

Instruction
- CPU가 동작하게하는 명령어
- 하드웨어와 소프트웨어간의 인터페이스(채널, 창구, 언어)

Opcode : 명령어의 종류를 표현하는 부분
Operand : 피연산자
트랜지스터 속 $2의 자리에 $2의 값과 $4의 값을 더해서 집어넣어라
Instruction Set
Instruction Set Architecture (ISA)
- 일반적으로 소프트웨어가 컴퓨터 또는 컴퓨터 계열의 CPU를 제어하는 방식을 정의하는 추상적인 모델.
- ISA는 명령어, 데이터 유형, 레지스터, 메모리 및 I/O 모델을 위한 하드웨어 지원을 정의함.
- ISA는 컴퓨터 프로세서가 이해하고 실행할 수 있는 명령어 집합을 의미함
- ISA(명령어 집합 아키텍처)는 컴퓨터가 지원해야 하는 기본 작업의 관점에서 컴퓨터의 설계를 설명합니다. 이는 오직 컴퓨터가 지원해야 하는 기본 작업의 집합이나 컬렉션에만 관심을 둡니다.
- 하드웨어와 가장 낮은 수준의 소프트웨어 간의 인터페이스
- CPU에 레지스터가 32개가 필요하다면, 이를 효율적으로 만들기위한 회사만의 비법이 있을거임
- Instruction 뿐만
명령어 집합은 다른 프로세서 간에 유사함
- 유사한 하드웨어 기술
- 유사한 기본 원리
- 모든 컴퓨터가 제공해야 하는 공통적인 기능 집합
- 인기 있는 명령어 집합 등
Microarchitecture
특정 설계 제약 및 목표하에 이루어지는 ISA의 구현 (구현적인 기술)
ISA의 사양을 충족하는 한, 다양한 구현(마이크로아키텍처, μarch)이 가능합니다.
• x86 ISA 다양한 구현을 가짐: 286, 386, 486, Pentium, Pentium Pro, Pentium 4, Core, …
소프트웨어에 노출되지 않고 하드웨어에서 수행되는 것들
- Pipelining(파이프라이닝)
- peculative execution (예측,추측 실행)
- Memory access scheduling (메모리 접근 스케줄링)
Microarchitecture는 회사마다 다양한 방법이 있을 수 있다
CISC VS RISC (55')
http://www.jidum.com/jidums/view.do?jidumId=401
CISC (Complex Instruction Set Computer)
- 오래된 설계 개념이다
- (다중 클럭) 복잡하고 가변적인 길이의 명령어
- ISA 내에서 많고 강력한 명령어를 지원한다
Ex) LOAD와 STORE 명령어가 다른 명령어에 통합됨
장점
- 어셈블리 프로그래밍을 쉽게 만들 수 있음(명령어가 강력하기 때문)
- 컴파일러가 더 단순해짐
- 명령어 메모리 사용량이 감소함
단점
- CPU 디자인이 더 어려워짐
- 명령어가 무거워지고 복잡해짐
Designing CPU is much harder
과거의 접근방식
- 새로운 요구에 맞춰 새로운 명령어를 추가하자
→ 새로운 관점 등장: 명령어는 작고 단순하게 유지하고, 복잡한 작업은 소프트웨어에서 처리하자
RISC (Reduced Instruction Set Computer)
- CISC의 새로운 컨셉
- Simple, standardized instructions
- ARM, MIPS, POWER, RISC-V
- Small instruction set, CISC type operation becomes a chain of RISC operations
이전에 CISC에서 제공햇던 강력한 명령어 대신 여러 스텝을 거쳐 많은 명령어들을 많이 불르는 방식으로 바꿈,
자잘한걸 많이 호출해야하지만 그러나 일관적이고 간단하므로 ㄱㅊㄱㅊ
장점
- CPU 디자인이 쉬워짐
- 작은 명령어 집합 => CLOCK SPEED가 빨라짐
단점
- Assembly language typically longer (compiler design issue)
- Heavy use of memory
Most modern x86 processors are implemented using RISC techniques

CISC의 접근법: IC을 줄일려고함
RISC의 접근법: CPI를 줄일려고함
RISC-V (RISC Version 5)
RISV-V : RISC 원칙에 기반한 오픈 스탠다드 ISA이다
- 완전한 오픈 ISA로, 학계와 산업계에 자유롭게 제공됩니다.
- RISC-V는 80x86 ISA보다 더 간단하고 우아한 설계를 가지고 있습니다.
- 빠르게 채택되고 있습니다
Arithmetic Operation (산술연산)
-
Simplicity favors regularity
- 회로제작이 더 쉬워진다
- 잠재적인 수행능력에서 이득을 본다 -
C code: f = (g + h) - (i + j); -
Compiled Assembly code:- add t0, g, h # temp t0 = g + h
- add t1, i, j # temp t1 = i + j
- sub f, t0, t1 # f = t0 - t1
Register Operands (레지스터 연산)
- 레지스터(Register)란
-
레지스터는 CPU 내부에 있는 작은 메모리 공간으로, 매우 빠른 속도로 데이터를 저장하고 처리할 수 있습니다.
-
레지스터는 주로 연산을 위해 자주 사용되는 데이터를 저장하거나, 메모리 접근보다 빠른 데이터 접근을 가능하게 합니다
- 레지스터 연산의 특징
-
Operands of arithmetic instructions must be registers
(산술연산의 대상은 반드시 레지스터(안의 데이터)여야 한다. 레지스터의 크기는 보통 32비트) -
RISC-V의 레지스터 크기 : 64 bits (doubleword)
- Number of registers: 32

