본 게시물은 개인적으로 공부하기 위해서 참조한 사이트에서 필요한 부분만 '쏘옥' ? 가져왔다기보다는 몽땅 가져왔다는 게 맞겠습니다.
자세한 정보는 아래 참조사이트에서 참고해주세요.
Electra Model
[서론]
-
kcElectra를 활용해서, Text Classification Model을 fine-tuning해서 릴리즈 하였으나, 정확하게 Electra가 돌아가는 마당을 이해하지는 않은 것 같아서, 이참에 관련 자료를 수집하고 이해할 필요가 있어서 정리하게 되었다.
-
구글 리서치팀에서 새로운 pre-training 기법을 적용한 language model인 Efficiently Learning an Encoder that Classifier Token Replacements Accurately (이하 ELECTRA)
-
기존의 Language model 들은 input을 mask token으로 치환하고, 치환 전의 원본 token 으로 복원하는 MLM (Masked Language Modeling)을 통해 pre-training 했다. 그러나, 이러한 모델들은 학습 시에 상당히 많은 계산량을 필요로 하여 충분한 컴퓨팅 리소스가 없는 연구자들은 language model의 pre-training을 연구하기 어려워지고 있다.
-
하여, ELECTRA는 모델의 정확도와 함께 '효율성'에 주목하여, RTD(Replaced Token Detection) 이라는 새로운 pre-training 태스크를 제안하여 보다 빠르고 효과적으로 학습한다.
-
ELECTRA는 모델의 크기, 데이터, 컴퓨팅 리소스가 동일한 조건에서 기존의 'BERT'의 성능을 능가했고, Small 모델에서 두드러졌다. (하나의 GPU로 4일만 학습한 모델로 계산량이 30배인 GPT를 능가)
-
Large 모델에서도 RoBERTa나 XLNet 대비 1/4 계산량으로 비슷한 성능에 도달했다.
(1) Electra Introduction
- 현재 SOTA(State-of-the-Art) representation learning 기법은 일종의 denosing autoencoder 학습이다.
** Denosing Auto-Encoder(dA)
=> Data에 Noise가 추가되었을 때, 이러한 Noise를 제거하여 원래의 데이터를 Extraction 하는 모델
-
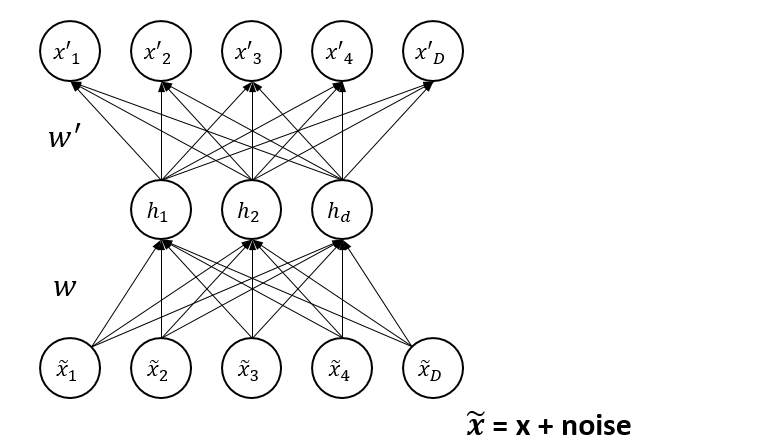
-
주로 input sequence token 중 약 15%를 마스킹하고, 복원하는 MLM 태스크를 통해서 학습을 하는데, MLM은 기존의 autoregressive language modeling 학습에 비해 양방향 정보를 고려해서 효과적인 학습을 할 수 있지만 전체 토큰 중 15%에서만 loss가 발생함. 즉, 하나의 example에서 고작 15%만 학습. 그래서 비용이 많이 듦. 학습 때 [mask] token을 모델이 참고하여 예측하지만 실제 inference로는 [mask] token이 존재하지 않음 의 단점이 있다.
-
이를 위해 RTD(Replaced Token Detection) 이라는 새로운 pre-training task를 제안했다.
-
RTD는 generator를 이용해 실제 input의 일부 token을 가짜 token으로 바꾸고 각 토큰이 실제 입력에 있는 진짜(origin) token 인지, generator가 생성한 가짜(replaced) token인지를 discriminator 가 맞히는 이진 분류 문제이다.
-
Electra는 RTD take로 입력의 15%가 아닌 모든 token에 학습하기 때문에 효율적이면서 효과적이다. ( downstream task 에서 성능도 더 좋음)
**downstream task :
=> 구체적으로 풀고 싶은 문제,
자연어처리 분야에서는 언어 모델을 pre-trained 방식을 이용해 학습을 진행하고 원하는 태스크를 fine-tuning 방식을 통해 모델을 업데이트 하는데, 이 때의 태스크를 downstream task 라고 한다.
