csv 파일외에 제멋대로 생긴 엑셀 파일들을 제대로 인코딩해서 LLM에게 전달해서 원하는 답을 얻기란 생각보다 어려운 일이다.
이번에 기본적으로 생긴 엑셀 파일들에 대해서 LLM에게 어떻게 전달하면 좋을 지에 대한 방법론을 찾다가 마이크로소프트에서 나온 spreadsheetLLM 관련 논문을 알게 되었다.
이 논문을 좀 읽으면서 인사이트를 찾고 싶었음.
SPREADSHEETLLM: Encoding Spreadsheets for Large Language Models
Abstract
스프레드시트는 광범위한 2차원 그리드, 유연한 레이아웃, 다양한 서식 옵션을 특징으로하며, 이는 대형 언어 모델(LLM)에 상당한 도전과제이다.
이에 대응해 이 논문에서는 SPREADSHEETLLM을 소개하면서, 스프레드시트에 대한 LLM의 강력한 이해 및 추론 능력을 발휘하고 최적화할 수 있또록 설계한 효율적인 인코딩 방법을 제시한다.
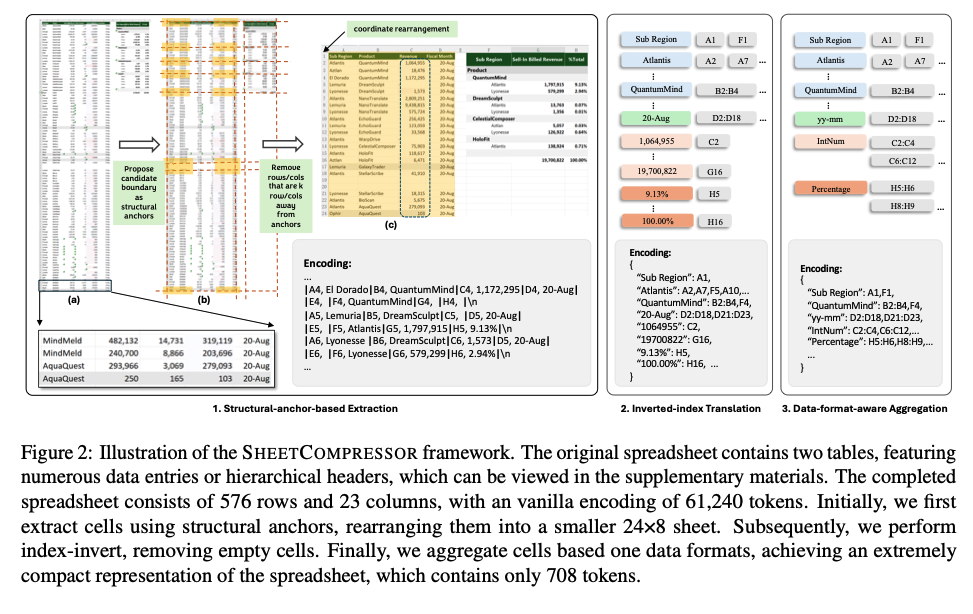
먼저 셀 주소, 값, 서식을 포함한 기본적인 직렬화(serialization) 접근법을 제안한다. 하지만 이러한 접근법은 LLM의 토큰 제한으로 인해 대부분의 애플리케이션에서 실용성이 부족하다. 이 문제를 해결하기 위해 SHEETCOMPRESSOR 라는 인코딩 프레임워크를 개발해서 LLM이 스프레드시트를 효과적으로 압축할 수 있도록 했다.
SHEETCOMPRESSOR는 다음과 같은 세 가지 모듈로 구성된다
(1) structural-anchor-based compression (구조적 앵커 기반 압축)
(2) inverse index translation (역 인덱스 변환)
(3) data-format-aware aggregation (데이터 형식 인식 집계)
이 프레임워크는 스프레드시트 테이블 탐지(task) 성능을 크게 향상시키고, GPT-4의 In-contenxt Learning 환경에서 기본 직렬화 방식보다 25.6% 더 높은 성능을 달성했다.
SHEETCOMPRESSOR을 활용한 미세 조정(파인 튜닝)된 LLM은 평균 25배의 압축률을 유지하면서도 f1-sore 78.9%를 기록해 기존 최고 모델보다 12.3% 높은 성능을 보였다.
추후 스프레드시트 이해를 위한 후속 작업으로 Chain of Spreadsheet 개념을 제안하고, 이를 고난도 스프레드시트 QA(tast)에서 검증했다. 이 연구의 방법론은 스프레드시트의 고유한 레이아웃과 구조를 체계적으로 활용해서 SPREADSHEETLLM이 다양한 스프레드시트 관련 작업에서 탁월한 성능을 발휘함을 입증하고 있다.
1. Introduction
스프레드시트는 데이터 관리를 위한 필수 도구로, Microsoft Excel과 Google Sheets와 같은 플랫폼에서 광범위하게 활용된다. 스프레드시트의 레이아웃과 구조를 이해하는 것은 전통적인 모델들에게 오랫동안 어려운 문제였고, 효과적인 데이터 분석과 지능적인 사용자 상호작용을 위해 매우 중요한 요소이다.
최근 대형 언어 모델(LLM)의 급속한 발전으로 테이블 처리와 추론 분야에서 새로운 가능성이 열렸는데, 스프레드시트는 LLM에게 다음과 같은 과제를 안겨준다.
(1) 토큰 제한 문제 : 스프레드시트는 보통 매우 큰 그리드를 가지고, 이를 기존 LLM이 처리할 수 있는 토큰 한계를 초과하는 경우가 많다.
(2) 비선형 구조 : 스프레드시트의 고유한 2차원 레이아웃과 구조는 LLM이 일반적으로 처리하는 선형 및 순차적 입력 방식과 잘 맞지 않는다.