Memory Operand (메모리 연산)
1. Meomory Operand란?
► 레지스터가 아닌 메모리에 저장된 데이터를 피연산자로 사용하는 경우를 의미
► CPU는 메모리 주소를 참조하여 메모리에 있는 데이터를 읽어와 레지스터에서 연산한다
Q. 왜 메모리 연산이 필요한가요?
A. 레지스터는 한정되어있으나, 데이터는 보통 매우 크기에 메모리에 데이터를 저장해놓고 갖고와야하는 경우가 생김 (연산 자체는 레지스터 상에서만 일어남!!!)
2. Memory Operand에서 사용 되는 명령어
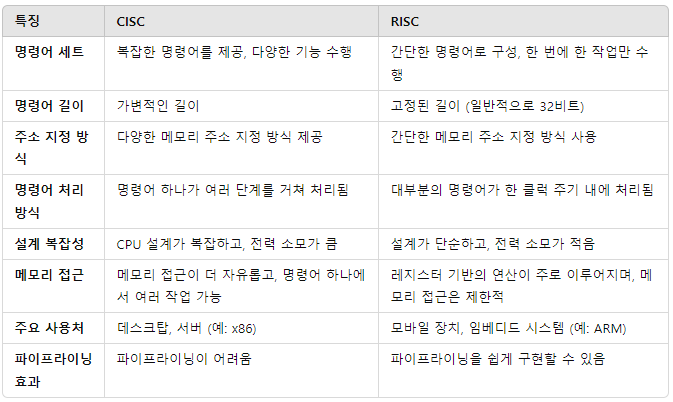
- loading instruction : 메모리에서 데이터를 CPU 내부 레지스터로 가져오는 명령어
•ld: load double word
• format:ld x2, 16(x3):x3메모리에서 16바이트 떨어진 메모리의 값을 읽어 x2에 저장해라
•address공간의 주소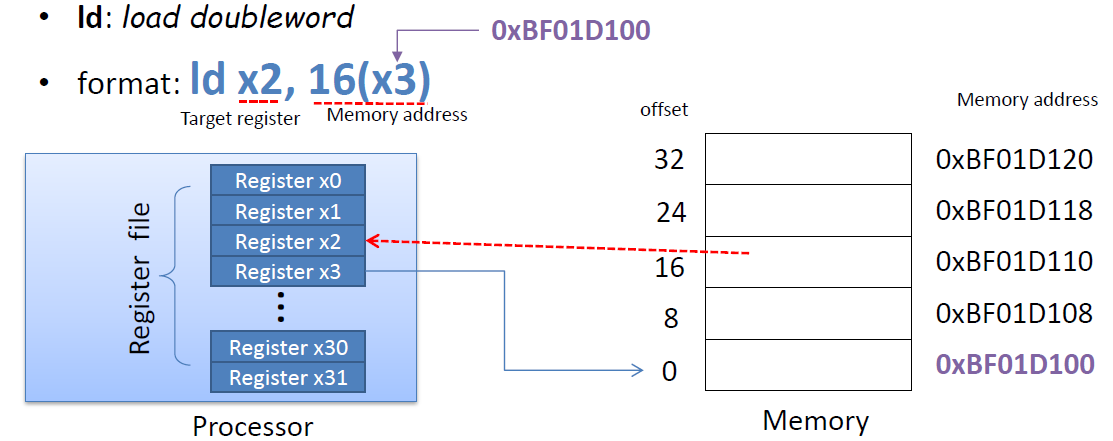
- store instruction : 레지스터의 값을 메모리에 저장하는 명령.
•sd: store double word
• format:sd x9, 96(x22):
►x9레지스터에 있는 값을x22레지스터에 저장된 메모리 주소에 96바이트 더한 위치에 저장하라는 명령어.
Ex) 배열 A의 기초 주소(base address)는 레지스터 x22에 들어있고, 변수 h는 레지스터 x21에 들어 있습니다.
[C code]:
A[12] = h + A[8];- 배열 A에서 12번째 위치에 있는 요소에 값을 저장합니다.
- 저장할 값은 변수 h에 있는 값과 배열 A의 8번째 위치에 있는 값을 더한 값입니다.
- doubleword가 디폴트이므로 한개는 8바이트이므로 a[12] = h (x21) + A[8] (64 가 된다
[Compiled RISC-V code]:
ld x9, 64(x22) // 배열 A의 base adress가 들어있는 x22 레지스터에서 64바이트 떨어진 위치에서 64비트 (doubleword의 크기)만큼 읽어 x9에 저장해라
add x9, x21, x9 //x21에 있는값 (h)와 x9에 있는값(A[8])을 더해서 x9에 저장해라
sd x9, 96(x22) //x9 레지스터에 있는 값을 x22 레지스터에 저장된 메모리 주소에 96바이트 더한 위치에 저장하라는 명령어. (A[12]이니 A의 base address에서 12*8 떨어진 곳) Memory Operand에 사용되는 명령어들은 레지스터에서 사용되는 add나 sub보다 수십배는 더 오래걸린다
물리적으로 CPU 밖으로 나가서 8바이트가 흘러들어와 저장이 되어야하기 때문
따라서 메모리로 가는 것은 최대한 피하는것이 좋다! (쩔수긴 함 ㅋ)
Endian
Big-endian vs Little-endian
Big-endian과Little-endian은 데이터를 메모리에 저장하는 두 가지 주요 방식입니다.
[Big-endian]
최상위 바이트(Most Significant Byte, MSB)가 가장 낮은 메모리 주소에 저장됩니다.
사람이 숫자를 읽는 방식과 비슷하게 큰 값이 앞에 오도록 정렬됩니다.
예를 들어, 32비트 숫자 0x1234ABCD을 Big-endian 방식으로 저장하면:
주소 0x1000: 12
주소 0x1001: 34
주소 0x1002: AB
주소 0x1003: CD
[Little-endian]
최하위 바이트(Least Significant Byte, LSB)가 가장 낮은 메모리 주소에 저장됩니다.
작은 값이 앞에 오도록 정렬됩니다.
동일한 32비트 숫자 0x1234ABCD을 Little-endian 방식으로 저장하면:
주소 0x1000: CD
주소 0x1001: AB
주소 0x1002: 34
주소 0x1003: 12
RISC-V에서는Little endian을 사용한다!
16진수의 한자리는 4비트를 가짐 (비트가 4개여야지 16개를 표현할 수 있기 때문)
1바이트는 8비트임 따라서 2자리수씩 끊는것 AB, CD,,,
Register VS Memory
-
Access speed- Register > Memory
-
Capacity- Register < Memory
-
Energy consumption- Register < Memory
그래서 자주 쓰이는 변수는 레지스터에 저장하는 것이 좋다
Spilling: 레지스터에 공간이 부족할 때 덜 자주 쓰이는 변수를 메모리로 옮기는것
Constant or Immediate Operands
- Arithmetic operation that uses a constant number
기존의 add명령어는 add x22, x22, x9 처럼 셋다 레지스터에서 갖고오는거라면
바로 4와 같은 상수(숫자)를 더하고 싶을 수도 있다.
그렇다면
var1: .dword 4 //어셈블리에서 변수 선언 . Var1은 변수명(주소이자 위치)을 의미 .dword 는 doubleword라는 타입, 4는 저장된 값(크기는 8바이트)
...
ld x9, var1(x3) # x3 + var1’s offset // x3이라는 base adress에다가 var1(4)이라는 offset을 더한 주소에서 값을 읽어 x9에다 저장해라
add x22, x22, x9► 이러한 연산은 로딩하는 과정에서 메모리를 들럿다와 매우 비효율적이다
따라서 immediate operand를 사용해서 즉시 연산 처리를 함
addi x22, x22, 4 // 상수 4가 메모리 안에 있는 값이 아님, 명령어 안의 비트의 빈공간에 숫자 4를 바로 넣은거임 (0100)▫ Immediate operand instructions are faster and use less energy
▫ 4 is included inside the instruction bits
Constant Zero
Register x0
- Special register hard-wired to have value 0
- Cannot be overwritten (modified)
Useful for common operations
- E.g., move data between registers
add x22, x21, x0 //x21의 값이 x22에 그대로 저장됨 (0이 더해졌기때문) - E.g., negate the value
sub x22, x0, x22 # x22 = -x22
Representing Instructions
RISC-V R-type
R-type 명령어의 특징:
- 연산 대상이 모두 레지스터에 있는 값을 사용합니다.
- 두 개의 소스 레지스터(rs1, rs2)와 하나의 목적지 레지스터(rd)를 사용하여 연산 결과를 저장합니다.
- 산술 연산(예: add, sub)과 논리 연산(예: and, or) 같은 레지스터 간 연산이 주로 사용됩니다.

