해당 게시물은 DeepLearningAI의 LangChain Chat with Your Data 강의를 듣고 개인적으로 정리한 내용입니다.
LangChain Chat with Your Data
(4) Retrieval
Retrieval은 검색 증강 생성(RAG) 흐름의 핵심이다.
저번 게시물에서 의미론적 검색의 기본 사항을 다루었고 많은 사용 사례에서 잘 작동한다는 것을 확인했다.
하지만 일부 케잇의 경우 잘 작동하지 않을 수도 있다는 것도 확인했다. 경우도 보았고 상황이 어떻게 잘못될 수 있는지도 보았습니다.
그래서 이번 게시물에서는 Retrieval에 대해 더 자세히 알아보고, 해당 실패했던 사례를 완화할 수 있는 방법들에 대해 다룬다.
◼︎ Retrieval
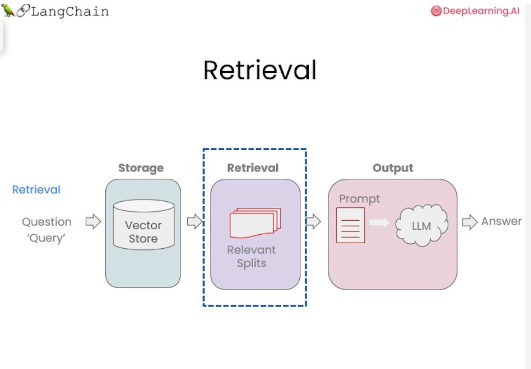
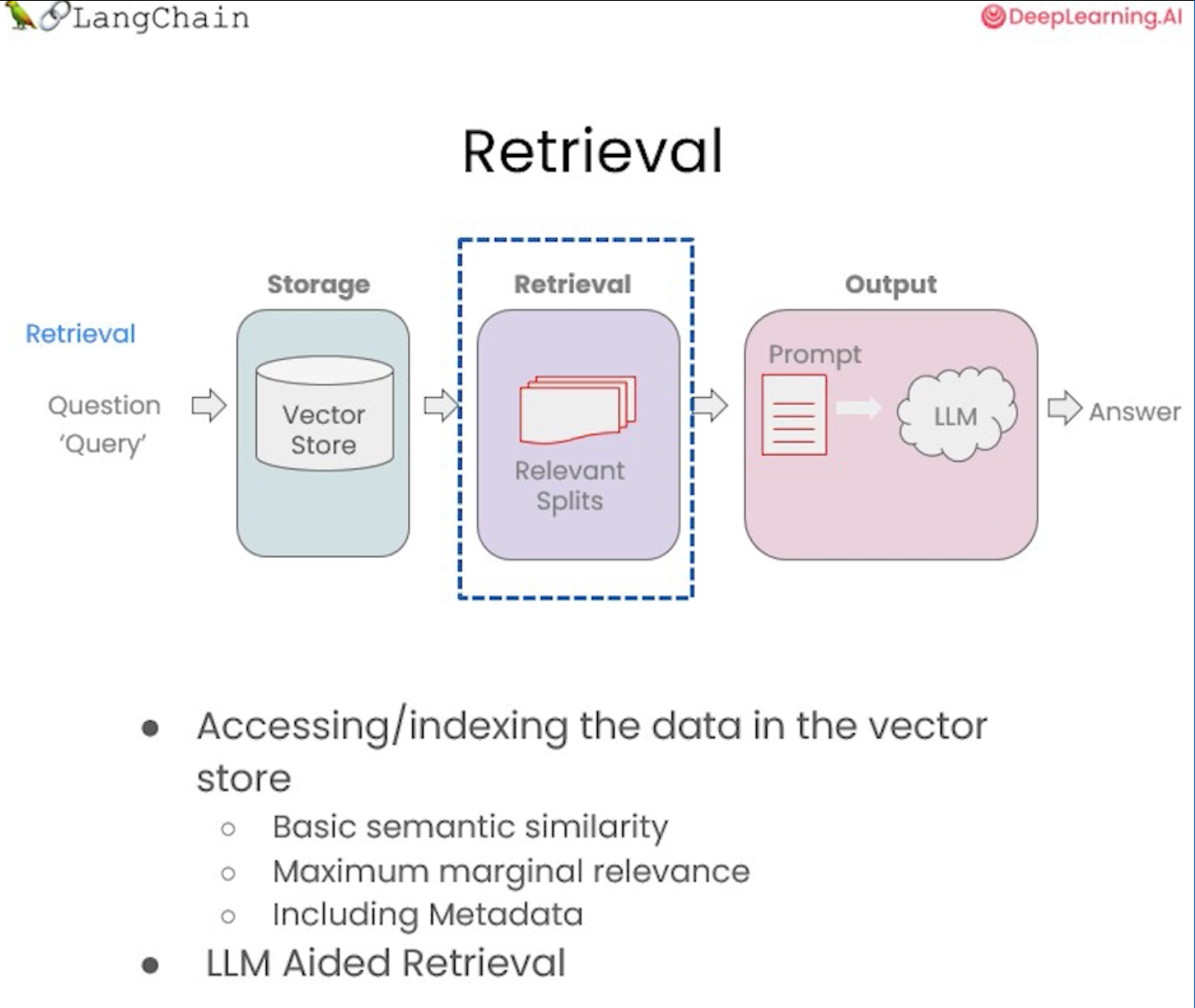
Retrieval(검색)은 쿼리가 들어오고 분할된 청크에서 해당 쿼리와 관련된 가장 관련성이 높은 것을 찾는 것이다.
◼︎ Retrieval - MMR(Maximum Marginal Relevance)
MMR(Maximum Marginal Relevance)의 아이디어는 항상 임베딩 공간에서 쿼리와 가장 유사한 문서를 가져오면 실제로는 엣지 케이스 중 하나에서 본 것처럼 다양한 정보를 놓칠 수 있다는 것이다.
