[LLM] Searching for Best Practices in Retrieval-Augmented Generation (대규모 언어 모델을 위한 검색-증강 생성(RAG) 기술 현황 관련 논문) 정리
Paper
서론
RAG(검색-증강 생성)을 활용해서 서비스를 만들고 있는 와중에 여러 이슈에 봉착하고는 한다. 일단 나는 vectordb에 정제된 데이터들을 넣고 RAG를 활용해서 최대한 도메인 집약적이고, 할루시네이션을 줄이는 가장 간단한 방법을 사용하고 있다.
LLM이 최전선에서 여러 많은 연구가 개발되고 있는 와중에 RAG에 대한 최신 연구를 찾아보다가 링크드인에서 해당 논문에 대한 추천을 보고 한 번 시간내서 쭉 읽어봤다.
나란 사람은 약간 tmi 충이기도 하고 석사시절부터 논문 리뷰를 할때 어려웠던 점은 모든 부분이 다 중요해보이는데 여기서 어떻게 가장 중요한 부분만 찾아서 발췌하지? 였는데 이 논문 역시도 중요한 부분을 발췌하기가 너무 어려웠던 것이다.
일단은 내용을 주르륵 다 읽었고 내용을 거의 다 통번역해서 읽었다. 물론 번역기와 gpt와 함께 했다.
그래서 gpt와 내가 같이 이뤄낸 해당 논문의 정리는 다음과 같다
서론 및 배경
- 대형 언어 모델 (LLM)은 최신 정보를 반영하지 못하거나 잘못된 정보를 생성하는(할루시네이션) 문제가 있음
- 이를 Retrieval-Augment3d Generation (RAG) 기술을 통해 문제를 해결하는데, RAG는 사전 훈련된 언어 모델과 검색 기반 모델의 강점을 결합해 성능을 향상시키는 것
연구목적
- 다양한 RAG 접근 방식을 비교해 최적의 구현 방법을 도출, 효율성과 성능 간의 균형을 맞춘 전략 제안
기존 연구
- 단순히 모델 크기를 키우는 것으로 지식 집약적인 작업이나 전문 분야에서의 오류를 줄일 수 없는데, RAG는 외부 지식 베이스에서 관련 문서를 검색해 정확한 정보를 제공함으로써 이러한 문제를 해결함
- 기존 연구의 방법으로는 쿼리 변환, 검색 기능 향상, 검색기 및 생성기 fine-tune
RAG 워크플로우
- 주요 단계 : 쿼리 분류(query classification), 검색(Retrieval), 재순위 지정(Reranking), 재구성(Repacking), 요약( Summarization) 등의 여러 중간 처리 단계로 구성
- 각 단계의 다양한 구현 방법이 존재하고, 이들의 조합이 RAG 시스템의 성능과 효율성에 영향을 미침
결론
RAG 시스템을 구현하기 위한 여러 모듈들의 조합의 실험을 수행했고,
특정 요구 사항을 해결하기 위한 두 가지 구체적인 방법을 발견했음
[1] 성능을 극대화 하는데 중점을 둘 경우 [2] 효율성과 효과성 사이의 균형을 희망할 경우
[1] 최고 성능 관행(Best Performance Practice) 중심:
- 최고의 성능을 달성하기 위해서는 쿼리 분류 모듈을 포함
검색(retriever) 에는 “Hybrid with HyDE” 방법을 사용
재정렬(Rerank) 에는 monoT5를 사용
재포장(Repacking) 에는 Reverse를 선택
요약(summarization) 에는 Recomp을 활용하는 것이 권장됨
paper에 국한되어 있지만 이 구성은 평균 점수 0.483을 기록하였음
[2] 효율성과 효과성에 대한 균형(Balanced Efficiency Practice) 맞추려고 할 때 :
- 성능과 효율성 사이의 균형을 맞추기 위해서는 쿼리 분류 모듈을 포함
검색(retriever) 에는 Hybrid 방법을 구현
재정렬(Rerank) 에는 TILDEv2를 사용
재포장(Repack) 에는 Reverse를 선택
요약(summarization) 에는 Recomp을 사용
→ 검색 모듈이 시스템에서 처리 시간의 대부분을 차지하기 때문에, 다른 모듈은 그대로 두고 Hybrid 방법으로 전환하는 것만으로도 지연 시간을 크게 줄이면서 비슷한 성능을 유지할 수 있음
아래는 전체 논문에 대한 내용이고 추가로 참고하면 좋을 듯 하다.
논문 내용
1. Introduction
생성적 대형 언어 모델은 강화 학습 또는 경량화를 통해 인간의 선호도에 맞춰 조정되었지만 오래된 정보를 생성하거나 사실을 조작하는 경향이 있다. 검색 증강 생성(RAG) 기술은 사전 훈련과 검색 기반 모델의 장점을 결합하여 모델 성능을 향상시키기 위한 강력한 프레임워크를 제공함으로써 이러한 문제를 해결한다.
또한 RAG를 사용하면 쿼리 관련 문서가 제공된다면 모델 매개변수를 업데이트할 필요 없이 특정 조직 및 도메인에 대한 애플리케이션을 신속하게 배포할 수 있다.
쿼리 종속 검색(query-dependent retrievals)을 통해 LLM(대형 언어 모델)을 향상시키기 위해 많은 RAG 접근 방식이 제안되었다. 일반적인 RAG 워크플로우에는 일반적으로 다음과 같은 여러 처리 단계가 포함된다.
- query classification : 주어진 입력에 대해 검색이 필요한지 여부 결정
- retrival : 쿼리와 관련된 문서를 효율적으로 가져오기
- reranking : 쿼리와의 관련성을 기준으로 검색된 문서의 순서를 재정의
- repacking : 더 나은 생성을 위해 검색된 문서를 구조화된 문서로 구성
- summarization : 재패킹된 문서의 응답 생성 및 중복 제거에 대한 정보
RAG를 구현하려면 문서를 청크로 적절하게 분할하는 방법, 이러한 청크를 의미적으로 표현하는 데 사용할 임베딩 유형, feature 표현을 효율적으로 저장하기 위한 벡터 데이터베이스 선택, LLM을 효과적으로 미세 조정하는 방법에 대한 결정이 필요하다. [그림 1 참고]
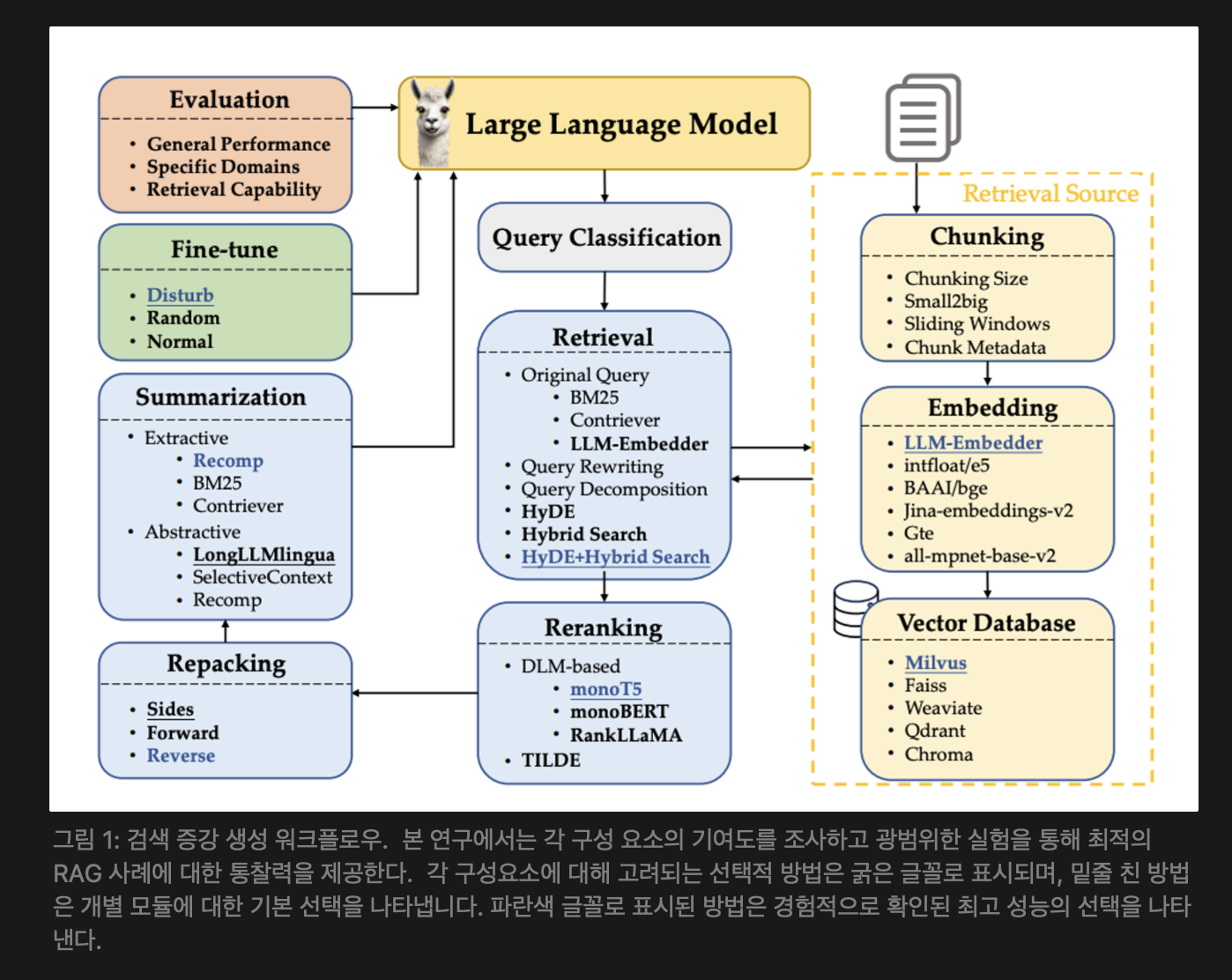
- 복잡한 과제와 처리해야 할 과제를 추가한다면 각 처리 단계를 구현은 가변적이다. 예를 들어, 입력된 질의에 대한 관련 문서를 검색하는데 있어서 다양한 방법이 선택될 수 있다. 한 가지 접근 방식은 먼저 쿼리를 다시 작성하고 검색을 위해 다시 작성된 쿼리를 사용하는 것이다. 또는 쿼리에 대한 응답을 먼저 생성하고 이러한 응답과 백엔드 문서 간의 유사성을 비교하여 검색하는 것이다. 또 다른 옵션은 일반적으로 긍정적 및 부정적 쿼리-응답 쌍을 사용하여 대조 방식으로 훈련되는 임베딩 모델을 직접 사용하는 것이다.
-
각 단계에 대해 선택된 기술과 그 조합은 RAG 시스템의 효과와 효율성 모두에 큰 영향을 미친다. 우리가
본 연구에서는 광범위한 실험을 통해 RAG의 모범 사례를 파악하는 것을 목표로 한다. 이러한 방법의 가능한 모든 조합을 테스트하는 것이 불가능하다는 점을 고려하여 최적의 RAG 사례를 식별하기 위해 3단계 접근 방식을 채택한다. -
먼저, 각 RAG 단계(또는 모듈)의 대표적인 방법을 비교하고 가장 성능이 좋은 방법 중 최대 3개를 선택한다. 다음으로, 다른 RAG 모듈은 변경하지 않고 개별 단계에 대해 한 번에 하나의 방법을 테스트하여 전체 RAG 성능에 대한 각 방법의 영향을 평가한다. 이를 통해 응답 생성 중 다른 모듈과의 기여도 및 상호 작용을 기반으로 각 단계에 대해 가장 효과적인 방법을 결정할 수 있다. 모듈에 가장 적합한 방법이 선택되면 후속 실험에 사용한다. 마지막으로, 성능보다 효율성이 우선시되거나 그 반대의 경우가 있는 다양한 애플리케이션 시나리오에 적합한 몇 가지 유망한 조합을 경험적으로 탐색한다. 이러한 결과를 바탕으로 이 연구에서는 성능과 효율성의 균형을 유지하는 RAG 배포를 위한 몇 가지 전략을 제안한다.
