LLM 관련 리서치를 하던 중에,
특정 도메인을 위한 LLM의 fine-tuning 학습 기법인 ORPO를 알게되었고, fine-tuning 관련 공부가 부족했던 지라 일단 발견한 개념부터 정리해보고자 한다.
ORPO (Odds Ratio Preference Optimization)
- 강화학습 및 최적화 분야에 사용되는 방법으로, 특히 LLM(대형 언어 모델)의 미세 조정(fine-tuning) 및 보상 모델링(reward modeling) 에 적용된다고 한다.
- 짧게 요약하면 주어진 선호 데이터(preference data)를 바탕으로 모델의 출력을 개선하는 기법 이다.
[1] 핵심 개념
- Odds Ratio(승산비, OR)
- 승산비는 특정 사건이 발생할 확률과 발생하지 않을 확률의 비율
- Preference Optimization (선호 최적화)
- 인간 피드백이나 특정 기준에 따라 더 나은 출력을 만들어내도록 모델을 최적화
- 보통 RLHF(Reinforce Learning from Human Feedback) 같은 방법이 사용되지만 ORPO는 이를 단순화해서 계산적으로 더 효율적으로 수행함
즉, 선호 데이터(Preference data)를 기반으로 승산비(Odds Ratio, OR)을 활용하여 모델을 최적화 하는 비법
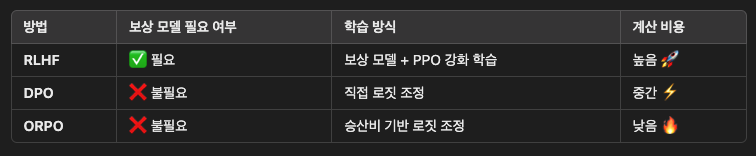
[2] ORPO vs 기존 방법(RLHF, DPO)
(1) RLHF(Reinforce learning from human feedback)
- 보상 모델을 학습한 후, 이를 이용해 정책(policy)를 업데이트 하는 방식
- PPO(Proximal Policy Optimization) 같은 강화 학습 알고리즘 사용
- 보상 모델 학습 및 PPO 적용 과정이 복잡하고 비용이 큰 단점
(2) DPO (Direct Preference Optimization)
- 보상 모델 없이 선호 데이터만 이용해 직접 최적화 하는 방법
- 보상 모델 훈련 단계를 생략할 수 있어 RLHF 보다 효율적
(3) ORPO
- DPO와 유사하지만 승산비(Odds Ratio)을 활용한 간단한 로짓 조정(logit adjustment) 기법을 사용
- 선호 데이터에서 주어진 두 출력 (좋은 답변 vs 나쁜 답변)의 확률 분포를 비교해 모델을 업데이트
- 계산량이 적고, 학습이 간단하면서 RLHF 수준의 성능을 목표로 함
[3] 장점
- 보상 모델이 불필요함 (RLHF 처럼 별도의 보상 모델 학습 필요 없음)
- 강화 학습 없이 최적화 가능 (PPO 등 복잡한 강화 학습 알고리즘 없이 작동)
- 계산적으로 효율적 (DPO처럼 간단한 로짓 조정만으로 모델을 미세 조정)
- 좋은 성능 유지 (RLHF와 유사한 성능을 달성하면서도 더 간결)
[4] 작동 방법
step 1. 데이터 준비 (Preference Data)
- ORPO에서는 쌍(pair)로 된 선호 데이터를 사용
- 일반적으로 더 좋은 응답(
chosen)과 더 나쁜 응답(rejected)의 쌍을 수집
step 2. 승산비 (Odds ratio) 계산
- 모델이 응답을 생성한 확률을 기반으로 좋은 응답
chosen과 나쁜 응답rejected비율 (승산비, OR)을 조정함
승산비 정의
OR = P(chosen) / P(rejected) = 0.8/0.2 = 4.0P(chosen) : 모델이 chosen 응답을 생성할 때
P(rejected) : 모델이 rejected 응답을 생성할 확률
이러한 승산비(OF)를 최대화 하는 방식으로 모델 업데이트
step 3. 로짓 조정 (Logit Adjustment)
- 모델이
chosen응답을 더 선호하기 위해 모델의 로짓(logit) 출력 조정
-OPRO에서는 아래와 같은 손실 함수(loss function) 사용
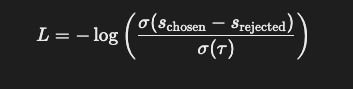
- Schosen :
chosen응답의 모델 점수(logit) - Srejected :
rejected응답의 모델 점수(logit) - σ(x)= 1/(1+e-x) 시그모이드 함수
- τ (온도 파라미터) : 학습의 안정성을 위해 사용됨
[5] 학습 과정 예시
step 1. 데이터 수집
- 사용자 피드백을 기반으로 좋은 응답과 나쁜 응답 쌍(pair) 모음
pairs:
- prompt: "뉴턴의 제1법칙을 쉽게 설명해줘."