비트별로 구역을 나누고 각 구역에 역할을 부여.
• opcode: Basic operation (연산의 종류를 알려줌)
• rd: destination register
• funct3: additional opcode
• rs1: 1st source register (5bits인 이유는 레지스터가 32개기 때문이다 (2^5)
• rs2: 2nd source register
• funct7: additional opcode

위 표에서 add와 sub의 opcode 는 동일한데, 이는 연산이라는 공통된 명령어라는 것을 의미
이후 funct7에서 추가적으로 각각 더하기와 빼기임을 구분을해준다.
원래는 fuct7과 funct3 그리고 opcode는 모두 합쳐져 opcode의 역할을 하지만
rs2, rs1, rd의 효율적인 배치를 따지다보니 하나의 역할이 세 토막으로 나뉘어진것이다.
예시로 보는 funct7의 중요성:
-
add 명령어:
opcode: 0110011
funct3: 000
funct7: 0000000 -
sub 명령어:
opcode: 0110011 (add와 동일)
funct3: 000 (add와 동일)
funct7: 0100000 (funct7을 통해 sub 연산이 구분됨)
예시로 보는 funct3의 중요성:
로드 명령어:
-
lb (load byte):
opcode: 0000011
funct3: 000 -
lh (load halfword):
opcode: 0000011
funct3: 001 -
lw (load word):
opcode: 0000011
funct3: 010
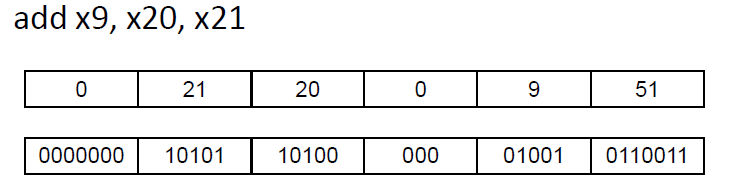
rs1 = x20
rs2 = x21
rd = x9
R-type 명령어의 종류
1. 논리 연산(Logical Operations)
and
or
xor
sll
2. 산술 연산(Arithmetic Operations)
ADD: add rd, rs1, rs2
rd = rs1 + rs2 (덧셈)
SUB: sub rd, rs1, rs2
rd = rs1 - rs2 (뺄셈)
MUL: mul rd, rs1, rs2
rd = rs1 * rs2 (정수 곱셈, M-extension에 해당)
DIV: div rd, rs1, rs2
rd = rs1 / rs2 (정수 나눗셈, M-extension에 해당)
-
비교 연산(Comparison Operations)
SLT: slt rd, rs1, rs2
rd = (rs1 < rs2) ? 1 : 0 (부호 있는 비교)
SLTU: sltu rd, rs1, rs2
rd = (rs1 < rs2) ? 1 : 0 (부호 없는 비교) -
시프트 연산(Shift Operations)
SLL: sll rd, rs1, rs2
rd = rs1 << rs2 (논리적 왼쪽 시프트)
SRL: srl rd, rs1, rs2
rd = rs1 >> rs2 (논리적 오른쪽 시프트)
SRA: sra rd, rs1, rs2
rd = rs1 >> rs2 (산술적 오른쪽 시프트) -
곱셈 및 나눗셈 연산(M-extension)
MUL: mul rd, rs1, rs2
rd = rs1 rs2 (곱셈)
MULH: mulh rd, rs1, rs2
rd = 상위 비트(rs1 rs2) (정수 곱셈 상위 비트)
DIV: div rd, rs1, rs2
rd = rs1 / rs2 (정수 나눗셈)
REM: rem rd, rs1, rs2
rd = rs1 % rs2 (정수 나머지)
[RISC-V I-type]
Immediate-type

