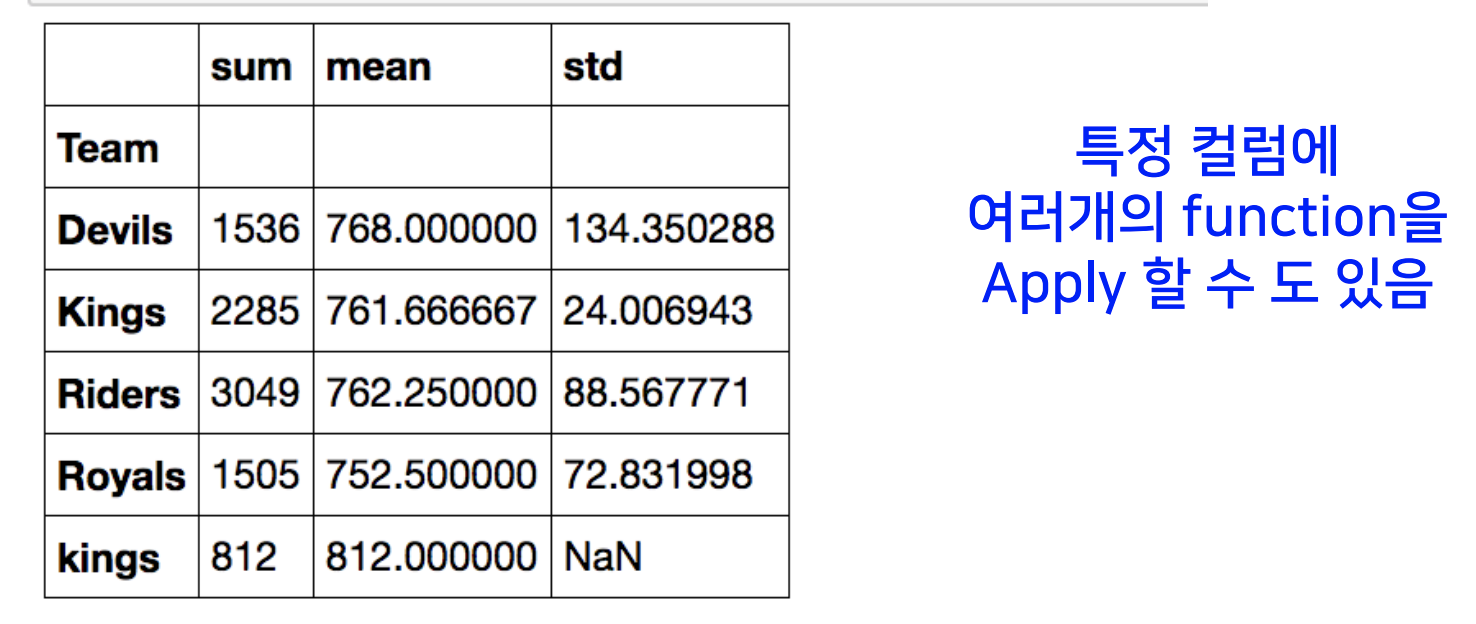
- group['points'].agg([np.sum, np.mean, np.std])
- grouby - transformation
- score = lamda x : (x.max())
grouped.transform(score) - 콜롬별로 모든값에 동일한 연산을 적용시킬수 있음.
grouby - filter
- 특정 조건으로 데이터를 검색할떄 사용가능.
- df.grouby('team').filter(lambda x: x["points"].sum()> 1000) 팀별로 포인트의 합이 100이상인지 확인해 보아라 .
case study
직접 테스트해보자
이 사이트 들어가면 데이터 다운 받을수 잇음.
https://www.shanelynn.ie/wp-content/uploads/2015/06/phone_data.csv
= pd.read_csv("파일경로/phone_data.csv")해주면 됨.
df_phone.head() 하면 파일 보임. import pandas as pd
df_hoylee = pd.read_csv("phone_data.csv")
df_hoylee.head()
df_hoylee.dtypes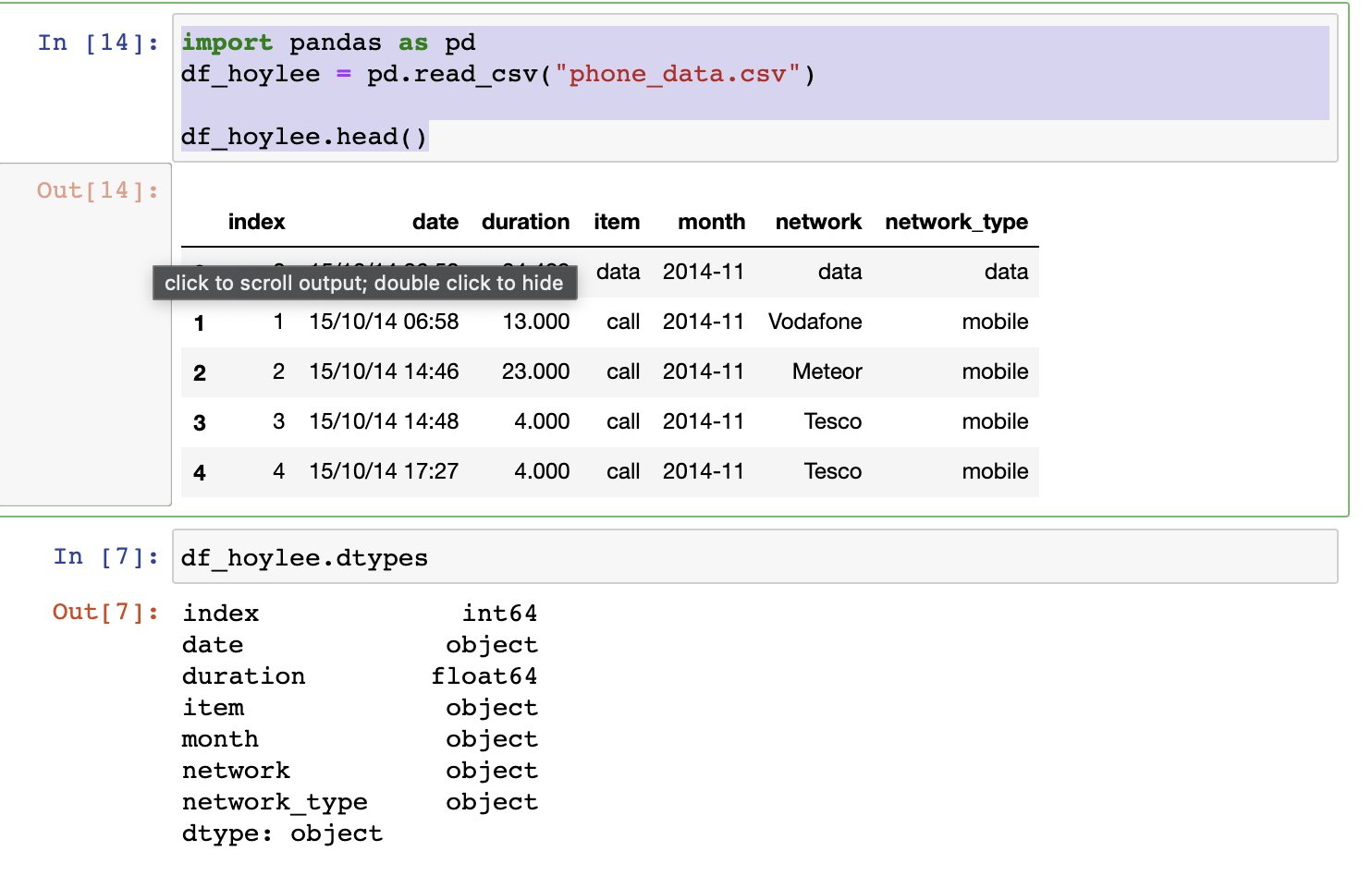
- 데이터 프레임을 불러와서 프레임 요소들의 타입을 찍어봄.
