Self-Reflective RAG with LangGraph
reference : https://blog.langchain.dev/agentic-rag-with-langgraph/
Motivation
- 대부분의 대형 언어 모델(LLM)은 주기적으로 공개 데이터의 방대한 코퍼스를 기반으로 학습되기 때문에, 최신 정보나 학습에 사용할 수 없는 비공개 데이터를 포함하지 못하는 한계가 있다.
이 문제를 해결하기 위해 LLM을 외부 데이터 소스에 연결하는 검색 기반 생성(RAG, Retrieval Augmented Generation) 방식이 LLM 응용 개발의 핵심 패러다임으로 떠오르고 있다.
- 기본적인 RAG 파이프라인은 다음과 같은 흐름으로 구성된다.
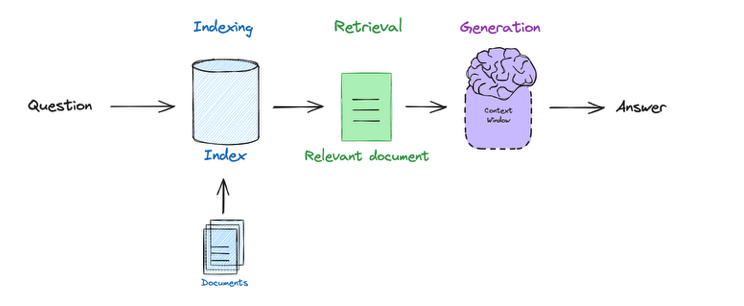
그림 : Basic RAG flow
(1) 사용자의 질의를 임베딩(벡터화)하고,
(2) 해당 잘의와 관련된 문서를 검색한 후,
(3) 검색된 문서를 기반으로 LLM이 답변을 생성
이렇게 하면 모델의 답변이 실제 문맥에 기반하게 되어 정확성과 신뢰도를 높일 수 있다.
Self-Reflective RAG
- 실제 구현에서 RAG는 단순한 파이프라인이 아니라 논리적인 의사결정을 요구하는 경우가 많다.
예를 들어- 언제 문서를 검색할 것인가? (질문 내용과 인덱스 구성을 고려해서)
- 더 나은 검색을 위해 질문을 다시 써야 할까?
- 검색된 문서가 관련 없을 때, 무시하고 다시 검색해야 할까?
-
이처럼 부정확한 검색 결과나 생성 결과를 LLM이 스스로 진단하고 수정하는 방식을 Self-Reflective RAG 라고 한다.
-
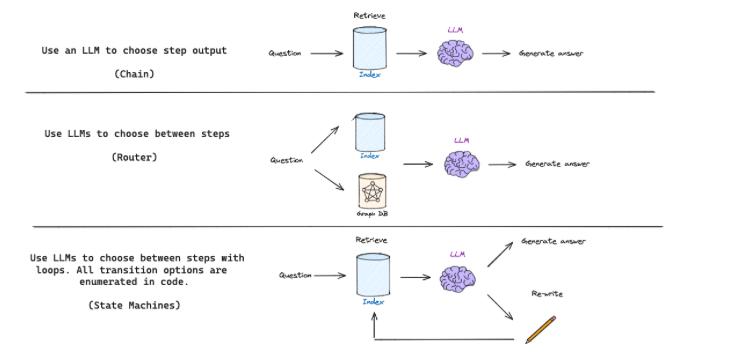
기본적인 RAG 플로우는 단순한 체인 구조로, 검색된 문서를 바탕으로 LLM이 응답을 생성하는 방식이다.
좀 더 복잡한 RAG 흐름에서는 라우팅(routing)을 도입해서 질문의 종류에 따라 다양한 검색기(retriever) 중 어떤 것을 사용할지 LLM이 선택하도록 한다. -
하지만 Self-Reflective RAG는 보통 다음과 같은 피드백 메커니즘이 필요하다.
- 질문을 다시 생성하거나 (re-generate query)
- 문서를 다시 검색하는 (re-retrieve) 과정
이러한 피드백 루프를 유연하게 관리하기 위해서는 state machine 같은
인지 아키텍처(cognitive architecture)가 유용하다
cognivite architecture(인지 아키텍처) :
-
state machine 은 다음과 같은 단계를 정의하고, 그 사이의 전이 조건을 명확하게 설정할 수 있도록 해준다.
- 예 : 검색 -> 문서 평가 -> 질문 재작성 -> 재검색
- 조건 : 검색된 문서가 적절하지 않으면 -> 질문을 다시 쓰고 -> 문서를 다시 검색
이러한 방식은 복잡한 흐름 제어를 가능하게 하고, RAG의 정확성과 효율성을 높이는데 유리하다.
Self-Reflective RAG with LangGraph
- 최근에는 langGraph가 출시되어, LLM 기반의 state machine을 쉽게 구현할 수 있는 도구로 다양한 RAG 플로우를 유연하게 구성할 수 있게 한다.
- 특히 문서 평가(document grading) 같은 명시적인 결정 지정(decision point)와 재검색(re-try retrieval) 같은 루프 구조를 포함한 RAG의 플로우 엔지니어링(flow engineering)에 매우 적합하다.
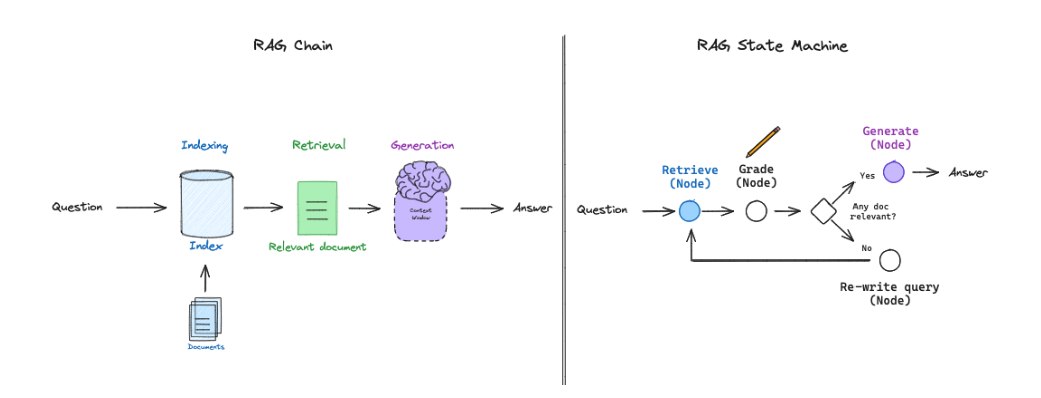
그림 : 복잡한 RAG 흐름을 State machines으로 설계함
- langGraph는 유연해서, Self-Reflective RAG 연구의 CRAG와 Self RAG가 langGraph로 구현이 가능하다.
Corrective RAG(CRAG) :
**
