[4코3파] 1명의 스위프트 개발자가 도망가고 4명의 코틀린 개발자, 3명의 파이썬 개발자의 코딩 테스트 스터디 : 4코3파
START :
[3코1파] 2023.01.04~ (293일차)
[4코1파] 2023.01.13~ (285일차)
[4코3파] 2023.10.01 ~ (23일차)
Today :
2023.10.23 [293일차]
Leetcode Array & Hashing 문제
뭔가 기초도 잘 모르면서 중상급 문제를 자꾸 깔짝이고 있는 듯한 느낌이 들어서,
밑바닥 돌이 잘 놔져있는지 돌다리도 두드려보고 건너기 위하여
leetcode tree 문제 복습겸 Array & Hashing 문제 다시 풀기
+코딩 인터뷰 189가지 프로그래밍 문제와 해법 완전분석 책이랑 같이 보기
[1] 217. Contains Duplicate
https://leetcode.com/problems/contains-duplicate/description/
문제 설명

정수 배열 안에 중복 원소가 있으면 True, 아니면 False
문제 풀이 방법
해당 문제를 푸는 방법은
Hashmap사용, 자료구조를 사용하지 않고 푸는 방법으로
Brute Fore, sorted로 푸는 방법이 있음
(1) Hashmap 사용, 자료구조를 추가해서 사용할 시
- 시간복잡도 O(n), 공간복잡도 O(n)
(2) Brute Force 사용 시
- 배열을 처음부터 돌아서 하나씩 확인하는 방법
- 시간복잡도 O(n^2) , 공간복잡도 O(1)
(3) Sorted 한 후 인접 배열로 찾을 시
- python sorted 메소드는 Timsort 사용 시간 복잡도 O(nlogn), 공간복잡도 O(1)
내 코드
Hash map
class Solution:
def containsDuplicate(self, nums: list[int]) -> bool:
numSet = set()
for num in nums:
if num in numSet:
return True
numSet.add(num)
return False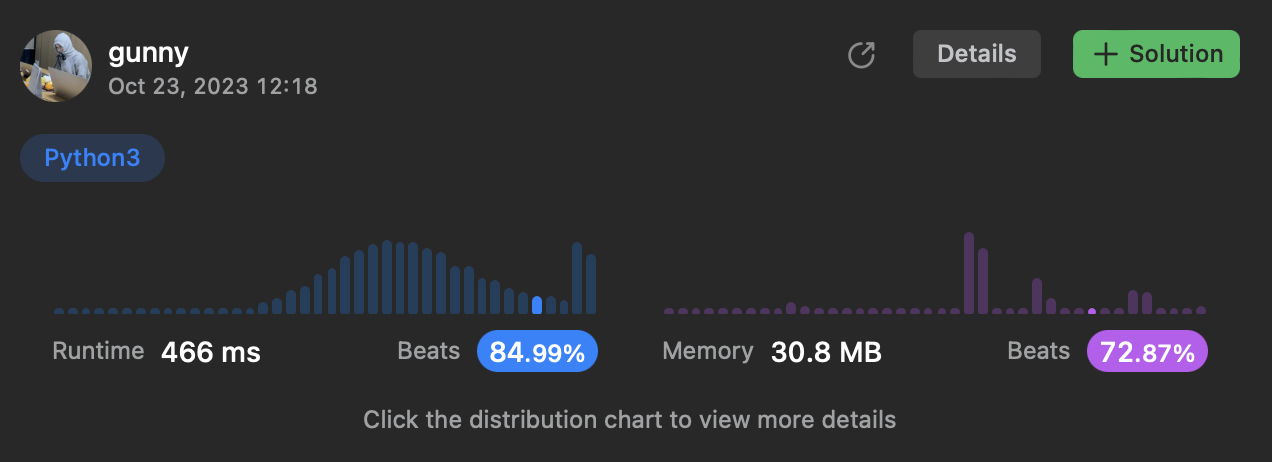
Brute Force
class Solution:
def containsDuplicate(self, nums: list[int]) -> bool:
for i in range(len(nums)):
for j in range(i+1, len(nums)):
if nums[i]==nums[j]:
return True
return False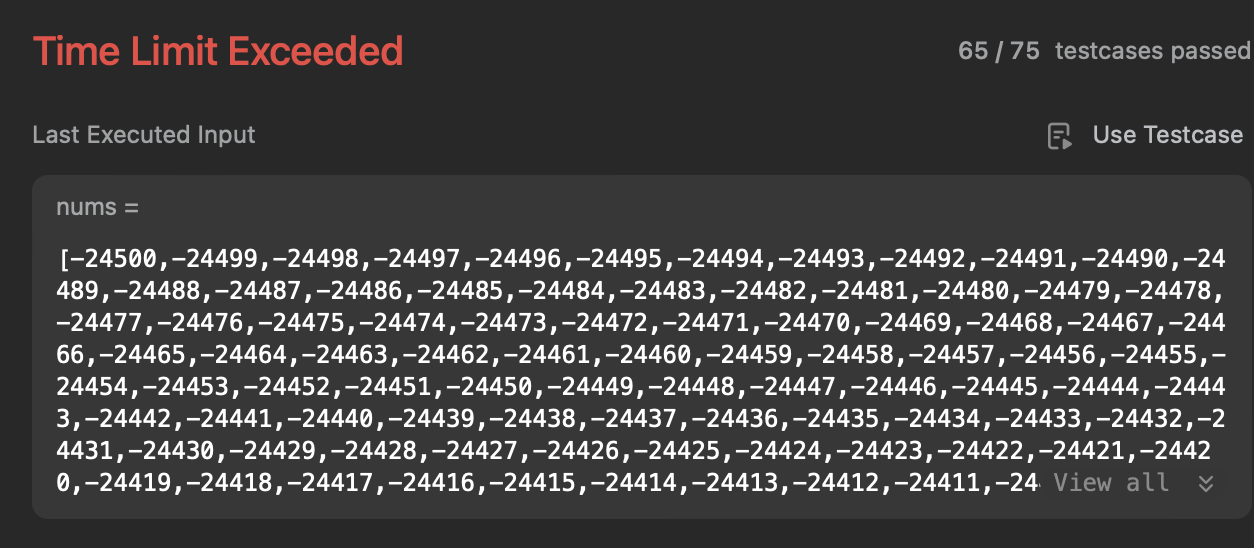
Sorted
class Solution:
def containsDuplicate(self, nums: list[int]) -> bool:
nums = sorted(nums)
for i in range(len(nums)-1):
if nums[i] == nums[i+1]:
return True
return False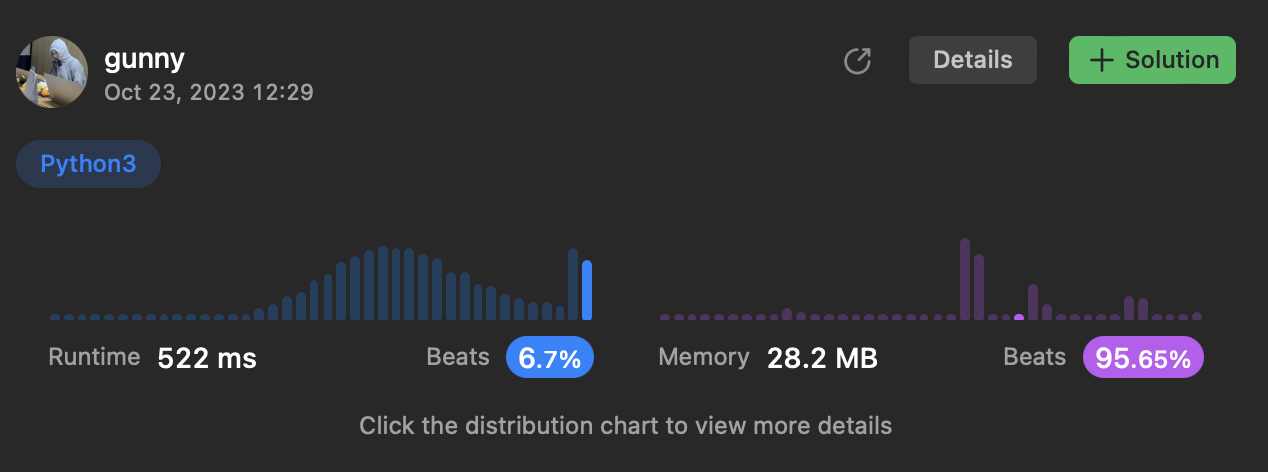
[2] 242. Valid Anagram
문제 설명
두 문자열 s, t가 주어졌을 때, t가 s의 anagram이면.true, 아니면 False를 반환한다.
