[Tensorflow] 2. Convolutional Neural Networks in Tensorflow (3 week Transfer Learning) : lecture
Tensorflow_certification(텐서플로우 자격증)
[Tensorflow] 2. Convolutional Neural Networks in Tensorflow (3 week Transfer Learning) : lecture
강의 내용
Tensorflow로 전이 학습(Transfer learning) 하기
기존 모델을 사용하여 많은 레이어를 동결하여 재학습을 방지하고 이미지에 맞게 학습한 컨볼루션을 효과적으로 '기억'하는 방법. 다른 모델의 컨볼루션을 사용하여 이미지를 다시 훈련할 수 있도록 이 아래에 자신만의 DNN을 추가.
과적합을 방지하는 데 있어 네트워크를 보다 효율적으로 만들기 위해 드롭아웃을 사용한 정규화 방법 dropout
전이 학습은 딥러닝에서 가장 중요한 기술이고 tensorflow를 활용하면 코드 몇 줄로 가능하다.
신경망을 처음부터 훈련하는 경우에는 많은 데이터가 필요하고 시간이 오래 걸리지만 오픈 소스 모델과 같이 다른 사람들이 몇 주간 훈련해둔 거대 데이터를 다운로드한 다음 그 파라미터를 시작점으로 삼아 특정 작업을 위한 우리의 작은 데이터셋을 조금 더 훈련 시킬 수 있다.
이것을 전이 학습이라고 부른다.
지금까지는 컨볼루션 신경망을 살펴보고 컨볼루션 신경망을 훈련시키면서 이미지에 특징을 추출하고 이미지에 해당하는 특징을 학습하는 것이었다. 하지만 대규모 모델인 다운로드 받는 것은 더 많은 이미지에서 추출해 낸 특징을 보유한 인셉션을 활용하는 것이다.
이러한 거대 모델은은 긴 시간에 걸쳐 수많은 이미지로 훈련한 만큼 우리가 가지고 있지 않은 데이터의 다른 특징들을 인식하고 더 나은 컨볼루션 신경망을 만드는데 유용할 것이다.
