[Tensorflow] 2. Convolutional Neural Networks in Tensorflow (4 week Multiclass Classifications) - lecture
Tensorflow_certification(텐서플로우 자격증)

[Tensorflow] 2. Convolutional Neural Networks in Tensorflow (4 week Multiclass Classifications) - lecture
2개 이상의 클래스를 다루는 분류기 만들기
Instrucing the Rock-Paper-Scissors
가위,바위,보 3개의 클래스로 구성된 데이터 셋으로 다중 클래스 분류기 만들기
지금까지는 말과 사람, 고양이와 개를 훈련하면서 단 2개의 출력값 클래스에 한정된 분류 문제를 다렀다
많은 경우 2개 이상의 출력값 클래스를 다룬다.
예를 들어 가위바위보는 잠재적으로 3개의 클래스를 지닌다.
이번 장은 이를 구현하는 방법을 자세히 다룬다.
이번 장은 다중 클래스 분류기 구축시 코드 상의 주요 차이점을 살펴본다. 이미지 데이터 생성기에서는 이들이 속한 디렉토리에 따라 자동으로 레이블이 지정된다.
즉, 가위바위보 데이터셋을 살펴 보면 가위, 바위, 보의 하위 디렉토리를 구성하고 안에 이미지가 있는 것이다.
이제 이미지 데이터 생성기가 이진 모드가 아닌 다중 크래스 모드에서 어떻게 작동하는지 살펴본다.
또한 컨볼루션 신경망의 DNN 파트에서 코드가 어떻게 변하는지 보고 이를 통해 다중 클래스를 효율적으로 다룬다.
여기서는 컴퓨터 그래픽으로 생성한 가위,바위,보 데이터셋을 사용할 것이다. 데이터 세트 생성 시 경험한 현상 중 하나는 데이터에 접근하는 과정이었는데, 가위바위보 데이터 세트를 구축하려면 다양한 인종의 손이 필요하다. 아시아인의 손/ 흑인의 손/ 남성, 및 여성의 손, 메니큐어, 끝이 뾰족한 손, 큰 손, 작은 손 등 실제 이미지로 하려면 많은 모델이 필요한데 예산은 충분하지 않아서 모든 요소에 대해서 CGI 로 제작한다.
컨볼루션의 핵심은 특징을 추출하는 것으로 손톱의 생김새, 손의 생김새가 중요하므로 손 사진과 동일한 데이터를 생성했다.
딥러닝의 흥미로운 점 하나는 컴퓨터 그래픽으로 이미지를 생성해서 부족한 데이터를 공급하는 수준에 도달했다는 것이다.
그래도 그래픽을 사용하는게 완벽하고 확실하지 않아 종종 문제가 발생하긴 한다.
Moving from binary to multi-class classification
지금까지 구축한 이진분류기는 서로 다른 두 가지 유형의 오브젝트(말/사람, 고양이/개)를 구분한다.
여기서는 여러 개의 클래스로 확장해본다.
말과 사람을 구분할 때는 아래와 같은 파일 구조를 사용했다.
각 클래스 별로 하위 디렉토리가 있고 이 경우에는 2개 였다.
