[Tensorflow] 3. Natural Language Processing in TensorFlow (2 week Word Embeddings) : Programming (3)
Tensorflow_certification(텐서플로우 자격증)
[Tensorflow] 3. Natural Language Processing in TensorFlow (2 week Word Embeddings) : Programming (3)
IMDB 리뷰 데이터 세트를 사용한 하위 단어 토큰화
- 하위 단어(subword) 텍스트 인코딩을 사용하는 사전 토큰화된 데이터세트를 살펴본다.
- 이전에는 단어 기반 토큰화(word-based)을 사용했었고, 이러한 단어 기반 토큰화와 하위 단어 텍스트 인코딩과의 어떤 차이가 있는지 확인해본다.
[1] Download the IMDB reviews plain texgt and tokenized datasets
- 먼저 Tensorflow Datasets에서 IMDB 리뷰 데이터세트를 다운로드한다. 다운로드 시 두 가지 구성이 제공된다.
plain_text - 기본값이며 Programming (1) 에서 사용했었다.
subwords8k - 사전 토큰화된 데이터 세트(즉, 문자열 유형의 문장 대신 이미 토큰화된 시퀀스를 제공한다
import tensorflow_datasets as tfds
# Download the plain text default config
imdb_plaintext, info_plaintext = tfds.load("imdb_reviews", with_info=True, as_supervised=True)
# Download the subword encoded pretokenized dataset
imdb_subwords, info_subwords = tfds.load("imdb_reviews/subwords8k", with_info=True, as_supervised=True)
[2] Compare the two datasets
- 언급한 대로 두 데이터 세트에서 반환되는 데이터 유형은 서로 다르다.
기본값의 경우 문자열이다.
# feature에 대한 설명
info_plaintext.features
# output
FeaturesDict({
'label': ClassLabel(shape=(), dtype=int64, num_classes=2),
'text': Text(shape=(), dtype=string),
})
2개의 훈련 예제를 선택하고 텍스트 피처를 출력해본다.
for example in imdb_plaintext['train'].take(2):
print(example[0].numpy()
# output
b"This was an absolutely terrible movie. Don't be lured in by Christopher Walken or Michael Ironside. Both are great actors, but this must simply be their worst role in history. Even their great acting could not redeem this movie's ridiculous storyline. This movie is an early nineties US propaganda piece. The most pathetic scenes were those when the Columbian rebels were making their cases for revolutions. Maria Conchita Alonso appeared phony, and her pseudo-love affair with Walken was nothing but a pathetic emotional plug in a movie that was devoid of any real meaning. I am disappointed that there are movies like this, ruining actor's like Christopher Walken's good name. I could barely sit through it."
b'I have been known to fall asleep during films, but this is usually due to a combination of things including, really tired, being warm and comfortable on the sette and having just eaten a lot. However on this occasion I fell asleep because the film was rubbish. The plot development was constant. Constantly slow and boring. Things seemed to happen, but with no explanation of what was causing them or why. I admit, I may have missed part of the film, but i watched the majority of it and everything just seemed to happen of its own accord without any real concern for anything else. I cant recommend this film at all.'
2024-04-16 14:25:34.588172: W tensorflow/core/kernels/data/cache_dataset_ops.cc:858] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
2024-04-16 14:25:34.588970: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequencesubwords8k에 대한 피처 출력
info_subwords.features
# output
FeaturesDict({
'label': ClassLabel(shape=(), dtype=int64, num_classes=2),
'text': Text(shape=(None,), dtype=int64, encoder=<SubwordTextEncoder vocab_size=8185>),
})subwords8k 훈련 예제 2개에 대한 텍스트 피처 출력
for example in imdb_subwords['train'].take(2):
print(example)
(<tf.Tensor: shape=(163,), dtype=int64, numpy=
array([ 62, 18, 41, 604, 927, 65, 3, 644, 7968, 21, 35,
5096, 36, 11, 43, 2948, 5240, 102, 50, 681, 7862, 1244,
3, 3266, 29, 122, 640, 2, 26, 14, 279, 438, 35,
79, 349, 384, 11, 1991, 3, 492, 79, 122, 188, 117,
33, 4047, 4531, 14, 65, 7968, 8, 1819, 3947, 3, 62,
27, 9, 41, 577, 5044, 2629, 2552, 7193, 7961, 3642, 3,
19, 107, 3903, 225, 85, 198, 72, 1, 1512, 738, 2347,
102, 6245, 8, 85, 308, 79, 6936, 7961, 23, 4981, 8044,
3, 6429, 7961, 1141, 1335, 1848, 4848, 55, 3601, 4217, 8050,
2, 5, 59, 3831, 1484, 8040, 7974, 174, 5773, 22, 5240,
102, 18, 247, 26, 4, 3903, 1612, 3902, 291, 11, 4,
27, 13, 18, 4092, 4008, 7961, 6, 119, 213, 2774, 3,
12, 258, 2306, 13, 91, 29, 171, 52, 229, 2, 1245,
5790, 995, 7968, 8, 52, 2948, 5240, 8039, 7968, 8, 74,
1249, 3, 12, 117, 2438, 1369, 192, 39, 7975])>, <tf.Tensor: shape=(), dtype=int64, numpy=0>)
(<tf.Tensor: shape=(142,), dtype=int64, numpy=
array([ 12, 31, 93, 867, 7, 1256, 6585, 7961, 421, 365, 2,
26, 14, 9, 988, 1089, 7, 4, 6728, 6, 276, 5760,
2587, 2, 81, 6118, 8029, 2, 139, 1892, 7961, 5, 5402,
246, 25, 1, 1771, 350, 5, 369, 56, 5397, 102, 4,
2547, 3, 4001, 25, 14, 7822, 209, 12, 3531, 6585, 7961,
99, 1, 32, 18, 4762, 3, 19, 184, 3223, 18, 5855,
1045, 3, 4232, 3337, 64, 1347, 5, 1190, 3, 4459, 8,
614, 7, 3129, 2, 26, 22, 84, 7020, 6, 71, 18,
4924, 1160, 161, 50, 2265, 3, 12, 3983, 2, 12, 264,
31, 2545, 261, 6, 1, 66, 2, 26, 131, 393, 1,
5846, 6, 15, 5, 473, 56, 614, 7, 1470, 6, 116,
285, 4755, 2088, 7961, 273, 119, 213, 3414, 7961, 23, 332,
1019, 3, 12, 7667, 505, 14, 32, 44, 208, 7975])>, <tf.Tensor: shape=(), dtype=int64, numpy=0>)
