[Tensorflow] 2. Convolutional Neural Networks in Tensorflow (2 week Augmentation: A technique to avoid overfitting) - Programming (1)
Tensorflow_certification(텐서플로우 자격증)
[Tensorflow] 2. Convolutional Neural Networks in Tensorflow (2 week Augmentation: A technique to avoid overfitting) - Programming (1)
Data Augmentation (데이터 증강)
- 이전 섹션에서는 학습 정확도가 높다고만 해서 좋은 예측 모델이 있다는 의미는 아니라는 점을 살펴봤다. 훈련 세트에 과적합되었기 때문에 새로운 데이터에서는 여전히 성능이 좋지 않을 수 있다. 여기서는 데이터 증강(Data Augmentation) 을 사용하여 과적합을 방지하는 방법을 살펴본다.
- 기존 학습 데이터의 속성을 수정하여 학습 데이터의 양을 증가시키는 방법인데, 예를 들어 이미지 데이터의 경우 기존 이미지에 회전, 뒤집기, 기울이기, 확대/축소 등 다양한 전처리 기술을 적용하여 모델이 학습해야 하는 다른 데이터를 시뮬레이션할 수 있다. 이렇게 하면 모델은 훈련 중에 이미지의 다양성을 볼 수 있으므로 이전에 볼 수 없었던 새로운 데이터를 더 잘 추론할 수 있다.
Baseline Performance
- 데이터 증강 없이 고양이와 개를 학습하는 데 매우 효과적인 모델부터 시작해보자. 이전에 사용했던 모델과 유사하게 32, 64, 128, 128개의 컨볼루션을 포함하는 4개의 컨볼루션 레이어가 있다. 시간을 절약하기 위해 20 에포크 동안만 훈련하여 테스트한다.
[1] data download and data load
import requests
url = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
file_name = 'cats_and_dogs_filtered.zip'
response = requests.get(url)
with open(file_name, 'wb') as f:
f.write(response.content)
print('다운로드 완료')import zipfile
# Unzip the archive
local_zip = './cats_and_dogs_filtered.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall()