Anagram은 원래 문자를 구성하고 있는 문자열을 정확히 한 번씩만 사용해 (재배열해서) 만들어지는 문자임
문제 풀이 방법
제일 먼저 접근했던 방법은 두 문자열을 sort 한 다음에 비교하는 것
이 경우에는 최적의 알고리즘이 아닐 수 있어 hash map을 이용해서, 각 문자를 구성하고 있는 문자열의 개수를 hashmap에 넣어 비교하면 시간복잡도 O(n), 공간복잡도 O(n)으로 풀 수 있음
내 코드
정렬해서 푸는 방법
시간복잡도는 O(nlogn), 공간복잡도는 O(1)
class Solution:
def isAnagram(self, s: str, t: str) -> bool:
return sorted(s) != sorted(t)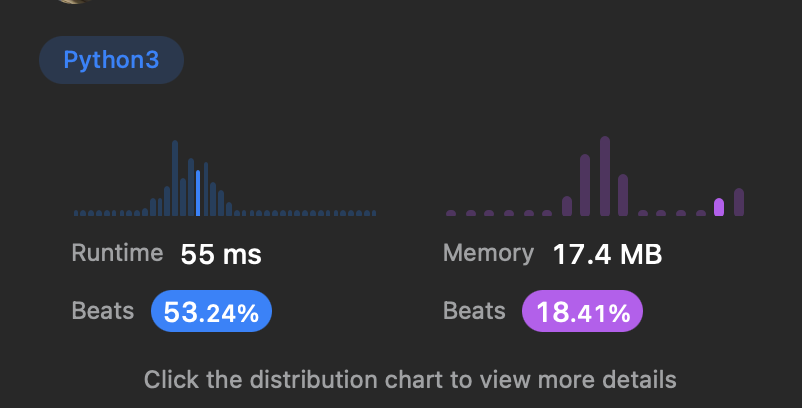
Hash map
class Solution:
def isAnagram(self, s: str, t: str) -> bool:
if len(s) != len(t):
return False
cntS, cntT = {},{}
for i in range(len(s)):
cntS[s[i]] = 1+cntS.get(s[i],0)
cntT[t[i]] = 1+cntT.get(t[i],0)
for j in cntS:
if cntS[j] != cntT.get(j,0):
return False
return True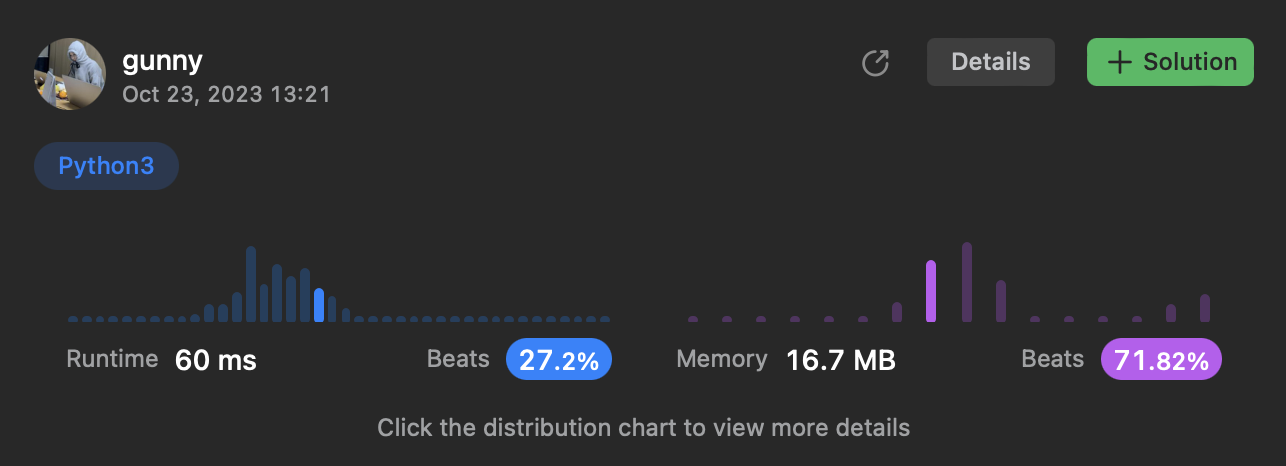
[3] 1. Two Sum
문제 설명
정수 배열 nums와 target 정수가 주어질 때, 배열의 원소 2개를 합해서 target을 만들 수 있을 때, 이 때의 원소 2개의 인덱스를 return
문제 풀이 방법
처음 접근은 무조건 brute force로 O(n^@)
당연히 효율적인 코스가 아니겠지요..
머리를 굴렸는데 easy 라고 하기덴 내머리가 더 수준이 낮은지 잘 모르겠다가 neetcode 보고 다시 기억 회상..
배열의 원소들의 각각을 target으로 빼ㅐㅆ을 때, target과 원소의 차가 나머지 원소 중 하나와는 같을 것이니까 이를 이용해서 풀면 되는 것이었다.
hash map을 사용해서, 정수 배열 nums를 한 번 순회하면서 target과의 차와 현재 인덱스를 저장하고, target의 차가 순차적으로 탐색하면서 저장해온 hash map의 키와 같다면 이때의 저장해놨던 hash map 인덱스와 현재 돌고 있는 배열의 index를 같이 return 하면 된다.
enumerate 함수를 사용!