예) BERT의 언어모델을 QA task로 학습함 (QA task가 downstream task)
- 즉, Electra는 RTD 태스크를 통해 기존의 representation learning 기법보다 더욱 효율적으로 학습했다고 볼 수 있다.
(2) Electra Method
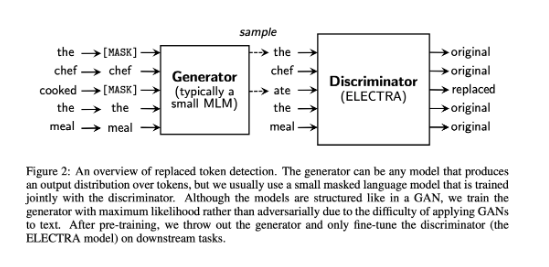
- RTD 태스크를 통해 학습하기 위해서는
GeneratorG와DiscriminatorD 두개의 네트워크가 필요하다. - 두 네트워크는 공통적으로 transformer의 encoder 구조이며,
input 데이터를 token sequence x= [x1, x2, ... xn] 으로 변환한 후,
문백 정보를 반영한 위치 vector seqence h(x) = [h1, h2, .. hn] 으로 매핑한다.
Generator G
-
Generator G는 BERT의 MLM과 학습 매커니즘이 유사하다.
[1] input token seqenme x = [x1, x2, ... xn]에 대해 마스킹할 위치의 집합 m=[m1, m2, ..mk]를 결정한다.
모든 마스킹의 위치는 1과 n 사이의 정수이다.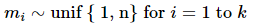
- masking 할 개수 k는 보통 전체 토큰의 15% (0.15n 사용)
[2] 결정한 위치에 있는 input token을 [MASK]로 치환한다.
[3] 마스킹된 입력 x(masked)에 대해서 generator는 원래 토큰이 무엇인지 예측함
<t번째 토큰에 대한 예측>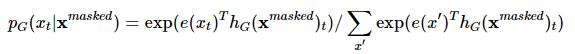
- 위의 e(.)는 임베딩을 의미하며, language model의 출력 레이어와 임베딩 레이어의 가중치를 공유(weight sharing) 하겠다는 것을 의미함
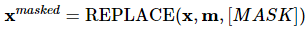
[4] 최종적으로 아래와 같은 MLM loss로 학습함
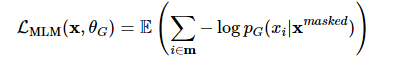
Discriminator D
-
Discriminator D는 input token sequence에 대해 각 token이 origin 인지 replaced 인지 이진 분류로 학습한다.
[1] Generator G를 이용해 마스킹 된 입력 토큰을 예측함 (Generator G에서의 [1]~[3] 단계)
[2] Generator G에서 마스킹할 위치의 집합 m에 해당하는 위치의 토큰을 [MASK]가 아닌 generator의 softmax 분포 pG(xt|X)에 대해 샘플링한 토큰으로 치환(corrupt) 한다.
-
Original input : [the, chef, cooked, the, meal]
-
input for generator : [[MASK], chek, [MASK], the, meal]
-
input for discrimiator : [the, chef, ate, the ,meal]
: 첫 번째 단어는 샘플링 했을 때, 원래 입력 토큰과 동일한 'the' 가 나온 것
: 두 번째 단어를 샘플링 했을 때, 원래 입력 토큰인 'cook' 이 아닌 'ate'가 나온것
: 이 치환과정의 수식은 아래와 같다.
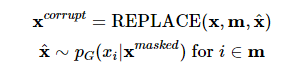
[3] 치한된 입력 x^corrupt에 대해서 discriminator는 아래와 같이 token이 원래 입력과 동일한지, 치환된 것인지 예측한다.
- Target classes ( binary classification )
: original : 해당 위치의 토큰은 원본 문장의 token과 같음
: replaced : 해당 위치의 토큰은 generator G에 의해 변형된 것 - t번째 token에 대한 예측은
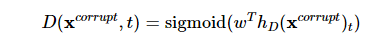
[4] 최종적으로 아래와 같은 loss로 학습
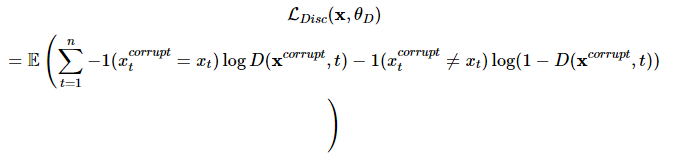
-
GAN 과의 차이점
-
Generator가 원래 token과 동일한 token을 생성했을 때, GAN은 negative sample(fask)로 간주하지만 ELECTRA는 positive sample로 간주한다.
