[Tensorflow] 2. Convolutional Neural Networks in Tensorflow (2 week Augmentation: A technique to avoid overfitting) : lecture
Tensorflow_certification(텐서플로우 자격증)
[Tensorflow] 2. Convolutional Neural Networks in Tensorflow (2 week Augmentation: A technique to avoid overfitting) : lecture
-
Image Augmentation(이미지 증강), Data Augmentation(데이터 증강)은 딥러닝에서 가장 폭넓게 활용되는 도구다. 이를 활용해 데이터 세트의 규모를 늘리고 신경망의 성과를 높일 수 있다.
-
증강을 활용해서 이미지를 회전시키거나 기울이는 등의 다른 방식으로 변환시키게 되면 효과적으로 데이터를 생성해서 훈련시킬 수 있다. 이미지를 기울인 다음 훈련 세트에 넘기는 것이다.
-
이러한 증강은 잘못하면 이미지를 워프하고 기울이다가 메모리 요구 사항을 넘어 갈 수 있는데, Tensorflow를 사용하면 손쉽게 가능하다.
이미지 생성기 라이브러리에서 이미지를 메모리로 불러오고 메모리가 이미지를 가공한 다음 결과적으로 학습시킬 신경망의 훈련 세트로 스트리밍하는 것이다. -
예를 들어 훈련 데이터의 고양이가 항상 서있는다면 누워 있는 고양이는 분류하기 힘들 것이다. 증강을 화룡해서 이미지를 회전시키거나 기울이는 등 다른 방식으루 변환시키게 되면 효과적으로 데이터를 생성해서 훈련시킬 수 있다.
이미지를 기울이고 훈련세트에 넘긴다. -
tensorflow를 사용해서 이미지 생성기와 이미지 데이터 생성기가 있는데, 드라이브에서 직접 이미지를 편집하는 것이 아니라 이미지가 디렉토리에서 나올 때 신경망에 넣기 위해서 이미지를 불러오는 것과 마찬가지로 증강이 일어나는 것이다.
-
데이터 세트를 다룰 때 다양한 증강을 실험하고 싶다면 원본 데이터를 오버라이드를 하면 안된다.
-
이미지 생성기 라이브러리에서 이미지를 메모리로 불러오고 메모리가 이미지를 가공한 다음 결과적으로 학습시킬 신경망의 훈련 세트로 스트리밍 하는 것이다.
이것이 딥러닝에서 가장 중요한 요령 중 하나이다.
요즘 이미지 증강에서 인기 있는 방식이기도 하다. -
데이터에 영향을 주지 않는 것이 가장 주요한 이유이다.
데이터를 가지고 다시 실험할 수 있으므로 데이터를 오버라이드 하지 않는다. -
하나의 이미지를 가지고 다양한 이미지를 생성하지만 다른 이미지를 저장하지 않기 때문에 메모리 부족이 생기지 않는 것도 장점이다.
-
이미지 증강, 데이터 증강은 딥러닝에서 가장 중요한 부분을 차지한다. 중요성을 고려했을 때 꼭 배워야 하는 기술이다.
Image Augmentation
-
이미지 증강은 데이터의 과적합을 방지하는 데 도움이 되는 매우 간단하지만 매우 강력한 도구이다.
데이터가 제한되어 있으면 잠재적인 미래 예측과 일치하는 데이터를 가질 가능성도 제한되며, 논리적으로 데이터가 적을수록 데이터에 대한 정확한 예측을 얻을 가능성도 줄어든다. -
간단히 말해서, 고양이와 강아지 분류기 모델은 고양이를 발견하기 위해 서있는 고양이 데이터만을 가지고 훈련하는 경우, 누워 있을 때 고양이가 어떻게 보이는지 본 적이 없다면 나중에는 이를 인식하지 못할 수도 있다.
-
이미지 증강은 회전과 같은 변환을 사용하여 훈련하는 동안 즉석에서 이미지를 수정한다. 따라서 '서 있는' 고양이를 90도 회전시켜 누워 있는 고양이의 이미지를 'simulate'할 수 있다. 따라서 이미 가지고 있는 것 이상으로 데이터 세트를 확장하는 효율적인 방법이다.
-
증강 및 사용 가능한 변환에 대해 자세히 알아보려면 아래의 사이트를 참고한다.
https://keras.io/api/layers/preprocessing_layers/ -
그리고 이를 전처리라고 부르는 데에는 매우 강력한 이유가 있습니다. 원시 이미지를 편집할 필요도 없고 디스크에서 수정하지도 않는다는 점이다. 훈련을 수행하는 동안 메모리 내에서 수행되므로 데이터 세트에 영향을 주지 않고 실험할 수 있다.
Introducing augmentation
지금 까지는 이진 클래스에서 이미지를 인식하기 위해 컨볼루션 신경망을 훈련시켰다. 말과 사람/ 고양이, 개를 구분했다.
훈련할 데이터가 적음에도 불구하고 결과는 잘 나타났지만 잘못하면 과적합이 나타날 수 있다.
특히 데이터 세트 규모가 작으면 예시의 수가 상대적으로 적어서 결과적으로 분류에 실수가 일어날 수 있다.
과적합(overfitting)을 가장 잘 이해하는 것이 중요한데, 제한된 데이터 세트 내에서는 대상을 잘 인식했지만 예상과 일치하지 않는 대상을 보면 혼동이 일어나는 것이다.