신경망은 데이터로부터 가장자리, 모서리, 둥근 모양, 곡선 모양, 방울 뿐 아니라 눈이나 동그라미, 정사각형, 바퀴와 같이 학습해야 할 특징들이 많다. 2,000개 25,000개로는 충분히 학습할 수 없다.
인셉션 네트워크나 다른 사람들이 훈련한 네트워크를 이용해서 신경망에 모든 지식을 다운로드하면 더욱 빠르게 시작할 수 있다.
거대한 모델을 구축할 수 없는 사람들도 이전에 사람들이 구축해 놓은 모델의 특징을 활용할 수 있다.
전이 학습의 좋은 점 중 하나는 tensorflow 내에서 구현하기가 쉽다는 것이다. 모델을 다운로드 하고 모델을 훈련 가능으로 만들고 다른 레이어는 동결시키거나 잠근 다음 실행하기만 하면 된다.
여기서는 인셉션 모델을 사용하는데 이미지 분류 모델이고 지금 까지 훈련한 1,000개의 이미지를 분류해낸다. 아마 백만 개가 넘는 이미지로 학습됐을 것이다.
아주 낮은 레벨을 살펴보고, 거기까지 잠근다음 DNN을 추가하고 그 낮은 레벨까지의 동결하고 추가한 DNN을 학습시킨다.
Understanding transfer learning:the concepts
이전에는 이진 분류기를 구축해서 고양이와 개, 말과 사람을 예측했다. 과적합을 발생하는 경우를 살펴봤고 이를 방지하는 몇 가지 사례를 살펴봤다. 여기서의 문제는 훈련 데이터 규모가 작다는 점과 추출할 수 있는 공통 요소가 너무 많다는 것이다.
이미지 증강을 사용해서도 해결되지 않았다.
이 두 경우 모두 처음부터 모델을 구축한 경우였는데, 이전에 훨씬 많은 데이터를 훈련한 기존 모델을 활용해서 이 모델이 학습한 특징을 활용하면 어떨까? 이것이 바로 전이 학습의 개념이다.
(이미지 증강을 사용해도 훈련 데이터 규모가 작거나,
또한 추출할 수 있는 공통 요소가 너무 많으면 과적합이 발생할 수 있다.