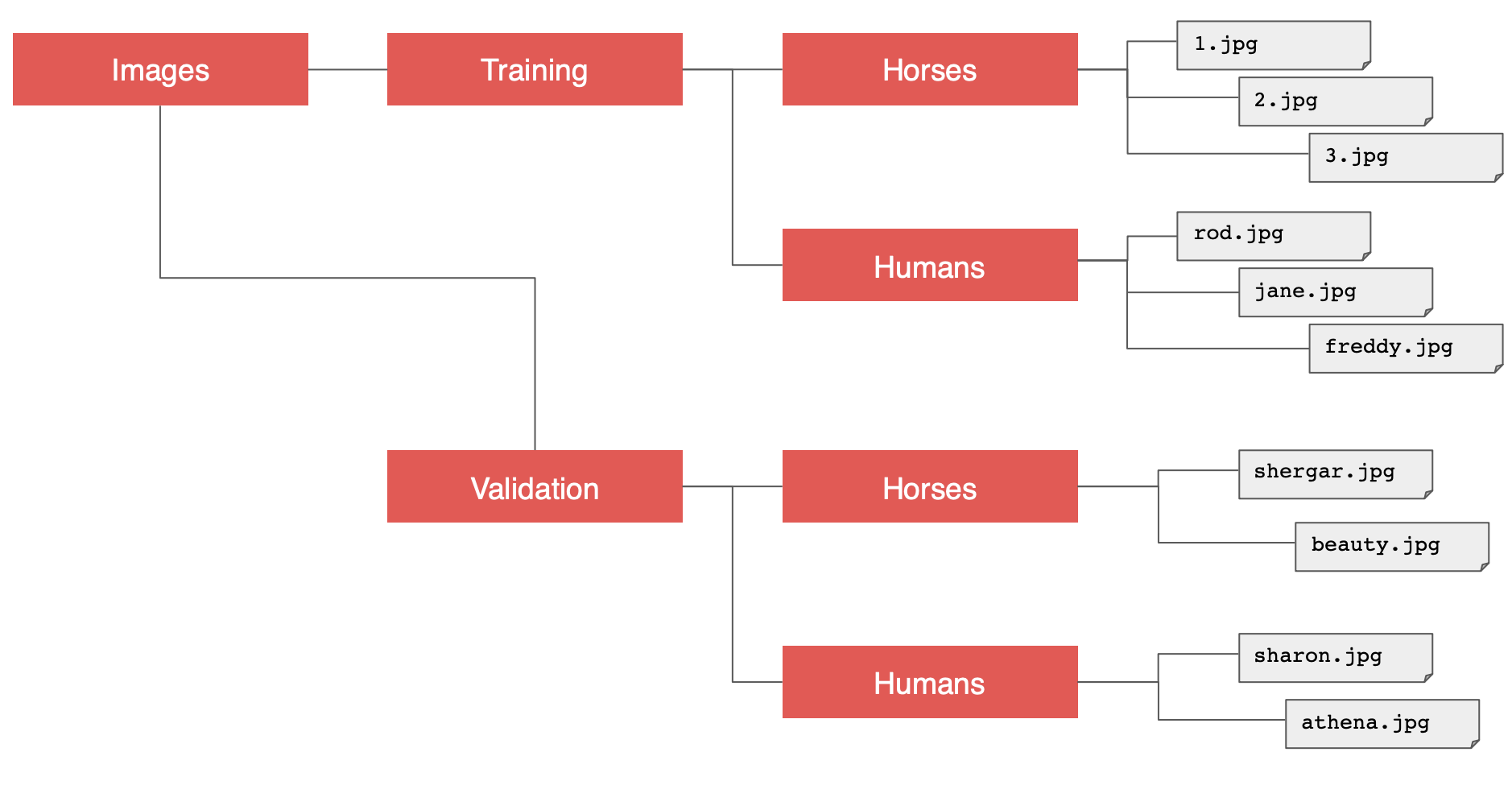
가장 먼저 할일은 다중 클래스로 복제하는 것이다.
훈련과 검증 모두 3개의 하위 디렉토리를 보유한다.
가위, 바위, 보로 각각에 해당하는 디렉토리이다.