위의 사진에서 이러한 신발만을 보고 신발이라고 인식했다면 신발의 생김새가 이렇다고 판단한다.

그래서 이러한 신발 이미지를 본다면 조금 다르지만 신발이라고 인식할 것이다.

위의 신발 또한 신발이지만 보지 않았다면 이러한 신발은 신발이라고 인식하지 못할 수 있다.
신발의 생김새에 대한 과적합이 발생한 것이다.
유연성이 부족하여 하이힐을 신발로 받아들이지 못하는 것이다.
훈련과 경험상 신발의 생김새는 하이킹 부츠에 해당하기 때문이다.
이것이 분류기 훈련 시 흔하게 나타나는 문제이다.
데이터가 제한되어 있을 때 특히 눈에 띄게 된다.
완벽한 분류기를 위해서는 무한한 데이터 세트가 필요하다.
그러나 그렇다면 훈련 시간이 너무 길어 지게 된다.
이번 강의에서는 몇 가지 도구를 통해 규모가 작은 데이터 세트를 더 효과적으로 활용한다.
먼저 증강이라는 개념의 콘셉을 이해해보자.

컨볼루션을 활용할 때는 이미지에 컨볼루션을 통과시켜서 특정한 특징을 학습시킨다. 고양이의 경우 뾰족한 귀, 사람은 4개의 다리가 아닌 2개의 다리 같은 요소이다.
이미지에 이러한 기능이 명확하게 나타나면 컨볼루션에서 이를 잘 파악할 수 있다.