내 코드
brute force
시간복잡도는 O(n^2), 공간복잡도는 O(1)
time limit 이 나야하는데 제약사항의 nums 의 범위가 이정도는 받아들일 수 있었나봄
class Solution:
def twoSum(self, nums: list[int], target: int) -> List[int]:
for i in range(len(nums)):
for j in range(i+1, len(nums)):
if nums[i] + nums[j] == target:
return [i,j]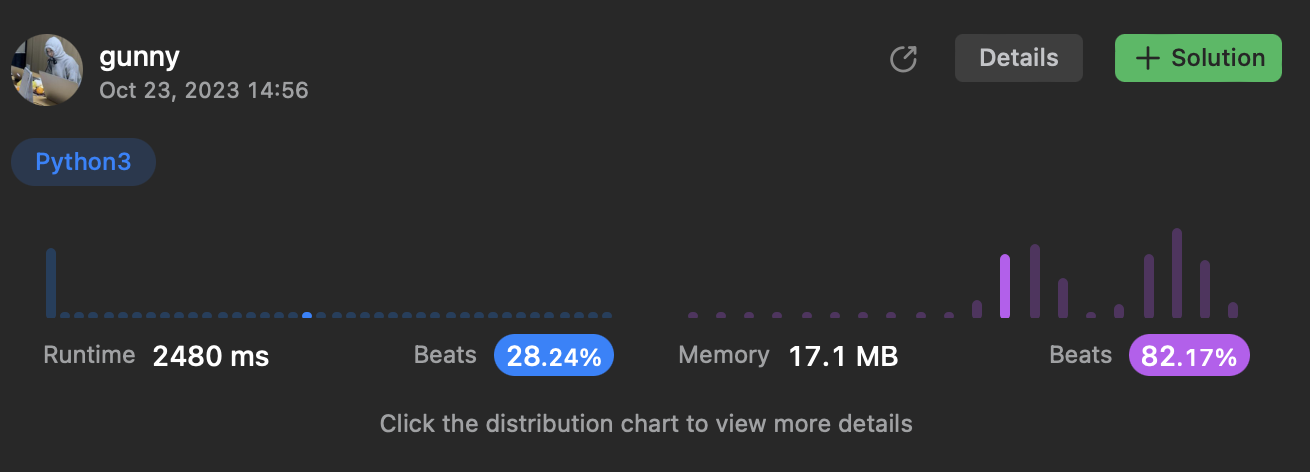
Hash map
class Solution:
def twoSum(self, nums: list[int], target: int) -> List[int]:
sumSet = {}
for i, n in enumerate(nums):
tmp = target-n
if tmp in sumSet:
return [sumSet[tmp], i]
sumSet[n] = i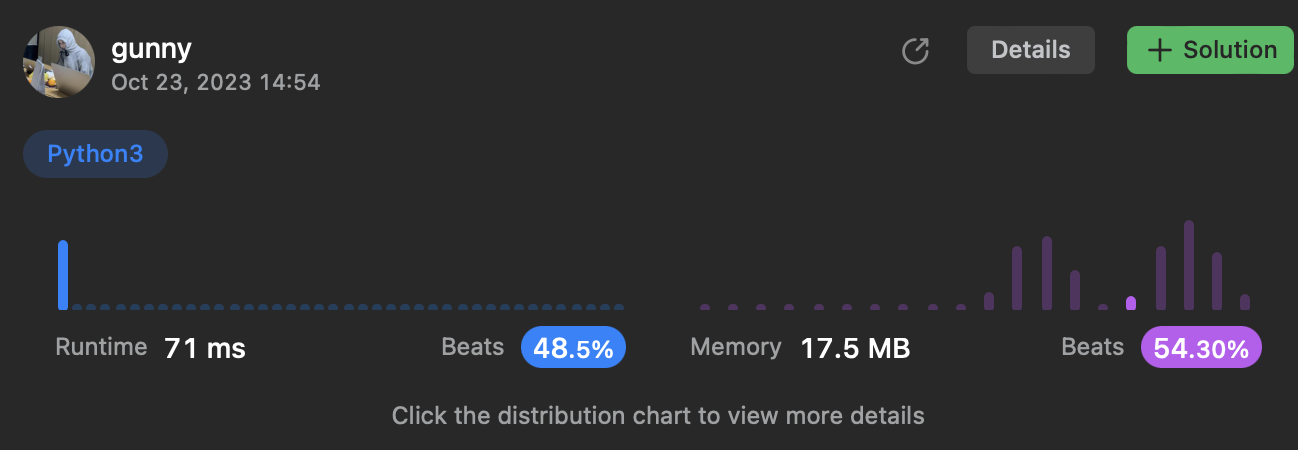
[4] 49. Group Anagrams
문제 설명
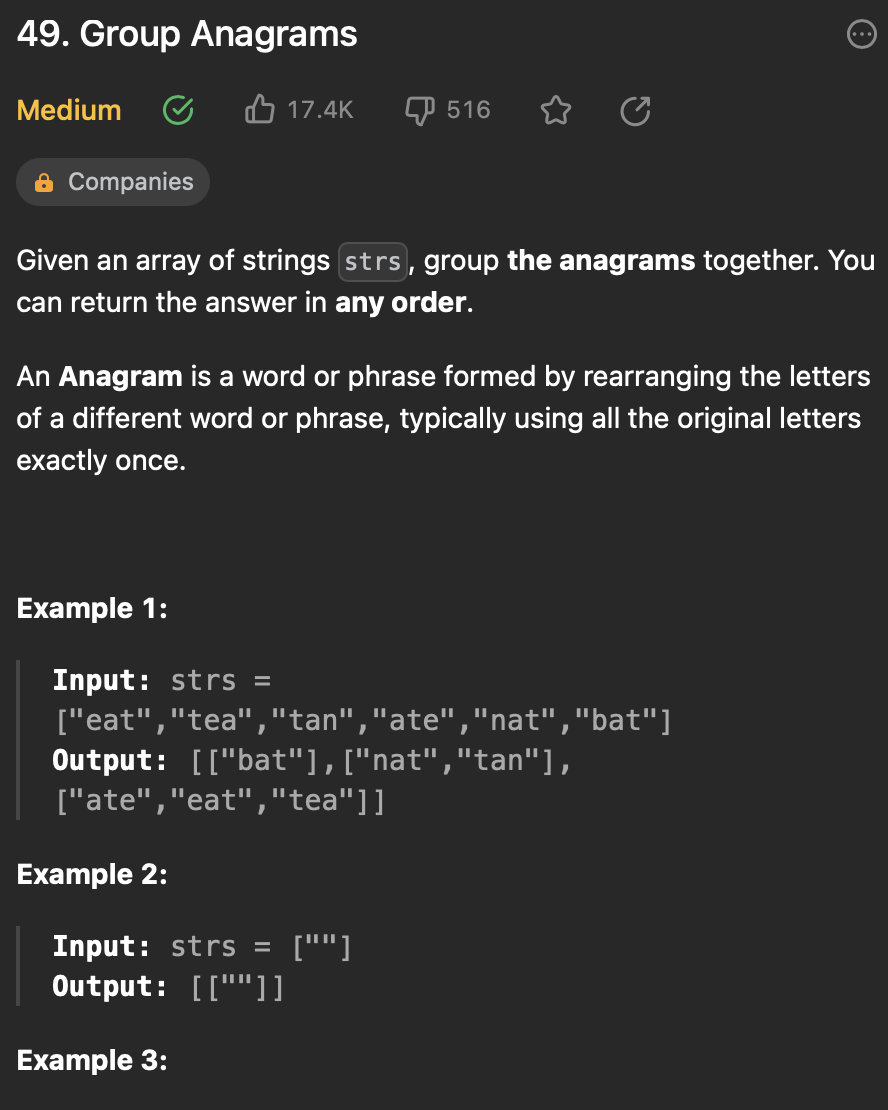

문자로 구성된 배열 strs가 주어질 때, Anagram에 해당하는 문자끼리 묶어서 list 로 반환함
문제 풀이 방법
나의 첫 풀이는 유사한 easy 문제인 (242. Valid Anagram)에서 풀었던 hashmap과 sorted를 활용했다.