모두 처음부터 모델을 구축한 경우에 발생했는데, 훨씬 더 많은 데이터를 훈련한 기존 모델을 활용해서 모델이 학습한 특징을 활용하는 '전이 학습(Transfer learning)'을 활용할 수 있다.)
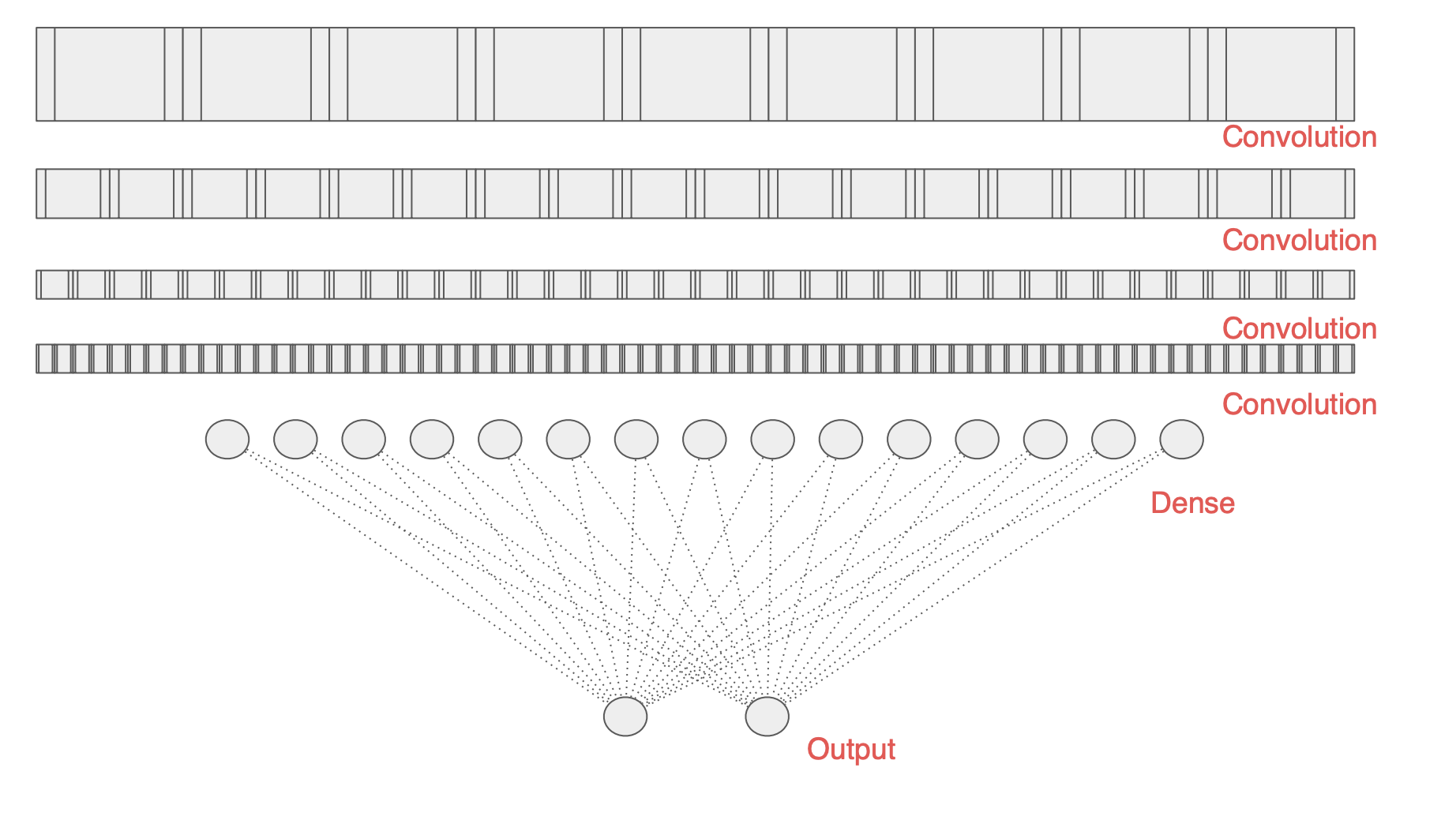
우리가 모델을 이런식으로 일련의 컨볼루션 레이어가 Dense 레이어 그리고 출력 레이어로 이어지게 시각화한다면
상단 레이어에 데이터를 공급하고 신경망이 데이터 내의 특징을 파악하는 컨볼루션을 학습하는 식이다.
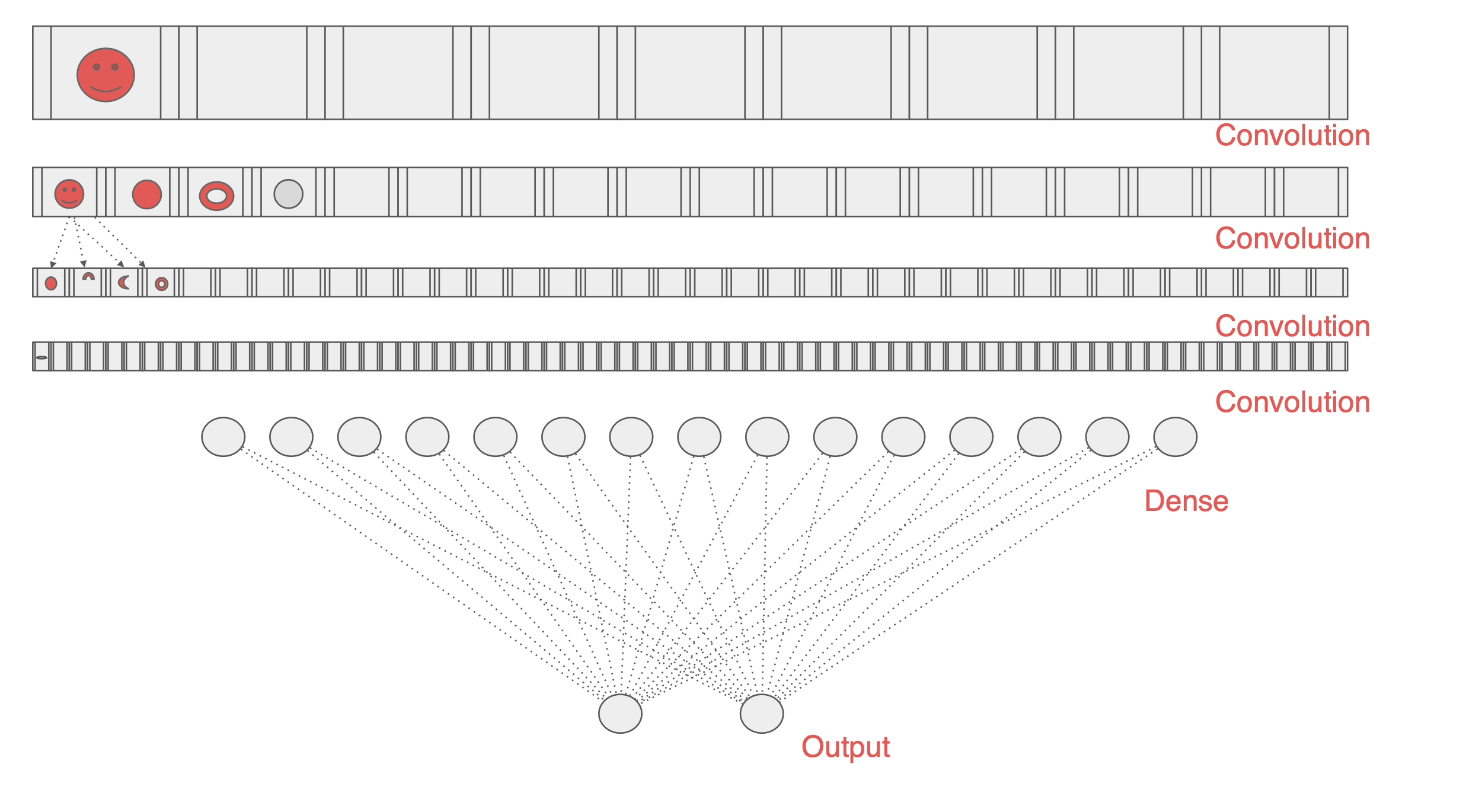
하지만 다른 사람의 모델을 보면,
우리의 모델보다 훨씬 복잡한 모델이고 더 많은 데이터를 학습했다.
컨볼루션 레이어가 있고 이전에 학습한 요소가 내재되어 있다.
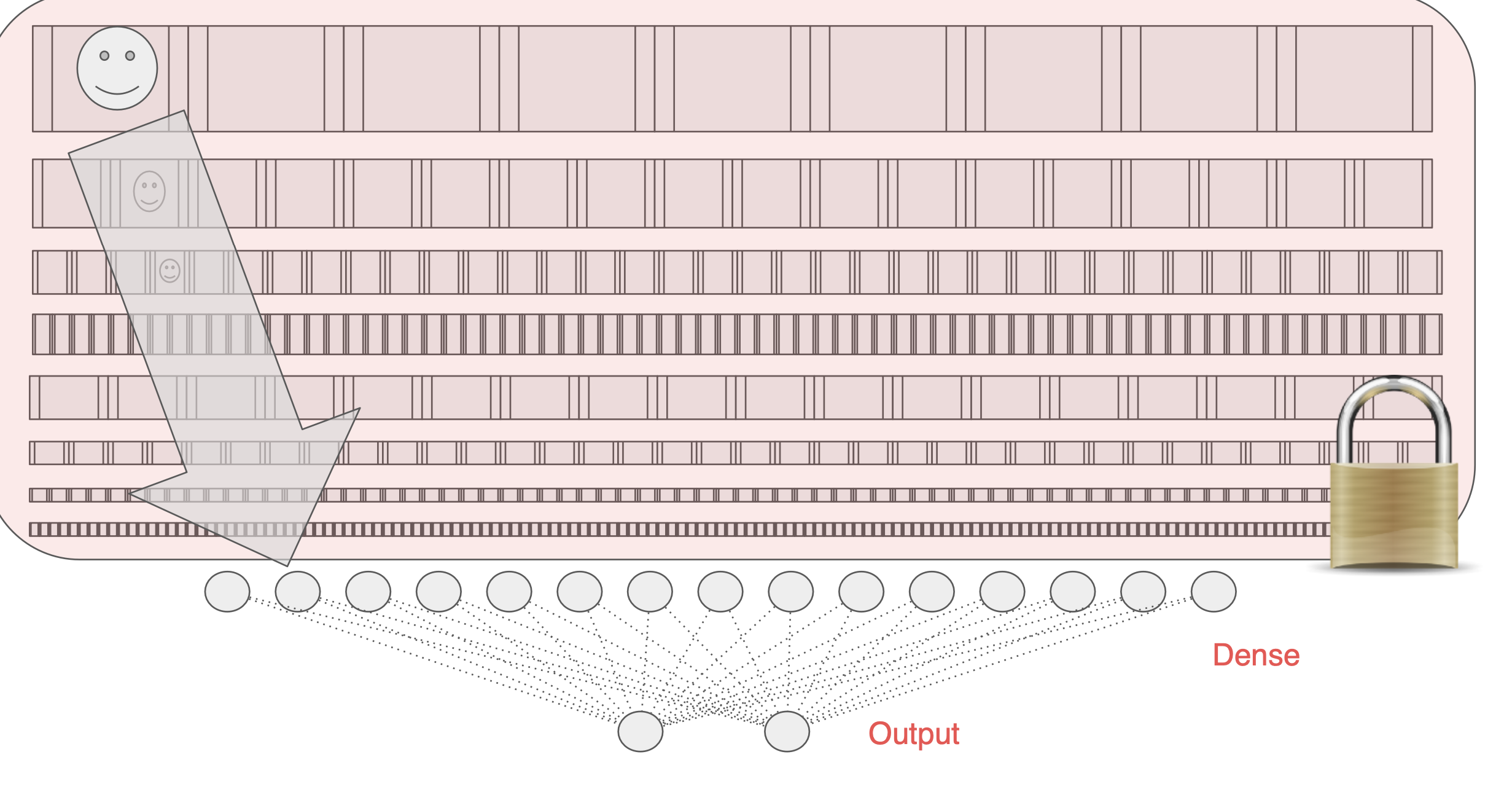
이러한 모델을 다시 훈련시키지 않고 잠근 다음 모델이 이전에 배운 컨볼루션을 활용해서 데이터의 특징을 추출하는 것이다.
그러면 대규모 데이터 세트에 훈련한 모델을 가지고 데이터 분류 시에 이 모델이 학습한 컨볼루션을 활용한다.
특징을 파악하기 위해 컨볼루션을 생성하고 활용하는 방법과 하나의 특징이 신경망을 통과하는 과정을 떠올려보면 다른 모델을 활용하는게 이해가 될 것이다.
그 모델의 Dense 레이어를 다시 우리의 데이터에 훈련시키는 것이다.
물론 이 컨볼루션 전체를 잠가야 할 수 도 있지만 그러지 않아도 된다. 아래쪽에 있는 몇 가지 컨볼루션은 다시 학습해도 된다.
이미지에 바로 쓰기는 너무 세분화 되어 있을 수 있다.
제대로된 조합을 찾기까지 시행착오가 있을 수 있다.
아주 훈련이 잘된 모델을 살펴보면 인셉션 모델이라는 것인데,
위 사이트에 더 자세히 살펴 볼 수 있다.
ImageNet의 데이터 세트로 사전에 훈련을 해서 140만개의 이미지가 1,000개의 클래스로 분류되어 있다.

