해당 게시물은 DeepLearningAI의 LangChain Chat with Your Data 강의를 듣고 개인적으로 정리한 내용입니다.
Instruction
LangChain을 사용해서 ChatGPT와 같은 대규모 언어 모델(LLM)을 사용해서
다양한 주제에 대한 질문에 답할 수 있다.
범용 LLM은 자신이 교육받은 내용만 알고 있기 때문에 개인 데이터에 특화되어 개인적인 질문에 대해서는 답하기 어렵다.
자신이 가지고 있는 데이터를 기반으로 대화를 나누고 그 정보를 사용하여 질문에 대답하는 LLM을 사용하는 방법이 있다.
바로 LangChain을 사용하는 방법이다.

LangChain은 자신이 가지고 있는 데이터를 기반으로 대화를 생성할 수 있다.
LangChain은 오픈 소스, LLM 애플리케이션 구축을 위한 개발 프레임워크이다.
LangChain은 모듈식 구성요소로 프롬프트(prompts), 모델(model), 인덱스(index), 체인(chains), 에이전트(agents)로 구성되어 있다.

먼저 LangChain 문서 로더를 사용하여 다양하고 흥미로운 소스에서 데이터를 로드하는 방법을 다루고,
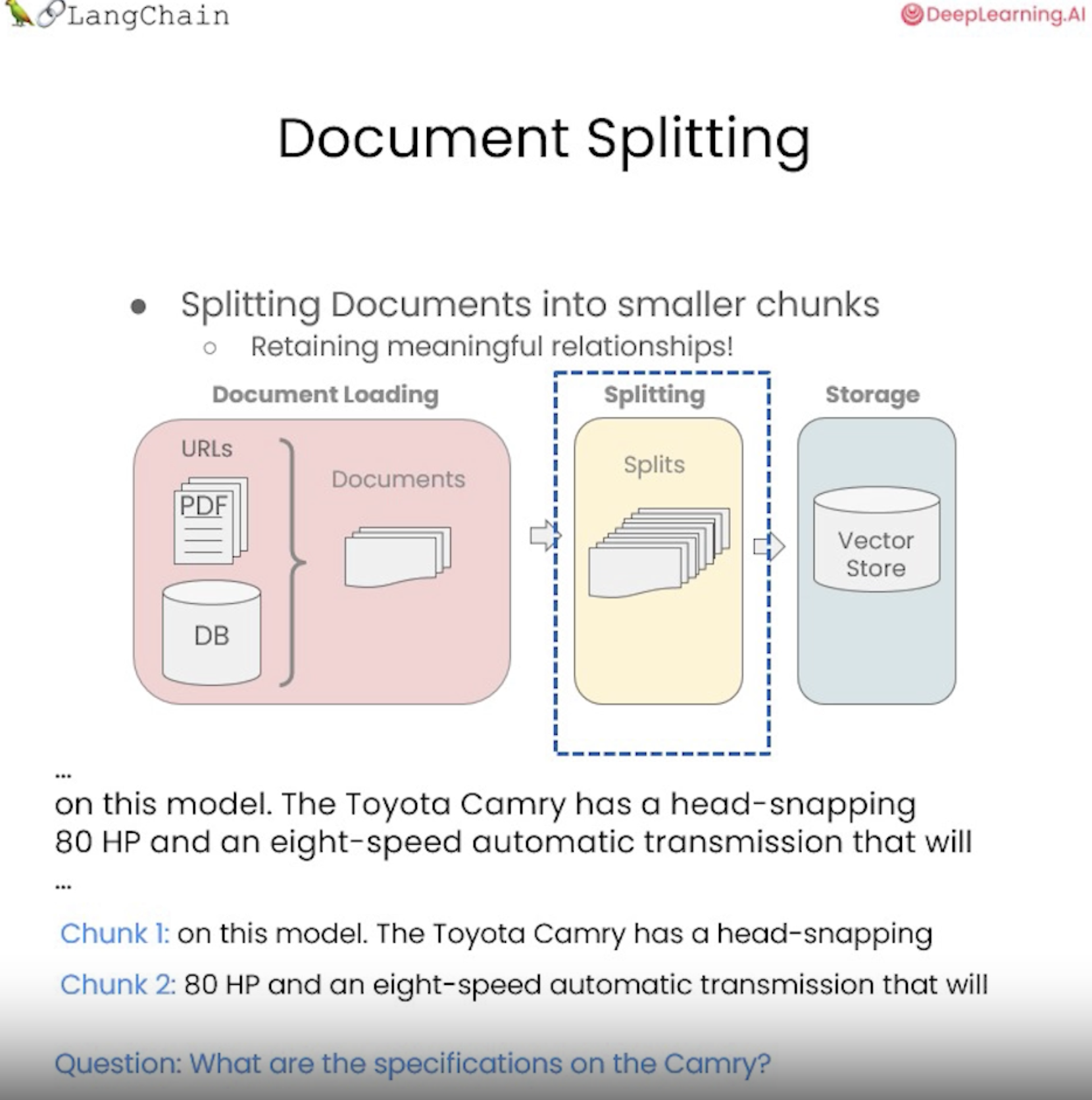
그런 다음 이러한 문서를 의미상 의미 있는 덩어리로 분할하는 방법을 알아본다.
이 전처리 단계는 간단해 보이지만 미묘한 차이가 많다.
다음으로 사용자 질문에 따라 관련 정보를 가져오는 기본 방법인 의미 검색(semantic search)에 대한 개요를 알아본다. 이것은 시작하기 가장 쉬운 방법이지만 실패하는 경우가 여러 가지가 있는데,
이러한 사례를 살펴본 다음 이를 해결하는 방법을 살펴본다.