(3) 스프레드시트 특화 요소 : LLM은 종종 셀 주소(cell addresses) 및 서식(format)과 같은 스프레드시트 특화 기능을 효과적으로 처리하는데 어려움을 겪고, 이는 스프레드시트 데이터를 정확하게 해석하고 활용하는 능력을 제한한다. (자세한 내용은 부록 A 참고)
이 연구에서는 LLM이 스프레드시트를 이해하고 추론하는 능력을 극대화하기 위한 프레임워크인 SPREADSHEETLLM을 소개한다. 먼저, 스프레드시트를 시퀀스로 직렬화(serialization)하는 기본적인 인코딩 방식을 제안하고, 이는 Markdown 기반 인코딩을 확장해서 필수적인 셀 주소와 (선택적) 서식 정보를 포함하도록 설계되었다.
그러나 LLM의 토큰 한계를 초과하는 대형 스프레드시트는 단순히 처리할 수 없을 뿐만 아니라, 기존 연구에서 관찰된 바와 같이 크기가 커질수록 모델의 정확도도 저하되는 경향이 있다. 이를 해결하기 위해서 여기에서는 SHEETCOMPRESSOR를 제안하고, 다음과 같은 세 가지 모듈로 구성된 새로운 인코딩 프레임워크를 포함한다.
(1) Structural Anchors for Efficient Layout Understanding (효율적인 레이아웃을 위한 구조적 앵커)
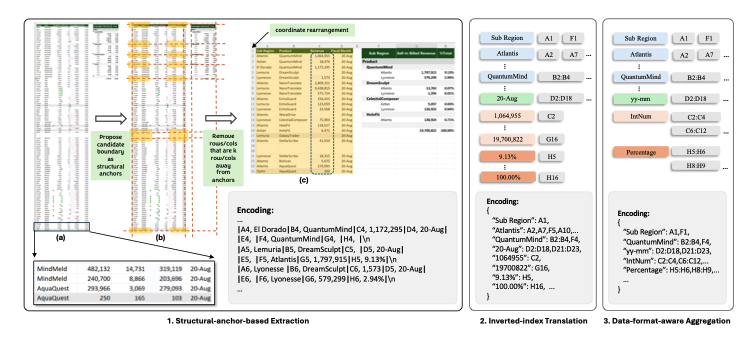
<그림 2의 (a), (b), (c)>
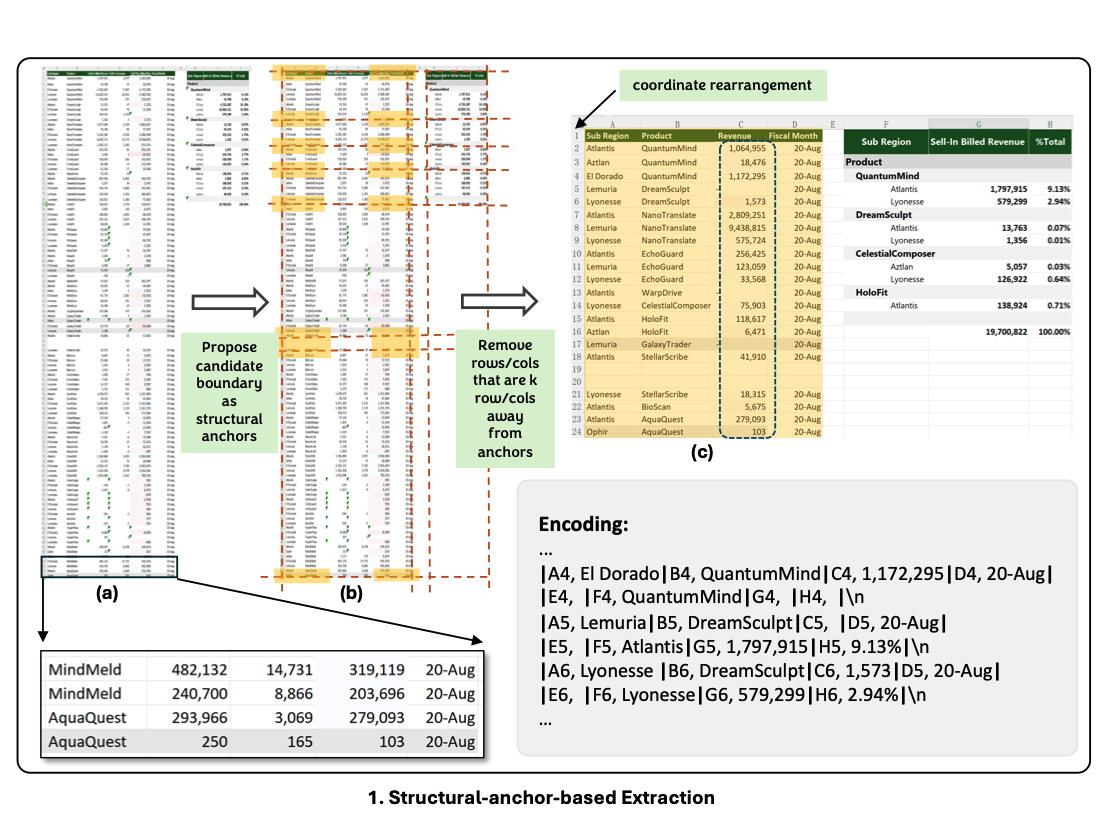
- 관찰 결과 대형 스프레드시트에는 동질적인 행과 열이 다수 퐇마되는 경우가 많고, 이는 레이아웃 구조 이해해 거의 기여하지 않는다. (그림 2 (a) 왼쪽 패널 참고) 이를 해결하기 위해
Structural Anchors를 정의하는데, 이는 테이블 경계에 위치한 이질적인 행과 열로, 중요한 레이아웃 정보를 제공한다(그림 2 (b) 참고). 이후, 멀리 떨어진 동질적인 행과 열을 제거해 시프레드시트의 요약된 골격(skeletn)버전을 생성한다. (그림 2 (c) 참고)
(2) Inverted-Index Translation for Token Efficiency (열 인덱스 변환 기반 효율화)

- 기본 직렬화 encoding 방식은 빈 셀과 반복적인 값이 많은 스프레드시트를 처리할 때 과도한 토큰을 소비하는 문제가 있다. (그림 2 (c) 참고. 이를 해결하기 위해 기본의 행(row)-열(column) 단위 직렬화 방식을 벗어나, 손실 없는 역 인덱스 변환(loossless inverted-index translation)을 JSON 형식으로 적용한다.