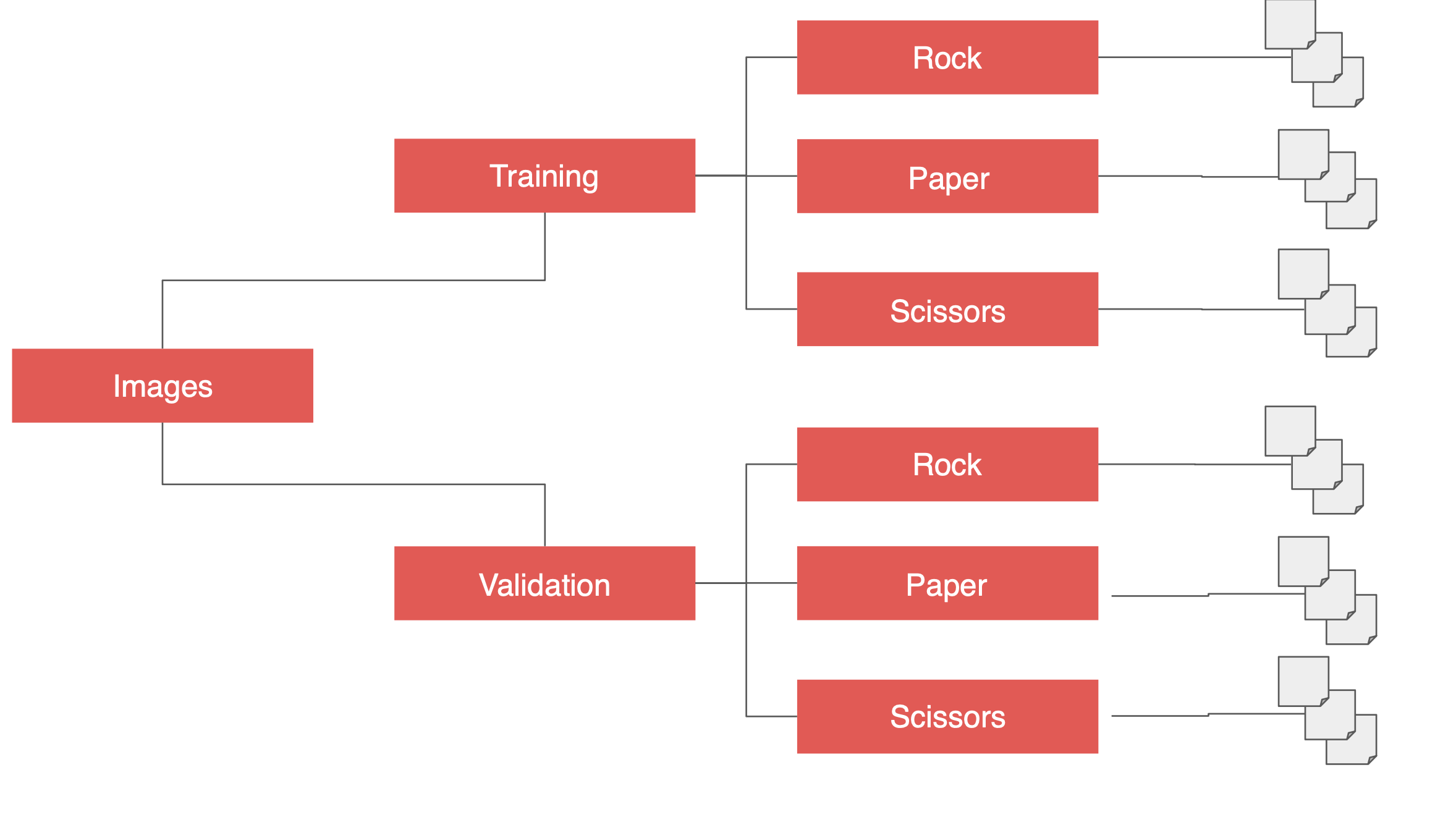
여기에 가위, 바위, 보에 해당하는 훈련 및 검증 이미지를 넣는다.
Introducing the Rock-Paper-Scissors dataset
-
가위바위보 자세를 취한 다양한 손 이미지 2,892개가 포함된 데이터세트이다. 라이센스가 있으므로 모든 목적으로 사용할 수 있지만 주로 학습과 연구를 위한 것이다.
-
가위바위보에는 다양한 인종, 연령, 성별의 다양한 손에서 찍은 이미지가 포함되어 있으며 가위바위보 또는 라벨이 붙어 있다. 훈련과 검증 데이터를 다운로드 할 수 있.
이러한 이미지는 모두 CGI 기반 데이터 세트를 실제 이미지에 대한 분류에 사용할 수 있는지 확인하기 위한 실험으로 CGI 기술을 사용하여 생성되었다. 또한 예측에 사용할 수 있는 몇 가지 이미지도 생성했다. -
이 모든 데이터는 흰색 배경에 배치되어 있고, 각 이미지는 24비트 색상의 300×300픽셀이다.
Explore multi-class with Rock Paper Scissors dataset
이것은 학습을 위해 만든 새로운 데이터 셋이다.
약 3천개의 이미지로 구성되어 있다. 전부 다양한 모델을 사용해 CGI로 생성했다. 다양한 피부톤과 인종을 포함한다.

데이터 셋을 다운로드하고자 한다면 아래의 링크를 참고한다.
data set : http://www.laurencemoroney.com/rock-paper-scissors-dataset/

이것은 이전에 사용했던 코드이다.
