[Tensorflow] 2. Convolutional Neural Networks in Tensorflow (1 week Exploring a Larger Dataset) : lecture
Tensorflow_certification(텐서플로우 자격증)

[Tensorflow] 2. Convolutional Neural Networks in Tensorflow (1 week Exploring a Larger Dataset) : lecture
[1] 강의 내용
- 2주차는 tensorflow로 cnn을 활용해 kaggle의 'Dogs vs Cats' 데이터를 활용해서 고양이와 개를 구분하는 분류기를 만드는 것이다.
데이터 셋은 https://www.kaggle.com/c/dogs-vs-cats/ 이다. 데이터는 약 25,000개이다.
대규모 데이터 세트에서 작동되는 것 중 하나는 과적합 방지에 도움을 주는 것이다. 작은 데이터셋은 과적합의 위험이 높지만 대규모 데이터는 과적합의 위험이 작아진다.
해당 섹션에서는 tensorflow를 활용해서 이미지 증강이라는 부분을 학습하게 된다.
예를 들면 고양이의 직립 데이터만 있지만 이를 이미지를 회전시키거나 해서 이미지를 증강시키는 것과 같다.
이미지의 증강은 회전, 왜국, 뒤집기, 프레임 주변으로 움직이기 등이 있다.
공공 데이터 세트를 사용할 때는 모든 이미지를 바로 흘려보내면서 이미지의 증강이 이루어질 수 있다.
그러므로 이미지를 직접 편집하지 않고, 데이터 세트를 변경하는 것이 아닌 모두 메모리 안에서 일어나게 할 수 있다.
또한 과적합을 막기 위해 기존 모델을 사용해서 전이 학습을 배우게 된다.
누구나 원하는 데이터를 모두 가지고 있지 않기 때문에 전이학습을 통해서 신경망을 다운로드 할 수 있다.