- 이 방식은 비어 있지 않은 셀의 텍스트를 인덱싱하는 사전을 생성하고, 동일한 텍스트를 가진 셀 주소를 병합하여 토큰 사용을 최적화하면서도 데이터 무결성을 유지한다.
(3) 숫자형 셀의 데이터 형식 집게(Data Format Aggregation)
- 연속된 숫자형 셀들은 종종 유사한 숫자 서식을 공유한다. 우리는 정확한 숫자 값 자체는 스프레드시트 구조 이해에 덜 주용하다는 점을 활용하여, 이들 셀에서 숫자 형식 문자열과 데이터 타입을 추출한다. 그런 다음 동일한 형식이나 데이터 타입을 가진 인접한 셀들을 클러스트링하여 그룹화한다.
- 그림 2의 오른쪽 예시에서 볼 수 있듯이, 이 접근법을 통해 일관된 형식 문자열과 데이터 타입으로 직사각형 영역을 표현함으로써 숫자 데이터의 분포를 효과적으로 파악하면서도 불필요한 토큰 사용을 줄일 수 있다.
이 논문에서는 다양한 LLM을 활용해 이 방법론을 포괄적으로 평가했다.
실험 결과 SHEETCOMPRESSOR는 스프레드시트 인코딩 시 토큰 사용량을 96%까지 감소시켰다. 또한 SPREADSHEETLLM은 스프레드시트 테이블 탐지(Table Detection) 작업에서 기존 SOTA(State-of-the-Art) 방법 대비 12.3% 높은 성능을 달성했다.
또한 여기서 SPREADSHEETLLM을 대표적인 스프레드시트 QA(질의 응답) 작업에 적용했다. Chain of Thought(COT) 방법론에서 영감을 받아, Chain of Spreadsheet(COS) 개념을 제안하고, 이를 통해 스프레드시트 추론 과정을 테이블 탐지 -> 매칭 -> 추론 파이프라인으로 분해했다. 그 결과 SPREADSHEETLLM은 기존 SOTA 테이블 QA 모델 대비 월등한 성능을 보였다.
2. Related Work
Spreadsheet Representation
- 스프레드시트 표현은 스프레드시트를 다양한 모델에 맞게 특정 표현 방식으로 변환하는 작업을 의미한다. 스프레드시트(또는 테이블) 표현 방법에는 여러 가지가 있다.
- Mask-RCNN을 확장해 스프레드시트의 공간적 및 시각적 정보를 활용하는 방법을 제안하기도 하고 이미지 테이블을 평가하기 위해 LLMs 활용을 시도하는 방법도 있었으나 Vision-Language Models(VLMs)에 스프레드시트 이미지를 입력했을 때는 성능이 좋지 않았다. 또한 행과 열 내 순차적 의미(sequential semantics)를 포착하기 위해 LSTM 기반 방법도 활용되었다. 이어 사전학습 언어 모델 기반의 스프레드시트 이해 방법도 제안되었고, 최근에는 Markdown과 HTML 포맷을 이용해 테이블을 표현하는 시도들도 이루어졌다.
- 그러나 이러한 방식들은 단일 테이블(single table) 입력에 최적화되어 있어, 스프레드시트와 같은 다중 테이블 환경에는 적합하지 않음을 실험적으로 확인했다. (Appendix B)
Spreadsheet Understanding
- 대부분의 Table LLMs 연구는 단일 테이블 환경에 국한되어 있다. 그러나 실제 스프레드시트는 다중 테이블을 포함하는 경우가 많고, 이는 LLM의 토큰 제한(token limi)을 초과하는 문제가 발생한다.
또한 다양한 레이아웃과 구조는 문제를 더욱 복잡하게 만든다. - 이에 따라 스프레드시트 테이블 탐지(Spreadsheet Table Detection) 작업이 등장했는데, Spreadsheet Table Detection은 주어진 시트 내에서 모든 테이블을 식별하고, 각각의 범위(range)를 결정하는 것을 목표로한다.
이 작업은 스프레드시트 이해의 기초적 작업이고, 상업용 스프레드시트 도구에서 매일 수억건 사용되는 기능이지만, 스프레드시트의 유연성과 복잡성으로 인해 정확도 개선의 여지가 여전히 크다.
Spreadsheet Downstream Tasks
- 스프레드시트 이해는 다음과 같은 다양한 후속 작업의 기반이 된다.
- 테이블 질의 응답(Table Question Answering, QA)
- 테이블 추출(Table Extraction)
- 수식 및 코드 생성(Formula or Code Generation)
- 오류 탐지(Error Detection)
- 본 논문에서는 이 중에서도 특히 스프레드시트 QA를 실험 대상으로 채택했다.
스프레드시트 QA는 스프레드시트 데이터를 이용한 Table QA의 확장 버전으로, 다수의 테이블을 탐지하고 매칭하는 복잡성이 추가된 작업이다.
LLM's Token Efficiency
- 관련 연구에 따르면 LLM은 긴 입력(context)가 주어질수록 성능이 급격히 저하된다. 이에 따라 , 성능 개선 및 비용 절감을 위한 압축(compression) 기법이 활발히 연구되고 있다. 일부 연구에서는 정보이론(information-theroy)을 활용해 중복 정보를 제거하고, 전용 모델을 사용해 프롬프트 압축을 최적화하는 시도도 존재한다.
그러나 이러한 방법들은 대부분 자연어 프롬프트(narual language prompts)를 대상으로 설계되어 표 형태(tabular data)에는 적합하지 않으며, 적용 시 구조 및 데이터 손실이 발생할 수 있다. - DBCopilot은
스키마 라우팅(schema routing)을 통해 대규모 데이터베이스에서 text-to-SQL 변환을 수행할 수 있다.
