해당 게시물은 DeepLearningAI의 LangChain Chat with Your Data 강의를 듣고 개인적으로 정리한 내용입니다.
LangChain Chat with Your Data
(6) Chat
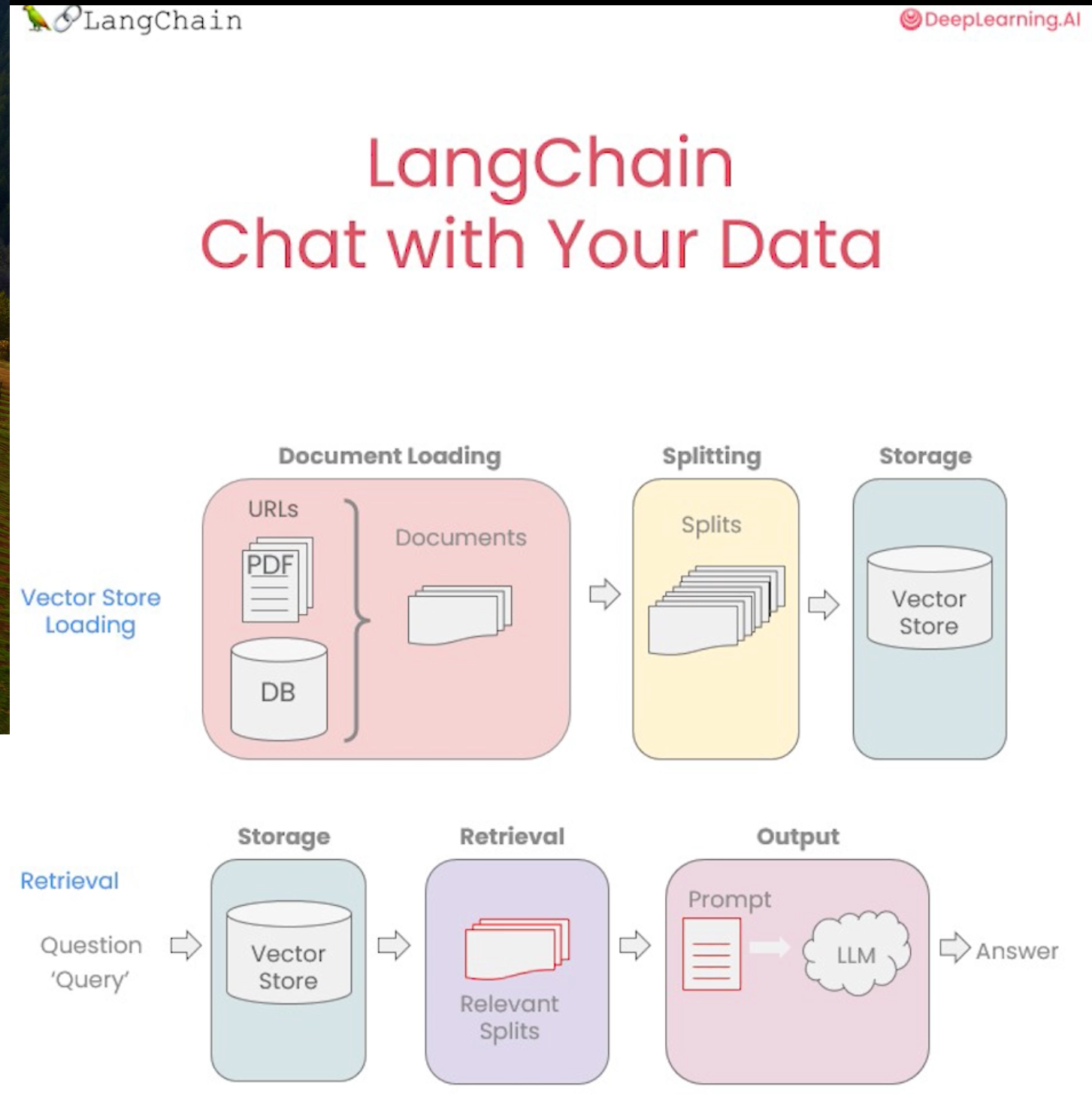
◼︎ Chat - chat history
나의 데이터를 가지고 챗봇을 만들기 위해서 문서 로드부터 시작하여 분할한 다음 벡터 저장소를 만들고 다양한 검색 유형에 대해 핸들링했다.
Question Answer 섹션에서 질문에 답할 수는 있지만 후속 질문을 처리할 수는 없었는데, 이번 섹션에서는 후속 질문을 처리할 수 있는 방법을 추가한다.
질의 응답이 가능한 챗봇을 만들기 위해서 채팅 기록(chat history)이라는 개념을 추가한다.이전에 체인과 교환한 대화나 메시지이다.
그것이 할 수 있는 일은 질문에 대답하려고 할 때 채팅 기록을 맥락에 맞게 가져갈 수 있게 하는 것이다.
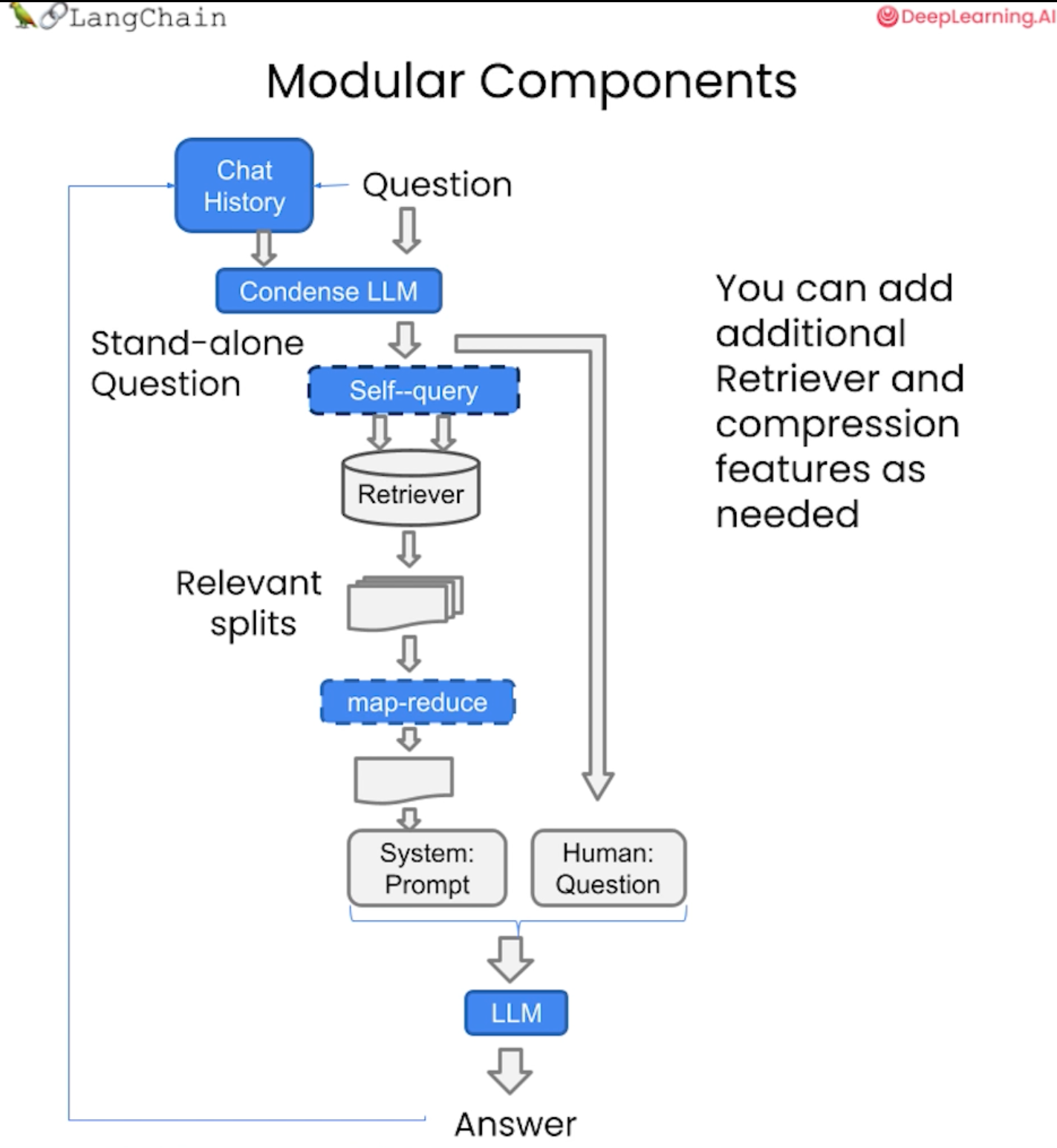
여기서 주목해야 할 중요한 점은 자체 쿼리나 압축 등 지금까지 이야기한 모든 멋진 유형의 검색을 여기에서 사용가능하다는 것이다. 우리가 이야기한 모든 구성 요소는 매우 모듈식이므로, 필요한 모듈을 엮어서 사용할 수 있다. 여기에 채팅 기록(chat history) 이라는 개념인 모듈만 추가하면 된다.
