Self-RAG: LEARNING TO RETRIEVE, GENERATE, AND CRITIQUE THROUGH SELF-REFLECTION (2023)
Paper
paper : https://arxiv.org/pdf/2310.11511
SELF-RAG: LEARNING TO RETRIEVE, GENERATE, AND CRITIQUE THROUGH SELF-REFLECTION (2023)
자가 성찰을 통한 검색, 생성 및 비판 학습
: 이 논문은 LLM이 검색하고 생성하며 스스로 비판적으로 평가하는 과정을 학습하도록 설계된 Self-RAG 프레임워크에 대한 연구이다.
Adaptive RAG를 구현하면서 그와 관련된 필요 개념들(예를 들면 query anaysis, self RAG, Corrective RAG)을 서치하고 있는데, 기반에 있는 논문들을 살펴 보고 있다. 그 중에서 이번 포스팅은 self-RAG와 관련된 2023년에 나온 self-RAG: learning to retrieve, generative and critique through self-refelction 이다.
Abstract
대형언어모델(LLM)은 엄청난 능력을 갖추고 있지만, 자체적으로 내장하고 있는 매개적(parametric) 지식에만 의존하기 때문에 종종 사실과 다른 부정확한 응답을 생성할 수 있다. 이러한 문제를 완화하기 위해 관련 지식을 검색하여 언어 모델을 보완하는 임시(ad hoc) 접근 방식인 검색-증강 생성(RAG, Retrieval-Augmented Generation)이 활용된다.
그러나 검색이 반드시 필요한지 여부나 검색된 문서가 관련성이 있는지에 상관 없이, 일정한 개수의 검색된 문서를 무분별하게 검색하고 포함하는 방식은 LLM의 범용성을 저하시킬 수 있고, 도움이 되지 않는 응답을 생성할 가능성이 있다.
여기서는 자가 성찰 검색-증강 생성(Self-Reflectvie Retrieval-Augmented Generation, Self-RAG) 라는 새로운 프레임워크를 제안했다. 검색과 자가 성찰(self-reflection)을 통해서 LLM의 응답 품질과 사실성을 향상시키는 방법이다.
본 프레임워크는 단일 임의의 LLM을 학습하여 필요에 따라 동적으로 문서를 검색하고, 검색된 문서 및 자체 생성된 내용을 특수 토큰(성찰 토큰, reflection tokens)을 사용해 생성한 내용을 성찰(reflect) 하도록 한다.
Self-RAG의 성찰 토큰(reflection tokens)을 생성하는 과정은 추론(inference) 단계에서 LLM의 제어 가능성을 높여, 다양한 작업 요구 사항에 맞게 모델의 동작을 조정할 수 있도록 한다.
실험 결과 self-RAG(7B 및 13B 매개변수 모델)은 다양한 작업에서 최신(state-of-the-art) LLM 및 검색-증강 모델을 크게 능가하는 성능을 보였다.
특히 Self-RAG는 오픈 도메인 질의응답(Open-domain QA), 추론(reasoning), 사실 검증(fact verification) 작업에서 ChatGPT 및 검색-증강된 Llma2-chat보다 뛰어난 성능을 보였고, 장문 생성(long-term generation)과 사시리성과 인용 정확도(critation accuracty)를 크게 향상시키는 것으로 나타났다.
1. Instruction
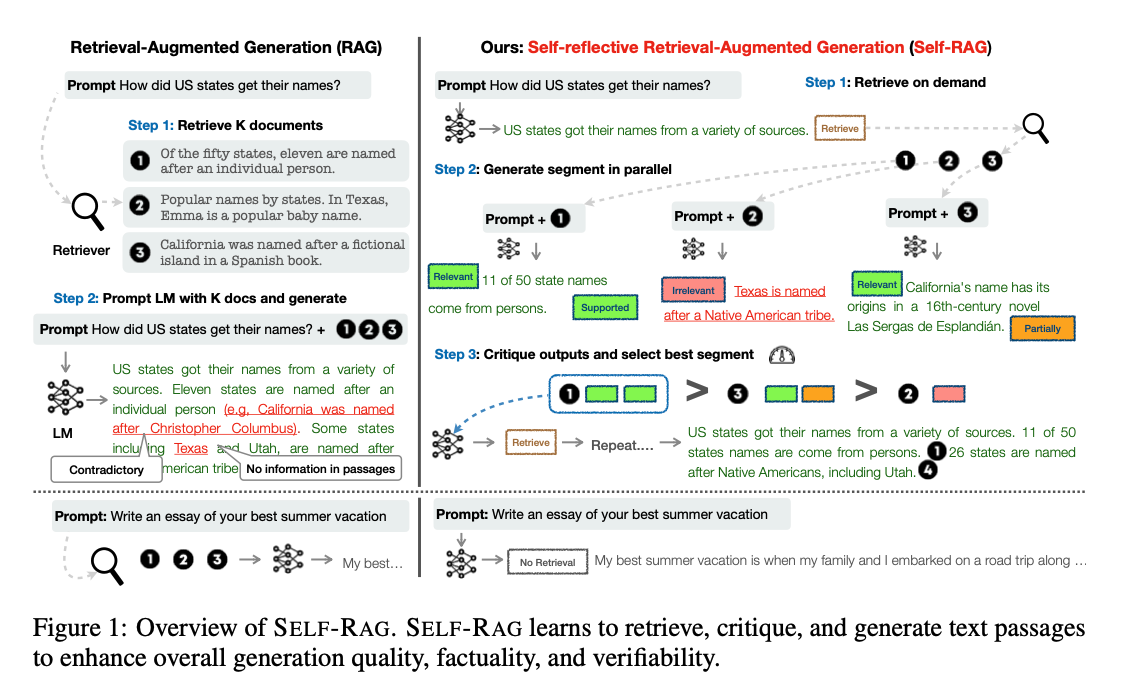
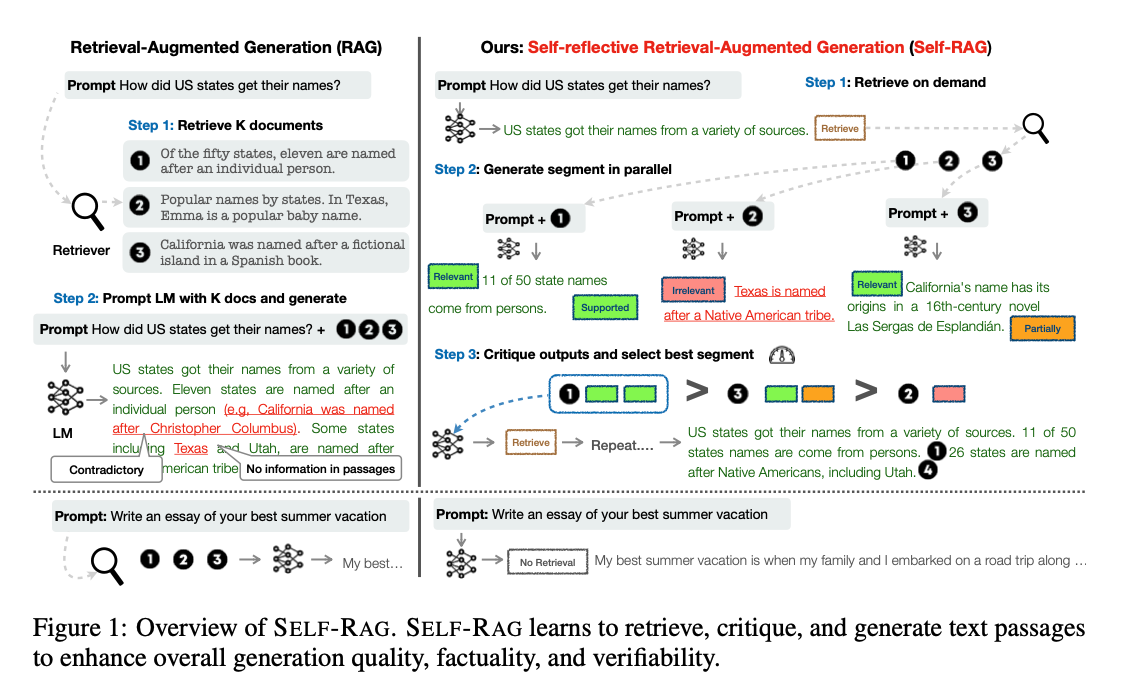
최신 대형 언어 모델은 모델의 크기와 학습 데이터 규모가 증가했지만 여전히 사실 오류(factual errors) 문제를 겪는다.