그러나 LLM은 multi-table layouts(다중 테이블 레이아웃) 및 복잡한 테이블 구조 이해가 부족하여, SQL과 유사한 쿼리 실행이 어려워지고, 이로인해 최신 테이블 관련 연구 성과를 스프레드시트에 직접 적용하기 어렵다.
3. Method (방법론)
이 논문에서는 Markdown 스타일의 텍스트 형식으로 스프레드시트를 인코딩하는 새로운 프레임워크를 제안했다. 더 압축적이고 효율적인 표현을 달성하기 위해, 세 가지 독립적이지만 결합 가능한 모듈을 도입했다.
(1) Structural-Anchor-Based Extraction (구조적 앵커 기반 추출)
(2) Inverted-Index Translation(인덱스 역 변환)
(3) Data-Froam-Aware Aggregation (데이터 형식 인식 집계)
3.1 Vanilla Spreadsheet Encoding with Cell Value, Address, and Format
(기존 스프레드시트 인코딩 방식)
- 현재까지 LLM을 위한 표준화된 스프레드시트 인코딩 방식이 존재하지 않아, 기존의 대표적인 테이블 데이터 인코딩 방식(예: HTML, XML, Markdown)의 성능을 비교했다. (Appendix B 참조)
- 그 결과 인코딩 길이와 스프레드시트 이해 작업 성능을 고려했을 때, Markdown 스타일 표현 방식이 가장 적합한 것으로 나타났다.
이를 수식으로 표현하면 다음과 같다.
- 여기서 S∈R^(m,n) 은 스프레드시트를 나타낸다.
- i,j는 각각 행(row)과 열(column) 인덱스
- m,n 은 전체 행 (row), 전체 열(column)의 범위를 나타냄
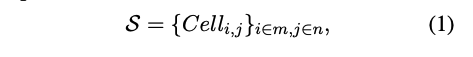
Markdown 기반 인코딩
- T∈R^1 : 텍스트 기반 표현된 셀
- 각 셀은 주소(Address), 값(Value), 형식(Format) 정보를 포함함
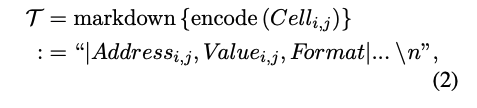
-
셀 형식 정보를 포함해서 셀의 표현에 배경색, 볼드체, 테두리 등의 셀 형식 정보를 추가하는 것도 실험했는데, 이러한 상세한 인코딩 방식은 모델의 성능을 저하시킨다는 결과를 도출했다.
그 이유는 (1) 토큰 제한 초과(Token Limit Exceedance)로 지나치게 세밀한 포맷 정보를 포함할 경우, 빠르게 토큰 한도를 초과하게 된다.
(2) LLM의 형식 정보 처리 한계로 현재 LLM은 구조 및 형식 정보(format cues)를 효과적으로 처리하는 능력이 부족하다. 따라서 단순히 형식 정보를 추가하는 것만으로는 스프레드시트 이해 성능이 향상되지 않는다.
(Appendix A에서 실험 결과 참고) -
이에 따라, 향후 연구에서는 LLM이 형식 및 구조적 정보를 보다 효과적으로 활용할 수 있도록 모델 개선 방안을 탐색할 계획이다.
3.2 Structural-anchor-based Extraction(구조적 앵커 기반 추출)
- 대규모 스프레드시트는 동일한 형식(homogeneous)의 행(row) 또는 열(column)이 다수 존재하는 경우가 많다. 이러한 중복된 데이터는 스프레드시트의 레이아웃 및 구조적 이해에 거의 기여하지 않는다. (그림 2(a) 참고)
- 이에 따라, 핵심적인 레이아수 및 구조 정보를 유지하면서 스프레드시트를 효과적으로 압국하는 새로운 휴리스틱(heuristic) 기반 방법을 제안한다. (부록 C 참고)
Structural Anchors(구조적 앵커) 정의
- 여기서의 방법은 table boundaries(테이블 경계)에 위치한
이질적인 행(heterogeneous row)와열(heterogeneous column)을 찾아 structural anchors(구조적 앵커)로 설정한다.
r_p = {Cell_(i,j)}_(i=p, j∈n): p번째 행 (Row)c_q = {Cell_(i,j)}_(i∈m,j=q): q번째 열 (Column)
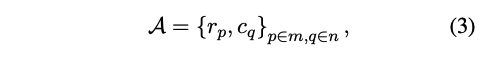
- 즉, 스프레드시트에서 경계 근처의 중요한 핼과 열을 구조적 앵커로 설정하는 것이다.
Data Filtering(데이터 필터링)
- 구조적 앵커를 활용해, 앵커 지점에서 k unit(유닛) 이상 떨어진 행과 열을 제거한다.
그 이유는 이러한 데이터들은 대부분 테이블의 경계를 형성하지 않기 때문이다.- k값은 필터링 강도를 조절하는 임계값(threshold) 역할을 한다.
- k 값이 클수록 더 넓은 범위의 데이터를 유지하고, 작을수록 더욱 압축된 표현을 얻을 수 있다.
- 다양한 k 값의 영향을 분석하기 위해 절제 연구(Abalation Study)를 수행했고, 그 결과는 Appendix D.1 에서 확인가능하다.
Extraced Data Representation(추출된 데이터 표현)
- 압축된 스프레드시트는 다음과 같이 표현된다.
- r_p^+ : 앵커 행에서 k유닛 이내에 위치한 셀
- c_q^+ : 앵커 열에서 k 유닛 이내에 위치한 셀
- 최종적으로 압축된 스프레드시트

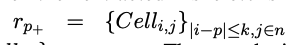

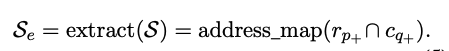
- 즉 구조적 앵커를 중심으로 특정 거리 내에 존재하는 데이터만 유지하고 나머지는 제거하는 방식이다.