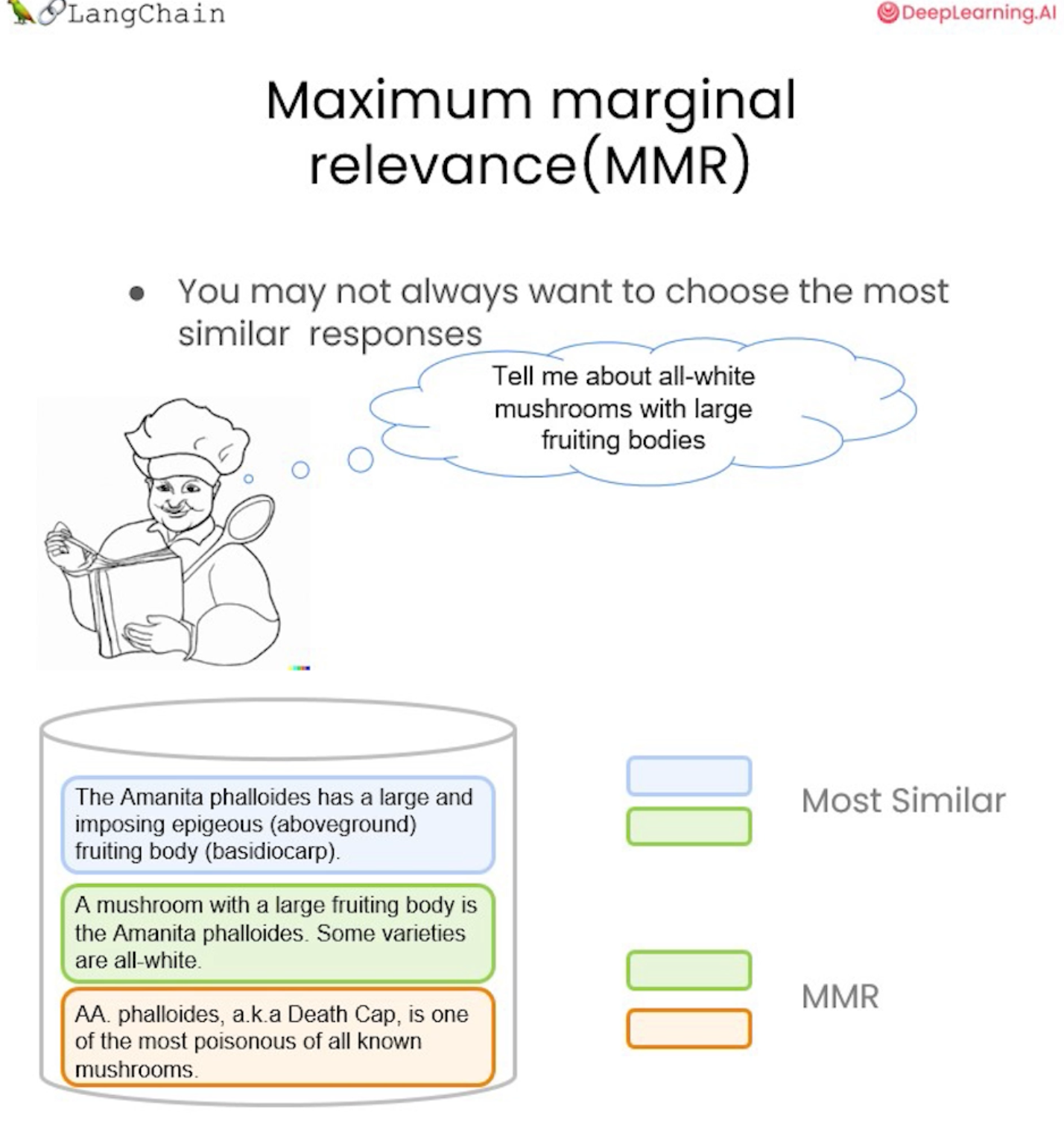
요리사가 모든 흰 버섯에 대해 질문하는 예를 확인해보자.
여기서 가장 유사한 결과를 살펴보면 이는 처음 두 문서가 될 것이다. 여기에는 자실체 및 모두 흰색이라는 쿼리와 유사한 많은 정보가 포함되어 있다.
여기서 해당 버섯이 독성이 있는지와 같은 정보를 추가로 얻고자 한다면, 다양한 문서 세트를 선택하므로 MMR을 사용하는 것이 중요하다.
MMR의 기본 아이디어는 쿼리를 보낸 다음 처음에 일련의 응답을 돌려받는 것이다.