◼︎ Chat code
import os
import openai
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
openai.api_key = os.environ['OPENAI_API_KEY']
# GUI
import panel as pn
pn.extension()
import datetime
current_date = datetime.datetime.now().date()
if current_date < datetime.date(2023, 9, 2):
llm_name = 'gpt-3.5-turbo-0301'
else:
llm_name = 'gpt-3.5-turbo'
llm_name환경 변수를 로드하고, 수업 자료(데이터)에 대한 모든 임베딩이 포함된 벡터 저장소를 로드한다.
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
persist_directory = 'data/chroma/'
embeddings = OpenAIEmbeddings()
vectordb Chroma(persist_directory=persist_directory, embedding_function=embeddings)
벡터 저장소에서 기본적인 유사성 검색을 실행한 뒤, 챗봇으로 사용할 언어 모델을 초기화 한다.
question = "What are major topics ofr this class?"
docs = vectordb.similarity_search(question, 3)
print(len(docs))
docs
##output
3
[Document(page_content="statistics for a while or maybe algebra, we'll go over those in the discussion sections as a \nrefresher for those of you that want one. \nLater in this quarter, we'll also use the disc ussion sections to go over extensions for the \nmaterial that I'm teaching in the main lectur es. So machine learning is a huge field, and \nthere are a few extensions that we really want to teach but didn't have time in the main \nlectures for.", metadata={'page': 8, 'source': 'data/MachineLearning-Lecture01.pdf'}),
Document(page_content="middle of class, but because there won't be video you can safely sit there and make faces \nat me, and that won't show, okay? \nLet's see. I also handed out this — ther e were two handouts I hope most of you have, \ncourse information handout. So let me just sa y a few words about parts of these. On the \nthird page, there's a section that says Online Resources. \nOh, okay. Louder? Actually, could you turn up the volume? Testing. Is this better? \nTesting, testing. Okay, cool. Thanks.", metadata={'page': 4, 'source': 'data/MachineLearning-Lecture01.pdf'}),
Document(page_content="Today, I'm also going to delve into a fair amount – some amount of linear algebra, and so \nif you would like to see a refres her on linear algebra, this w eek's discussion section will \nbe taught by the TAs and will be a refresher on linear algebra. So if some of the linear \nalgebra I talk about today sort of seems to be going by pretty quickl y, or if you just want \nto see some of the things I'm claiming today with our proof, if you wa nt to just see some \nof those things written out in detail, you can come to this week's discussion section.", metadata={'page': 0, 'source': 'data/MachineLearning-Lecture02.pdf'})]
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model_name = llm_name, temperature=0)
llm.predict('hello world!')
# build prompt
from langchain.prompts import PromptTemplate
template = """Use the following pieces of context to answer the question at the end. \
If you don't know the answer, just say that you don't know, don't try to make up an answer. \
Use three sentences maximum. Keep the answer as concise as possible. \
Always say "thanks for asking!" at the end of the answer.
{context}
Question: {question}
Helpful Answer:"""
QA_CHAIN_PROMPT = PromptTemplate(input_variables=['context', 'question'],
template= template)프롬프트 템플릿을 초기화하고 검색 QA 체인을 생성한 다음 질문을 전달하고 결과를 얻을 수 있다.
# run Chain
from langchain.chains import RetrievalQA
question = "Is probability a class topic?"
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever = vectordb.as_retriever(),
return_source_documents = True,
chain_type_kwargs={'prompt': QA_CHAIN_PROMPT}
)이제 여기서 본격적으로 메모리를 추가한다.
여기서는 대화 버퍼 메모리를 사용하여 작업하는데, 이것이 하는 일은 단순히 기록에 있는 채팅 메시지의 버퍼 목록을 유지하고 매번 질문과 함께 이를 챗봇에 전달하는 것이다.
메모리 키, 채팅 기록을 지정하고 프롬프트의 입력 변수와 함께 정렬된다.
그런 다음 반환 메시지가 true임을 지정한다.
result = qa_chain({'query': question})
result
##output
{'query': 'Is probability a class topic?',
'result': 'Yes, probability is a class topic. Thanks for asking!',
'source_documents': [Document(page_content="of this class will not be very program ming intensive, although we will do some \nprogramming, mostly in either MATLAB or Octa ve. I'll say a bit more about that later. \nI also assume familiarity with basic proba bility and statistics. So most undergraduate \nstatistics class, like Stat 116 taught here at Stanford, will be more than enough. I'm gonna \nassume all of you know what ra ndom variables are, that all of you know what expectation \nis, what a variance or a random variable is. And in case of some of you, it's been a while \nsince you've seen some of this material. At some of the discussion sections, we'll actually \ngo over some of the prerequisites, sort of as a refresher course under prerequisite class. \nI'll say a bit more about that later as well. \nLastly, I also assume familiarity with basi c linear algebra. And again, most undergraduate \nlinear algebra courses are more than enough. So if you've taken courses like Math 51, \n103, Math 113 or CS205 at Stanford, that would be more than enough. Basically, I'm \ngonna assume that all of you know what matrix es and vectors are, that you know how to \nmultiply matrices and vectors and multiply matrix and matrices, that you know what a matrix inverse is. If you know what an eigenvect or of a matrix is, that'd be even better. \nBut if you don't quite know or if you're not qu ite sure, that's fine, too. We'll go over it in \nthe review sections.", metadata={'page': 4, 'source': 'data/MachineLearning-Lecture01.pdf'}),
Document(page_content='Instructor (Andrew Ng) :Yeah, yeah. I mean, you’re asking about overfitting, whether \nthis is a good model. I thi nk let’s – the thing’s you’re mentioning are maybe deeper \nquestions about learning algorithms that we’ll just come back to later, so don’t really \nwant to get into that right now. Any more questions? Okay. \nSo this endows linear regression with a proba bilistic interpretati on. I’m actually going to \nuse this probabil – use this, sort of, probabilist ic interpretation in order to derive our next \nlearning algorithm, which will be our first classification algorithm. Okay? So you’ll recall \nthat I said that regression problems are where the variable Y that you’re trying to predict \nis continuous values. Now I’m actually gonna ta lk about our first cl assification problem, \nwhere the value Y you’re trying to predict will be discreet value. You can take on only a \nsmall number of discrete values and in th is case I’ll talk about binding classification \nwhere Y takes on only two values, right? So you come up with classi fication problems if \nyou’re trying to do, say, a medical diagnosis and try to decide based on some features that \nthe patient has a disease or does not have a di sease. Or if in the housing example, maybe \nyou’re trying to decide will this house sell in the next six months or not and the answer is \neither yes or no. It’ll either be sold in the next six months or it won’t be. Other standing', metadata={'page': 10, 'source': 'data/MachineLearning-Lecture03.pdf'}),
Document(page_content="statistics for a while or maybe algebra, we'll go over those in the discussion sections as a \nrefresher for those of you that want one. \nLater in this quarter, we'll also use the disc ussion sections to go over extensions for the \nmaterial that I'm teaching in the main lectur es. So machine learning is a huge field, and \nthere are a few extensions that we really want to teach but didn't have time in the main \nlectures for.", metadata={'page': 8, 'source': 'data/MachineLearning-Lecture01.pdf'}),
Document(page_content='come back to this again. Any questions a bout this? Actually, let me clean up another \ncouple of boards and then I’ll see what questions you have. \nOkay. Any questions? Yeah? \nStudent: You are, I think here you try to measure the likelihood of your nice of theta by a \nfraction of error, but I think it’s that you measure because it depends on the family of \ntheta too, for example. If you have a lot of parameters [inaudible] or fitting in?', metadata={'page': 9, 'source': 'data/MachineLearning-Lecture03.pdf'})]}이것은 단일 문자열이 아닌 메시지 목록으로 채팅 기록을 반환한다.
이것은 가장 간단한 유형의 메모리이다.
result는 'Yes, probability is a class topic. Thanks for asking!'를 반환한다.