- 압축 후 텍스트 표현 T_e는 원본보다 훨씬 짧아지고, 데이터 추출 후 셀 좌표를 re-mapping(재 매핑)하여 데이터 간 관계를 유지한다. 이 방법을 통해서 스프레드시트 콘텐츠의 75%를 필터링하면서도, 테이블 경계에 위치한 97%의 행과 열을 유지할 수 있다.
3.3 Inerted-index Translation(역 인덱스 변환)
- 스프레드시트에는 empty rows(빈 행), empty columns(빈 열), 그리고 scattered cells(흩어진 셀)이 다수 포함되어 있다. 기본적인 인코딩 방식(3.1 참고) 셀 주소(cell address)와 해당 내용(cell contents)를 짝짓는 그리드(grid) 기반 방식을 사용한다.
- 하지만 이러한 방식은 (1) empty cells(빈 셀)도 기록해야 해 토큰 소비량(token consumption)이 급증하거나, (2) 같은 값을 가진 셀이 여러 본 중복 저장되면서 불필요한 데이터 증가가 발생하는 비효율성을 초래한다.
이러한 문제를 해결하기 위해 **2단계 Inverted-index Translation 방법을 제안한다.
(1) 1단계 : 행렬(Matrix) -> 딕셔너리(Dictionary) 변환
- 기존 행렬 기반(matrix-style) 인코딩을 딕셔너리(dictionary) 형식으로 변환
- 이때, 셀의 값(Cell value)을 Key로 설정하고, 셀 주소(Cell Address)를 해당 값의 Index로 활용
(2) 2단계 : 동일한 값의 셀 병합(Merging of Identical Values)
- 같은 값을 가진 셀들을 병합(Merge)
- Empty Cells(빈 셀)은 제외
- 셀 주소를 범위(Range)로 표현하여 압축 효과 극대화
이 과정을 수식으로 표현한다면

값(Value) -> 해당 값을 가진 셀주소(Address)의 형태로 변환하여 중복을 제거하고 효율적인 표현을 가능하게 한다.
- 이러한 방법으로 SHEETCOMPRESSOR의 압축률(compression Ratio)가 4.41에서 14.91로 증가하고, 중복 데이터 제거 및 빈 셀 배제로 인해 토큰 소비량이 대폭 감소했다. 또한 모든 스프레드시트 이해(Spreadsheet Understanding) 작업에서 적용 가능한 손실 없는(Lossless) 방법이었다.
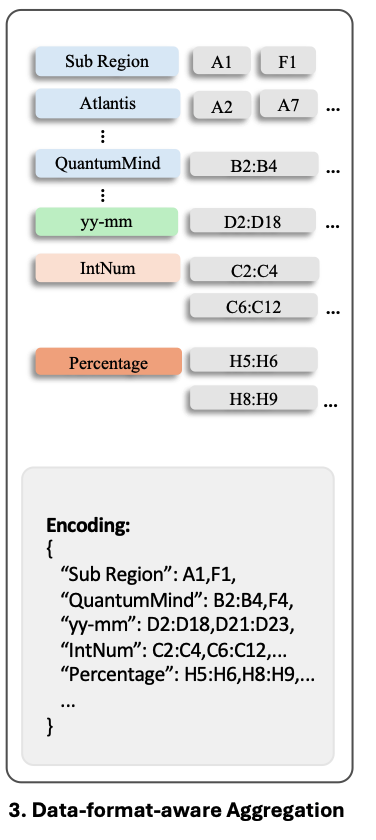
3.4 Data-format-aware Aggregation(데이터 형식 인식 기반 집계
- 스프레드시트에서 인접한 셀들은 동일한 데이터 형식을 공유하는 경우가 많다.
예를 들어 Figure 2(3)에서 C열 (Column C)는 다양한 제품의 매출(Sell-in Billed Revenue)를 나타낸다. 그러나 개별 숫자 값(예: "18,476", "18,674") 자체는 스프레드시트의 구조와 의미를 이해하는데 필수적이지 않다. - 대신 데이터 타입이 중요한 의미를 가진다. 데이터 타입은 시간(Time), 전화번호(phone Number)와 같은 근본적인 의미(Semantic Property)를 나타내고, 숫자 값의 세부 정보보다 동일한 데이터 타입을 클러스터링하여 압축(Clustering-based Comprssion) 하면 토큰 수를 줄일 수 있다.
- 추가적인 압축 및 정보 통합을 위해서 NFS(Number Format String) 기반 집계 방법을 도입한다.
[1] 1단계 NFS(Number Format String)
- 스프레드시트 셀에서 내장 속성(Built-in Attribute)으로 제공되는 데이터 형식 문자열
- 예를 들어 날짜 "2024.2.14"의 NFS는 "yyyy-mm-dd
- 추출방법으로는 ClosedXML 또는 OpenPyXL 등의 도구를 사용하여 기본적으로 NFS를 추출 가능. 하지만 사용자가 명시적으로 NFS를 설정하지 않은 경우, NFS 정보가 누락될 수 있다.
[2] 2단계 규칙 기반 데이터 타입 매핑(Rule-based Type Matching)
- NFS가 없는 경우, 규칙 기반 데이터 타입 인식기(Rule-based Recognizer)를 활용해 셀 값을 특정 데이터 타입으로 매핑한다.
- 주요 데이터 타입은 8개로 연도(Year), 정수(Interger), 실수(Float), 백분율(Percentage), 과학 표기법(Scientific Notation), 날짜(Date), 시간(Time), 통화(Currency), 이메일(Email), 기타(Others)
- 실제 데이터셋 (real-world corpera)에서 55%의 셀이 위 9가지 데이터 타입에 해당한다.
[3] 3단계. 데이터 타입 및 NFS 기반 집계(Aggregation Algorithm 적용)
- Algorithm 1을 적용하여 동일한 데이터 형식(NFS)과 데이터 타입을 공유하는 셀을 그룹화(Clustering)한다.
