[LLM] LLM 모델 output 강제화하기 (prompt에서StructuredOutputParser 사용과 model의 with_structured_output 함수 비교)
LLM
서론
-
나는 openAI의 사용화된 gpt 모델과 meta의 오픈소스 llama 를 가지고 AI agent를 만드는 팀에서 일을 하고 있다.
-
그 중 LLM의 output을 json 형태나 아니면 원하는 스키마 형태로 반환하기 위해서 chain을 만들어 LLM의 생성된 output을 확인하던 중 LLama의 prompt 내에서 StructuredOutputParser 가 의도된 바와 같이 output을 내놓지 않으면서 발생했다 !
-
나는 LLM의 답변의 형태를 원하는 대로 반환하기 위해서 langchain 한국어 튜토리얼을 참고해서 prompt 내에 format_instructions 을 사용해서 구조화된 출력파서인
StructuredoutputParser를 사용했다!
그러나 희망하는 output 형태가 아니였다.
본론
시도 1. prompt에 StructuredoutputPaser 사용하기
- 일단 목표는 LLM 에게 '카테고리(Category)'와 '설명(Description)'을 전달하면 그에 관련되어 파생되어 나올 수 있는 추천 질문을 3개 생성하도록 하고 싶다. 희망하는 output 구조는
{question1 : 생성한 질문1,
question2 : 생성한 질문2,
question3: 생성한 질문3} 이다.
step1
일단 langchain의 output parser인 ResponseSchema 클래스를 사용해서 원하는 응답 스키마를 정의하고 StructuredOutputParser를 response_schemas 를 사용해 초기화해서, 정의된 응답 스키마에 따라서 출력을 구조화했다.
아래와 같이 response_schemas를 question1, question2, question3로 받기 위해서 구조화된 출력 파서를 정의했다.
from langchain.output_parsers import ResponseSchema, StructuredOutputParser
response_schemas = [
ResponseSchema(name="question1", description="The first question created"),
ResponseSchema(name="question2", description="The second question created"),
ResponseSchema(name="question3", description="The third question created")
]
# 응답 스키마를 기반으로 한 구조화된 출력 파서 초기화
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)step2
프롬프트를 작성해준다. (영문판, 한국판 희망하는 대로)
case 1. 영문
from langchain_core.prompts.chat import ChatPromptTemplate
prompt = PromptTemplate(template="""Instruction: Your task is to generate questions that a human user might realistically ask based on the provided Category and Description.
\n
Guidelines:
Focus on User Perspective: Imagine you are the user exploring this topic. Create questions that are natural, relevant, and curiosity-driven.
Avoid Irrelevant or Overly Broad Questions: Keep the questions specific to the given information. Do not generate vague or unrelated questions.
Category Independence: If there are multiple categories, treat each category independently. Do not combine categories to form a single question.
\n
Input Example:
category: {category}
decription {description}
Your Output:
Generate 3 questions per category.
Ensure the questions are user-friendly, concise, and directly tied to the given information.
Answer in korean.
format: {format_instructions}
"""
)
case2. 한국어
from langchain_core.prompts.chat import ChatPromptTemplate
prompt = PromptTemplate(template=지침: 귀하의 과제는 제공된 카테고리와 설명을 기반으로 인간 사용자가 실제로 물어볼 수 있는 질문을 생성하는 것입니다.
\n
지침:
사용자 관점에 집중: 이 주제를 탐구하는 사용자라고 상상해 보세요. 자연스럽고 관련성이 있으며 호기심을 유발하는 질문을 만드세요.
관련성이 없거나 지나치게 광범위한 질문은 피하세요: 질문은 주어진 정보에 구체적으로 유지하세요. 모호하거나 관련성이 없는 질문을 생성하지 마세요.
카테고리 독립성: 여러 카테고리가 있는 경우 각 카테고리를 독립적으로 취급하세요. 카테고리를 결합하여 단일 질문을 형성하지 마세요.