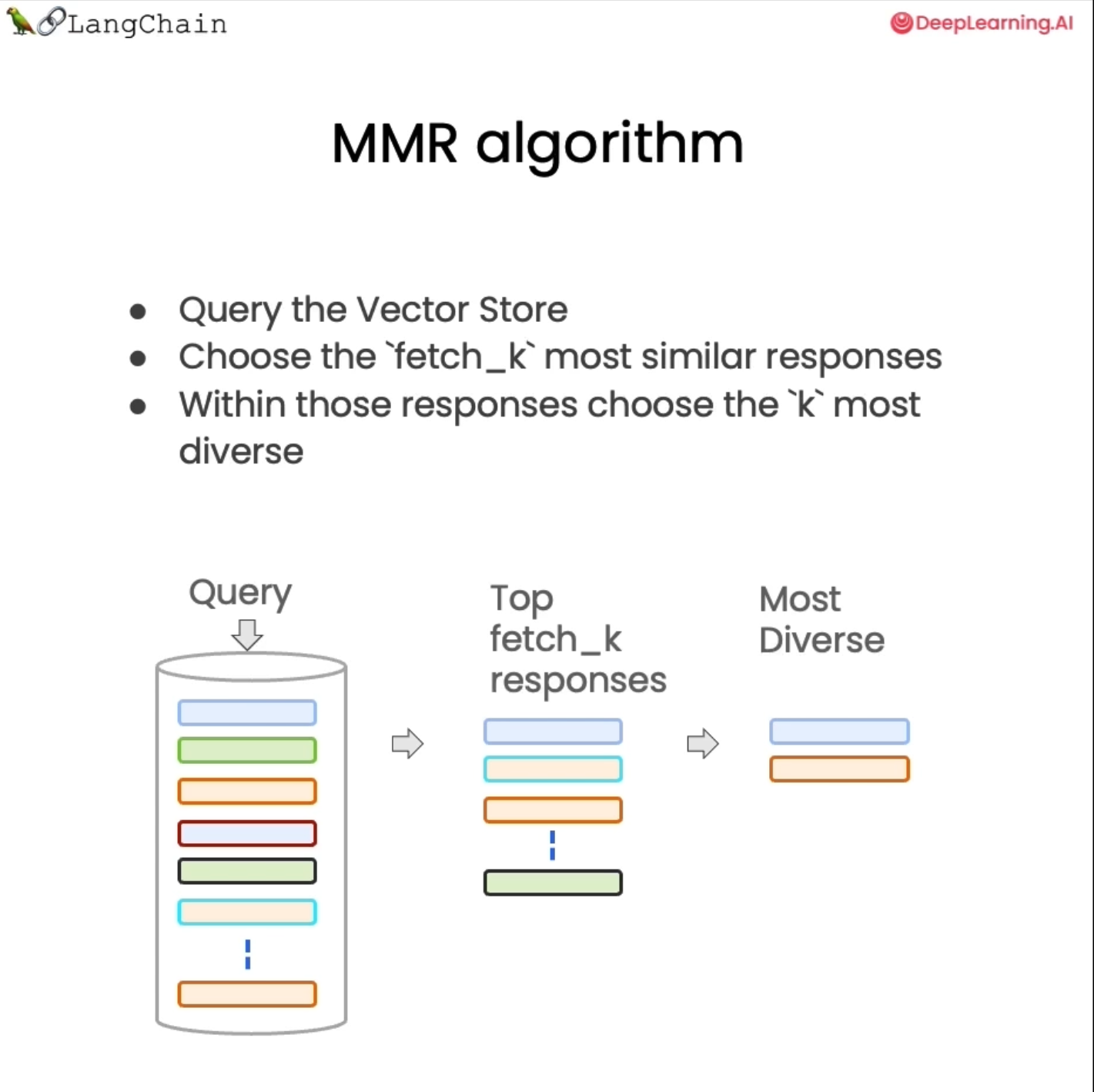
"fetch_k"는 우리가 받는 응답 수를 결정하기 위해 제어할 수 있는 매개 변수이다. 의미론적 유사성에 근거해서 작업을 수행한다.
더 작은 문서 세트를 만들고 의미적 유사성을 기반으로 가장 관련성이 높은 문서뿐만 아니라 다양한 문서에 대해서도 최적화한다. 그리고 해당 문서 세트에서 사용자에게 반환할 마지막 "k"를 선택한다.
◼︎ Retrieval - self-query
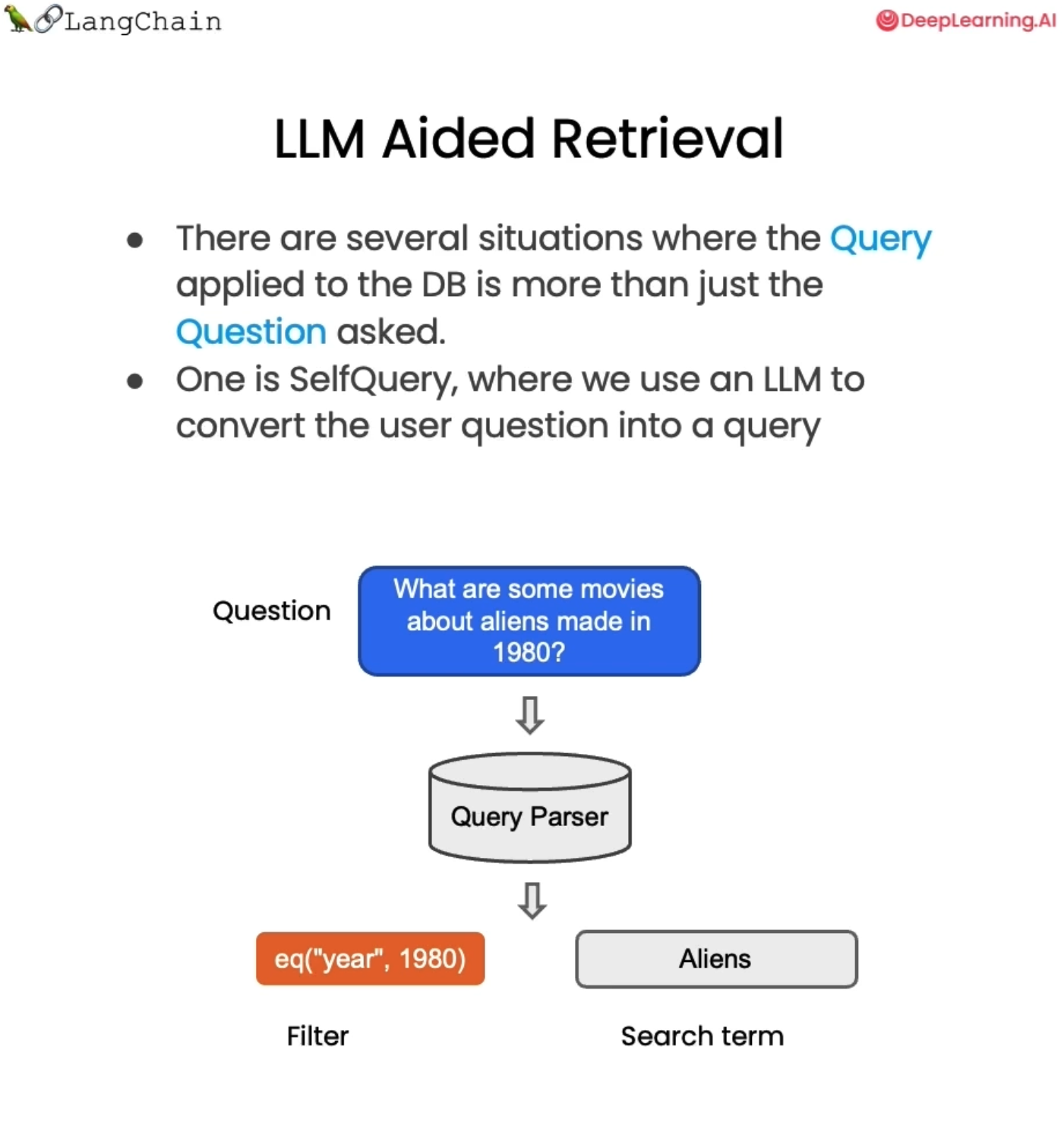
또 다른 검색 유형은 셀프 쿼리(self-query)이다.