누군가가 백만 개의 이미지를 가지고 학습한 모델을 가지고 이러한 파마리터를 다운로드해서 자신의 학습 과정을 적은 데이터를 가지고 부트스트랩 할 수 있다.
자신의 데이터셋에서 찾을 수 없었던 특징을 찾을 수 있고 훈련 속도를 증가 시킬 수 있다.
또한 멀티캐스트러닝을 사용해서 두 개 이상의 클래스가 있을 때, 가위바위보와 같이 클래스가 3개 인 경우 인셉션이라면 1,000개의 클래스 이므로 2개 이상, 3개, 더 나아가 1,000개의 클래스를 가진 모델 특성에 대해 배운다.
The cats vs dogs dataset
간단한 컨볼루셔널 신경망 프로그래밍을 통해 큰 데이터 세트를 살펴보고, 다운로드하고 훈련을 위해 준비하고, 일부 데이터 전처리를 처리한다.
Training with the cats vs. dogs dataset
1주차에는 데이터의 이미지 크기가 작고 대상에 집중되어 있던 패션 데이터부터, 말과/사람, 액션 포즈를 취한 이미지가 있는 상황을 다뤘었다.
컨볼루션을 활용해 위치와 상관없이 이미지의 특징을 파악할 수 있었다.
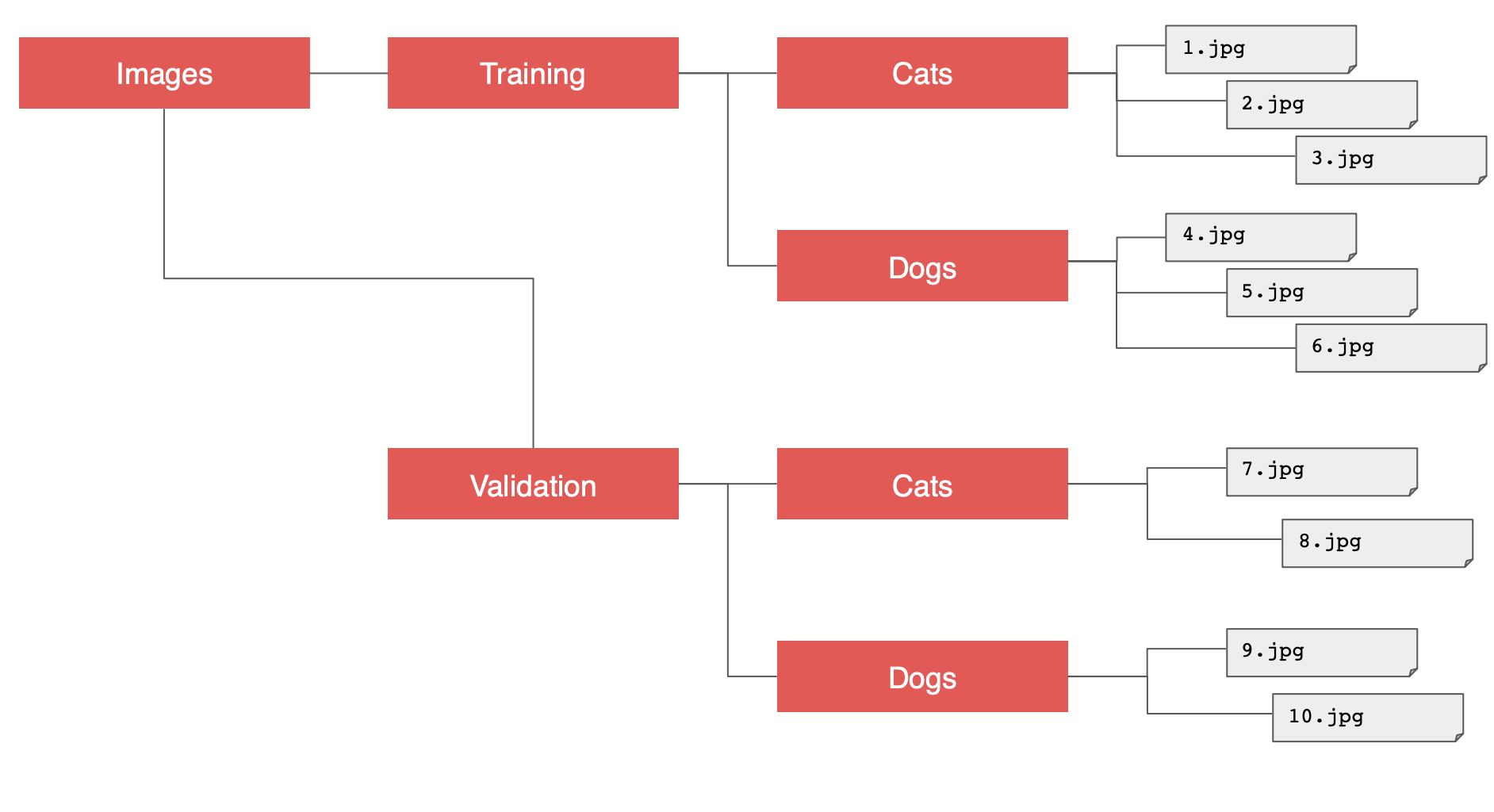
위 데이터는 kaggle의 데이터셋으로 분류기를 구축해서 고양이와 개를 구분하는 것이다.
Tensorflow, keras의 장점은 이름이 지정된 하위 디렉토리에 넣으면 생성된 이미지에 자동으로 레이블이 지정된다는 것이다.
그러니 고양이와 개 데이터 세트에서 이를 활용할 수 있고 분류기를 구축하는데 빠르게 앞서나갈 수 있다.
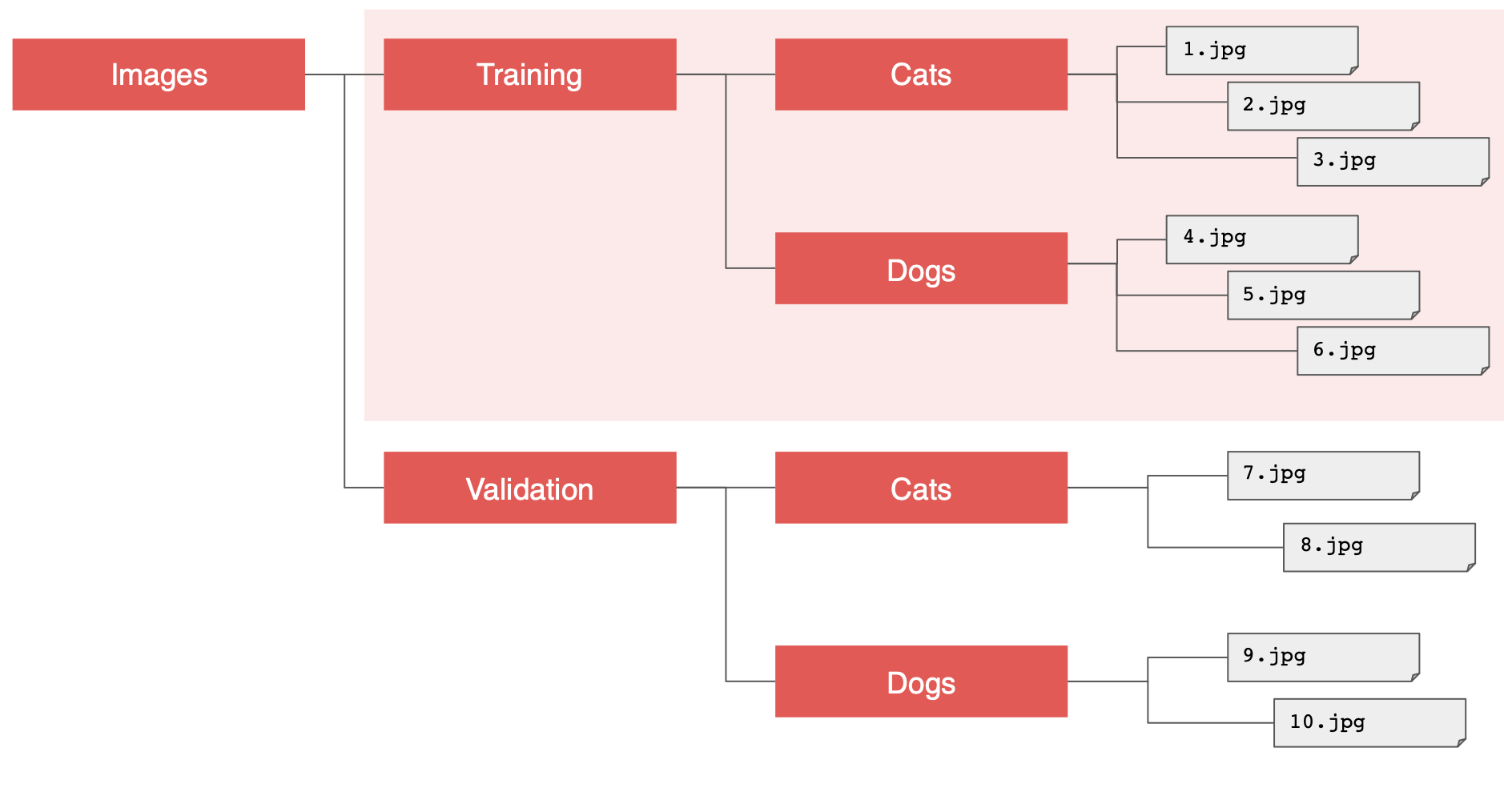
그리고 이 디렉토리를 세분화해서 훈련세트와 검증세트로 나눈다.
