해당 게시물은 DeepLearningAI의 LangChain Chat with Your Data 강의를 듣고 개인적으로 정리한 내용입니다.
LangChain Chat with Your Data
(2) Data Splitting
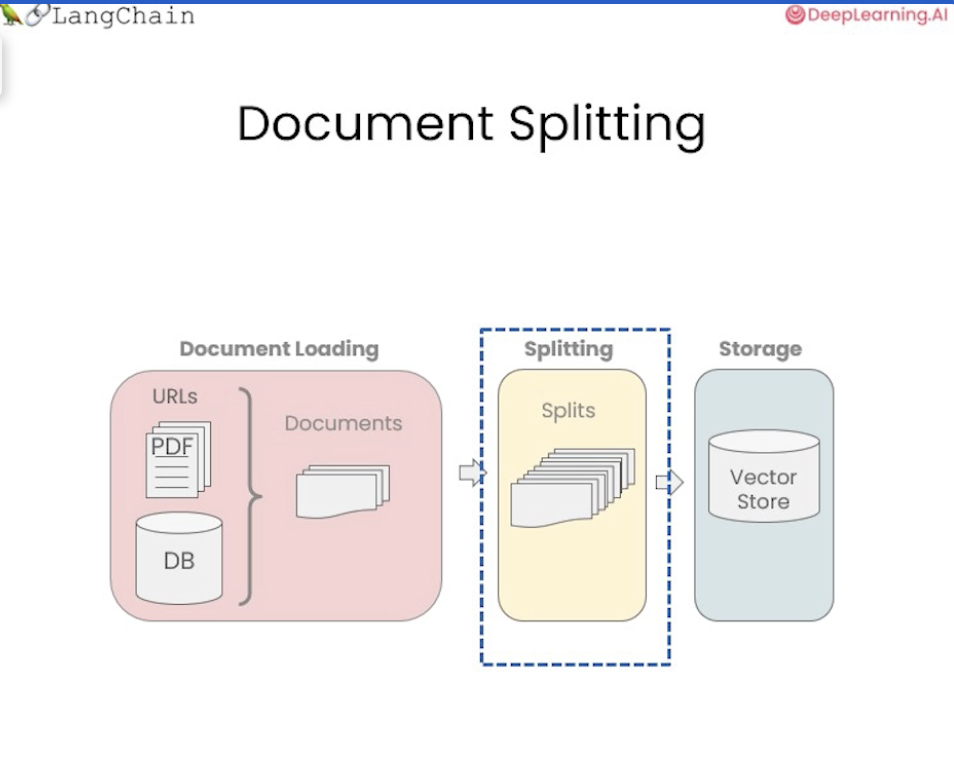
◼︎ Chunk
01에서 문서를 표준 형식으로 로드하는 방법을 알았다면, 로드해온 문서를 이제 더 작은 덩어리(chunk)로 나눈다.
바로 Data(Document) splitting이다.
Data splitting을 어떻게 하느냐에 따라서 미묘하게 미치는 영향이 달라질 수 있다.
Data splitting은 데이터를 문서 형식으로 로드한 후에 각 문자의 길이 등에 따라 청크를 분할할 수 있다.
하지만 이러한 방법은 조금 까다로울 수 있다.
아래의 그림과 같이 Toyota Camry와 일부 사양에 대한 문장을 볼 때,
...
on this models. The Toyota Camry has a head-snapping \
80 HP and an eight-speed automatric transmission that will \
... 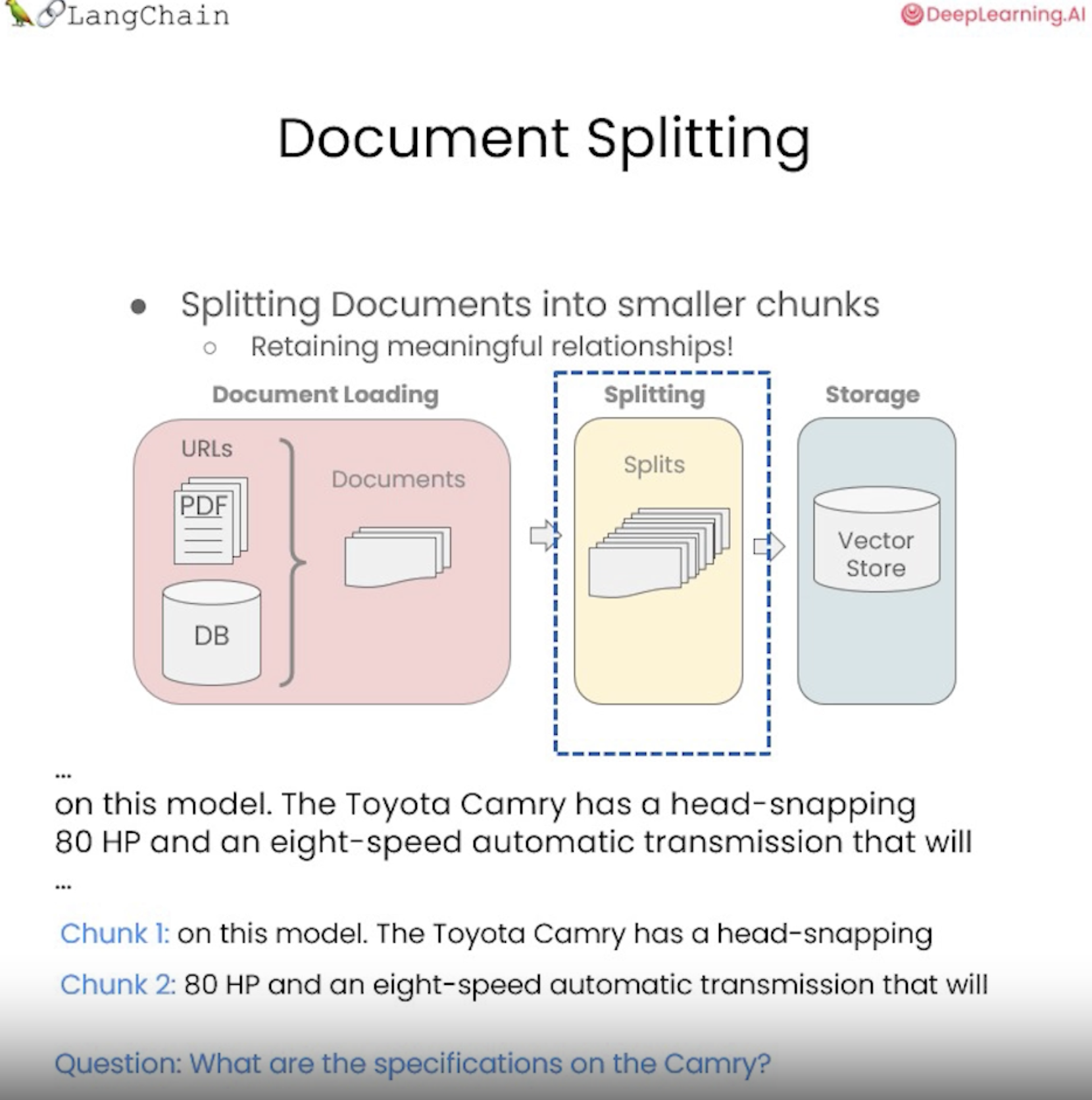
위와 같은 분할을 수행하면 문장의 일부가 한 chunk로 끝나고 문장의 다른 부분이 또 다른 chuck로 끝난다.