-
Generator가 discriminator을 속이기 위해 adversarial 하게 학습하ㅣ는 것이 아니고, maximum likelihood로 학습한다.
- Generator에서 샘플하는 과정 때문에 역전파가 불가능하고, 따라서 adversarial 하게 generator를 학습하는 것이 어려움- 강화학습으로 구현해봤지만, maximum likelihood로 학습 시킬때보다 성능이 좋지 않았음
-
Generator의 입력으로 노이즈 벡터를 넣어주지 않는다.
-
최종적으로 ELECTRA는 대용량 코퍼스 X에 대해서 generator loss와 discriminator loss의 합을 최소화하도록 학습함
-
이때 λ는 50을 사용하고, 파라미터는 이진 분류는 discriminator loss와 30000 클래스 분류인 generator loss의 스케일을 맞추는 역할을 함
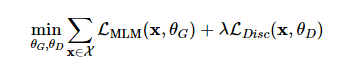
-
샘플링 과정이 있어서 discriminator loss는 generator로 역전파 되지 않으며,
위의 구조로 pre-training을 마친 뒤 generator는 버리고 discriminator만 취해서 downstream task로 fine-tuning을 진행함
(3) Experiments
- ELECTRA의 성능 평가를 위해 General Langauage Understanding Evaluation (GLUE) 벤치마크와 Stanford Question Answering (SQuAD) 데이터셋 사용
- 대부분 실험은 BERT와 동일하게 Wikipedia 와 BooksCorpus를 사용해서 pre-training을 시켰으며 Large 모델의 경우에는 XLNet에서 사용한 ClueWeb, CommonCrawl, Gigaword를 사용했다.
- 모델의 구조와 대부분의 하이퍼 파라미터 역시 BERT와 동일하게 세팅함
- 10번의 fine-tuning 결과의 중간값(median)을 최종 성능으로 사용
Weight sharing
-
Generator와 discriminator는 모두 Transformer 인코더 구조이기 때문에, 두 네트워크의 가중치를 공유하여 학습하는 weight sharing 기법을 쓸 수 있고, pre-training의 효율 향상을 기대할 수 있다.
-
동일한 구조의 두 네트워크가 주어졌을 때 [1] 임베딩의 가중치만 공유하고 그 외의 가중치는 따로 학습시키거나 [2] 모든 가중치를 서로 공유하는 방법을 생각해 볼 수 있다.
-
논문에서는 각 weight sharing 세팅에 대해 500k step 만큼 학습시키고 GLUE로 성능을 평가함.
-
논문에서 가중치를 공유하지 않을 때 83.5, embedding만 공유할 때 84.3, 모든 가중치를 공유할 때 84.4 로, 모든 가중치를 공유하는 것이 좋은 성능을 보였다.
이를 paper에서 Discriminator는 입력으로 들어온 token만 학습하는 반면, generator는 출력 레이어에서 softmax를 통해 사전에 있는 모든 token에 대해서 밀도 있게 학습할 수 있다. ELECTRA는 결국 discriminator 만을 취해서 사용하는데, 이 때 generator와 임베딩을 공유해서 학습하는 경우의 discriminator는 훨씬 효과적으로 학습했을 것이고 결과적으로 더 좋은 성능을 기록한 것으로 보고있다.
-
성능 자체는 모든 가중치를 공유하는 방법이 좋지만 generator와 discriminator의 크기를 반드시 동일하게 맞춰야 하는 제약이 생기기 때문에, 결국 discriminator만 사용하는데 이 때 generator를 이와 동일한 크기로 가져가는 것은 학습의 효율을 떨어트릴 수 있다. 또한 더 작은 generator를 사용하는 것이 상당히 효과적이어서, paper 에서는 embedding만 공유하는 세팅으로 진행되었다.
smaller generators
- Generator와 discriminator의 크기를 동일하게 가져가면, ELECTRA를 학습하기 위해서는 BERT와 같은 일반 MLM 모델에 비해 단순 계산으로는 거의 두 배의 계산량이 필요하다. 이 문제를 완화하기 위해 paper에서는 generator의 크기를 줄이는 실험을 진행했다.