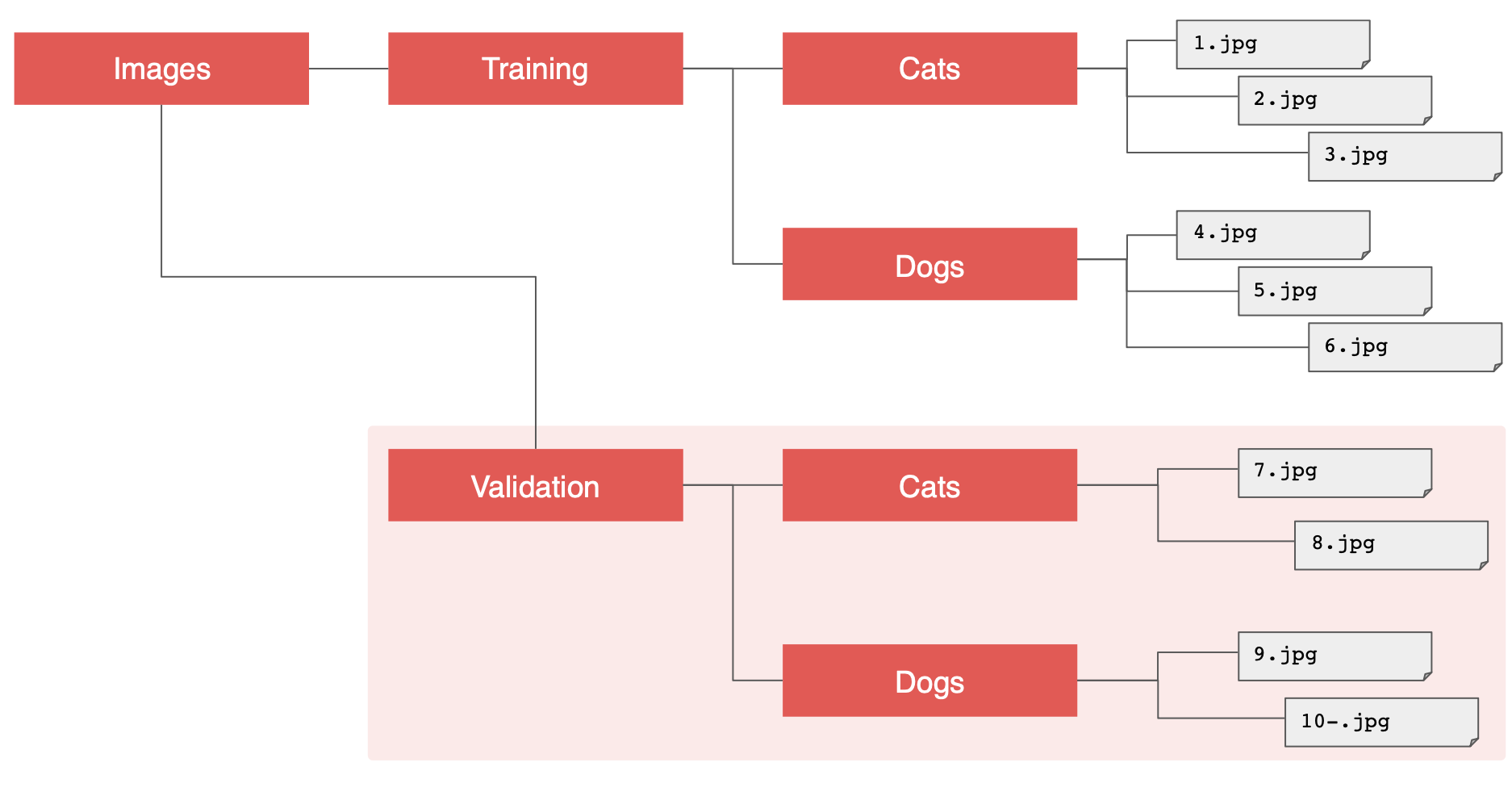

ImageGenerator를 사용해서 폴더에 할당할 수 있다.
ImageGenerator를 생성하기 위해서는 하나의 인스턴스를 만들어야 한다.
데이터가 정규화되어 있지 않으면 recale 파라미터를 사용한다.
tensorflow의 ImageDataGenerator를 활용해서 불러오는 데이터의 크기를 조정할 수 있고 (rescale),
이름이 지정된 하위 디렉토리에 이미지를 넣으면 생성된 이미지에 자동으로 레이블이 지정된다.

flow_from_directory 메소드를 통해서 생성기 객체를 확보할 수 있다.

훈련 데이터셋의 경우 훈련 디렉토리에 지정하고,

목표 사이즈를 지정하낟.