의미상으로 조회하려는 콘텐츠뿐만 아니라 필터링하려는 일부 메타데이터에 대한 언급도 포함하는 질문을 받을 때 유용하다.
예를 들면 "1980년에 제작된 외계인에 관한 영화는 무엇인가?" 와 같은 질문에는 실제로 두 가지 구성 요소가 있다.
의미론적인 부분으로 '외계인' 에 관한 영화이다. 그래서 우리는 영화 데이터베이스에서 외계인을 찾고자한다.
그러나 여기서 추가적으로 '1980년'이라는 연도인 각 영화에 대한 메타데이터를 실제로 참조하는 부분도 있다.
우리가 할 수 있는 일은 언어 모델 자체를 사용하여 원래 질문을 필터와 검색어라는 두 가지 별도 항목으로 분할하는 것이다.
대부분의 벡터 저장소는 메타데이터 필터를 지원한다. 따라서 1980년과 같은 메타데이터를 기반으로 레코드를 쉽게 필터링할 수 있다.
◼︎ Retrieval - compression
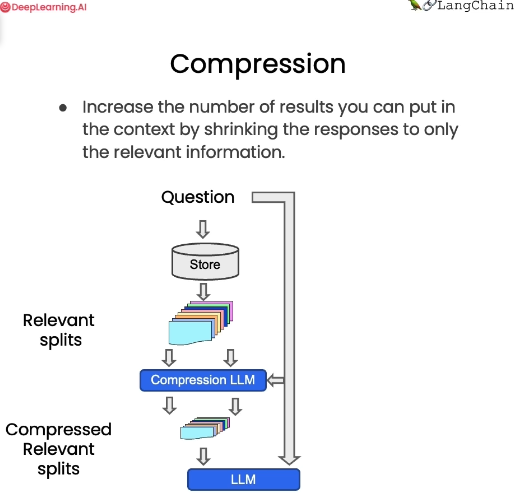
압축(compression)에 대해서도 설명하자면, 는 검색된 구절 중 가장 관련성이 높은 부분만 추출하는 데 유용할 수 있다.
예를 들어, 질문을 하면 처음 한두 문장만 관련 부분이더라도 저장된 문서 전체를 돌려받는다.
압축을 사용하면 언어 모델을 통해 모든 문서를 실행하고 가장 관련성이 높은 세그먼트를 추출한 다음 가장 관련성이 높은 세그먼트만 최종 언어 모델 호출에 전달할 수 있다.
이 방법은 언어 모델을 더 많이 호출해야 하지만, 가장 중요한 사항에만 최종 답에 대해 집중할 수 있기 때문에 좋다.
이 방법은 약간의 절충안이다.
◼︎ example code - similarity_search와 max_marginal_relevance_search 비교
import os
import openai
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
openai.api_key = os.environ['OPENAI_API_KEY']
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
persist_directory = 'data/chroma/'
embedding = OpenAIEmbeddings()
vectordb = Chroma(
persist_directory = persist_directory,
embedding_function = embedding
)vector db인 Chroma와 embedding을 위해 OpenAI를 임포트한다.
vectordb._collection.count()
##output
152_collection.count를 통해서 152개의 문서가 있다는 것을 확인할 수 있다.
texts = [
"""The Amanita phalloides has a large and imposing epigeous (aboveground) fruiting body (basidiocarp).""",
"""A mushroom with a large fruiting body is the Amanita phalloides. Some varieties are all-white.""",
"""A. phalloides, a.k.a Death Cap, is one of the most poisonous of all known mushrooms.""",
]smalldb = Chroma.from_texts(texts, embedding=embedding)버섯에 대한 정보가 있는 예제의 텍스트를 작성한 후에, 예제로 사용할 수 있는 작은 데이터베이스를 만든다.
question = "Tell me about all-white mushrooms with large fruiting bodies""Tell me about all-white mushrooms with large fruiting bodies(큰 자실체를 가진 순백색 버섯에 대해 알려주세요)" 에 대한 질문으로 유사성 검색을 수행해본다.
smalldb.similarity_search(question,k=2)
## output
[Document(page_content='A mushroom with a large fruiting body is the Amanita phalloides. Some varieties are all-white.'),
Document(page_content='The Amanita phalloides has a large and imposing epigeous (aboveground) fruiting body (basidiocarp).')]가장 관련성이 높은 두 문서만 반환하도록 "k=2"를 설정한다면,
'자실체가 큰 버섯은 광대버섯입니다. 전체가 흰색인 것도 있습니다.'와
'아마니타는 크고 인상적인 후성(위) 자실체(담자과체)를 가지고 있습니다.' 라는 document가 나오게 된다. 독성이 있다는 언급을 하는 문서는 없다.
smalldb.max_marginal_relevance_search(question,k=2)
## output
Number of requested results 20 is greater than number of elements in index 3, updating n_results = 3
[Document(page_content='A mushroom with a large fruiting body is the Amanita phalloides. Some varieties are all-white.'),
Document(page_content='A. phalloides, a.k.a Death Cap, is one of the most poisonous of all known mushrooms.')]이제 MMR(max_marginal_relevance_search)를 이용하고, "fetch_k=3"을 설정해본다.
'자실체가 큰 버섯은 광대버섯입니다. 전체가 흰색인 것도 있습니다.'
라는 문서와 A. phalloides, 일명 Death Cap은 알려진 모든 버섯 중에서 가장 유독한 버섯 중 하나입니다.'라는 문서가 등장한다.
검색한 문서 중 독성이 있다는 정보가 반환된 것을 확인할 수 있다.