- R : 앞서 사전 정의된 규칙(predefined rules)
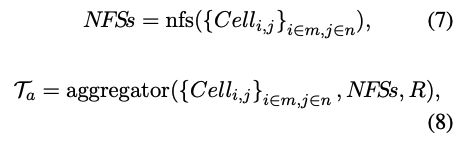
- 이 방법을 통해서 압축률(Compression Ratio)dl 14.91에서 24.79로 증가했고, 데이터 형식을 기반으로 중복 요소를 클러스터링하여 토큰 수를 감소시켰다. 또한 복잡한 스프레드시트에서도 구조적 의미를 유지하면서 효율적인 데이터 표현이 가능하다.
3.5 Chain of Spreadsheet(스프레드시트 체인)
SPREADSHEETLLM의 활용 범위를 확장하고 다양한 다운스트림 태스크를 지원하기 위해 Chain of Spreadsheet(COS) 기법을 도입한다.
Cos는 두 가지 주요 단계로 구성된다.
[1] **Table IDentification and Boundary Detection (표 식별 경계 감지)
- 입력은 압축된 스프레드시트(Compressed Spreadsheet)와 특정 질의(Task Query)이다.
- LLM이 스프레드시트 내에서 질의와 관련된 표(Table)을 식별하고, 해당 표의 정확한 경계를 감지한다(Boundary Detection). 이를 통해 분석에 불필요한 데이터를 배제하고, 처리 효율성을 최적화한다.
[2] Response Generation(응답 생성)
- 입력으로는 Specified Table Section(식별된 표)와 질의(Query)이다.
- LLM이 해당 표를 재분석하여 최적의 응답을 생성. 이 과정에서 정확성과 문맥 인식을 극대화한다.
Cos 기법의 장점으로 복잡한 스프레드시트에서도 효과적으로 작동하고, 작업을 단계별로 분할(Breakdown)하여 효율적인 데이터 처리가 가능하게 한다. 또한 문맥을 고려해 정확한 응답을 생성한다.
4. Experiments (실험)
본 연구에서 제안된 방법으로 스프레드시트 이해(Spreadsheet Understanding)에 미치는 효과를 검증하였는데, 이를 위해 기본적인 스프레드시트 표 검출(Spreadsheet Table Detection)과 스프레드시트 QA(Spreadsheet Question Answering)실험을 진행했다.
[1] Spreadsheet Table Detection(스프레드시트 표 검출)
- 스프레드시트 이해의 핵심 평가 기준으로 표 구조를 정확하게 식별하는 능력을 측정.
- Dong et al. (2019b)의 연구를 기반으로 실험을 진행함. 해당 실험을 통해 SPREADSHEETLLM이 스프레드시트의 표(Table)를 어떻게 감지하고 해석하는지 평가
[2] Spreadsheet Question Answering(스프레드시트 QA)
- 표 검출 기능을 바탕으로 다운스트림 태스크에서의 성능을 평가
- 사용자가 입력한 질의(Query)에 대해 스프레드시트 데이터를 이해하고 적절한 응답을 생성하는 능력을 측정함
- 단순한 표 검출을 넘어, 구조화된 데이터 내에서 의미를 파악하고 문맥에 맞는 답변을 생성하는 능력을 평가하는 대표적인 실험
4.1 스프레드시트 표 검출 (Spreadsheet Table Detection)
4.1.1 데이터셋 (Dataset)
- Dong et al. (2019b)에서 제시한 실제 스프레드시트 데이터셋을 사용
- 해당 데이터셋은 테이블 경계가 주석으로 표시된 스프레드시트로, 정확한 주소 라벨링에 복잡성과 애매함이 존재 (Fleiss Kappa 값: 0.830)
- 이를 해결하기 위해, 5명의 전문가에 의한 품질 개선 파이프라인을 적용하여 검증된 테스트 세트를 확보
- 188개의 스프레드시트로 구성된 검증된 테스트 세트 사용
- 테스트 세트는 토큰 사용량에 따라 Small, Medium, Large, Huge 네 가지 카테고리로 나누어 64:32:70:22 비율로 분배
- 평가 지표: Error-of-Boundary 0 (EoB-0)로, EoB-0는 위쪽, 왼쪽, 아래쪽, 오른쪽 경계의 정확한 일치를 요구함
4.1.2 실험 설정 (Experiment Setup)
기준 모델(Baseline) 및 평가 지표:
- TableSense-CNN (Dong et al., 2019b)을 기준 모델로 선택
- F1 Score를 주요 평가 지표로 사용하여 정밀도(Precision)와 재현율(Recall)을 균형 있게 평가
- F1 Score는 모델의 전체 정확도를 평가하는 데 유용
모델 선택:
- 폐쇄형 모델(closed-source): GPT-4와 GPT-3.5
언어 이해 능력이 뛰어난 OpenAI의 모델을 사용 - 개방형 모델(open-source): Llama2, Llama3, Phi3, Mistral-v2
오픈소스 모델을 다양한 스펙트럼에서 선택하여 비교 평가 - 구체적인 모델 구성은 부록 G에서 확인 가능
4.2 스프레드시트 QA (Spreadsheet QA)
4.2.1 데이터셋 (Dataset)
- 기존의 Table QA 데이터셋은 단일 테이블 시나리오에만 집중되어 있으며, 여러 테이블이 포함된 스프레드시트에 대한 성능 평가가 부족했다. 이 갭을 메우기 위해, 다중 테이블 환경에 맞춘 새로운 스프레드시트 QA 데이터셋을 개발했다.
데이터셋 구성:
- 더 큰 컬렉션에서 64개의 스프레드시트를 샘플링
- 각 스프레드시트에 대해 4-6개의 질문을 생성
- 질문은 검색, 비교, 기본 산술과 같은 기본적인 작업을 대상으로 설정
- 복합 연산을 제외하고 특정 기술을 테스트하는 데 집중
질문-답변 형식:
- 각 질문은 정확한 셀 주소나 셀 주소를 포함한 수식으로 된 답변을 포함
- 이를 통해 모델이 스프레드시트 데이터를 탐색하고 해석하는 능력을 직접적이고 명확하게 평가할 수 있도록 구성
최종 데이터셋:
- 307개의 항목으로 구성된 데이터셋
- 각 항목은 (Q, A, S) 형태로 구성되며, Q는 질문, A는 답변, S는 해당 스프레드시트
- 이 데이터셋은 스프레드시트에서 여러 테이블을 처리하는 모델의 성능을 평가하는 데 중요한 역할을 한다.