Coding transfer learning from the inception model
전이 학습을 코드로 구현하는 방법이다.
입력부터 시작하는데, keras의 layers API를 사용해서 레이어를 선택해서 어떤 것을 선택하고 어떤 것을 다시 훈련할 것인지를 선택한다.

이 URL에서 인셉션 신경망을 대상으로 사전에 훈련해 둔 가중치 사본을 확인할 수 있다.
모델을 훈련한 뒤에 보이는 스냅샷이라고 생각하면된다.
그 다음 파라미터를 모델의 뼈대에 불러온 다음 다시 훈련을 완료한 모델에 돌려 놓는 것이다.

이제 인셉션을 사용하는데, Keras 내에 모델의 정의가 내장되어 있다.
이를 우리의 데이터에 맞게 원하는 입력 형태에 맞춰서 인스턴스화 하고 내장된 가중치가 아닌 방금 다운로드한 스냅샷을 사용하겠다고 명시한다.

InceptionV3는 상단에 완전히 연결된 레이어가 있다.
include_top 을 False로 하면 이를 무시하고 컨볼루션으로 넘어가겠다고 명시하는 것이다.

이제 사전에 훈련된 모델을 인스턴스했으므로 레이어를 반복 실행하고 잠가서 해당 코드로 훈련이 불가능하다는 것을 명시한다.

이 코드로 사전에 훈련된 모델의 요약을 출력할 수 있는데, 내용이 아주 방대하다.
Adding your DNN

- 기존 모델에서 레이어를 가져와서 재학습되지 않도록 만드는 방법을 살펴봤다. 즉, 이미 학습된 컨볼루션을 모델에 고정(또는 고정)하는 것이다. 이제 데이터를 재교육할 수 있는 자체 DNN을 맨 아래에 추가해야 한다.
Coding your own model with transferred features
모든 레이어에 이름이 있으므로 사용하려는 마지막 레이어의 이름을 찾아 볼 수 있다. 요약을 살펴보면 아래쪽 레이어가 3x3 으로 컨볼루션된 것을 확인할 수 있다.
하지만 좀 더 자세한 정보가 있는 것을 사용하고자 하는데, 그래서 모델 설명 위로 이동해 mixed7을 선택하기로 한다.
mixed7은 7x7 이라는 많은 컨볼루션의 출력이다.
이 계층을 사용할 필요는 없고 다른 계층으로도 실험할 수 있다.
하지만 여기서는 처음부터 이 레이어를 가져와 출력에 적용한다.

이제 last_output이라고 불리는 인셉션 모델의 mixed7 레이어에서 출력값을 가져와 새 모델을 정의한다.
이 모델은 강좌 시작시 만들었던 Dense 모델과 동일하게 보일 것이다.
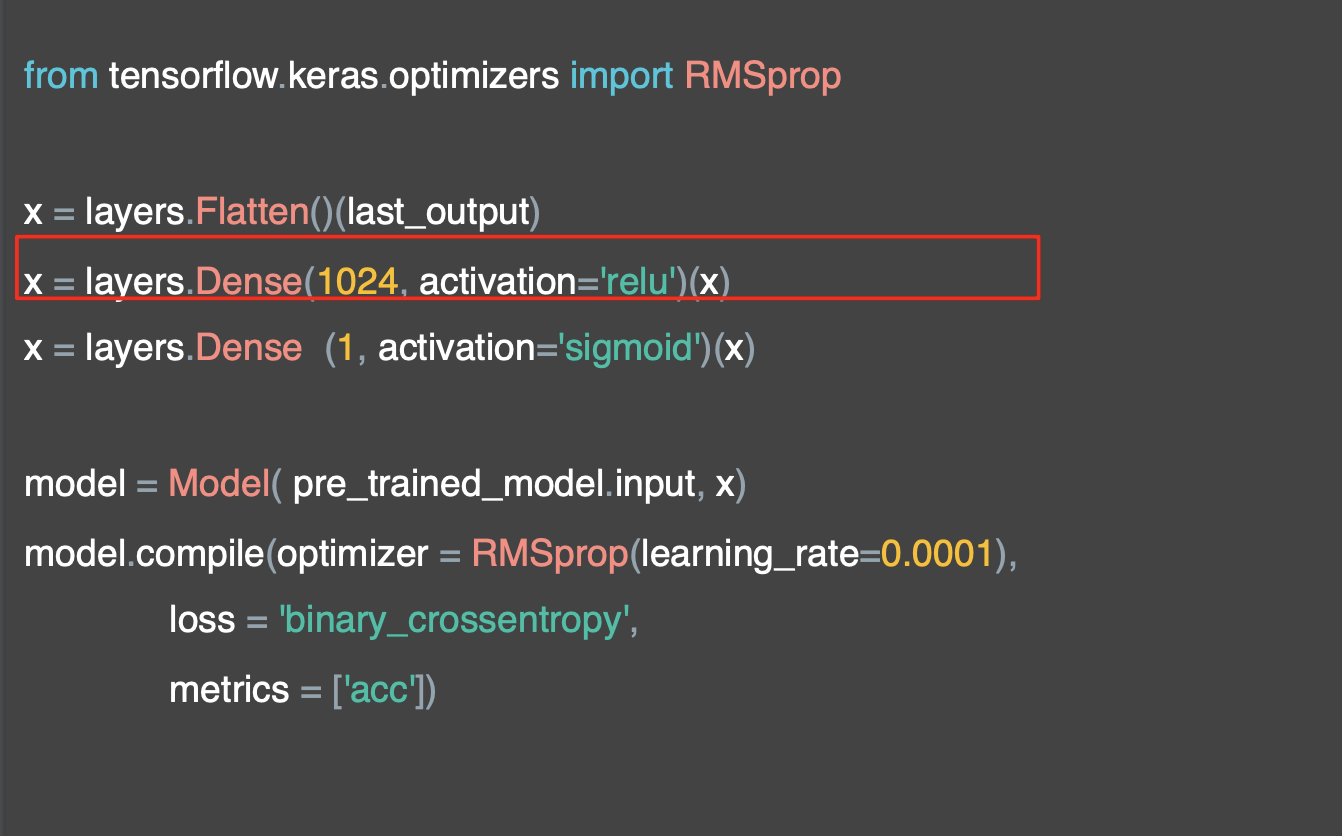
코드는 조금 다르지만 이 방법은 레이어 API를 사용하는 다른 방법이다.
먼저 입력을 평면화하는 것으로 시작하는데, 이것은 인셉션의 출력이다.