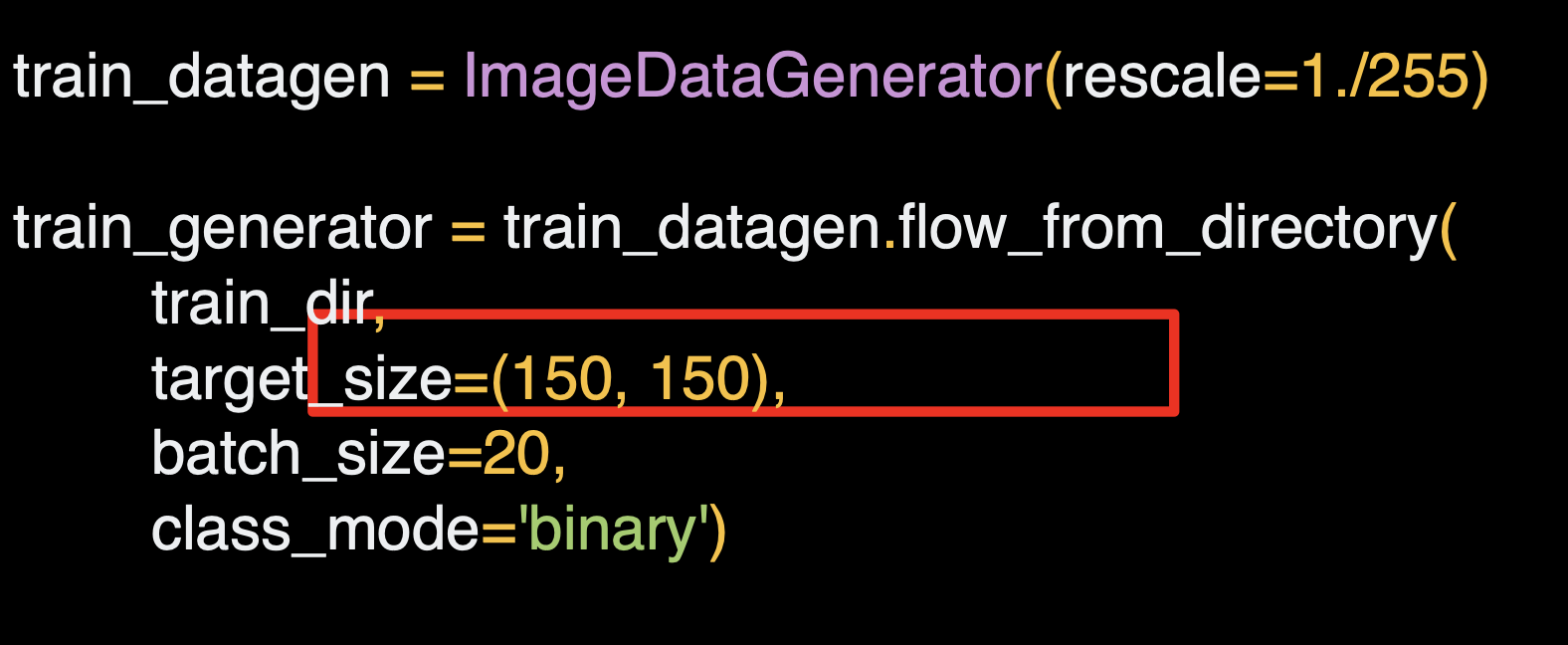
이 경우 다양한 모양과 크기의 이미지를 사용하게 되므로 대략 150x150으로 사이즈를 조정한다.
배치사이즈는 20으로 설정한다.
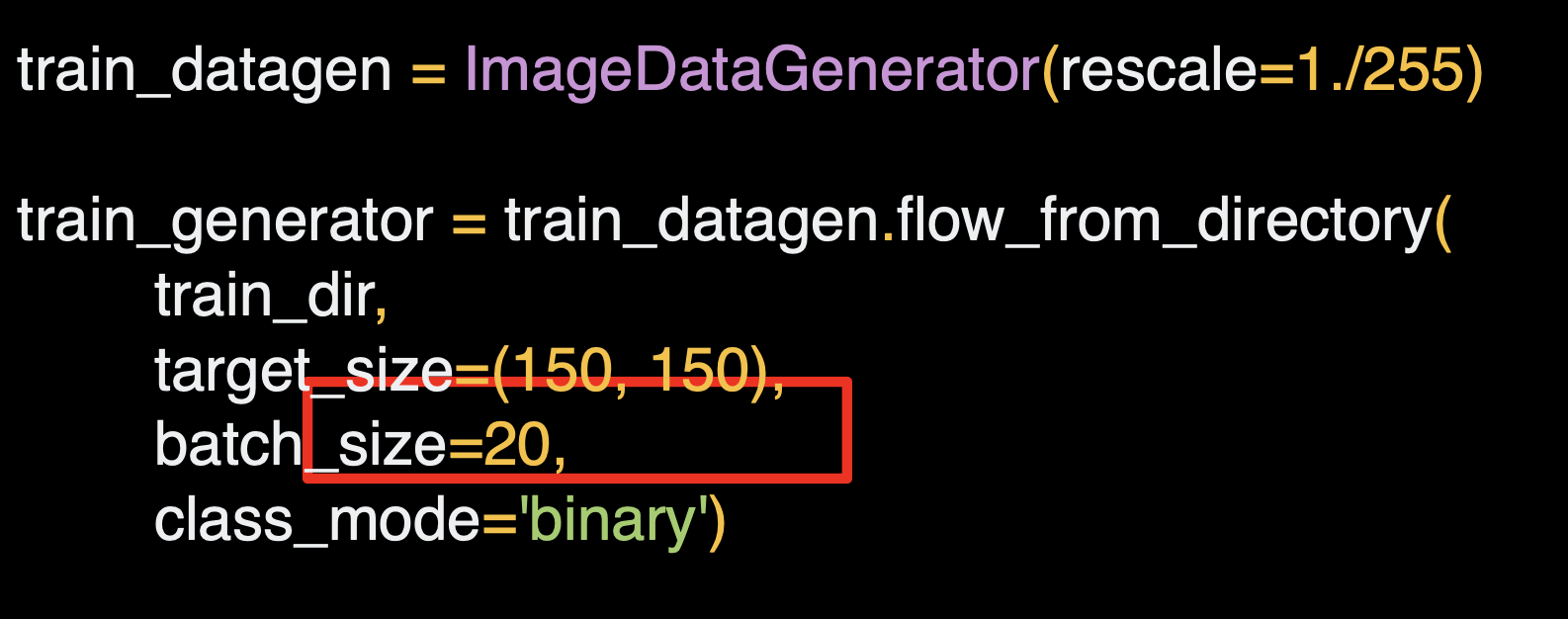
이미지는 총 2,000개라서 20개씩 100개의 배치를 활용한다.