chunk 1은 on this model. The Toyota Camry has a head-snapping
chunk 2은 80 HP and an eight-speed automatic transmission that will
이 된다.
그런 다음 Camry의 사양이 무엇인지에 대한 질문에 대답하려고 할 때
(Question. What are the specifications on the Camry?)
실제로 두 chunk 모두 올바른 정보가 담기지 않고 분할되어있는 것을 볼 수 있다.
그래서 위 사양에 대한 질문에 정확하게 답할 수 없게된다.
따라서 의미상 관련된 chunk를 함께 얻기 위해 청크를 분할하는 방법은 중요하다.
◼︎ Splitter
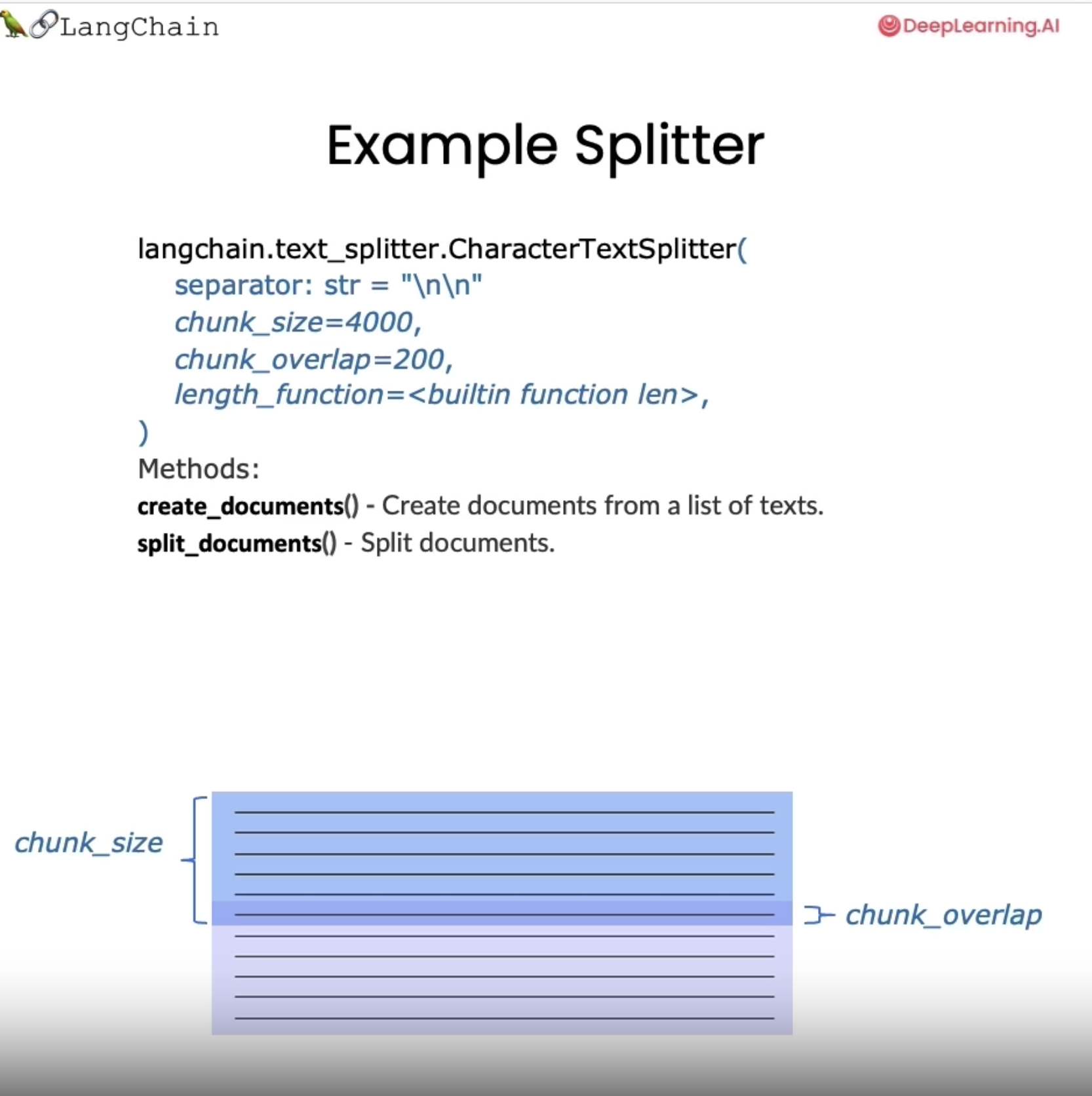
위 사진처럼 LangChain의 모든 텍스트 분할기(text_splitter)의 기본은 일부 chunk가 겹치는 일부 청크 크기의 청크로 분할하는 것을 포함한다.
청크 크기는 몇 가지 여러 방법으로 측정할 수 있는데, 청크의 크기를 측정하기 위해 길이 함수를 전달할 수 있고, 대개 문자 또는 토큰으로 측정한다.
청크 겹침(chunk_overlap)은 일반적으로 한 청크에서 다른 청크로 이동할 때 슬라이딩 창처럼 두 청크 사이에 약간의 중첩으로 유지된다. 이를 통해 동일한 컨텍스트 조각이 한 청크의 끝과 다른 청크의 시작에 있을 수 있으며 일관성에 대한 개념을 만드는 데 도움이 된다.