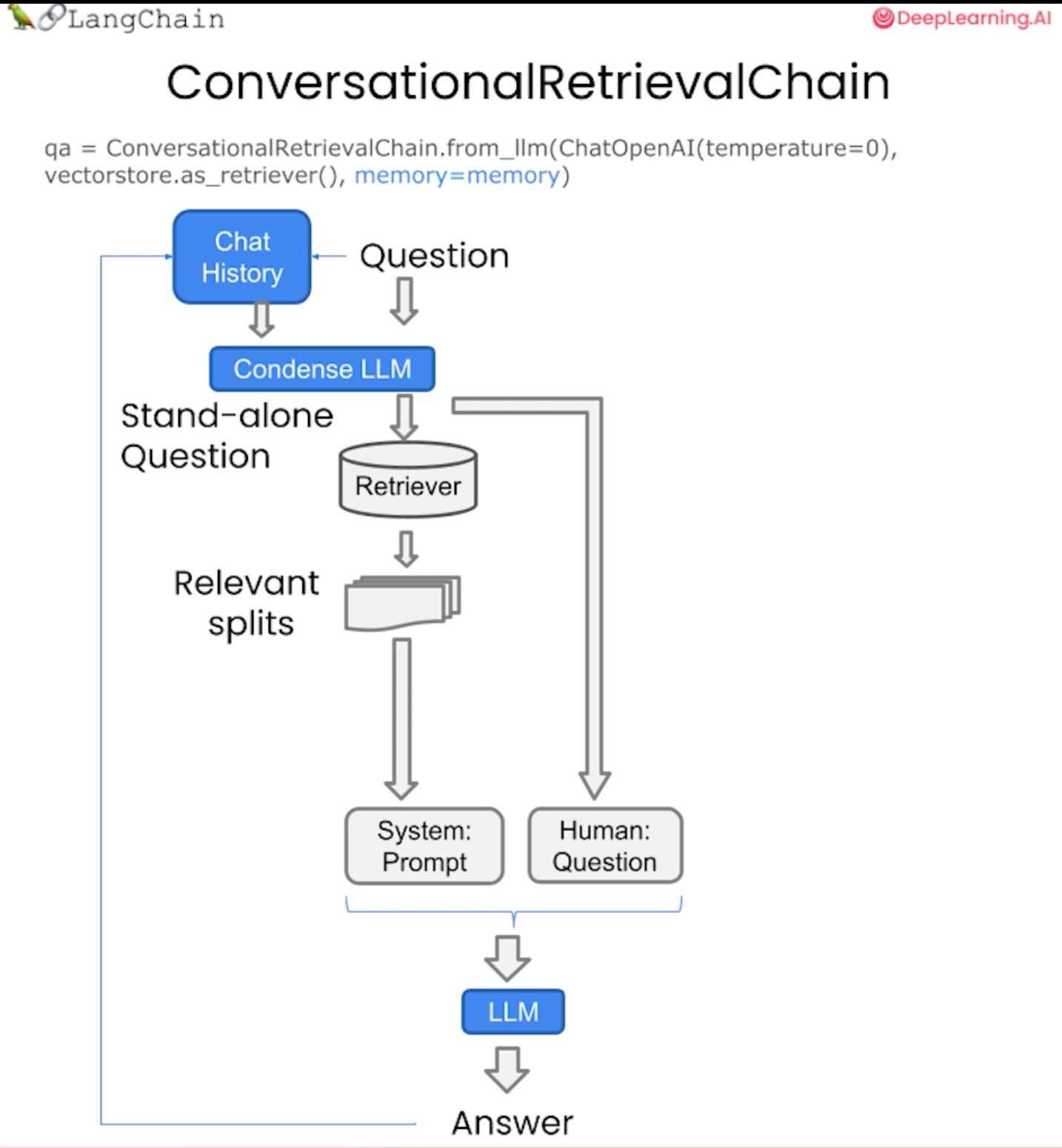
이제 새로운 유형의 체인인 대화형 검색 체인을 만든다. 우리는 언어 모델을 전달하고, 검색기를 전달하고, 메모리에 전달한다.
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(
memory_key='chat_history',
return_messages=True
)대화형 검색 체인은 메모리뿐만 아니라 검색 QA 체인 위에 새로운 비트를 추가한다.
from langchain.chains import ConversationalRetrievalChain
retriever = vectordb.as_retriever()
qa = ConversationalRetrievalChain.from_llm(
llm,
retriever=retriever,
memory = memory
)
구체적으로 추가되는 것은 기록과 새로운 질문을 가져와 관련 문서를 조회하기 위해 벡터 저장소에 전달할 독립형 질문으로 압축하는 단계를 추가한다는 것이다.
이를 실행한 후 UI에서 살펴보고 어떤 효과가 있는지 살펴본다.
반환하는 결과를 확인하고, 그 대답에 대한 후속 질문을 해본다.
이는 이전과 동일한 질문이다. 그래서 우리는 확률이 수업 주제인가요?
question = 'Is probability a class topic?'
result = qa({'question':question})
result
##output
{'question': 'Is probability a class topic?',
'chat_history': [HumanMessage(content='Is probability a class topic?'),
AIMessage(content='Yes, probability is mentioned as a prerequisite for the class. The instructor assumes familiarity with basic probability and statistics.')],
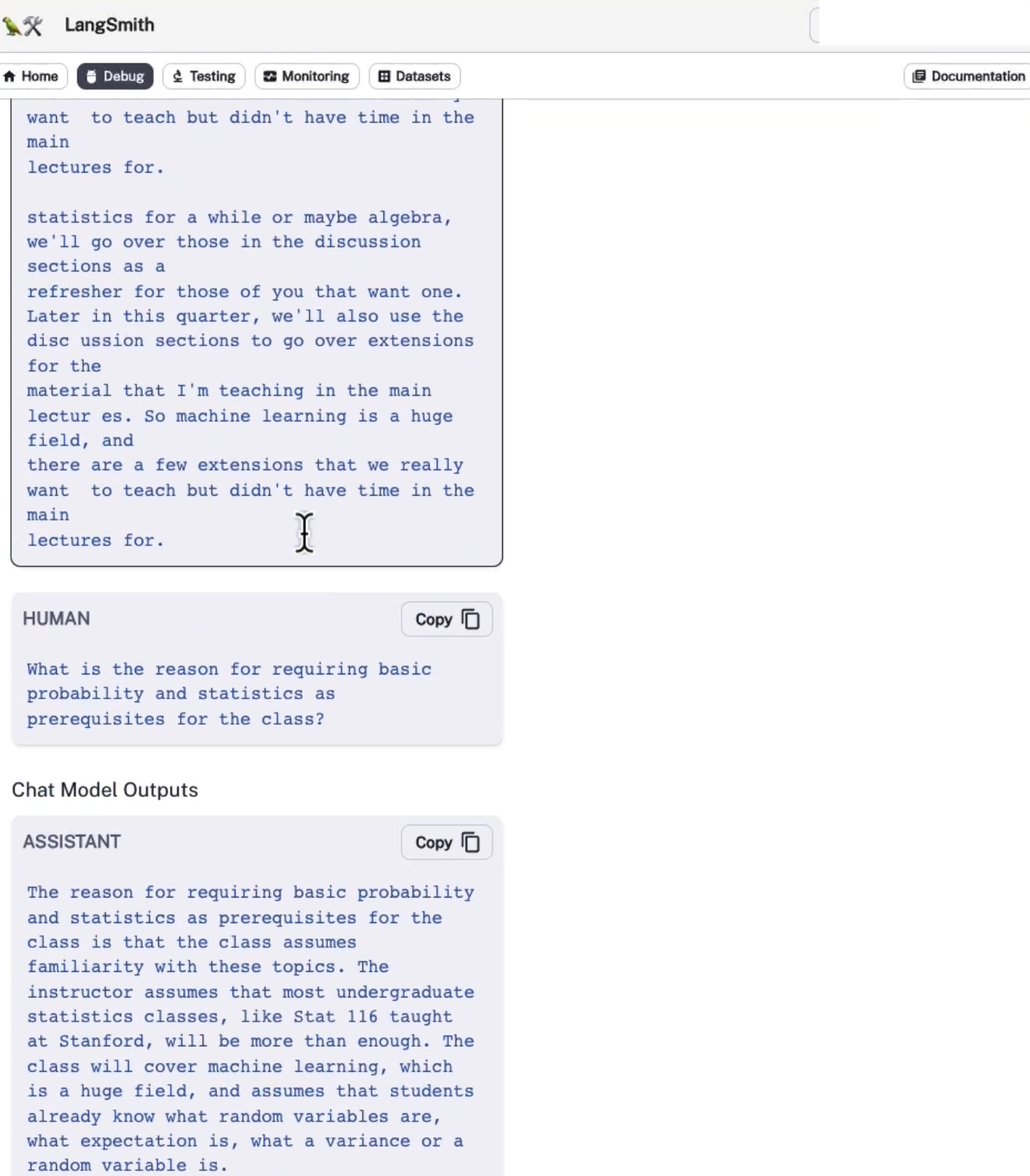
'answer': 'Yes, probability is mentioned as a prerequisite for the class. The instructor assumes familiarity with basic probability and statistics.'}답을 얻은 후에, 이러한 전제 조건이 왜 필요한지 후속질문을 한다.
question = 'why are those prerequeites needed?'
result = qa({'question': question})
result['answer']
##output
'Familiarity with basic probability and statistics is needed as prerequisites for the class because machine learning heavily relies on these concepts. Understanding probability and statistics is crucial for understanding the underlying principles and algorithms used in machine learning. It helps in analyzing and interpreting data, making predictions, and evaluating the performance of machine learning models. Without a basic understanding of probability and statistics, it would be challenging to grasp the concepts and techniques taught in the class.'이전과 다르게 그 답은 이전처럼 컴퓨터 과학과 혼동하지 않고 기본적인 확률과 통계를 전제 조건으로 언급하고 이를 확장하고 있음을 알 수 있다.