그런 다음 검색된 문서를 사용하여 LLM이 문서에 대한 질문에 답변할 수 있도록 하는 방법을 보여 주고, 해당 챗봇 경험을 완전히 재현하기 위해서 메모리를 다루고, 이를 구축하는 방법을 진행한다.
그러면 데이터와 대화할 수 있는 완전한 기능을 갖춘 챗봇이 될 수 있다.
01. document_loading
데이터와 채팅할 수 있는 애플리케이션을 만들려면 먼저 데이터를 사용할 수 있는 형식으로 로드해야 한다.
LangChain document loader는 80가지가 넘는 다양한 유형의 문서 로더를 보유하고 있다.

Document loader는 다양한 형식과 소스의 데이터에 액세스하고 표준화된 형식으로 변환하는 세부 사항을 처리한다.
웹사이트, 다양한 데이터베이스, YouTube 등 데이터를 로드하려는 다양한 위치가 있을 수 있으며 이러한 문서는 PDF, HTML, JSON과 같은 다양한 데이터 유형으로 제공될 수 있다.
따라서 Document Loader의 목적은 이러한 다양한 데이터 소스를 가져와 표준 문서 개체에 로드하는 것이다.
표준 문서 개체는 콘텐츠와 관련 메타데이터로 구성된다.

LangChain에는 다양한 유형의 문서 로더가 있으며 YouTube, Twitter, Hacker News와 같은 공개 데이터 소스에서 텍스트 파일과 같은 구조화되지 않은 데이터를 로드하는 작업을 처리하는 작업도 있고, 유저나 유저의 회사가 소유하고 있는 개인적인 데이터 소스에서 구조화되지 않은 데이터를 로드하는 작업을 처리할 수도 있다. figma 혹은 notion 처럼 정형화되지 않는 곳에서도 데이터를 로드할 수 있다.
Document Loader를 사용하여 구조화된 데이터를 로드할 수 있는데, 테이블 형식의 데이터이며 질문 답변이나 의미 체계 검색을 수행하려는 셀이나 행 중 하나에 일부 텍스트 데이터가 있을 수 있다.