LangChain의 텍스트 분할기는 모두 문서 생성 및 문서 분할 방법을 가지고 있고, 여기에는 내부적으로 동일한 논리가 포함되며 즉 텍스트 목록을 가져오는 인터페이스와 문서 목록을 가져오는 약간 다른 인터페이스를 노출할 뿐이다.

LangChain에는 다양한 유형의 분할기/스플리터(splitter)가 있으며, 이러한 텍스트 분할기는 다양한 차원에 따라 다르다. 청크를 분할하는 방법과
문자열별인지 토큰 별인지에 청크의 길이를 측정하는 방법에 따라 달라질 수 있다.
다른 작은 모델을 사용하여 문장의 끝이 언제인지 결정하고 이를 덩어리를 분할하는 방법으로 사용하는 경우도 있다.
청크로 분할하는 데 있어 또 다른 중요한 부분은 메타데이터이다.
모든 청크에 걸쳐 동일한 메타데이터를 유지하면서 관련성이 있는 경우 새로운 메타데이터 조각을 추가하므로 실제로 이에 초점을 맞춘 일부 텍스트 분할기가 있다.
청크 분할은 작업 중인 문서 유형에 따라 달라지는 경우가 많으며 이는 코드를 분할할 때 더욱 명확해진다.
Language() 텍스트 분할기는 Python, Ruby, C와 같은 다양한 언어에 대한 구분으로, 이러한 문서를 분할할 때 다양한 언어와 해당 언어에 대한 관련 구분 기호를 고려합니다.