addi 와 같은 명령어는 rs2가 필요가 없음 -> 남는 부분 따라서
addi x5, x3, 4
이것의 경우 4같은 숫자를 할당하는 공간에 12비트가 할당이되니 2^12
들어갈 수 있는 최대 숫자는 -2048~2047 (2의보수이므로 한비트가 부호를 위해 빠져서 2^11)
또한, immediate의 값은 명령어의 종류에 따라 다르게 해석이 된다
1. 메모리 접근 명령어 (ld, lw 등)
예를 들어, ld x14, 8(x2)에서 immediate 값(8)은 오프셋(offset)으로 해석됩니다.
x2 레지스터에 저장된 주소에 immediate 값(8)을 더하여, 최종 메모리 주소를 계산한 뒤 해당 주소에서 값을 가져옵니다.
2. 산술 연산 명령어 (addi, andi, ori 등)
산술 연산 명령어에서 immediate 값은 연산에 사용되는 상수로 해석됩니다.
예를 들어, addi x22, x22, 4 명령어에서는 immediate 값(4)가 상수로 사용됩니다.
즉, x22 레지스터의 값에 4를 더한 결과를 다시 x22 레지스터에 저장합니다.
3. 분기 명령어 (beq, bne 등)
immediate는 분기할 주소의 오프셋으로 사용됩니다.
예를 들어 beq x1, x2, offset에서 offset은 현재 명령어로부터 얼마만큼 떨어진 주소로 분기할지를 나타냅니다.


(01111이 아닌 01110)
[RISC-V S-type]
Store-type
(27`30)
• Two registers and one immediate field
• Two immediate fields: 7bits+5bits
• rs1 and rs2 remain in the same position for all instructions

사실상 i-type과 내부적으론 똑같은데,,왜 저따우로 햇냐면
rd가 필요없어져서 rd부분을 immediate로 돌리고 원래 immmediate에서 5비트 때서 rs2할당
sd같은 ㄱ

사실상 0000000 + 01000 = 8

Logical Operations
(32') 다시들어잉

-
Shift operation
00000000 00001001 = 9
00000001 00100000 = 9 x 32 (shift left 5) -
Shift instructions (I-type)
(n칸 옮기라는 숫자가 immediate에 들어감)- slli, srli – shift left (right) logical immediate - sra, srai – shift right arithmetic (immediate): fill with sign-bit 1100 0011 → 1110 0001 (일종의 sign extension이다)
1. srl (Shift Right Logical)
- 레지스터 값을 기준으로 오른쪽 시프트할 비트 수를 결정합니다.
- 두 번째 레지스터에 있는 값만큼 첫 번째 레지스터의 값을 오른쪽으로 시프트합니다.
- 이 명령어는 레지스터 간의 연산으로, 시프트할 비트 수가 동적으로 결정됩니다.
srl x1, x2, x3
x2 레지스터의 값을 x3 레지스터의 값만큼 오른쪽으로 시프트하고, 결과를 x1에 저장합니다.
2. srli (Shift Right Logical Immediate)
- 즉시 값(immediate)을 사용하여 시프트할 비트 수를 결정합니다.
- 첫 번째 레지스터의 값을 즉시 값만큼 오른쪽으로 시프트하고, 결과를 다시 레지스터에 저장합니다.
- 이 명령어는 정적인 즉시 값을 사용하여 시프트할 비트 수를 고정합니다.
srli x1, x2, 5
x2 레지스터의 값을 5비트만큼 오른쪽으로 시프트하고, 그 결과를 x1에 저장합니다.
3. sra (Shift Right Arithmetic)
- 오른쪽으로 비트를 이동시키면서, 왼쪽의 빈 비트들은 부호 비트(가장 왼쪽 비트, MSB)로 채워집니다.
- 즉, 양수일 경우에는 0이, 음수일 경우에는 1이 왼쪽 빈 비트를 채웁니다.
- 이는 부호를 유지하며, 정수를 오른쪽으로 시프트할 때 필요한 기능입니다
AND/OR Instructions

1. and (Register-based AND)
- and는 두 레지스터의 값을 비트 단위로 AND 연산하여 결과를 또 다른 레지스터에 저장합니다.
- 이 명령어는 레지스터 간 연산으로, 두 레지스터의 값이 필요합니다.
[동작 예시:]
and x1, x2, x3
x2: 1010 1010₂
x3: 1100 1100₂
x1: 1000 1000₂ (각 비트를 AND 연산)
2. andi (Immediate AND)
- andi는 레지스터와 즉시 값(immediate)을 비트 단위로 AND 연산한 후 결과를 레지스터에 저장합니다.
- 즉, 한쪽 피연산자는 레지스터 값이고, 다른 쪽 피연산자는 명령어 자체에 포함된 즉시 값(상수)입니다.
동작 예시
andi x1, x2, 15
x2: 1010 1010₂
15: 0000 1111₂
x1: 0000 1010₂ (각 비트를 AND 연산)