데이터 프레임의 데이터 형식을 바꿔볼수 있음import dateutil df_hoylee["date"] = df_hoylee["date"].apply(dateutil.parser.parse, dayfirst=True) df_hoylee.dtypes
dateutil.parser.parse 데이터형식 시간 타입으로 변경
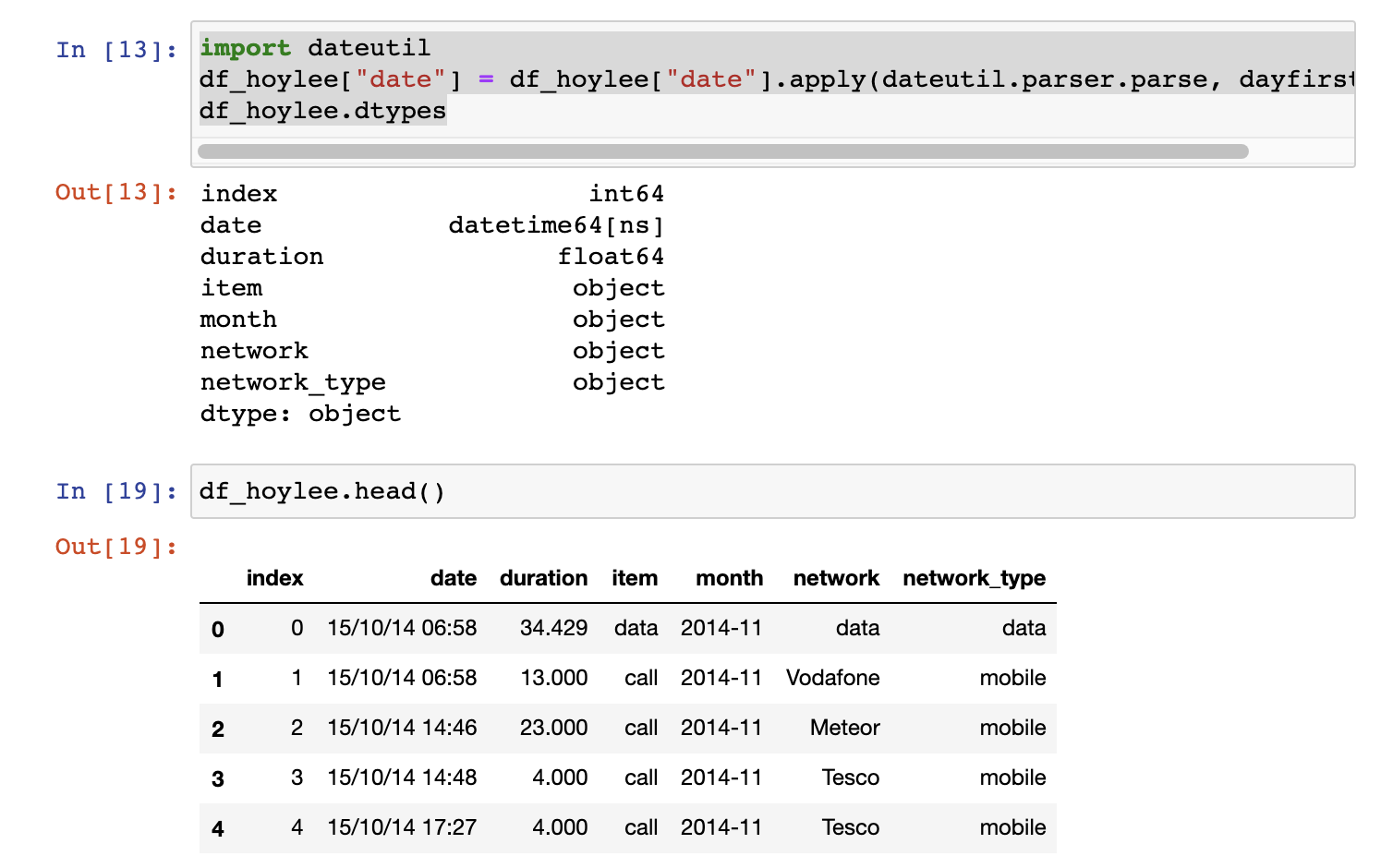
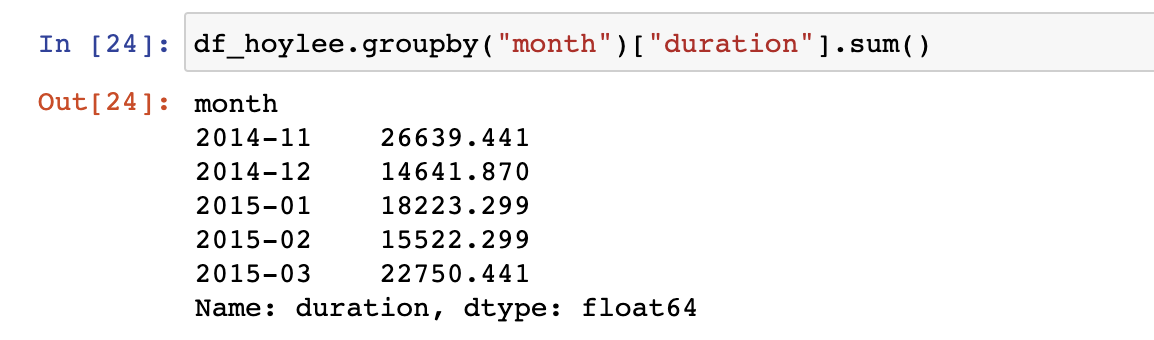
1. 이런식으로 데이터를 달 별로 끊어서 볼수 있고list(df_hoylee.groupby("month")) df_hoylee.groupby("month")["duration"].sum() df_hoylee.groupby("month")["duration"].sum().plot()
- 달 별로 끊어진 데이터중 duration의 합들을 더해 출력할수도 잇음.
- 그래프로도 그릴수 잇음.
- 그래프로도 그릴수 잇음.
df_hoylee.groupby(["month","item"])["duration"].count()
df_hoylee.groupby(["month","item"])["duration"].count().unstack()이런 식으로도 해볼수 있고,
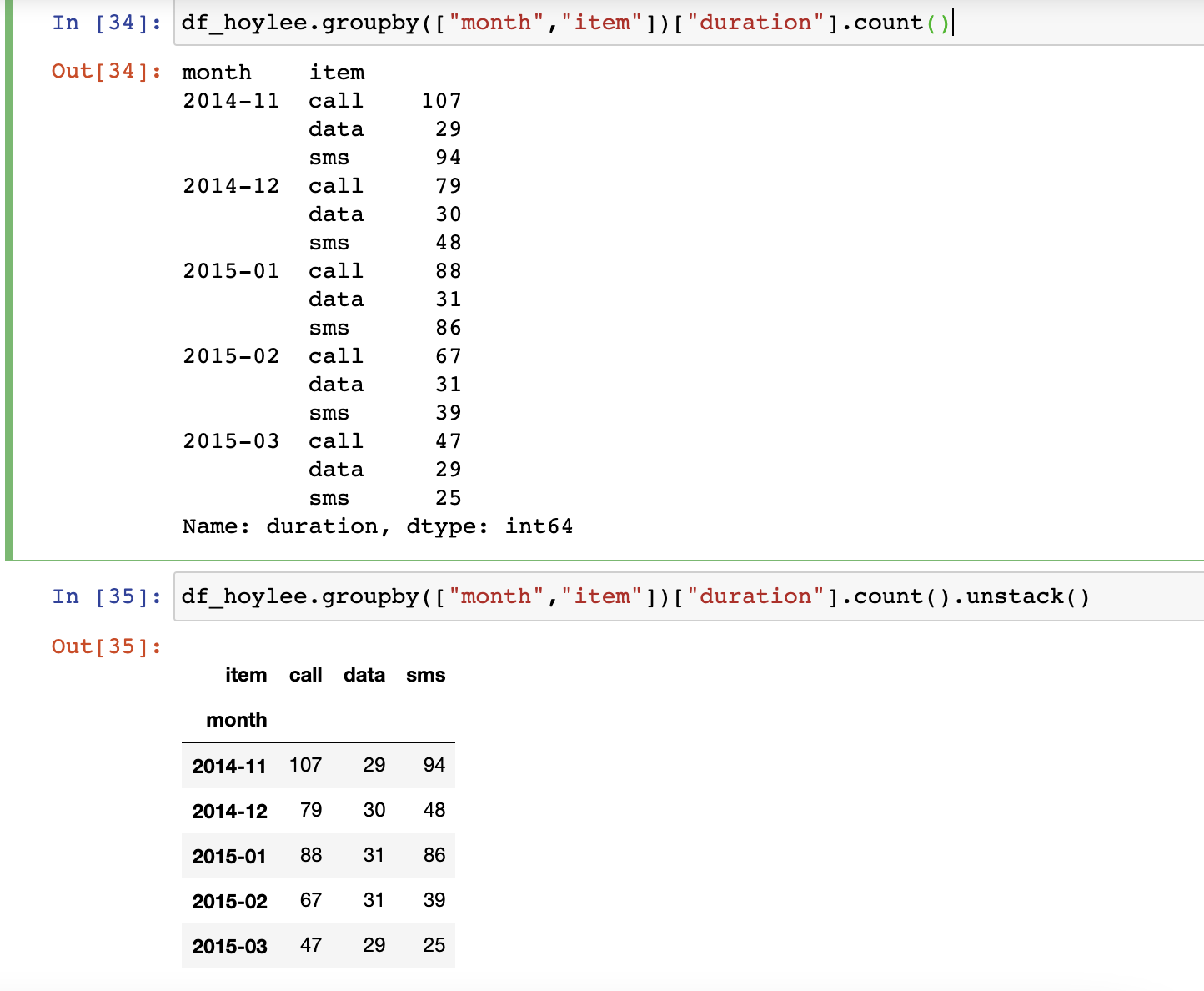
df_hoylee.groupby("month").agg({"duration":"sum"})
df_hoylee.groupby("month", as_index=False).agg({"duration":"sum"})month를 인덱스로 쓰지 않을수 도 있다.