4.2.3 실험 절차 (Experiment Procedure)
- 여기서는 스프레드시트 테이블 검출(Spreadsheet Table Detection) 작업에 대해 사전 학습된 모델을 활용하여 QA 실험을 수행했다. 실험 절차는 섹션 3.5의 CoS (Chain of Spreadsheet) 방식을 따랐다.
실험 절차로는
[1] 관련 테이블 식별 및 압축 적용
- CoS 방식을 활용하여 질문과 관련된 테이블을 식별
- 테이블 크기가 너무 크면 추가 압축 기법 적용
- 기존의 구조적 앵커 기반 압축(Structural-anchor-based Extraction) 및 역색인 변환(Inverted-index Translation) 기법 활용
[2] 테이블이 너무 큰 경우, 추가 분할 적용
- 기존 압축 기법으로도 크기가 여전히 큰 경우 테이블 분할(Table Splitting) 알고리즘 적용
- 이 알고리즘은 헤더(Header)를 자동 인식하고, 의미론적 연결성을 유지하는 방식으로 테이블을 분할
[3] 분할된 테이블 조합 후 최적의 맥락 유지
- 단순한 테이블 자르기가 아닌, 연관성 높은 데이터끼리 전략적으로 결합
- 이를 통해 질문에 대한 문맥적 일관성 유지 및 정보 손실 최소화
- 테이블 분할 알고리즘의 상세 내용은 Appendix M.2에서 확인 가능
즉, CoS 기반으로 질문과 관련된 테이블을 먼저 식별하고, 테이블 크기가 크면 압축을 적용, 그래도 크다면 분할 기법 적용한다. 헤더를 중심으로 전략적으로 분할, 문맥적 일관성 유지하는 것이다.
Result
5.1 Compression Ratio(압축 비율)
압축 비율(r)은 다음과 같이 정의된다.
- n = 원본 스프레드시트의 토큰 수
- n′ = 압축된 스프레드시트의 토큰 수
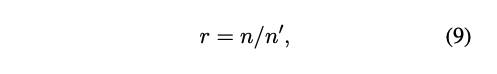
- 실험 결과, 최대 25배 압축 효과 달성과 대규모 데이터셋 처리 시 연산 부담 대폭 감소했다.

- SHEETCOMPRESSOR의 다양한 모듈 조합별 압축률은 Table 1 을 참고하며, 다양한 스프레드시트 구조에서 일관되게 높은 성능 발휘하는 것을 볼 수 있다.
5.2 Spreadsheet Table Detection(스프레드시트 테이블 검출)
5.2.1 주요 실험 결과(Main Results)
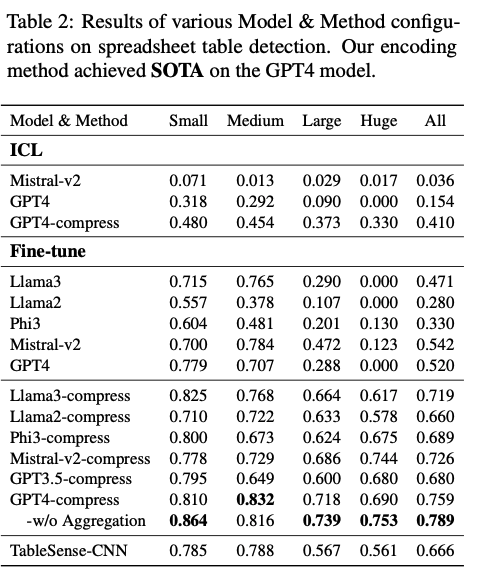
1) Enhanced Performance with various LLMs(다양한 LLM 기반 성능 향상)
- Table 2를 통해 다양한 모델 및 방법의 성능 차이를 확인 가능할 수 있다.
- 다양한 LLM 기반 성능을 비교해보면 GPT-4 모델을 학습했을 때, F1 스코어 ≈ 76%으로 이 논문의 인코딩 방법(집계 없이 사용) 적용 시 F1 스코어 ≈ 79%이다.
- 원본 데이터로 학습한 동일 모델 대비 27% 향상했으며, 기존 SOTA 모델인 TableSense-CNN 대비 13% 향상했다. 또한 최신 SOTA 성능 달성하였다.
- 오픈소스 모델 성능 비교해보면 Llama3 & Mistral-v2: F1 ≈ 72% (SOTA 대비 6% 낮음)
압축 방법 적용 후 성능 향상 폭:
Llama3: +25%, Phi3: +36%, Llama2: +38%, Mistral-v2: +18%
로 확인할 수 있다. - 즉, 압축 기법이 LLM의 성능을 크게 향상시키고, 특히 오픈소스 모델에서도 강력한 성능 개선 효과가 나타난다.
2) Benefits for Larger Spreadsheets(대형 스프레드시트에서 더 큰 이점)
- 모델의 토큰 한계 때문에 처리하기 어려웠던 대형 스프레드시트에서 압축 기법이 효과적이다.
- 대형 문서에서 F1 스코어 상승폭이 있었다.
Huge (초대형): GPT-4 대비 75%↑, TableSense-CNN 대비 19%↑
Large (대형): GPT-4 대비 45%↑, TableSense-CNN 대비 17%↑
Medium (중형): GPT-4 대비 13%↑, TableSense-CNN 대비 5%↑
Small (소형): GPT-4 대비 8%↑ - 즉, 토큰 제한으로 인한 정보 손실을 최소화하여 큰 문서에서도 높은 성능을 유지한다.