다음으로 Dense 레이어를 추가하는데,
마지막 레이어에서 2 클래스를 분류하기 위해 시그모이드에 의해 활성화된 뉴런 하나만 있는 출력 레이어가 있다.

그런 다음 Model 추상 클래스를 사용해 모델을 만들 수 있다.
그리고 방금 생성한 입력과 레이어 정의를 전달한다.

그런 다음 옵티마이저, 손실 함수, 수집하려는 메트릭을 사용하여 컴파일한다.
이미지 생성기를 사용하여 이미지를 보강한다.

이전과 마찬가지로 지정된 디렉터리에서 모든 확장 과정을 거치면서 생성기로부터 훈련 데이터를 가져온다.

이제 model.fit을 통해 제너레이터를 학습한다.
이를 100 epoch 동안 실행한다.

흥미로운 점은 이렇게 하면 또 다른 과적합 상황에 처하게 된다.
다음은 훈련의 정확도와 검증의 정확도를 비교한 그래프이다.
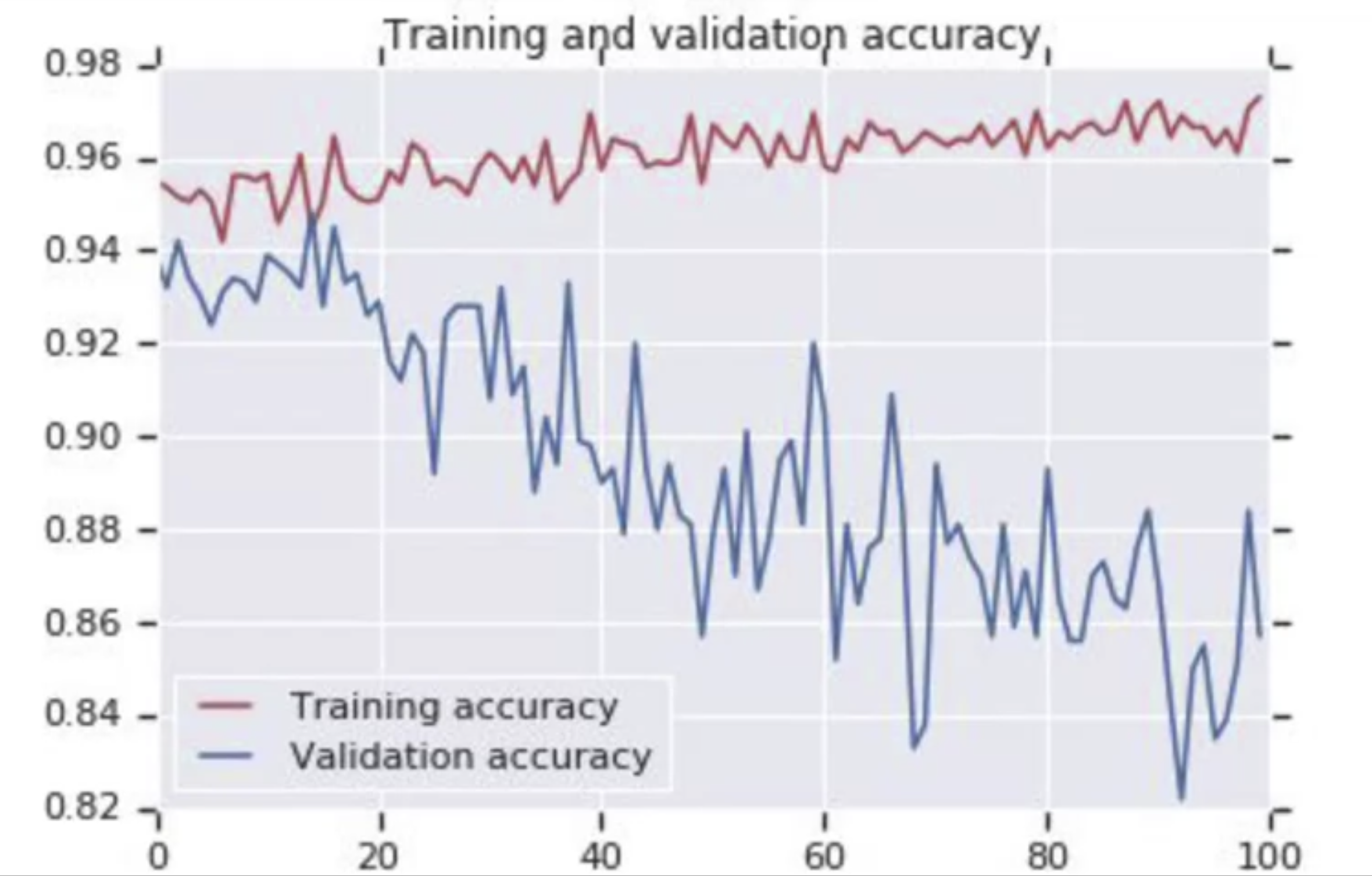
처음에는 순조롭게 진행됐지만 검증이 훈련과 멀어지는 양상을 보이고 있다. 이러한 방법을 해결할 수 있을까?
Using dropout!
훈련이 잘 된 모델인 Inception 모델(ImageNet의 데이터 세트로 140만 개의 이미지가 1,000개의 클래스로 분류됨)을 활용해서 나의 데이터를 기반으로 분류 태스크를 수행할 수 있다. (https://arxiv.org/abs/1512.00567)
Dropout
https://www.youtube.com/watch?v=ARq74QuavAo
Dropout은 신경망에서 무작위 수의 뉴런을 제거하는 것이다.
