[Tensorflow] 2. Convolutional Neural Networks in Tensorflow (3 week Transfer Learning) : programming
Tensorflow_certification(텐서플로우 자격증)
[Tensorflow] 2. Convolutional Neural Networks in Tensorflow (3 week Transfer Learning) : programming
전이 학습(Transfer Learning)
- 여기서는 사전 학습된 모델을 사용하여 작은 학습 데이터 세트로도 좋은 결과를 얻을 수 있는 방법을 알아본다. 이를 전이 학습이라고 하며 기존 모델의 훈련된 레이어를 활용하고 애플리케이션에 맞게 자체 레이어를 추가하여 이를 수행한다.
예를 들어 다음 과정을 수행한다.
(1) 한 모델의 컨볼루션 레이어를 얻는다.
(2) 그 위에 Dense layer를 붙인다.
(3) Dense 신경망만 학습한다.
(4) 결과를 평가한다.
이렇게 하면 매우 깊은 네트워크에 대한 훈련 시간을 건너뛰게 되어 애플리케이션 구축 시간을 절약할 수 있다. 학습한 기능을 사용하고 데이터 세트에 맞게 조정하면 된다.
[1] Pretrained model 설치
사전 학습된 InceptionV3 모델을 다운로드 받아야 한다.
colab에서 설치시 wget을 사용하고 jupyter notebook을 활용할 때는 request를 사용한다.
import requests
url = "https://storage.googleapis.com/mledu-datasets/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5"
output_path = "inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5"
response = requests.get(url)
with open(output_path, 'wb') as f:
f.write(response.content)다운 받은 사전 학습된 모델을 준비하고 필요한 레이어를 구성해야 한다.
여기서는 InceptionV3 아키텍처의 컨볼루션 레이어를 기본 모델로 사용한다.
애플리케이션에 맞게 입력 형태를 설정한다.
여기서는 150x150x3으로 설정했다.
from tensorflow.keras.applications.inception_v3 import InceptionV3
from tensorflow.keras import layers
local_weights_file = 'inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5'
pre_trained_model = InceptionV3(input_shape=(150,150,3),
include_top= False,
weights= 'imagenet')
pre_trained_model.load_weights(local_weights_file)
for layer in pre_trained_model.layers:
layer.trainable = False
pre_trained_model.summary()
이미 학습한 피처를 활용하기 위해서 컨볼루션 레이어를 선택한다.
기본 모델의 마지막 레이어로 'mixed7'을 선택했다.
last_layer = pre_trained_model.get_layer('mixed7')
print('last layer output shape: ', last_layer.output.shape)
last_output = last_layer.output훈련할 Dense 레이어를 추가한다.
먼저, 모델에 대한 입력을 준비할 때 InceptionV3 모델의 사전 학습된 가중치를 가져오고 나중에 교체할 완전 연결 레이어를 마지막에 제거한다.
모델이 수용할 입력 형태도 지정해야하고, 마지막으로 이러한 레이어는 이미 훈련되었으므로 해당 레이어의 가중치를 고정한다.
[2] Add dense layers for your classifier
분류기에 Dense layer를 추가 한다.
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras import Model
x = layers.Flatten()(last_output)
x = layers.Dense(1024, activation='relu')(x)
x = layers.Dropout(0.2)(x)
x = layers.Dense(1, activation='sigmoid')(x)
model = Model(pre_trained_model.input, x)
model.summary()
선택한 mixed7 레이어 뒤로 쌓은 Dense layer, dropout한 layer들이 쌓인것을 볼 수 있다. 기존의 InceptionV3 모델을 다시 한 번 보자면
아래와 같은 스트럭처 였다.
그리고 옵티마이저는 RMSprop, loss는 binary_crossentropy를 사용하여 모델을 컴파일 한다.
import tensorflow as tf
model.compile(loss='binary_crossentropy',
optimizer=tf.keras.optimizers.RMSprop(learning_rate=0.001),
metrics=['accuracy'])[3] Prepare the dataset
이제 데이터세트를 준비한다.