Airbyte, Stripe, Airtable과 같은 것들 또한 로드가 가능하다.
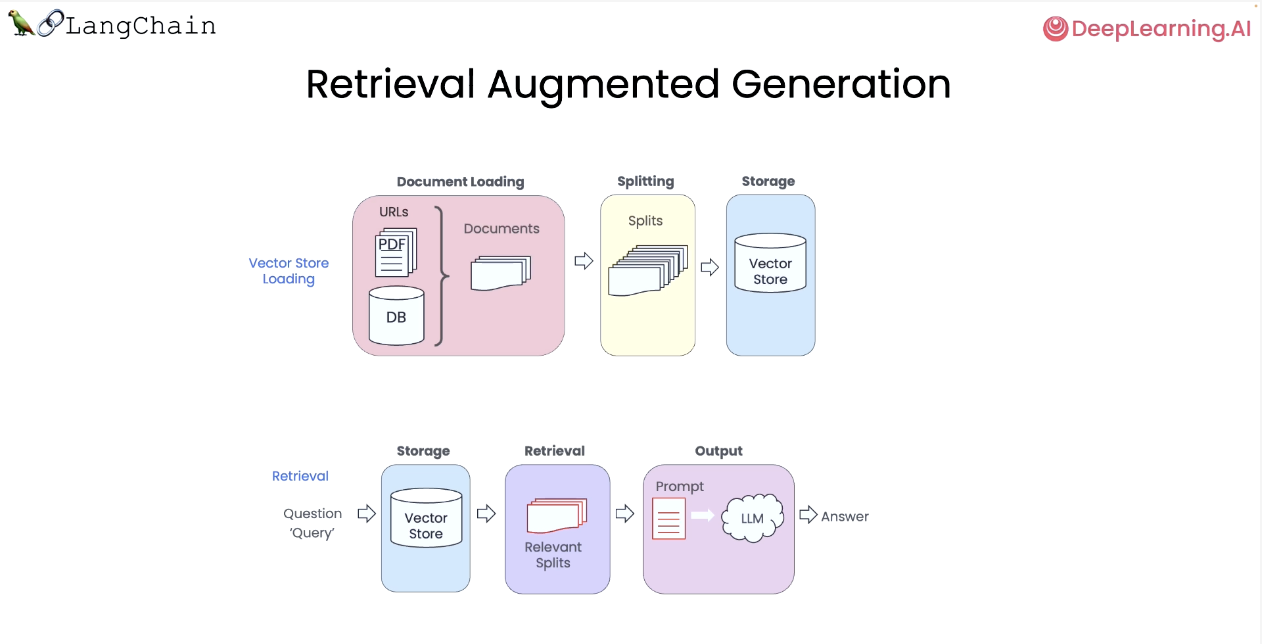
RAG(Retriver Argument Generation; 검색 증강 생성)
검색 증강 생성(RAG)에서 LLM은 실행의 외부 데이터세트에서 상황별 문서를 검색한다. 특정 문서(예: PDF, 비디오 세트 등)에 대해 질문하려는 경우에 유용하다.
기본적으로 OpenAI API 키와 같이 필요한 일부 환경 변수를 로드한다.
PDF 파일 로드하기
Langchain의 PyPDF 로더를 사용한다.
load 메소드를 호출하여 문서를 로드한다.
샘플 코드에서 현재 불러온 PDF에는 22개의 서로 다른 페이지가 있고, 각각은 고유한 문서이다.
첫 번째 장을 살펴보면 문서가 가장 먼저 구성되는 것은 페이지의 내용인 일부 페이지 콘텐츠이다. 조금 길 수 있으므로 처음 몇 백 글자만 프린트해본다.
정말 중요한 또 다른 정보는 각 문서와 관련된 메타데이터인데, 메타데이터 요소를 통해 액세스할 수 있다.
여기에서 두 개의 서로 다른 내용이 있는 걸 볼 수 있는데,
하나는 소스 정보, 이것은 우리가 로드한 파일의 이름인 PDF이고 다른 하나는 페이지 필드로 이는 로드된 PDF의 페이지에 해당한다.