<그림 1>의 왼쪽 검색-증강 생성(RAG) 기법은 LLM의 입력에 따라 관련성이 높은 검색 문서를 추가해, 지식 집약적인 작업에서 사실 오류를 줄이는 역할을 한다.
그러나 이러한 방법은 LLM의 범용성을 저해할 수 있고, 불필요하거나 주제와 관련 없는 문서를 포함해 저품질의 출력을 생성할 수도 있다.
특히 검색된 정보가 사실적 근거(factual grounding)로서 유용한지 여부를 고려하지 않고 무분별하게 검색하는 방식이 문제이다.
또한 기존의 RAG 기법은 검색된 문서와 일관된 출력을 보장하지 못하는데, 이는 모델이 제공된 문서에서 사실을 활용하고 따르도록 명시적으로 학습되지 않았기 때문이다.
본 연구에서는 Self-Reflective Retrieval-Augmented Generation, Self-RAG를 도입해, 필요할 때만 검색을 수행하고 생성된 내용을 스스로 평가하는 방식을 통해 LLM의 생성 품질을 향상시키면서도 범용성을 유지할 수 있도록 한다.
Self RAG는 단일 LLM을 엔드 투 엔드(end-to-end) 방식으로 학습시켜, 주어진 작업 입력을 기반으로 작업 출력을 생성하는 동시에, 중간에 특수 토큰(reflection tokens, 성찰 토큰)을 생성하도록 한다. 성찰 토큰은 검색 필요 여부를 나타내는 retrieval tokens(검색 토큰)과 생성된 결과의 품질을 평가하는 critique tokens)(비판 토큰)으로 나뉜다. <그림 1>의 오른쪽
Self RAG의 동작 과정은 다음과 같다.
- 검색 필요성 판단 : 입력 프롬프트와 이전 생성 결과를 기반으로, 검색된 문서를 추가하는 것이 유용한지를 결정한다. 필요하다고 판단되면 검색 토큰을 출력하여 검색 모델을 호출한다. (step1)
- 검색 결과 및 활용 생성 : 검색된 문서를 동시에 처리하며, 해당 문서들의 관련성을 평가한 후, 이에 기반한 작업 출력을 생성한다. (step2)
- 출력 비판 및 선택 : 생성된 결과를 비판하는 비판 토큰을 생성하여, 사실성과 전체적인 품질을 평가하고 최적의 출력을 선택한다
-
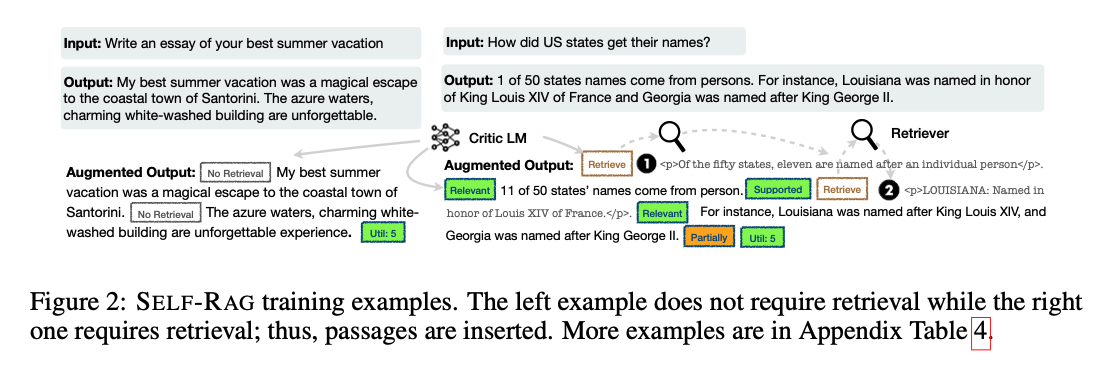
Self-RAG의 이러한 과정은 기존 RAG 방식과 차별화되는데, 기존 RAG는 검색이 필요 여부와 관계없이 고정된 개수의 문서를 항상 검색하고 활용하며, 생성된 결과의 품질을 다시 검토하지 않는다. 예를 들어, Figure 1 하단의 사례에서처럼, 특정 작업에서는 사실적 지식이 필요하지 않을 수도 있다.
self-RAG는 각 생성된 문서 조각(segment)에 대해 참조 출처를 제공하며, 출력이 검색 문서에서 뒷받침되는지 여부를 자체적으로 평가하여, 더 쉽게 사실 검증을 수행할 수 있도록 한다. -
Self-RAG는 기존 LLM이 단어 예측을 수행하는 방식과 유사하게, 성찰 토큰을 포함한 확장된 모델 어휘(vocabulary)를 학습해, 성찰 토큰을 자연스럽게 생성하도록 한다. 모델 학습 과정에서 성찰 토큰과 검색된 문서가 포함된 다양한 텍스트 데이터를 활용하여 LLM을 학습한다.