- 다른 하이퍼 파라미터는 그대로 두고, 레이어의 크기만 줄였다. (레이어의 크기는 hidden layer와 Feed-forward Network의 크기, attention head 수를 의미)
- 논문에서는 크기가 작은 generator 뿐 아니라 unigram generator로도 실험했다. (Unigram generator는 간단한 baseline으로 학습 corpus에 등장하는 unigram의 분포를 기반으로 샘플링 하는 generator)
=> 동일하게 500k step으로 학습해서, 작은 모델은 같은 계산량/시간에 따라 더 많은 step을 돌기 때문에 계산량 대비 성능을 손해본 셈이됐지만 그럼에도 불구하고 discriminator의 크기 대비 1/4-1/2 크기의 generator를 사용했을 때 가장 좋은 성능을 보였다.
- 이를 paper에서는 Generator가 너무 강력하면 discriminator의 task가 너무 어려워져서 이러한 현상이 나타날 수 있고, discriminator의 parameter를 실제 데이터 분포가 아닌 generator을 모델링 하는데 사용할 수 있기 때문이라고 해석했다.
(4) Electra Traning Algorithm
- Electra를 효과적으로 학습시킬 수 있는 알고리즘은 기본적으로 generator와 discriminator를 jointly 하게 학습시키는 방식이다.
[1] Two-stage 학습 : generator만 LMLM 으로 n step 동안 학습시키고, discriminator를 generator의 학습된 가중치로 초기화하고 LDisc로 discriminator만 n step 동안 학습 시키는 방식 (generator 가중치는 고정)
[2] Adversarial : GAN 처럼 adversarial training을 모사해 학습 시킴
- Two-stage 학습에서 discriminative objective로 바꿨을 때, 성능이 쭉 오름 Adversarial 학습이 maximum likelihood 기반의 학습보다 성능이 낮은데 이 현상의 원인은 MLM의 성능이 좋지 않아서(MLM 성능은 58%, Maximum likelihood로 학습한 generator는 65%), 학습된 generator가 분포의 엔트로피가 낮아서 (softmax분포는 하나의 token에 확률이 쏠려 있어 샘플링 시 다양성이 떨어짐)으로 본다.
(4) Electra small Models
- Electra 모델의 pre-training의 효율성 향상을 위해 1개의 GPU로도 빠르게 학습할 수 있는 작은 모델을 만드는 실험을 진행했는데, ELECTRA-Small 모델의 하이퍼파라미터는 아래 표와 같고, 크기가 대조군이 BERT-base에 비해서 매우 작다.
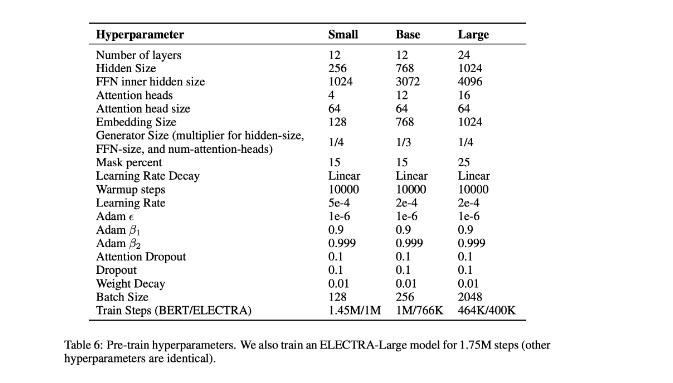
그러나, BERT-small 보다 좋은 성능을 보인다.
(4) Electra Efficiency Analysis
-
Electra가 성능이 왜 좋은지에 대해 일종의 ablation study의 성격으로 아래와 같이 실험을 세팅했는데,
- ELECTRA 15% : electra 구조를 유지하되, discriminator loss를 input token의 15%만으로 만듦- Replace MLM : Discriminator를 MLM 학습 하되, [MASK]로 치환하는 것이 아니라 generator가 만든 token으로 치환
- All-Tokens MLM : Replace MLM 처럼 하되, 일부(15%) token만 치환하는 것이 아닌 모든 token을 generator가 생성한 token으로 치환
(5) Conclusion
- 해당 paper에서는 language representation learning을 위한 self-supervision 태스크인 Replaced Token Detection(RTD) 제안합니다.
- 작은 generator가 만들어 낸 질 좋은 negative sample과 input token을 구별할 수 있도록 text encoder를 학습시키는 것이다.
- Masked lanuage modeling에 비해, 제안하는 pre-training objective는 훨씬 효율적(compute-efficient)이고, downstream tasks에 대한 결과 역시 좋음
[참고 사이트]
[참고 논문]
1. http://www.iro.umontreal.ca/~vincentp/Publications/denoising_autoencoders_tr1316.pdf
