AutoGen > Use Cases > Enhanced Inference
https://microsoft.github.io/autogen/0.2/docs/Use-Cases/enhanced_inference
Enhanced Inference
autogen.OpenAIWrapper는 opnai>=1 버전에서 고급 LLM 추론 기능을 제공한다. autogen.Completion은 openai.Completion 및 openai.ChatCompletion의 대체제로, openai<1에서 고급 LLM 추론을 위한 드롭인 방식의 대안이다.
AUtoGen을 이용해 추론을 수행하면 다음과 같은 다양한 이점을 누릴 수 있다.
성능 조정, API 통합, 캐싱, 오류 처리, 다중 설정 추론, 결과 필터링, 템플릿 처리 등.
Tune Inference Parameters(for openai <1)
openai<1 용 추론 파라미터 조정의 예시 목록은 다음 페이지에서 확인 가능하다
Tune Inference Parameters Examples
https://microsoft.github.io/autogen/0.2/docs/Examples#inference-hyperparameters-tuning
Choices to optimize
최적화 가능한 항목들을 살펴보면, Foundation Model(파운데이션 모델)을 사용한 텍스트 생성의 비용은 일반적으로 입력과 출력 토큰 수의 총합으로 측정된다. 파운데이션 모델을 사용하는 애플리케이션 개발자의 관점에서 보면, 정해진 추론 예산(예: 코딩 문제 하나를 푸는데 평균적으로 소모되는 비용) 내에서 생성된 텍스트의 유용성을 극대화하는 것이 목표이다.
이 목표는 추론 하이퍼파라미터를 최적화함으로써 달성할 수 있으며, 이는 생성 결과의 유용성과 비용에 큰 영향을 준다.
조정 가능한 주요 하이퍼파라미터들을 살펴보면,
(1) model : 사용할 모델 ID를 지정하는 필수 항목
(2) prompt/messages : 모델에 입력되는 프롬프트 또는 메시지. 생성 작업의 맥락을 제공한다.
(3) max_tokens : 생성될 최대 토큰 수
(4) temperature: 생성 결과의 무작위성을 조절하는 값(0~1). 값이 높을수록 다양하고 창읮거인 결과이고 낮을 수록 예측 가능한 결과가 나온다.
(5) top_p : 각 토큰 생성 시 고려할 누적 확률 질량의 범위를 설정하는 값(0~1). 값이 낮으면 더 확실한 토큰만 고려하고 높으면 다양성을 높일 수 있다.
(6) n : 프롬프트당 생성할 응답 수. 응답 수가 많을 수록 다양성 증가, 하지만 비용도 함께 증가한다.
(7) stop : 출력 중 해당 문자열이 생성되면 중단되도록 설정한다.
(8) presence_penalty, frequency_penalty : 특정 단어나 구의 존재 및 반복에 대한 생성 영향력을 조절한다.
(9) best_of : 여러 응답 중 가장 확률이 높은 결과를 선택하도록 서버 측에서 응답을 여러 개 설정한다.
하이퍼파라미터 간의 상호작용 및 주의점으로는 temperature 와 top_p는 둘 다 생성의 무작위성을 조절하기 떄문에 같이 조정하면 충돌할 수 있다. 또한 n과 best_of는 일반적으로 같이 조정하지 않는 것이 좋다. n과 max_tokens는 전체 생성 토큰 수에 영향을 주므로, 결과적으로 비용에 영향을 준다.
이러한 상호작용과 trade-off(트레이드 오프) 때문에 수작업으로 최적의 하이퍼파라미터를 찾는 것은 매우 어렵다.
이러한 선택들이 실제로 중요한지에 대해서 아래 블로그 글에서의 gpt-3.5-turbo, gpt-4에 대한 튜닝 결과 예시를 확인 가능하다.
blogpost(exapmle tuning results)
https://microsoft.github.io/autogen/0.2/blog/2023/04/21/LLM-tuning-math/
AutoGen으로 추론을 튜닝할 때는 다음 요소들이 필요하다.
(1) Validiation data 검증 데이터
(2) Evaluation function 평가 함수
(3) Metric 최적화할 지표
(4) Search space 탐색 공간
(5) Budgets 예산 (추론 및 최적화)
Validation data (검증 데이터)
다양한 인스턴스를 수집하여 dict 형식의 반복 가능한 객체로 저장한다.