-
여기서 성찰 토큰은 강화 학습의 보상 모델(reward models) 개념에서 영감을 받아, 미리 학습된 비판 모델(critic model)이 원본 말뭉치(corpus)에 삽입하는 방식으로 생성된다. 이를 통해 학습 과정에서 별도의 비판 모델을 실시간으로 유지할 필요가 없고, 연산 부담이 줄어든다.
-
비판 모델은 부분적으로 입력, 출력, 그리고 성찰 토큰이 포함된 데이터셋을 기반으로 supervised learning 된다. 이는 OpenAI의 GPT-4(OpenAI, 2023)을 프롬프트하여 생성한 것이다. 기존 연구에서 제어 토큰(control tokens)을 활용하여 텍스트 생성을 유도하는 방식과 유사하지만 self-RAG의 LLM은 각 생성된 조각(segment) 이후 자체적으로 예측을 평가하는 비판 토큰을 활용하여 생성 품질을 향상시킨다.
-
Self-RAG는 또한 사용자 정의 가능한(customizable) 디코딩 알고리즘을 제공해, 성찰 토큰의 결과를 기반으로 강하거나(hard), 약한(soft) 제약 조건을 만족하도록 조정할 수 있다.
-
특히 추론 과정에서
(1) 검색 빈도 조정 : 다양한 다운스트림 작업에 맞춰 검색 빈도를 유연하게 조정
(2) 사용자 선호도 반영 : 성찰 토큰을 활용해 세그먼트 단위 빔 서치(segment-level beam search)를 수행해 성찰 토큰의 가중 합(weighted lenear sum)을 세그먼트 점수로 사용하여 모델의 동작을 사용자 요구에 맞출 수 있다.
-
Self-RAG에서 추론(reasoning) 및 장문 생성(long-form generation)을 포함한 6가지 작업에서 실험을 수행한 결과, 기존의 사전 학습(pre-trained) 및 지시 조정(instruction-tuned) LLM 보다 뛰어난 성능을 보였다. 더 많은 매개변수를 가진 LLM 및 널리 사용되는 RAG 방식보다 높은 인용 정확도(citation accuracy)를 기록했다. 특히 self-RAG는 검색-증강된 chatGPT와 비교했을 때 4가지 작업에서 능가했고, Llama2-chat(2023) 모델 보다 모든 작업에서 더 우수한 성능을 보였다.
-
분석 결과, Self-RAG의 성찰 토큰을 활용한 학습 및 추론 과정이 전체적인 성능 향상에 효과적이며, 테스트 시 모델을 사용자 요구에 맞게 조정ㅎ아는데 유용함을 확인했다., 예를 들어 인용 정확도와 생성 완결성 간의 trade-off를 조절할 수 있는 기능이 추가적으로 제공된다.
2. RELATED WORK
Retrieval-Augmented Generation, RAG (검색-증강 생성)
-
RAG는 언어 모델(LM)의 입력 공간을 검색된 텍스트 문서로 보강하는 방식으로, 미세 조정(fine-tuning) 하거나 사전 학습된(off-the-shelf) LMs와 함께 사용할 경우 지식 집약적인 작업에서 큰 성능 향상을 가져온다.
-
최신 연구에서는 고정된 개수의 검색 문서를 입력에 추가한 후 지시 조정(instruction-tuning) 하거나, 검색 모델과 LM을 공동 사전 학습한 후 few-shot 방식으로 작업 데이터셋에 미세 조정하는 방식을 제안한다.(Izacard et al., 2022b; Luo et al., 2023)
-
기존 연구들은 주로 한 번만 검색을 수행하는 반면, Jiang et al. (2023)은 특정한 LLM 위에서 동적으로 문서를 검색하는 방식을 제안하고, Schick et al. (2023)은 LM이 명명된 엔티티(named entities)를 위한 API 호출을 생성하도록 학습했다. 이러한 방식들은 실행 시간(runtime) 효율성 저하, 비관련 문맥에 대한 취약성, 출처 표기 부족 등의 단점을 가진다.
-
Self RAG는 임의의 LM이 필요할 때만 검색을 수행할 수 있도록 학습되며, 성찰 토큰(reflection tokens)을 활용해 검색과 생성의 품질을 개선하는 제어 가능한 생성(controlled generation) 기법을 도입해 기존 접근 방식의 한계를 극복한다.
Concurrent RAG
- 최근 몇 연구에서는 RAG 접근 방식을 개선하기 위해 새로운 학습 및 프롬프트 전략을 제안했는데, Lin et al. (2023)는 검색 모델과 LM을 지시 조정 데이터셋에서 두 단계로 미세조정하는 방법을 제안했다. self-RAG도 다양한 지시-따르기 데이터셋에서 학습되지만, 필요할 때만 검색을 수행하고, 세밀한(self-reflection 기반) 평가를 통해 최적의 출력을 선택할 수 있다는 점에서 더 넓게 적용 가능하며 제어가 가능하다.
- Yoran et al. (2023)은 자연어 추론 모델(NLI) 모델을, Xu et al. (2023)은 요약 모델을 사용해 검색된 문서를 필터링하거나 압축한 후 LM을 프롬프트하는 방식을 제안했다. 그러나 Self RAG는 추론 과정에서 외부 모델을 사용하지 않고도 검색 문서를 병렬로 처리하며, 자가 성찰을 통해 비관련 문서를 필터링한다. 또한, 모델의 출력 사실성(factuality)등 다양한 품질 측면을 평가하는 메커니즘을 제공한다.
- LATS(Zhou et al., 2023)는 사전 학습된 LM을 프롬프트하여 질문 응답 작업에서 관련 정보를 검색하고, LM이 생성한 가치 점수(value scores)를 기반으로 트리 탐색(tree search)를 수행하는 방식을 제안했다. 하지만 LATS의 가치 함수는 각 생성 결과에 대한 단일 점수를 제공하는 반면 Self-RAG는 세밀한 자가 성찰(fine-grained self-refelction)을 통해 검색 및 생성 품질을 세분화하여 평가할 수 있도록 학습된다.
Training and Generating with Critics)
- 강화 학습 기반 언어 모델 최적화(RLHF, Reinforcement Learning from Human Feedback)은 인간의 선호도에 맞춰 LLM을 정렬하는데 효과적인 방법으로 입증되었는데, Wu et al. (2023)는 다중 보상 모델(multiple reward models)을 활용한 세밀한 RLHF를 제안했다.
- Self-RAG도 검색 및 생성 결과에 대한 세밀한 비판(fine-grained critique)를 수행하지만, 비판 모델(critic model)을 활용해 생성된 성찰 토큰(reflection tokens)을 포함한 데이터셋을 학습하는 방식으로 이루어진다. 이 방식은 RLHF보다 훨씬 낮은 학습 비용으로 모델을 학습할 수 있다. RLHF가 주로 학습 과정에서 인간 선호도를 반영하는 것에 집중하는 반면, Self-RAG는 추론 과정에서 생성 결과를 제어할 수 있는 메커니즘을 제공한다.