-
이 연구가 기여하는 것은 세 가지로,
[1] 광범위한 실험을 통해 기존 RAG 접근 방식과 그 조합을 철저히 조사하여 최적의 RAG 방식을 식별하고 권장 방식을 제공한다.
[2] 일반, 전문(또는 도메인별) 및 RAG 관련 기능을 포괄하는 검색 증강 생성 모델의 성능을 종합적으로 평가하기 위해 평가 지표 및 해당 데이터 세트의 포괄적인 프레임워크를 소개한다.
[3] multi-modal 검색 기술의 통합이 시각적 입력에 대한 질문 답변 기능을 실질적으로 향상시키고 "생성으로서의 검색" 전략을 통해 multi-modal 콘텐츠 생성 속도를 높일 수 있음을 보여준다.
2. Related Work
대형 언어 모델(LLM)인 chatGPT와 LLaMA가 생성하는 응답의 정확성을 보장하는 것은 필수적이다. 그러나 모델의 크기를 확장하는 것만으로는 특히 지식 집약적인 작업과 전문화된 도메인에서 발생하는 환각 문제를 근본적으로 해결 할 수 없다. RAG는 외부 지식 베이스에서 관련 문서를 검색해 이러한 과제를 해결하고 LLM에게 정확하고 실시간의 도메인 기반의 맥락을 제공한다.
이전 연구에서는 쿼리 및 검색 변환기, 검색기 성능 향상, 그리고 검색기와 생성기의 미세 조정을 통해 RAG 파이프라인을 최적화 했다. 이러한 최적화는 입력 쿼리, 검색 메커니즘 및 생성 괒어 간의 상호작용을 개선해 응답의 정확성과 관련성을 보장한다.
2.1 Query and Retrieval Transformation(쿼리 및 검색 변환)
효과적인 검색을 위해서 쿼리가 정확하고 명확하고 상세해야 한다.
쿼리가 임베딩으로 변환되더라도 쿼리와 관련 문서 간의 의미적 차이는 존재할 수 있는데, 이전 연구들은 쿼리 변환을 통해 쿼리 정보를 향상시켜 검색 성능을 개선하는 방법을 탐구 했다. Query2Doc와 HyDE는 원래 쿼리에서 의사 문서(pseudo-documents)를 생성해 검색을 향상하고 TOC는 쿼리를 하위 쿼리로 분해해서 검색된 내용을 최종 결과로 집계한다.
2.2 Retriever Enhancement Strategy (검색기 향상 전략)
문서 청킹 및 임베딩 방법은 검색 성능에 크게 영향을 미친다.
일반적인 청킹 전략은 문서를 청크로 나누지만 최적의 청크 길이를 결정하는 것은 어려울 수 있다. 작은 청크는 문장을 단편화 시킬 수 있고, 큰 청크는 관련 없는 컨텍스트를 포함할 수 있다.
LlamaIndex는 Small2Big과 sliding window와 같은 청킹 방법을 최적화한다.
검색된 청크가 관련이 없을 수 있고, 숫자가 많아 질 수 있기 때문에 관련 없는 문서를 필터링 하기 위해 재랭킹이 필요하다. 재랭킹 과정에서 느린 추론 단계가 필요하지만 더 나은 성능을 제공한다.
TILDE는 쿼리 용어의 가능성을 미리 계산하고 저장해 그 합에 기반해 문서를 랭킹한다.
2.3 Retriever and Generator Fine-tuning (검색기와 생성기 미세 조정(
RAG 프레임워크 내에서 검색기와 생성기를 최적화하기 위한 미세 조정은 매우 중요하다.
일부 연구는 검색기 컨텍스트를 더 잘 활용하기 위해 생성기를 미세 조정하는데 중점을 두어 신뢰할 수 있고 견고한 생성된 콘텐츠를 보정한다.
다른 연구는 생성기에 유익한 구절을 검색하도록 검색기를 미세 조정한다. 전체적인 접근 방식은 RAG를 통합 시스템으로 간주해 검색기와 생성기를 함께 미세조정해서 전체 성능을 향상 시키는 것이다. 이 방법은 복잡성과 통합의 어려움을 증가시킨다.
여러 연구에서는 텍스트 생성[7, 8], LLM과의 통합[6, 39], 멀티모달[40] 및 AI 생성 콘텐츠[41]와 같은 측면을 다루는 현재 RAG 시스템을 광범위하게 논의했다. 이러한 연구는 기존 RAG 방법론에 대한 포괄적인 개요를 제공하지만 실제 구현에 적합한 알고리즘을 선택하는 것은 여전히 어려운 일이다.
이 연구에서는 RAG 방법을 적용하는 모범 사례에 중점을 두고 LLM에서 RAG에 대한 이해와 적용을 향상시킨다.
3. RAG Workflow
RAG 워크 플로우의 구성 요소의 각 모듈에 대해 일반적으로 사용되는 접근 방식을 검토하고 최종 파이프라인을 위한 기본 및 대체 방법 선택함
3.1 Query Classification
모든 쿼리가 정보 기반 생성(RAG)를 필요로 하는 것은 아니다. RAG는 정보의 정확성을 높이고 환각 현상을 줄일 수 있지만 빈번한 검색은 응답 시간을 증가 시킨다. 따라서 우리는 쿼리를 분류해서 검색이 필요한지 여부를 결정하는 것으로 시작한다. 검색이 필요한 쿼리는 RAG 모듈을 통해 진행되고, 그렇지 않은 쿼리는 LLM에 의해 직접 처리한다.
검색은 일반적으로 모델의 파라미터를 초과하는 지식이 필요로할 때 권장된다. 그러나 검색의 필요성은 작업에 따라 달라지는데, 2023년 까지 훈련된 LLM은 “Sora was developed by OpenAI” 라는 번역은 검색 없이 처리할 수 있지만, 동일한 주제에 대한 소개 요청은 관련 정보를 제공하기 위해서는 검색이 필요하다.
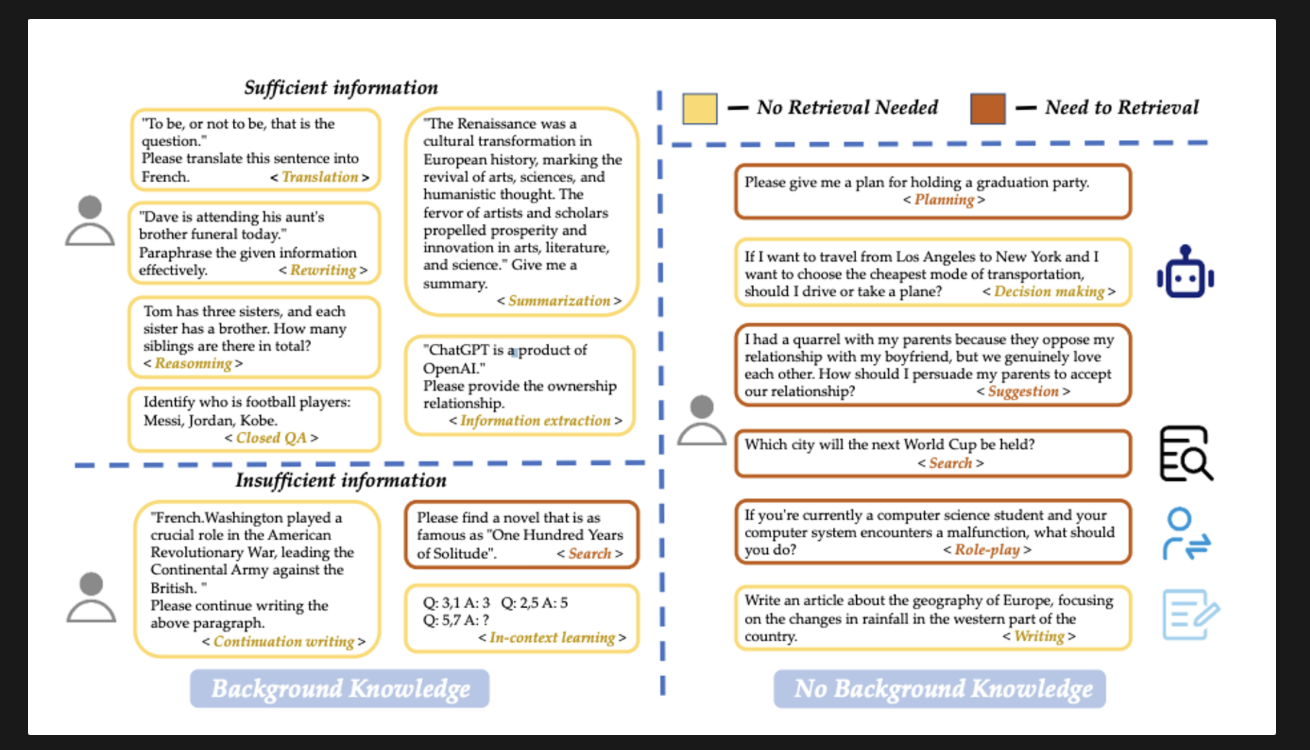
그래서 여기서는 쿼리가 검색을 필요로 하는지 여부를 결정하기 위해 작업 유형별로 분류할 것을 제안하고 있다. 주어진 정보에 충분한지 여부에 따라 작업을 15가지로 분류했다. (특정 작업과 예는 아래 그림 2를 참고)
사용자 제공 정보에 전적으로 기반한 작업은 ‘충분’으로 표시되어 검색이 필요하지 않고, 그렇지 않은 경우 ‘불충분(insufficient)로 표시되어 검색이 필요할 수 있다. 이 결정을 자동화하기 위해 분류기를 훈련한다.
실험 세부 사항은 부록 A.1 을 참고한다.
[그림 2]
Figure 2: Classification of retrieval requirements for different tasks. In cases where information is not provided, we differentiate tasks based on the functions of the model.
(그림 2: 다양한 작업에 대한 검색 요구 사항 분류기. 정보가 제공되지 않는 경우에는 모델의 기능에 따라 작업을 차별화함)
[Background knowledge]
<sufficient information>
case 1 : "사느냐 죽느냐, 그것이 문제로다." 이 문장을 프랑스어로 번역해주세요. < 번역 > : **검색 필요 없음**
case 2 : "데이브는 오늘 이모의 동생 장례식에 참석하고 있습니다." 주어진 정보를 효과적으로 바꿔 표현하세요. < 다시 쓰기 > : **검색 필요 없음**
case 3 : “톰에게는 세 명의 자매가 있고, 각 자매는 동생이 있다. 형제 자매의 총 수는? < 추론 > : **검색 필요 없음**
case 4: 다음 중 축구 선수가 누구인지 확인하세요: 메시, 조던, 고베.< 닫힌 QA > : **검색 필요 없음**
case 5: "르네상스는 예술, 과학, 인본주의적 사고의 부활을 의미하는 유럽 역사의 문화적 변혁이었습니다. 예술가와 학자들의 열정은 예술, 문학, 과학 분야의 번영과 혁신을 촉진했습니다." 요약을 해주세요. < 요약 > : **검색 필요 없음**
case 6: "ChatGPT는 OpenAI의 제품입니다." 소유 관계를 제공해주세요. < 정보 추출 > : **검색 필요 없음**
<insufficient information>
case 1 : "프랑스.워싱턴은 미국 독립 전쟁에서 영국에 맞서 대륙군을 이끄는 중요한 역할을 했습니다."