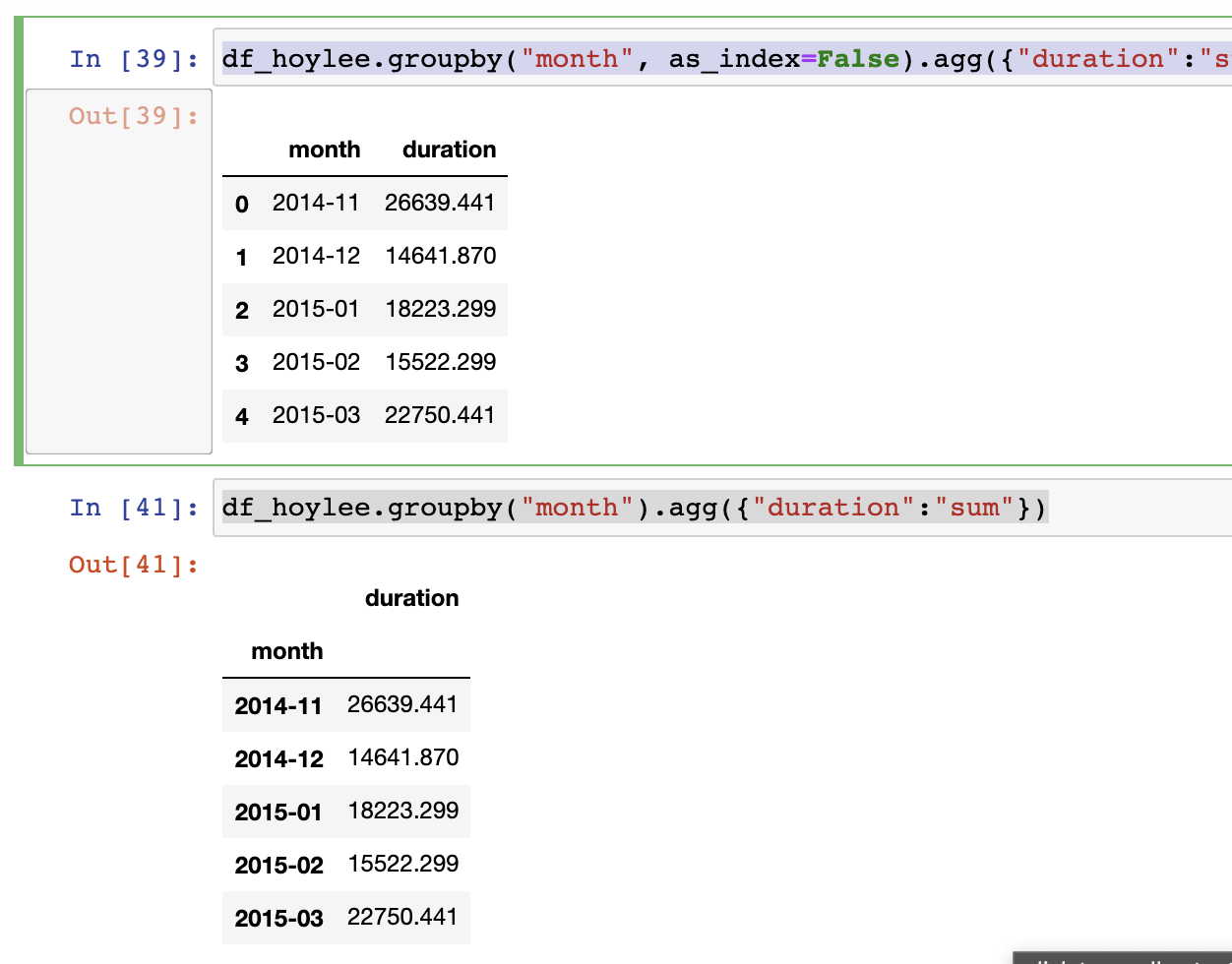
df_hoylee.groupby(["month", "item"]).agg({"duration":"sum","network_type":"count","date": "first"})이런 식으로 좀더 다채롭게 활용도 가능하다.