기존의 답은
'The prerequisites are needed because the course assumes familiarity with basic probability and statistics, as well as basic linear algebra. These concepts are fundamental to understanding and applying machine learning algorithms. Without a solid understanding of probability, statistics, and linear algebra, it would be difficult to grasp the concepts and techniques taught in the course.'
=> '기본적인 확률과 통계는 물론 기본적인 선형대수학에 대한 지식을 전제로 하기 때문에 전제조건이 필요합니다. 이러한 개념은 기계 학습 알고리즘을 이해하고 적용하는 데 기본입니다. 확률, 통계, 선형대수학에 대한 확실한 이해가 없으면 이 과정에서 가르치는 개념과 기술을 이해하기 어려울 것입니다.'
현재 메모리를 얹은 후에 나온 답은
'Familiarity with basic probability and statistics is needed as prerequisites for the class because machine learning heavily relies on these concepts. Understanding probability and statistics is crucial for understanding the underlying principles and algorithms used in machine learning. It helps in analyzing and interpreting data, making predictions, and evaluating the performance of machine learning models. Without a basic understanding of probability and statistics, it would be challenging to grasp the concepts and techniques taught in the class.'
=> '머신러닝은 이러한 개념에 크게 의존하기 때문에 기본 확률과 통계에 대한 지식이 수업의 전제 조건으로 필요합니다. 기계 학습에 사용되는 기본 원리와 알고리즘을 이해하려면 확률과 통계를 이해하는 것이 중요합니다. 이는 데이터 분석 및 해석, 예측, 기계 학습 모델의 성능 평가에 도움이 됩니다. 확률과 통계에 대한 기본적인 이해가 없으면 수업에서 가르치는 개념과 기법을 이해하기가 어려울 것입니다.'
인 것을 확인할 수 있다.
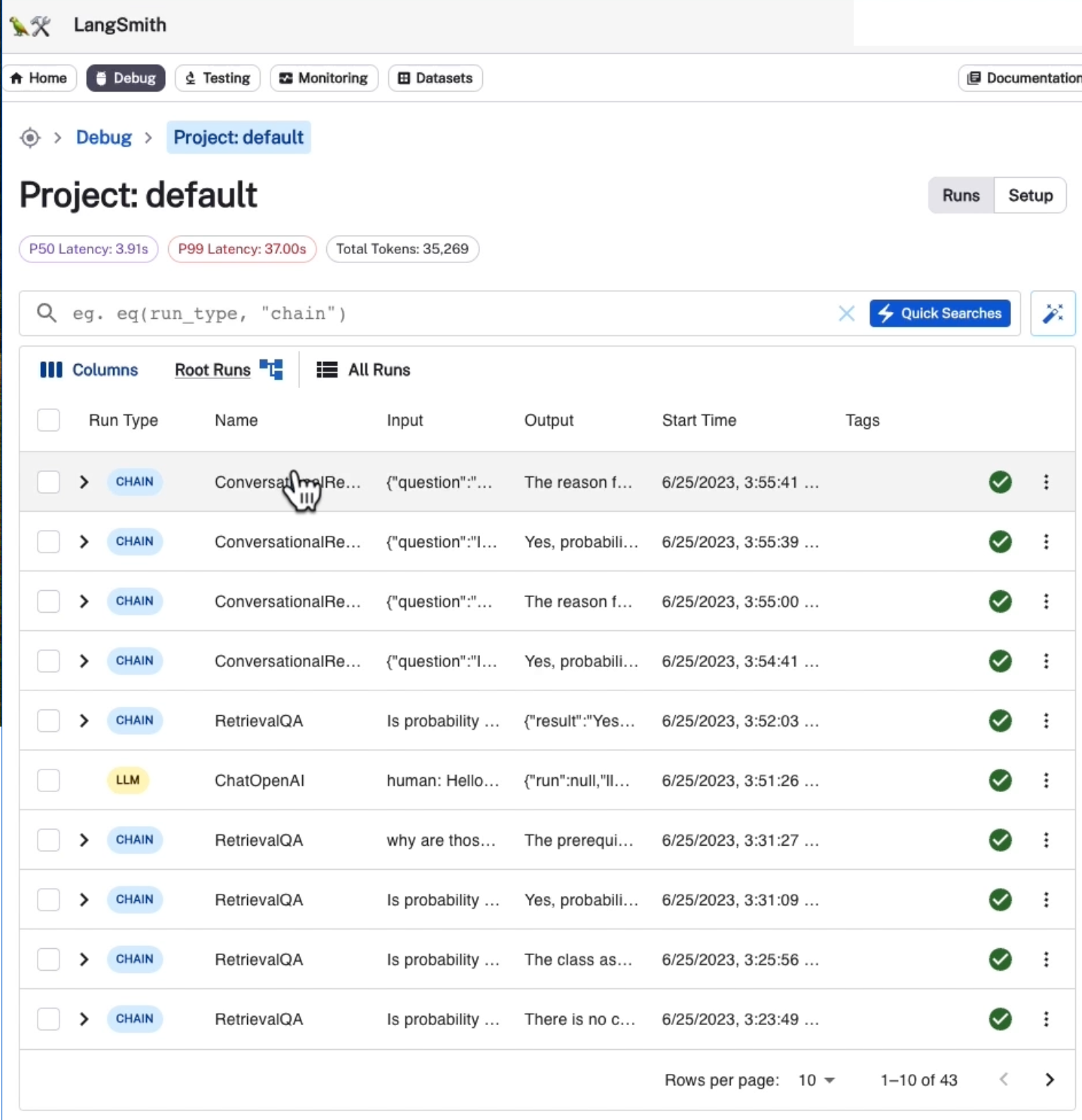
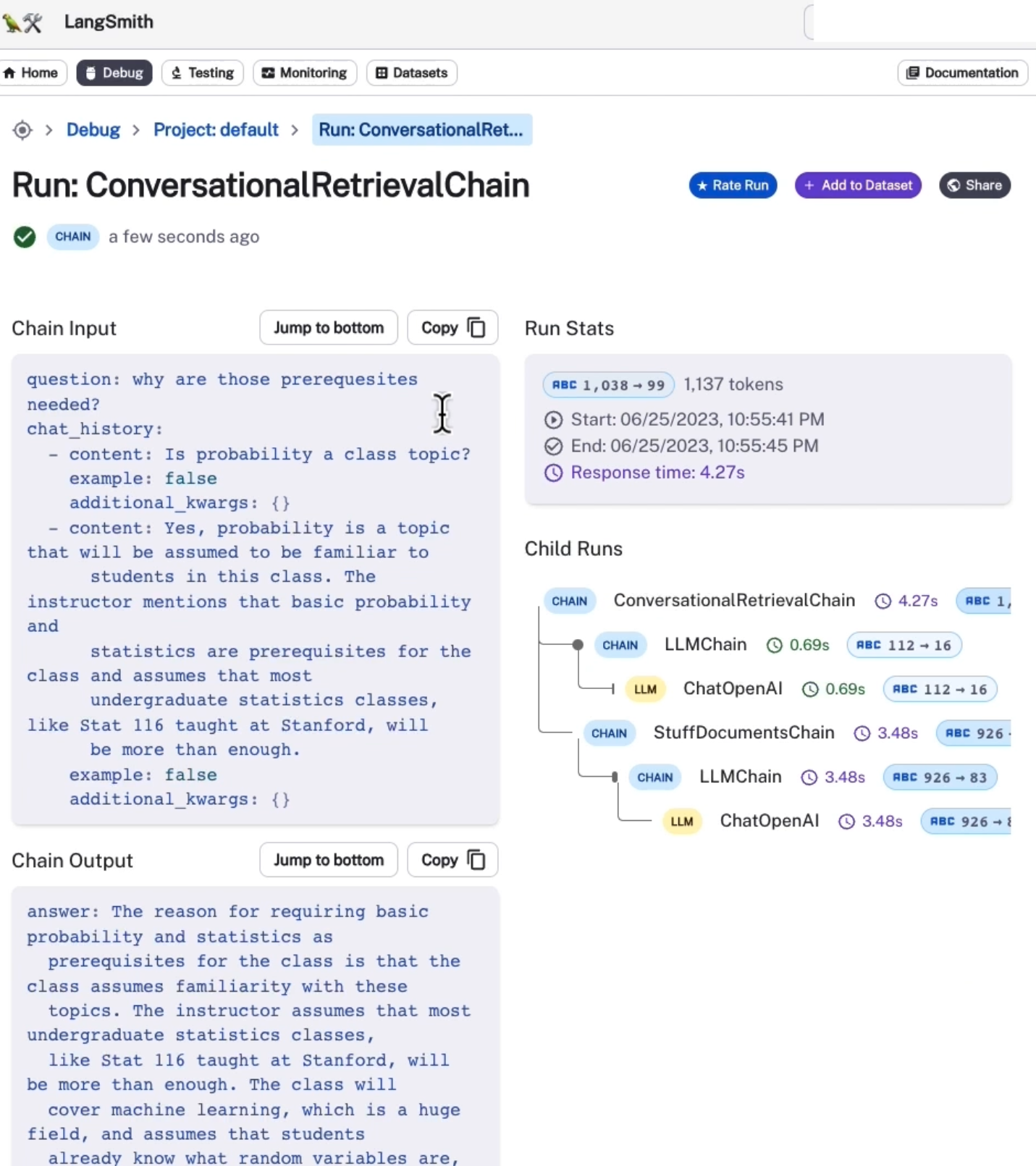
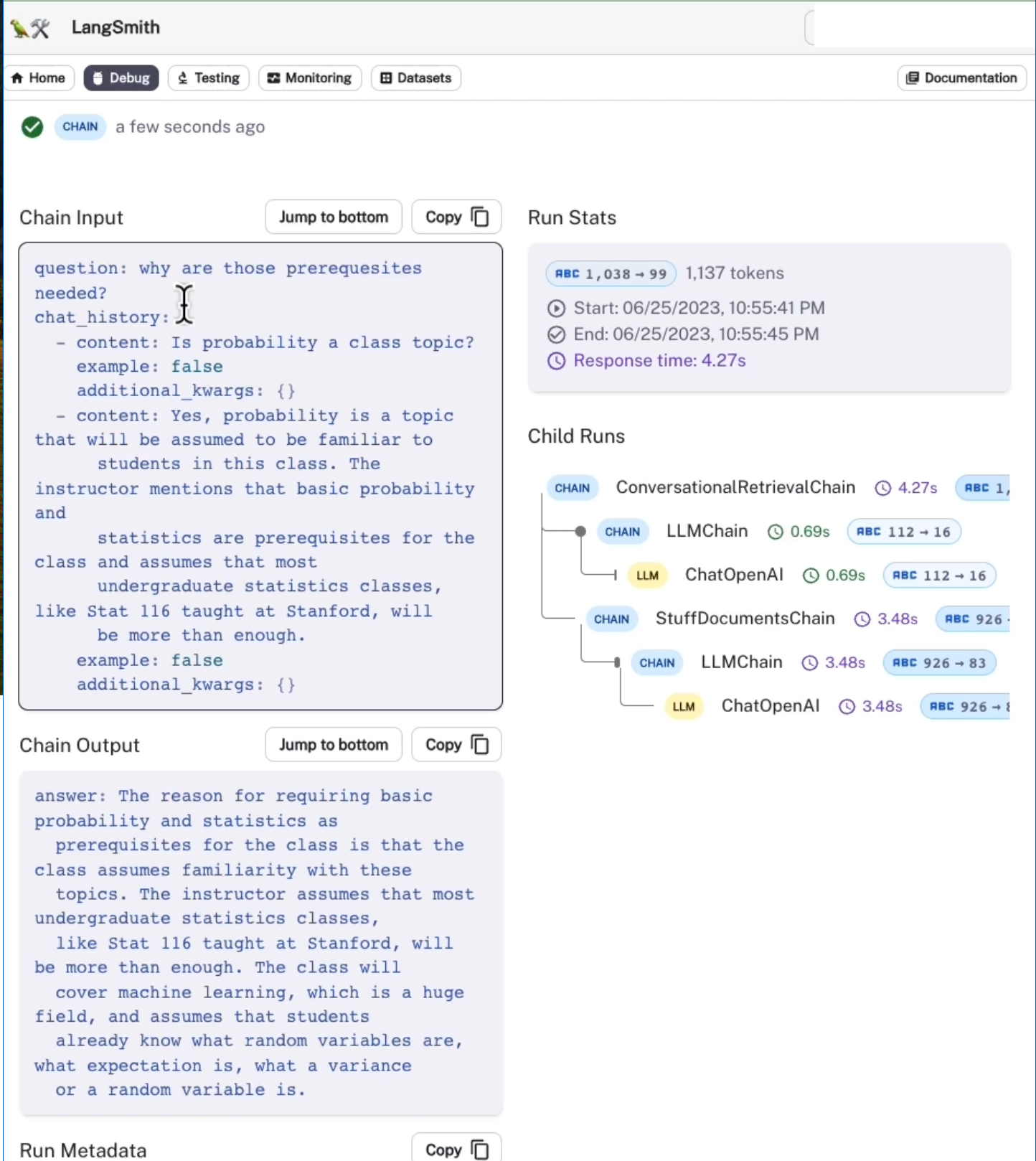
UI 내부에서 어떤 일이 벌어지고 있는지 살펴보면,
체인에 대한 입력에는 질문뿐만 아니라 채팅 기록도 포함되어 있음을 알 수 있다.
채팅 기록은 메모리에서 나오며 이는 체인이 호출되어 이 로깅 시스템에 기록되기 전에 적용된다.
추적해보면 두 가지 별도의 작업이 진행되고 있음을 알 수 있다. 먼저 LLM에 대한 호출이 있고 그 다음에는 관련 문서 체인에 대한 호출이 있다.
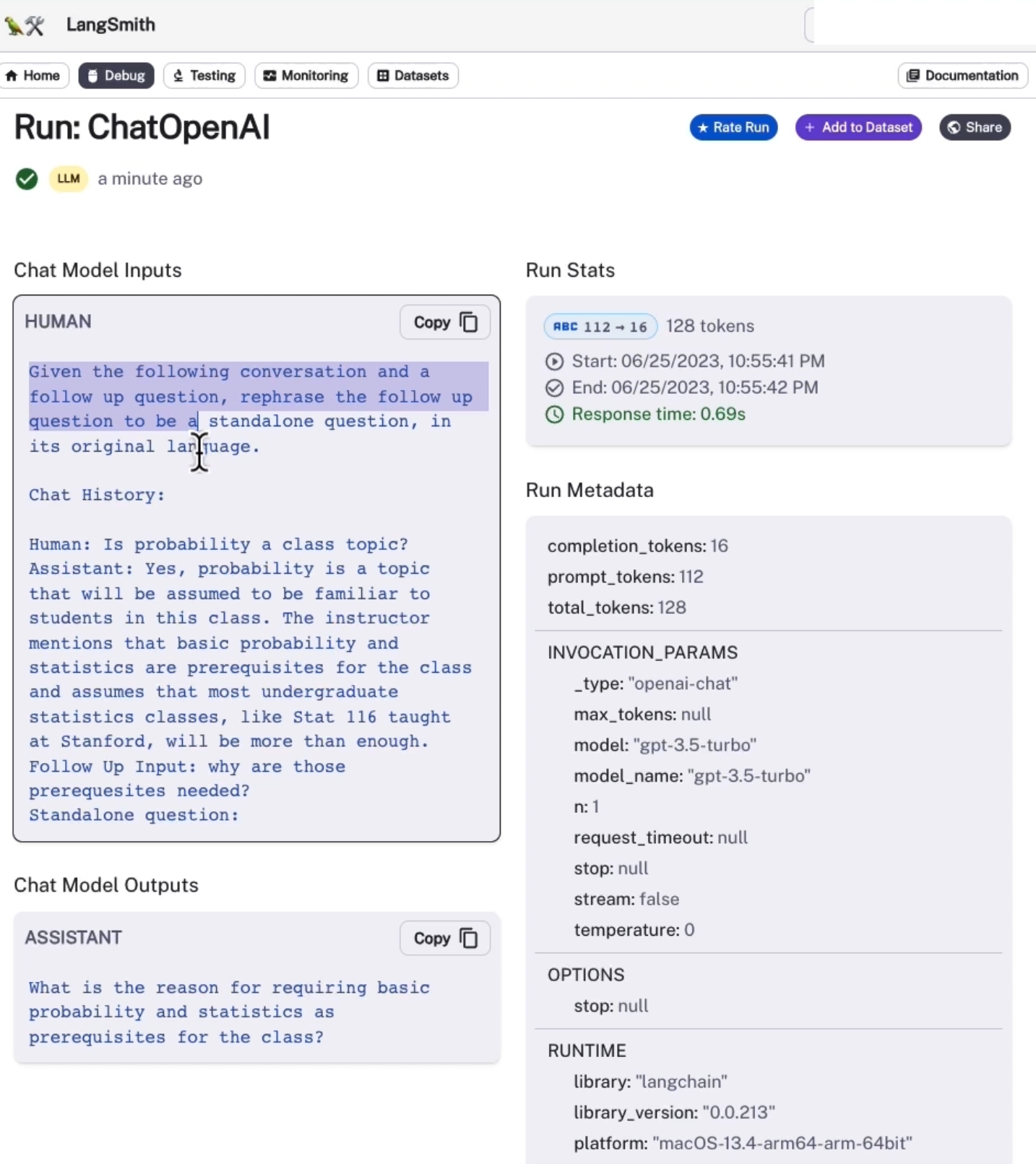
첫 번째 콜을 살펴보면 여기에서 몇 가지 지침이 포함된 프롬프트를 볼 수 있다.