위 문단을 계속해서 작성해주세요. <계속 집필> : **검색 필요 없음**
case 2 : 『백년의 고독』만큼 유명한 소설을 찾아보세요. < 검색 > : **검색 필요함**
caes 3: Q: 3,1 A: 3 Q: 2,5 A: 5 질문: 5,7 답변: ? < 상황 내 학습 > : 검색 필요 없음
[No Background knowledge]
<dialog>
Q1. 졸업파티를 열 계획을 알려주세요. < 기획 > : **검색 필요**
Q2. 로스앤젤레스에서 뉴욕까지 이동하고 가장 저렴한 교통수단을 선택하려면 운전을 해야 할까요, 아니면 비행기를 타야 할까요? < 의사결정 > : **검색 필요**
Q3. 남자친구와의 연애를 반대하시는 부모님 때문에 갈등도 있었지만, 진심으로 사랑하고 있어요. 우리의 관계를 받아들이도록 부모님을 어떻게 설득해야 할까요? <제안> : **검색 필요**
Q4. 다음 월드컵은 어느 도시에서 개최되나요? < 검색 > : **검색 필요**
Q5. 현재 컴퓨터 과학을 전공하는 학생이고 컴퓨터 시스템에 오작동이 발생하면 어떻게 해야 합니까? < 역할극(role-play > : **검색 필요**
Q6. 유럽 서부 지역의 강수량 변화에 초점을 맞춰 유럽 지리에 관한 기사를 작성하세요. < 글쓰기 > : **검색 필요 없음**[참고]
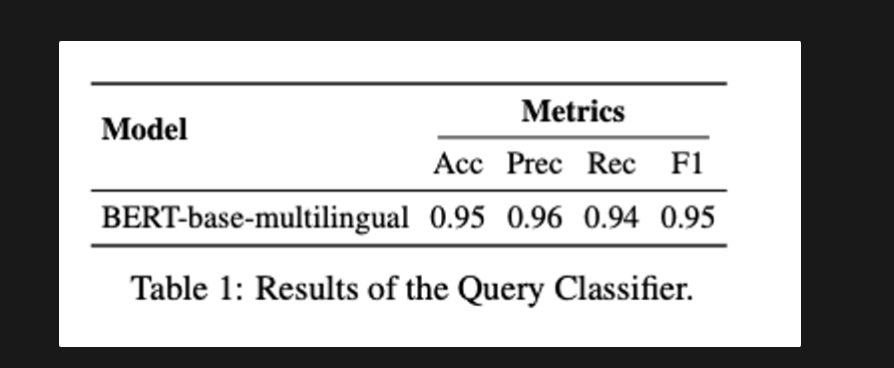
Query classification
- databricks-Dolly-15k 데이터 셋을 사용하고 gpt-4로 추가 데이터를 생성함 질문을 생성하기 위한 프롬프트 템플릿을 아래의 표 14
[Instruction] Please generate ten descriptions for the continuation task. [Context] For example: 1.“French.Washington played a crucial role in the American Revolutionary War, leading the Continental Army against the British.” Please continue writing the above paragraph. 2.“The discovery of the double helix structure of DNA by James Watson and Francis Crick revolutionized the field of genetics, laying the foundation for modern molecular biology and biotechnology.” Please continue by discussing recent developments in genetic research, such as CRISPR gene editing, and their potential ethical implications.
→ [지침] 연속된 작업에 대한 설명을 10개 생성하세요.
[컨텍스트] 예시
1.“프랑스.워싱턴은 미국 독립 전쟁에서 중요한 역할을 했습니다. 영국에 대항하는 대륙군.” 위 문단을 계속해서 작성해주세요.
2.“제임스 왓슨과 프랜시스의 DNA 이중 나선 구조 발견크릭은 유전학 분야에 혁명을 일으켜 현대 분자생물학의 토대를 마련했습니다. 생물학과 생명공학.” 계속해서 최근 개발 상황에 대해 논의해 주시기 바랍니다. 예를 들면 CRISPR 유전자 편집과 같은 유전 연구 및 잠재적인 윤리적 영향.
- BERT-base-multilingual-cased를 분류기로 선택, 배치크기 16, 학습률 1e-5
3.2 Chunking
문서를 더 작은 세그먼트로 나누는 것은 검색 정밀도를 높이고 대규모 언어 모델(LLM)의 길이 문제를 피하는데 중요함. 이 과정은 token-level, Semantic-level, Sentence-level (토큰, 의미, 문장 수준) 등 다양한 세분성 수준에서 적용됨
-
token-level (토큰 수준) : 간단하지만 문장ㅇ르 나눌 수 있어 검색 품질에 영향을 줌
-
Semantic-level (의미 수준) : LLM을 사용해 단락을 결정, 문맥을 보존하지만 시간이 많이 소요됨
-
Sentene-level (문장 수준) : 텍스트의 의미를 보존하면서 간단하고 효율적
해당 paper에서는 ‘sentence-level(문장 수준)’ 분할을 사용해 간편성과 의미 보존의 균형을 맞춤
3.2.1 Chunk size
-
분할 크기는 성능에 중요한 영향을 미침. 큰 chunk는 더 많은 문맥을 제공해 이해도를 높이지만 처리 시간이 길어짐. 작은 chunk는 검색 회수를 개선하고 시간을 단축하지만 충분한 문맥이 부족할 수 있음
- 최적의 분할 크기를 찾기 위해서는 신뢰성과 관련성과 같은 지표 간의 균형이 필요함
-
신뢰성 : 응답이 할루시네이션인지 검색된 텍스트와 일치하는지 측정
-
관련성 : 검색된 텍스트와 응답 쿼리와 일치하는지 여부 측정
→ (LlamaIndex 평가 모듈 사용)
: embedding에는 긴 입력 길이를 지원하는 text-embedding-ada-0022 모델 사용
평가모델과 생성모델로 zephyr-7b-alpha, gpt-3.5-turbo 선택함
여기서는 분할 하는 충접의 크기를 20 token으로, 각 문서의 첫 60page를 코퍼스로 사용하고 선택한 코퍼스에 따라서 약 170개의 쿼리를 생성하도록 LLM을 프롬프팅함.
-
3.2.2. Chunking Techniques
- small-to-big, sliding window는 분할 블록 관계를 조직해 검색 품질을 향상시킴 작은 크기의 블록을 사용해 쿼리와 일치시키고 작은 블록과 문맥 정보를 포함하는 큰 블록이 반환됨
3.2.3 Embedding Model Selection
- 올바른 임베딩 모델을 선택하는 것은 쿼리와 분할 블록의 효과적인 의미적인 일치를 위해 중요함 여기서는 FlagEmbedding 평가 모듈을 사용해 적절한 오픈 소스 임베딩 모델 선택함
3.2.4. Metadata Addition
- 타이틀, 키워드, 가설 질문과 같은 메타데이터를 추가해 검색을 개선하고, 검색된 텍스트를 후처리할 수 있는 방법을 제공해 LLM이 검색된 정보를 더 잘 이해할 수 있도록함
- 최적의 분할 크기를 찾기 위해서는 신뢰성과 관련성과 같은 지표 간의 균형이 필요함
-
3.3 Vector Databases
백터 데이터베이스는 임베딩 벡터와 메타데이터를 저장해서 다양한 인덱싱 및 근사 최근접 이웃(ANN) 방법을 통해 쿼리에 관련된 문서를 효율적으로 검색한다.
이 연구에서는 네 가지 기준에 따라 벡터데이터 베이스를 평가했는데, 여러 인덱스 유형과 억 단위 벡터 지원, 하이브리드 검색, 클라우드 네이티브 기능등의 측면에서 유연성, 확장성, 현대 클라우드 기반 인프라에서 배포 용이성에 대한 영향을 보았다.
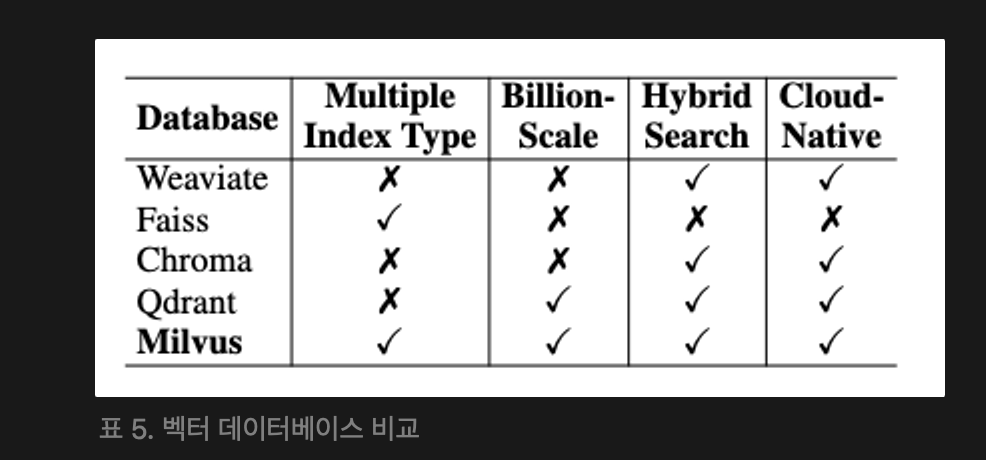
다섯 가지 오픈소스 벡터 데이터베이스(Weaviate, Faiss, Chroma, Quadrant, Milvus)를 비교한 결과 Milvus가 모든 필수 기준을 충족해 가장 포괄적인 솔루션으로 나타났다.
3.4 Retrieval Methods
사용자 쿼리에 대한 검색 모듈은 쿼리와 문서 간의 유사성에 따라 상위 k개의 관련 문서를 선택한다. 이 문서들은 생성 모델이 적절한 응답을 생성하는데 사용한다. 하지만 원본 쿼리는 표현이 부족하거나 의미 정보가 부족하여 성능이 저하될 수 있다. 이를 해결하기 위해 세 가지 쿼리 변환 방법을 평가했다.
[1] Query Rewriting(쿼리 재작성) : 쿼리를 더 잘 맞게 수정하여 문서 검색 성능을 향상시킴
[2] Query Decomposition (쿼리 분해) : 원본 쿼리에서 파생된 하위 질문으로 문서를 검색
[3] Pseudo-documents Generation (가상 문서 생성) : 사용자 쿼리를 기반으로 가상 문서를 생성하고 이 문서의 임베딩을 사용해 유사한 문서를 검색함
최근 연구에서는 어휘 기반 검색(lexical-based)과 벡터 검색을 결합하면 성능이 크게 향상되는 것으로 나타났다. 본 연구에서는 희소 검색에 BM25를 사용하고 밀도 검색에 비지도 인코더인 Contriever를 사용해 Thaku를 기반으로 한 두 가지 강력한 기준선 역할을 지정했다.
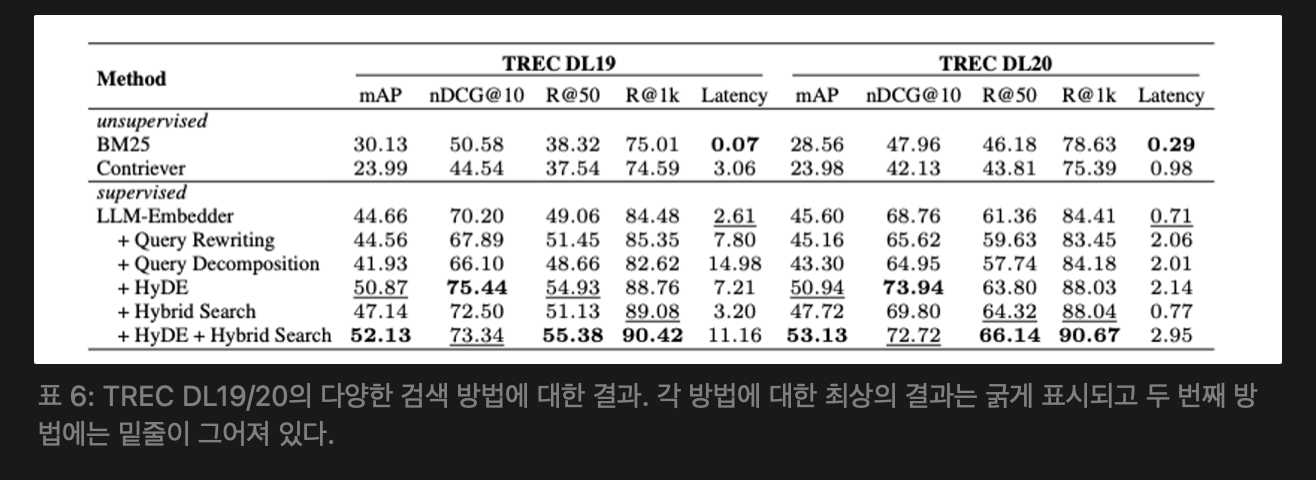
3.4.1 Results for different retrieval methods (다양한 검색 방법의 결과)
TREC DL 2019 및 2020년 passage 랭킹 데이터셋에서 다양한 검색 방법의 성능을 평가했다.