2024-04-16 14:26:18.610131: W tensorflow/core/kernels/data/cache_dataset_ops.cc:858] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
2024-04-16 14:26:18.610509: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence다운로드에 포함된 인코더 개체를 가져와 이를 사용하여 위 시퀀스를 디코딩할 수 있다. plain_text 구성에 제공된 것과 동일한 문장에 도달하는 것을 볼 수 있다.
# Get the encoder
tokenizer_subwords = info_subwords.features['text'].encoder
# Take 2 training examples and decode the text feature
for example in imdb_subwords['train'].take(2):
print(tokenizer_subwords.decode(example[0]))
# output
This was an absolutely terrible movie. Don't be lured in by Christopher Walken or Michael Ironside. Both are great actors, but this must simply be their worst role in history. Even their great acting could not redeem this movie's ridiculous storyline. This movie is an early nineties US propaganda piece. The most pathetic scenes were those when the Columbian rebels were making their cases for revolutions. Maria Conchita Alonso appeared phony, and her pseudo-love affair with Walken was nothing but a pathetic emotional plug in a movie that was devoid of any real meaning. I am disappointed that there are movies like this, ruining actor's like Christopher Walken's good name. I could barely sit through it.
I have been known to fall asleep during films, but this is usually due to a combination of things including, really tired, being warm and comfortable on the sette and having just eaten a lot. However on this occasion I fell asleep because the film was rubbish. The plot development was constant. Constantly slow and boring. Things seemed to happen, but with no explanation of what was causing them or why. I admit, I may have missed part of the film, but i watched the majority of it and everything just seemed to happen of its own accord without any real concern for anything else. I cant recommend this film at all.
2024-04-16 14:28:45.082808: W tensorflow/core/kernels/data/cache_dataset_ops.cc:858] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
2024-04-16 14:28:45.100925: W tensorflow/core/framework/local_rendezvous.cc:404] Local rendezvous is aborting with status: OUT_OF_RANGE: End of sequence[3] Subword Text Encoding
train_data = imdb_plaintext['train']
training_sentences = []
for s, _ in train_data:
training_sentences.append(s.numpy().decode('utf8'))
training_sentences[:3]
#output
["This was an absolutely terrible movie. Don't be lured in by Christopher Walken or Michael Ironside. Both are great actors, but this must simply be their worst role in history. Even their great acting could not redeem this movie's ridiculous storyline. This movie is an early nineties US propaganda piece. The most pathetic scenes were those when the Columbian rebels were making their cases for revolutions. Maria Conchita Alonso appeared phony, and her pseudo-love affair with Walken was nothing but a pathetic emotional plug in a movie that was devoid of any real meaning. I am disappointed that there are movies like this, ruining actor's like Christopher Walken's good name. I could barely sit through it.",
'I have been known to fall asleep during films, but this is usually due to a combination of things including, really tired, being warm and comfortable on the sette and having just eaten a lot. However on this occasion I fell asleep because the film was rubbish. The plot development was constant. Constantly slow and boring. Things seemed to happen, but with no explanation of what was causing them or why. I admit, I may have missed part of the film, but i watched the majority of it and everything just seemed to happen of its own accord without any real concern for anything else. I cant recommend this film at all.',
'Mann photographs the Alberta Rocky Mountains in a superb fashion, and Jimmy Stewart and Walter Brennan give enjoyable performances as they always seem to do. <br /><br />But come on Hollywood - a Mountie telling the people of Dawson City, Yukon to elect themselves a marshal (yes a marshal!) and to enforce the law themselves, then gunfighters battling it out on the streets for control of the town? <br /><br />Nothing even remotely resembling that happened on the Canadian side of the border during the Klondike gold rush. Mr. Mann and company appear to have mistaken Dawson City for Deadwood, the Canadian North for the American Wild West.<br /><br />Canadian viewers be prepared for a Reefer Madness type of enjoyable howl with this ludicrous plot, or, to shake your head in disgust.']from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
vocab_size = 10000
oov_tok = '<OOV>'
tokenizer_plaintext = Tokenizer(num_words=vocab_size, oov_token=oov_tok)
tokenizer_plaintext.fit_on_texts(training_sentences)
sequences = tokenizer_plaintext.texts_to_sequences(training_sentences)
위에서는 10000의 vocab_size를 사용하지만 생성된 사전을 사용하여 디코딩할 때 OOV 토큰을 쉽게 찾을 수 있다는 것을 알 수 있다.