이러한 인스턴스는 dict의 반복 가능한 객체에 저장할 수 있다. 예를 들어, 각 인스턴스 dict는 "problem"을 키로, 수학 문제의 설명 str을 값으로, "solution"을 키로, 해답 str을 값으로 포함할 수 있다.
{"problem": "수학 문제 설명", "solution": "해답"}Evaluation function (평가 함수)
평가 함수는 응답 리스트와 검증 데이터의 키워드 인자를 받아 성능 지표(metrics)가 담긴 dict을 반환해야 한다.
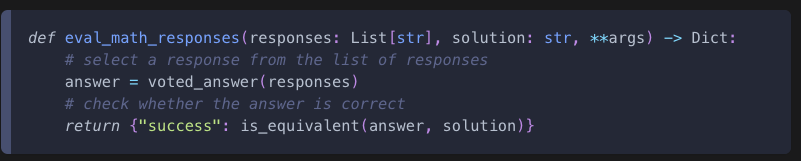
autogen.code_utils 와 autogen.math_utils는 코드 생성 및 수학 문제 풀이를 위한 예시 평가 함수들을 제공한다.
Metric to optimize
최적화할 지표는 일반적으로 튜닝에 사용되는 모든 데이터 인스턴스에 대한 집계된 메트릭이다. 예를 들어, 사용자는 "suceess"를 지표로 하고 최적화 모드를 "max"로 설정할 수 있다. 기본적으로 평균(average)를 집계 함수로 사용한다. 사용자가 필요하다면, 커스터마이즈된 집계 함수를 직접 제공할 수 있다.
Search space (탐색 공간)
사용자는 각 하이퍼파라미터에 대해 선택적으로 탐색 범위를 지정할 수 있다.
(1) model
- 고정 문자열(str)로 지정하거나,
flaml.tune.choice를 사용해 여러 선택지를 제공할 수 있다.
(2)prompt / messages - prompt는 문자열 또는 문자열 리스트로서, 프롬프트 템플릿을 의미한다.
- messages는 딕셔너리의 리스트 또는 딕셔너리 리스트들의 리스트 형태로, 메시지 템플릿을 나타낸다.
- 각 프롬프트/메시지 템플릿은 각각의 데이터 인스턴스에 따라 포맷팅된다.
예를 들어 프롬프트 템플릿은 다음과 같을 수 있다.
"{problem} Solve the problem carefully. Simplify your answer as much as possible. Put the final answer in \boxed{{}}."이 경우 {problem}은 각 데이터 인스턴스의 "problem" 필드로 대체된다.
(3) max_tokens, n, best_of
- 이들은 고정된 값으로 지정하거나,
flaml.tune.randint,flaml.tune.qrandint,laml.tune.lograndint,flaml.qlograndint등을 사용하여 탐색 범위를 지정할 수 있다. - 기본적으로
max_tokens는[50, 1000)범위에서 탐색되며n은[1, 100)범위에서 탐색된다. best_of는 기본적으로 1로 고정된다.
(4) stop
0 문자열(str), 문자열 리스트, 문자열 리스트들의 리스트, 또는 None일 수 있다. 기본값은 None이다.
(5) temperature 또는 top_p
- 이 둘중 하나는
flaml.tune.uniform,flaml.tune.loguniform등으로 지정하거나 고정된 값으로 설정할 수 있다. - 둘은 동시에 지정하지 않는다
- 기본적으로
[0,1]구간에서temperatrue또는top_p중 하나를 임의로 선택하여 구성한다.
(6) presence_penalty, frequency_penalty
- 고정값으로 지정하거나
flaml.tune.uniform을 통해 설정할 수 있다. - 기본적으로는 튜닝되지 않는다.
Budgets
Inference budget(추론 예산) 은 데이터 인스턴스당 평균 추론 비용을 의미한다.
Optimization budget(최적화 예산)은 튜닝 과정 전체에서 사용할 수 있는 총 예산을 의미한다. 두 예산 모두 달러 기준, 1000 토큰당 가격을 따른다.
Perform tuning
이제 autogen.Completion.tune을 사용해 튜닝을 수행할 수 있다.
예를 들어 num_samples는 샘플링할 설정의 수를 의미한다.