이진 분류로 class_mode가 binary 이다.
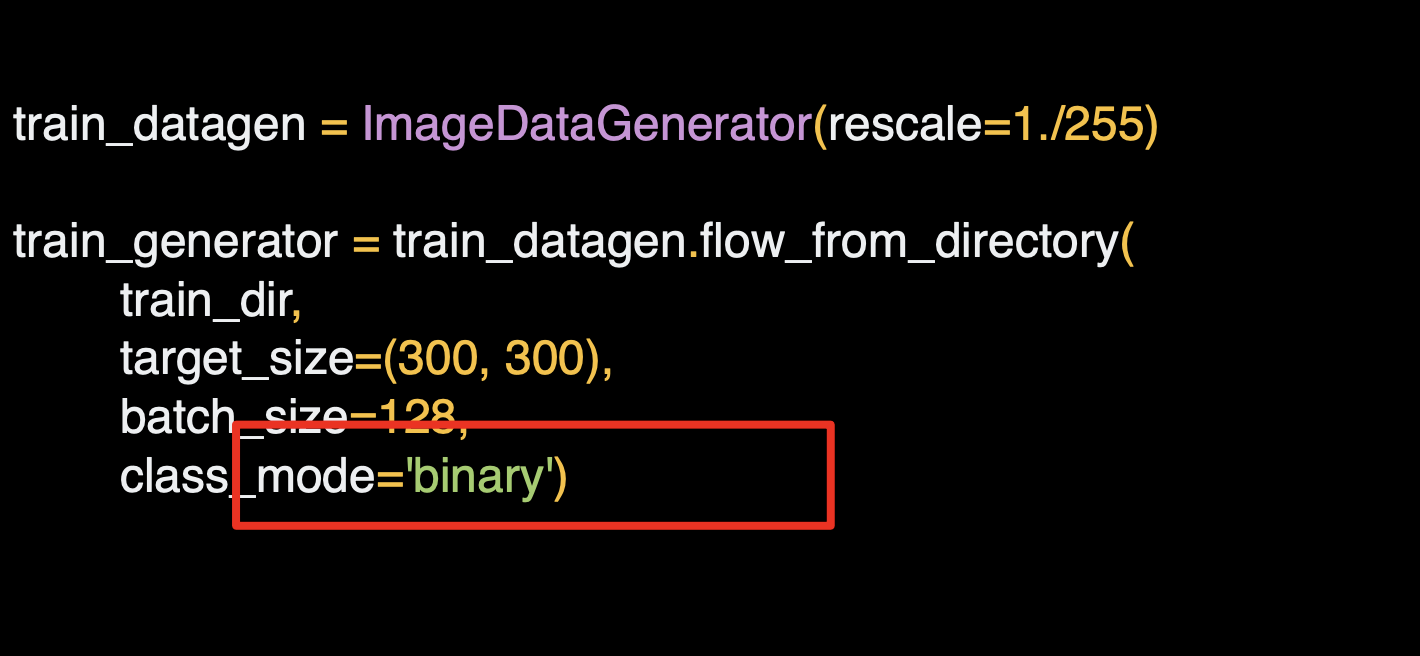
다중 클래스의 경우에는 'categorical'로 바꿔줘야 한다.

다음으로는 모델의 정의 부분이다.
출력 레이어를 바꿔야 하는데, 이진 분류의 경우에는 단 하나의 뉴런을 가지고 sigmoid 함수로 활성화 하는 것이 더 효율적이다. 이 경우 하나의 클래스는 0에 가깝게 하나는 1에 가깝게 예측한다.

다중 분류에는 3개의 뉴런이 있는 출력 레이어 (가위, 바위, 보) 이므로 softmax로 활성화된다. 모든 값을 확률로 전환하고 총합은 1이 되게 만든다.

여기서 이렇게 생긴 손을 살펴보면 손이 보일 확률이 나오는데 엄지와 검지를 펼친 상태고 나머지가 붙어있는 형태라 가위로 오인할 수 있다.
3개의 뉴런과 softma로 구성된 신경망 출력은 이를 반영하고 이러한 식으로 표현한다.