아래의 표 6에 나타난 결과에 따르면 지도 학습 기반 방법이 비지도 학습 방법보다 훨씬 우수한 성능을 보였다. 하이브리드 검색과 HyDE를 검색한 LLM-Embedder가 가장 높은 점수를 기록했는데, 쿼리 재작성 및 분해는 성능을 크게 향상 시키지 않았다. 효율성을 고려해 하이브리드 검색과 HyDE 조합이 기본 검색 방법으로 추천한다. 효율성을 고려할 때 하이브리드 검색은 희소 검색(BM25)와 밀도 검색(원본 임베딩)을 결합해서 상대적으로 낮은 지연시간으로 주목할 만한 성능을 달성한다.
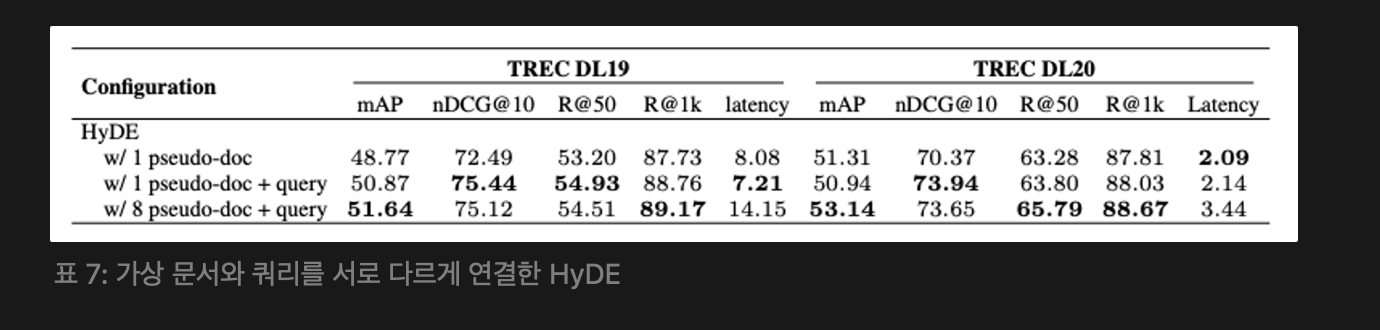
3.4.2 HyDE with Different Concatenation of Documents and Query (HyDE와 가상 문서 및 쿼리의 다양한 결합)
가상 문서와 쿼리의 다양한 결합 전략이 검색 성능에 미치는 영향을 평가했다.여러 가상 문서와 원본 쿼리를 결합하면 검색 성능이 크게 향상되지만, 지연 시간도 증가한다. 따라서 하나의 가상 문서를 사용하는 것이 충분하다.
3.4.3 Hybrid search with Different Weight on Sparse Retrieval (하이브리드 검색에서 희소 검색에 대한 가중치 조정)
하이브리드 검색에서 희소 검색과 밀집 검색 간의 가중치를 조절하는 α 값을 평가한다.
Ss, Sd는 각각 희소 검색과 밀집 검색에서의 정규화된 관련성 점수이고, Sh는 전체 검색 점수이다.
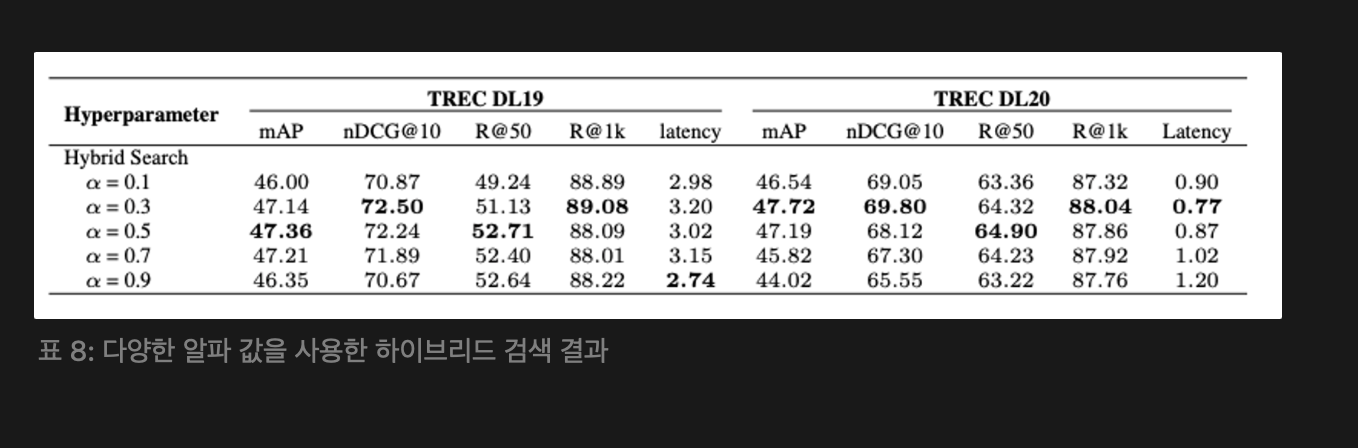
성능에 미치는 영향을 파악하기 위해 다섯 가지 α 값을 평가했고, α = 0.3이 가장 우수한 성능을 나타냈고, 하이브리드 검색의 효과를 극대화할 수 있다. α의 적절한 조정은 검색 효과성을 어느 정도 향상시킬 수 있음을 보여준다. 추가 구현 세부 사항은 아래의 부록 A.2 참고
[A.2 Experimental Details of Retrieval Methods]
-
dataset : TREC DL 2019, 2020 passage ranking datasets
-
평가 지표 : 검색 평가에 널리 사용되는 지표로 mAP, nDCG@10, R@50, R@1k
mAP와 nDCG@10는 결과 순서를 고려하는 반면 R@k는 순서를 고려하지 않음.
각 방법이 쿼리당 발생시키는 평균 지연 시간도 파악함
-
구현 세부 사항 :
- 희소 검색 : tf-idf 알고리즘으로 BM25 알고리즘 사용
- 밀집 검색 : 비지도 대비 텍스트 인코더로 Contriever 사용. 지도 학습 밀집 검색은 LLM-Embedder를 사용 BM25와 Contriever 기본 구현은 Pyserini에서 제공함. BM25 인덱스는 Lucene을 사용해 MS MARCO 컬렉션에서 구축, 밀집 벡터 인덱스는 Faiss의 Flat 구성에서 같은 데이터셋에서 생성
- 쿼리 재작성 : Zephyr-7b-alpha 모델을 사용해 원래 쿼리 재작성
- 쿼리 분해 : GPT-3.5-turbo-0125 를 사용해 원래 쿼리를 여러 하위 쿼리로 나눔
- 가상의 답변 생성 : HyDE의 구현을 따르고, 더 발전된 지시 기반 언어 모델인 GPT-3.5-turbo-instruct를 사용해 가상의 답변 생성. 이 모델은 temperature 0.7에서 최대 512 token까지 샘플링함
- 검색 실험과 평가는 Pyserini 도구 키트를 이용해 수행
-
3.5 Reranking Methods
초기 검색 후에는 검색된 문서의 관련성을 높이기 위해 순위 재지정 단계를 사용하여 가장 관련성이 높은 정보가 목록 상단에 표시되도록 한다. 이 단계에서는 보다 정확하고 시간 집약적인 방법을 사용하여 문서를 효과적으로 재정렬하여 쿼리와 최상위 문서 간의 유사성을 높인다.
순위 재지정 모듈에서는 분류를 활용하는 DLM 재순위 지정과 쿼리 가능성에 초점을 맞춘 TILDE 재지정이라는 두 가지 접근 방식을 고려한다. 이러한 접근 방식은 각각 성능과 효율성을 우선시 한다.
[1] DLM Reranking
-
Reranking을 위해 위해 딥러닝(DLM)모델을 활용한다. 이러한 모델은 쿼리에 대한 문서 관련성을 "참" 또는 "거짓"으로 분류하도록 미세 조정됐다. 미세 조정 중에 모델은 관련성에 따라 라벨이 지정된 연결된 쿼리와 문서 입력으로 학습된다. 추론 시 문서는 "진짜" 토큰의 확률에 따라 순위가 지정된다.
[2] TILDE Reranking
-
모델의 어휘 전반에 걸쳐 토큰 확률을 예측하여 각 쿼리 용어의 가능성을 독립적으로 계산합니다. 쿼리 토큰의 미리 계산된 로그 확률을 합산하여 문서의 점수를 매기므로 추론 시 신속한 순위 재지정이 가능함
문서에 존재하는 토큰만 인덱싱하고, NCE 손실을 사용하고, 문서를 확장하여 효율성을 높이고 인덱스 크기를 줄이는 방식으로 이를 개선한다. 우리의 실험은 기계 독해를 위한 대규모 데이터 세트인 MS MARCO Passage 순위 데이터 세트를 사용했다. monoT5, monoBERT, RankLLaMA 및 TILDEv2 모델을 사용하여 PyGaggle 및 TILDE 에서 제공하는 구현을 따르고 수정합니다. 재순위(Reranking) 결과는 아래 표 9를 참고
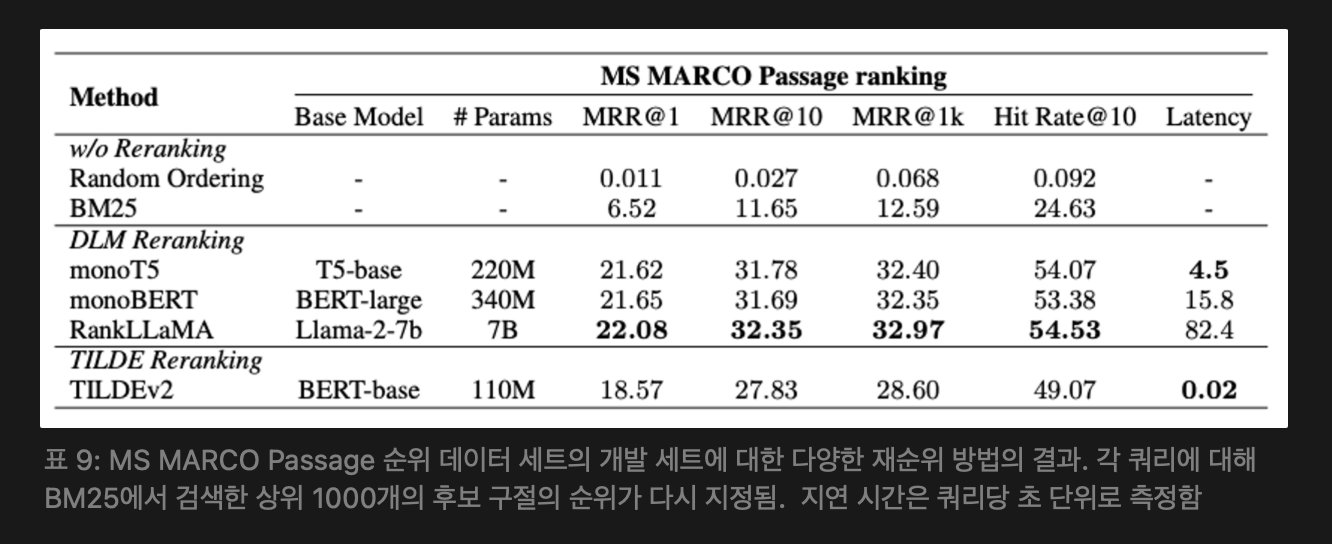
성능과 효율성의 균형을 맞추는 포괄적인 방법으로 monoT5를 권장한다. RankLLaMA는 최고의 성능을 달성하는 데 적합한 반면, TILDEv2는 고정 컬렉션에 대한 가장 빠른 경험에 이상적이다. 실험 설정 및 결과에 대한 자세한 내용은 아래 [ 부록 A.3] 참고
-
[부록 A.3 Experimental Details of Reranking Methods]
- 데이터셋: 실험에서는 기계 독해 작업을 위해 설계된 대규모 MS MARCO Passage ranking 데이터셋을 사용한다. 이 데이터셋은 880만 개 이상의 문서와 100만 개의 쿼리로 구성되어 있다. 훈련 세트는 쿼리와 해당 쿼리에 대응하는 긍정적 및 부정적 문서 쌍이 약 3억 9천 8백만 개로 이루어져 있으며, 개발 세트는 6,980개의 쿼리와 이들 쿼리의 BM25 검색 결과로 구성되며, 각 쿼리의 상위 1000개의 후보 문서를 유지한다. 테스트 세트는 공개되지 않았기 때문에, 우리는 개발 세트에서 방법의 효과를 평가한다.