Dropout은 두 가지 이유로 매우 잘 작동하는데
첫 번째는 인접한 뉴런이 종종 비슷한 가중치로 끝나서 과적합으로 이어질 수 있으므로 일부를 무작위로 삭제하면 이를 제거할 수 것이다.
두 번재는 종종 뉴런이 이전 계층의 뉴런의 입력에 과중한 가중치를 부여하여 결과적으로 과도하게 특수화될 수 있다는 것이다.
그래서 dropout은 신경망의 잠재적인 나쁜 효과들을 없앨 수 있다.
Dropout에 대한 추가적인 설명은 아래의 링크를 참고한다.
Exploring dropouts
위에서는 전이 학습의 방법을 살펴봤는데, 고양이과 개에서 인셉션 분류기 기능을 사용하면 또 다시 과적합 상황이 발생한다.
이미지 증강을 했음에도 불구하고 과적합이 또 나타나는 것이다.
그래서 이를 피하는 몇 가지 방법을 살펴본다.
100 번이 상의 epoch에서 훈련 세트와 검증 세트의 정확도를 확인하면 좋아보이지 않는다.
Keras에는 Dropout이라는 레이어가 있다.
Dropout이란 신경망의 레이어가 때로 비슷한 가중치를 가지면서 서로 과적합에 이르도록 영향을 준다.
이처럼 크고 복잡한 모델에서는 리스크로 작용한다.
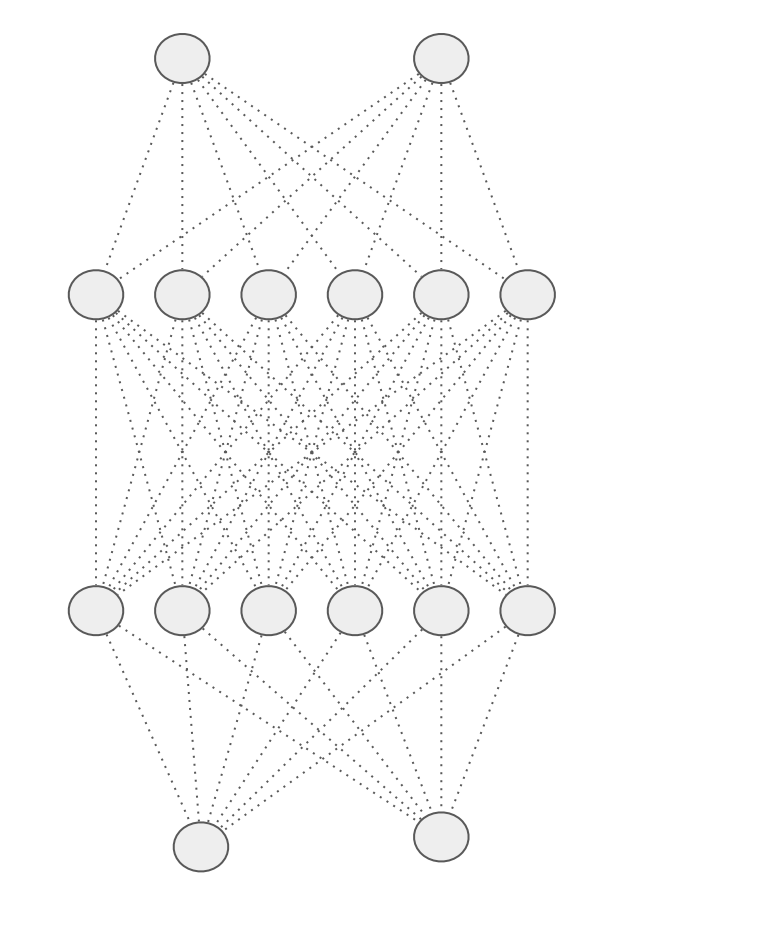
Dense 레이어는 아마 위와 비슷하게 보일 것인데, 일부를 Dropout 하면 아래와 같아진다.
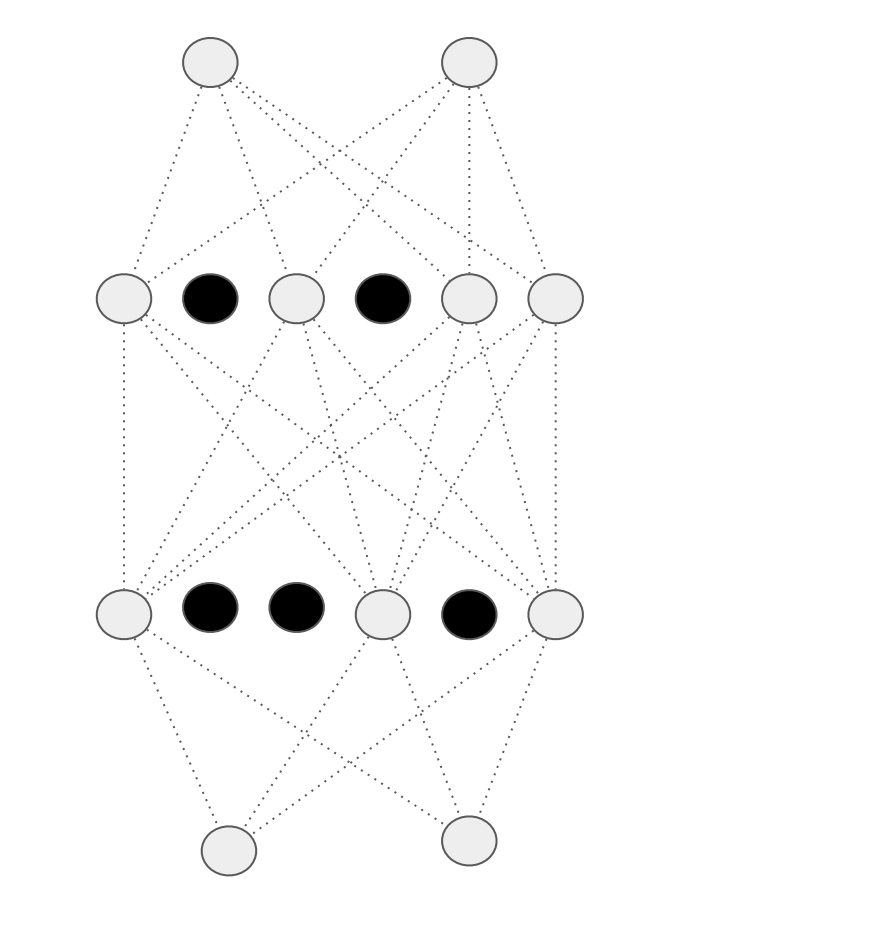
그러면 이웃이 서로 과하게 영향을 주지 않아 과적합을 제거할 수 있다.
코드로 구현해보자.
앞서 다룬 모델의 정의를 살펴본다.