\n
입력 예:
카테고리: {category}
설명 {description}
출력:
카테고리당 3개의 질문을 생성하세요.
질문이 사용자 친화적이고 간결하며 주어진 정보와 직접 연결되어 있는지 확인하세요.
한국어로 답변하세요.
형식: {format_instructions}
"""step3
- 넣을 카테고리(category), 설명(description) 을 정의하고 위해서 정의한 format_instruction을
partial함수를 통해서 prompt에 넣어준다.
category = "문서"
description ="""당신의 목표는 질문에 대한 답변을 문서에서 효과적으로 찾아 제공하는 것입니다.
당신의 기능은 문서 검색 및 관련 정보 제공입니다."""
prompt = prompt.partial(category=category,
description=description,
format_instructions=format_instructions)step4
- model과 prompt를 엮어서 chain을 만든다.
나의 모델은 다른 곳에서 불러오기 때문에 model 정의는 따로 정의하지 않았다. 희망하는 오픈소스 모델과 gpt 모델은 각자 불러와서 llama_model, gpt_model에 정의해야한다. (나는 llama3.1 버전을 사용했고, gpt는 gpt4.0 mini를 사용했다. )
llama_chain = prompt | llama_model
gpt_chain = prompt | gpt_modelstep5
- llama3.1 모델로 엮은 chain과 gpt mini의 생성한 값을 비교해본다.
딱히 question은 영향을 아직 끼치지 않아서 그냥 없이 invoke 했다.
llama_result = llama_chain.invoke({"question" : ""})
gpt_result = gpt_chain.invoke({"question" : ""})
print(llama_result.content)
print(gpt_result.content)llama_result

gpt_result

-
얼추 형태는 맞았지만 한국어로 반환하라는 명령어 때문에 key 값으로 question1, question2, question3 을 질문1, 질문2, 질문3으로 반환했고, dict[dict] 형태로 반환되어 처음 키를 category로 잡아버리는 상황이 발생했다.
-
같은 프롬프트이지만 mini인 gpt는 찰떡같이 해당 출력형태로 반환한다.
llama용 프롬프를 만들어서 좀 더 정교하게 다듬어도 되지만 프롬프트를 수정해야 하는 시행착오가 발생한다.
아무튼 이러한 상황에서, 희망하는 스키마로 아웃풋을 완전 강제화 할 수 있는 방법이 있는데 그것이 바로 model 자체에 with_structured_output을 사용하는 것이다!
시도 2. model 에 with_structured_output 사용하기
step1
- 이번에는 pydantic의 basemodel, Field를 사용해서 출력하고자 하는 응답 스키마를
RecommendQuestion클래스로 구조화해줬다.
from pydantic import BaseModel, Field
class RecommendQuestion(BaseModel):
question1: str = Field(description="The first question created")
question2: str = Field(description="The second question created")
question3: str = Field(description="The third question created")step2
- 프롬프트를 생성한다. 위와 프롬프트 내용은 동일하지만 format_instruction은 사용하지 않으니 해당 인자를 제외한다.
from langchain_core.prompts import PromptTemplate
prompt = PromptTemplate(template="""Instruction: Your task is to generate questions that a human user might realistically ask based on the provided Category and Description.
\n
Guidelines:
Focus on User Perspective: Imagine you are the user exploring this topic. Create questions that are natural, relevant, and curiosity-driven.
Avoid Irrelevant or Overly Broad Questions: Keep the questions specific to the given information. Do not generate vague or unrelated questions.
Category Independence: If there are multiple categories, treat each category independently. Do not combine categories to form a single question.
\n
Input Example:
category: {category}
decription {description}
Your Output:
Generate 3 questions per category.
Ensure the questions are user-friendly, concise, and directly tied to the given information.
Answer in korean.