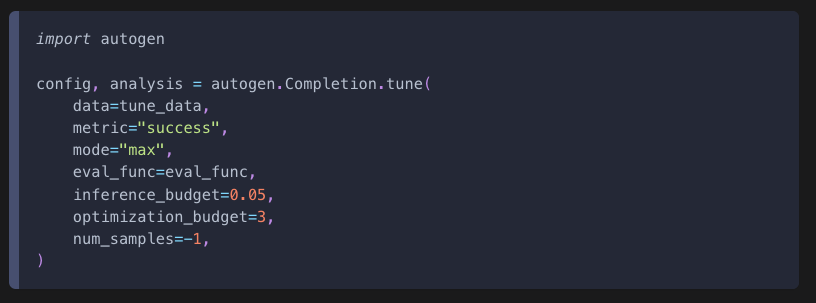
-1로 설정하면 최적화 예산이 소진될 때까지 무제한으로 샘플링한다.
리턴된 config 객체에는 최적화된 설정이 포함되어 있으며, analysis 객체에는 시도된 모든 설정과 결과가 포함된 ExperimentAnalysis 객체가 포함된다.
튜닝된 config는 추론 수행에 그대로 사용할 수 있다.
(참고로 예시 docs에는 autogen.Complection을 사용할 수 있다고하지만, autogen에 init 파일에 Complection 클래스가 정의되어 있지 않았다. 그래서 캡쳐로 대체함)
API unification
autogen.OpenAIWrapper.create()는 chat(채팅모델)과 non-chat(비채팅 모델) 모두에 대해 생성(completion)을 만들 수 있으며 OpenAI API와 Azure OpenAI API 양쪽 모두에서 사용할 수 있다.
from autogen import OpenAIWrapper
client = OpenAIWrapper()
response = client.create(messages=[
{
"role" : "user",
"content" : "2+2=",
}
],
model='gpt-3.5-turbo')
print(client.extract_text_or_completion_object(response))
"""
['4']
"""
print(response.cost)
"""
8.5e-06
"""로컬 LLM의 경우, FastChat과 같은 패키지를 사용해 엔드포인트를 실행한 다음, 동일한 API를 사용해 요청을 보낼 수 있다. 로컬 LLM을 사용해 추론하는 예제는 아래에서 확인 가능하다.
Examples on inference with local LLMs
https://microsoft.github.io/autogen/0.2/blog/2023/07/14/Local-LLMs/
Usage Summary
autogen의 OpenAIWrapper는 API 호출 시 토큰 수 및 비용을 추적한다.
create() 메서드를 사용하여 요청을 시작하고, print_usage_summary()를 호출하여 전체 사용 내역(캐시된 요청과 실제 요청 모두 포함)의 비용 및 토큰 사용량을 확인할 수 있다.
model=["actual", "total"](기본값) : 모든 생성 요청 및 캐시되지 않은 요청에 대한 사용 요약을 출력한다.model='actual': 캐시되지 않은 요청만 출력한다.model='total: 전체 요청 (캐시 포함)에 대한 사용 정보를 출력한다.
필요한 경우 clear_usage_summary()를 사용하여 세션의 사용 정보를 초기화할 수 있다. 관련 예제는 아래의 노트북을 참고하면 된다.
clear_usage_summary() view notebook
https://github.com/microsoft/autogen/blob/0.2/notebook/agentchat_cost_token_tracking.ipynb
예제 사용법
from autogen import OpenAIWrapper
client= OpenAIWrapper()
client.create(
messages=[
{
"role" : "user",
"content" : "Python learnign tips."
}
],
model = "gpt-3.5-turbo",
)
client.print_usage_summary()
client.clear_usage_summary()
"""
----------------------------------------------------------------------------------------------------
Usage summary excluding cached usage:
Total cost: 0.00044
* Model 'gpt-3.5-turbo-0125': cost: 0.00044, prompt_tokens: 12, completion_tokens: 287, total_tokens: 299
All completions are non-cached: the total cost with cached completions is the same as actual cost.
----------------------------------------------------------------------------------------------------
"""참고로 사용자 지정 모델 클라이언트(custom model client)를 사용하는 경우, 만약 해당 클라이언트에 사용 요약 기능이 구현되어 있지 않다면, 사용 요약은 제공되지 않는다.
Caching
캐싱은 autoGen의 User Guide의 LLM Caching으로 옮겨갔다.
해당 부분은 User Guide에서 다시 언급하겠다.