chosen: "뉴턴의 제1법칙은 물체가 외부 힘을 받지 않으면 현재의 운동 상태를 유지한다는 뜻이에요."
rejected: "뉴턴의 제1법칙은 아이작 뉴턴이 만든 세 가지 운동 법칙 중 하나예요."
- prompt: "‘안녕하세요, 잘 지내세요?’를 프랑스어로 번역해줘."
chosen: "Bonjour, comment ça va?"
rejected: "Bonjour, comment es-tu?"
- prompt: "서울의 수도는 어디야?"
chosen: "서울은 대한민국의 수도입니다."
rejected: "서울은 한국의 한 도시입니다."
chosen응답이 더 자연스럽고 정확한 문장rejected응답은 틀리지는 않았지만 덜 선호됨
step 2. 모델이 각 응답할 확률에 대해 예측
- ORPO 모델은
chosen과rejected응답을 보고 각각의 확률 계산
예제 : "뉴턴의 제1법칙을 쉽게 설명해줘"
chosen : "뉴턴의 제1법칙은 물체가 외부 힘을 받지 않으면
현재의 운동 상태를 유지한다는 뜻이에요."
→ P(chosen) = 0.8
rejected: "뉴턴의 제1법칙은 아이작 뉴턴이 만든
세 가지 운동 법칙 중 하나예요."
→ P(rejected) = 0.2- 승산비(OR) 계산
OR = 0.8/0.2 = 4.0-> 모델이 chosen을 rejected 보다 4배 더 선호한다는 의미
step 3. 손실 및 계산 및 모델 업데이트
- 모델의 로짓 차이를 기반으로 손실(loss)을 계산하고
chosen의 점수를 높이이고rejected의 점수를 낮추는 방식으로 모델을 학습시킴
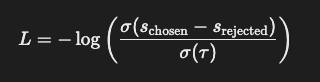
chosen 응답의 로짓 점수 Schosen = 2.5
rejected 응답의 로짓 점수 Srejected = 1.0
온도 파라미터 τ= 1.0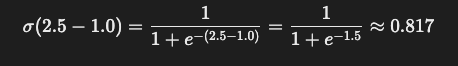
- 손실함수 L을 최소화하도록 모델을 업데이트해서
chosen의 응답 확률이더 높아지도록 만듦
[6] ORPO의 실제 사용 예
- 챗봇 개선 : AI가 더 자연스럽고 유용한 답변을 제공하도록 학습
- 자동 번역 모델 최적화 : 사용자가 선호하는 번역을 더 많이 하도록 모델 조정
- 추천 시스템 : 사용자 피드백 기반으로 더 나은 추천을 제공
[7] 추가 개념
ORPO에서 로짓(Logit) 점수의 계산 방법
- ORPO에서 로짓 점수(s)는 모델이 특정 응답을 출력할 확률을 결정하는 중요한 요소
- 로짓 점수는 모델이 특정 응답을 선택할 """원시적인 점수"""로 ,확률로 변환되기 전에 사용됨
로짓 점수(Logit)
- 모델이 어떤 단어나 문장을 출력할 때 내부적으로 계산하는 점수
- 소프트맥스(softmax) 함수를 통해 확률 값으로 변환됨
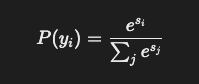
- si = 특정 응답 yi의 로짓 점수
- P(yi) = 모델이 해당 응답을 선택할 확률
- ∑e^(s_j) = 모든 가능한 응답의 지수 합
즉, 로짓 점수가 클수록 모델이 해당 응답을 더 선호한다는 뜻
로짓 점수 계산에 대한 것은 아래 포스팅 참고
-> https://velog.io/@heyggun/LLM-logit-%EA%B3%84%EC%82%B0
결론
ORPO은 승산비 기반 최적화(odds ratio-based optimization)을 이용해, 보상 모델 없이도 효과적으로 LLM을 미세조정 하는 방법이다.
DPO와 비슷하지만 더 간단한 로짓 조정 방식을 이용해 가볍게 하면서도 성능을 유지하는 것이 특징
참고 사이트