Youtube 문서 파일 로드하기
다음 유형의 Document Loader는 YouTube에서의 파일이다.
유튜브에는 재미있는 콘텐츠가 많고,그래서 많은 사람들이 이 문서 로더를 사용하여 자신이 좋아하는 비디오나 강의 등에 대해 질문할 수 있다.
여기서는 몇 가지 다른 항목을 가져오는데, 핵심 부분은 YouTube 비디오에서 오디오 파일을 로드하는 YoutubeAudioLoader이고, 다른 핵심 부분은 OpenAIWhisperParser이다.
해당 모듈은 음성-텍스트 모델인 OpenAI의 Whisper 모델을 사용하여 YouTube 오디오를 작업할 수 있는 텍스트 형식으로 변환한다.
URL을 지정하고 오디오 파일을 저장할 디렉터리를 지정한 다음 OpenAIWhisperParser와 결합된 이 YoutubeAudioLoader의 조합으로 일반 로더를 생성할 수 있다.
그런 다음 "loader.load"를 호출하여 이 YouTube에 해당하는 문서를 로드한다.
이 작업은 몇 분 정도 걸릴 수 있다.
로드한 내용의 내용을 살펴보면, YouTube 비디오의 대본의 첫 번째 부분이다.
좋아하는 YouTube 동영상을 선택하고 작성되 스크립트가 적합한지 확인해볼 수도 있다.
인터넷 URL
다음 문서 세트는 인터넷의 URL이다.
LangChain에서 웹 기반 로더를 가져와서 이를 활성화하고, 임의의 URL을 선택한다.
예시로 GitHub 페이지에서 마크다운 파일을 선택하고 이에 대한 로더를 생성한다.
그런 다음 loader.load를 호출하면 페이지의 내용을 살펴볼 수 있다.
여기에는 많은 공백이 있고 그 뒤에 초기 텍스트가 있고 그 다음에는 추가 텍스트가 있는 것을 볼 수 있다.
이는 정보를 실행 가능한 형식으로 만들기 위해 실제로 정보에 대해 일부 사후 처리를 수행해야 하는 이유를 보여주는 좋은 예이다.
Notion 파일
마지막으로 Notion에서 데이터를 로드하는 방법이다.
Notion은 개인 및 회사 데이터 모두를 저장하는 매우 인기 있는 저장소이고, 많은 사람들이 Notion 데이터베이스와 통신하는 챗봇을 만든다.
노트북에는 Notion 데이터베이스의 데이터를 LangChain에 로드할 수 있는 형식으로 내보내는 방법에 대한 지침이 표시된다.해당 형식이 있으면 Notion 디렉터리로더를 사용하여 해당 데이터를 로드하고 작업할 수 있는 문서를 가져올 수 있다.
여기에 있는 내용을 살펴보면 마크다운 형식임을 알 수 있는데, 이 노션 문서는 블렌들(Blendle)의 직원 핸드북(Employee Handbook)에서 따온 것이다.
많은 사람들이 Notion을 사용하고, 이를 기반으로 채팅하고 싶은 Notion 데이터베이스가 있다고 할 때 해당 데이터를 내보내서 가져와 이 작업을 시작할 수 있다.
이렇게 다양한 문서를 로드하면서, 다양한 소스의 데이터를 표준화된 형태로 가져올 수 있다.
그러나 이러한 문서들은 크기가 크기 때문에, 이를 더 작은 덩어리로 분할해야 한다.
작은 문서로 분할하는 것은 RAG랄 수행할 때 중요하다.
RAG를 사용하려면 가장 관련성이 높은 콘텐츠 조각만 검색해야 하므로 여기에 로드한 전체 문서를 선택하는 것이 아니라 무엇에 가장 관련성이 높은 단락이나 몇 개의 문장만 선택하고 싶기 때문이다.