더 깊게 생각했을 경우 고양이 이미지를 귀가 다른 방향을 향하는 고양이 이미지와 일치하도록 이미지를 변형시킨다면 어떻게 될까?
이전에 신경망에서 귀가 이렇게 기울어진 고양이를 훈련한 적이 없다면 아마 인식하지 못할 것이다.
귀가 기울어진 고양이 데이터가 없다면 과적합 상황이 나타날 수 있다.
해 이미지를 훈련하면 이 특징을 인식하게 되면서, 귀가 기울어진 고양이 이미지가 없어도 귀가 똑바로 서 있는 고양이 사진을 결과적으로 기울이게 만들 수 있다.
-> 지금까지 이진 클래스에서 이미지 인식을 위한 컨볼루션 신경망을 훈련시켰는데, 말/사람을 구분하거나 고양이/개를 구분했다. 훈련 데이터가 상대적으로 적었지만 결과가 잘 나타났다. 그러나, 잘못하며 과적합으로 인해서 분류가 잘 되지 않을 수 있다.
특히 데이터 세트 규모가 작으면 예시의 수가 상대적으로 적어 결과적으로 분류에서 실수가 일어나게 된다. 제한된 데이터 세트 내에서는 대상을 잘 인식하지만 예상과 일치하지 않는 대상을 보면 혼동이 일어나게 된다.
완벽한 분류기를 구축하기 위해서는 무한한 데이터 세트가 필요하지만 그렇게 되면 훈련 시간이 너무 길어지게 된다.
이 때 몇가지 도구를 통해서 규모가 작은 데이터 세트를 효과적으로 활용해보려고 하는데 첫번째가 바로 '증강(Augmentation)'이다.
Start Coding..
- 이제 Keras의 이미지 확대 구현을 살펴보았으니 코드를 자세히 살펴본다.
Keras 사이트에서 다양한 API에 대한 자세한 내용을 확인할 수 있다.
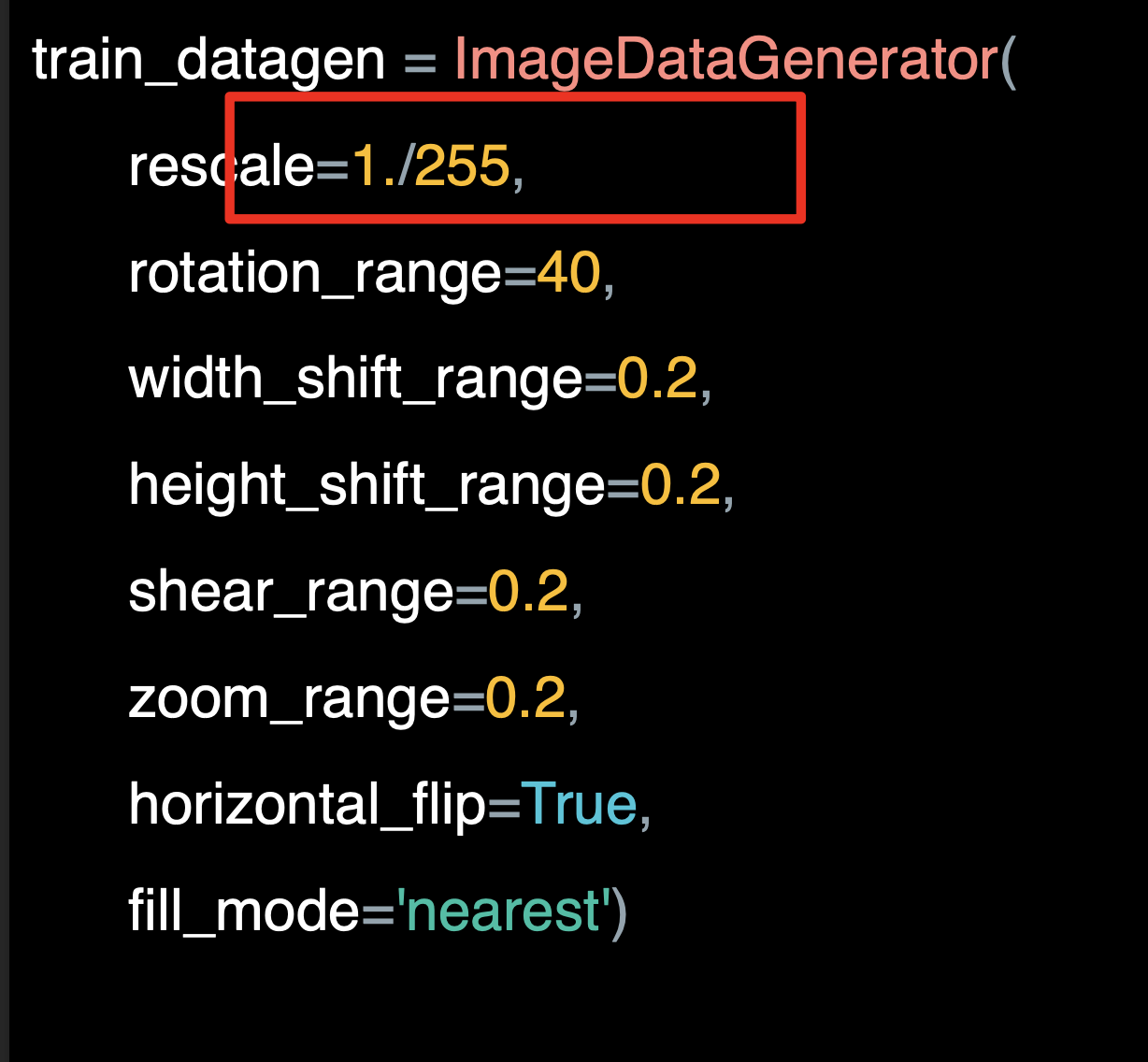
Coding augmentation with ImageDataGenerator
이전에 사용한 이미지 생성기 클래스를 사용해 이를 수행할 수 있다.

실제로 데이터를 로드하고 크기를 조정할 때 약간의 이미지 증강을 수행했다. 파일 시스템에서 모든 이미지를 변환한 다음 다음 로드하지 않아도 되고 즉시 크기를 조정할 수 있다.