◼︎ example code 2- similarity_search와 max_marginal_relevance_search 비교
이전 강의에서 MATLAB에 관해 질문하고 반복되는 정보가 포함된 문서를 돌려받았던 예제로 다시 비교해보자.
question = "what did they say about matlab?"
docs_ss = vectordb.similarity_search(question,k=3)
docs_mmr = vectordb.max_marginal_relevance_search(question, k=3)vector store의 similarity_search를 docs_ss로
max_marginal_relevance_search를 doc_mmr로 할당하고 각 k값을 3으로 준 다음의 결과값을 비교한다.
docs_ss = vectordb.similarity_search(question,k=3)
docs_mmr = vectordb.max_marginal_relevance_search(question, k=3)print(docs_ss)
print(docs_mmr)
##output
[Document(page_content='those homeworks will be done in either MATLA B or in Octave, which is sort of — I \nknow some people call it a free ve rsion of MATLAB, which it sort of is, sort of isn\'t. \nSo I guess for those of you that haven\'t s een MATLAB before, and I know most of you \nhave, MATLAB is I guess part of the programming language that makes it very easy to write codes using matrices, to write code for numerical routines, to move data around, to \nplot data. And it\'s sort of an extremely easy to learn tool to use for implementing a lot of \nlearning algorithms. \nAnd in case some of you want to work on your own home computer or something if you \ndon\'t have a MATLAB license, for the purposes of this class, there\'s also — [inaudible] \nwrite that down [inaudible] MATLAB — there\' s also a software package called Octave \nthat you can download for free off the Internet. And it has somewhat fewer features than MATLAB, but it\'s free, and for the purposes of this class, it will work for just about \neverything. \nSo actually I, well, so yeah, just a side comment for those of you that haven\'t seen \nMATLAB before I guess, once a colleague of mine at a different university, not at \nStanford, actually teaches another machine l earning course. He\'s taught it for many years. \nSo one day, he was in his office, and an old student of his from, lik e, ten years ago came \ninto his office and he said, "Oh, professo r, professor, thank you so much for your', metadata={'page': 8, 'source': 'data/MachineLearning-Lecture01.pdf'}),
Document(page_content='into his office and he said, "Oh, professo r, professor, thank you so much for your \nmachine learning class. I learned so much from it. There\'s this stuff that I learned in your \nclass, and I now use every day. And it\'s help ed me make lots of money, and here\'s a \npicture of my big house." \nSo my friend was very excited. He said, "W ow. That\'s great. I\'m glad to hear this \nmachine learning stuff was actually useful. So what was it that you learned? Was it \nlogistic regression? Was it the PCA? Was it the data ne tworks? What was it that you \nlearned that was so helpful?" And the student said, "Oh, it was the MATLAB." \nSo for those of you that don\'t know MATLAB yet, I hope you do learn it. It\'s not hard, \nand we\'ll actually have a short MATLAB tutori al in one of the discussion sections for \nthose of you that don\'t know it. \nOkay. The very last piece of logistical th ing is the discussion s ections. So discussion \nsections will be taught by the TAs, and atte ndance at discussion sections is optional, \nalthough they\'ll also be recorded and televi sed. And we\'ll use the discussion sections \nmainly for two things. For the next two or th ree weeks, we\'ll use the discussion sections \nto go over the prerequisites to this class or if some of you haven\'t seen probability or \nstatistics for a while or maybe algebra, we\'ll go over those in the discussion sections as a \nrefresher for those of you that want one.', metadata={'page': 8, 'source': 'data/MachineLearning-Lecture01.pdf'}),
Document(page_content="same regardless of the group size, so with a larger group, you probably — I recommend \ntrying to form a team, but it's actually totally fine to do it in a sma ller group if you want. \nStudent : [Inaudible] what language [inaudible]? \nInstructor (Andrew Ng): So let's see. There is no C programming in this class other \nthan any that you may choose to do yourself in your project. So all the homeworks can be \ndone in MATLAB or Octave, and let's see. A nd I guess the program prerequisites is more \nthe ability to understand big?O notation and know ledge of what a data structure, like a \nlinked list or a queue or bina ry treatments, more so than your knowledge of C or Java \nspecifically. Yeah? \nStudent : Looking at the end semester project, I mean, what exactly will you be testing \nover there? [Inaudible]? \nInstructor (Andrew Ng) : Of the project? \nStudent : Yeah. \nInstructor (Andrew Ng) : Yeah, let me answer that later. In a couple of weeks, I shall \ngive out a handout with guidelines for the pr oject. But for now, we should think of the \ngoal as being to do a cool piec e of machine learning work that will let you experience the", metadata={'page': 9, 'source': 'data/MachineLearning-Lecture01.pdf'})]
[Document(page_content='those homeworks will be done in either MATLA B or in Octave, which is sort of — I \nknow some people call it a free ve rsion of MATLAB, which it sort of is, sort of isn\'t. \nSo I guess for those of you that haven\'t s een MATLAB before, and I know most of you \nhave, MATLAB is I guess part of the programming language that makes it very easy to write codes using matrices, to write code for numerical routines, to move data around, to \nplot data. And it\'s sort of an extremely easy to learn tool to use for implementing a lot of \nlearning algorithms. \nAnd in case some of you want to work on your own home computer or something if you \ndon\'t have a MATLAB license, for the purposes of this class, there\'s also — [inaudible] \nwrite that down [inaudible] MATLAB — there\' s also a software package called Octave \nthat you can download for free off the Internet. And it has somewhat fewer features than MATLAB, but it\'s free, and for the purposes of this class, it will work for just about \neverything. \nSo actually I, well, so yeah, just a side comment for those of you that haven\'t seen \nMATLAB before I guess, once a colleague of mine at a different university, not at \nStanford, actually teaches another machine l earning course. He\'s taught it for many years. \nSo one day, he was in his office, and an old student of his from, lik e, ten years ago came \ninto his office and he said, "Oh, professo r, professor, thank you so much for your', metadata={'page': 8, 'source': 'data/MachineLearning-Lecture01.pdf'}),