""",
)
step3
- prompt에 category, description을 동일하게 partial을 사용해 넣어준다.
category = "인공지능(AI)의 미래"
description = "인공지능 기술은 최근 몇 년 동안 급격하게 발전했으며, 여러 산업에서 중요한 역할을 하고 있습니다. 이에 따라 AI가 인간의 삶에 미칠 영향을 예측하고, AI 기술이 발전하면서 생길 수 있는 윤리적, 사회적 문제에 대해 논의할 필요성이 커지고 있습니다."
prompt = prompt.partial(category=category,
description=description)
step4
- model을 불러오고 model에
with_structured_output을 이용해서 위에서 정의한 응답 스키마에 맞는 클래스를 넣어준다.
그리고 위의 프롬프트와 엮어서 chain을 생성한다.
llama_chain = prompt | llama_model.with_structured_output(RecommendQuestion)
gpt_chain = prompt | gpt_model.with_structured_output(RecommendQuestion)
step5
- 결과를 비교해본다.
llama_result = llama_chain.invoke({"question" : ""})
gpt_result = gpt_chain.invoke({"question" : ""})llama_result
RecommendQuestion(question1='인공지능 기술이 앞으로 몇 년 내에 어떻게 발전할지 예측할 수 있을까요?',
question2='인공지능이 인간의 삶에 미칠 영향을 어떤 식으로 예상할 수 있을까요?',
question3='인공지능이 여러 산업에 적용되는 것에 대해 더 많이 알려지고 싶습니다.')gpt_result
RecommendQuestion(question1='인공지능이 인간의 삶에 어떤 구체적인 영향을 미칠 것으로 예상되나요?',
question2='AI 기술의 발전이 가져올 수 있는 윤리적 문제는 무엇인가요?',
question3='인공지능이 여러 산업에서 중요한 역할을 하기 위해 필요한 조건은 무엇인가요?')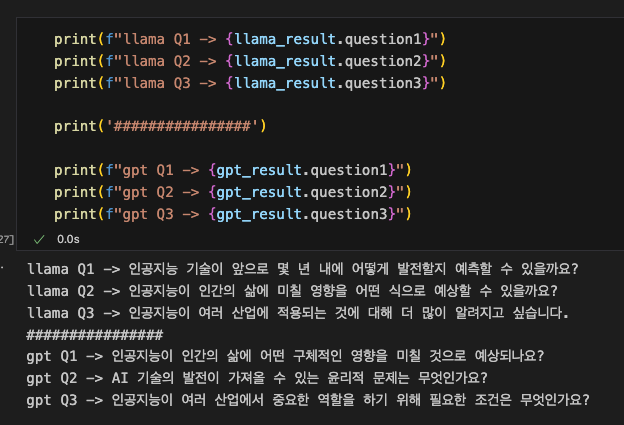
- 위에서 정의한 RecommendQuestion의 클래스의 인스턴스로 question1, question2, question3가 잘 나오는 걸 볼 수 있다. 능지 이슈로 인해서 llama 가 gpt보다 답변 퀄리티가 좀 떨어지긴 한다.
결론
- LLM에서 나온 결과를 백엔드나 프론트엔드, 혹은 나온 결과를 다른 api로 보내서 사용해야 하는 경우에는 정해진 스키마에 따라서 구조화된 output을 내야 하는 경우에 따라서는 model 자체에
with_structured_output을 사용한다. - 그 외에 콘텐츠 생성을 해서 output 형태를 맞추고 싶다고 한다면 langchain의 output parser를 사용한다. (
StructuredOutputParser와 같이) - 찾아보니까 model에 아웃풋을 강하게 저런식으로 넣어주면 output 의 퀄리티가 조금은 저하될 수 도 있다고 하는데, 해당 인자의 반환값을 api의 인자로 넣어줘야 하거나 확실한 output이 필요한 경우에는 어쩔수 없이
with_structured_output을 사용할 것 같다. 차이점은.. 좀 찾아봐야 겠음 !
참고 사이트