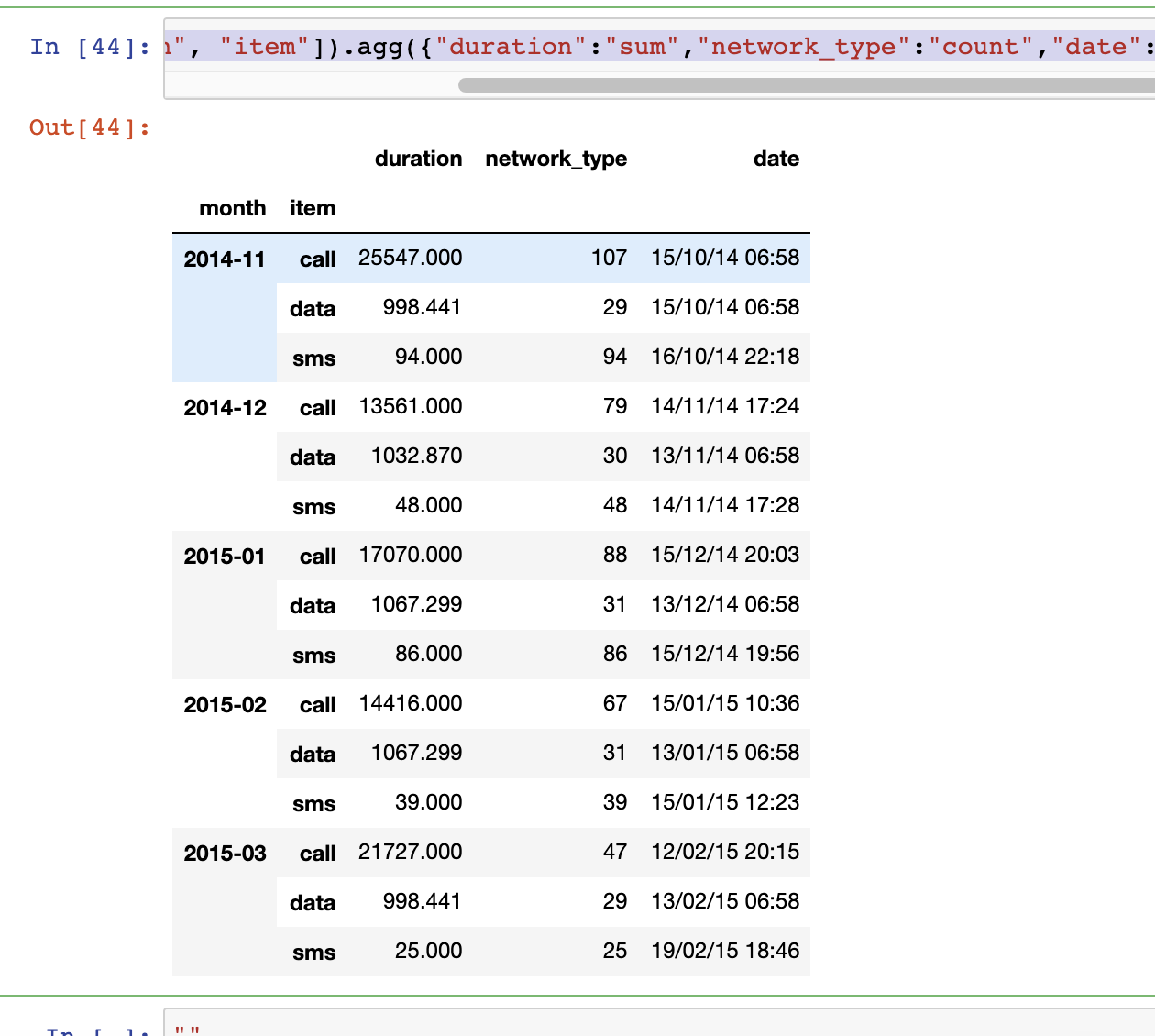
df_hoylee.groupby(["month", "item"]).agg({"duration":[min, max, np.mean]})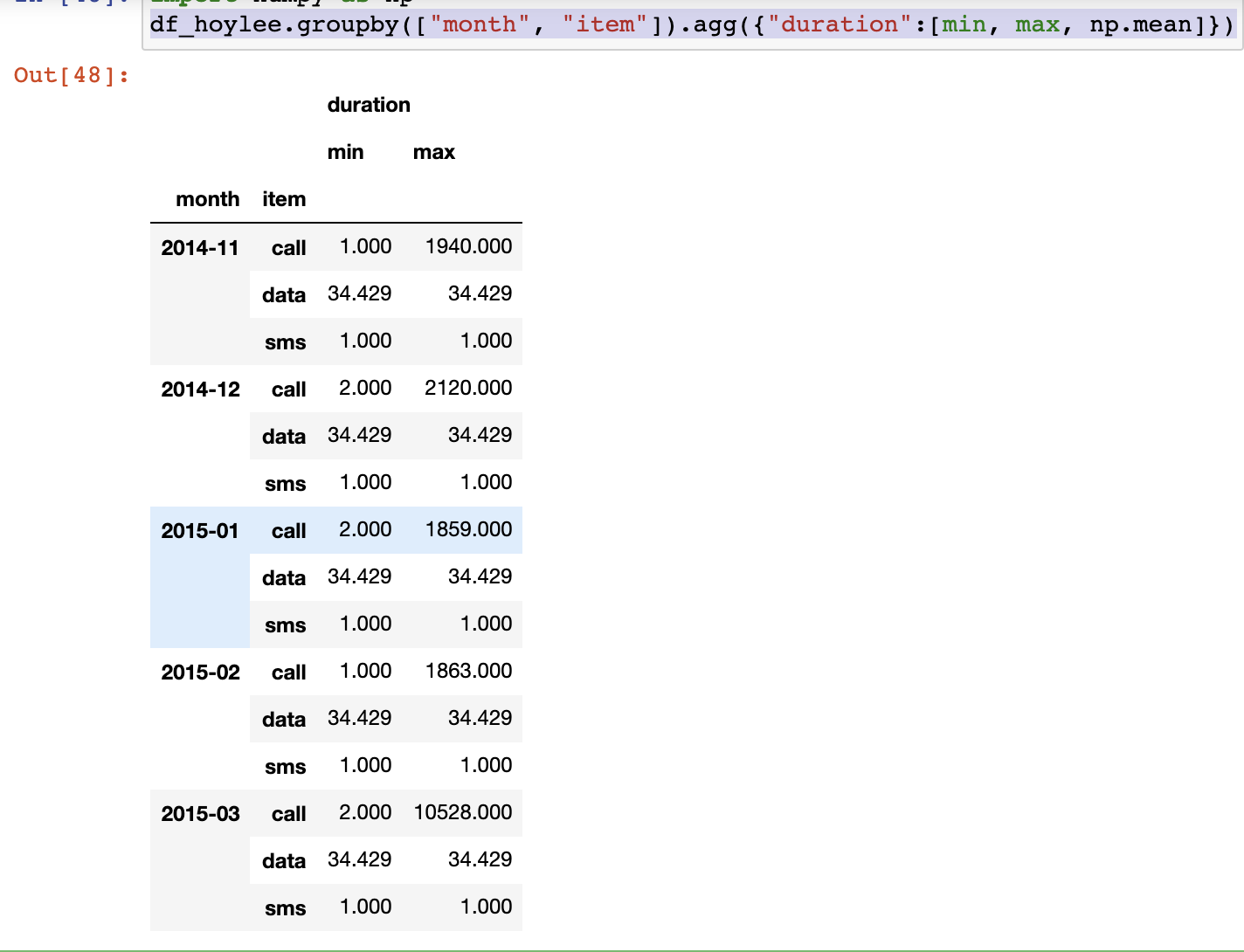
test.add_prefix("duration")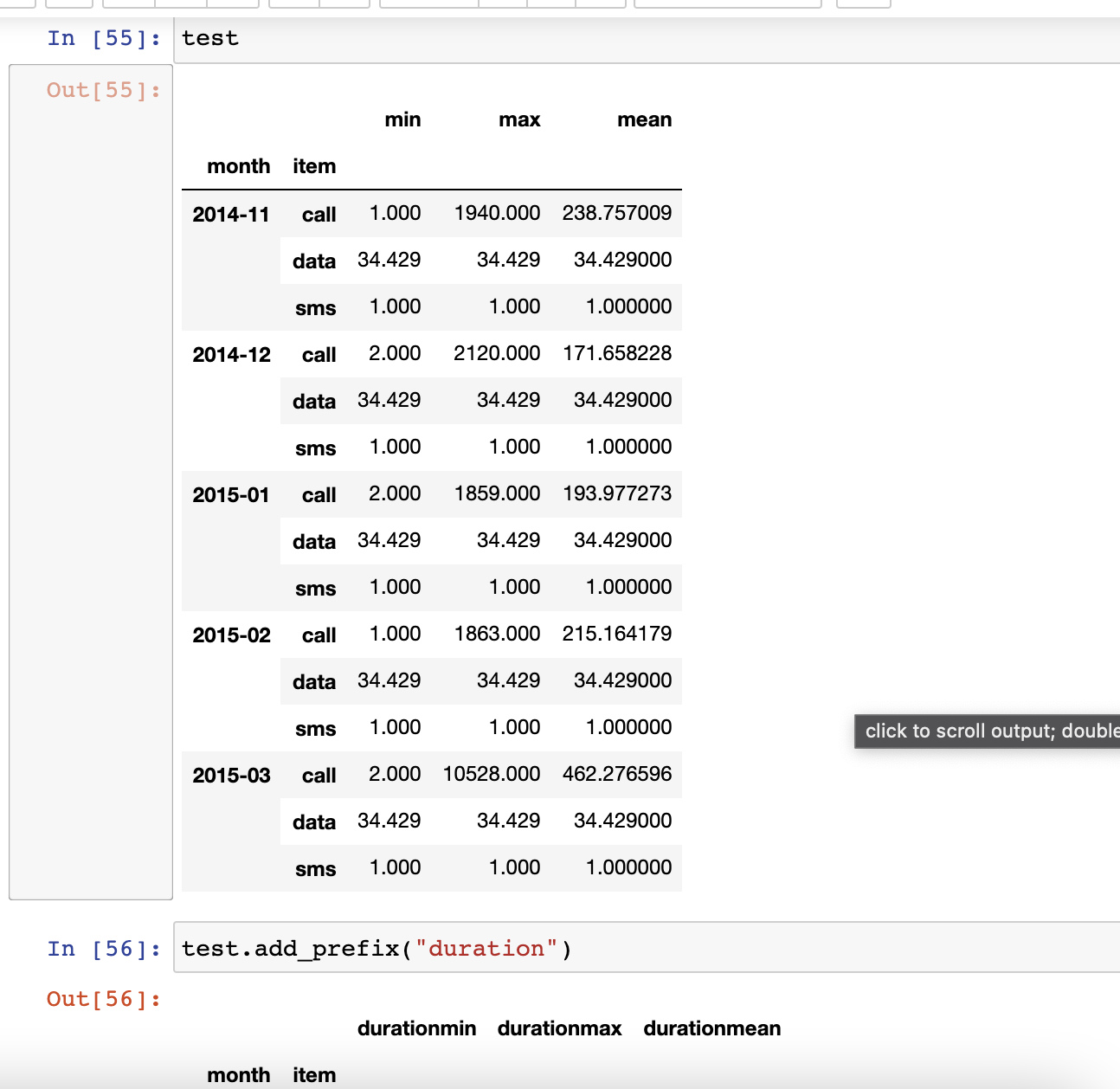
pivot Tavle
- excelㅔ서 보는 것과 동일
- index축은 grouby와 동일
- column에 추가로 labeling값을 추가
- value에 numeric type 값을 aggregation하는 형태
예제
1장에서 했던거 처럼 pd_hoylee라는 곳에, csv파일을 넣고, date만 파일 타입을 바꿔준다.