여기에 dropout을 추가했다.

파라미터는 0과 1사이이고 드롭시킬 유닛의 비율을 결정한다.
이 경우 뉴런의 20%를 dropout 하는 것이다.
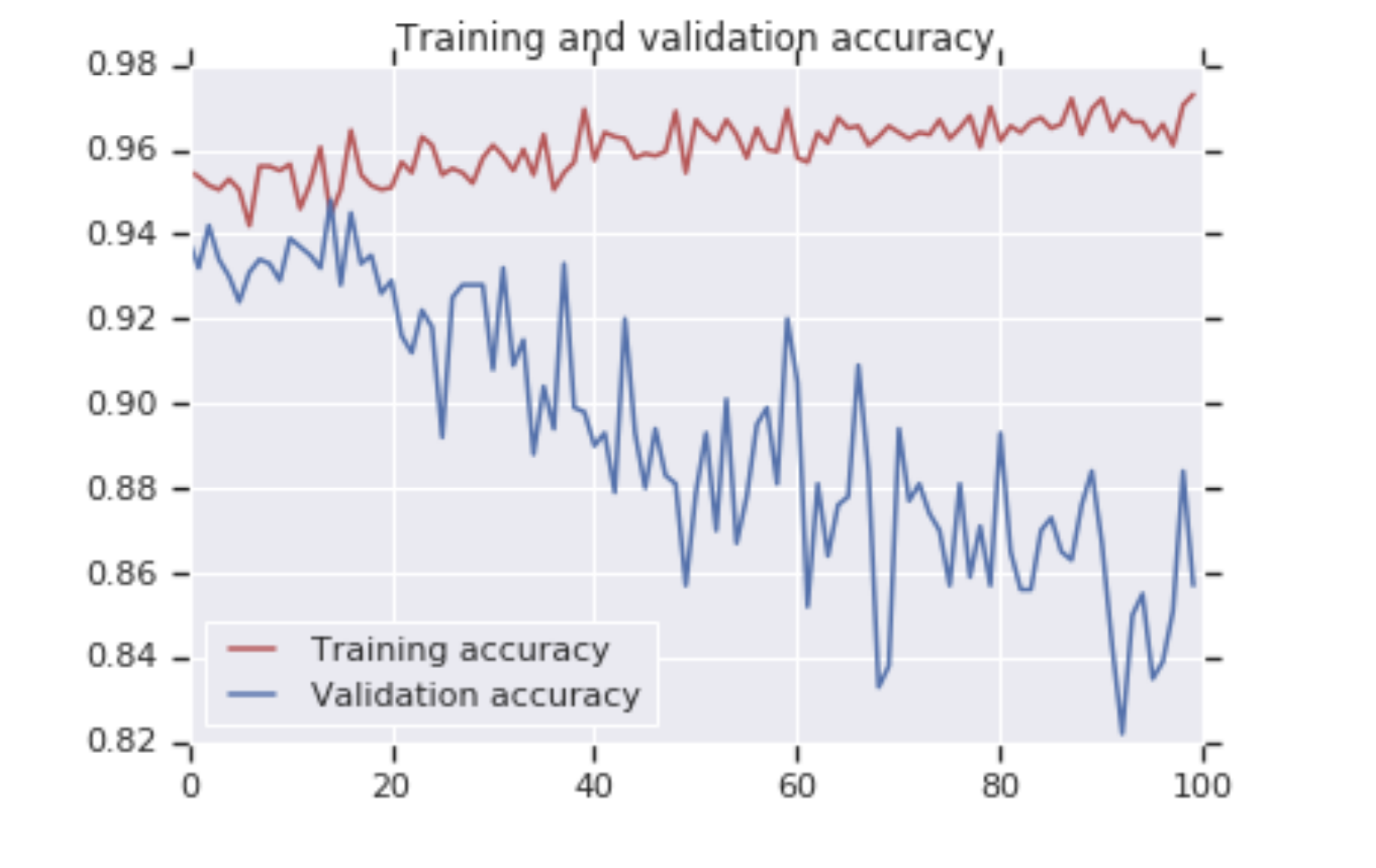
이를 비교해보자, 위는 dropout 추가 전의 훈련 정확도 차트이다. 시간이 가면서 검증 정확도가 훈련 정확도와 많이 달라지므로 dropout을 사용하기에 좋은 후보이다.
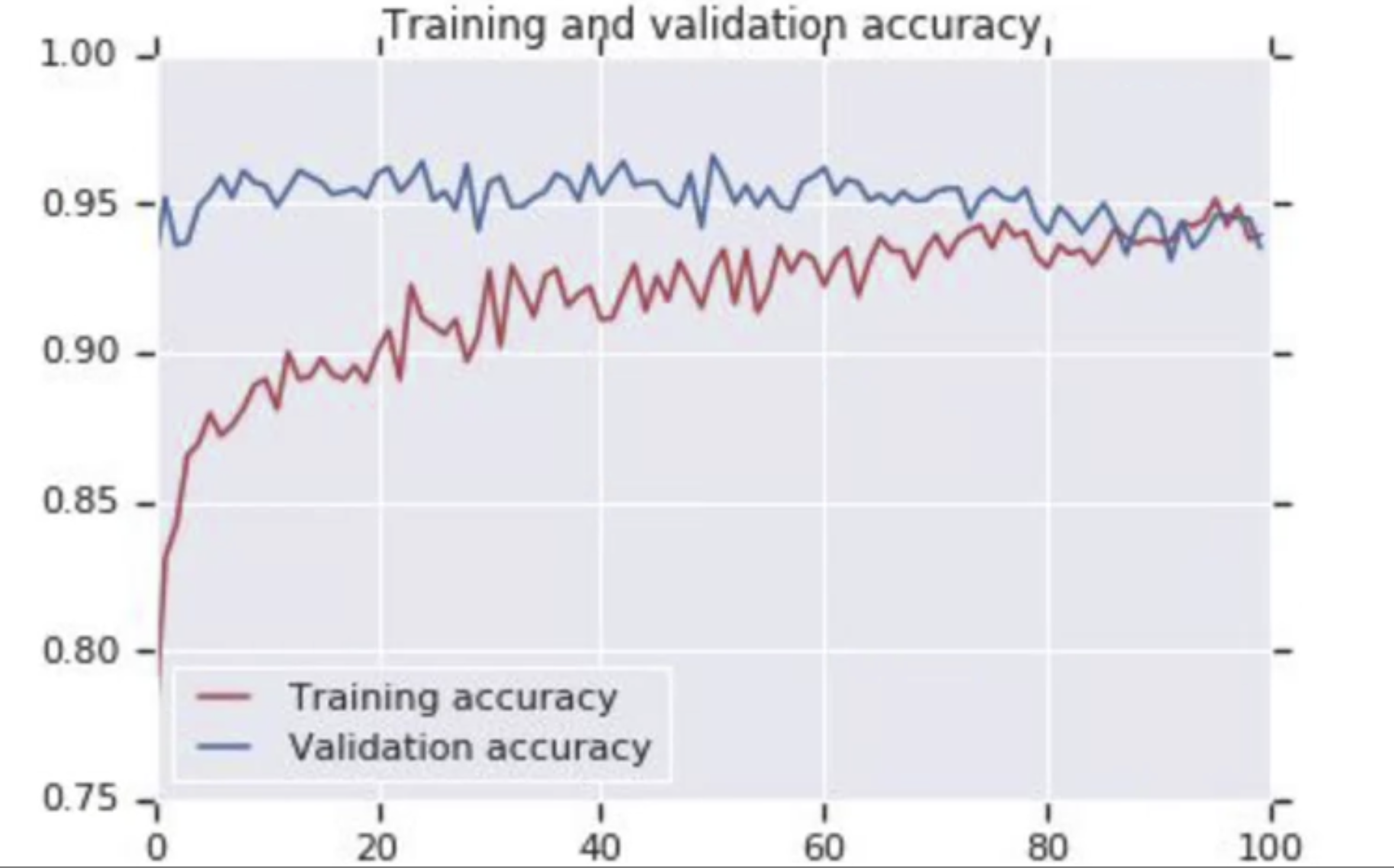
아래는 Dropout의 결과이다. 차이가 보일 것이다.
Exploring Transfer Learning with Inception
전이 학습 프로그래밍 관련 포스팅 참고
[Tensorflow] 2. Convolutional Neural Networks in Tensorflow (3 week Transfer Learning) : programming
먼저 인셉션 네트워크의 가중치를 다운로드하고, 이 가중치를 활용해서 새로운 인스턴스를 인스턴스화한다.
컨볼루션 레이어 중 하나를 입력 레이어로 끌어오고 그 출력값을 사용한다. 이걸 last output으로 지정한다.
이제 모델을 설치해서 last output을 입력값으로 활용한다. 이 값을 1차원으로 만든 다음 Dense layer와 dropout, 출력 레이어가 나오게 된다.