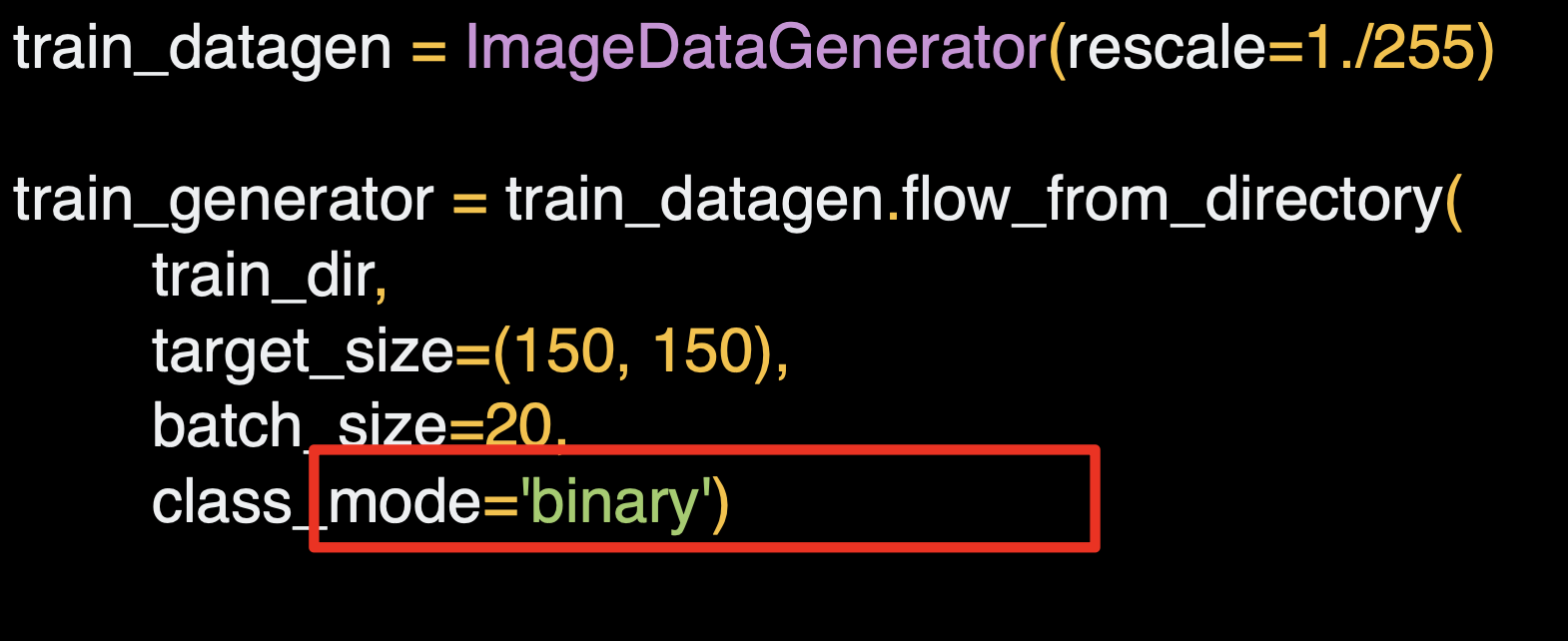
분류하고자 하는 클래스는 두개 이므로 이진 클래스 모드를 사용한다.
이와 같이 검증 데이터의 경우 생성기를 설정하고 검증 디레곹리에 지정한다.

컨볼루션과 풀링을 쌓아서 이미지의 과정을 볼 수 있다.
말과 사람을 구분하는 분류기의 모델과 유사하다.
간단한 cnn layer를 3층 쌓아 개/고양이 분류기를 만든다.