df_hoylee['date'] = df_hoylee['date'].apply(dateutil.parser.parse, dayfirst=True)df_hoylee.pivot_table(["duration"], index=[df_hoylee.month, df_hoylee.item], columns=df_hoylee.network, aggfunc="sum", fill_value=0)
df_hoylee.groupby(["month", "item", "network"])["duration"].sum().unstack()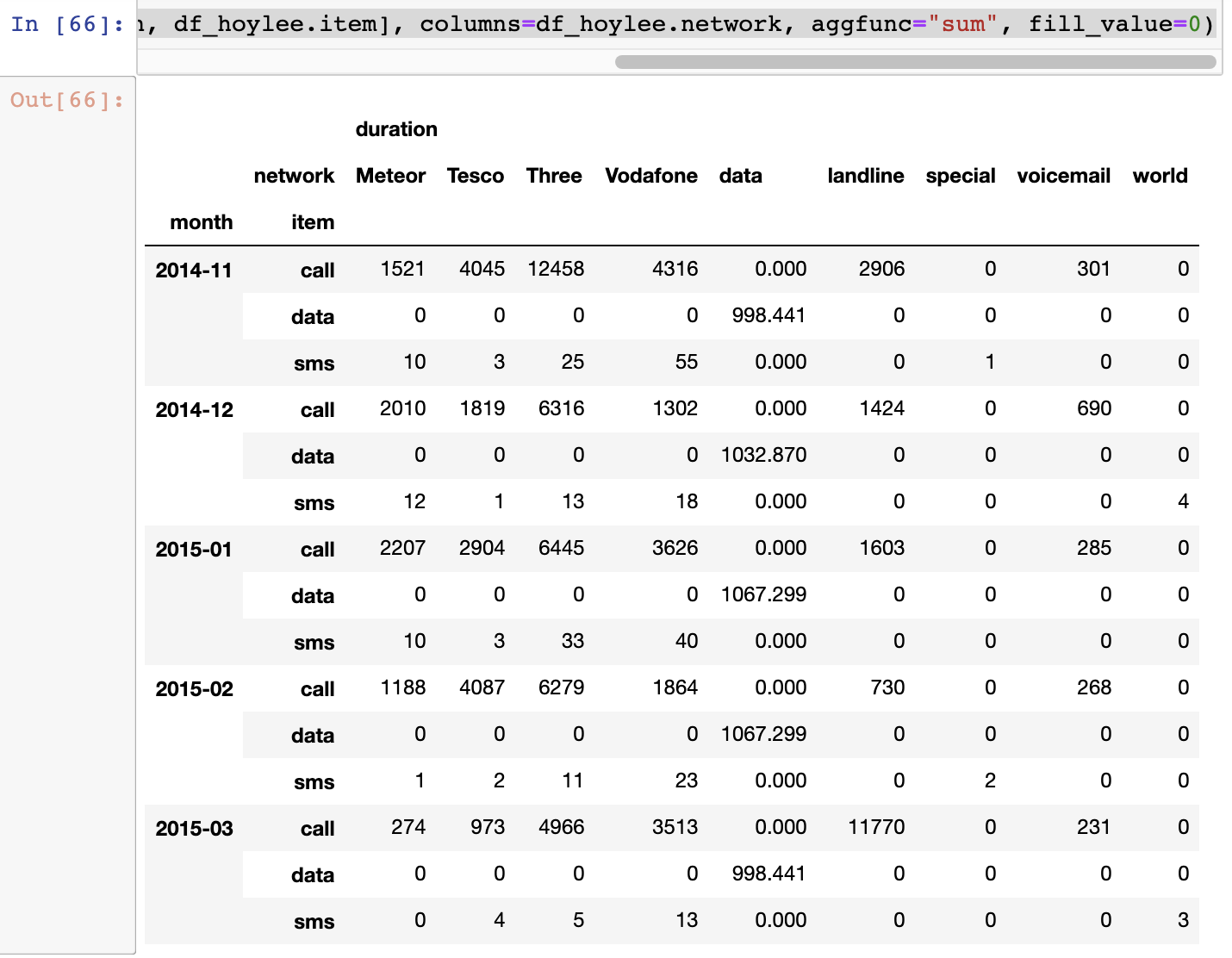
원하데로 행 열을 생성하고, 값들을 나열할수 잇따. fill_value는 값이 안들어 가는 곳에는 0 을채워넣는다는 말.
두번쨰 방법으로 해도 된다. 첫번쨰 방법이 좀더 직관적?