- 평가 지표: 평가 지표로는 MRR@1, MRR@10, MRR@1k, Hit Rate@10을 사용한다. MRR@10은 MS MARCO에서 제안한 공식 지표이다.
- 구현 세부 사항: PyGaggle 및 TILDE 에서 제공한 구현을 따르며, 이를 수정합니다. DLM 기반 Reranking에는 T5-base 기반의 monoT5 , BERT-large 기반의 monoBERT, 그리고 Llama-2-7b 기반의 RankLLaMA를 사용한다. TILDE Reranking에는 BERT-base 기반의 TILDEv2 를 사용한다. 일반적으로 50개의 문서가 Reranking 모듈에 입력으로 제공됩니다. 재정렬 및 재패킹 단계 후 남은 문서는 top-k 값 또는 관련성 점수 임계값을 설정하여 추가로 집중화할 수 있다.
- 결과 분석: reranking 결과는 위 표 9에 제시되어 있다. 결과를 무작위로 섞인 순서 및 BM25 검색 기준선과 비교한다. 모든 reranking방법은 모든 지표에서 성능이 현저히 향상되었다. monoT5와 monoBERT는 거의 동일한 성능을 보이며, RankLLaMA가 가장 좋은 성능을 보인다. TILDEv2는 가장 빠르며, 쿼리당 약 10~20밀리초가 소요되지만 성능 측면에서 비용이 발생한다. 또한 TILDEv2는 reranking된 문서가 이전에 색인화된 컬렉션에 정확히 포함되어 있어야 한다.. 새로운 문서에 대해서는 추론 시에 전처리를 다시 해야 하며, 이로 인해 효율성 장점이 사라진다.
3.6 Document Repacking
문서가 제공되는 순서가 LLM 응답 생성의 성능에 영향을 미칠 수 있는데, 이를 해결하기 위해 Reranking 이후 워크플로우에 Repacking 모듈을 통합한다. 이 모듈에는 “forward”, “reverse”. “sides” 의 세 가지 재패킹 방법이 포함된다.
forward 방법은 재정렬 단계에서 하위 관련성 점수에 따라 문서를 재패킹하고 reverse는 문서를 상위 관련성 점수에 따라 배열한다. Liu et al. 연구에서 관련 정보가 입력의 앞부분이나 뒷부분에 배치될 때 최적의 성능이 달성된다는 결론을 바탕으로 “sides” 옵션을 추가했다.
재패킹 방법은 주로 이후 모듈에 영향을 미치므로 다른 모듈과 조합하여 최상의 repacking 방법을 선택했고 여기서는 “sides” 방법을 기본 재패킹 방법으로 선택했다.
3.7 Summarization
검색 결과는 중복되거나 불필요한 정보를 포함할 수 있고, 이는 LLM이 정확한 응답을 생성하는데 방해가 될 수 있다. 긴 프롬프트는 추론 과정을 느리게 할 수 있는데, 따라서 검색된 문서를 요약하는 효율적인 방법이 RAG 파이프라인에서 중요하다.
요약 작업은 추출(extractive) 일 수 있고 생성(abstractive) 일 수도 있다. 추출적 방법은 텍스트를 문장으로 나눈 후 중요도에 따라 점수를 매기고 순위를 매긴다. 생성적 압축은 여러 문서에서 정보를 종합해서 재구성하고 요약한다. 이러한 작업은 query-based(쿼리 기반)과 non-query-based(비쿼리 기반) 일 수 있다. 본 연구에서는 RAG가 쿼리와 관련된 정보를 검색하므로, 쿼리 기반 방법에만 초점을 맞췄다.
[1] Recomp : 추출적 및 생성적 압축기가 있음. 추출적 압축기는 유용한 문장을 선택하고, 생성적 압축기는 여러 문서에서 정보를 종합함
[2] LongLLMLingua : LLMLingua를 개선하여 쿼리와 관련된 주요 정보에 초점을 맞춤
[3] Selective Context : 입력 컨텍스트에서 중복된 정보를 식별하고 제거하여 LLM 효율성을 높임. 이 방법은 기본 인과 언어 모델이 계산한 자기 정보를 사용해 어휘 단어의 정보성을 평가함. 비쿼리 기반 방법으로 쿼리 기반 방법과 비쿼리 기반 방법 간의 비교를 가능하게 함
이러한 방법은 NQ, TriviaQA, hotpotQA라는 세 가지 벤치마크 데이터셋에서 평가되었다. 다양한 요약 방법의 비교 결과는 아래 [표 10]을 참고.
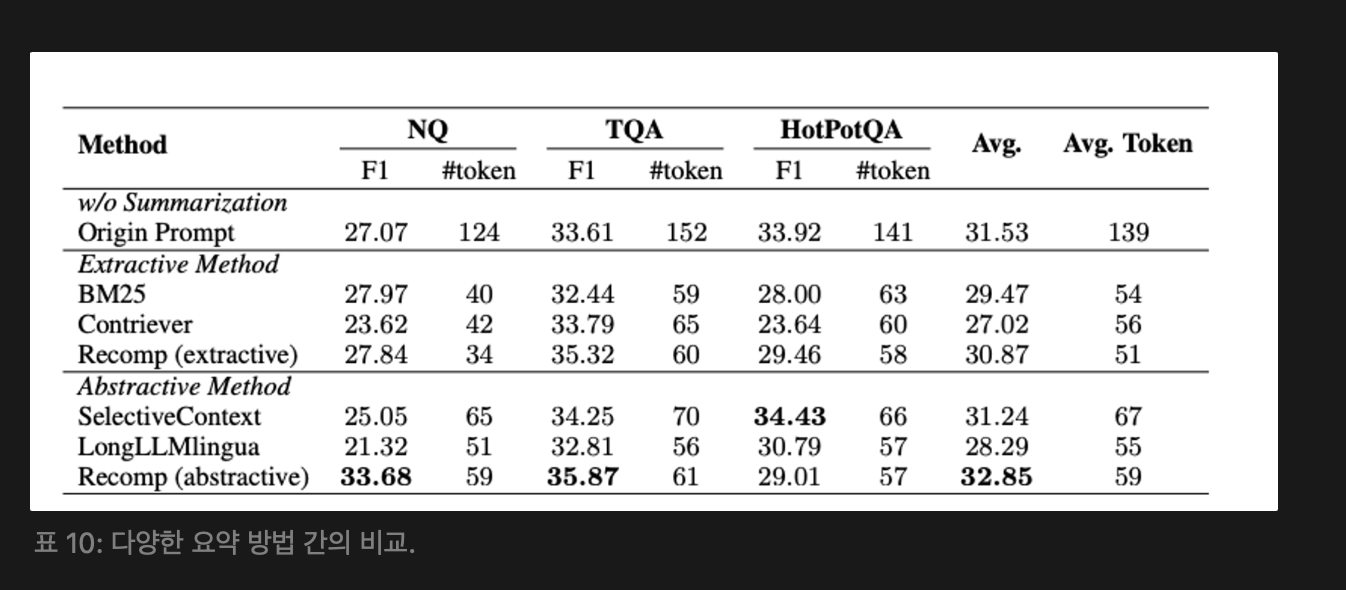
여기서는 Recomp를 추천하는데, LongLLMLingua는 성능이 좋지 않지만 실험 데이터셋에서 훈련되지 않았기 때문에 더 나은 일반화 능력을 보여준다. LOngLLMLingua는 대안 방법으로 고려된다.
쿼리 기반이 아닌 방법에 대한 추가 구현 세부 사항 및 논의는 아래 [부록 A.4]참고
[부록 A.4 Experimental Details of Summarization Methods] : 요약 방법의 실험 세부사항
- Selective Context : 입력 컨텍스트에서 중복 정보를 식별하고 제거하여 LLM의 효율성을 향상 시킴. 기본 인과 언어 모델이 계산한 자기 정보를 사용해 어휘 단어의 정보성으 평가함. 이 방법은 비쿼리 기반으로, 쿼리 기반과 비쿼리 기반 접근 방식의 비교를 가능하게 함
- Datasets : Natural Questions(NQ), TriviaQA, HotpotQA 3가지 데이터셋에서 평가
- Metrics : 평가 메트릭에는 f1 score, 요약 후 변경된 토큰 수를 포함함. 간결성을 측정
- Implementation Details : 모든 방법에서 Llama3-8B-Instruct를 생성 모델로 사용하고 요약 비율을 0.4로 설정. 추출적 방법의 경우 중요도 점수가 유지할 문장을 결정함. 생성적 방법의 경우 요약 비율을 사용해 최대 생성 길이를 조절하고 추출적 방법고 일치시킴. 실험은 NQ test set, TriviaQa test set, HotpotQA dev set에서 수행
여기서는 생성기 미세 조정에 중점을 두고 relevant 와 irrelevant 컨텍스트가 생성기의 성능에 미치는 영향을 확인했다.
x를 RAG 시스템에 입력한 쿼리로 를 이 입력에 대한 컨텍스트로 나타낸다.
생성기의 메소 조정 손실은 정답 출력의 y의 음의 로그 우도이다.
미세 조정의 영향을 확인하기 위해 relevant 와 irrelevant 컨텍스트에 대해 를 쿼리와 관련된 컨텍스트로 drandom을 무작위로 검색한 컨텍스트로 정의한다.
의 구성을 변경해 모델을 훈련한다.
- : 증강된 컨텍스트는 쿼리와 관련된 문서로 구성되며, 로 표기합니다.
- : 컨텍스트는 하나의 무작위 샘플 문서를 포함하며, 로 표기합니다.
- : 증강된 컨텍스트는 관련 문서와 무작위로 선택된 문서로 구성되며, 로 표기합니다.
- : 증강된 컨텍스트는 쿼리와 관련된 문서의 두 복사본으로 구성되며, 로 표기합니다.
여기서는 미세 조정되지 않은 기본 LM 생성기를 로, 해당 에서 미세 조정된 모델 로 나타낸다. 여러 QA 및 독해 데이터셋에서 모델을 미세 조정했다.
QA 작업의 답변이 상대적으로 짧기 때문에, 정답 범위를 평가 메트릭으로 사용했고, 기본 모델로 Llama-2-7B [50]을 선택하였으며, 훈련과 유사하게 모든 훈련된 모델을 에서 검증 세트로 평가했다. 여기서 은 검색 없이 추론을 나타낸다. 그림 3은 주요 결과를 나타낸다.
관련 문서와 무작위 문서의 혼합으로 훈련된 모델 ()이 골드 문서 또는 혼합된 컨텍스트로 제공될 때 가장 우수한 성능을 보였다. 이는 훈련 중에 관련 및 무작위 컨텍스트를 혼합하면 비관련 정보에 대한 생성기의 강건성을 향상시키면서 관련 컨텍스트를 효과적으로 활용할 수 있음을 시사한다.
