Corrective RAG
paper : https://blog.langchain.dev/agentic-rag-with-langgraph/
reference : https://blog.langchain.dev/agentic-rag-with-langgraph/
Abstract
대규모 언어 모델(LLM)은 생성된 텍스트의 정확성이 모델이 내재적으로 가진 파라메트릭 지식만으로는 보장될 수 없기 때문에 필연적으로 환각(hallucination) 을 발생시킨다. 검색 증강 생성(Retrieval-Augmented Generation, RAG)은 LLM을 보완할 수 있는 실용적인 방법이지만, 검색된 문서의 관련성에 크게 의존하므로 검색 과정에서 오류가 발생하면 모델이 어떻게 동작할지에 대한 우려가 있다.
이를 해결하기 위해 우리는 생성의 강건성을 향상시키기 위한 Corrective Retrieval-Augmented Generation, CRAG)를 제안한다.
질의(query)에 대해 검색된 문서들의 전체적인 품질을 평가하는 경량 검색 평가 모듈을 설계하고, 이를 통해 검색에 대한 신뢰도를 산출하고, 이에 따라 다양한 검색 액션을 실행할 수 있도록 한다.
정적인 제한된 코퍼스에서의 검색은 suboptimal document(최적 보다 못한 문서) 만을 반환할 수 있어, 검색 결과를 보강하기 위해 대규모 웹 검색을 추가적으로 활용한다. 또한 검색된 문서에서 핵심 정보를 선별하고 불필요한 정보를 제거하기 위해 분해 후 재구성(decompose-tehn-recompose) 알고리즘을 설계했다.
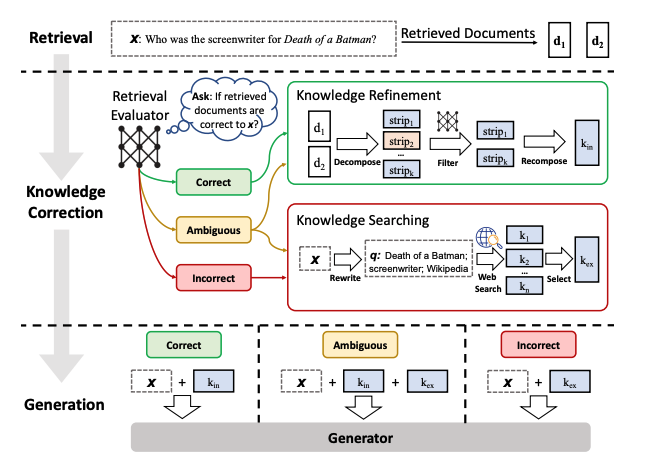
Corrective RAG(CRAG)의 아이디어는 아래와 같다.
- 쿼리에 대해 검색된 문서들의 전반적인 품질을 평가하기 위해 경량화 된 검색 평가기를 사용하며, 각 문서에 대해 신뢰도 점수를 반환한다.
- 벡터스토어 기반 검색 결과가 애매하거나 사용자 질의와 무관하다고 판단되면, 웹 기반 문서 검색을 추가적으로 수행해 문맥을 보완한다.
- 검색된 문서를 지식 조각(knowledge strips)으로 분할한 뒤, 각 조각을 평가 및 필터링하여 무관한 내용을 제거하는 방식으로 지식 정제(knowledge refinement)를 수행한다.