crosstab
- 특허 두 칼럼에 교차 빈도, 비율, 덧셈 등을 구할 때 사용
- Pivot table의 특수한 형태
- User-Item Rating Matrix 등을 만들 때 사용가능함
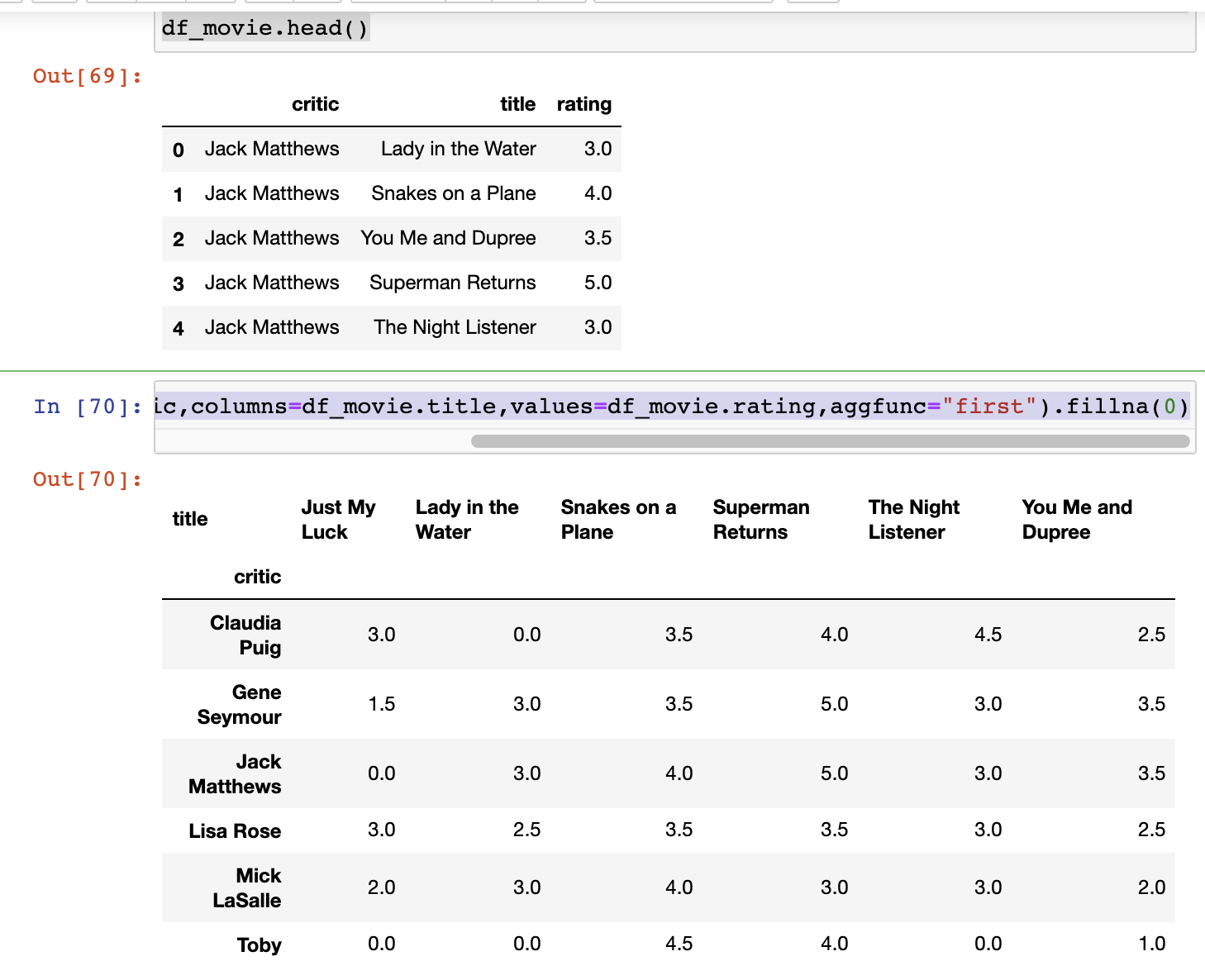
df_movie = pd.read_csv("movie_rating.csv")
df_movie.head()pd.crosstab(index=df_movie.critic,columns=df_movie.title,values=df_movie.rating,aggfunc="first").fillna(0)똑같이 행렬 선언하고, 사용할수 있음 pivot이나, crosstab이나 비슷하게 행렬 만들수 있다.
merge & concat
- 두개의 데이터를 하나로 합침.
- on='subject_id' 이런식으로 원하는 부분을 선택하면, 그 열에 일치하는 것들끼리 합칠수 잇음.
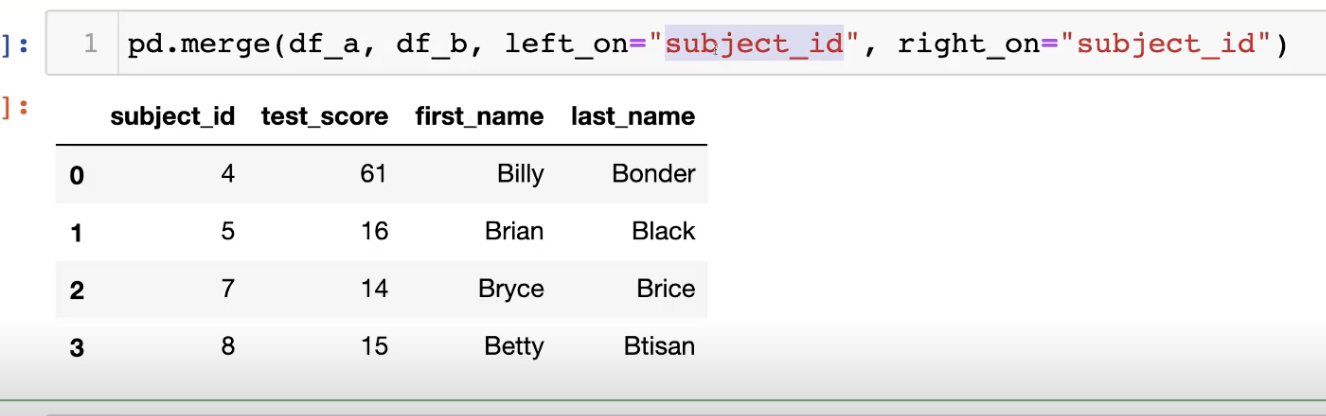
- 비교하고 싶은 열의 이름이 다르면 ,left on right on 을 사용하는데
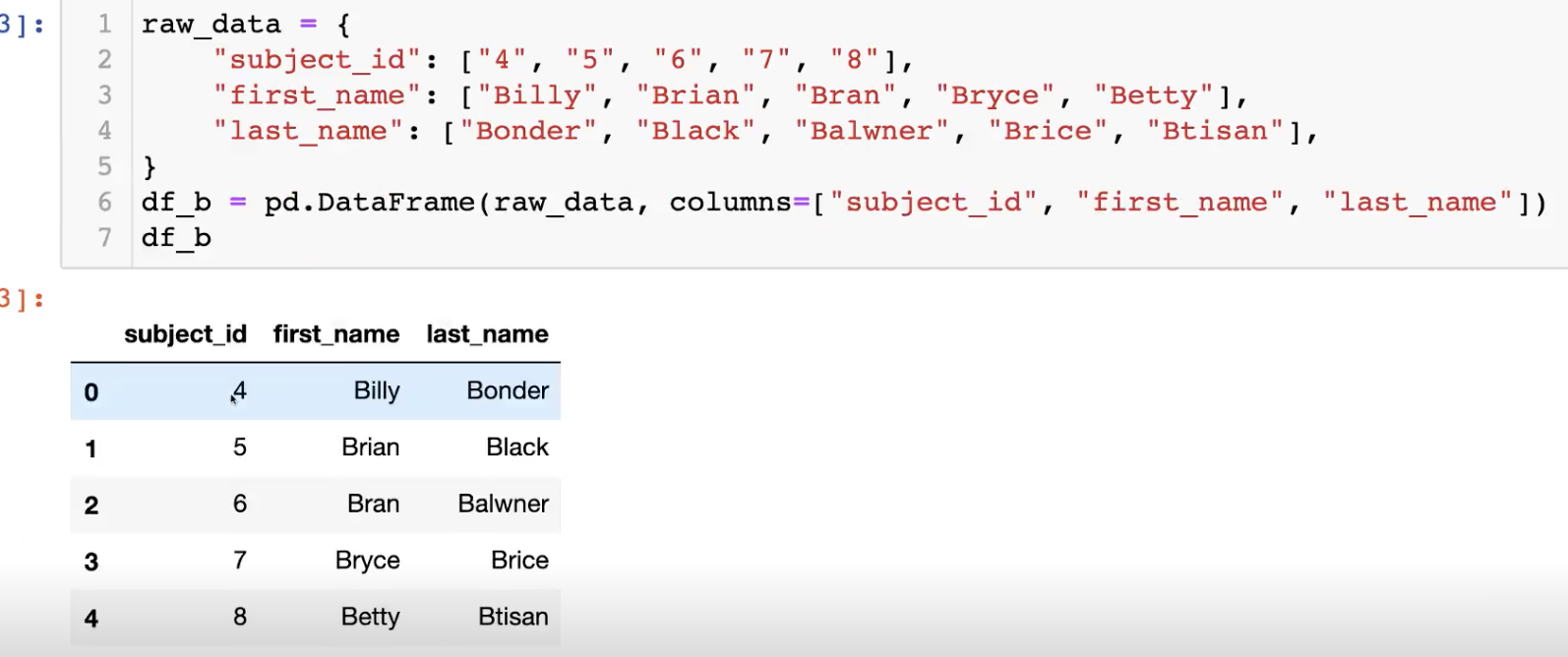
우선 데이터를 생성
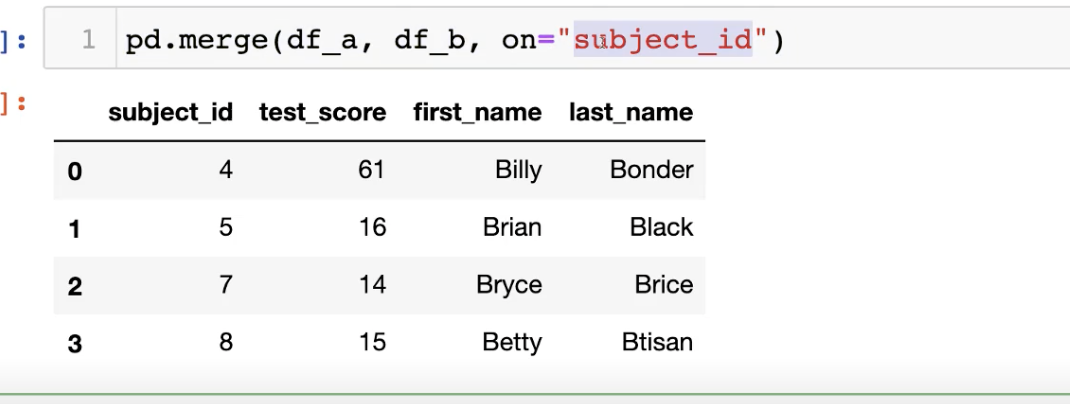
- merge 를 이용해서 원하는 기준으로 두 데이터 프레임을 합칠수 잇고,
- 합치고 싶은 데이터 열들의 이름이 다르면 레프트 언 라이트 언을 쓴다
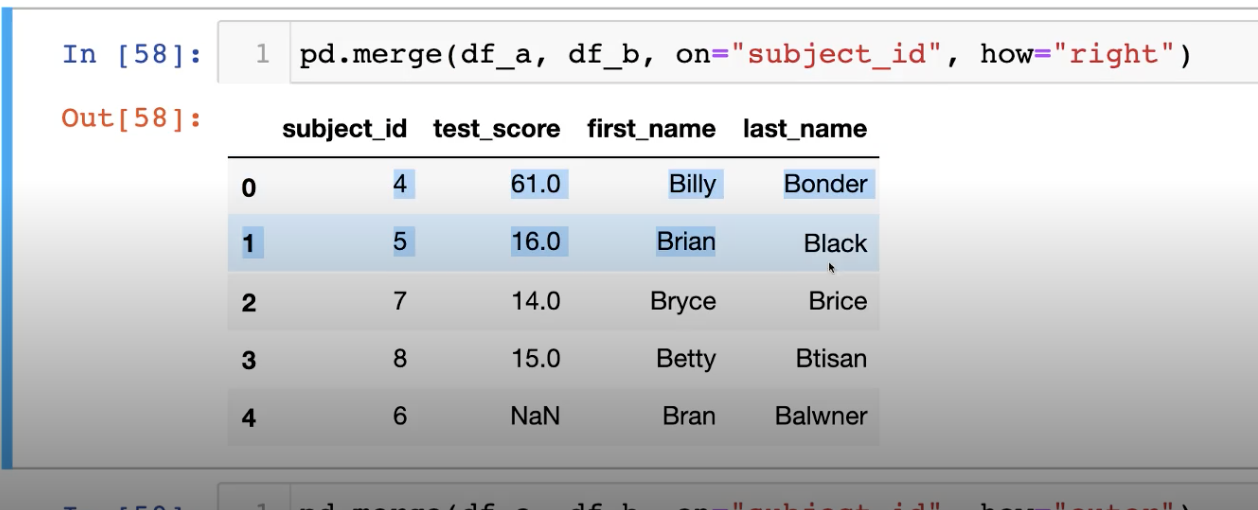
- how를 사용해서 데이터를 붙일때 어느데이터를 기준으로 할건지 정할수 도 잇다. (left, outer도 들어 갈수 잇음.)
concat
- 데이터 값을 붙이는것.
- df.new = pd.concat([df_a,df_b])