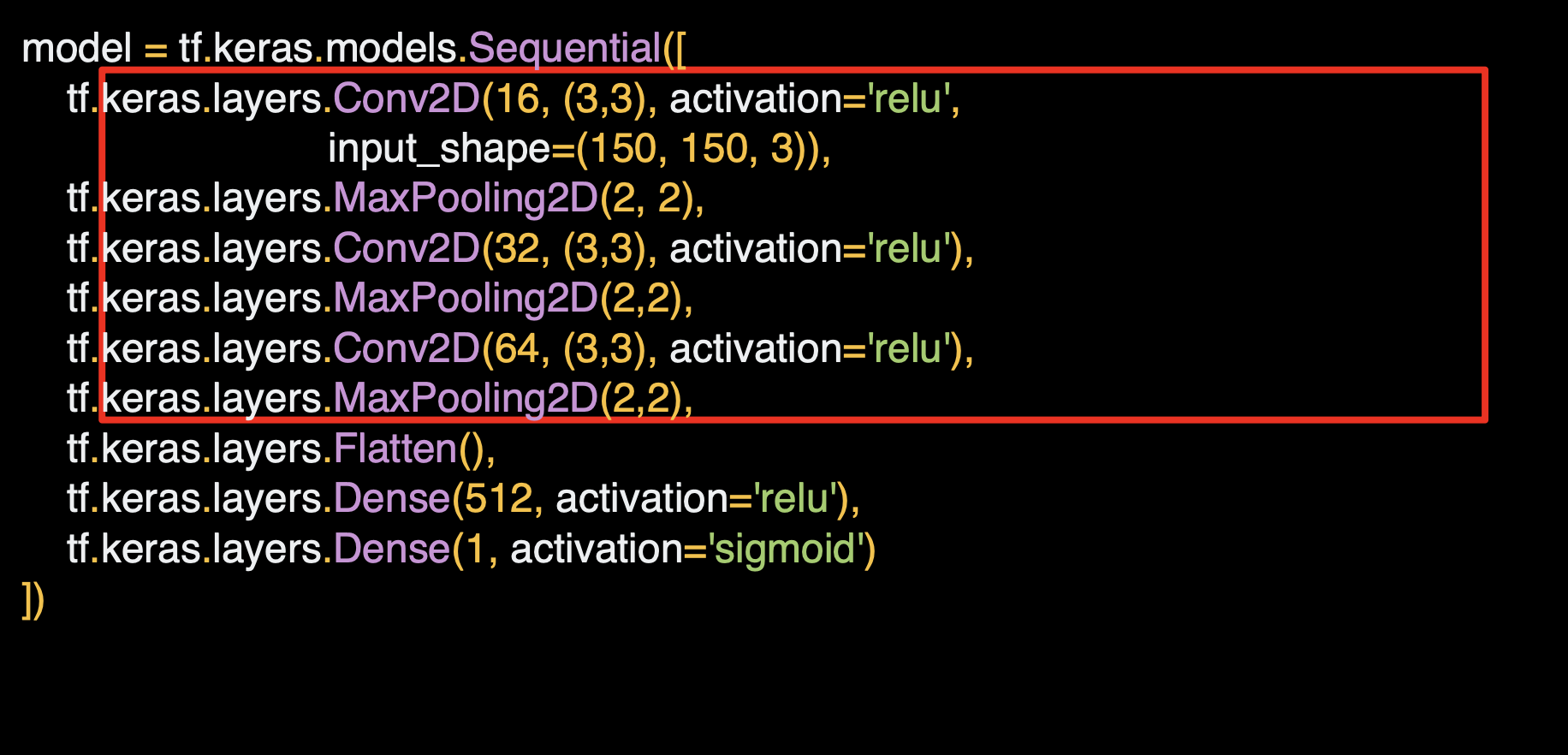
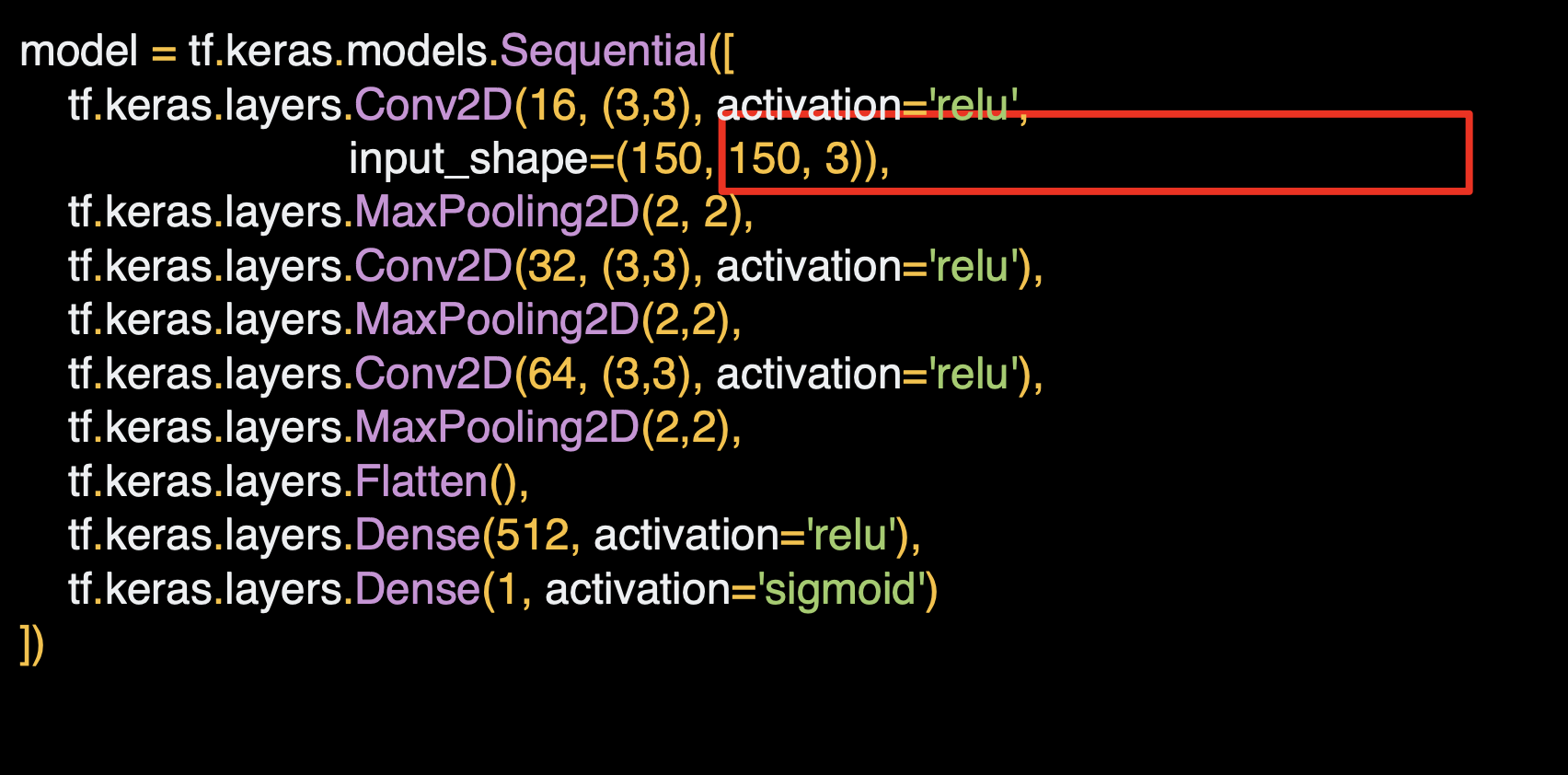
비슷하게 single neuron 에서 출력값으로 sigmoid 함수를 사용한다.