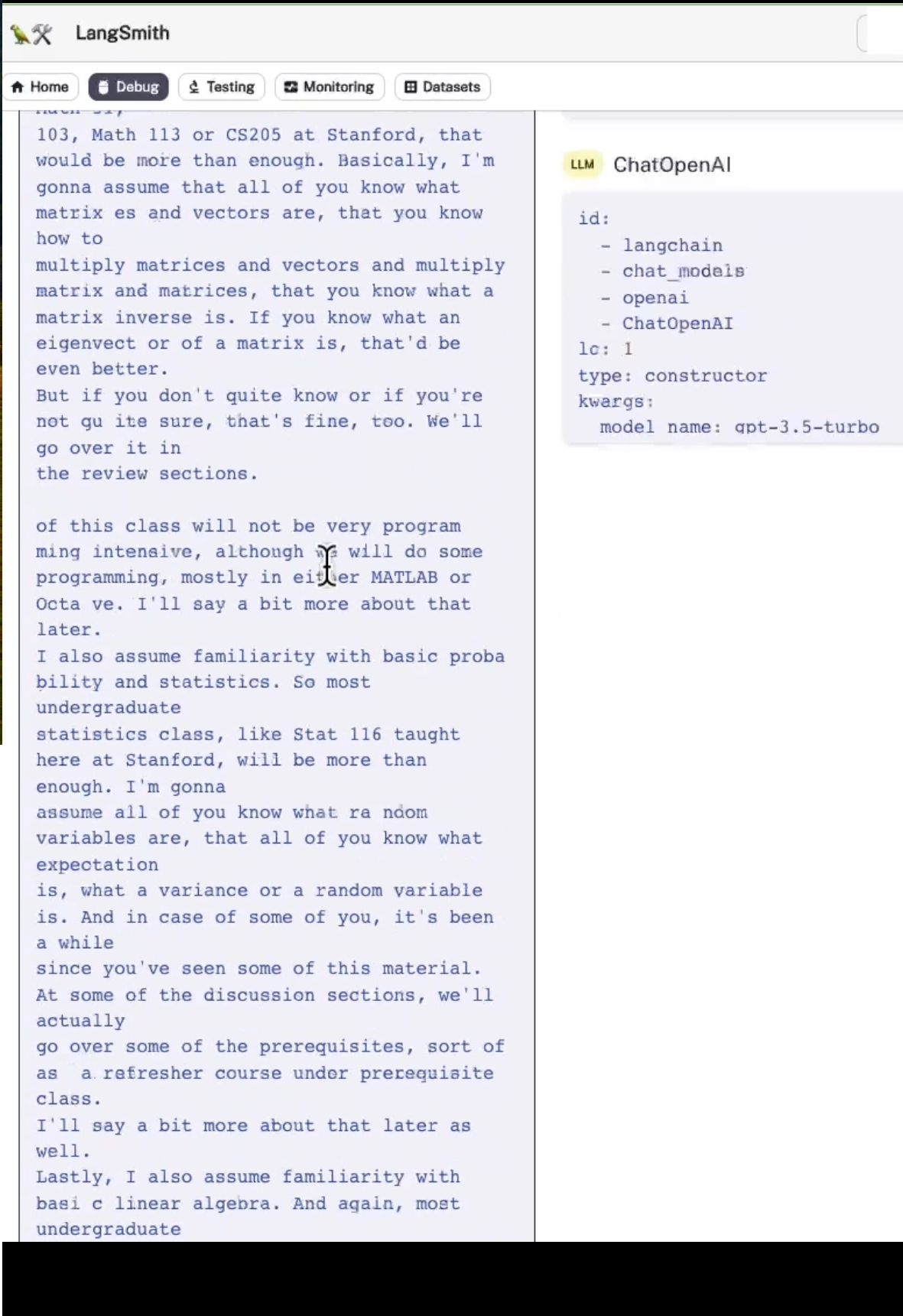
다음 대화와 후속 질문이 주어지면 "후속 질문을 독립형 질문으로 바꾸어 표현하세요. 여기에는 이전의 히스토리가 있다. 그래서 우리가 먼저 물어본 질문인 "확률이 수업 주제인가요?" 이고, 추후에 답변이 제공된다.
그리고 여기에 독립형 질문으로 "기본적인 확률과 통계학을 수업의 전제조건으로 요구하는 이유는 무엇인가요?" 에 대한 독립형 응답이 검색기로 전달되고 4개의 문서, 3개의 문서 또는 우리가 지정한 만큼 검색한다.
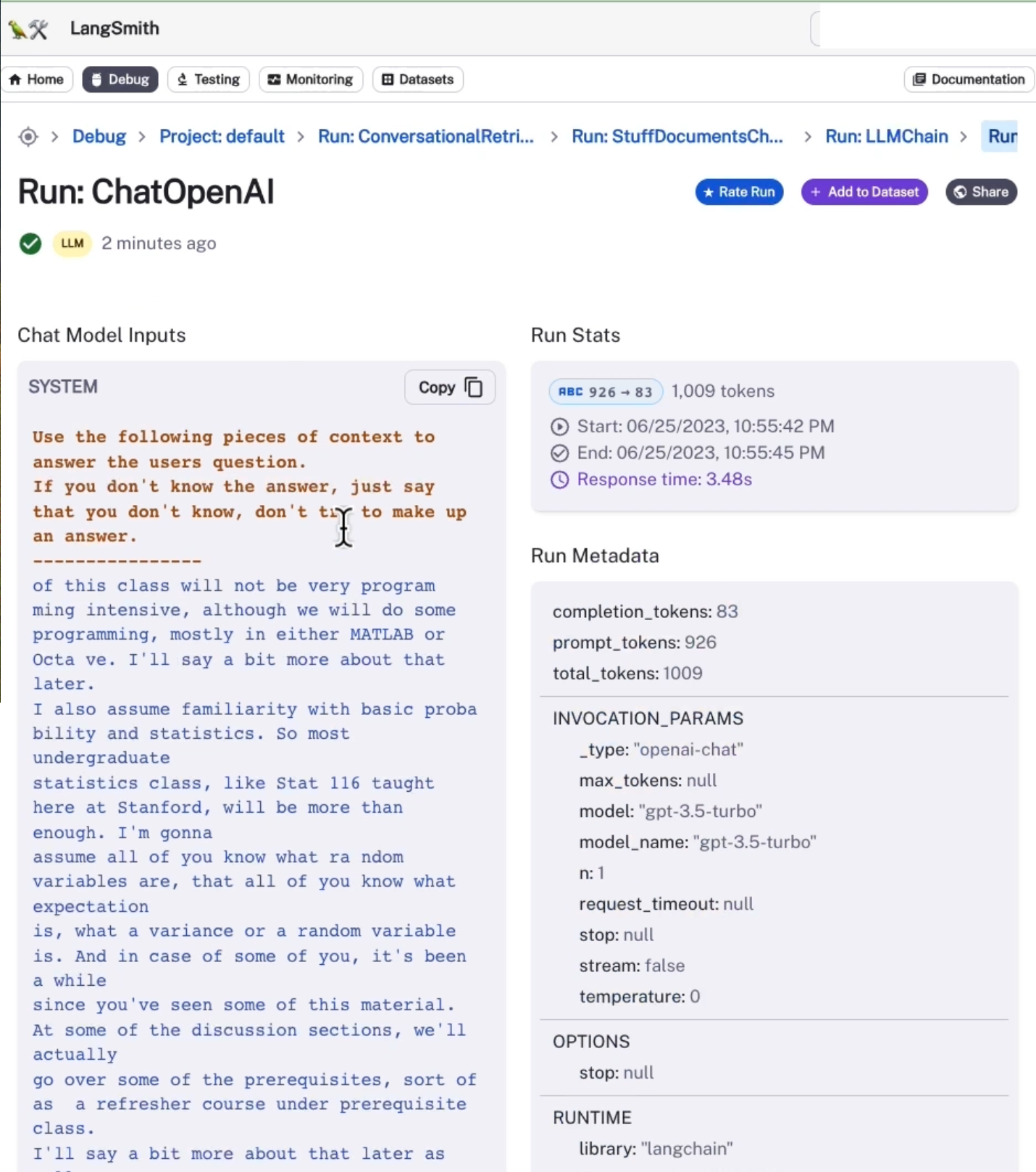
그런 다음 해당 문서를 stuff 문서 체인에 전달하고 원래 질문에 답하려고 한다.