- 다른 연구들은 LM의 생성을 유도하기 위해 일반적인
제어 토큰(control tokens)을 활요하는 방식을 사용하지만, Self-RAG는 검색 필요성 결정 및 생성 품질 자체 평가를 위해 성찰 토큰(reflection tokens)을 활용한다는 점에서 촤별화된다. - Xie et al. (2023)은 자가 평가(self-evaluation) 기반 디코딩 프레임워크를 제안햇지만, 이는 추론 작업(reasoning tasks)에서 논리적 일관성(reasoning path consistency)만을 평가할 뿐, 검색을 활용하거나 다양한 품질 측면을 평가하지 않는다.
- 최근 LLM 개선 연구들은 모델이 초기 출력을 생성한 후 자연어 피드백을 반영하여 다시 출력을 생성하는 방식을 채택하고 있다.
이러한 방식은 추론 효율성(inference efficiency) 저하라는 문제를 가진다.
Self-RAG는 이러한 반복적 평가 과정을 성찰 토큰을 통해 모델 자체가 수행하도록 하여, 성능을 유지하면서도 효율성을 높일 수 있다.
3. Self-RAG : Learning To Retrieve, Generate and Critique
Self-RAG는 검색과 self-reflection을 통해 LLM의 생성 품질과 사실성(factuality)를 향상시키는 프레임워크이다.
기존 창의성과 범용성을 유지하면서도 검색된 정보를 필요로할 때만 활용하고, 생성된 출력을 자체적으로 평가하는 메커니즘을 갖춘 것이 특징이다.
self-RAG의 학습 과정에서는 LLM이 필요에 따라 검색된 문서를 활용하여 텍스트를 생성하고, 자체적으로 생성 품질을 평가하도록 특수 토큰(reflection tokens)을 학습한다. 이러한 reflection tokens은 검색 필요성을 결정하거나, 생성된 출력을 관련성/신뢰성/완전성 측면에서 평가하는 역할을 한다. 일반적인 RAG 방식이 검색된 문서의 출처를 무조건적으로 활용하는 것과는 달리, Self-RAG는 검색된 정보의 신뢰성을 평가하고 불완전한 정보를 보완하는 구조를 가진다.
3.1 Problem Formalization and overview(문제 정의 및 개요)
입력 x 가 주어졌을 때, 모델 M은 여러 개의 출력 세그먼트로 구성된 텍스트 출력 y=[y1, ..., yT]를 순차적으로 생성하도록 학습된다. 여기서 각 세그먼트 yt는 일반적인 텍스트 토큰과 함께 성찰 토큰(reflection tokens)를 포함할 수 있다. (Table 1 참고)
- Retrieve (검색 여부 결정)
- IsREL (관련성 판단)
- IsSUP (지원 수준 판단)
- IsUSE (유용성 판단)

-
Retrieve
- Input : x 또는 (x,y)로 입력 질문 또는 입력 질문과 이전 생성 텍스트
- Output : {yes, no, continue} - 검색 필요 여부 또는 이전 검색 결과 계속 사용
- Definition : 모델이 R(검색기)를 사용해 외부 정보를 검색할지 여부를 결정 -
IsREL
- Input : x, d로 입력 질문과 검색된 문서
- Output : {relevant, irrelevant} - 문서 관련성 판단
- Definition : 검색된 문서 d가 질문 x를 해결하는데 유용한 정보를 제공하는지 판단
-
IsSUP
- Input : x,d,y - 입력 질문, 검색된 문서, 생성된 답변
- Output : {fully supported, partially supported, no support} - 답변 문서의 지원 수준
- Definition : 생성된 답변 y의 검증 가능한 내용이 문서 d에 의해 얼마나 지원되는지 평가 -
IsUSE
- Input : x,y - 입력 질문과 생성된 답변
- Output : {5,4,3,2,1} - 5점 척도의 유용성 저뭇
- Definition : 생성된 답변 y가 질문 x에 대해 얼마나 유용한지 평가
[표 1] : Self-RAG에 사용된 네 가지 유형의 reflection tokens. 각 유형은 출력 값을 나타내기 위해 여러 토큰을 사용한다. 하단 세 줄은 세 가지 유형의 critique 토큰이며, 굵은 텍스트는 가장 바람직한 critique 토큰을 나타낸다. x,y,d는 각각 입력, 출력 및 관련 구절이다.

- Self-RAG 추론 알고리즘을 위해 필요한 것들은 ① 텍스트를 생성하는 언어모델 M, ② 관련 문서를 찾는 검색 엔진인 검색기 R , ③ 위키피디아 같은 지식 저장소인 대규모 문서 모음 {d1, ... dN}이다.
- 입력과 출력 형식은 Input은 사용자 질문 x와 지금까지 생성한 텍스트 y_(<t)이고 Output은 다음 문장 세그먼트 y_t 이다.
단계별 작동방식을 살펴보자면,
-
step1. 검색 필요성을 판단한다.
- 모델 M이 (x, y_(<t)를 보고 "Retrieve" 토큰을 예측함
: 정보 검색이 필요한가요? 라고 스스로에게 묻는 것과 같다. -
step2. 만약 Retreive==Yes(검색 필요) 라면,
- R을 사용해 관련 문서들 D를 검색한다. (이전 문장 y_(t-1)을 검색 쿼리로 사용한다.
- 각 문서에 대해 관련성을 판단하는데, 모델 M이 각 문서 d에 대해 "이 문서가 질문과 관련 있나요?(ISREL)" 을 예측해 모델 M이 각 문서 d를 사용해 다음 문장 y_t를 생성한다.
- 생성된 문장을 평가하기 위해 모델 M이 각 문서 d와 생성된 문장 y_t에 대해 "이 문장이 문서에 의해 뒷받침되나요?(IsSUP)"과 "이 문장이 유용한가요?(IsUSE)"를 예측한다.
- IsREL, IsSUP, IsUSE 점수를 기반으로 생성된 문장들 중 최고의 문장을 선택한다. -
step3. 만약 Retreive==No(검색 불필요) 라면,
- 모델 M이 직접 다음 문장 yt를 생성하고, 생성된 문장에 대해 모델 M가 자체적으로 "이 문장이 유용한가요?(IsUSE)"를 예측한다.

이 알고리즘의 핵심은 모델이 스스로 검색이 필요한지 판단하고 필요하다면 여러 문서를 검토해 가장 관련성이 높고 신뢰할 수 있는 정보를 기반으로 답변을 생성한다는 점이다. 검색이 불필요한 질문 (예: 창의적 작문)에 대해서는 모델이 자체 지식을 사용해 직접 답변을 생성한다.