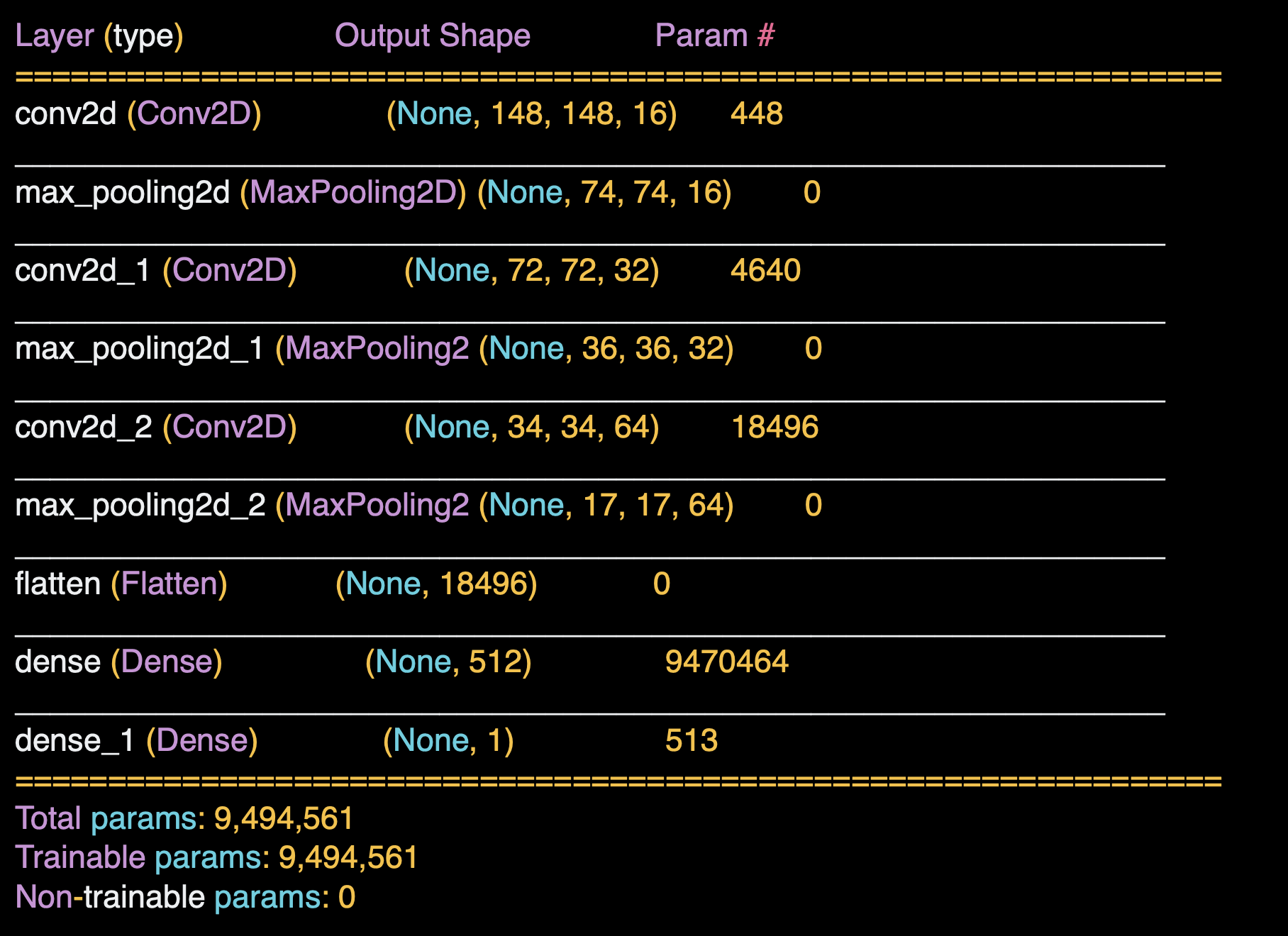
모델의 summary()를 통해 아래와 같이 모델의 structure를 확인하면, 레이어의 요약이 이전과 비슷하지만 크기가 다르다.