다음은 이미지 생성기가 크기를 다시 조정하여 전체 이미지 증강 옵션을 사용하는 방법이다.
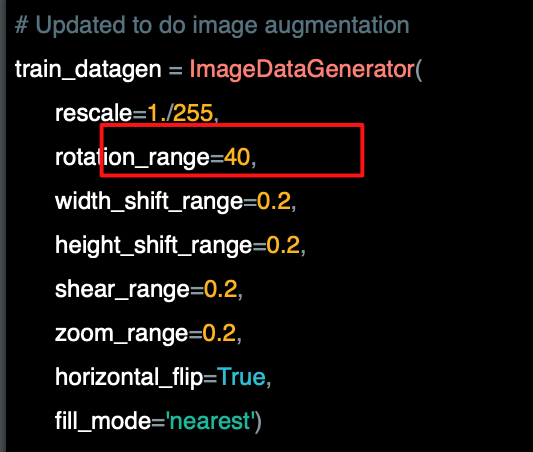
회전 범위는 이미지를 무작위로 회전시키는 0~180도 범위이다.
따라서 이 경우에서는 0에서 40도의 임의의 각도만큼 회전한다.
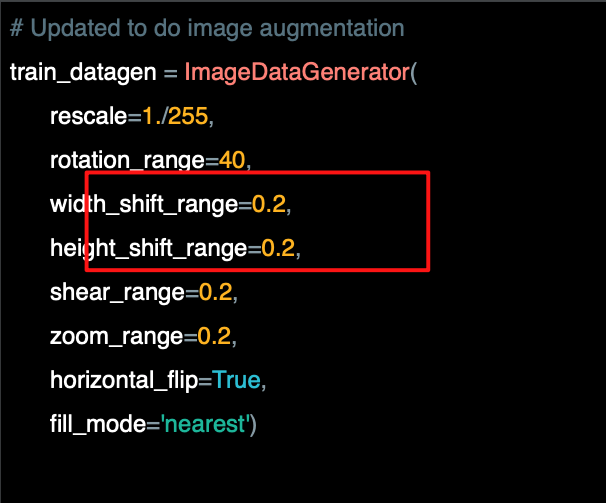
이동하면 이미지가 프래임 내부로 이동한다.
많은 사진의 피사체는 중앙에 있는데, 이러한 종류의 이미지를 기반으로 훈련하면 해당 시나리오에 과적합 할 수 있다.
이 파라미터는 이미지 크기의 비율로 피사체를 임의로 움직여야 하는 정도를 지정한다.
이 경우에는 수직 또는 수평으로 20% 상쇄(offset) 할 수 있다.

자르기 또한 매우 강력한데, 예를 들어 오른쪽 이미지를 보면 우리는 그것이 사람이라는 것을 알 수 있다. 그러나 우리의 훈련 데이터에는 그 방향에 있는 사람의 이미지가 없다.

우리는 이 사람과 유사한 방향의 이미지를 가지고 있으므로 x축을 따라 기울여서 그 사람을 자르면 비슷한 자세로 끝난다.
이것이 shear_range 옵션이다.
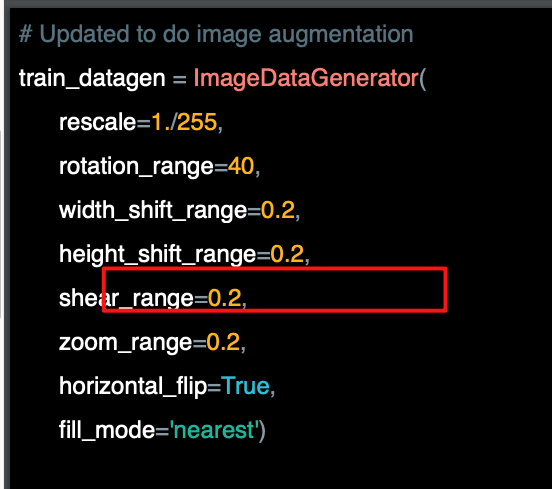
이미지의 지정된 부분까지 임의의 양으로 이미지를 자른다.
따라서 이 경우 이미지의 최대 20%까지 자르는 것이다.

줌 또한 효과적인데, 예를 들어 오른쪾 이미지를 보면 분명히 오른쪽을 향한 여성이다.