[Algorithm 1: Self RAG 추론]
Inference overveiw : 그림 1, Algorithm 1은 Self-RAG의 추론 과정을 개괄적으로 보여준다.
(1) 검색 필요성 평가
- 입력 x와 이전까지 생성된 텍스트 y_(<t)를 바타응로, 모델이 검색이 필요한지 여부를 판단하는 검색 토큰(retrieval tokens)을 생성한다.
- 검색이 필요하지 않은 경우, 일반적인 LLM과 동일하게 다음 출력을 생성한다.
- 검색이 필요한 경우, 모델은 검색된 문서의 적절성을 평가하는 비판 토큰(critique token)을 생성한다.
(2) 검색된 문서 평가 및 출력 생성
- 검색된 문서가 제공되면 모델은 ① 검색된 문서의 관련성을 평가하는 비판 토큰을 생성하고, ② 다음 출력 세그먼트를 생성하며, ③ 해당 출력이 검색된 문서에 의해 뒷받침되는지를 평가하는 비판 토큰을 생성한다.
(3) 전체 출력 평가
- 최종적으로 모델은 전체 출력의 품질과 유용성을 평가하는 비판 토큰을 추가로 생성한다.
Self-RAG는 여러 개의 검색된 문서를 병렬로 처리하면서, 성찰 토큰을 활용해 부드러운 제약(soft constraints) 또는 강력한 제어(hard control)을 적용하여 최종 출력을 생성한다. (섹션 3.3 참고)

예를 들어 <그림 1>의 오른쪽에서 검색된 문서 중 d1이 첫 번째 단계에서 선택된다. 이는 d2가 직접적인 증거를 제공하지 않음(ISREL = Irrelevant), d3의 내용이 부분적으로만 지원됨, d1은 완전히 지원(fully supported) 와 같은 이유이다.
Training overveiw
Self-RAG는 임의의 LLM이 성찰 토큰을 활용한 출력을 생성하도록 학습하는 방식을 채택한다. 이를 위해 기존 어휘(vocabulary)에 성찰 토큰을 추가한 확장 어휘를 사용해 다음 토큰을 예측하는 방식으로 모델을 학습한다.
(1) 학습 데이터 구축
- 사전에 구축된 데이터셋을 기반으로, 검색 모델 R을 사용하여 검색된 문서를 추가한다.
- 비판 모델(critic model) C를 활용해 검색된 문서 및 생성된 출력의 품질을 평가하는 성찰 토큰을 삽입한다. (Appendic Algorithm 2 참고)
(2) 비판 모델 학습(C)
- 모델 C는 검색된 문서의 적절성과 출력 품질을 평가하는 성찰 토큰을 생성하도록 학습된다.(Section 3.2.1 참고.)
- 비판 모델을 활용해 성찰 토큰이 포함된 학습 데이터를 사전에 생성한다(offline augmentation)
(3) 생성 모델 학습(M)
- 최종적으로 LLM M을 기존 LM 학습 목표를 기반으로 학습한다.
- 학습이 완료되면 모델 M은 추론 과정에서 비판 모델 없이도 성찰 토큰을 생성할 수 있다.
이와 같은 Self-RAG의 학습 및 추론 방식이 기존 RAG와 비교시 검색 효율성을 높이고 생성 품질을 향상시키면서도 모델의 창의성과 범용성을 유지할 수 있도록 설계되었다.
3.2 Self-RAG Training
self-RAG의 학습 과정은 두 개의 모델을 학습하는 방식으로 이뤄진다.
(1) 비판 모델(critic model, C) 학습
(2) 생성 모델(generator model, M) 학습
3.2.1 Training the critic model
비판 모델 C를 학습하기 위해서는 각 출력 세그먼트에 대한 성찰 토큰(reflection tokens)를 라벨링한 데이터가 필요하다. 하지만 수작업으로 모든 세그먼트에 성찰 토큰을 직접 추가하는 것은 매우 비용이 많이 드는 작업이다.
이를 해결하기 위해 최신 LLM(gpt-4)을 활용해 자동으로 성찰 토큰을 생성하는 방법이 효과적일 수 있다. 하지만 이러한 proprietary LMs에 의존할 경우 API 비용이 증가하고 재현성이 낮아지는 문제가 있다.
따라서 GPT-4에 활용해 성찰 토큰이 포함된 데이터를 생성한 뒤, 이 데이터를 내부 비판 모델(critic model) C에 증류(distillation) 하는 방식으로 학습 데이터를 구축했다.
데이터 샘플링 및 생성 과정(Data collection for critic model
[1] 원본 학습 데이터에서 샘플링
- 학습 데이터셋 {X,Y} 에서 무작위로 샘플링된 샘플 {X_sample, Y_sample}을 선택
[2] GPT-4를 활용한 reflection tokens 생성
- 각 reflection tokens 유형(예: 검색 필요성, 관련성, 신뢰성) 등은 서로 다른 정의와 입력값을 가짐(table 1참고)
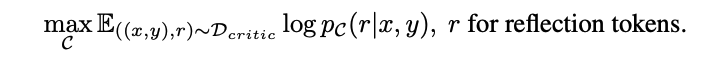
- 따라서 각 유형에 맞은 프롬프트를 작성하여 GPT-4에 입력
- 예를 들어 REtrieve(검색 필요 여부 평가) 토큰의 경우 다음과 같은 프롬프트 사용.
"Given an instruction, make a judgment on whether finding some external documents from the web helps to generate a better response." ("지침이 제공되면 웹에서 일부 외부 문서를 찾는 것이 더 나은 응답을 생성하는 데 도움이 되는지 판단하십시오.")
- 이후 few-shot 예제 (입력 x, 출력 y)를 제공해서 적절한 reflection tokens p(r|I,x,y)를 예측하도록 함
[3] GPT-4 reflction tokens와 human evaluations 비교
- 수작업으로 평가한 결과 GPT-4가 생성한 reflection tokens은 인간 평가와 높은 일치도를 보임
- 최종적으로 각 reflection tokens 유형 별로 4k~20k개의 지도학습 데이터를 수집하여 C 학습 데이터셋을 구축
(자세한 프롬프트 목록은 Appendix Section D, 추가 분석은 Appendix A.1 참고)
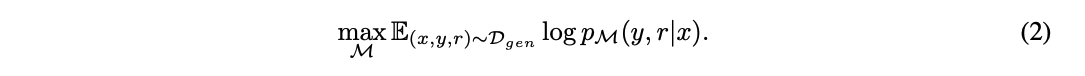
비판 모델 학습 과정(Critic learning)
비판 모델 C를 학습하기 위해, 수집된 학습 데이터셋 D_(critic)를 활용한다.