3) Improvements in In-Context Learning(In-Context Learning (ICL) 성능 개선)
- 압축된 데이터가 ICL(문맥 내 학습) 성능도 향상
- GPT-4의 ICL 기반 F1 성능이 26% 증가
- Fine-tuning 없이도 성능 향상 효과
- 추가적인 ICL 결과는 Appendix J.2 참고한다.
4) Significant Cost Reduction(비용 절감 효과)
- 압축을 통해 입력 토큰 수가 줄어들어 비용이 거의 선형적으로 감소
- GPT-4 및 GPT-3.5-turbo 모델 기준 96% 비용 절감
- 상세한 비용 절감 계산 방식은 Appendix I 참고한다.
최종적으로 정리해보자면
- 최대 25배 압축 비율 달성하여 토큰 절약 및 처리 효율성 향상
- GPT-4, Llama3, Mistral-v2 등 다양한 모델에서 높은 F1 성능 개선
- 특히 대형 스프레드시트에서 압축 효과가 더 크게 나타남
- ICL(문맥 내 학습) 성능도 크게 향상됨 (Fine-tuning 없이도 효과적)
- 비용 절감 효과 극대화 (최대 96% 절감)
으로 볼 수 있다.
5.2.2 Ablation Experiment Results
Ablation Experiment : 각 모듈을 제거한 상태에서 모델의 성능을 비교해 어떤 모듈이 가장 중요한지 분석하는 실험
Table 3 주요 결과:
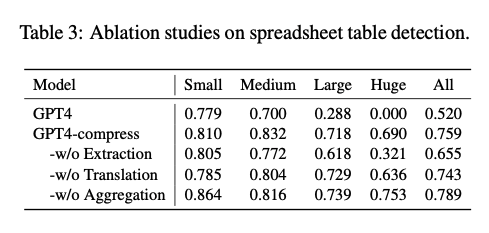
추출(Extraction) 모듈 제거 → F1 대폭 하락
- 핵심 구조 정보를 포착하고 유지하는 데 필수적인 역할
- Table 1에서도 가장 높은 토큰 절감 효과를 보였음
집계(Aggregation) 모듈 제거 → F1 소폭 증가
- 숫자 기반 표현보다 NFS(Numerical Feature Summarization)가 더 추상적이므로,
- LLM이 해석하는 데 어려움을 겪을 가능성 존재
- 하지만 높은 압축률을 제공하여 비용 절감 및 실용성 면에서 강점
즉, 결론적으로 (1) 추출 모듈은 필수적이며 제거 시 성능이 크게 하락한다. (2) 집계 모듈은 성능에 미치는 영향이 적지만 높은 압축률을 제공한다. (3) 전체적으로 압축 기법이 성능 유지와 비용 절감 측면에서 효과적이다.
5.3 Spreadsheet QA(스프레드시트 QA 실험 결과)
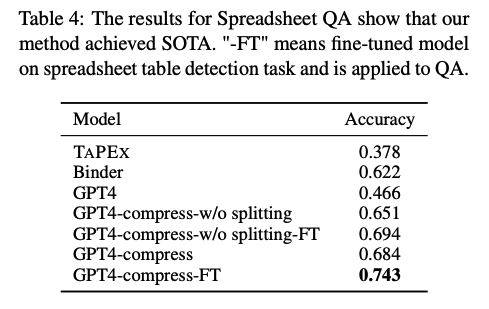
1) CoS 방법의 효과 (Contextual Selection, CoS)
- CoS 기법 적용 시 성능 22% 향상 (GPT-4 대비)
- 기존 모델은 대형 스프레드시트를 직접 입력하면 토큰 한도를 초과하는 문제 발생
- CoS는 질문과 관련된 영역만 선택하여 입력 → 불필요한 데이터 줄여 효율성 증가
- 대형 스프레드시트에서도 효과적인 QA 수행 가능
2) Fine-tuning의 일반화 성능
- 스프레드시트 테이블 검출(Task 1)로 학습된 모델이 QA(Task 2)에서도 성능 향상
- Fine-tuning 적용 후 정확도 6% 증가
- 기존 SOTA 모델 대비 성능 비교 시 TAPEX 대비 +37%, Binder 대비 +12%
- Fine-tuning이 단순한 구조 파악뿐만 아니라, 문서 전체의 이해도를 향상
3) 테이블 분할(Split) 알고리즘의 효과
- ICL(문맥 내 학습) 기반 QA에서 정확도 3% 향상
- Fine-tuned 모델에서는 정확도 5% 향상
- 토큰 제한 때문에 원래 처리 불가능했던 테이블도 처리 가능하게 만듦
즉, 최종적으로 정리하자면 Ablation 실험 결과, "추출 모듈"이 가장 중요한 역할 수행한다. CoS 방법이 GPT-4의 QA 성능을 22% 향상시키며, Fine-tuning을 적용하면 일반화 성능이 높아지며, 기존 SOTA 모델 대비 +37% 개선
을 보였다. 또한 테이블 분할(Split) 알고리즘이 QA 성능을 추가적으로 향상 (ICL +3%, Fine-tuned +5%)했다.
6. Conclusion
- SPREADSHEETLLM는 스프레드시트 데이터 처리를 위한 혁신적인 프레임워크이다. 스프레드시트 데이터를 효과적으로 처리하고 이해할 수 있도록 LLM을 활용한 새로운 프레임워크이며, SHEETCOMPRESSOR 기법을 통해 대규모 스프레드시트의 크기, 다양성, 복잡성 문제 해결할 수 있다.
- 토큰 사용량과 계산 비용을 대폭 줄여 대형 데이터셋에서도 실용적인 응용 가능하며, 최신 LLM들을 Fine-tuning하여 스프레드시트 이해 성능을 크게 향상시킬 수 있다.
- "Chain of Spreadsheet" 기법을 활용하여 스프레드시트 기반의 다운스트림 작업에서도 높은 성능을 보였다.
- 결과적으로, SPREADSHEETLLM은 더 지능적이고 효율적인 데이터 분석 및 사용자 상호작용을 가능하게 한다.