두개도 비슷혀~
XOR Instructions


(not이라는 명령어는 따로 없으며, xor 명령어로 그 역할을 대체함)
Instructions for Making Decisions
- beq, bne: conditional branches
[beq]: "branch if equal"
beq rs1, rs2, L1
► rs1과 rs2가 같으면 L1으로 이동해라
[bne]: "branch if not equal"
bne rs1, rs2, L1
► rs1과 rs2가 다르면 L1으로 이동해라
[C code]
if (i==j)
f = g + h;
else
f = g – h;- 변수들을 각각 레지스터에 할당했다고 가정
f:x19, g:x20, h:x21, i:x22, j:x23
[RISC-V assembly code]
bne x22, x23, Else # go to Else if i ≠ j
add x19, x20, x21 # f = g + h (skipped if i ≠ j)
beq x0, x0, Exit # if 0 == 0, go to Exit //항상 같으므로 무조건 exit ( else부분을 건너뛰기 위한 구문) (unconditional)
Else: sub x19, x20, x21 # f = g − h (skipped if i = j)
Exit:[C code]
While (save[i]==k)
i += 1;- 변수들을 각각 레지스터에 할당했다고 가정
i:x22, k:x24, base of save: x25 (array의 base address가 x25)
[RISC-V assembly code]
Loop: slli x10, x22, 3 // (shift left logical 3 이니 2^3을 곱하란 의미 ) x10 = i x 8 (array지만 디폴트가 doubleword이므로 8byte로 가정, 따라서 8을 곱함)
add x10, x10, x25 // x10 = address of save[i], x25라는 베이스 주소에 offset인 x10 더하기
ld x9, 0(x10)// x9 = save[i] x10: 가져오고자하는 데이터의 주소값, 0은 offset
bne x9, x24, Exit // go to Exit if save[i] ≠ k (x9와 x24가 다르면 exit)
addi x22, x22, 1 // i = i+1
beq x0, x0, Loop // go to Loop
Exit:[8][8][8][8]
Other Conditional Branches (19'30)
[blt]: “branch if less than”
blt rs1, rs2, L1
- rs1, rs2의 크기를 비교한다 (2의 보수 기준, 음수도 가능)
- rs1이 rs2보다 작으면 L1으로 가라
[bge]: “branch if greater than or equal””
bge rs1, rs2, L1
- rs1, rs2의 크기를 비교한다 (2의 보수 기준, 음수도 가능)
- rs1이 rs2보다 같거나 크면 L1으로 가라
[bltu, bgeu]
- Numbers in registers are treated as unsigned (프로그래머가 알아서 판단해서 사용)
Array Index Out-of-bound check
- Array index check
int[] age = new int[5];
age[-2] = 12; // 겠냐고
age[2] = 4;
age[12] = 4; // 겠냐고Need to check if index>0 and index<=max_length
if x20 >= x11 or x20 < 0, goto IndexOutOfBounds
bgeu x20, x11, IndexOutOfBounds
x20이 index, x11이 최대치
만약 x20이 -1이면 bgeu가 2의 보수로 봤을땐 -1인데 (11111111111~0) unsigned로 해석하면 엄청 큰수가 되서 암튼간에 Indexoutofbound로 처리가됨, 음수면 존나 커져서 아웃 ㅋㅋ
Supporting Procedures (36:20)
Procedure (function) calls
- Pass function parameters
- Transfer control (control = 실행지점)
- Acquire necessary memory space
- Run procedure
- Store return value (result) to predefined location
- Return control
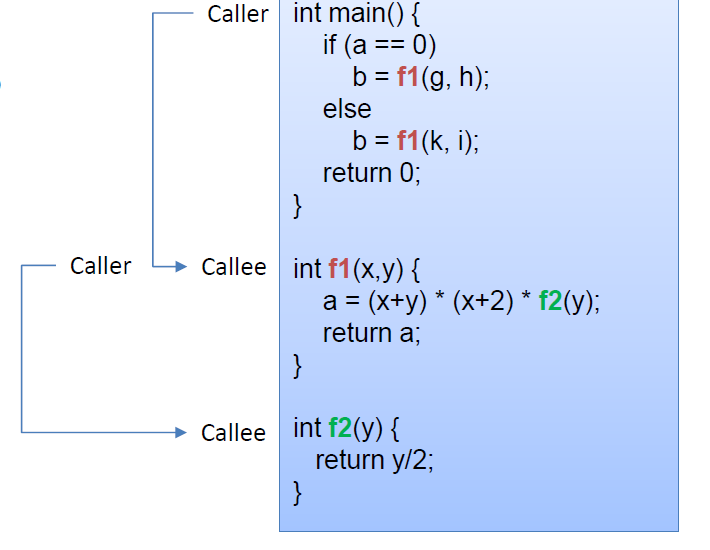
int main() {
if (a == 0)
b = f1(g, h);
else
b = f1(k, i);
return 0;
}