왼쪽의 이미지는 사람 또는 말 훈련 세트에서 가져온 것인데 매우 유사하지만 살마의 전체를 보기 위해 축소되었다.
훈련 이미지를 확대하면 오른쪽 이미지와 매우 유사한 이미지가 나타날 수 있다.
따라서 훈련하는 동안 확대하면 이와 같은 좀 더 일반적인 예를 확인할 수 있다.
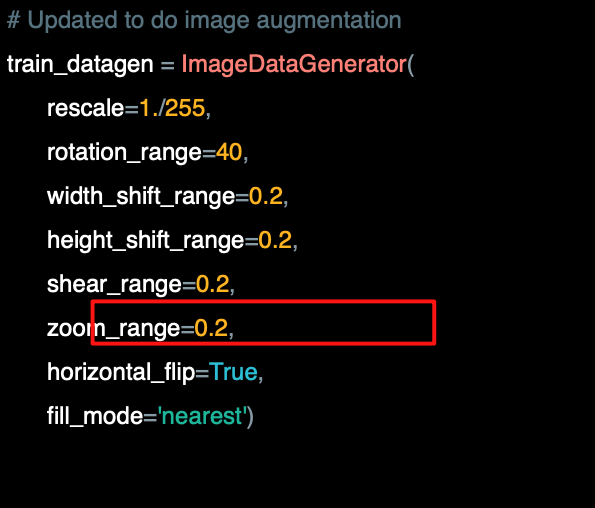
이처럼 zoom_range를 통해서 코드로 확대한다.
0.2는 확대할 이미지의 상대적 부분이다.
즉 이러한 경우 확대는 무작위로 크게 이미지의 최대 20%가 된다.

또 다른 유용한 도구는 수평 뒤집기이다.
예를 들어 오른쪽 그림은 훈련 데이터에 왼손을 든 여성의 이미지는 없고 왼쪽의 이미지처럼 오른손을 들고 있는 여성의 이미지가 있어 훈련 데이터를 올바르게 분류하지 못할 수 있다.