주어진 문자 배열을 돌면서 각 문자를 sorted 해서 정렬된 문자를 hash map의 key로 두고, 원래 문자 배열을 리스트에 담아 value로 뒀다.
돌면서 정렬문자가 있으면 value에 추가 없으면 리스트에 담아서 새로운 key, value를 생성하면서 풀었음
마지막에는 hash map의 values만 리스트로 뽑아서 return !
내 코드
시간복잡도는 O(n*nlogn) 이다.
정렬할 때 nlogn 과 strs 배열의 n 이 걸리기 때문
공간복잡도는 O(n) 임! tmp와 dictionary에 저장함
from collections import defaultdict
class Solution:
def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
if len(strs)==1:
return [strs]
ans = defaultdict(list)
for s in strs:
tmp = ''.join(sorted(s))
ans[tmp].append(s)
return ans.values()
defaultdicts를 사용하지 않고 그냥 dictionary에 있는 메소드를 써서도 푼다.
class Solution:
def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
if len(strs)==1:
return [strs]
strMap = {}
for s in strs:
tmp = ''.join(sorted(s))
if strMap.get(tmp,0) ==0:
strMap[tmp] = [s]
else:
strMap[tmp].append(s)
return list(strMap.values())다른 풀이
O(m*n) 으로 풀 수 있는 풀이
문자 배열에 있는 문자들과 기준점이 되는 'a'의 아스키코드의 차이의 값을 키로 해서
미리 만들어놓은 26개의 cnt 배열에 value 값으로 넣는다.
a-z 까지 (26)개임.
위에서는 고유한 string 데이터 타입을 저장해서 비교했다면 이건 아스키코드로 변환해서 기준점이 되는
문자와의 차이를 key 값으로 둬서 비교하는 것!
from collections import defaultdict
class Solution:
def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
ans = defaultdict(list)
for string in strs:
count = [0]*26
for s in string:
count[ord(s)-ord('a')]+=1
ans[tuple(count)].append(string)
return ans.values() [5] 347. Top K Frequent Elements
https://leetcode.com/problems/top-k-frequent-elements/description/
문제 설명
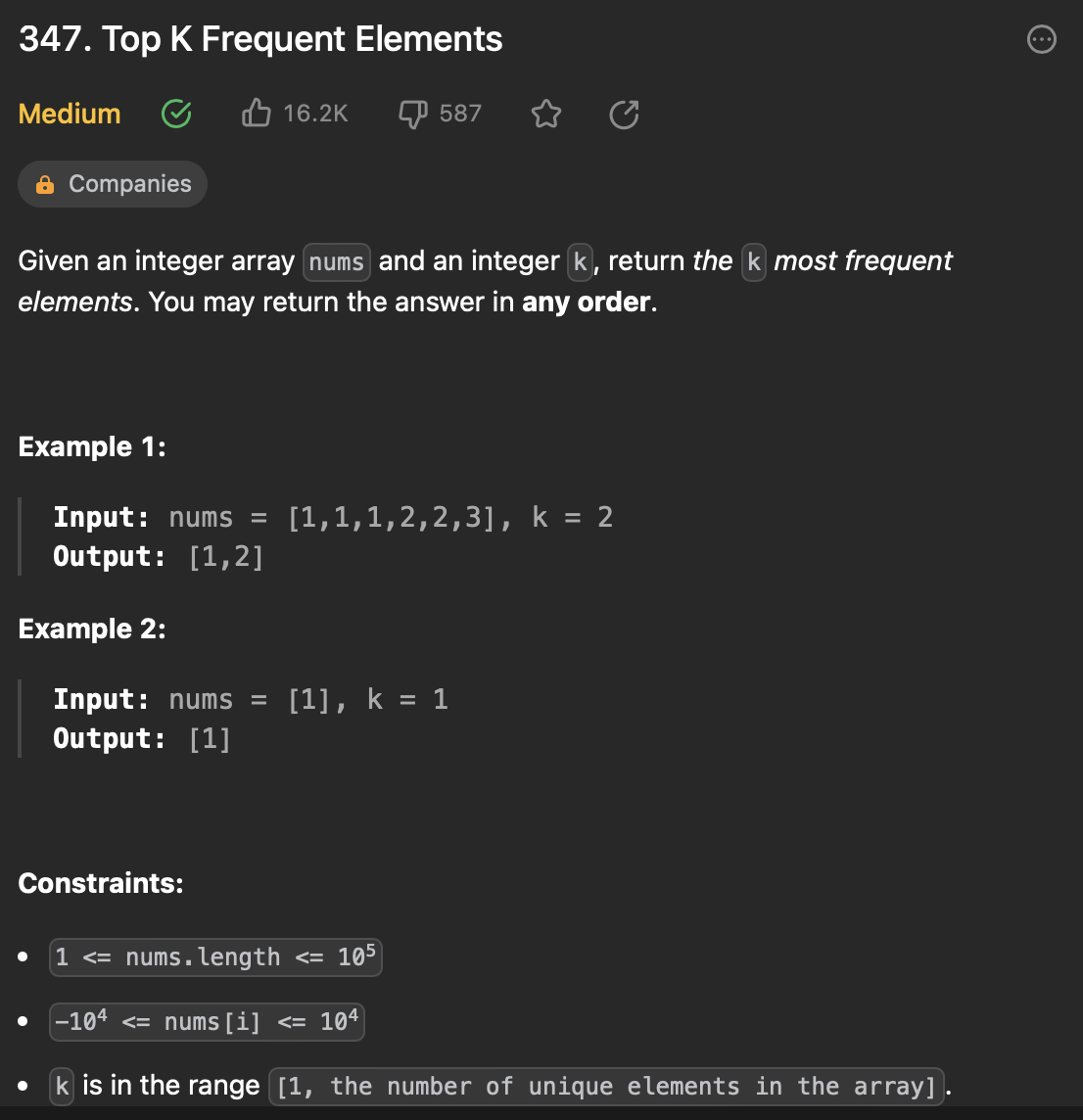

주어진 정수 배열에서, 빈도수가 가장 높은 k개의 정수 원소를 retrun함
문제 풀이 방법
collections의 Counter나, dictionary에 넣어서 비교해서 풀면 easy 문제겠지.. 하지만 그런 방법밖에 생각이 안나 버린나.
내 코드
시간복잡도 O(n log n) nums를 탐색하는 n과 딕셔너리를 sorting하는 nlogn, 공간복잡도 O(n)
class Solution:
def topKFrequent(self, nums:list[int], k:int)->list[int]:
numDict= {}
for num in nums:
numDict[num] = 1+numDict.get(num, 0)
return [i for i,v in sorted(numDict.items(), key=lambda x: x[1], reverse=True)][:k]
Counter(nums)를 사용하여 nums 리스트의 요소를 세어 딕셔너리로 변환합하므로 O(n)이며, counter.most_common(k)를 사용하여 빈도가 가장 높은 상위 k개 요소를 추출합니다. most_common 메서드는 내부적으로 우선순위 큐를 사용하여 빠르게 상위 k 요소를 추출해서 시간 복잡도는 O(k log n)임.