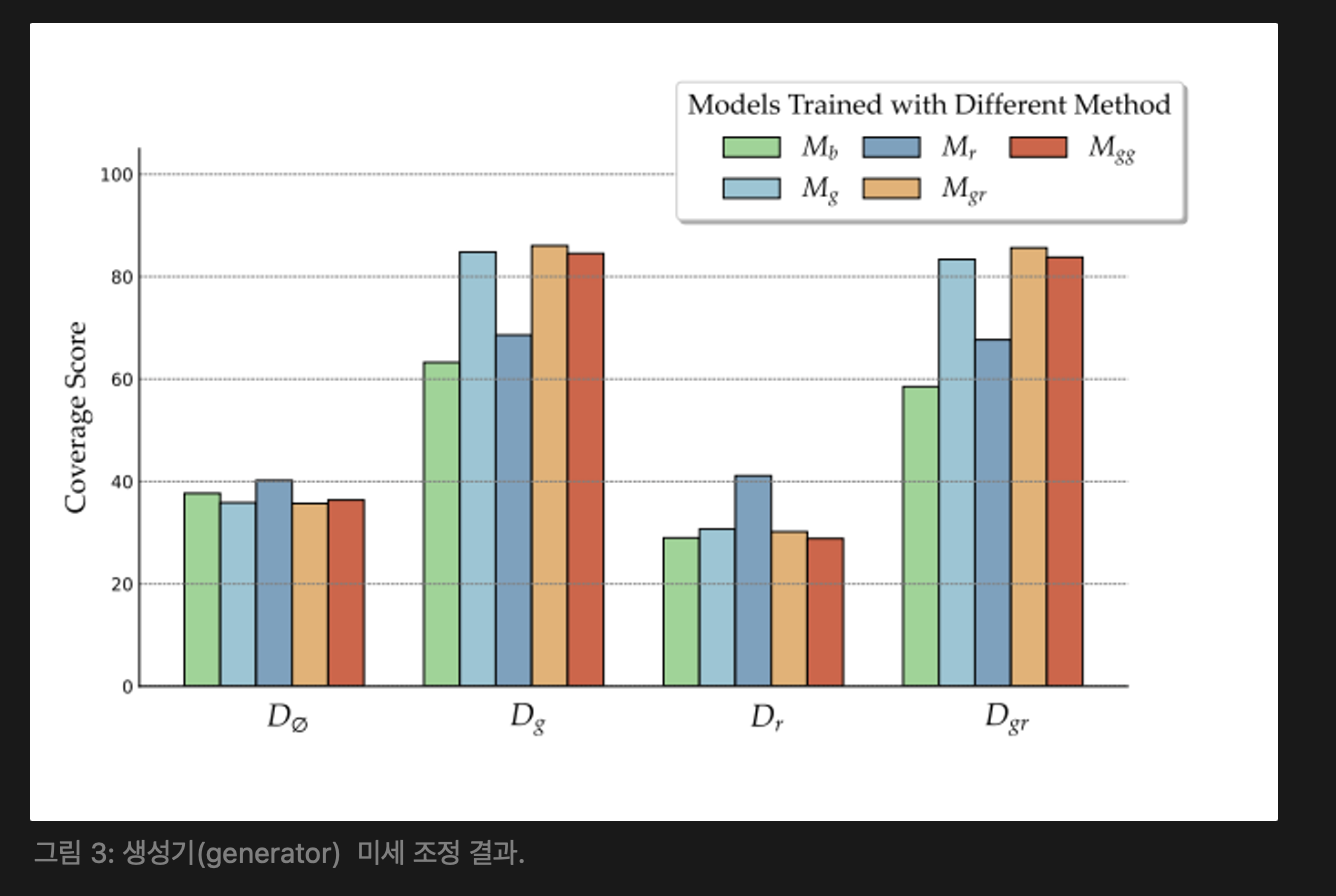
따라서 훈련 중에 몇 가지 관련 문서와 무작위로 선택된 문서로 증강하는 방법이 가장 좋은 접근법으로 확인됐다. 자세한 데이터셋 정보, 하이퍼파라미터 및 실험 결과는 [아래 부록 A.5 참고]
[부록 A.5 Experimental Details of Generator Fine-tuning]
Datasets : ASQA [60], HotpotQA [59], NarrativeQA [61], NQ [57], SQuAD [62], TriviaQA [58], TruthfulQA [63]를 포함한 여러 질문 응답(QA) 및 독해 데이터셋에서 모델을 미세 조정했다. 데이터가 다른 데이터셋보다 상당히 많은 경우에는 무작위 샘플링을 수행했다. 평가를 위해 ASQA [60], HotpotQA [59], NQ [57], TriviaQA [58]를 사용하였으며, 이들의 검증 분할 또는 훈련 세트에서 수동으로 나눈 서브셋을 이용하여 모델을 평가했다.
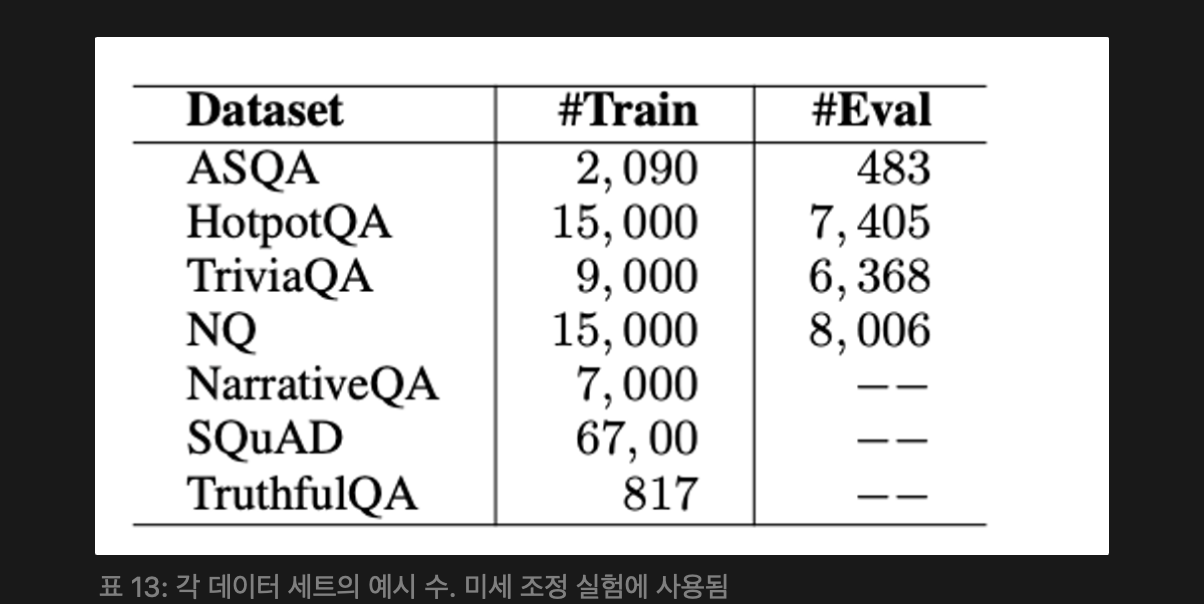
각 데이터셋의 훈련 및 평가 예제 수는[위 표 13] 를 참고. 각 데이터 항목에 대해 데이터셋에서 제공된 문서를 로 사용합니다. 을 얻기 위해서는 같은 데이터셋 내에서 서로 다른 항목의 컨텍스트를 샘플링하여 과 의 분포가 대체로 비슷하게 한다.
Metrics : QA 작업의 답변이 상대적으로 짧기 때문에 정답 범위를 평가 메트릭으로 사용합니다. 모델의 생성 길이를 제한하기 어려운 경우가 있을 수 있다.
Implementation Details : 기본 모델로 Llama-2-7b [50]을 선택했다. 효율성을 위해 훈련 중에 LoRA와 int8 양자화를 사용하했다. 미세 조정 및 평가에 사용된 프롬프트 템플릿은 주로 Lin et al. 을 따르고 생성기는 3 에포크 동안 훈련하며, 시퀀스의 최대 길이를 1600으로 제한하고 배치 크기는 4, 학습률은 5e-5로 설정했다. 테스트 동안에는 제로샷 설정을 사용한다.
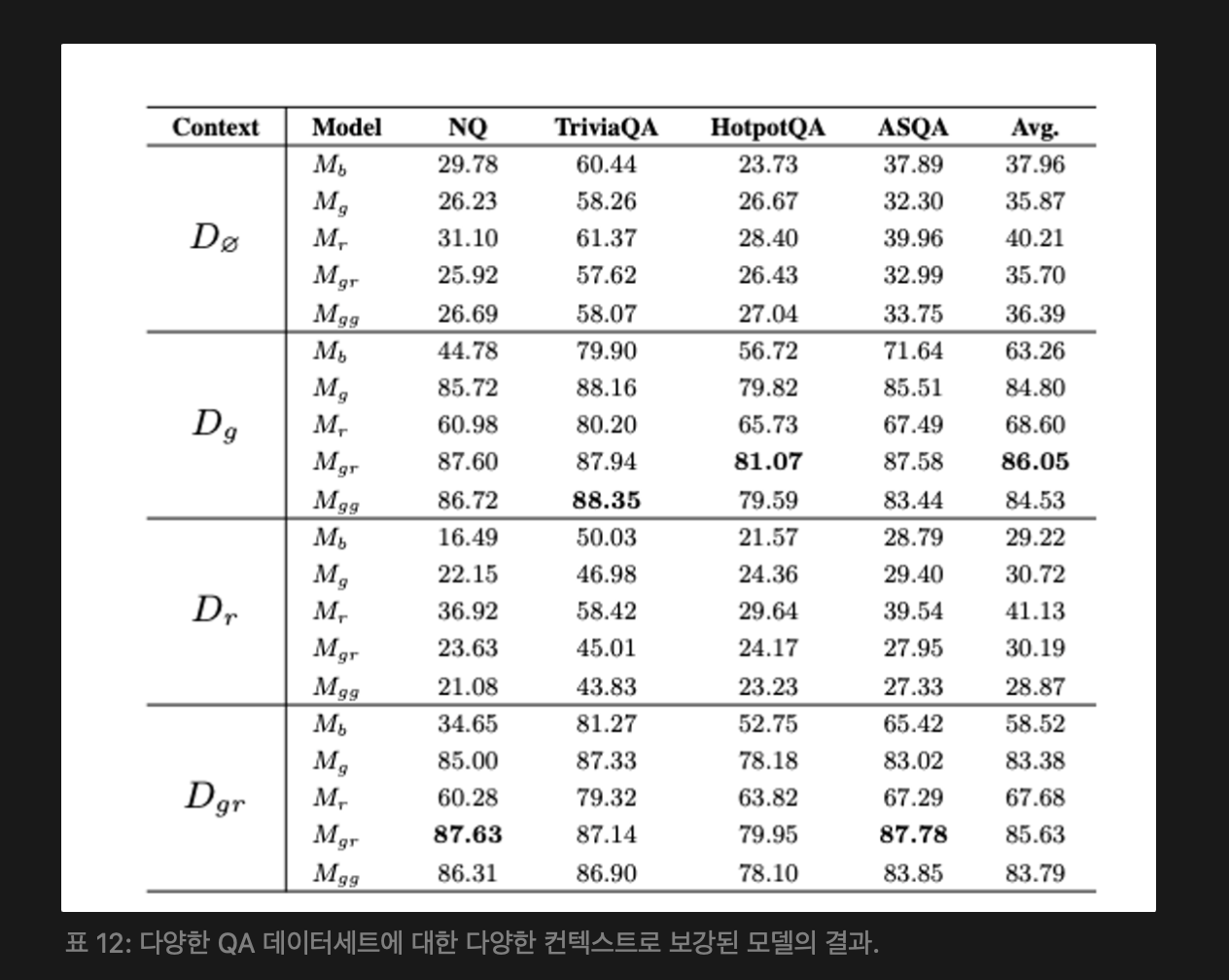
Detailed Results : 아래 [ 표 12] 는 각 데이터셋에 대한 평가 결과를 보여준다.