- df_new.reset_index(drop=False)
- df.new = pd.concat([df_a,df_b],axis =1)
import os
files = [file_name for file_name in os.listdir("./big-data-tutorial/data") if file_name.endswith("csv")]
filesdf_list = [os.path.join("data",df_filename) for df_filename in files]
df_list = [pd.read_csv(os.path.join("data",df_filename)) for df_filename in files]save = pd.concat(df_list[0:])persistence
- data loading 시db connetion 기능을 제공함. (sqlite3)
!conda install --y Xlsxwriter엑셀 파일 쓸떄 필요한 코드
29 분 쯤 부터 데이터를 서버 와 연결하고 파일 저장하는거 나옴.
확률론 맛보기
강의 소개
딥러닝의 기본 바탕이되는 확률론에 대해 소개합니다.
확률분포, 조건부확률, 기대값의 개념과 몬테카를로 샘플링 방법을 설명합니다.
데이터의 초상화로써 확률분포가 가지는 의미와 이에 따라 분류될 수 있는 이산확률변수, 연속확률변수의 차이점에 대해 설명합니다.
확률변수, 조건부확률, 기대값 등은 확률론의 매우 기초적인 내용이며 이를 정확히 이해하셔야 바로 다음 강의에서 배우실 통계학으로 이어질 수 있습니다. 기대값을 계산하는 방법, 특히 확률분포를 모를 때 몬테카를로 방법을 통해 기댓값을 계산하는 방법 등은 머신러닝에서 매우 빈번하게 사용되므로 충분히 공부하시고 넘어가시기 바랍니다.
딥러닝에서 확률론이 왜 필요한가?