최종적으로, 전체 코드의 시간 복잡도는 O(n + k log n)임 여기서 n은 nums 리스트의 요소 수이고, k는 반환할 상위 k 요소의 개수임
Counter(nums)를 사용하여 nums 리스트의 요소를 딕셔너리로 변환하는데, 이 딕셔너리는 각 고유한 요소의 빈도를 저장합니다. 따라서 딕셔너리의 크기는 nums 리스트에서 고유한 요소의 수에 따라 결정되므로 O(n)과 리스트에서 최대 k개의 요소를 가지므로 전체 공간 복잡도는 O(n + k)
class Solution:
def topKFrequent(self, nums:list[int], k:int)->list[int]:
numDict= {}
for num in nums:
numDict[num] = 1+numDict.get(num, 0)
return [i for i,v in sorted(numDict.items(), key=lambda x: x[1], reverse=True)][:k]
다른 풀이 시간복잡도 O(n), 공간복잡도 O(n+k)로 푸는 방법이다.
먼저 빈도 k는 아무리 해도 주어진 nums의 길이를 넘지 못하므로,
임시로 0부터 nums의 길이 만큼의 빈 배열을 만들어 놓는다.
다음으로 정수배열 num의 count를 한 dictionary를 만든 후,
각 num를 key로 두고 빈도(횟수)를 value로 저장했던 dictionary를 만든 후에
위에서 만들어 놨던 배열의 인덱스를 횟수라고 생각하고, 임시 배열의 인덱스(빈도)에 해당 num 원소를 넣고,
해당 임시 배열을 탐색하면서, k개 만큼 원소를 가져와 return 한다.
이러면 O(n), O(n+k) 로 가능
class Solution:
def topKFrequent(self, nums:list[int], k:int)->list[int]:
ans = []
cnt = {}
freq = [[] for _ in range(len(nums)+1)]
for n in nums:
cnt[n] = 1+cnt.get(n,0)