이미지를 수평으로 뒤집는 다면 오른쪽 이미지와 구조적으로 비슷해지며 오른쪽 팔 올리기에 과적합 하지 않을 수 있다.
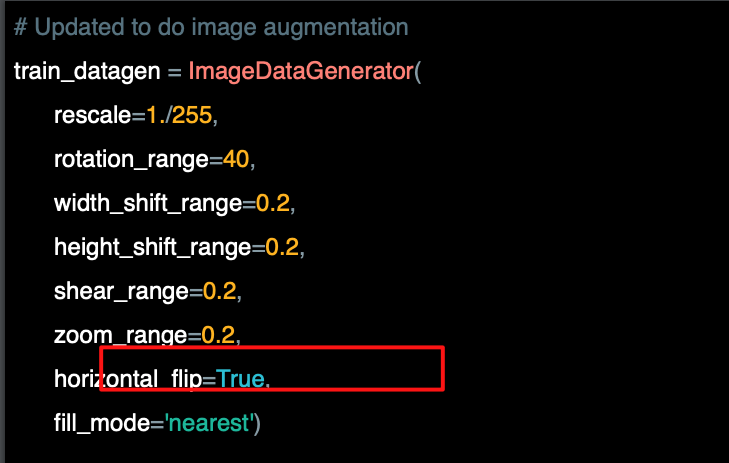
임의의 수평 뒤집기를 키기 위해서는 horizontal_filp=true 로 설정할 경우 이미지가 임의로 뒤집힌다.
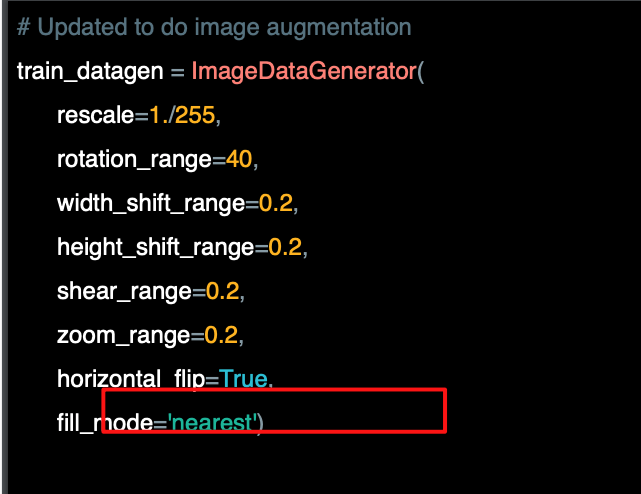
마지막으로 fill_mode 인데, 이 작업으로 인해 손실되었을 수 있는 모든 픽셀을 채운다.
여기서는 'nearest'를 사용했는데 이는 이 픽셀의 이웃을 사용해서 균일성을 유지하려고 하는 것이다.
다른 옵셔는 Carets 문서를 확인하면 된다.
이것이 바로 이미지 증강의 개념이다.
증강 및 비증강이 된 고양이/개 데이터셋으로 실험해서 이것이 미치는 영향을 확인할 수 있다.
Demonstrating overfitting in cats vs dogs
더 긴주기에 걸쳐 더 작은 데이터 세트를 가진 고양이와 개 훈련에 대해 살펴본다.
2,00개의 훈련 데이터를 가지고 100번의 epcoh로 훈련했다.
첫 번째 epoch 후에는 정확성과 검증 정확도의 수치를 확인한다 . (promgramming 1 포스팅 확인)
8번의 epoch 이후 정확도는 0.8에 가까워졌지만 검증 정확도는 성장이 늦춰졌다.
전체 100번의 epoch에 대한 정확도와 손실을 플로팅한다.
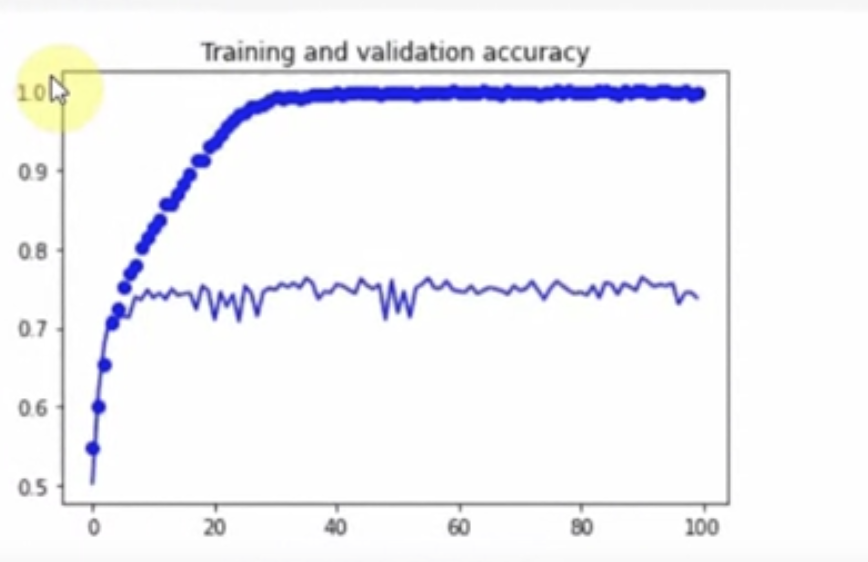
이 수치를 보면 훈련이 20번의 epoch 가 조금 넘었을 때 100% 정확도에 근접했음을 알 수 있다.
반면 검증은 대략 70%에 머물렀고 이로써 과적합됐다는 것을 볼 수 있다.
다시 말해 신경망은 훈련된 2,000개의 이미지에 대해 고야잉와 개의 이미지 및 데이터의 상관 관계를 찾는 데는 훌륭하지만 이전에 보지 못한 이미지를 예측하려고 시도하면 약 70% 정도 정확하다는 것을 볼 수 있다.
이것이 앞서 이야기 했던 신발의 예시와 같다.
이제 이미지 증강을 사용한 실험을 한 번 더 진행해본다.
The impact of augmentation on Cats vs. Dogs
이미지 증강을 통한 실험은 programing (2) 포스팅을 참고한다.
이제 과적합을 확인했으므로 간단한 코드 수정을 통해 동일한 컨볼루셔널 신경망에 데이터 증대를 추가하여 과적합을 줄이는 더 나은 훈련 데이터를 제공하는 방법이다.
Adding augmentation to cats vs. dogs
이전에는 고양이와 개에 대한 작은 데이터 세트를 훈련했고, 훈련 초기에 과적합이 비교적 일찍 발생하는 것을 보았다.
이제 훈련에 이미지 증강을 추가할 때의 영향을 살펴보자.