◼︎ Splitter example code (1)
- 먼저 Open AI API 키를 로딩하여 이전과 같이 환경을 설정한다.
import os
import openai
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
openai.api_key = os.environ['OPENAI_API_KEY']- 다음으로 LangChain에서 가장 일반적인 유형의 텍스트 분할기 두 가지를 import 한다. recursive character text splitter(재귀 문자 텍스트 분할기) 와 the character text splitter(문자 텍스트 분할기) 이다.
from langchain.text_splitter import RecursiveCharacterTextSplitter, CharacterTextSplitter- 상대적으로 작은 청크 크기인 26을 설정하고 더 작은 청크 오버랩인 4를 설정해본다.
chunk_size = 26
chunk_overlap = 4이 두 가지 다른 텍스트 분할기를 r splitter, c splitter로 초기화하고 각각 재귀와 문자 분할기로 할당한다.
r_splitter = RecursiveCharacterTextSplitter(
chunk_size = chunk_size,
chunk_overlap = chunk_overlap
)
c_splitter = CharacterTextSplitter(
chunk_size = chunk_size,
chunk_overlap = chunk_overlap
)그런 다음 몇 가지 다른 사용 사례를 살펴본다.
a부터 z까지 첫 번째 문자열을 로드하고, 위 splitter로 사용하여 분할기의 값을 확인해본다.
text1 = 'abcdefghijklmnopqrstuvwxyz'
print(r_splitter.split_text(text1))output : 
재귀 문자 텍스트 분할기로 분할하면 여전히 하나의 문자열로 끝난다.
이는 길이가 26자이고 청크 크기를 26으로 지정했기 때문이다.
따라서 실제로 여기서는 분할을 수행할 필요가 없었다.
output

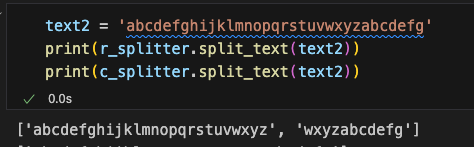
그러면, 청크 크기로 지정한 26자보다 긴 약간 긴 문자열에 대해 수행해본다면,
두 개의 서로 다른 청크가 생성되는 것을 볼 수 있다.
첫 번째 청크는 a-z로 26자이고, 다음 청크는 'wxyzabcdefg'이다
해당 청크들은 그것들은 4개의 'wxyz'가 겹치는 부분이고(overlap), 그런 다음 나머지 문자열로 구성되어있는 것을 볼 수 있다.
text3 = "a b c d e f g h i j k l m n o p q r s t u v w x y z"
print(r_splitter.split_text(text3))문자 사이에 공백이 많이 있는 좀 더 복잡한 문자열을 예시로 수행해본다면,
이제 공백이 있어서 3개의 chunk로 분할되는 것을 볼 수 있다.
output

겹치는 부분을 살펴보면 첫 번째 항목에는 l,m이 있고 두 번째 항목에도 l,m이 있음을 알 수 있다. l과 m 사이의 공백 때문에 실제로 청크를 구성하는 4개로 계산되어 겹치기 때문이다.
문자 텍스트 분할기를 사용해본다면,
text1 = 'abcdefghijklmnopqrstuvwxyz'
print(c_splitter.split_text(text1))
text2 = 'abcdefghijklmnopqrstuvwxyzabcdefg'
print(c_splitter.split_text(text2))
실행해도 실제로 분할을 전혀 시도하지 않는 것을 볼 수 있다.
문자 텍스트 분할기는 단일 문자로 분할되고 기본적으로 해당 문자가 개행 문자이다. 하지만 여기에는 개행 문자가 없기 때문에 분할이 되지 않았던 것이다.
text3 = "a b c d e f g h i j k l m n o p q r s t u v w x y z"
print(c_splitter.split_text(text3))여기서 개행을 하는 구분 기호를 빈 공간으로 설정하여 문자열 분할기를 다시 설정한 다음 위 텍스트로 실행해보면 아래와 같이 분할된다.
c_splitter2 = CharacterTextSplitter(
chunk_size = chunk_size,
chunk_overlap = chunk_overlap,
separator = ' '
)print(c_splitter2.split_text(text3))
◼︎ Splitter example code 2
다른 예제를 들어서 splitter를 사용해보자.
some_text = """When writing documents, writers will use document structure to group content. \
This can convey to the reader, which idea's are related. For example, closely related ideas \
are in sentances. Similar ideas are in paragraphs. Paragraphs form a document. \n\n \
Paragraphs are often delimited with a carriage return or two carriage returns. \
Carriage returns are the "backslash n" you see embedded in this string. \
Sentences have a period at the end, but also, have a space.\
and words are separated by space."""위와 같이 긴 문단의 텍스트가 있고, 해당 텍스트는 문단 사이의 일반적인 구분 기호인 이중 개행 기호가 있다. 이 텍스트의 길이는 약 500정도이다.
c_splitter = CharacterTextSplitter(
chunk_size = 450,
chunk_overlap = 0,
separator = ' '
)
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=450,
chunk_overlap = 0,
separators= ["\n\n", "\n", " ", ""]
)이제 두 개의 텍스트 분할기를 정의하고, 위와 마찬가지로 공백을 구분 기호로 사용하여 문자 텍스트 분할기를 사용한다.