zip_ref.close()이 노트북에서 나중에 데이터 증강을 사용할 때 새 모델을 쉽게 초기화할 수 있도록 모델 생성을 함수 내부에 배치한다.
import os
base_dir = 'cats_and_dogs_filtered'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
# Directory with training cat pictures
train_cats_dir = os.path.join(train_dir, 'cats')
# Directory with training dog pictures
train_dogs_dir = os.path.join(train_dir, 'dogs')
# Directory with validation cat pictures
validation_cats_dir = os.path.join(validation_dir, 'cats')
# Directory with validation dog pictures
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
print(train_cats_dir)
print(train_dogs_dir)
print(validation_cats_dir)
print(validation_dogs_dir)
# output
cats_and_dogs_filtered/train/cats
cats_and_dogs_filtered/train/dogs
cats_and_dogs_filtered/validation/cats
cats_and_dogs_filtered/validation/dogs[2] ImageDataGenerator
from tensorflow.keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale= 1./255)
test_datagen = ImageDataGenerator(rescale = 1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
batch_size=20,
class_mode = 'binary',
target_size=(150,150),
)
validation_generator = test_datagen.flow_from_directory(
validation_dir,
batch_size=20,
class_mode = 'binary',
target_size=(150,150),
)
# output
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.[3] model build & model compile & training
