KoELECTRA/KcELECTRA Model
1.Introduction
- KoElectra와 KcElectra는 ELECTRA의 한국어버전 language model 이다.
- ELECTRA에 대한 설명은 친절하고 아주 똑똑한 사람들이 정리한 ELECTRA 논문을 바탕으로 전 velog에 정리한 바 있다.
- ELECTRA는 간단히 말하면 기존의 BERT와 같은 MLM 학습이 아닌Generator(G), discriminator(D)를 이용한
RTD(Replaced Token Detection)pre-training 학습 방법을 사용한다. - 위 방법은 들어오는 실제 orgin 데이터(input token)을 Generator 에서 replaced token, 혹은 origin token으로 바꾸고, 이를 Discriminator 에서 이게 origin token 인지 replaced token 인지에 대해 판별하는 (binary classification) 하는 프로세스이다.
- 같은 Electra 모델이지만 'Ko' 와 'Kc' 앞 접두사가 다른데, 학습시킬 때 사용한 데이터셋의 성격이 조금 다른 듯하다.
2. KoElectra
git repo : https://github.com/monologg/KoELECTRA
- KoELECTRA-base 와 KoELECTRA-Small 두 가지 모델로 배포되었다.
- Wordpiece 사용, 모델 s3 업로드로 OS 상관없이 Transformers 라이브러리만 설치하면 곧바로 사용할 수 있다는 특장점이 있다.
(Transformers v2.8.0 부터 EelctraModel을 공식 지원하여, 모델을 직접 다운로드 하지 않고 곧바로 사용할 수 있다) - 작성하는 23년 5월 11일 기준 Pretraining 된 모델의 Detail을 살펴보면,
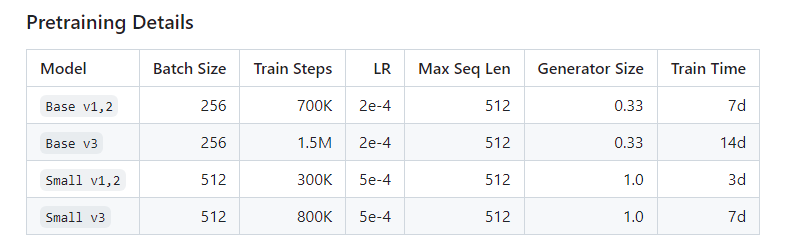
버전이 총 v1, v2, v3가 있는 것 같은데, v1과 v2는 14G Corpus(2.6B tokens) 으로 뉴스, 위키, 나무위키를 사용했고 v3는 20G의 모두의 말뭉치를 추가적으로 사용하여 신문, 문어, 구어, 메신저, 웹 데이터가 추가되었다.
- KoELECTRA-small 의 경우 공식 ELECTRA에서 배포한 Small 모델과 설정이 동일하지만 KoELECTRA-base와 달리 Generator와 Discriminator의 모델 사이즈가 동일하다는 특징이 있따.
- Batch size 및 Train steps을 제외하고 원 논문의 Hyperparameter와 동일하게 가져갔다고 한다. (paper와 동일하게 가져간 것이 성능이 가장 좋았다고 함)
2. KcElectra
git repo : https://github.com/Beomi/KcELECTRA
- '이준범' 님의 모델로 공개된 한국어 Transformer 계열 모델이 대부분 한국어 위키, 뉴스 기사, 책 등 정제되어 있는 데이터를 기반으로 학습되어 있는데, KcELECTRA는 온라인 뉴스와 댓글과 대댓글을 수집해, 토크나이저와 ELECTRA 모델을 처음부터 학습한 Pre-trained ELECTRA 모델이다.
- 기존의 KcBERT 대비 데이터셋 증가와 vocab 확장으로 상당한 수준으로 성능이 향상되었다.
3. KoElectra와 KcElectra 사용
- KcElectra repo에 따르면 General Courpus로 학습한
KoELECTRA가 보편적인 task에서는 성능이 더 잘 나올 가능성이 높다고 한다. KcELECTRA는 user generated, Nosiy text에 대해 보다 더 잘 동작하는 Pre-trained Model 이라고 나와있다.
일단 나는 서비스 유저들을 대상으로 유저들이 작성한 글에 대하여 text classification modeling을 수행하는 project를 수행해야 했는데,
위의 목적에 따라서 user 데이터들은 정형화되어 있지않고, Noisy text에 가깝기 때문에 KcElectra를 활용하여 downstream stream Task를 진행했다.
데이터의 형태가 구어체인 댓글, 대댓글로 학습된 KcElecta가 더 적합했기 때문이다. 현재 지금 회사에서 일하고 있는 한은 아무래도 KcElectra를 기반을 Text Classification을 계속 진행하지 않을까 싶다.
이상 프로젝트의 이야기는 해당 게시물의 논점과 좀 벗어나므로 여기서 끝

꿈꾸는 것도 개발처럼 깊게