재귀 문자 텍스트 분할기의 separators 인자에는 이중 개행, 단일 개행, 공백 및 아무것도 없는 빈 문자열 목록을 볼 수 있는데, 바로 텍스트 조각을 분할할 때 먼저 이중 개행으로 분할을 시도한다는 것이다. 그런 다음 여전히 개별 청크를 더 분할해야 하는 경우 단일 줄 바꿈으로 이동한다.
분리된 텍스트를 예쁘게 보기 위해서 pprint를 import 해서 사용했다.
import pprint
pp = pprint.PrettyPrinter(indent=1)pp.pprint(c_splitter.split_text(some_text))위의 텍스트에서 이러한 기능이 어떻게 수행되는지 살펴보면 문자 텍스트 분할기가 공백으로 분할되는 것을 확인할 수 있다.
output
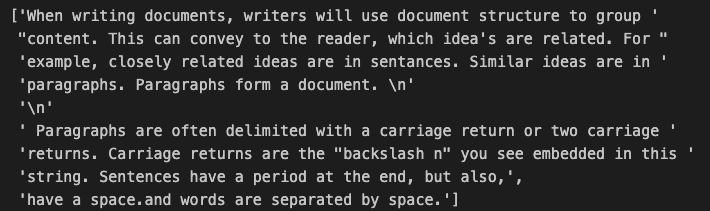
pp.pprint(r_splitter.split_text(some_text))output
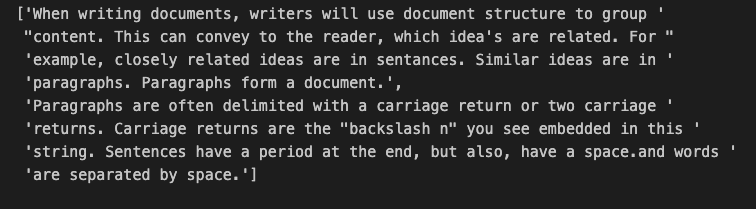
재귀 텍스트 분할기는 먼저 이중 개행으로 분할을 시도해서, 여기서는 두 개의 단락으로 분할된다. 첫 번째 문단이 450자보다 짧더라도 이제 각각의 문단인 두 문단이 문장 중간에 분할되는 것이 아니라 청크로 표시되기 때문에 이것이 더 나은 분할이라고 지정한 것이다.
r_splitter = RecursiveCharacterTextSplitter(
chunk_size = 150,
chunk_overlap = 0,
separators = ["\n\n", "\n", "\.", " ", ""]
)더 작은 청크로 나누기 위해서 마침표 구분 기호도 추가해서 문장 사이를 분할하는 것을 목표로 해보자.
pp.pprint(r_splitter.split_text(some_text))
#ouput
['When writing documents, writers will use document structure to group '
"content. This can convey to the reader, which idea's are related. For "
'example,',
'closely related ideas are in sentances. Similar ideas are in paragraphs. '
'Paragraphs form a document.',
'Paragraphs are often delimited with a carriage return or two carriage '
'returns. Carriage returns are the "backslash n" you see embedded in this',
'string. Sentences have a period at the end, but also, have a space.and words '
'are separated by space.']이 텍스트 분할기를 실행하면 문장별로 분할되어 있지만 마침표가 실제로 잘못된 위치에 있는 것을 볼 수 있다. 그 이유는 아래의 정규식 때문이다.
r_splitter = RecursiveCharacterTextSplitter(
chunk_size=150,
chunk_overlap=0,
separators=["\n\n", "\n", "(?<=\. )", " ", ""]
)
r_splitter.split_text(some_text)
## output
['When writing documents, writers will use document structure to group content. '
"This can convey to the reader, which idea's are related. For example,",
'closely related ideas are in sentances. Similar ideas are in paragraphs. '
'Paragraphs form a document.',
'Paragraphs are often delimited with a carriage return or two carriage '
'returns. Carriage returns are the "backslash n" you see embedded in this',
'string. Sentences have a period at the end, but also, have a space.and words '
'are separated by space.']이 문제를 해결하기 위해 약간 더 복잡한 정규식을 지정할 수 있는데, 실행해 보면 문장으로 나누어져 있고, 마침표가 올바른 위치에 있으면서 적절하게 나누어져 있는 것을 볼 수 있다.