다음 셀에서는 고양이, 개 데이터를 줄인 버전을 다운로드하고 훈련 및 검증 디렉토리에 압축을 풀고 이밎 생성기를 설정한다.
훈련 디렉토리에서는 전과 마찬가지로 이미지 증강을 사용한다.
이미지를 불러와서 올바른 클래스로 분류한다. 2,000개는 훈련용 1,000개는 검증용이다.
20 epoch를 사용해서 학습한다.
훈련 정확도가 점차 높아지고 있고 검증 정확도는 90대 중반으로 안착했다.
완료된 시점을 보면 훈련 정확도는 90%이고 검증은 97%에 가까운 좋은 수치가 발생한다.
이제 20번의 epoch의 곡선을 살펴보면, 과적합을 피했다는 것을 볼 수 있다.
여러 개의 오브젝트를 분류해야 하면 다른 시나리오가 필요할 수 있다.
What have we seen so far?
지금까지 전이 학습을 살펴보았고 기존 모델을 사용하여 많은 레이어를 동결하여 재학습을 방지하고 이미지에 맞게 학습한 컨볼루션을 효과적으로 '기억'하는 방법을 살펴봤다.
그런 다음 다른 모델의 컨볼루션을 사용하여 이미지를 다시 훈련할 수 있도록 이 아래에 자신만의 DNN을 추가했다.
과도한 전문화와 그에 따른 과적합을 방지하는 데 있어 신경망을 보다 효율적으로 만들기 위해 드롭아웃을 사용한 정규화에 대해 배웠다.