int f1(x,y) {
a = (x+y) * (x+2) * f2(y);
return a;
}
int f2(y) {
return y/2;
}
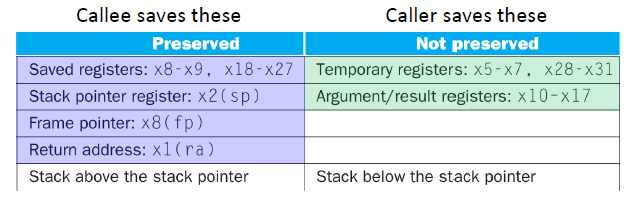
RISC-V conventions (절대적인 규칙은 아님,,ㅎ 걍 지키면 좋음)
- x10~x17: eight parameter registers in which to pass parameters or return
values (x10~x17은 함수 진입 시점에서 전달할 값이 있으면 이 레지스터들을 쓰자) - x1: one return address register (x1에 있는 값은 일반적인 값이 아닐라 함수가 끝낫을때 어디로 가야할지 그 메모리주소 저장할 레지스터)
RISC-V instruction for procedure handling
jal x1, ProcedureAddress (함수 호출 명령어)
• jal: “jump-and-link” (어디로 점프해서 마저 수행하라)
• Branch unconditionally and save the address of the next instruction (return
address) to the designated register (무조건 적으로 점프해라, 그리고 다음 명령어의 주소를 지정된 레지스터(x1) 저장해라(link) -> 함수로 점프하기 전에 돌아올 지점을 링크해놓는,,,
Program counter (PC) register
- Contains the address of current instruction being executed
(현재 실행중인 명령어의 주소를 저장하는 특수한 레지스터) - jal saves PC+4 to the rd (usually x1)
Unconditional branch without saving the return address
jal x0, Label
- x0는 뭔짓을 해도 저장이 안되는 특수한 레지스터이므로
= 나는 리턴할 생각이 없고 걍 점프나해라
► 함수 호출과는 무관하게 그냥 실행 위치를 옮기고 싶을때 사용 가능
Returning from a procedure (54'30)
- jalr: “jump and link register” instruction (I-type) (호출된 함수 끝부분에 있는 명령어)
jalr x0, 0(x1)
마찬가지로 x0에 뭘 시도해도 의미가 없다.
기계적으로 리턴할땐 이 명령어를 쓰면됨.
• Branches to the address stored in register x1 (i.e., 0 + address in x1)
** x0 is hard-wired to zero, writing to x0 will have the effect of discarding the
value (e.g., return address)
Using More Registers (57'00)
-
Procedure may need more than 8 registers for execution
(함수에서 8개 이상의 레지스터를 요구할 수 있다)
-
Compiler chooses to use other additional registers (8개의 레지스터말고 다른거 사용)
- Save the value of registers to memory → spill (쩔수없이 메모리 사용)
- Restore the value after procedure finishes예를들어 x18을 사용했다면 convention을 넘어간 input 호출용 레지스터가 아니므로
x18에 원래 있던 값을 다른 곳에 저장한 후(spilling) 사용하고, 이후에 다시 복원해야함만약 32개의 레지스터를 넘어간다면 어쩔 수 없이 포인터를 전달해야하는,,,그런 st
-
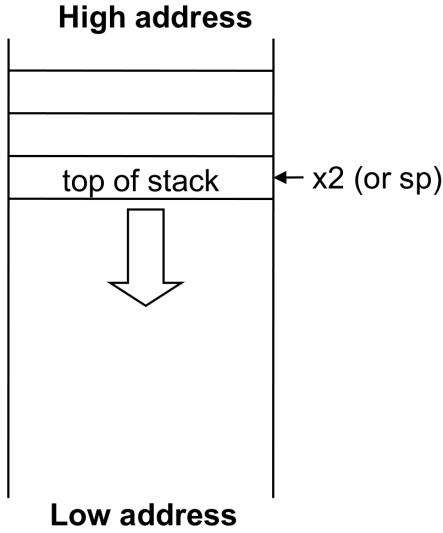
Ideal place for spilling registers: stack
-
Last-in-first-out queue in memory
-
Memory area for spilling registers
-
Stack pointer,
x2(sp, 이것또한 레지스터임) -
Stack grows from high address to low address
-
stack pointer is adjusted by one doubleword for each register that is saved (i.e., push) and restored (i.e., pop)
Compiling a Leaf Procedure (01'06'00)
[Leaf procedure ]
- procedure that does not call other procedure