4. Searching for Best RAG Practices
그림 1의 RAG의 워크플로우를 따르면서, 개별 모듈을 순차적으로 최적화하고 대안 중에서 가장 효과적인 옵션을 선택한다. 이러한 반복적인 과정을 거치면서 최종 모듈을 구현하기 위한 최적의 방법을 결정한다. 각 쿼리에 몇 개의 무작위 선택된 관련 문서가 추가된 Llama2-7B-Chat 모델을 사용하고 이 모델을 생성기로 사용했다. 1천만개의 영어 위키피디아 텍스트와 4백만 개의 의학 데이터 텍스트를 포함하는 벡터 데이터베이스를 구축하기 위해 Milvusf를 사용했다. 또한 쿼리 분류, 재랭킹, 요약 모듈을 제거했을 때의 결과를 통해 각 모듈의 기여도를 평가했다.
4.1 Comprehensive Evaluation
다양한 NLP 작업과 데이터셋을 대상으로 RAG 시스템의 성능을 평가하기 위한 광범위한 실험을 수행했는데, 특히 (1) 상식 추론, (2) 사실 확인, (3) 오픈 도메인 QA, (4) multi Hop QA, (5) 의학 QA 이다.
작업 및 해당 데이터셋에 대한 자세한 내용은 아래의 부록 A.6 참고
[부록 A.6 Experimental Details of Comprehensive Evaluation] : 종합 평가의 실험 세부사항
작업 및 데이터셋 : RAG 시스템의 성능을 평가하기 위해 다양한 NLP 작업과 데이터셋에서 광범위한 실험을 수행했다.
- 상식 추론 (Commonsense Reasoning): MMLU, ARC-Challenge, OpenbookQA 데이터셋에서 평가
- 팩트 확인 (Fact Checking): FEVER 및 PubHealth 데이터셋을 포함
- 오픈 도메인 QA (Open-Domain QA): NQ, TriviaQA, WebQuestions데이터셋에서 평가
- 멀티홉 QA (MultiHop QA): HotPotQA, 2WikiMultiHopQA, MuSiQue 데이터셋에서 평가 MuSiQue의 경우 제시한 접근 방식을 따르며 답변 가능한 2-hop 질문에만 초점을 맞췄다.
- 의료 QA (Medical QA): PubMedQA 데이터셋에서 평가함. 각 데이터셋에서 우리는 실험을 위해 테스트 세트에서 무작위로 500개의 항목을 추출함. 테스트 세트가 없는 데이터셋의 경우, 대신 개발 세트를 사용함
RAG의 능력을 평가하기 위해, NQ, TriviaQA, HotPotQA, 2WikiMultiHopQA 및 MuSiQue에서 총 500개의 항목을 균등하게 수집하나. 각 항목은 “질문, 정답 문서, 정답”의 삼중항입니다.
메트릭: 오픈 도메인 QA 및 멀티홉 QA 작업에는 토큰 수준의 F1 점수와 EM 점수를 사용하며, 다른 작업에는 정확도를 사용한다. EM 점수는 모델 생성이 정답을 포함하고 있는지 여부를 기반으로 성능을 평가하는 보다 관대한 방법을 사용하며, 엄격하게 정확한 일치를 요구하지 않는다.
RAG 능력 평가를 위해, 우리는 RAGAs에서 네 가지 메트릭을 채택했다
(1) : 충실성 (Faithfulness), (2) 컨텍스트 적합성 (Context Relevancy), (3) 답변 적합성 (Answer Relevancy), (4) 답변 정확성 (Answer Correctness).
- 충실성 (Faithfulness): 생성된 답변이 검색된 컨텍스트와 얼마나 사실적으로 일치하는지를 측정함. 모든 주장이 제공된 컨텍스트에서 직접 유추될 수 있다면, 답변은 충실하다고 간주함
- 컨텍스트 적합성 (Context Relevancy): 검색된 컨텍스트가 원래 쿼리에 얼마나 적합한지를 평가함. 컨텍스트 적합성은 주어진 질문에 답하는 데 적합한 검색된 컨텍스트 내 문장의 비율로 계산됨 여기서 ∣S∣는 적합한 문장의 수를, ∣Total∣는 검색된 총 문장의 수를 나타냄.
- 답변 적합성 (Answer Relevancy): 생성된 답변이 원래 쿼리에 얼마나 적합한지를 평가
- 답변 정확성 (Answer Correctness): 생성된 답변의 정확성을 정답과 비교하여 평가
모든 메트릭은 RAGAs 프레임워크를 사용하여 평가하며, GPT-4가 판정 역할을 함
추가적으로, 검색된 문서와 정답 문서 간의 코사인 유사성을 검색 유사성 (Retrieval Similarity)으로 계산함. 검색된 문서와 정답 문서를 임베딩 모델에 입력한 후, 결과 임베딩을 사용하여 코사인 유사성을 계산함
구현 세부 사항 : 오픈 도메인 QA 및 멀티홉 QA 데이터셋의 경우, 생성 모델의 최대 새로운 토큰 수를 100으로 설정함. 다른 데이터셋의 경우 50으로 설정함 지나치게 긴 검색된 문서에 대해서는 RankLLaMA 및 LongLLMLingua를 평가할 때 문서를 2048 단어로 잘라냄
모든 데이터셋에 대해 생성 동안 greedy 디코딩을 사용한다. 다양한 RAG 모듈의 능력을 보다 잘 비교하기 위해 제로샷 평가 설정을 채택한다. 즉, 문맥 내 예제는 제공되지 않는다. 선택형 및 팩트 확인 작업에서는 모델이 생성한 답변이 다양한 형태를 취할 수 있다. (예: “정답은 A” 대신 “A”). 따라서 모델이 생성한 응답을 전처리하여 정답 레이블과 정규 표현식 템플릿을 적용하여 일치시킨다.
RAG의 기능을 평가하기 위해 Faithfulness, Context Relevancy, Answer Relevancy, Answer Correctness 등의 지표를 사용하고, 검색된 문서와 정답 문서의 코사인 유사도를 계산해 검색 유사성도 측정했다.
상식 추론, 사실 확인, 의료 QA 작업에는 정확도를 평가 지표로 사용하고, 오픈 도메인 QA, multiHop QA는 토큰 단위 f1 score와 정확한 일치(EM) 점수를 사용했다. 최종 RAG 점수는 앞서 언급된 다섯 가지 RAG 기능의 평균으로 계산했다. 각 데이터셋에서 최대 500개의 예제를 서브 샘플링했다.
4.2 Results and Analysis
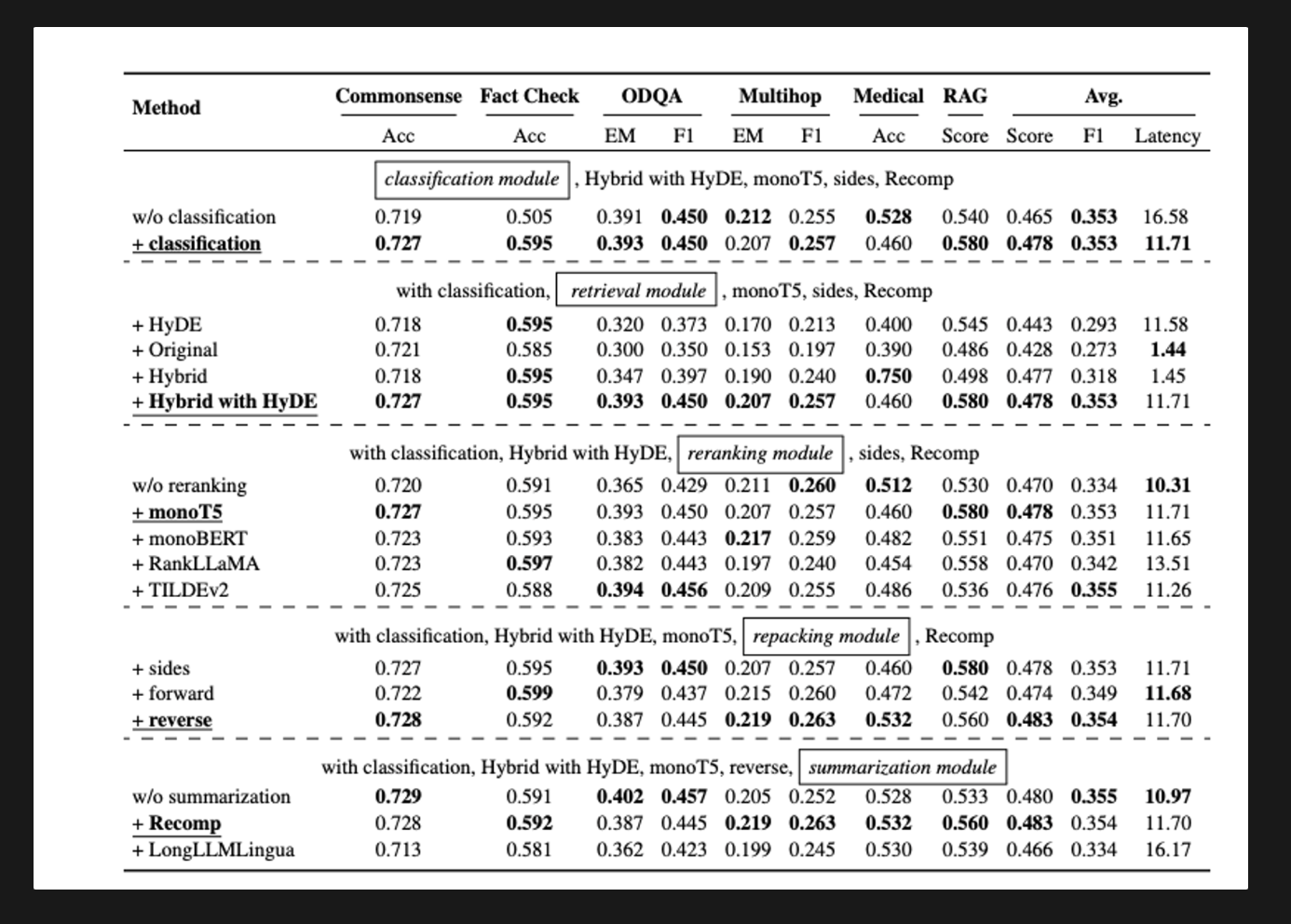
- query classification module : 효과성과 효율성 모두에 기여해 전체 점수를 평균 0.428에서 0.443으로 개선하고, 쿼리 지연 시간을 16.41초에서 11.58로 줄임
- Retrieval Module : ‘hybrid with HyDE’ 방법이 가장 높은 RAG 점수인 0.58 달성, 11.71 초의 상당한 계산 비용이 소요됨. ‘hybrid’ 또는 ‘original’ 방법을 추천하며, 이 방법들은 성능을 유지하면서 지연 시간을 줄임
- Reranking Module : 재랭킹 모듈이 없는 경우 성능이 크게 저하되고, 재랭킹의 필요성을 강조함.MonoT5가 가장 높은 평균 점수를 달성해 검색된 문서의 관련성을 증대시키는데 효과적임을 확인함. 재랭킹이 생성된 응답의 질을 향상시키는데 중요한 역할을 한다는 것을 나타냄
- Refacking Module : Reverse 구성은 우수한 성능을 보여 RAG 점수 0.560을 달성함. 쿼리에 더 관련성 높은 컨텍스트를 가까이 배치하는 것이 최적의 결과를 가져옴
- Summarization Module : Recomp 가 가장 우수한 성능을 보여주었으나, 요약 모듈을 제거함으로써 비슷한 결과를 낮은 지연 시간으로 얻을 수 있음. 그럼에도 불구하고 Recomp는 생성기의 최대 길이 제약을 해결할 수 있는 능력 덕분에 선호되는 선택임. 시간이 민감한 애플리케이션에서는 요약을 제거함으로써 응답 시간을 효과적으로 줄일 수 있음
각 모듈은 RAG 시스템의 전체 성능에 각자 기여하고, 쿼리 분류 모듈은 정확도를 향상시키고 지연 시간을 줄이며, 검색 및 재랭킹 모듈은 다양한 쿼리를 처리하는 시스템의 능력을 크게 향상 시킴. 재포장 및 요약 모듈은 시스템의 출력을 더욱 정제해서 다양한 작업에서 고품질 응답을 보장함
5. Discussion
5.1 Best Practices for Implementing RAG
실험 결과에 따르면, RAG 시스템을 구현하기 위한 두 가지 구체적인 방법 또는 관행을 제안한다. 각 방법은 특정 요구 사항을 해결하기 위해 맞춤화되어 있다
하나는 성능을 극대화하는 데 중점을 두고, 다른 하나는 효율성과 효과성 사이의 균형을 맞추는 것이다.