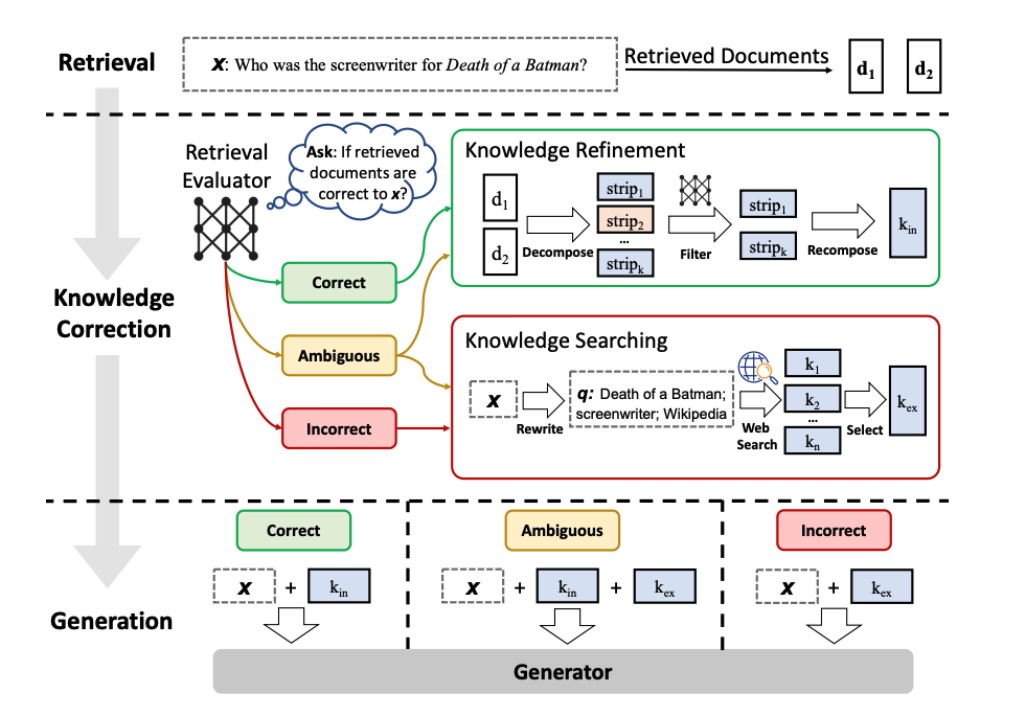
그림 : CRAG 다이어그램
이 워크플로우를 설명하기 위해, 몇 가지 단순화 및 조정을 거쳐 그래프 구조로 표현할 수 있다. (필요에 따라 커스터마이징 및 확장 가능)
- 처음에는 지식 정제(knowledge refinement) 단계를 생략한다. 흥미롭고 유용한 후처리 방식이지만, LangGraph로 구현시 이 워크플로우의 전체 구조를 이해하는데 필수는 아니다.
- 만약 어떤 문서가 이 쿼리와 무관하다고 판단되면, 보안을 위해 웹 검색을 수행한다. 이때 빠르고 사용하기 편리하게 Tavily Search API를 활용할 수 있다.
- 웹 검색 최적화를 위해 query rewriting을 적용한다.
- 이진 분기를 위한 판단에 Pydnatic을 사용해 출력을 모델링하고, 이를 OpenAI tool로 등록해 LLM이 실행될 때마다 자동으로 호출되도록 한다. 이 방식을 통해 논리 분기 조건에서 일관된 이진 로직을 유지할 수 있다.
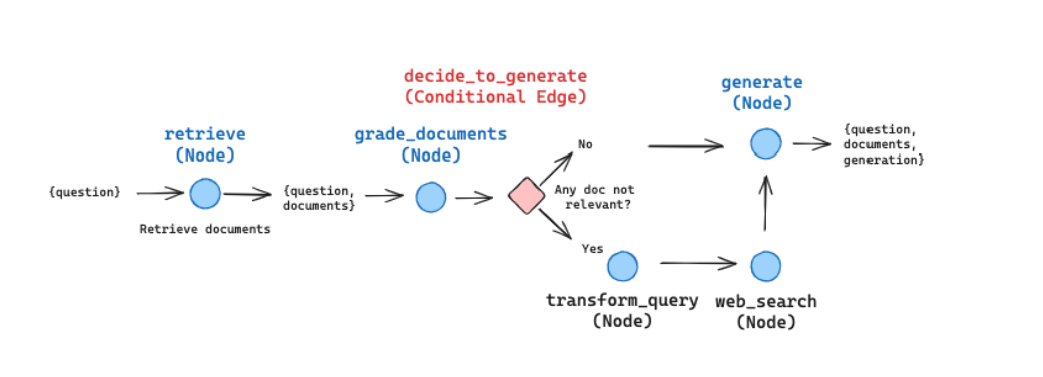
그림 : LangGraph로 구현한 CRAG
해당 레퍼런스 사이트에서는 블로그 포스트 3개를 인덱싱하고, 관련된 정보를 질의했을 때 실행 흐름(trace)를 확인할 수 있도록 하는 jupyter notebook을 공유하고 있다. (jupyter notebook 내용 : 각 노드간의 논리적 흐름을 명확하게 보여주는 코드로, 블로그 포스트의 주제를 벗어난 질문을 하게 된다면, 조건 분기 로직의 하단 경로가 호출되서 Tavliy 웹 검색을 통해 보조 문서를 수집하고, 이를 기반으로 최종 응답을 생성한다. )
Corrective RAG (CRAG) jupyter notebook
: https://github.com/langchain-ai/langgraph/blob/main/examples/rag/langgraph_crag.ipynb?ref=blog.langchain.dev
LangGraph : https://smith.langchain.com/public/af0a82ae-69e6-4314-9c63-03ca49e56864/r?ref=blog.langchain.dev