long long int f = local 변수

leaf_example:
addi sp, sp, -24 // 스택 포인터(sp)를 24만큼 감소하여 3개의 레지스터를 저장할 공간 확보
sd x5, 16(sp) // x5(임의) 레지스터를 스택에 저장 (sp기준 두칸 올리기)
sd x6, 8(sp) // x6(임의)레지스터를 스택에 저장 (sp기준 한칸 올리기)
sd x20, 0(sp) // x20 레지스터를 스택에 저장
add x5, x10, x11 // x5 = g + h
add x6, x12, x13 // x6 = i + j
sub x20, x5, x6 // x20 = (g + h) - (i + j)
addi x10, x20, 0 // 결과를 x10에 저장 (x10 = x20 + 0)
ld x20, 0(sp) // 스택에서 x20 레지스터 복원
ld x6, 8(sp) // 스택에서 x6 레지스터 복원
ld x5, 16(sp) // 스택에서 x5 레지스터 복원
addi sp, sp, 24 // 스택 포인터를 원래 위치로 복원
jalr x0, 0(x1) // 호출한 함수로 복귀Register Saving Convention
Two groups of registers in RISC-V
- No need for callee to save (보통 호출당해서 쓰는 레지스터)
x5~x7,x28~x31(애초에 중요한 값은 여기에 넣으면 안됨)
- registers for temporary use
- Callee must preserve (save, use and restore) if used
x8,x9,x18~x27(웬만하면 안쓰는데 썼으면 원상복구하는 레지스터)
addi sp, sp, -24 // adjust stack to make room for 3 items
sd x20, 0(sp) // save register x20 for use afterwards (예시로 든거고 실제로는 x7같은걸 써야함)
add x5, x10, x11 // register x5 contains g + h
add x6, x12, x13 // register x6 contains i + j
sub x20, x5, x6 // f = x5 − x6, which is (g + h) − (i + j)
addi x10, x20, 0 // returns f (x10 = x20 + 0)
ld x20, 0(sp) // restore register x20 for caller
addi sp, sp, 24 // adjust stack to delete 3 items
jalr x0, 0(x1) // branch back to calling routineNested Procedure
Issues with nested procedures
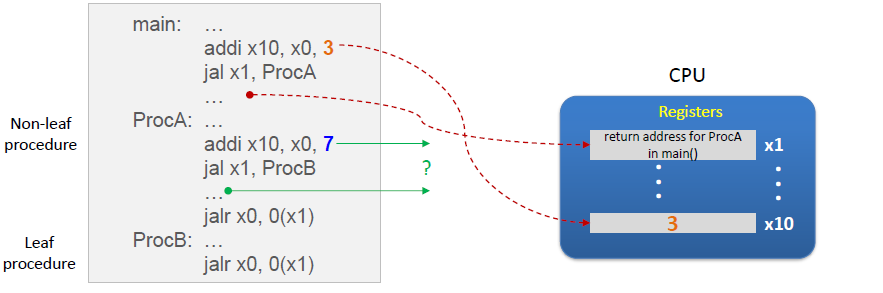
Register Preservation Responsibility
Recursive Procedure
Factorial
[C Code]
long long int fact (long long int n)
{
if (n < 1) return (1);
else return (n * fact(n − 1));
}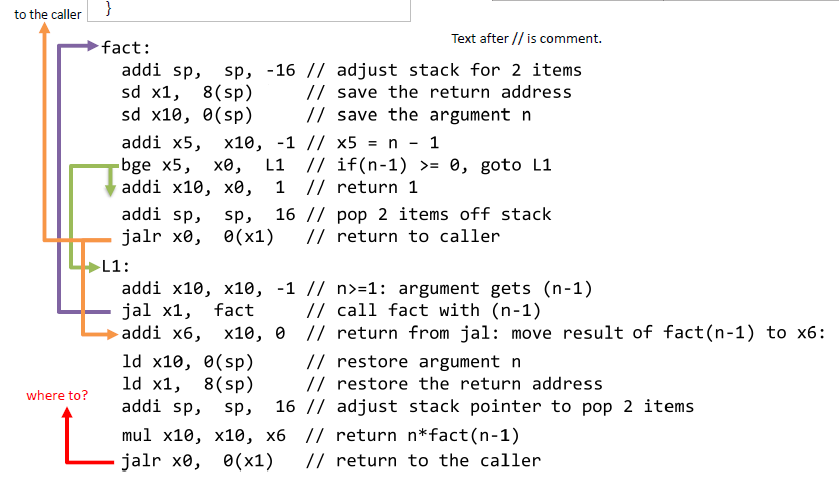
recursive 가 몇번 진행됐는지 알 수 없기에 통용될수있는 코드를 짜야함
fact:
addi sp, sp, -16 // 스택 포인터를 16만큼 줄여 2개의 값을 저장할 공간 확보
sd x1, 8(sp) // 현재 리턴 주소 x1을 스택에 저장 (sp + 8 위치에 저장)
sd x10, 0(sp) // 인수 n이 저장된 x10을 스택에 저장 (sp + 0 위치에 저장)
addi x5, x10, -1 // n - 1을 계산하여 x5에 저장 (x5 = n - 1)
bge x5, x0, L1 // n-1이 0 이상이면 L1으로 분기, 그렇지 않으면 다음 명령어 실행
addi x10, x0, 1 // n == 1인 경우, 결과를 1로 설정 (x10에 1 저장) (return 1)
addi sp, sp, 16 // 스택을 원래대로 복구 (sp를 16만큼 더해서 복구)
jalr x0, 0(x1) // 리턴 주소로 복귀 (호출한 함수로 돌아감)