[1] 모델 초기화
- 사전 학습된 LLM을 사용해 C를 초기화한다.
- 생성 모델 M과 동일한 모델(Llama 2-7B)을 C의 초기 모델로 사용하여 일관성을 유지한다.
[2] 지도 학습
- 조건부 언어 모델링(Objective: Conditional Language Modeling) 방식으로 C를 학습한다.
- 주어진 입력 (x,y)에 대해 reflection tokens (r)의 로그 가능도(log-likelihood)를 최대화하는 방식으로 학습한다.
[3] 학습 성능 평가
- 학습된 C 모델은 90% 이상의 정확도를 달성하였다.
이를 통해 self-RAG의 critic model C는 검색된 문서의 관련성 평가, 생성된 출력의 신뢰성 검증 등 다양한 reflection tokens을 생성할 수 있는 능력을 갖추게 된다.
3.2.2 Training the Generator Model
Data collection for Generator(생성 모델 학습 데이터 구축)
- Self-RAG 생성 모델 M은 기존의 입력-출력 (x,y)를 기반으로, 검색(retrieval) 및 비판(critique) 모델의 출력을 반영해서 학습 데이터셋을 증강(augmentation)한다.
[데이터의 증강 과정]
[1] 각 출력 세그먼트 y_t에 대해 비판 모델 C를 실행
- C는 추가적인 검색의 필요 여부를 평가한다.
- 검색이 필요하면, 특수 토큰
Retrieve=Yes를 추가하고, 검색 모델 R이 상위 K개의 문서 D를 검색한다.
[2] 검색된 문서 D에 대한 비판 모델 C 평가 수행
- 검색된 각 문서에 대해, C는 문서가 관련 있는지 평가하고
IsREL토큰을 예측한다. - 관련성이 있다고 판단되면, 해당 문서가 모델의 생성 결과를 뒷받침하는지 평가하고
IsSUP토큰을 예측한다.
[3] reflection tokens 추가
IsREL,IsSUP토큰을 검색된 문서 또는 생성된 텍스트 뒤에 추가한다.- 출력 y( 또는 마지막 세그먼트 y_T)에 대해, 전체 응답의 유용성을 평가하는
IsUSE토큰을 예측한다. - 이를 통해 reflection tokens이 포함된 증강된 출력 데이터를 구축하고, 최종적으로 이를 학습 데이터셋 D_gen에 추가한다.
Generator Learning(생성 모델 학습 과정)
생성 모델 M은 reflection tokens이 추가된 학습 데이터셋 D_gen을 활용하여 학습된다. 기본적인 학습 목표는 기존의 텍스트 생성을 수행하면서도 reflection tokens를 예측하는 것이다.
[1] 학습 목표(Objectvie Function)
- 기존의 다음 토큰 예측(Next Token Prediction) 방식을 그대로 유지하면서, 추가적으로 reflection tokens도 함께 예측할 수 있도록 확장된 언어 모델링 목표를 설정한다.
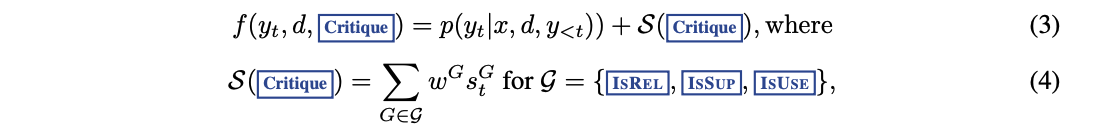
- 즉, 모델 M은 입력 x에 대해 출력 y와 reflection tokens (r)을 함께 예측하도록 학습된다.
[2] 학습 중 특수 처리
- 검색된 텍스트는 손실(loss) 계산에서 제외(masking) 처리
- 검색된 문서는
<p> ... </p>태그로 감싸고, 이 부분은 학습 중 손실 계산에서 제외한다. <그림 2> 참고
- 모델 어휘 V 확장(기존 어휘 V에 새로운 reflection tokens
{Critique, Retrieve}를 추가해, 모델이 이를 학습할 수 있도록 한다.
이 과정을 통해서 self-RAG 생성 모델 M은 검색이 필요한지 스스로 판단하고, 검색도니 정보가 응답을 뒷받침하는지 평가하며, 최종적으로 신뢰성 높은 응답을 생성할 수 있도록 학습된다.
Connections to prior work on learning with critique(기존 연구와의 연결, critique를 활용한 학습)
-
기존 RLHF 방식은
Proximal Policy Optimization(PPO)를 활용하여 보상 모델(reward model)을 통해 학습한다.하지만 self-RAG는 PPO를 사용하지 않고 비판(critique) 정보를 오프라인에서 사전 계산하여 학습 데이터에 직접 삽입한다. 이를 통해 생성 모델(LM)이 표준 LM 학습 목표를 유지하면서도 critique를 학습할 수 있도록 한다. 결과적으로 PPO 대비 학습 비용이 크게 절감된다.
-
Sepcial Tokens for Controlled Generation (생성 제어를 위한 특수 토큰)과의 관련성에서는, 이전의 연구에서 특수 토큰을 활용해서 생성 모델의 출력을 조절하는 연구가 있었다.
Self-RAG 역시 특수 토큰을 학습해서 각 생성 세그먼트의 신뢰성을 스스로 평가하도록 하고, 이를 통해 soft re-ranking 또는 hard constraints를 적용하는 방식으로 모델 출력을 조정 가능하다.
-
이처럼 Self-RAG는 기존 RLHF와 비교해 학습 비용을 낮추면서도 critique를 활용하는 방식을 발전시켰으며, 기존의 생성 제어 연구를 확장하여, 모델이 스스로 평가를 수행할 수 있도록 설계된 점에서 차별성을 갖는다.
3.3 Self-RAG Inference
self-RAG는 자체 평가를 위한 Reflection Token을 생성해, 다양한 태스크 요구사항에 맞춰 동작을 조절할 수 있다.
- 사실적 정확성이 중요한 태스크 : 문서 검색을 더 자주 수행하여 근거 기반 출력을 강화
- 창의성이 중요한 태스크 : 검색을 줄이고 창의적 출력을 우선함
Adaptive retrieval with threshold
- 모델이 Retrieve 토큰을 생성하여 필요할 때만 검색을 수행
- 특정 임계값(threshold)을 설정해 검색 빈도를 조정할 수 있음
-Retrieve = Yes의 확률이 특정 기준을 초과하면 검색을 수행- 예시 : 정확성이 중요한 태스크에서는 낮은 임곗값을 설정해 검색을 더 자주 수행하도록 조정 가능
Tree-decoding with critique tokens
- 트리 디코딩 + Critique 토큰을 활용해 각 생성 단계에서 모델이 자체 평가를 수행해 최적의 출력을 선택하는 방식
[1] 검색 및 병렬 후보 생성
- 검색이 필요한 경우, K개의 문서를 검색한 후, 모델이 각 문서를 기반으로 K개의 후속 출력 후보를 생성한다. Segment-Level Beam Search 적용해 각 타임스텝(t)마다 최상의 B개 출력 유지한다.