for n,c in cnt.items():
freq[c].append(n)
for i in range(len(freq)-1, 0, -1):
for num in freq[i]:
ans.append(num)
if len(ans)==k:
return ans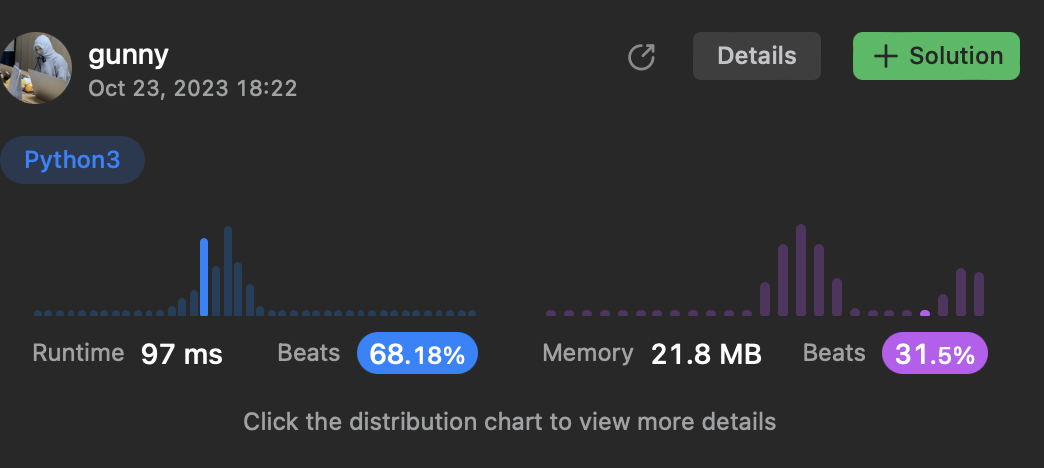
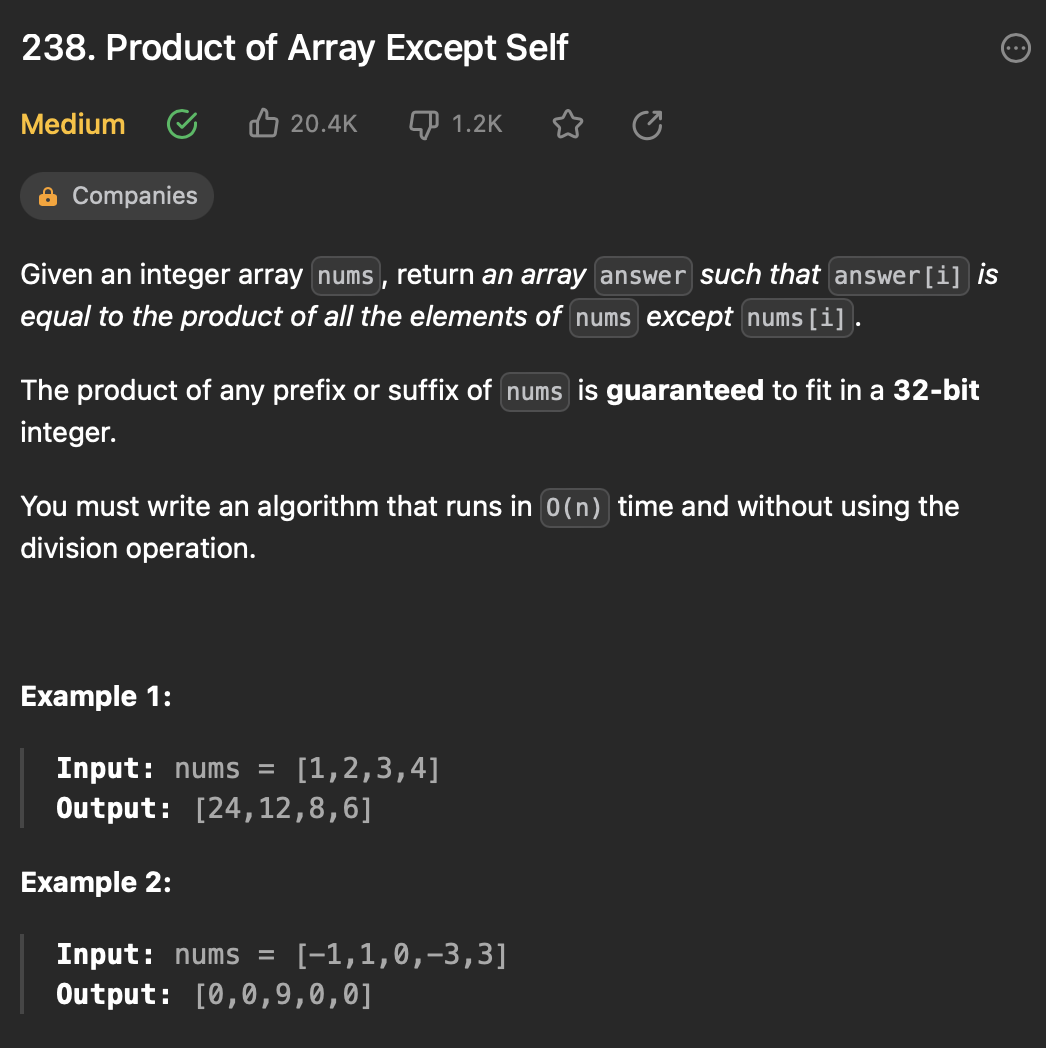
[6] 238. Product of Array Except Self
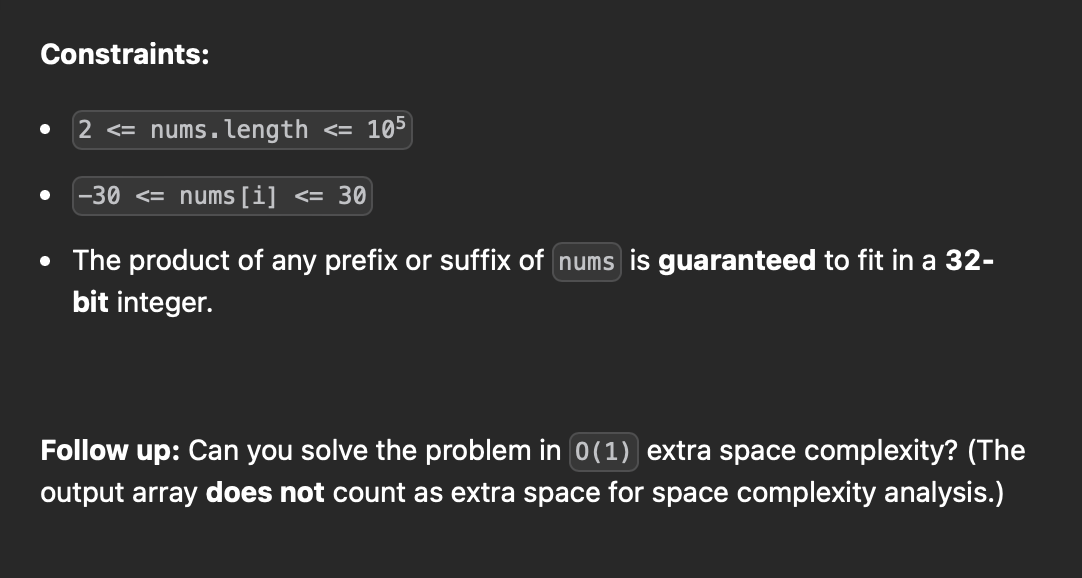
문제 설명
문제 풀이 방법
처음 시도는 nums 배열을 탐색 하면서 해당 인덱스 기준으로 nums 배열을 슬라이싱해서 임시 배열은 만든 후, reduce로 배열의 곱을 구하는 방식으로 진행했는데, 시간복잡도가 O(n^2) 라서 TLE 가 났다!
문제에 prefix, postfix 가 있었지만 기억도 안나고 어떻게 풀어야 할지 감도 안왔음..
일단 Neetcode 도움을 받긴했다.
현재 인덱스를 제외하고 배열의 원소들의 곱을 구하기 위해서는 현재 인덱스로부터 앞까지의 곱 prefix 와, 현재 인덱스를 제외하고 그 뒤에서 배열 끝까지의 곱 postfix를 가지고 구할 수 있는데
prefix와 postfix 배열을 따로따로 두고 곱을 구하면 O(n^) 가 될 수 있으므로
임시 배열 하나에 prefix와 postfix를 곱한 값을 저장해 나가면 O(n)으로 해결할 수 있다.
예전 1월달에 푼 기록을 봤는데 그때도 나는 reduce를 쓰면서 삽질하고 있었음..
문제를 잘못이해한거지~
암튼 이건 약간 수학적 사고가 있어야하는 것 같다 기억하자 prefix, postfix!!
내 코드
class Solution:
def productExceptSelf(self, nums: list[int]) -> list[int]:
ans = [1] * (len(nums))
prefix, postfix = 1,1
for i in range(len(nums)):