따라서 이를 살펴보면 시스템 답변이 있음을 알 수 있다. 다음 컨텍스트 조각을 사용하여 사용자의 질문에 답변한다.
우리는 많은 컨텍스트를 가지고 있고, 독립형 질문들이 있다. 그러면 우리는 확률과 통계를 전제 조건으로 하는 질문과 관련된 답변을 얻을 수 있다.
◼︎ final chat model code
질문에 답변할 때뿐만 아니라 해당 질문을 독립형 질문으로 다시 표현하기 위해 다양한 프롬프트 템플릿을 전달할 수도 있다. 여기에서 이제부터는 다양한 유형의 메모리와 다양한 옵션을 시도해본다.
db와 retriever chain을 로드하고, 파일을 전달한다.
PDF loader로 pdf 파일을 불러온 후, 해당 문서를 분할한다.(splitter),
그 후 분할한 문서를 우리는 임베딩을 생성하여 벡터 저장소에 저장한다.
해당 벡터 저장소를 retriever로 변환하고, "search_kwargs=k"와 유사성을 사용하여 전달할 수 있는 매개변수와 동일하게 설정한다.
그런 다음 대화형 검색 체인을 만드는 데, 여기서는 메모리를 전달하지 않는 것이다. 여기서는 GUI의 편의를 위해 메모리를 외부에서 관리하도록 한다. 그 이유는 채팅 기록이 체인 외부에서 관리되어야 하기 때문이다.
그다음 채팅 기록을 연결된 메모리가 없기 때문에 체인으로 전달하고, 나온 결과로 채팅 기록을 확장한다. 그런 다음 모든 것을 하나로 모아 이를 실행하여 챗봇과 상호 작용할 수 있는 코드를 구현할 수 있다.
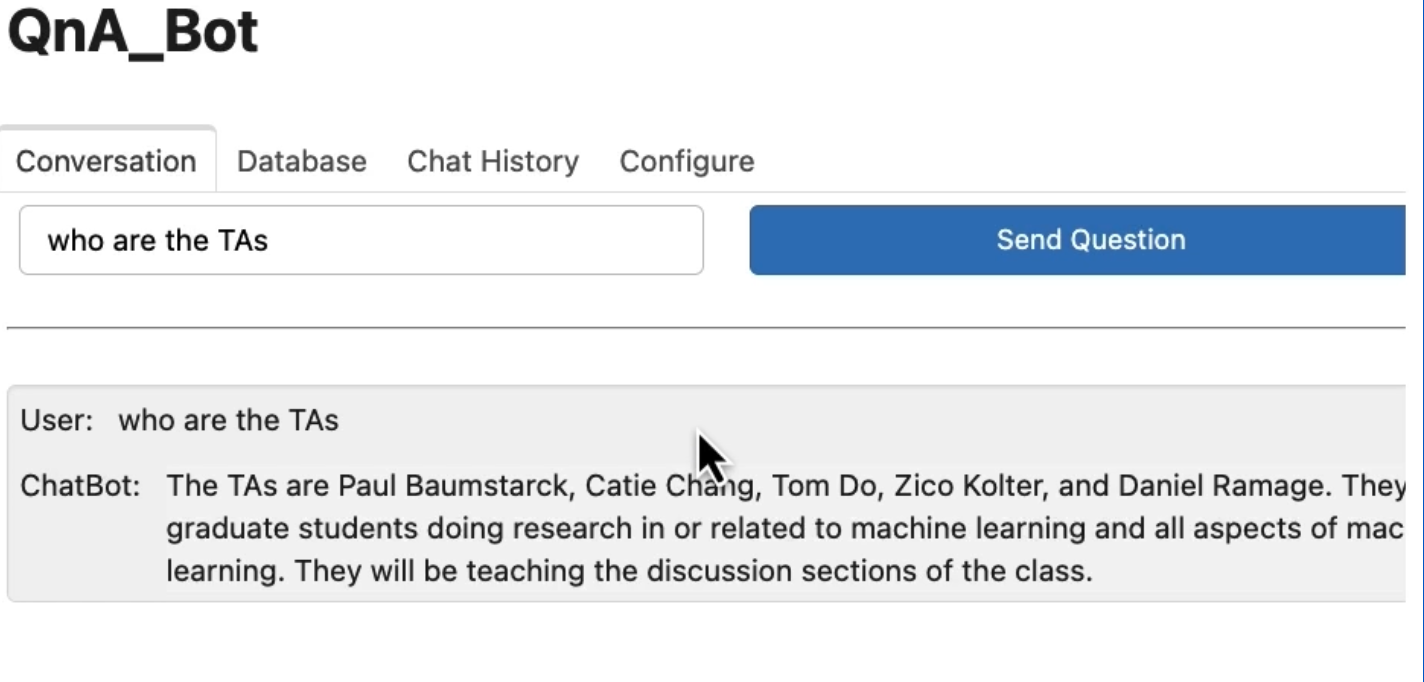
구현된 코드로 " TA는 누구입니까?" 라는 질문을 한다면
"TA는 Paul Baumstarck, Catie Chang입니다. " 라는 답변을 얻을 수 있다.
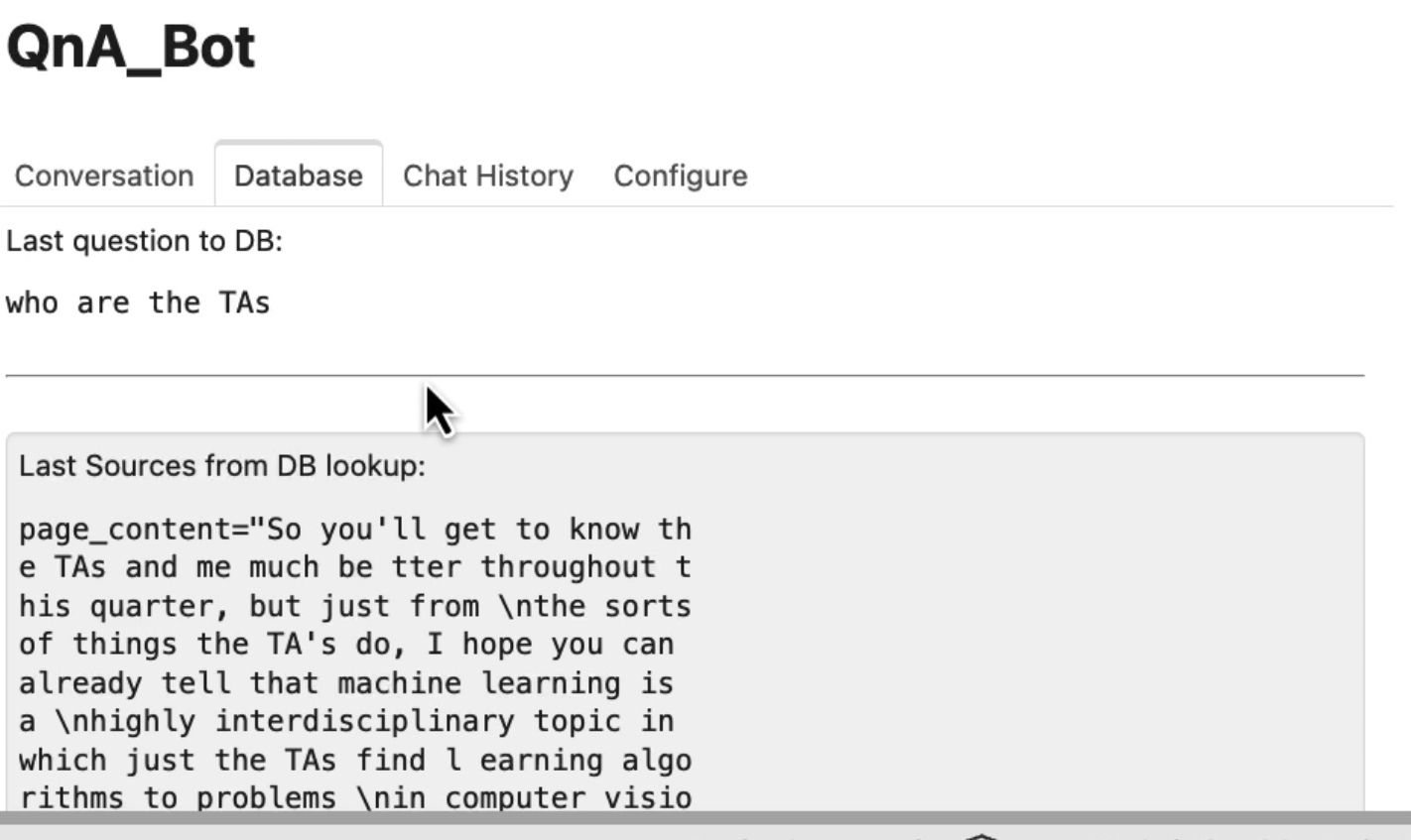
해당 데이터베이스를 클릭하면 데이터베이스에 대해 마지막으로 질문한 질문과 검색에서 얻은 소스를 볼 수 있다.