AutoGen > User Guide > LLM Caching
https://microsoft.github.io/autogen/0.2/docs/topics/llm-caching/
Error handling
Runtime error
서로 다른 모델/엔드포인트의 설정 목록을 전달하여 속도 제한(rate litmit)이나 기타 런타임 오류를 완화할 수 있다.
예를 들어
from autogen import OpenAIWrapper
from config import settings
open_ai_api_key = settings.openai_api_key.get_secret_value()
anthropic_api_key = settings.anthropic_api_key.get_secret_value()
client = OpenAIWrapper(
config_list=[
{
"model" : "gpt-4o-mini",
"api_key": open_ai_api_key,
},
{
"model" : "gpt-3.5-turbo",
"api_key" : open_ai_api_key,
},
{
"model" : "claude-3-5-haiku-20241022",
"api_key" : anthropic_api_key,
},
]
)
공식 docs의 예시는 아래와 같다.
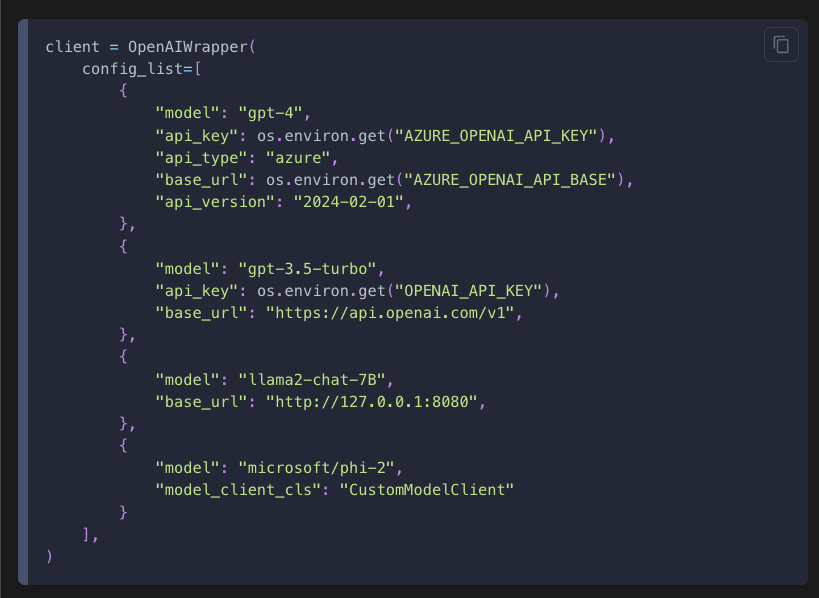
client.create()는 Azure OpenAI의 GPT-4, OpenAI의 GPT-3.5-turbo, 로컬에서 호스팅된 llama2-chat-7B, 그리고 사용자 정의 모델 클라이언트 클래스인 CustomModelClient를 사용하는 phi-2를 하나씩 순차적으로 쿼리하여 유효한 결과가 나올 때까지 시도한다. 이는 속도 제한이 병목인 상황에서 개발 속도를 높일 수 있다.
마지막 선택이 실패하면 오류가 발생하므로, 가장 안정적인 모델을 마지막에 배치하는 것이 좋다.
편의를 위해 다음과 같은 설정 로드 유틸리티 함수들이 제공된다.
(1) get_config_list : 주로 제공된 API 키를 기반으로 API 호출을 위한 설정을 생성한다.
(2) config_list_openai_aoai : 환경 변수나 로컬 파일에서 API 키를 불러와, Azure OpenAI와 OpenAI 엔드포인트 모두를 사용하는 설정 목록을 구성한다.
(3) config_list_from_json: 환경 변수나 로컬 JSON 파일에서 JSON 구조로 된 설정을 불러오며, 필터링 기준에 따라 설정을 추려낼 수 있는 유연성이 있다.
(4) config_list_from_models: 지정된 모델 리스트를 기반으로 설정을 생성하며, 특정 모델만 타겟팅할 때 유용하다.
(5) config_list_from_dotenv: .env 파일에서 설정 목록을 구성하며, 다수의 API 설정 및 키를 하나의 파일에서 통합 관리할 수 있도록 한다.