◼︎ Splitter example code 3 - pdf loader + data splitting
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader('data/MachineLearning-Lecture01.pdf')
pages = loader.load()
pages
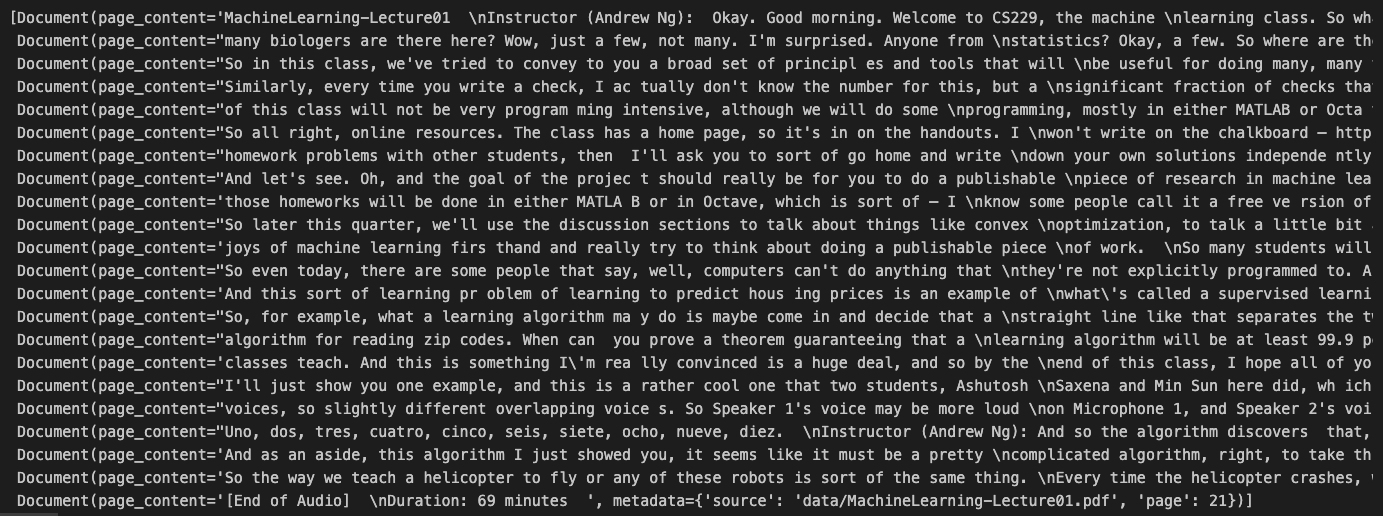
이제 data loading에서 로더로 불러왔던 PDF를 선택해 작업을 수행해본다.
pdf 파일을 로드한 후에, 텍스트 분할기를 정의하고, 길이 함수를 전달한다
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
chunk_size = 1000,
chunk_overlap=150,
separator = '\n',
length_function = len
)Python에 내장된 문자열 길이를 계산하는 LEN을 기본값으로 사용하고 있지만 더 명확하게 하기 위해 이를 지정했다.
docs = text_splitter.split_documents(pages)
docsdocs

len(docs), len(pages)
## output
77, 22이제 문서를 사용하기 위해서 문서 분할 방법을 사용하고 문서 목록을 전달한다. 해당 문서의 길이를 원본 페이지의 길이와 비교하면 이러한 분할로 인해 생성된 문서가 훨씬 더 많다는 것을 알 수 있다.
Notion DB로도 비슷한 작업을 할 수 있는데, 원본 문서의 길이와 새로운 분할 문서의 길이와 비교해보면, 분할 문서의 사이즈가 더 큰 것을 볼 수 있다.
위에서는 계속 문자열 기반으로 분할을 했으나, '토큰'을 기반으로 하는 텍스트 분할기도 사용할 수 있다.
◼︎ token splitting
token splitting이 유용한 이유는 LLM에 토큰 수로 지정되는 컨텍스트 창이 있는 경우가 많기 때문이다. 따라서 토큰이 무엇인지, 토큰이 어디에 나타나는지 아는 것이 중요하다. 그런 다음 이를 분할하여 LLM이 이를 어떻게 보는지에 대한 아이디어를 얻을 수 있다.
from langchain.text_splitter import TokenTextSplitter
text_splitter = TokenTextSplitter(
chunk_size= 1,
chunk_overlap =0
)
cha_splitter = CharacterTextSplitter(
chunk_size=1,
chunk_overlap=0
)token과 character의 차이점을 실제로 이해하기 위해 chunk 크기가 1이고 chunk overlap이 0인 토큰 텍스트 분할기를 초기화 한 후 모든 텍스트를 관련 토큰 목록으로 분할한다.
text1 = 'foo bar bazzyfoo'
print(text_splitter.split_text(text1))
print(cha_splitter.split_text(text1))
## output
['foo', ' bar', ' b', 'az', 'zy', 'foo']
['foo bar bazzyfoo']
이를 분할하면 여러 개의 토큰으로 분할되어 있고 길이와 문자 수 측면에서 모두 조금씩 다르다.
token splitter는 ['foo', ' bar', ' b', 'az', 'zy', 'foo']
character splitter는 ['foo bar bazzyfoo'] 이다.