시작은 150x150 이지만 컨볼루션을 거치면 148x148이 된다.
마지막 17x17이 되면 Dense layer 에 입력한다.
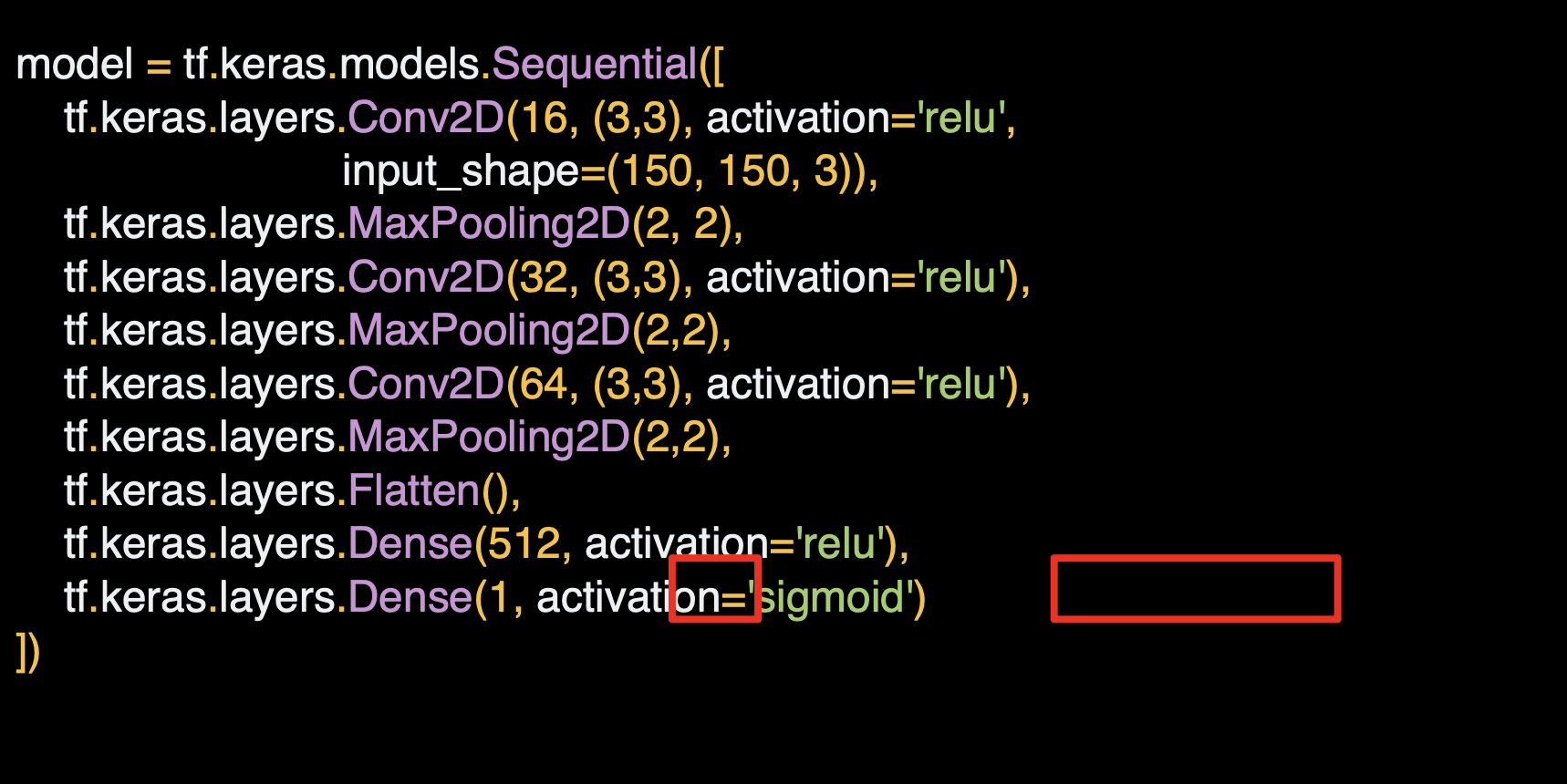
컴파일은 이전과 동일한데,
leanring_rate 인 lr 파라미터를 주정하여 학습률을 바꿀 수 있다.

여기서는 모델의 optimizer를 RMSprop으로 주었고, 학습한후에는 위의 generator를 통해서 model 학습 과정을 history 변수에 할당해서 history object를 데이터용으로 쿼리할 수 있다.

이제 훈련해서 model.fit 생성기를 호출하고 훈련 생성기와 검증 생성기를 넣는다.
고양이, 개를 분류하는 사진 중에 
해당 고양이 사진을 개로 판단하는데,
해당 사진을 크롭해서 
이러한 사진으로 분류기에 넣으면 고양이로 판단한다.
큰 사진에 개로 판단하는 어떤 특성이 있는 것이다.
이미지를 자르면 훈련에 어떤 영향이 있을까?
이 이미지가 자르지 않은 이미지에 비해 고양이라는 점을 더 잘 보여줄 수 있도록 학습시킨 것일까?