L1:
addi x10, x10, -1 // n = n - 1 (x10에 n - 1 저장)
jal x1, fact // fact(n-1)을 재귀적으로 호출 (리턴 주소는 x1에 저장)
addi x6, x10, 0 // 재귀 호출의 결과 fact(n-1)을 x6에 저장 (x10 값을 x6으로 복사)
ld x10, 0(sp) // 스택에서 n 값을 복원 (sp + 0 위치에서 x10에 저장)
ld x1, 8(sp) // 스택에서 리턴 주소를 복원 (sp + 8 위치에서 x1에 저장)
addi sp, sp, 16 // 스택 포인터를 원래대로 복구 (sp를 16만큼 더해서 원래 위치로)
mul x10, x10, x6 // n * fact(n-1)을 계산하여 x10에 저장 (최종 결과를 x10에 저장)
jalr x0, 0(x1) // 리턴 주소로 복귀 (호출한 함수로 돌아감)
Procedure’s Local Data on the Stack
- Local variables within the procedure
- Placed into stack
- Procedure frame ( = activation record)
- Segment of stack that contains saved registers, return address and local variables
- Frame pointer, FP (x8) – point to the first word of the procedure frame (프레임의 시작점)
- SP may change during execution
stack 영역 : 자료구조의 형태가 아닌 사용 용도를 의미하는 것
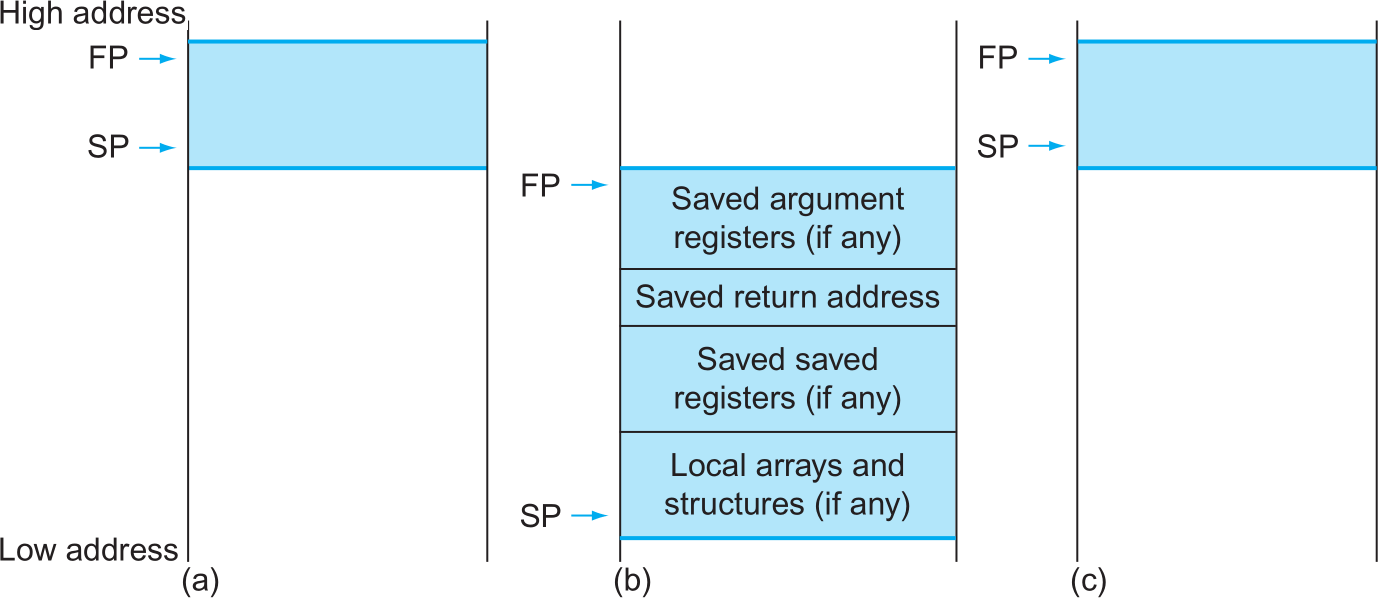
High add
- Saved argument register을 다 채워넣음
- Saved return address
- Saved saved registers (if any)
- Local arrays and structures (if any)
return을 할때 해당 값이 그대로 유지되긴하지만 레지스터에 는 Fp와 Sp의 (포인터)값을 바꾼다
-> 정보가 그대로 남아있기때문에 해킹 취약점이 될 수 있다.
-> 근데 왜 그러냐? : 메모리 영역을 초기화하는 것 또한 비효율적이기 때문
Allocating Memory on the Heap
Address space convention
- Address space: range of addresses that can be used/allocated/referred
- It has nothing to do with the real physical memory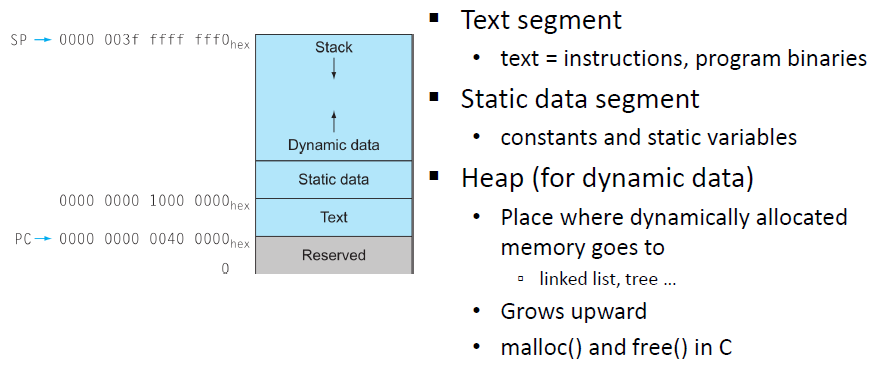
- Dynamic data : Heap 영역으로 간주, 동적으로 할당된 메모리를 위한 공간 (Heap은 올라감)
- Stack영역은 한도가 없으므로 계속해서 함수를 호출하면 계속해서 밑으로 커짐
- static data: 계속 고정적으로 존재해야하는 전역변수들이 배치된다.
- Text : 프로그래밍 자체의 Binary code를 의미함 (exe파일)
관행적으로 이렇게 쓰이고 있다.
Wide Immediate Operands
▪ There are times when constants are too big to fit into 12 bits
▪ RISC-V provides lui (Load Upper Immediate) instruction
• U-type instruction
Branch Instruction Format
bne라는 instruction에서 branch의 타겟 대상은 12비트라서 2의 12승
2의 12승 비트 안에 들어가는 숫자의 의미는 개별 바이트 값이 아닌 instruction의 개수
값이 10이면 10바이트가 아닌 instruction의 개수 그래서 개당 4바이트니까 총 표현할 수 있는 바이트는 2의 12승 x 4(byte)
이후에 2바이트짜리 instruction도 지원하기 위해서 2만 곱해서 (다만 범위는 반이 줄어듬)
13비트의 표현효과를 가짐
왜 무조건 0인가? 2혹은 4를 표현하면 짝수니까 맨 끝자리는 걍 0이거덩여