이것은 문자 분할과 토큰 분할의 미묘한 차이를 보여주는 것이다.
위에서 로드한 문서에 이것을 적용해보자.
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader('data/MachineLearning-Lecture01.pdf')
pages = loader.load()
docs = text_splitter2.split_documents(pages)
docs[:5]
## output
[Document(page_content='MachineLearning-Lecture01 \n', metadata={'source': 'data/MachineLearning-Lecture01.pdf', 'page': 0}),
Document(page_content='Instructor (Andrew Ng): Okay. Good', metadata={'source': 'data/MachineLearning-Lecture01.pdf', 'page': 0}),
Document(page_content=' morning. Welcome to CS229, the machine ', metadata={'source': 'data/MachineLearning-Lecture01.pdf', 'page': 0}),
Document(page_content='\nlearning class. So what I wanna do today', metadata={'source': 'data/MachineLearning-Lecture01.pdf', 'page': 0}),
Document(page_content=' is ju st spend a little time going over the', metadata={'source': 'data/MachineLearning-Lecture01.pdf', 'page': 0})]첫 번째 문서를 살펴보면 페이지 내용이 대략 다음과 같은 새로운 분할 문서가 있다.

page_content, metadata로, metadata에서는 source와 page를 얻을 수 있다.
print(pages[0])
#output
page_content='MachineLearning-Lecture01 \nInstructor (Andrew Ng): Okay. Good morning. Welcome to CS229, the machine \nlearning class. So what I wanna do today is ju st spend a little time going over the logistics \nof the class, and then we\'ll start to talk a bit about machine learning. \nBy way of introduction, my name\'s Andrew Ng and I\'ll be instru ctor for this class. And so \nI personally work in machine learning, and I\' ve worked on it for about 15 years now, and \nI actually think that machine learning is th e most exciting field of all the computer \nsciences. So I\'m actually always excited about teaching this class. Sometimes I actually \nthink that machine learning is not only the most exciting thin g in computer science, but \nthe most exciting thing in all of human e ndeavor, so maybe a little bias there. \nI also want to introduce the TAs, who are all graduate students doing research in or \nrelated to the machine learni ng and all aspects of machin e learning. Paul Baumstarck \nworks in machine learning and computer vision. Catie Chang is actually a neuroscientist \nwho applies machine learning algorithms to try to understand the human brain. Tom Do \nis another PhD student, works in computa tional biology and in sort of the basic \nfundamentals of human learning. Zico Kolter is the head TA — he\'s head TA two years \nin a row now — works in machine learning a nd applies them to a bunch of robots. And \nDaniel Ramage is — I guess he\'s not here — Daniel applies l earning algorithms to \nproblems in natural language processing. \nSo you\'ll get to know the TAs and me much be tter throughout this quarter, but just from \nthe sorts of things the TA\'s do, I hope you can already tell that machine learning is a \nhighly interdisciplinary topic in which just the TAs find l earning algorithms to problems \nin computer vision and biology and robots a nd language. And machine learning is one of \nthose things that has and is having a large impact on many applications. \nSo just in my own daily work, I actually frequently end up talking to people like \nhelicopter pilots to biologists to people in computer systems or databases to economists \nand sort of also an unending stream of people from industry coming to Stanford \ninterested in applying machine learni ng methods to their own problems. \nSo yeah, this is fun. A couple of weeks ago, a student actually forwar ded to me an article \nin "Computer World" about the 12 IT skills th at employers can\'t say no to. So it\'s about \nsort of the 12 most desirabl e skills in all of IT and all of information technology, and \ntopping the list was actually machine lear ning. So I think this is a good time to be \nlearning this stuff and learning algorithms and having a large impact on many segments \nof science and industry. \nI\'m actually curious about something. Learni ng algorithms is one of the things that \ntouches many areas of science and industrie s, and I\'m just kind of curious. How many \npeople here are computer science majors, are in the computer science department? Okay. \nAbout half of you. How many people are from EE? Oh, okay, maybe about a fifth. How ' metadata={'source': 'data/MachineLearning-Lecture01.pdf', 'page': 0}
print(pages[0].metadata)
#output
{'source': 'data/MachineLearning-Lecture01.pdf', 'page': 0}
print(docs[0])
#output
page_content='MachineLearning-Lecture01 \n' metadata={'source': 'data/MachineLearning-Lecture01.pdf', 'page': 0}로드해온 0 페이지의 메타데이터와 청크의 메타데이터의 소스와 페이지가 동일하다는 것을 확인할 수 있다.