바위일 확률은 극히 낮고 보일 확률은 높고 가위일 확률이 조금 있다. 이 모든 확률을 더하면 1이 된다.
마지막으로 변경할 부분은 신경망의 컴파일 부분인데,
앞에서는 loss function을 binary_crossentropy로 지정했다.

다중 클래스는 'categorical_crossentorpy'로 변경한다.

다른 범주형 손실 함수도 있는데 희소 범주형 교차 엔트로피는 패션 mnist에서 사용했는데, 해당 손실함수를 사용해도 된다.
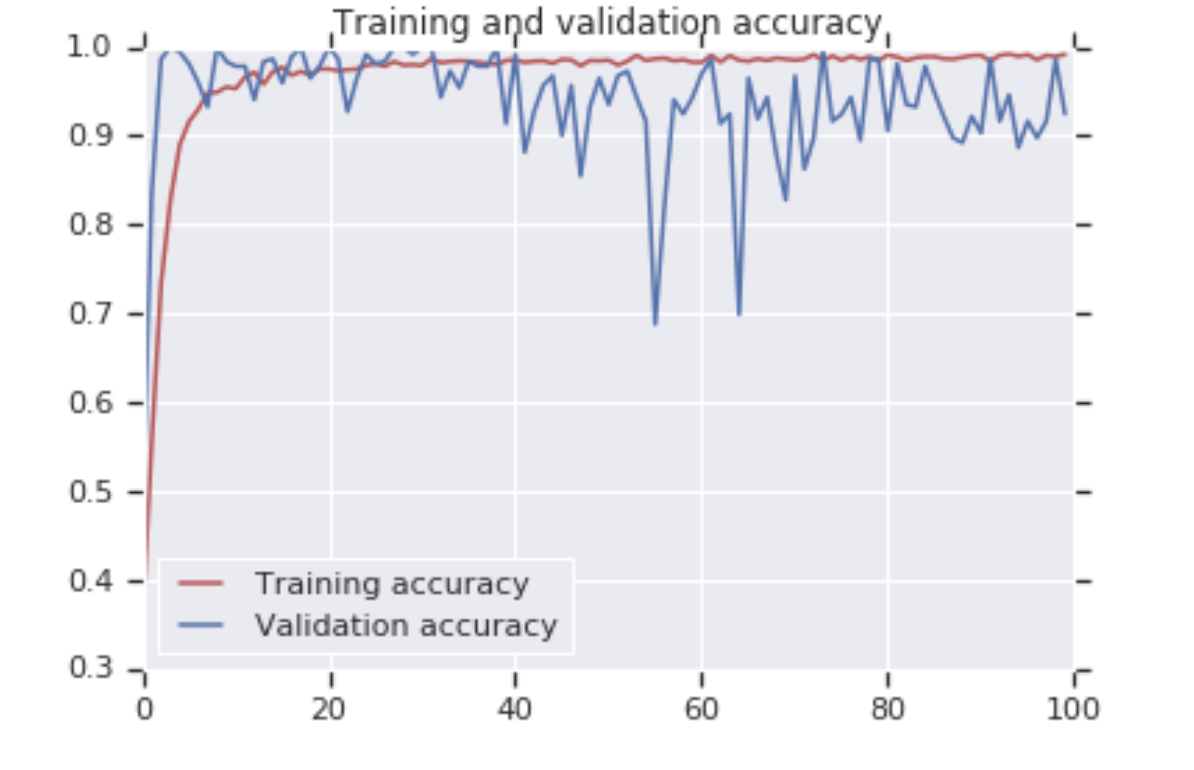
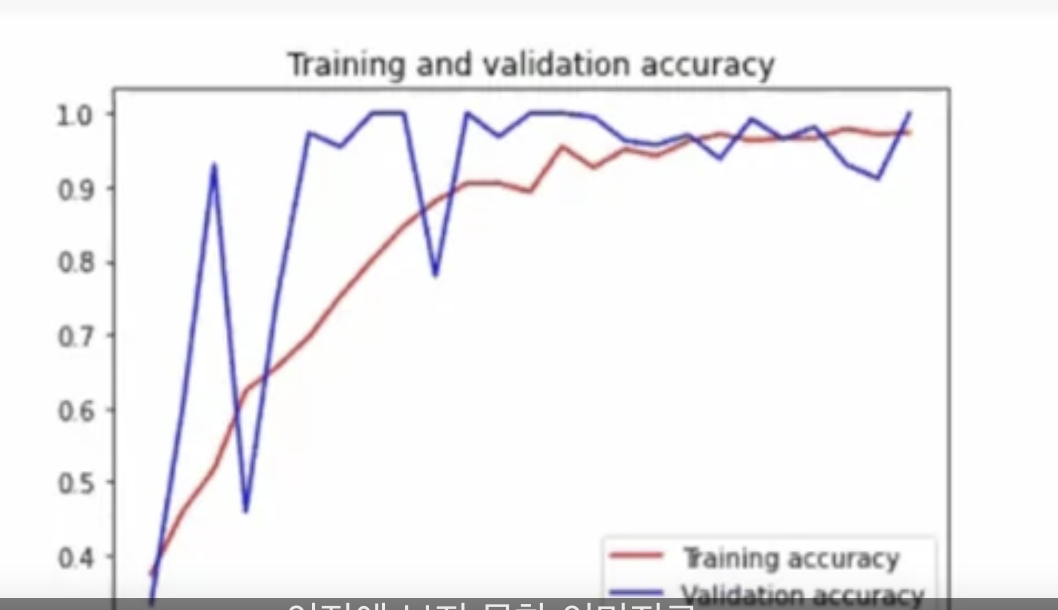
이걸 100번의 epoch로 활용하면 이러한 차트가 나오게 된다.
25번의 epoch 쯤에서 훈련 정확도가 최대치를 찍으니 과하게 epoch를 설정할 필요가 없다.
Tran a classifier with Rock Paper Scissors
다중 클래스 분류 실습의 자세한 정보는 아래의 링크를 확인한다.
첫 단계로 데이터를 다운로드하여 확보한다.
하위 디렉토리에 압축을 푼다음 내부의 파일을 살펴보면, 각 클래스별로 840개가 있고 파일 이름을 볼 수 있다.
파일 몇 개를 살펴보고 데이터가 어떻게 생겼는지 볼 수 있ㄸ.
피부 색이 다른 여러 개의 손이 있다.
모델을 구축하는데 이미지는 300x300 이지만 이미지 생성기를 설정해서 편차를 150x150으로 줄인다.
생성기가 이미지의 크기를 조정해 훈련 디렉토리에 증강시킨다.