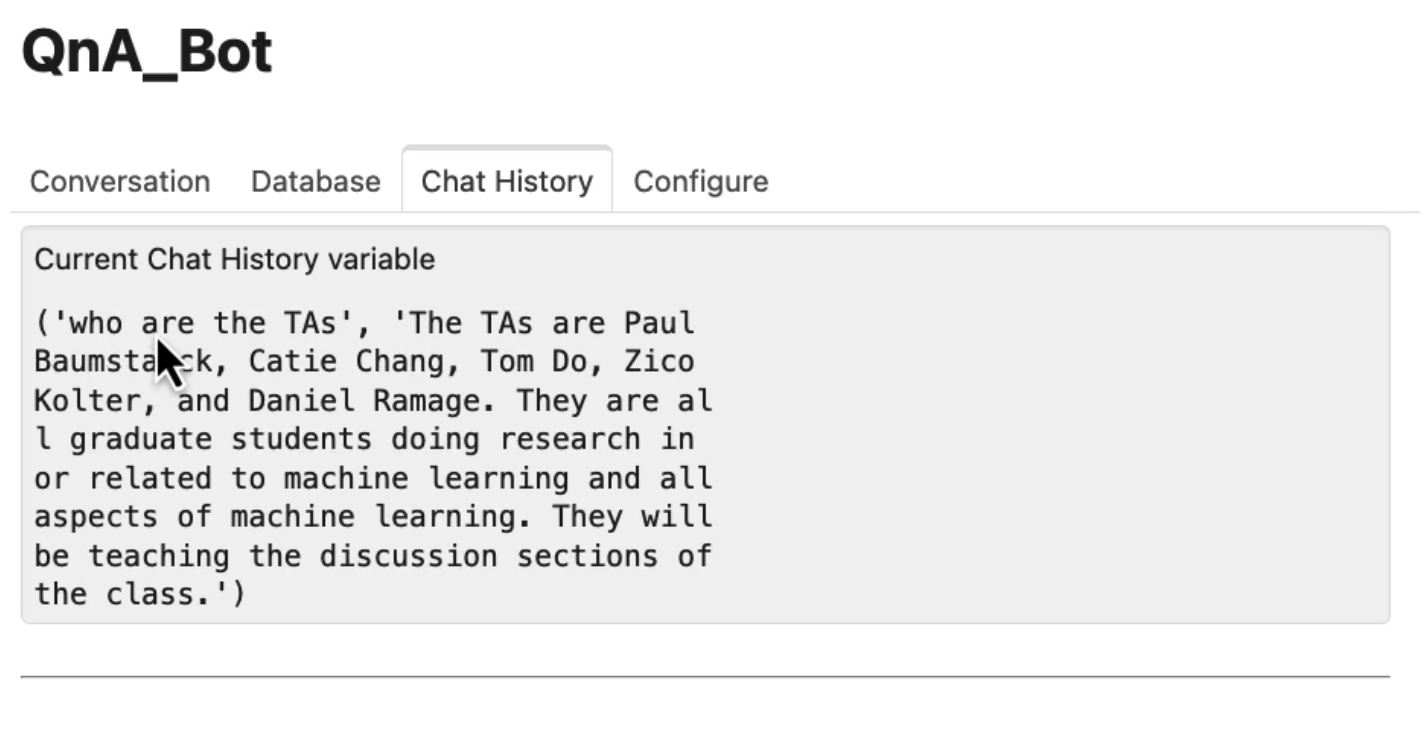
해당 문서는 분할이 발생한 후를 보여주는데, 검색한 각 청크들이다. 입력과 출력이 포함된 채팅 기록을 볼 수 있다. 그리고 그리고 파일을 업로드할 수 있는 구성 공간도 있는 것을 볼 수 있다.
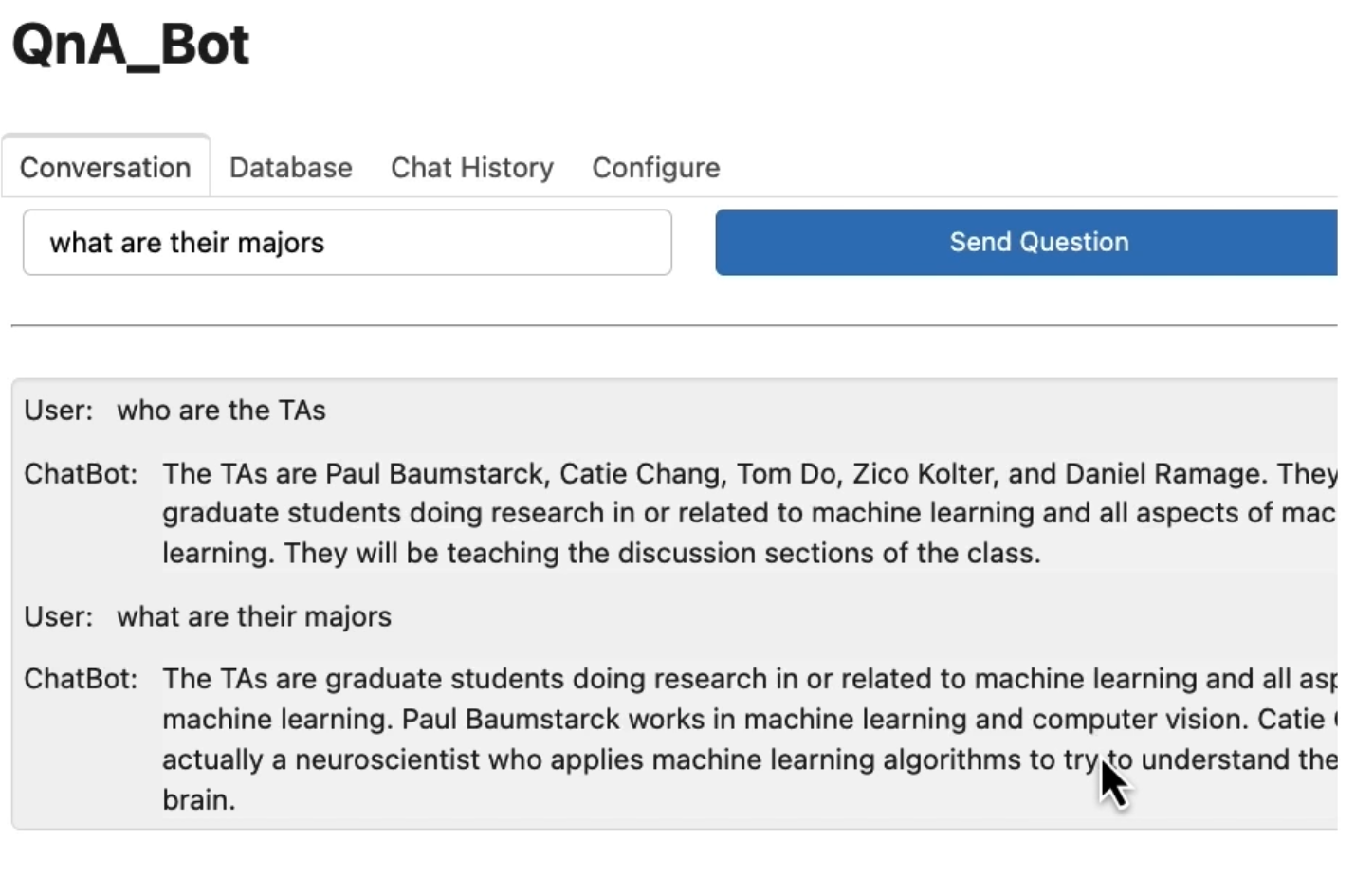
그 이후에 후속 질문을 요청할 수도 있다. 예를 들면 "그들의 전공이 무엇인가요" 인데, 앞서 언급한 TA에 대한 답변을 받을 수 있다. Paul은 기계 학습과 컴퓨터 비전을 연구하고 있고 Catie는 실제로 신경과학자라는 답변을 얻을 수 있다.