import tensorflow as tf
def create_model():
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3,3), input_shape=(150,150,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(
loss = 'binary_crossentropy',
optimizer= tf.keras.optimizers.RMSprop(learning_rate=0.001),
metrics=['accuracy'],
)
return modelEPOCH = 20
model = create_model()
history = model.fit(train_generator,
steps_per_epoch = 100, # 2,000 images = batch_size * steps
epochs =20,
validation_data = validation_generator,
validation_steps=50, # 1,000 images = batch_size * steps
verbose= 2)

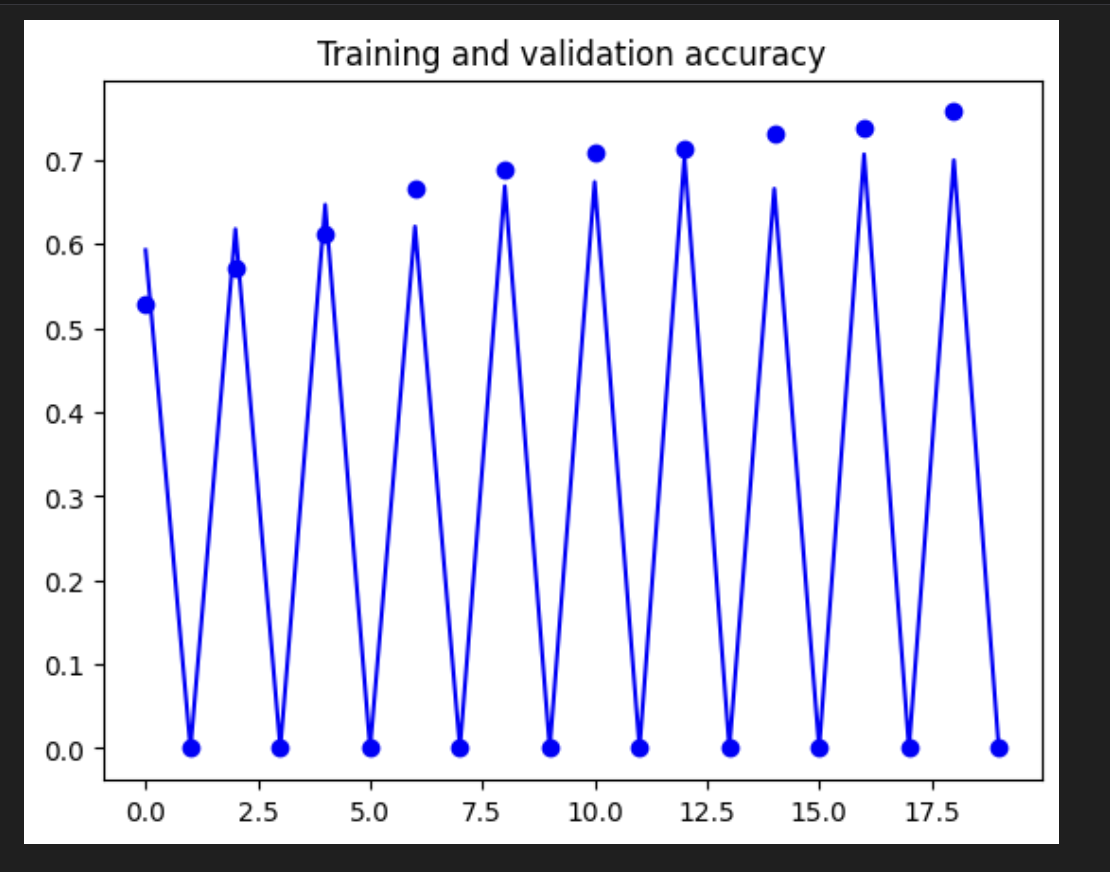
[3] acc, loss visualization
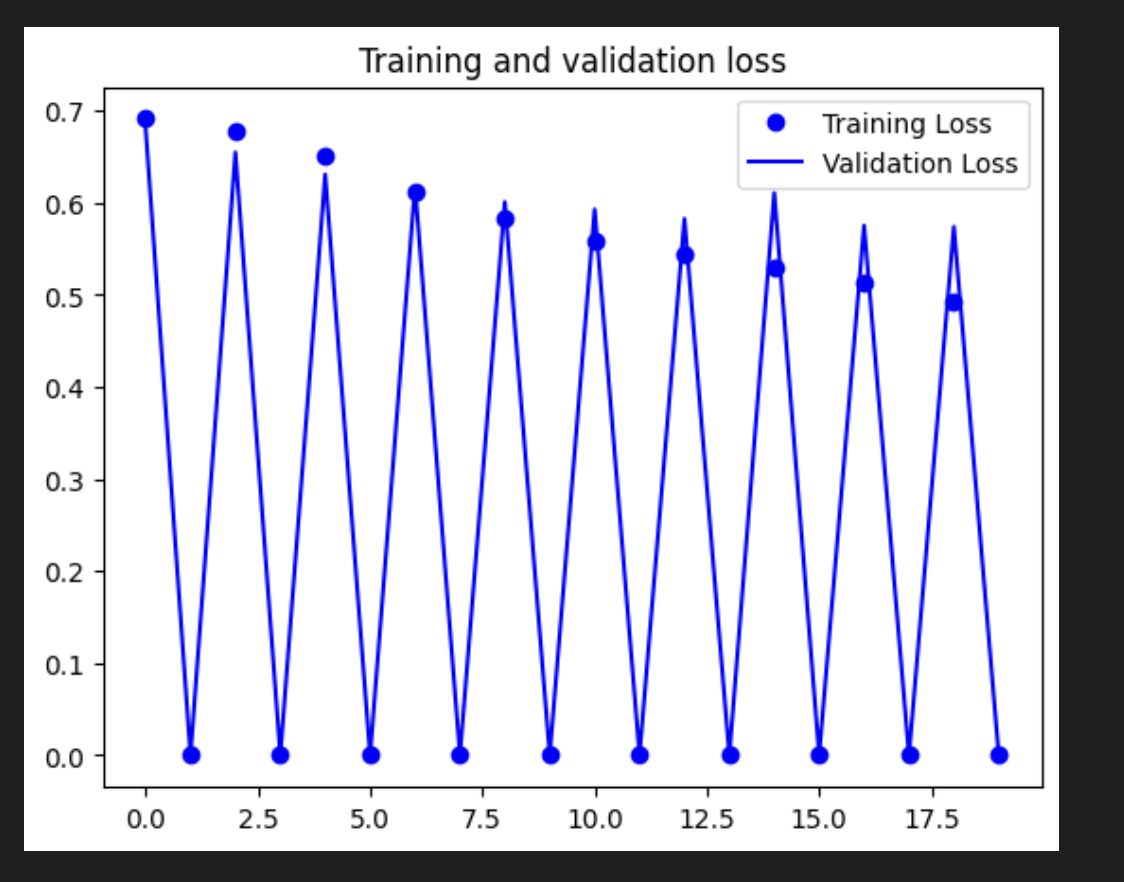
[4] Data augmentation
과적합을 방지하는 간단한 방법 중 하나는 이미지를 약간 늘리는 것입니다. 생각해 보면 대부분의 고양이 사진은 매우 비슷합니다. 귀가 맨 위에 있고 그 다음은 눈, 그 다음은 입 등입니다. 눈과 귀 사이의 거리와 같은 것들도 항상 상당히 유사합니다.
이미지를 약간 조정하면 어떻게 될까요? 이미지 회전, 스쿼시 등이 바로 이미지 확대의 전부입니다. 그리고 이를 쉽게 만들어주는 API가 있습니다!
이미지 크기를 조정하는 데 사용한 ImageDataGenerator를 살펴보세요. 이미지를 확대하는 데 사용할 수 있는 다른 속성이 있습니다.
train_datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
rotation_range는 그림을 무작위로 회전하는 각도(0~180) 값width_shift및height_shift는 그림을 수직 또는 수평으로 무작위로 이동하는 범위(전체 너비 또는 높이의 일부)shear_range는 전단 변환을 무작위로 적용하기 위한 것zoom_range는 사진 내부를 무작위로 확대/축소하는 데 사용horizontal_flip은 이미지의 절반을 수평으로 무작위로 뒤집는 것.