Document(page_content='algorithm then? So what’s different? How come I was making all that noise earlier about \nleast squares regression being a bad idea for classification problems and then I did a \nbunch of math and I skipped some steps, but I’m, sort of, claiming at the end they’re \nreally the same learning algorithm? \nStudent: [Inaudible] constants? \nInstructor (Andrew Ng) :Say that again. \nStudent: [Inaudible] \nInstructor (Andrew Ng) :Oh, right. Okay, cool.', metadata={'page': 13, 'source': 'data/MachineLearning-Lecture03.pdf'}),
Document(page_content="machine data, like the magneto-encephalogram would be an EEG data. We'll talk about \nthat more when we go and describe ICA or independent component analysis algorithms, \nwhich is what you just saw.", metadata={'page': 18, 'source': 'data/MachineLearning-Lecture01.pdf'})]이를 상세하게 다시 비교해보면,
print(f"vectordb.simiarity_serach : \n {docs_ss[0].page_content}")
print("-"*50)
print(f"vectordb.max_marginal_relevance_search : \n {docs_mmr[0].page_content}")
vectordb.simiarity_serach :
'those homeworks will be done in either MATLA B or in Octave, which is sort of — I \nknow some people call it a free ve rsion of MATLAB, which it sort of is, sort of isn\'t. \nSo I guess for those of you that haven\'t s een MATLAB before, and I know most of you \nhave, MATLAB is I guess part of the programming language that makes it very easy to write codes using matrices, to write code for numerical routines, to move data around, to \nplot data. And it\'s sort of an extremely easy to learn tool to use for implementing a lot of \nlearning algorithms. \nAnd in case some of you want to work on your own home computer or something if you \ndon\'t have a MATLAB license, for the purposes of this class, there\'s also — [inaudible] \nwrite that down [inaudible] MATLAB — there\' s also a software package called Octave \nthat you can download for free off the Internet. And it has somewhat fewer features than MATLAB, but it\'s free, and for the purposes of this class, it will work for just about \neverything. \nSo actually I, well, so yeah, just a side comment for those of you that haven\'t seen \nMATLAB before I guess, once a colleague of mine at a different university, not at \nStanford, actually teaches another machine l earning course. He\'s taught it for many years. \nSo one day, he was in his office, and an old student of his from, lik e, ten years ago came \ninto his office and he said, "Oh, professo r, professor, thank you so much for your'
(이 숙제는 MATLA B나 Octave에서 수행됩니다. 이것은 일종의 — 저는 \n어떤 사람들이 그것을 MATLAB의 무료 버전이라고 부르는 것을 알고 있습니다. . \n이전에 MATLAB을 본 적이 없는 분들을 위해 말씀드리자면, 그리고 저는 대부분의 분들이 가지고 있다는 것을 알고 있습니다. MATLAB은 행렬을 사용하여 코드를 작성하는 것을 매우 쉽게 만들어주는 프로그래밍 언어의 일부인 것 같습니다. 수치 루틴의 경우, 데이터를 이동하고 \n데이터를 플롯합니다. 그리고 이는 많은 학습 알고리즘을 구현하는 데 사용할 수 있는 배우기 매우 쉬운 \n도구입니다. \n그리고 여러분 중 일부가 자신의 작업을 수행하려는 경우 MATLAB 라이센스가 없는 경우 집에 있는 컴퓨터 등이 있습니다. 이 수업의 목적을 위해 다음도 있습니다. — [청취 불가] \n기록해 두세요 [청취 불가] MATLAB — 소프트웨어 패키지도 있습니다 인터넷에서 무료로 다운로드할 수 있는 옥타브(Octave)라고 합니다. 또한 MATLAB보다 기능이 다소 적지만 무료이며 이 수업의 목적에 따라 거의 모든 작업에 \n작동합니다. \n실제로 저는, 음, 그렇습니다. 전에 MATLAB을 본 적이 없는 분들을 위해 \n부담으로 말씀드리자면, 한번은 스탠포드가 아닌 다른 대학에 있는 제 동료가\n실제로 다른 기계를 가르쳤던 적이 있습니다. 적립 코스. 그는 수년 동안 그것을 가르쳤습니다. \n어느 날 그는 그의 사무실에 있었는데, 10년 전 같은 학교 출신의 옛 학생이 \n 그의 사무실로 와서 "아, 교수님, 교수님, 정말 감사합니다."라고 말했습니다.)
vectordb.max_marginal_relevance_search :
'those homeworks will be done in either MATLA B or in Octave, which is sort of — I \nknow some people call it a free ve rsion of MATLAB, which it sort of is, sort of isn\'t. \nSo I guess for those of you that haven\'t s een MATLAB before, and I know most of you \nhave, MATLAB is I guess part of the programming language that makes it very easy to write codes using matrices, to write code for numerical routines, to move data around, to \nplot data. And it\'s sort of an extremely easy to learn tool to use for implementing a lot of \nlearning algorithms. \nAnd in case some of you want to work on your own home computer or something if you \ndon\'t have a MATLAB license, for the purposes of this class, there\'s also — [inaudible] \nwrite that down [inaudible] MATLAB — there\' s also a software package called Octave \nthat you can download for free off the Internet. And it has somewhat fewer features than MATLAB, but it\'s free, and for the purposes of this class, it will work for just about \neverything. \nSo actually I, well, so yeah, just a side comment for those of you that haven\'t seen \nMATLAB before I guess, once a colleague of mine at a different university, not at \nStanford, actually teaches another machine l earning course. He\'s taught it for many years. \nSo one day, he was in his office, and an old student of his from, lik e, ten years ago came \ninto his office and he said, "Oh, professo r, professor, thank you so much for your'
(이 숙제는 MATLA B나 Octave에서 수행됩니다. 이것은 일종의 — 저는 \n어떤 사람들이 그것을 MATLAB의 무료 버전이라고 부르는 것을 알고 있습니다. . \n이전에 MATLAB을 본 적이 없는 분들을 위해 말씀드리자면, 그리고 저는 대부분의 분들이 가지고 있다는 것을 알고 있습니다. MATLAB은 행렬을 사용하여 코드를 작성하는 것을 매우 쉽게 만들어주는 프로그래밍 언어의 일부인 것 같습니다. 수치 루틴의 경우, 데이터를 이동하고 \n데이터를 플롯합니다. 그리고 이는 많은 학습 알고리즘을 구현하는 데 사용할 수 있는 배우기 매우 쉬운 \n도구입니다. \n그리고 여러분 중 일부가 자신의 작업을 수행하려는 경우 MATLAB 라이센스가 없는 경우 집에 있는 컴퓨터 등이 있습니다. 이 수업의 목적을 위해 다음도 있습니다. — [청취 불가] \n기록해 두세요 [청취 불가] MATLAB — 소프트웨어 패키지도 있습니다 인터넷에서 무료로 다운로드할 수 있는 옥타브(Octave)라고 합니다. 또한 MATLAB보다 기능이 다소 적지만 무료이며 이 수업의 목적에 따라 거의 모든 작업에 \n작동합니다. \n실제로 저는, 음, 그렇습니다. 전에 MATLAB을 본 적이 없는 분들을 위해 \n부담으로 말씀드리자면, 한번은 스탠포드가 아닌 다른 대학에 있는 제 동료가\n실제로 다른 기계를 가르쳤던 적이 있습니다. 적립 코스. 그는 수년 동안 그것을 가르쳤습니다. \n어느 날 그는 그의 사무실에 있었는데, 10년 전 같은 학교 출신의 옛 학생이 \n 그의 사무실로 와서 "아, 교수님, 교수님, 정말 감사합니다."라고 말했습니다.)