ans[i] = prefix
prefix *= nums[i]
for i in range(len(nums)-1, -1, -1):
ans[i] *= postfix
postfix *= nums[i]
return ans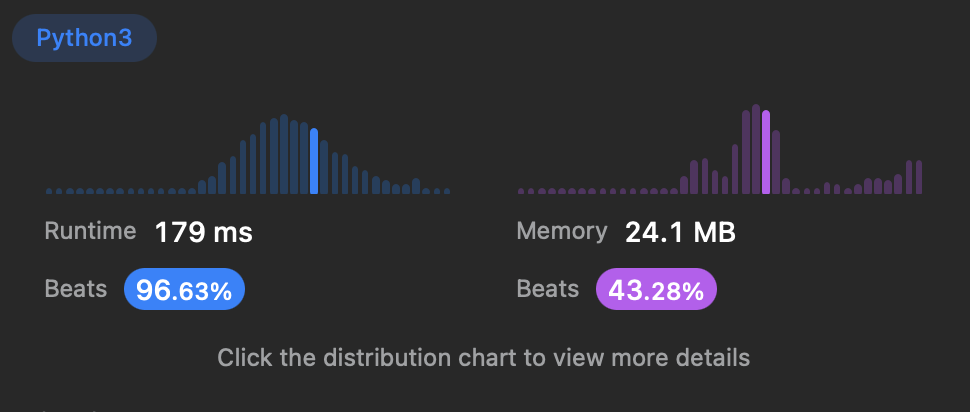
[7] 36. Valid Sudoku
문제 설명
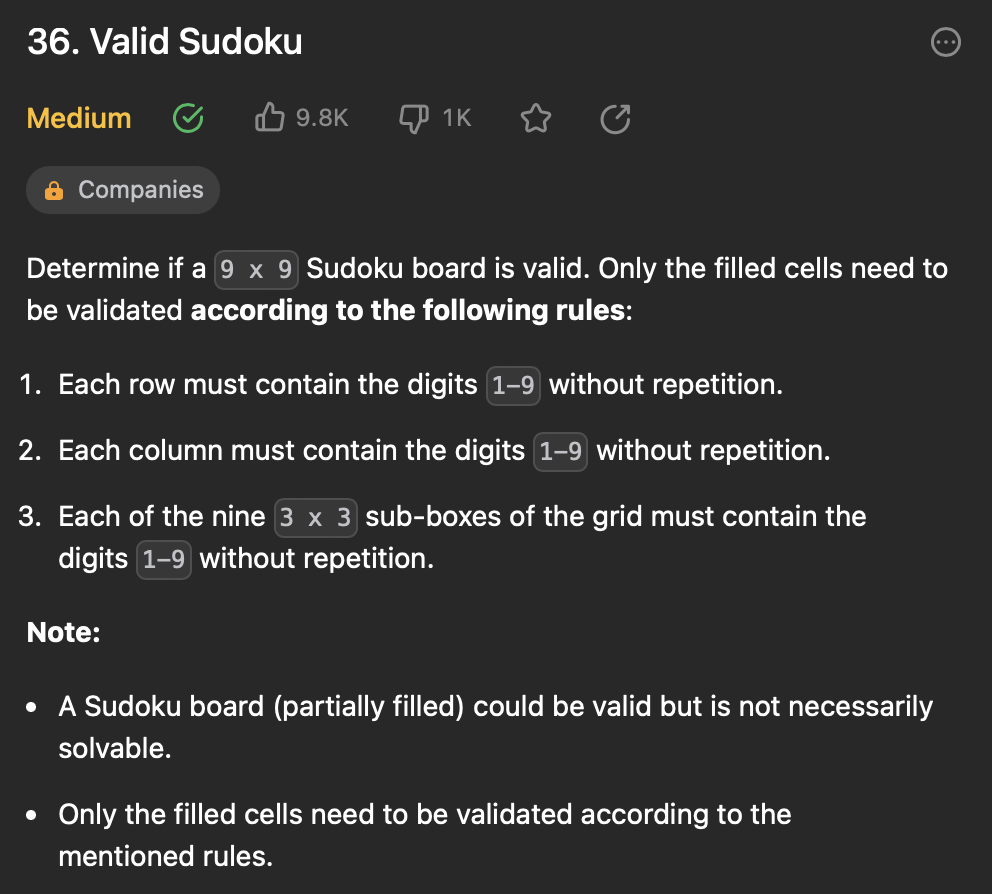

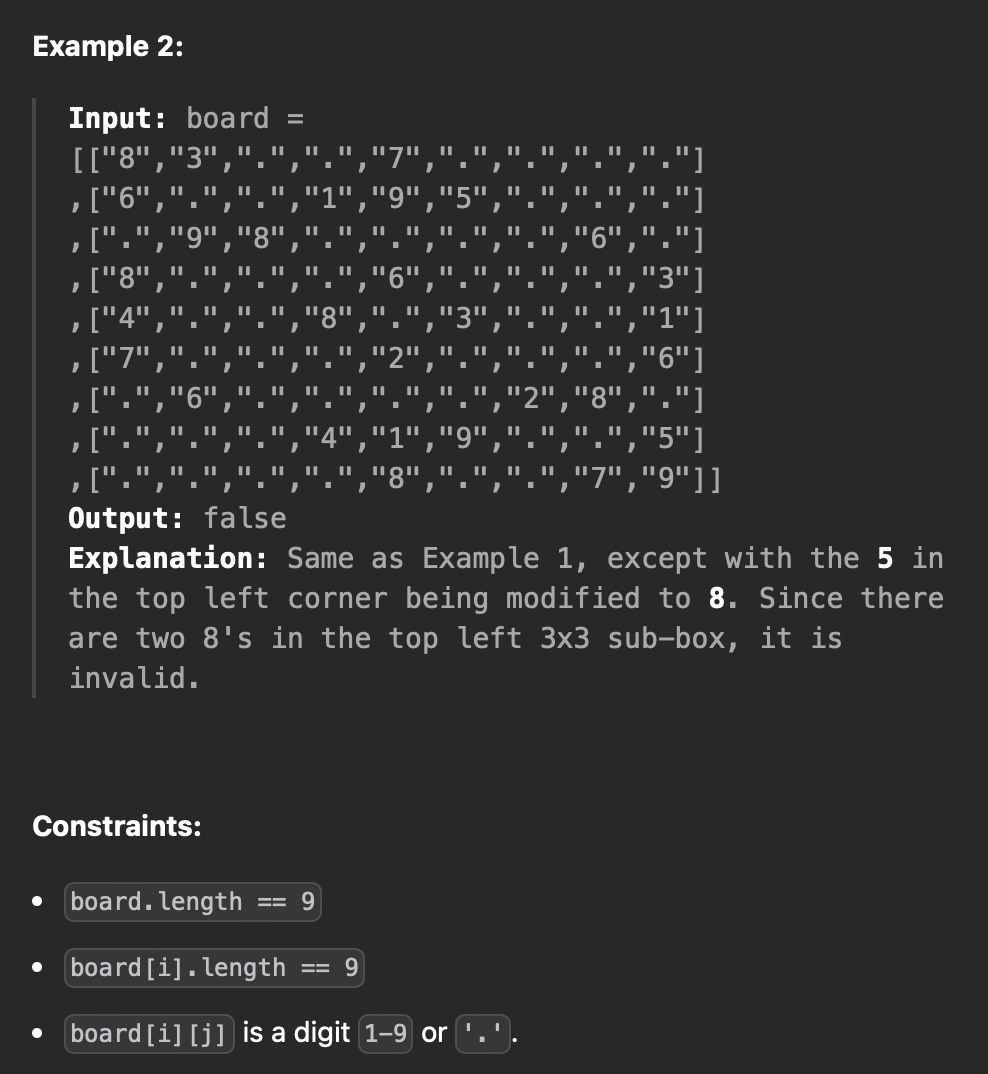
9x9 행렬의 스토쿠 보드가 주어질 때 아래의 조건에 맞춰서
(1) 각 행에는 1~9의 숫자가 반복 없이 포함되어야 함
(2) 각 열에는 1~9의 숫자가 반복 없이 포함되어야 함
(3) 그리드의 9개의 3 x 3 하위 상자 각각에는 숫자 1-9가 반복 없이 포함되어야 함
유효한 스토쿠 보드이면 True, 아니면 False를 return 한다.
문제 풀이 방법
주어진 스토쿠에 해당하는 유한한 숫자를 입력하는 것이 아니라
위에 있는 3가지의 조건어 맞는지에 대한 유효성 검사만 하면 되는 것이다.
해당 보드의 열, 행, 그리고 3x3 형태의 작은 사각형 (9x9로 구성되어 있어서 총 행, 열에 3x3 서브 사각형으로 구성됨)
각 행,열,사각형에 duplicates한 숫자가 들어가야 하므로
각 행,열,사각형에 해당하는 set 자료구조를 만든 후에
board의 원소를 한 줄씩 탐색해가며, 위에서 만든 행,열,사각형 set 자료구조안에 board의 원소를 넣어서 update한다. '.' 이라면 빈칸이니 continue 넘어가고, 탐색하는 도중에 행이나 열, 사각형 셋 set 자료 안에 넣었던 board의 원소가 있다면 바로 False를 반환한다.
모든 board의 원소를 search 했다면 True를 반환한다.
여기서의 포인트는 현재의 board 좌표가 어느 서브 사각형에 있는지를 찾아내는 것이 관건이다.
이는 각 서브 사각형의 행,열의 길이 3의 몫으로 나눠 사각형의 위치를 찾아낼 수 있다.