이는 수평 비대칭에 대한 가정이 없는 경우(예: 실제 사진)와 관련이 있음fill_mode는 회전 또는 너비/높이 이동 후에 나타날 수 있는 새로 생성된 픽셀을 채우는 데 사용되는 전략
[5] 모델 재학습
model_for_aug = create_model()
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
batch_size=20,
target_size=(150,150),
class_mode='binary'
)
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150,150),
batch_size=20,
class_mode='binary'
)
history_with_aug = model_for_aug.fit(
train_generator,
steps_per_epoch=100,
validation_data = validation_generator,
validation_steps= 50,
verbose=2
)
[6] 모델 재평가
EPOCHS = 20
# Create new model
model_for_aug = create_model()
# This code has changed. Now instead of the ImageGenerator just rescaling
# the image, we also rotate and do other operations
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
test_datagen = ImageDataGenerator(rescale=1./255)
# Flow training images in batches of 20 using train_datagen generator
train_generator = train_datagen.flow_from_directory(
train_dir, # This is the source directory for training images
target_size=(150, 150), # All images will be resized to 150x150
batch_size=20,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
# Flow validation images in batches of 20 using test_datagen generator
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
# Train the new model
history_with_aug = model_for_aug.fit(
train_generator,
steps_per_epoch=100, # 2000 images = batch_size * steps
epochs=EPOCHS,
validation_data=validation_generator,
validation_steps=50, # 1000 images = batch_size * steps
verbose=2)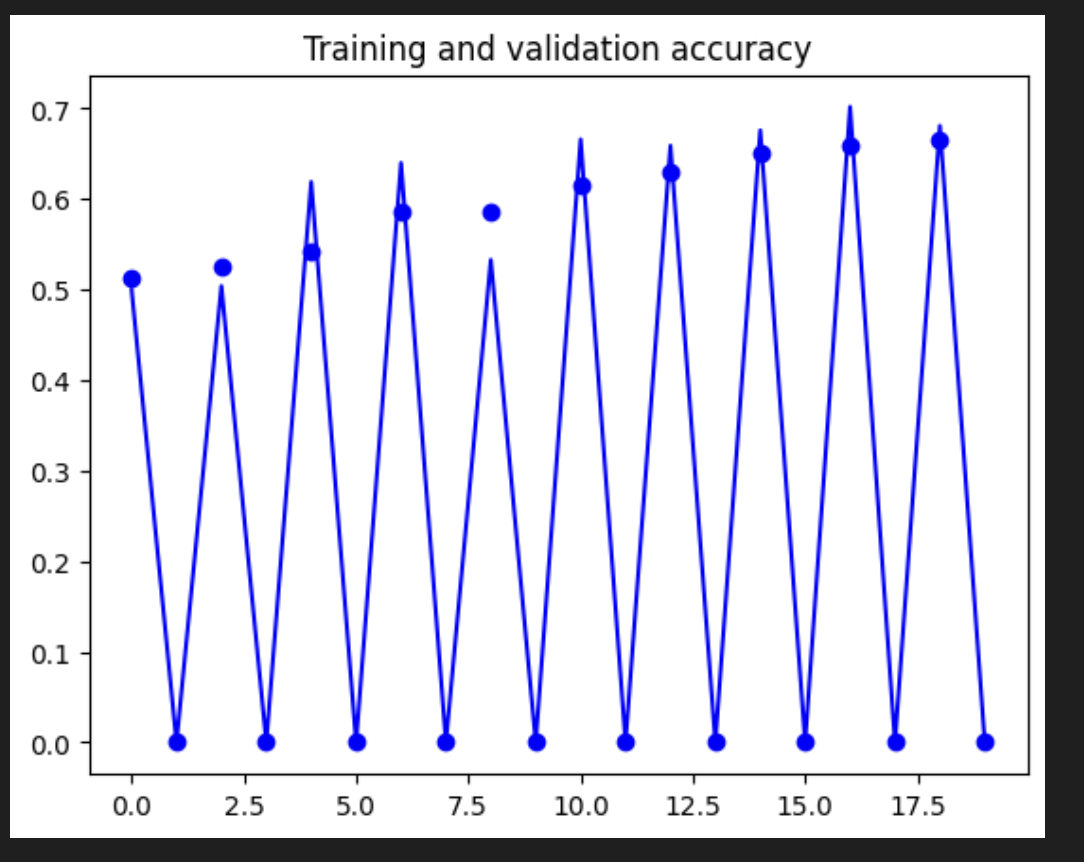
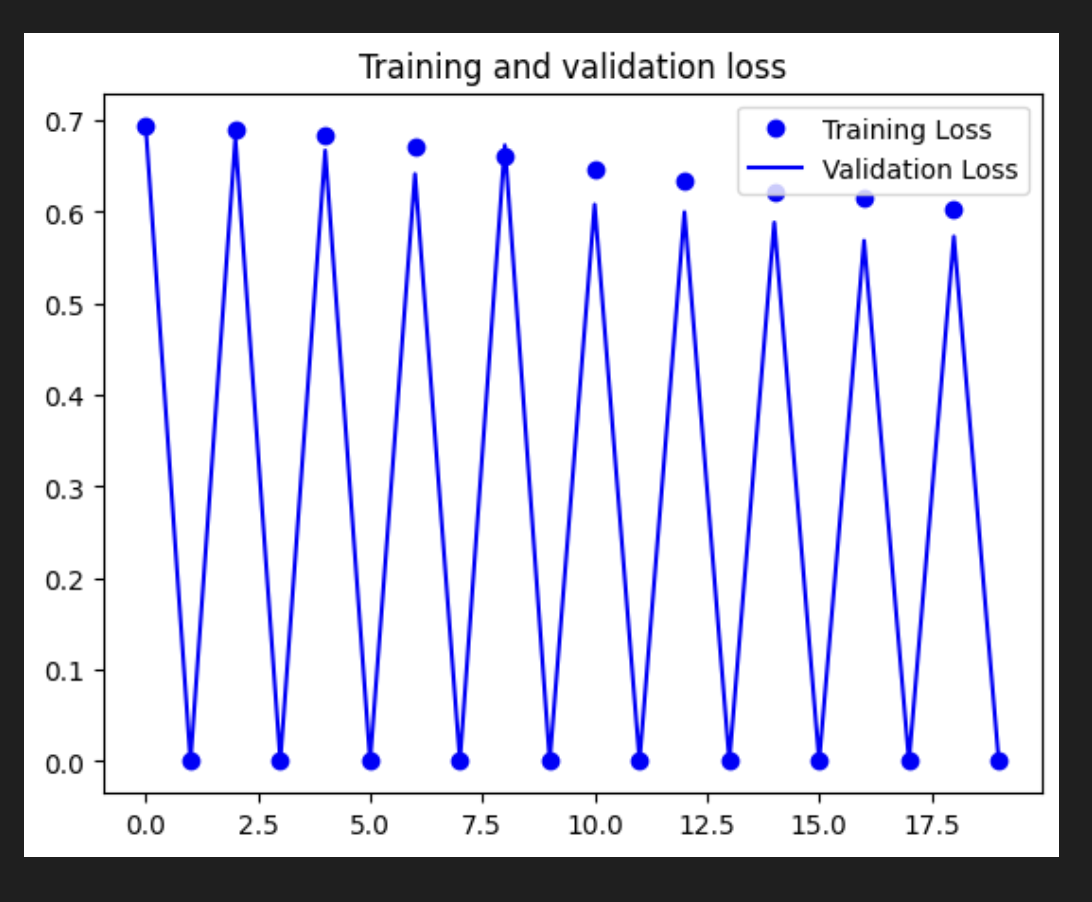
- 훈련 정확도가 기준선에 비해 떨어졌다. 이는 데이터 증강으로 인해 이미지에 더 많은 다양성이 있으므로 모델이 이를 학습하기 위해 더 많은 실행이 필요하기 때문에 예상된다.
- 좋은 점은 검증 정확도가 더 이상 지연되지 않고 훈련 결과와 일치한다는 것이다. 이는 모델이 이제 보이지 않는 데이터에서 더 나은 성능을 발휘한다는 것을 의미한다.
여기서는 과적합을 방지하는 간단한 방법인 데이터 증강을 사용했다.
이미 가지고 있는 동일한 이미지를 간단히 조정하여 기본 결과를 향상시킬 수 있다. ImageDataGenerator 클래스에는 이를 수행하기 위한 기본 제공 매개변수가 있는데, train_datagen에서 값을 좀 더 수정해 보고 어떤 결과가 나오는지 확인해보자.
이러한 경우는 모든 경우에 적용되는 것은 아니다. 다음 장에서는 데이터 증강이 검증 정확도를 향상시키는 데 도움이 되지 않는 시나리오가 나오게 된다.