[2] Critique Score를 활용한 최적 출력 선택
-
Critique Score를 통해 각 출력 후보(yt)를 평가하고 가장 높은 점수를 가진 출력을 선택한다.
-
Critique Score를 활용한 최적 출력을 선택한다.
Critique Score를 통해 각 출력 후보(yt)를 평가하고, 가장 높은 점수를 가진 출력을 선택하기 위해 세 가지 평가 항목(G)을 가중 평균한 값은 Critique Score 이다.IsREL (관련성): 검색된 문서와 출력이 얼마나 관련있는지IsSUB (근거 제공 여부): 검색된 문서가 생성된 출력을 뒷받침하는지IsUSE (출력의 전체적인 유용성: 최종적으로 유용한 답변인지
- 각 평가 항목의 가중치(wG)를 조정하여, 특정 기준을 더 강조할 수 있다. 예를 들어 사실 검증이 주용한 경우
IsSUP가중치를 높이고, 반대로 차의성이 중요한 경우IsUSE가중치를 올리고IsSUP을 낮출 수 있다.
[3] hard Constraint
- 소프트 평가 대신, 원하지 않는 Critique Token을 포함하는 출력을 강제 배제할 수도 있다. 예를 들어
IsSUP = No Support인 경우 해당 출력을 제거하여, 검색 근거가 있는 답변만 생성한다.
-> Self RAG는 RLHF처럼 모델 자체를 재학습할 필요 없이 하이퍼파라미터만 조정하여 동작을 변경하는데, 기존 RLHF 연구에서 다루던 여러 기준 간 균형 조절을 추가 학습없이 수행할 수 있다. 즉 추론 과정에서만 Critique Token을 활용해 검색, 평가, 출력을 동적으로 조정하는 시스템으로 기존 RAG 방식보다 더 효율적이고 유연한 제어가 가능하도록 설계되었다.
4. EXPERIMENTS, 5. RESULTS AND ANALYSIS
실험에 대한 결과라 요약으로 갈음
<실험 설계>
self-RAG 논문에서는 다양한 태스크에서 모델의 성능을 평가했다.
<평가 태스크>
- 닫힌 집합 태스크: 공중 보건 관련 사실 검증(PubHealth), 과학 시험 기반 - 추론(ARC-Challenge)
짧은 형태 생성 태스크: 오픈 도메인 QA(PopQA, TriviaQA-unfiltered)
긴 형태 생성 태스크: 전기문 생성, 장문형 QA(ALCE-ASQA)
<베이스라인>
- 검색 없는 모델: Llama2(7B, 13B), Alpaca(7B, 13B), ChatGPT, Llama2-chat13B
- 검색 있는 모델: 기존 RAG 방식으로 증강된 모델들, 그리고 비공개 데이터로 훈련된 모델(ChatGPT, Llama2-chat)
<구현 세부사항>
- 데이터: 다양한 지시 따르기 데이터셋에서 150k 쌍 사용
- 기본 모델: Llama2 7B 및 13B
- 검색기: Contriever-MS MARCO
- 추론 설정: ISREL, ISSUP, ISUSE 가중치를 각각 1.0, 1.0, 0.5로 설정
<주요 결과>
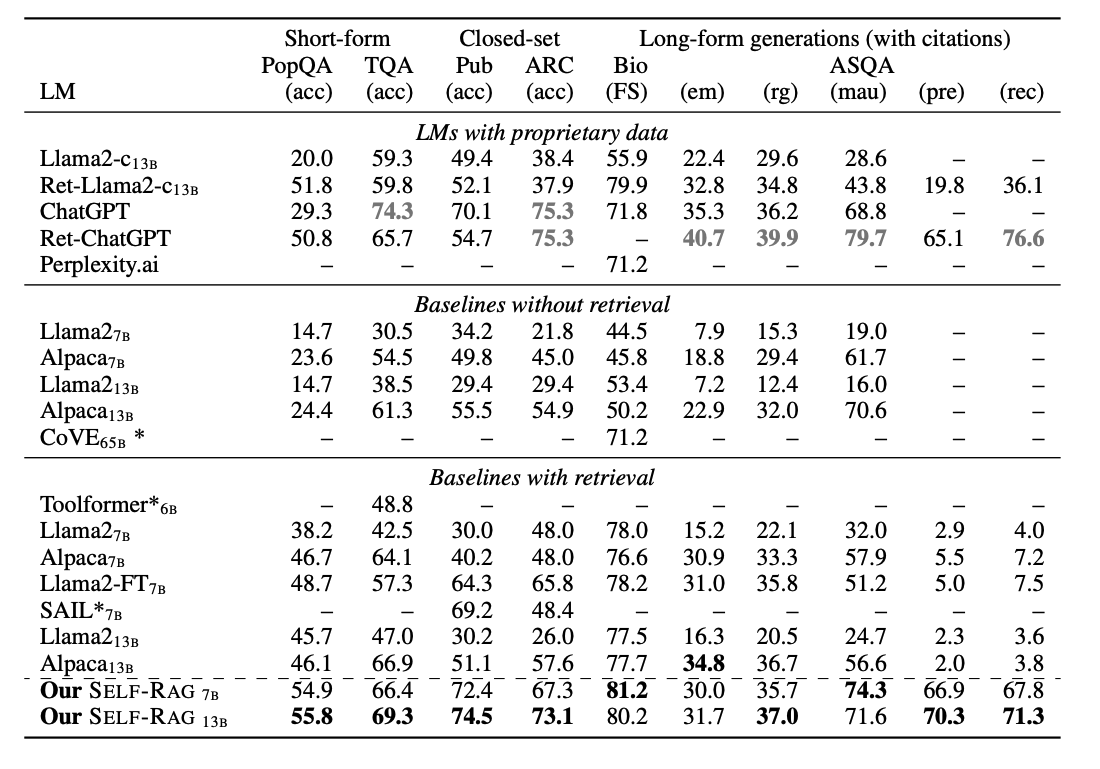
