[2024] day 81. Leetcode 1669. Merge In Between Linked Lists
2024년부터 새롭게 다시 시작하는 코딩테스트
2024년 3월 20일 (수)
Leetcode daily problem
1669. Merge In Between Linked Lists
Problem
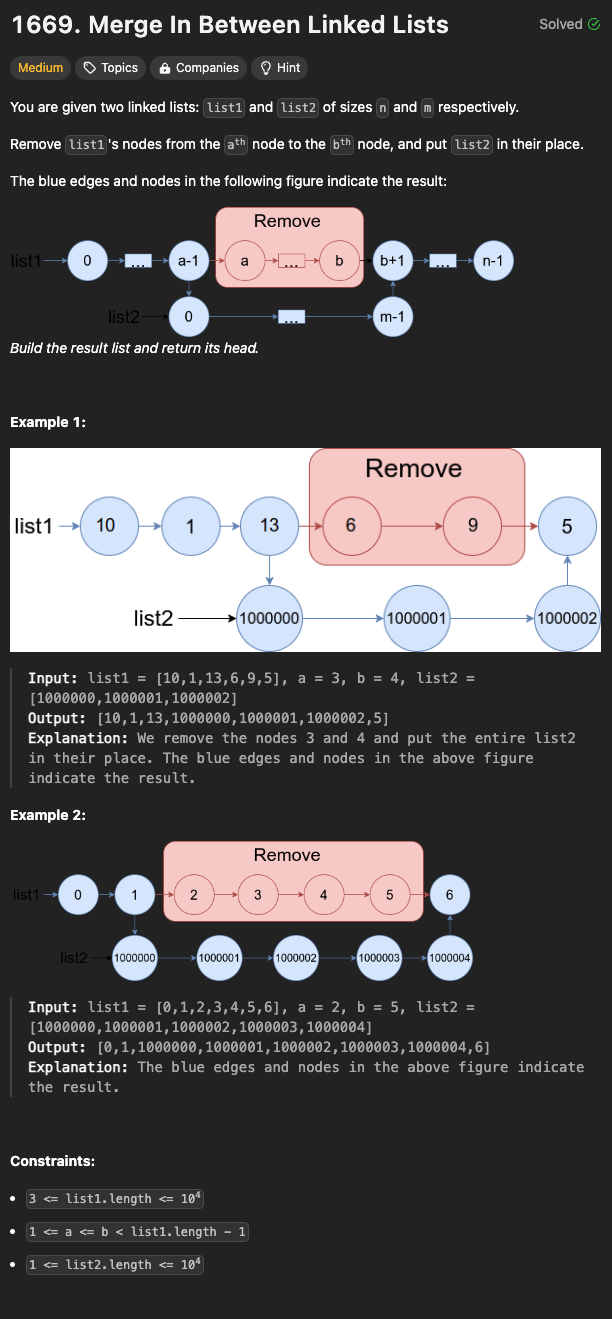
두 개의 연결 리스트(linked list) list1, list2가 제공될 때, 각 크기는 n,m 이다.
list1의 노드를 a번째 노드에서 b번째 노드까지 제거하고 그 자리에 list2를 넣고, 최종 연결 리스트를 반환한다.
Solution
linked list
해당 문제는 두 개의 연결형 리스트를 병합하는 문제이다.
하나의 연결형 리스트의 범위를 제거하고, 해당 범위 내에 다른 연결형 리스트를 넣어 병합해야 한다.
포인터 개념을 잘 이해하고 핸들링해야 한다.
(여기서의 "포인터"는 연결 리스트의 노드를 가리키는 변수이다. 연결 리스트의 각 노드는 데이터와 다음 노드를 가리키는 포인터로 구성된다.
예를 들어, ListNode 클래스의 인스턴스인 dummy1, dummy2, list2는 각각 연결 리스트의 노드를 가리키는 포인터이다. 이 포인터들을 사용하여 연결 리스트의 구조를 변경하거나 탐색한다.)
주어진 두 개의 연결형 리스트를 가르키는 포인터들을 생성해서(dummy1)
제거해야 하는 노드의 전까지 순서(a)까지 포인터를 이동시킨다.
해당 연결형 노드의 다음이 제거해야 할 노드를 가르킬 때 까지 이동시킨다는 말이다.
제거해야할 다음 포인터를 가르키는 포인터를 생성하고 (dummy2)
해당 포인터를 제거가 끝나는 지점(b)까지 이동시킨다.
위에서 제거해야할 지점(a)를 가리키는 포인터 dummy1의 다음 노드를 연결해야하는 list2로 이동시키고, list2의 포인터를 list2 까지 이동한다.
list2의 마지막 노드에서 다음 노드를 가르키는 포인터로 포인터 제거가 끝난 지점을 가르키는 dummy2를 가리키면 된다.
따라서 코드에서 dummy1, dummy2, list2는 단순히 노드를 가리키는 포인터로 사용되며, 연결 리스트의 구조를 조작하기 위해 이러한 포인터들을 이용해서 연결형 리스트들을 조작한다.
포인터는 메모리 주소를 가리키기 때문에 연결 리스트의 각 노드는 메모리 상의 다음 노드의 주소를 저장하는 포인터를 포함하므로, 포인터 변수를 통해서 핸들링 하면서 연결형 리스트를 병합시키는 것이다.
데이터가 들어있는 객체를 핸들링하는 것이 아닌 포인터의 개념을 잘 이해하고 핸들링하는 것이 중요하다고 보겠다.
Code
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def mergeInBetween(self, list1: ListNode, a: int, b: int, list2: ListNode) -> ListNode:
dummy1 = list1
for _ in range(a-1):
dummy1 = dummy1.next
dummy2 = dummy1.next
for _ in range(b-a+1):
dummy2 = dummy2.next
dummy1.next = list2
while list2.next:
list2 = list2.next
list2.next = dummy2
return list1
Complexicity
시간 복잡도
첫 번째 루프에서 a 위치의 노드를 찾을 때의 시간 복잡도 O(n) -> n: a 위치 길이
두 번째 루프에서 a 위치에서 시작해 b 위치의 노드를 찾을 때의 시간 복잡도 O(m-n) -> m : b 위치의 길이
여기까지의 시간 복잡도는 (n+(m-n)) 이므로, 총 O(m) 이다.
그 뒤에 list2의 마지막 노드를 찾기 위한 while문에서 O(k) -> k : list2의 길이로,
전체적인 시간 복잡도는 O(m+k)이다.
공간 복잡도
여기서 dummy1, dummy2를 생성하는데 단순 포인터의 개념으로 추가 공간을 필요로 하지 않기 때문에 공간 복잡도는 O(1)이다.