- 최고 성능 관행(Best Performance Practice): 최고의 성능을 달성하기 위해서는 쿼리 분류 모듈을 포함하고, 검색에는 “Hybrid with HyDE” 방법을 사용하며, 재정렬에는 monoT5를 사용하고, 재포장에는 Reverse를 선택하며, 요약에는 Recomp을 활용하는 것이 권장된다. 이 구성은 평균 점수 0.483을 기록하였지만, 계산적으로 집약적인 과정이 필요하다.
- 균형 잡힌 효율성 관행:(Balanced Efficiency Practice) 성능과 효율성 사이의 균형을 맞추기 위해서는 쿼리 분류 모듈을 포함하고, 검색에는 Hybrid 방법을 구현하며, 재정렬에는 TILDEv2를 사용하고, 재포장에는 Reverse를 선택하며, 요약에는 Recomp을 사용하는 것이 좋다. 검색 모듈이 시스템에서 처리 시간의 대부분을 차지하기 때문에, 다른 모듈은 그대로 두고 Hybrid 방법으로 전환하는 것만으로도 지연 시간을 크게 줄이면서 비슷한 성능을 유지할 수 있다.
5.2 Multimodal Extension
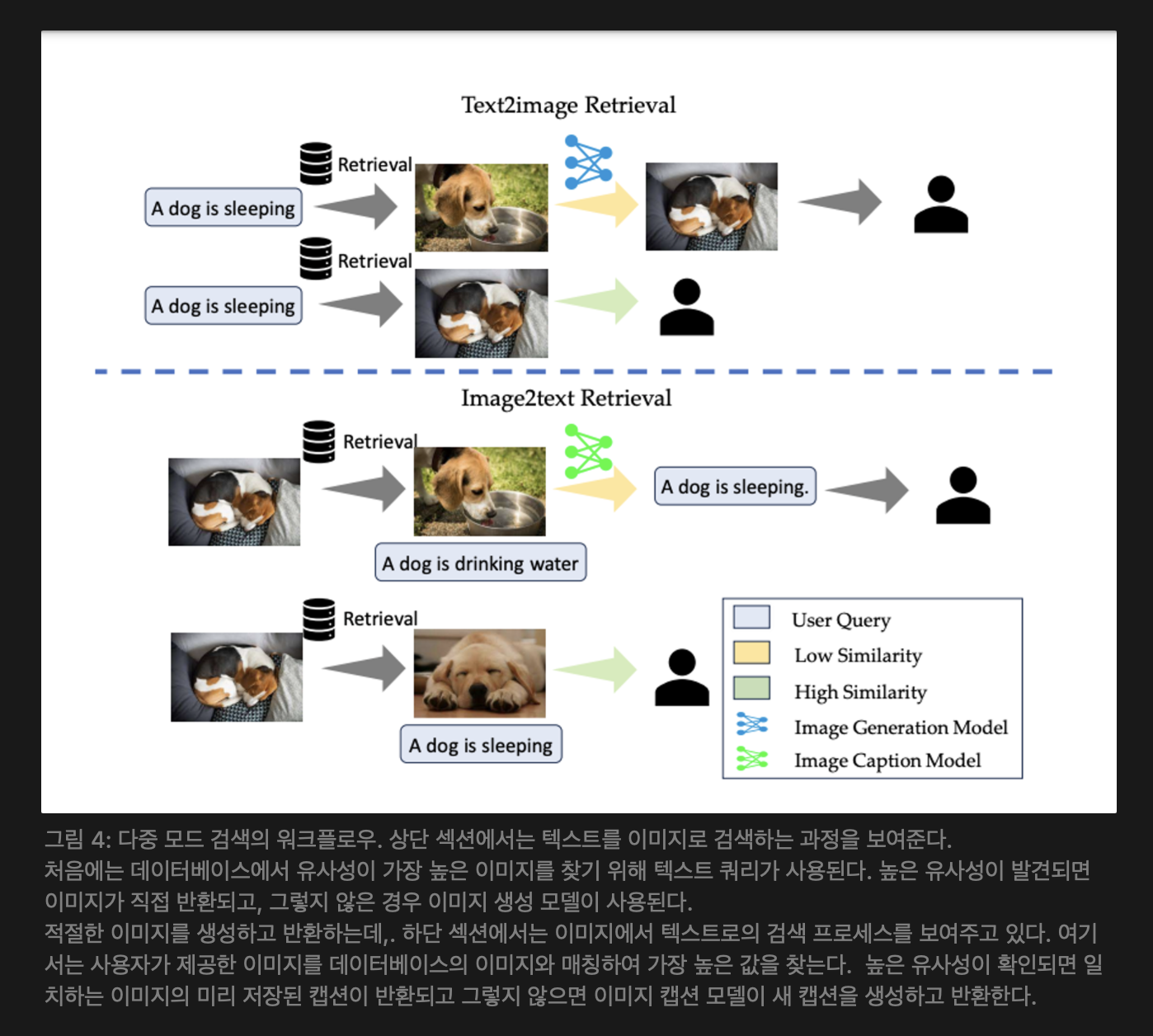
그림 4: 다중 모드 검색의 워크플로우. 상단 섹션에서는 텍스트를 이미지로 검색하는 과정을 보여준다.
처음에는 데이터베이스에서 유사성이 가장 높은 이미지를 찾기 위해 텍스트 쿼리가 사용된다. 높은 유사성이 발견되면 이미지가 직접 반환되고, 그렇지 않은 경우 이미지 생성 모델이 사용된다.
적절한 이미지를 생성하고 반환하는데,. 하단 섹션에서는 이미지에서 텍스트로의 검색 프로세스를 보여주고 있다. 여기서는 사용자가 제공한 이미지를 데이터베이스의 이미지와 매칭하여 가장 높은 값을 찾는다. 높은 유사성이 확인되면 일치하는 이미지의 미리 저장된 캡션이 반환되고 그렇지 않으면 이미지 캡션 모델이 새 캡션을 생성하고 반환한다.
RAG를 multi-modal 애플리케이션으로 확장할 때 즉 텍스트-이미지 및 이미지-텍스트 검색 기능을 시스템에 통합하였으며, 대량의 이미지와 텍스트 설명 쌍을 검색 소스로 활용한다. 위 [그림 4]에 나타난 바와 같이, 텍스트-이미지 기능은 사용자의 쿼리가 저장된 이미지의 텍스트 설명과 잘 맞을 때 이미지 생성 과정을 가속화한다 (즉, “검색으로 생성” 전략). 반면, 이미지-텍스트 기능은 사용자가 이미지를 제공하고 입력 이미지에 대해 대화를 할 때 작동한다. 이러한 mluti-modal RAG 기능은 다음과 같은 이점을 제공한다.
- 근거 기반 (Groundedness): 검색 방법은 검증된 다중 모달 자료에서 정보를 제공하므로 진위성과 구체성을 보장한다. 반면, 실시간 생성은 모델에 의해 새로운 콘텐츠를 생성하므로 때때로 사실 오류나 부정확성이 발생할 수 있다.
- 효율성 (Efficiency): 검색 방법은 일반적으로 더 효율적이며, 특히 답변이 이미 저장된 자료에 존재할 때 그렇습니다. 반면, 생성 방법은 특히 이미지나 긴 텍스트의 경우 새로운 콘텐츠를 생성하는 데 더 많은 계산 자원을 필요로 할 수 있다.
- 유지 관리성 (Maintainability): 생성 모델은 새로운 애플리케이션에 맞추기 위해 신중한 미세 조정이 필요하다. 반면, 검색 기반 방법은 검색 소스의 크기와 품질을 단순히 확대하거나 향상시킴으로써 새로운 요구에 맞게 개선할 수 있다.
이 전략의 적용 범위를 비디오 및 음성 같은 다른 모달리티로 확장하고, 효율적이고 효과적인 교차 모달 검색 기술을 탐색할 계획이다.
6. Conclusion
이 연구에서는 대형 언어 모델이 생성하는 콘텐츠의 품질과 신뢰성을 향상시키기 위해 검색 증강 생성(RAG)의 최적 구현 방법을 식별하는 것을 목표로 한다. RAG 프레임워크 내 각 모듈에 대한 다양한 잠재적 솔루션을 체계적으로 평가하고, 각 모듈에 가장 효과적인 접근 방식을 추천했다. 또한, RAG 시스템에 대한 포괄적인 평가 기준을 도입하고, 다양한 대안 중에서 최상의 방법을 결정하기 위해 광범위한 실험을 수행했다. 이 연구는 검색 증강 생성 시스템에 대한 깊은 이해를 제공할 뿐만 아니라 향후 연구를 위한 기초를 마련한다.
Limitations
LLM 생성기의 미세 조정에 대한 다양한 방법의 영향을 평가했는데, 이전 연구에서는 검색기와 생성기를 함께 훈련시키는 것이 가능하다는 것을 보여주었다. 앞으로 이 가능성을 탐색할 예정이다. 본 연구에서는 모듈 설계 원칙을 채택하여 최적의 RAG 구현을 찾는 과정을 단순화하고 복잡성을 줄였다. 벡터 데이터베이스 구축 및 실험 수행과 관련된 막대한 비용으로 인해, 우리의 평가는 청크 모듈 내 대표적인 청크 기법의 효과와 영향을 조사하는 데 국한되었다. 다양한 청크 기법이 전체 RAG 시스템에 미치는 영향을 추가로 탐색하는 것도 흥미로울 것이다. RAG의 자연어 처리 분야에서의 적용과 이미지 생성으로의 확장을 논의하였지만, 향후 연구로 음성 및 비디오와 같은 다른 모달리티로의 확장도 매력적인 탐색 분야가 될 것이다.
결론
모델의 크기가 커진다고 해서 할루시네이션이 줄어들지 않음.
쿼리 재생성은 연구결과 유의미한 효과적인 성능을 보이지 않았음.
모든 쿼리에 RAG를 사용하는것이 아니라 윗 로직에서 쿼리 분류 모듈을 포함하는 것이 좋음
아무튼 서비스 개발하다가 쿼리를 분류할 때 LLM 한테 맞기고 다음 스텝에서 무조건 RAG 태우는 로직을 하면서 기존 ML 을 배포했던 나한테는 응답까지의 시간이 최대 8초까지도 걸리는것에 대해서 많은 충격과 공포를 받았었는데, 왜냐면 내가 처음 회사에 들어가서 추천이나 예측 모델에서 인퍼런스 시간이 1초만 넘어가도 서버팀이랑 개발팀 차장님들이 너무 느리고 느리다고 해서 진땀을 뺐었기 때문이다.
근데 LLm에서는 1초도 빠른거고 그 이상의 추론 시간이 걸려서 아웃풋이 나온다니 아직까지 충격적이긴하다.
아무튼 전 회사에서 좀 더 빠른 추론 시간에 대한 강박이 있어선지, 내가 개발한 카테고리에서는 분류모델을 학습해서 쿼리 분류를 LLM에게 맡기지 않게 했고, 카테고리에서도 먼저 쿼리가 들어오면 RAG로 가는건지 그냥 바로 LLM에게 갈건지에 대한 로직을 생각했었는데 내 방법이 틀리지만은 않았구나 라는 생각을 했다.
아무튼 RAG에 대해서도 HyDE가 좋다고하는데 이 방법을 사실 잘 몰라서 다음 paper는 HyDE에 대해서 찾아봐야겠다고 생각했다.
아무튼 나는 논문 하나 보는것도 하루 죙일 걸리네 ... 이게 맞나?