similarity_search와 MMR의 첫 번째 문서는 찾아낸 문서 청크가 동일하다.
그러나, 두 번째로 찾은 문서들을 비교해보면
'into his office and he said, "Oh, professo r, professor, thank you so much for your \nmachine learning class. I learned so much from it. There\'s this stuff that I learned in your \nclass, and I now use every day. And it\'s help ed me make lots of money, and here\'s a \npicture of my big house." \nSo my friend was very excited. He said, "W ow. That\'s great. I\'m glad to hear this \nmachine learning stuff was actually useful. So what was it that you learned? Was it \nlogistic regression? Was it the PCA? Was it the data ne tworks? What was it that you \nlearned that was so helpful?" And the student said, "Oh, it was the MATLAB." \nSo for those of you that don\'t know MATLAB yet, I hope you do learn it. It\'s not hard, \nand we\'ll actually have a short MATLAB tutori al in one of the discussion sections for \nthose of you that don\'t know it. \nOkay. The very last piece of logistical th ing is the discussion s ections. So discussion \nsections will be taught by the TAs, and atte ndance at discussion sections is optional, \nalthough they\'ll also be recorded and televi sed. And we\'ll use the discussion sections \nmainly for two things. For the next two or th ree weeks, we\'ll use the discussion sections \nto go over the prerequisites to this class or if some of you haven\'t seen probability or \nstatistics for a while or maybe algebra, we\'ll go over those in the discussion sections as a \nrefresher for those of you that want one.'
'algorithm then? So what’s different? How come I was making all that noise earlier about \nleast squares regression being a bad idea for classification problems and then I did a \nbunch of math and I skipped some steps, but I’m, sort of, claiming at the end they’re \nreally the same learning algorithm? \nStudent: [Inaudible] constants? \nInstructor (Andrew Ng) :Say that again. \nStudent: [Inaudible] \nInstructor (Andrew Ng) :Oh, right. Okay, cool.'
응답이 다양해지고 있는 것을 발견할 수 있다.
문서3 또한 마찬가지이다.
similarity_search는 "same regardless of the group size, so with a larger group, you probably — I recommend \ntrying to form a team, but it's actually totally fine to do it in a sma ller group if you want. \nStudent : [Inaudible] what language [inaudible]? \nInstructor (Andrew Ng): So let's see. There is no C programming in this class other \nthan any that you may choose to do yourself in your project. So all the homeworks can be \ndone in MATLAB or Octave, and let's see. A nd I guess the program prerequisites is more \nthe ability to understand big?O notation and know ledge of what a data structure, like a \nlinked list or a queue or bina ry treatments, more so than your knowledge of C or Java \nspecifically. Yeah? \nStudent : Looking at the end semester project, I mean, what exactly will you be testing \nover there? [Inaudible]? \nInstructor (Andrew Ng) : Of the project? \nStudent : Yeah. \nInstructor (Andrew Ng) : Yeah, let me answer that later. In a couple of weeks, I shall \ngive out a handout with guidelines for the pr oject. But for now, we should think of the \ngoal as being to do a cool piec e of machine learning work that will let you experience the"
mmr은
"machine data, like the magneto-encephalogram would be an EEG data. We'll talk about \nthat more when we go and describe ICA or independent component analysis algorithms, \nwhich is what you just saw."
인 것을 볼 수 있다.
◼︎ example code - Addressing Specificity: working with metadata
question = "what did they say about regression in the third lecture?"자체 쿼리 예제로 넘어가 "세 번째 강의에서 회귀에 대해 뭐라고 말했습니까" 라는 문제에 대해 진행해보자.
그냥 찾았을 경우 세 번째 강의뿐만 아니라 첫 번째, 두 번째 강의 결과도 반환했었다.
docs = vectordb.similarity_search(
question,
k=3,
filter= {"source":"data/MachineLearning-Lecture03.pdf"}
)
이 문제를 해결하기 위해서는 메타데이터 필터를 지정하는 방법을 사용한다. 원하는 정보인 소스가 세 번째 강의 PDF를 전달한다.