이미지 증강 코드는 ImageGenerator를 통해서 2,000개의 훈련 데이터를 회전, 뒤집기, 등등을 사용한다.
훈련을 시작하면 비증강했던 데이터와 같이 2,000개를 사용했지만 처음에 수행했던 버전보다 정확도가 낮다는 것을 볼 수 있다.
이는 수행되는 다른 이미지 처리의 임의의 효과 때문이다.
epoch를 몇 번 더 실행하면 정확도가 천천히 올라가는 것을 볼 수 있다.
마지막 epoch에 도달했을 때 모델은 훈련 데이터에서 약 86% 테스트 데이터에서 약 81%를 보여준다.
이를 플로팅 했을 때
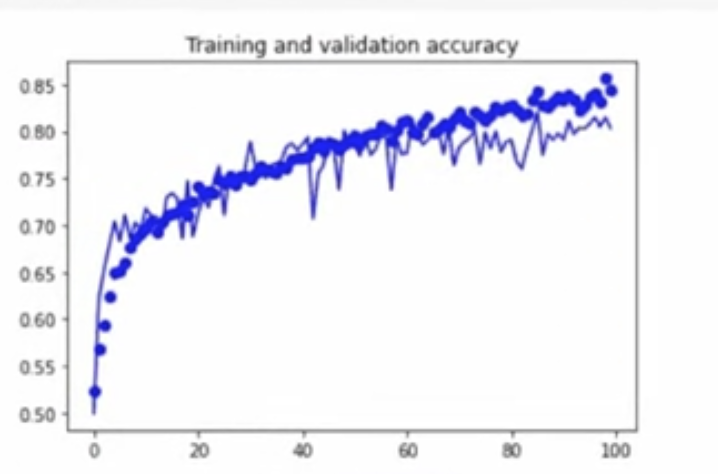
훈련과 검증 정확성 및 손실이 서로 단계뼐로 있음을 볼 수 있다.
이전과 비교해 과적합을 해결했다는 신호로 볼 수 있다.
정확도는 조금 낮아지지만 상승 추세에 있기 때문에, 더 많은 epoch는 정확도를 100%에 도달하게 만들 수 있을 것이다.
Exploring augmentation with horses vs. humans
이러한 이미지 증강은 과적합을 모두 해결할 수 있는 방법은 아니다. 실제로 다양한 이미지를 얻는데 도움이 되는 방법이다.
예를 들어 말 또는 사람 데이터 세트를 보고 동일한 epoch를 위해 훈련하면 비교해 볼 수 있다.
학습을 100번의 epoch를 사용했다면 테스트 정확도는 꾸준히 높아지는 것을 볼 수 있지만 처음에는 검증 정확도가 단계적이다가 그 정도가 크게 달라진다.
여기서는 이미지 증강에도 불구하고 이미지의 다양성이 여전히 희박하고 검증 세트는 제대로 설계되지 않았을 수 있다.
즉 이미지 유형이 훈련 세트의 이미지에 너무 가까운 것이다.
예를 들어 사람은 훈련 및 검증 세트 모두에서 거의 항상 이미지의 중앙에 서 있어서 이미지를 증강하면 검증 세트에 있는 것과 다르게 보이는 이미지로 변경된다.
훈련이 끝날 때까지 훈련 정확도는 100%를 향하지만 검증은 60~70 정도에서 변동한다.

검증은 계속해서 변동하고 있다.
예를 들어서, 이미지의 다양성이 희박해서 증강했더라도 검증 세트가 훈련 세트 이미지에 너무 가깝다면 별 효과가 없을 수 있다.
이미지 증강은 훈련 이미지에 임의의 요소를 도입하지만 검증 세트가 동일한 임의성을 가지지 않으면 효과가 없다. 그러므로 광범위한 이미지 세트는 훈련 뿐 아니라 세트트를 위해서도 필요하다. 그렇지 않으면 이미지 증강은 크게 도움이 되지 않는다.
- 여기까지 TensorFlow가 이미지 확대와 함께 제공하는 매우 유용한 도구를 살펴봤다. 이를 통해 프레임 주위로 이미지를 이동하고, 기울이고, 회전하는 등의 도구를 사용하여 작은 데이터 세트에서 더 큰 데이터 세트를 효과적으로 시뮬레이션할 수 있다. 이는 과적합을 수정하는 데 효과적인 도구가 될 수 있다.