여기서는 저번에 사용했던 강아지/고양이 데이터를 사용한다.
import os
base_dir = 'cats_and_dogs_filtered'
train_dir = os.path.join( base_dir, 'train')
validation_dir = os.path.join( base_dir, 'validation')
# Directory with training cat pictures
train_cats_dir = os.path.join(train_dir, 'cats')
# Directory with training dog pictures
train_dogs_dir = os.path.join(train_dir, 'dogs')
# Directory with validation cat pictures
validation_cats_dir = os.path.join(validation_dir, 'cats')
# Directory with validation dog pictures
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
print(train_dir)
print(validation_dir)
print(train_cats_dir)
print(train_dogs_dir)
print(validation_cats_dir)
print(validation_dogs_dir)
# output
cats_and_dogs_filtered/train
cats_and_dogs_filtered/validation
cats_and_dogs_filtered/train/cats
cats_and_dogs_filtered/train/dogs
cats_and_dogs_filtered/validation/cats
cats_and_dogs_filtered/validation/dogsImageDataGenerator를 생성해서, 데이터 증강 기술 또한 포함한다.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(
rescale=1./255.,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True,
shear_range=0.2,
zoom_range=0.2,
)
test_datagen = ImageDataGenerator(
rescale=1./255.
)
train_generator = train_datagen.flow_from_directory(
train_dir,
batch_size=20,
target_size=(150,150),
class_mode='binary'
)
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150,150),
batch_size=20,
class_mode='binary'
)
# output
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.[4] model Training
history = model.fit(train_generator,
steps_per_epoch=100,
validation_data=validation_generator,
epochs=20,
validation_steps=40,
verbose=2)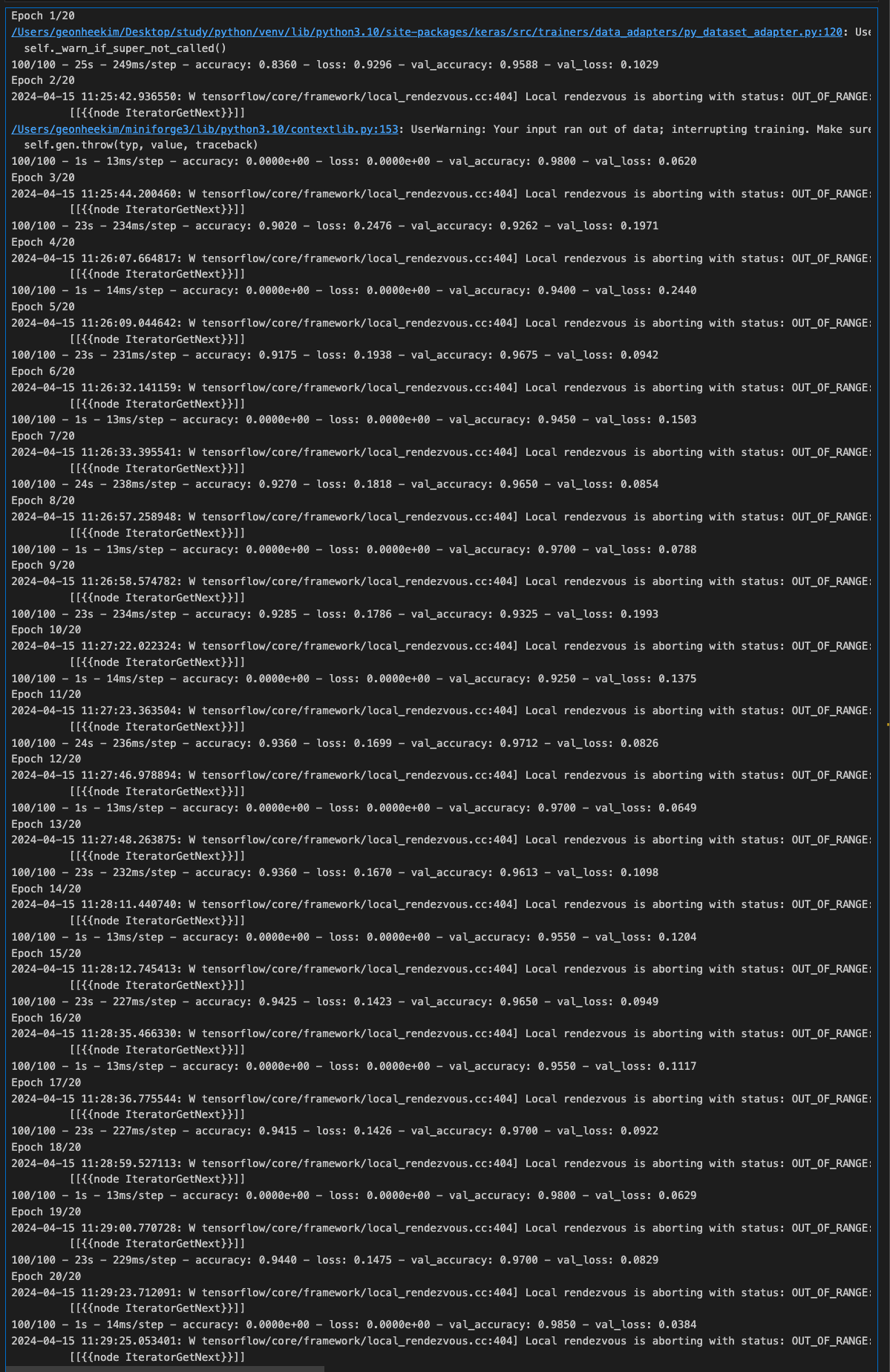
[5] Evaluate the result
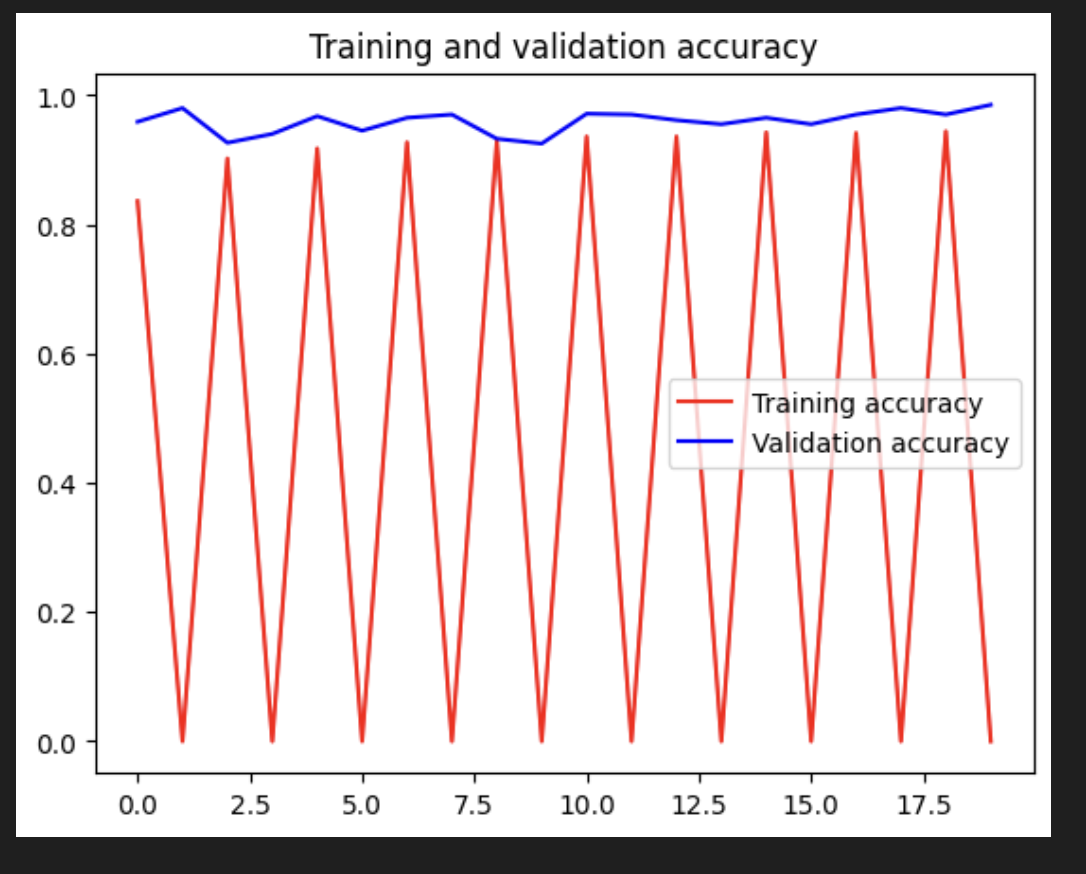
모델을 평가하고 결과를 출력해본다.
보시다시피, 훈련 정확도가 향상됨에 따라 검증 정확도도 높아지는 추세이다.
이는 모델이 더 이상 과적합되지 않는다는 좋은 신호이다.