for d in docs:
print(d)
##output
page_content='MachineLearning-Lecture03 \nInstructor (Andrew Ng) :Okay. Good morning and welcome b ack to the third lecture of \nthis class. So here’s what I want to do t oday, and some of the topics I do today may seem \na little bit like I’m jumping, sort of, from topic to topic, but here’s, sort of, the outline for \ntoday and the illogical flow of ideas. In the last lecture, we talked about linear regression \nand today I want to talk about sort of an adaptation of that called locally weighted \nregression. It’s very a popular algorithm that’s actually one of my former mentors \nprobably favorite machine learning algorithm. \nWe’ll then talk about a probabl e second interpretation of linear regression and use that to \nmove onto our first classification algorithm, which is logistic regr ession; take a brief \ndigression to tell you about something cal led the perceptron algorithm, which is \nsomething we’ll come back to, again, later this quarter; and time allowing I hope to get to \nNewton’s method, which is an algorithm fo r fitting logistic regression models. \nSo this is recap where we’re talking about in the previous lecture, remember the notation \nI defined was that I used this X superscrip t I, Y superscript I to denote the I training \nexample. And when we’re talking about linear regression or linear l east squares, we use \nthis to denote the predicted value of “by my hypothesis H” on the input XI. And my' metadata={'page': 0, 'source': 'data/MachineLearning-Lecture03.pdf'}
page_content='Student: It’s the lowest it – \nInstructor (Andrew Ng) :No, exactly. Right. So zero to the same, this is not the same, \nright? And the reason is, in logi stic regression this is diffe rent from before, right? The \ndefinition of this H subscript theta of XI is not the same as the definition I was using in \nthe previous lecture. And in pa rticular this is no longer thet a transpose XI. This is not a \nlinear function anymore. This is a logistic function of theta transpose XI. Okay? So even \nthough this looks cosmetically similar, even though this is similar on the surface, to the \nBastrian descent rule I derive d last time for least squares regression this is actually a \ntotally different learning algorithm. Okay? And it turns out that there’s actually no \ncoincidence that you ended up with the same l earning rule. We’ll actually talk a bit more \nabout this later when we talk about generalized linear models. But this is one of the most \nelegant generalized learning models that we’l l see later. That even though we’re using a \ndifferent model, you actually ended up with wh at looks like the sa me learning algorithm \nand it’s actually no coincidence. Cool. \nOne last comment as part of a sort of l earning process, over here I said I take the \nderivatives and I ended up with this line . I didn’t want to make you sit through a long \nalgebraic derivation, but later t oday or later this week, pleas e, do go home and look at our' metadata={'page': 14, 'source': 'data/MachineLearning-Lecture03.pdf'}
page_content='when you had a Q’s tow. Like you make it too small in your – \nInstructor (Andrew Ng) :Yes, absolutely. Yes. So local ly weighted regression can run \ninto – locally weighted regression is not a penancier for the problem of overfitting or \nunderfitting. You can still run into the same problems with locally weighted regression. \nWhat you just said about – and so some of these things I’ll leave you to discover for \nyourself in the homework problem. You’ll actu ally see what you just mentioned. Yeah? \nStudent: It almost seems like you’re not even th oroughly [inaudible] w ith this locally \nweighted, you had all the data th at you originally had anyway.' metadata={'page': 4, 'source': 'data/MachineLearning-Lecture03.pdf'}for d in docs:
print(d.metadata)
##output
{'page': 0, 'source': 'data/MachineLearning-Lecture03.pdf'}
{'page': 14, 'source': 'data/MachineLearning-Lecture03.pdf'}
{'page': 4, 'source': 'data/MachineLearning-Lecture03.pdf'}검색될 문서를 살펴보면 모두 정확히 그 강의에서 나온 것임을 확인할 수 있다.
◼︎ Addressing Specificity: working with metadata using self-query retriever(자체 쿼리 검색기를 사용하여 메타데이터 작업)
쿼리 자체에서 메타데이터를 추론하려는 경우도 있기 때문에
이 문제를 해결하기 위해 LLM을 사용하여
(1) 벡터 검색에 사용할 쿼리 문자열
(2) 전달할 메타데이터 필터
를 추출가능한 SelfQueryRetriever를 사용할 수 있습니다.
대부분의 벡터 데이터베이스는 메타데이터 필터를 지원하므로 새로운 데이터베이스나 인덱스가 필요하지 않습니다.이 작업을 수행하기 위해 언어 모델을 사용할 수 있으므로 수동으로 지정할 필요가 없다. OpenAI라는 언어 모델을 가져온 뒤, 자체 쿼리 검색기로 메타데이터의 다양한 필드와 해당 필드를 지정할 수 있는 속성 정보를 가져온다.
메타데이터에는 소스와 페이지라는 두 개의 필드만 있다.
메타데이터에 이러한 각 속성에 대한 이름, 설명 및 유형에 대한 설명을 작성한다. 이 정보는 실제로 언어 모델에 전달되므로 최대한 설명을 확실하게 작성해야한다.
그런 다음 이 문서 저장소에 실제로 무엇이 있는지에 대한 몇 가지 정보를 지정한다.
언어 모델을 초기화한 다음 "from_llm" 메소드를 사용하고 언어 모델, 쿼리할 기본 벡터 데이터베이스, 설명 및 설명에 대한 정보를 전달하여 자체 쿼리 검색기를 초기화한다.
다음으로 메타데이터를 입력한 다음 "verbose=True"를 같이 전달한다.
"verbose=True"를 설정하면 LLM이 메타데이터 필터와 함께 전달되어야 하는 쿼리를 추론할 때 내부적으로 무슨 일이 일어나고 있는지 확인할 수 있다.
이 질문으로 자체 쿼리 검색기를 실행하면 "verbose=True" 덕분에 내부에서 무슨 일이 일어나고 있는지를 프린트하고 있어 확인할 수 있다.
회귀 쿼리를 얻었습니다. 이것이 의미론적 비트이고, 소스 속성과 문서 값 사이의 동등 비교기가 있는 필터와 세 번째 기계 학습 강의에서 회귀 질문에 대해 있는 문서값을 얻었다.
따라서 이는 기본적으로 회귀 시 의미 공간에서 조회를 수행한 다음 이 값의 소스 값이 있는 문서만 보는 필터를 수행하라는 의미이다.
따라서 문서를 반복하여 메타데이터를 인쇄하면 해당 문서가 모두 이번 세 번째 강의에서 나온 것임을 알 수 있다.
위의 예시에서 자체 쿼리 검색기를 사용하여 메타데이터를 정확하게 필터링할 수 있는 것을 보여준다.