모델을 구성하고 학습을 수행한다.
정확도 및 검증 정확도를 주목해서 보면, 25 epoch로 학습했을 때 10 epoch 쯤에서 이미 수치가 잘 나오기 시작한다.
훈련 데이터 정확도는 98%, 검증 데이터는 95%에 도달한다.
정확도를 플롯해보면 정확도는 1.0에 도달하고 있고,
검증은 왔다갔다하지만 초기 epoch 이후에는 계속 0.9-1 사이이다.
Try testing the clasifier
모델이 이전에 모지 못한 이미지로 한번 테스트 해보자.
Test the Rock Paper Scissors classifier
테스트시 사용할 수 있는 몇 가지 이미지를 이용해서 모델을 테스트 해본다. 이미지 생성기에서는 디렉토리에서 클래스를 활용하므로 알파벳 순으로 정렬된다.
그러므로 첫 번째 값은 보(paper), 바위(rock) , 가위(scissors) 이다.
이번 코스에서는
ML의 작동 방식을 이해하는 첫 번째 원칙부터 DNN을 사용하여 기본 컴퓨터 비전을 수행하고 그 이상으로 컨볼루션을 다뤘다.
그런 다음 컨볼루션을 사용하여 이미지에서 특징을 추출하는 방법을 살펴봤고, 컨볼루션 및 풀링을 사용하여 구축하고 복잡한 여러 크기의 이미지를 처리하는 TensorFlow 및 Keras의 도구를 이용했다.
이를 통해 과적합이 분류기에 어떻게 영향을 미칠 수 있는지 확인하고 이를 방지하기 위한 이미지 확대, 드롭아웃, 전이 학습 등의 몇 가지 전략을 살펴봤다. 마무리하기 위해 다중 클래스 분류를 위한 모델을 구축하기 위한 코드를 확인했다.