다양한 모델 엔드포인트 설정 방법에 대한 전체 코드 예제를 확인하려면 아래의 링크를 참고하면 된다. User Guide의 LLM Configuration에 있어, 해당 부분도 User Guide 할때 더 자세히 알아보도록 할 것이다.
model endpoint settings
https://microsoft.github.io/autogen/0.2/docs/topics/llm_configuration/
Logic error
또 다른 유형의 오류는 응답이 특정 요구 조건을 만족하지 못하는 경우이다. 예를 들어 응답이 유효한 JSON 문자열 이여야 할 때, 그렇지 않은 응답은 필터링하고 싶을 수 있다.
이를 위해 a list of configurations(설정 목록) 과 a filter function(필터 함수)를 제공할 수 있다.
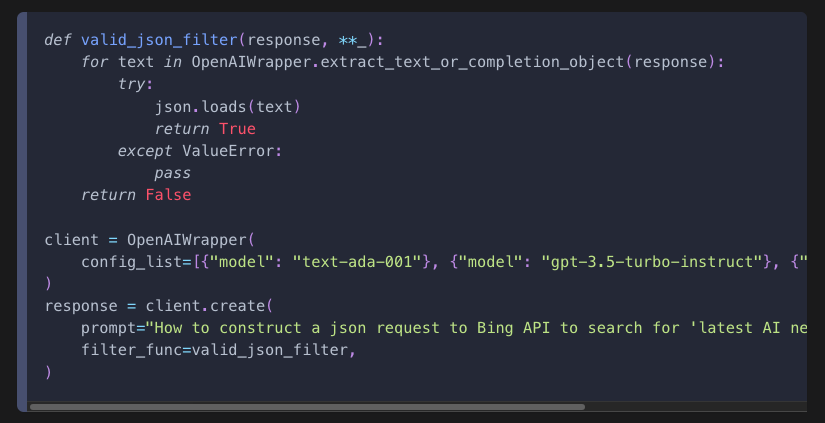
위 예제는 test-ada-001, gpt-3.5-tubor-instruct, text-davinci-003을 순차적으로 시도해서 유효한 JSON 문자열이 반환되면 멈추고, 아니면 마지막 설정까지 진행한다.
또한 동일한 모델을 여러 번 반복해서 리스트에 넣는 것도 가능 하다. 예를 들어 서로 다른 시드를 주어 하나의 모델을 여러 번 시도하여 최종 응답의 견고성을 높일 수 있다.
하지만 현재 (25.04.24 기준 text-davinci-003 모델은 없으므로 예시를 대체한다.
import json
from autogen import OpenAIWrapper
config_list = [
{
"model": "text-ada-001",
},
{
"model" : "gpt-3.5-turbo-instruct"
},
]
def valid_json_filter(response, **_):
for text in OpenAIWrapper.extract_text_or_completion_object(response):
try:
json.loads(text)
return True
except ValueError:
pass
return False
client = OpenAIWrapper(
config_list=config_list,
)
response = client.create(
prompt="How to construct a json request to Bing API to search for 'latest AI news'? Return the JSON request.",
filter_func=valid_json_filter,
)
response
Completion(id='cmpl-BPglxEpdWNN4q1X8GDrgY0rSNGdNr', choices=[CompletionChoice(finish_reason='length', index=0, logprobs=None, text="\nThe JSON request to Bing API for searching 'latest AI news' would look")], created=1745462317, model='gpt-3.5-turbo-instruct:20230824-v2', object='text_completion', system_fingerprint=None, usage=CompletionUsage(completion_tokens=16, prompt_tokens=22, total_tokens=38, completion_tokens_details=None, prompt_tokens_details=None), cost=0, message_retrieval_function=<bound method OpenAIClient.message_retrieval of <autogen.oai.client.OpenAIClient object at 0x11f7c2990>>, config_id=1, pass_filter=False)Templating
(해당 부분부터 docs로 테스트 해볼 시 되지 않아서 내용은 여기까지만 정리)
제공된 prompt나 message가 템플릿인 경우, 주어진 context(문맥)을 바탕으로 자동으로 완성된다.
템플릿은 format 문자열(str.format) 형식일 수도 있고, 아래 예시처럼 여러 입력 필드로부터 문자열을 생성하는 함수 일수도 있습니다.
요약하자면, AutoGen에서는 프롬프트나 메시지를 미리 정의된 템플릿 형태로 만들어주고, 나중에 필요한 값들을 채워넣어 자동으로 실제 메시지를 생성할 수 있다는 뜻이다.