- 전반적 성능 비교: self-RAG(7B, 13B)는 비공개 데이터로 훈련된 모델을 포함한 대부분의 베이스라인을 능가. 특히 PubHealth, PopQA, 전기문 생성, ASQA에서 ChatGPT보다 우수한 성능 달성. ASQA에서 인용 정확도 측면에서 뛰어난 성능 보임 (70.3% 정밀도, 71.3% 재현율)
- 검색 없는 모델과 비교: self-RAG는 모든 태스크에서 검색 없는 모델들을 크게 상회. 특히 CoVE와 같은 정교한 프롬프트 기법을 사용하는 모델보다도 우수한 성능
- 검색 있는 모델과 비교: 비공개 모델이 아닌 모델 중에서 모든 태스크에서 최고 성능 기록. 특히 PubHealth, ARC-Challenge와 같이 단순히 검색된 텍스트를 복사하는 것만으로는 해결하기 어려운 태스크에서 기존 RAG 접근법보다 큰 개선 보임. ASQA에서 인용 정확도가 다른 모델들보다 현저히 높음
<분석 결과>
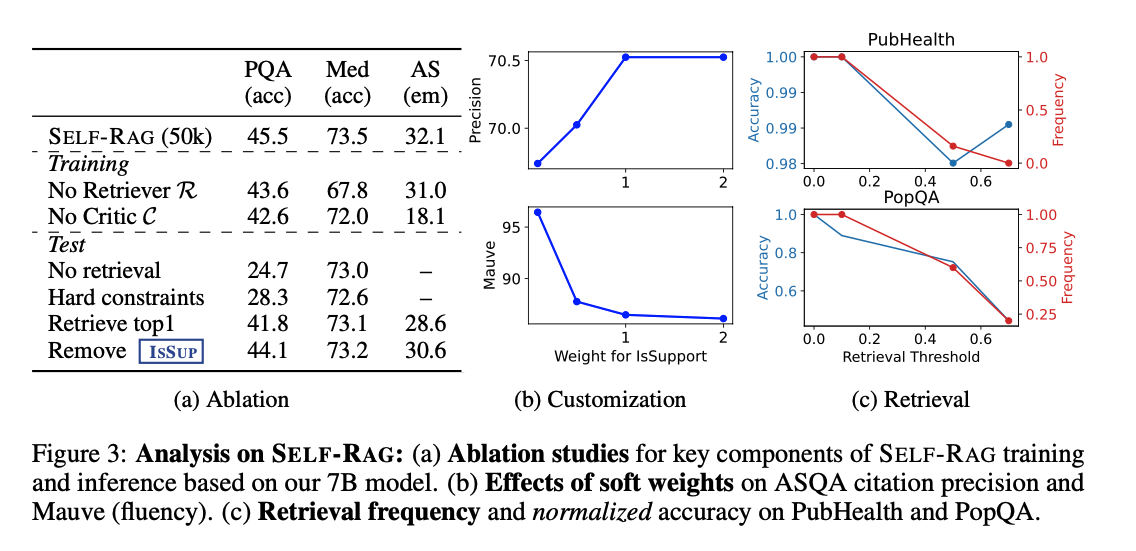
- 요소별 중요도(Ablation Studies): 검색기, 비평기, 추론 알고리즘의 각 구성 요소가 모두 성능에 중요한 기여. 비평기 없이 항상 상위 1개 문서만 검색하는 방식은 PopQA와 ASQA에서 큰 성능 저하 보임
- 추론 시 커스터마이징 효과:
IsSUP가중치 증가 시 인용 정확도 향상되나 유창성(MAUVE) 감소. 이는 사실 검증과 유창성 사이의 균형을 조절 가능함을 보여줌 - 적응형 검색의 효율성: 검색 임계값 조정으로 검색 빈도와 정확도 사이 균형 조절 가능. PopQA는 검색 감소 시 성능이 크게 떨어지나, PubHealth는 상대적으로 적은 영향
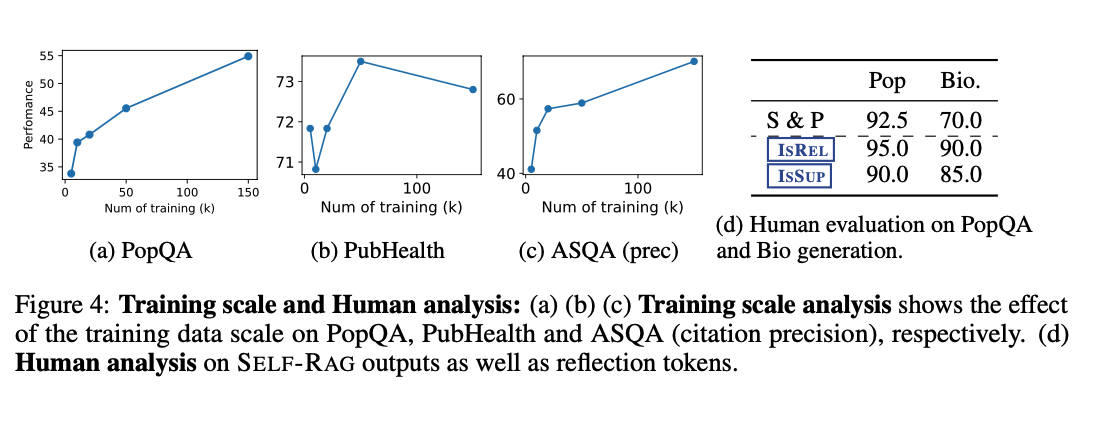
- 훈련 데이터 규모의 영향: 훈련 데이터 증가에 따라 성능 향상, 특히 PopQA와 ASQA에서 두드러짐. 훈련 데이터를 더 확장하면 추가 성능 향상 가능성 시사
- 인간 평가: SELF-RAG 출력은 지원 및 타당성(S&P) 평가에서 높은 점수 획득 모델이 예측한 반영 토큰(
IsREL,IsSUP)이 인간 평가와 높은 일치도 보임 - 파라메트릭 vs 비파라메트릭 지식: self-RAG는 검색된 증거에 더 의존하는 경향, 다른 모델들은 자체 파라메트릭 지식에 의존. 이는 self-RAG가 더 검증 가능한 응답 생성에 유리함을 시사
6. Conclusion
-
이 연구에서는 self-RAG라는 새로운 프레임워크를 소개하며, 이를 통해 LLM의 품질과 사실성을 향상시키는 방법을 제안했다.
-
self-RAG는 다음과 같은 특징을 가진다:
- 필요할 때만 검색을 수행하는 "온디맨드 검색 (Retrieval on Demand)"
- 모델이 스스로 생성한 출력을 비판적으로 평가하는 "자기 반성 (Self-Reflection)"
- 새로운 "Reflection Token"을 활용하여, 기존 LM 동작을 확장
-
self-RAG는 6가지 태스크에서 다중 평가 지표를 활용한 실험을 통해 기존 RAG 방식이나 더 큰 파라미터를 가진 LLM보다 우수한 성능을 보였다.