• 딥러닝은 확률론 기반의 기계학습이론에 바탕을 두고 있습니다
• 기계 학습에서 사용되는 손실함수(lossfunction)들의 작동원리는 데이터 공간을 통계적으로 해석해서 유도하게 됩니다
• 딥러닝은 확률론 기반의 기계학습이론에 바탕을 두고 있습니다
• 기계학습에서 사용되는 사용되는 노름은 예측 오차의 분산을 가장 최소화하는 방향으로 학습하도록 유도합니다
• 분류문제에서 사용되는 교차엔트로피(cross-entropy)는 모델예측의 불확
실성을 최소화하는 방향으로 학습하도록 유도합니다
• 분산 및 불확실성을 최소화하기 위해서는 측정하는 방법을 알아야합니다
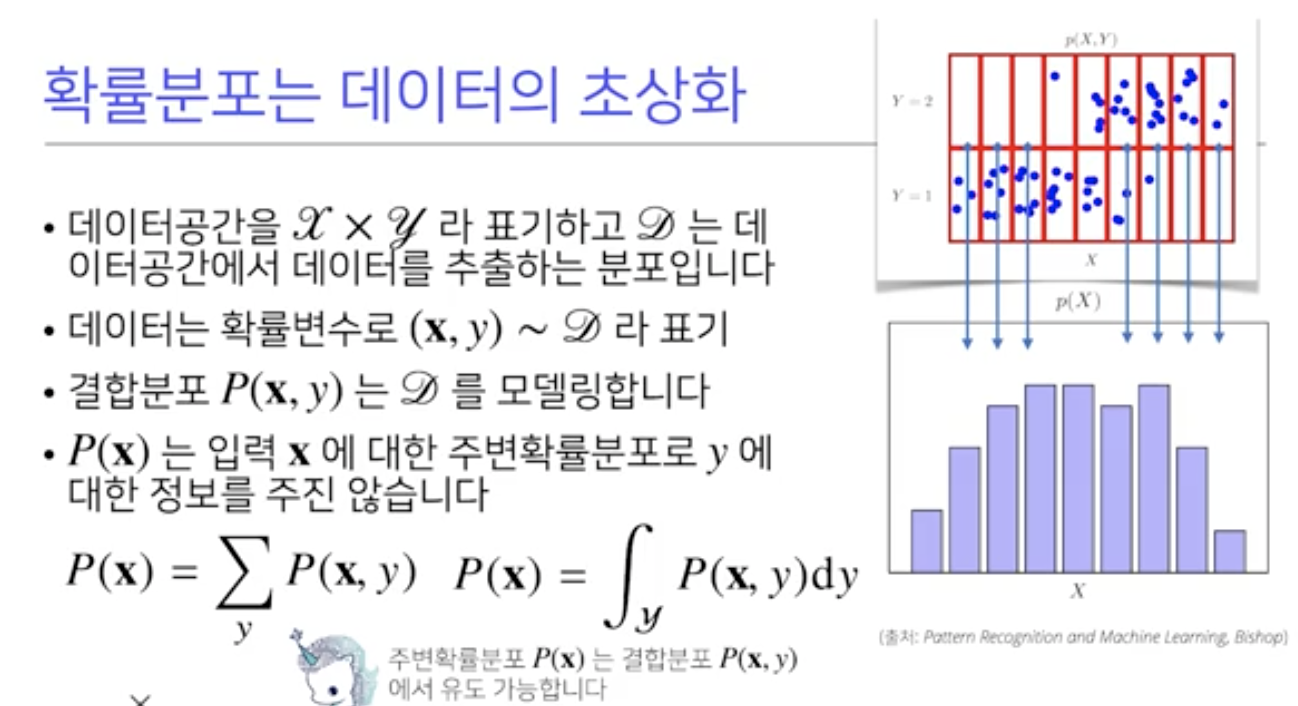
확률분포는데이터의초상화
- 데이터공간을 라표기하고 는 데이터 공간에서 데이터를 추출하는 분포입니다
• 데이터는확률변수로 (x,y)~D 라표기
이산확률 변수 vs연속확률 변수
• 확률변수는확률분포 D 에 따라 이산형(discrete)과 연속형(continuous)
확률 변수로 구분하게됩니다
- 데이터 공간이 정수 집합이라고 한다면 이산형이라고 하겟지만, 실수라고 무조건 연속형이라할수 없다. 예를 들어 0.5,-0.5이 중에서 하나를 선택한다면 이산형이라 할수 잇따.
- 아직 확신은 아니지만, 이산형은 주어진 값중 골라질 확률이고, 연속형은 주어진 범위중 나올 확률이다.
- 이산형 확률 변수는 확률 변수가 가질 수 있는 경우의 수를 모두 고려하여 확률을 더해서 모델링한다 확률 질량함수,
- 연속형 확률 변수는 데이터 공간에 정의 된 확률 변수의 밀도(density)위에서의 적분을 통해 모델링한다

- 모든 확률변수가 이산형과 연속형으로 이루어진건 아니다. 우리가 배울건 대부분 이산형 연속형...
확률분포는 데이터의 초상화
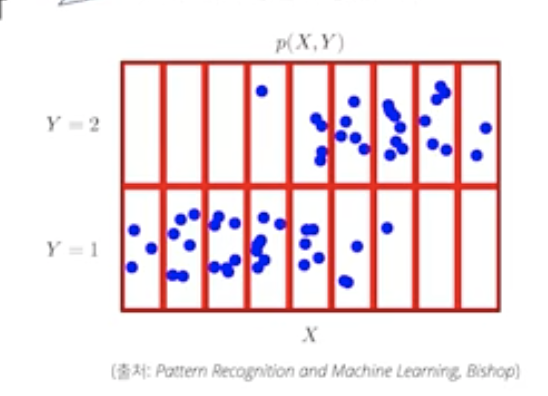
-
빨간 색 칸막이가 없다고 생각하면, 연속형의 확률변수 처럼 생각이 들지만, 빨간 칸으로 나누어서 본다고 가정하면, 빨간색 한칸에 몇개의 파란점이 있는지를 통해, 이산형으로 볼수도 잇다.
-
• 데이터 공간을 X*Y라표기하고 D는 데이터공간에서 데이터를 추출하는 분포입니다
-
데이터는 확률변수로 (x,y)~D라 표기
-
결합분포 P(x,y)는 원래 확률분포 D를 모델링합니다.
-
이떄 주의할점은 원래 확률분포 D가 이산이나 연속이나에 따라서 결합분포p(x,y)의 분포를 연속이냐 이산이냐 정하는게 아니고, 원래 확률분포에 상관없이 결합분포를 연속형이나 이산형으로 사용해 볼수 잇따.
-
결합분포p(x,y)를 입력 x에 대한 주변확률 분포로 y에 대해 적분해 P(x)로 만들어 줄수 잇따.
-
사진을 보면, x에 대해 확률이분포 되었지만, y에 대한 정보가 없어졌다는걸 볼수 잇따. 반대로 y에 대한 주변확률분포도 만들 수 있다.
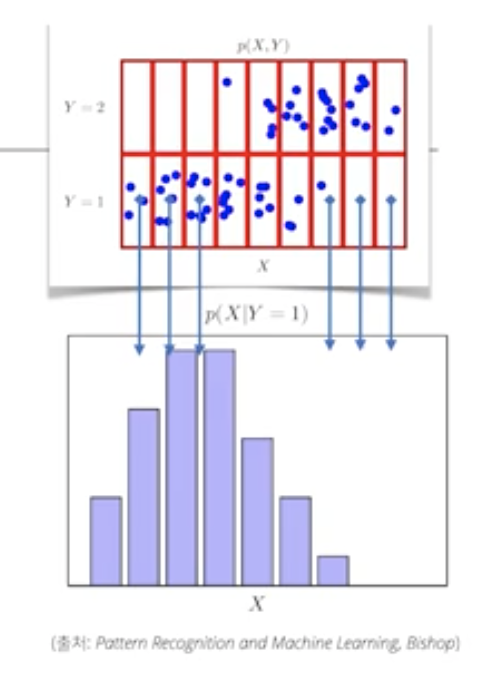
-
사진을 보면, 아까랑 다르게, p(X|Y=1)이라는 식이 생겻는데, 이를 조건부 확률 분포라 하며, Y가 1일떄의 점들에 대한 주변확률 분포를 만들어 볼수도 있다.
-
우리가 관심을 가지는 방향에 따라 대이터 초상화를 그릴수 잇고, 데이터 분석하는데 도움을 준다는 걸 기억하자.
조건부 확률과 기계학습.
- 방금 전까지 보았던, p(x|y) 을 해석하면, 입력변수 y에 대해 정답이 x일 확률
- 주의)결과가 이산형은 확률로 나오지만 연속형은 밀도로 나옴.
- 로지스틱 회귀 분류문제에서softmax(WX + b) 를 데이터 x로 부터 추출된 특징패턴 X와 가중치 행렬 W을 통해 조건부확률 p(y|x)로 계산할수도 있다. 같은거라니..
- 회귀문제의 경우 연속확률 변수로 다루기 떄문에 밀도 함수로 다루어야한다. 조건부 기댓값 E[y|x]로 구함


기대값이 뭔가ㄴ요?
- 평균!
- 확률 분포가 주어지면 데이터를 분석하는데 사용 가능한 여러 종류의 통계적범함수(statisticalfunctional)를 계산 할 수 있습니다
- • 기대값(expectation)은 데이터를 대표하는 통계량 이면서 동시에 확률분포를 통해 다른 통계적범함수를 계산하는데 사용됩니다
몬테칼를로 샘플링
- 함수가 이산형이든 연속형이든 몬테칼로가능
- 확률분포를 모를떄 데이터를 이용하여 기대값을 계산하려면, 몬테칼를로 샘플링 방법으 사용해야한다.
- 몬테카를로 샘플링은 독립추출만 보장된다면, 대수의 법칙에 의해 수렴성을 보장한다