내 코드
class Solution:
def longestConsecutive(self, nums: list[int]) -> int:
numSet = set(nums)
length, longest = 0, 0
for n in numSet:
if (n-1) not in numSet:
length =1
while (n+length) in numSet:
length +=1
longest = max(longest, length)
return longest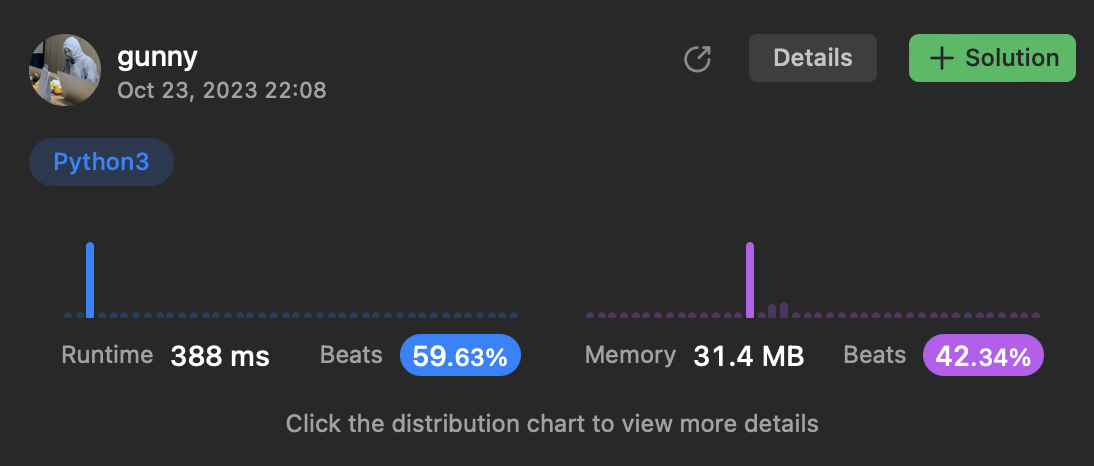
[8] 128. Longest Consecutive Sequence
문제 설명
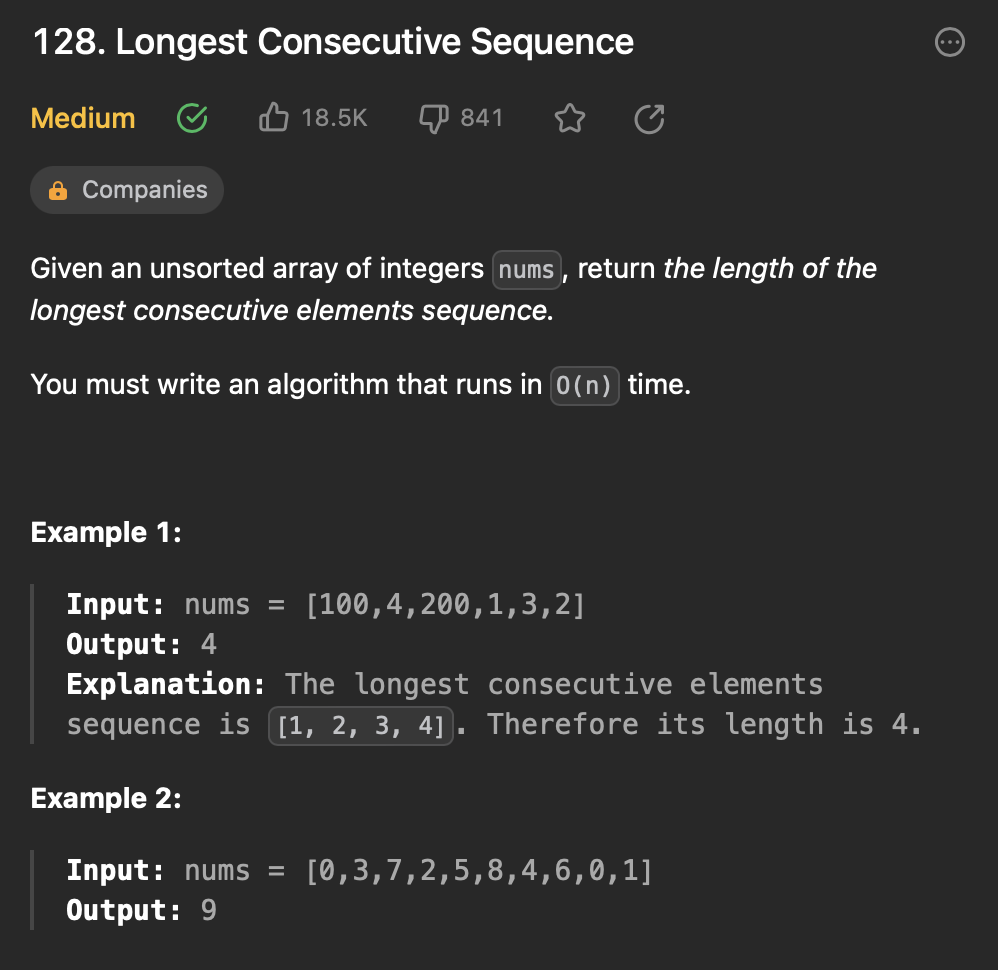
정렬되지 않는 정수 배열이 주어질 때, 가장 긴 연속 요소의 배열을 return 하는 시간복잡도 O(n) 알고리즘을 작성하기
문제 풀이 방법
이것도 도통 아이디어가 떠오르지 않아서 O(nlogn) 이나 o(n^2)이라도 풀어보려고,
class Solution:
def longestConsecutive(self, nums: list[int]) -> int:
if len(nums)==0:
return 0
nums = sorted(nums)
maxCnt=1
cnt = 1
for i in range(len(nums)-1):
if nums[i]+1 == nums[i+1]:
cnt +=1
maxCnt = max(maxCnt, cnt)
else:
cnt = 1
return maxCntnums를 정렬하고, 돌면서 maxCnt를 찾았는데 테스트케이스 40번째
nums=[1,2,0,1] 에서 걸렸다.. 근데 0,1,2 에서 걸렸음 ㅠㅠ
해당 문제를 푸는 접근법은, 주어진 배열을 연속된 sequence 로 나누고,
그 sequence의 길이 중 가장 긴 길이를 return 하는 것으로 접근해야한다.
예를 들면 nums = [100,4,200,1,3,2]
가 있다면 nums의 섹션은 [1,2,3,4], [100], [200] 연속된 sequence는 총 3개이다.
이걸 어떻게 O(n)으로 나눌 수 있을까?
배열에서의 삽입, search가 O(n)으로 가능하려면 hash map 자료구조를 사용해야하고
dictionary 혹은 set을 이용한다.
이 문제는 주어진 nums을 set으로 만든 numSet이라는 자료구조를 하나 생성하고 O(n)
이 numSet을 돌면서, 해당 원소의 -1 값이 numSet이 있는지 없는지 확인 한 후
없다면 length를 기본 1로, 그 이후에 그 다음값이 있는지 while 문으로 확인하면서 최대 길이를 찾아가야 한다.
여기서 해당 원소의 -1을 왜 numSet에서 찾느냐 하면,
위의 주어진 3개의 연속된 sequence들은 모두 첫번째 원소가 가장 작은 숫자이므로, 그 앞에 숫자가 있다면 연속됐을 것이고 없기 때문에 끊어졌을 것이기 때문임 (발설명..)
내 코드
class Solution:
def longestConsecutive(self, nums: list[int]) -> int:
numSet = set(nums)
length, longest = 0, 0
for n in numSet:
if (n-1) not in numSet:
length =1
while (n+length) in numSet:
length +=1
longest = max(longest, length)
return longest
여담
1단계 Array+Hashing 8문제 다시 풀고 정리하는데 하루 종일 걸린거 레전드 인생~
하지만 다음에는 훅훅 풀겠지 이번에는 꼼꼼하게 하고 넘어갔으니까
근데 또 못 푼다? 그럼 걍... 죽어야지 뭐