메타데이터를 각 청크에 적절하게 전달하는 것이 필요하지만, 분할 시 실제로 청크에 더 많은 메타데이터를 추가할 수도 있다.
해당 청크가 문서의 다른 항목이나 개념과 관련하여 문서 어디에서 왔는지와 같은 정보가 포함될 수 있으며 일반적으로 이 정보는 질문에 답할 때 이 청크가 정확히 무엇인지에 대한 추가 컨텍스트를 제공하는 데 사용될 수 있다.
◼︎ Context aware splitting
이에 대한 구체적인 예를 보기 위해 실제로 각 청크의 메타데이터에 정보를 추가하는 또 다른 유형의 텍스트 분할기를 살펴보자.
from langchain.document_loaders import NotionDirectoryLoader
from langchain.text_splitter import MarkdownHeaderTextSplitter이 텍스트 분할기는 마크다운 헤더 텍스트 분할기이고 헤더 또는 하위 헤더를 기반으로 마크다운 파일을 분할한 다음 해당 헤더를 메타데이터 필드에 콘텐츠로 추가하고 모든 필드에 전달하는 splitter이다.
markdown_document = """# Title\n\n \
## Chapter 1\n\n \
Hi this is Jim\n\n Hi this is Joe\n\n \
### Section \n\n \
Hi this is Lance \n\n
## Chapter 2\n\n \
Hi this is Molly"""먼저 title와 하위 헤더인 Chapter가 있는 문서를 가지고 예시를 들어보자면, 분할하려는 헤더 목록과 해당 헤더의 이름을 단일 해시태그가 있고 해당 헤더를 헤더 1, 헤더 2, 해시태그 3개, 헤더 3이라는 두 개의 해시태그가 있다
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]해당 헤더를 사용하여 마크다운 헤더 텍스트 분할기를 초기화하고, 위의 예제를 분할합니다.
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on
)
md_header_splits = markdown_splitter.split_text(markdown_document)md_header_splits
## output
[Document(page_content='Hi this is Jim \nHi this is Joe', metadata={'Header 1': 'Title', 'Header 2': 'Chapter 1'}),
Document(page_content='Hi this is Lance', metadata={'Header 1': 'Title', 'Header 2': 'Chapter 1', 'Header 3': 'Section'}),
Document(page_content='Hi this is Molly', metadata={'Header 1': 'Title', 'Header 2': 'Chapter 2'})]이러한 예 중 몇 가지를 살펴보면 첫 번째 예에 "안녕하세요, 저는 Jim입니다, 안녕하세요, 조입니다."라는 내용이 있고 이제 메타데이터에는 header 1로 Title, Header 2로 Chapter 1이 있다.
그 아래는 "안녕하세요, 이쪽은 Lance입니다"라는 내용이 있다.
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on
)
md_header_splits = markdown_splitter.split_text(markdown_document)data loader 시 사용했던 notion directory 로더를 사용하여 notion 디렉토리를 로드해서 이는 마크다운에 파일을 로드한다.
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on
)
md_header_splits = markdown_splitter.split_text(markdown_document)다음으로 헤더 1을 단일 해시태그로, 헤더 2를 이중 해시태그로 사용하여 마크다운 splitter를 정의하고, 텍스트를 분할한 다음 분할한 청크를 얻는다.
md_header_splits
## output
[Document(page_content='Hi this is Jim \nHi this is Joe', metadata={'Header 1': 'Title', 'Header 2': 'Chapter 1'}),
Document(page_content='Hi this is Lance', metadata={'Header 1': 'Title', 'Header 2': 'Chapter 1', 'Header 3': 'Section'}),
Document(page_content='Hi this is Molly', metadata={'Header 1': 'Title', 'Header 2': 'Chapter 2'})]
print(md_header_splits[0])
print(md_header_splits[1])
## output
page_content='Hi this is Jim \nHi this is Joe' metadata={'Header 1': 'Title', 'Header 2': 'Chapter 1'}
page_content='Hi this is Lance' metadata={'Header 1': 'Title', 'Header 2': 'Chapter 1', 'Header 3': 'Section'}살펴보면 첫 번째 항목에는 일부 페이지의 내용이 포함되어 있으며, 이제 메타데이터까지 아래로 스크롤하면 헤더 1이 Blendel의 직원 핸드북으로 로드된 것을 확인할 수 있다.
위의 방법들이 적절한 메타데이터를 사용하여 의미상 관련된 청크를 얻는 방법이다. 다음으로는 분할한 청크들을 vector store(벡터 저장소)로 옮겨야 한다.