이진 분류기의 경우 이는 큰 영향을 미치지 않을 수 있지만 모델을 교육할 때(예: 텍스트 생성) OOV token을 피함으로써 이점을 얻을 수 있는 다른 애플리케이션이 있을 수 있습니다. 위의 토크나이저에 OOV가 없도록 하려면 vocab_size가 88k 이상으로 증가한다. 이로 인해 훈련 속도가 느려지고 모델 크기가 커질 수 있습니다. 또한 새로운 단어가 포함될 수 있는 다른 데이터 세트에 사용될 때 인코더는 강력하지 않아 다시 OOV가 발생한다.
tokenizer_plaintext.sequences_to_texts(sequences[0:1])
# output
["this was an absolutely terrible movie don't be <OOV> in by christopher walken or michael <OOV> both are great actors but this must simply be their worst role in history even their great acting could not redeem this movie's ridiculous storyline this movie is an early nineties us propaganda piece the most pathetic scenes were those when the <OOV> rebels were making their cases for <OOV> maria <OOV> <OOV> appeared phony and her pseudo love affair with walken was nothing but a pathetic emotional plug in a movie that was devoid of any real meaning i am disappointed that there are movies like this ruining actor's like christopher <OOV> good name i could barely sit through it"]하위 단어 텍스트 인코딩은 단어의 일부를 사용하여 전체 단어를 구성함으로써 이 문제를 한다. 이는 일반적이지 않은 단어를 만날 때 더 유연해진다. 이 특정 인코더에 대해 이러한 하위 단어가 어떻게 보이는지 확인해보자.
print(len(tokenizer_plaintext.word_index))
# output
88583
print(len(tokenizer_subwords.subwords))
#output
7928이전 일반 텍스트 문장에 이를 사용하면 어휘 크기가 더 작더라도(위의 10k에 비해 8k에 불과) OOV가 없음을 알 수 있다.
tokenized_string = tokenizer_subwords.encode(training_sentences[0])
print(tokenized_string)
original_string = tokenizer_subwords.decode(tokenized_string)
print(original_string)
# output
[62, 18, 41, 604, 927, 65, 3, 644, 7968, 21, 35, 5096, 36, 11, 43, 2948, 5240, 102, 50, 681, 7862, 1244, 3, 3266, 29, 122, 640, 2, 26, 14, 279, 438, 35, 79, 349, 384, 11, 1991, 3, 492, 79, 122, 188, 117, 33, 4047, 4531, 14, 65, 7968, 8, 1819, 3947, 3, 62, 27, 9, 41, 577, 5044, 2629, 2552, 7193, 7961, 3642, 3, 19, 107, 3903, 225, 85, 198, 72, 1, 1512, 738, 2347, 102, 6245, 8, 85, 308, 79, 6936, 7961, 23, 4981, 8044, 3, 6429, 7961, 1141, 1335, 1848, 4848, 55, 3601, 4217, 8050, 2, 5, 59, 3831, 1484, 8040, 7974, 174, 5773, 22, 5240, 102, 18, 247, 26, 4, 3903, 1612, 3902, 291, 11, 4, 27, 13, 18, 4092, 4008, 7961, 6, 119, 213, 2774, 3, 12, 258, 2306, 13, 91, 29, 171, 52, 229, 2, 1245, 5790, 995, 7968, 8, 52, 2948, 5240, 8039, 7968, 8, 74, 1249, 3, 12, 117, 2438, 1369, 192, 39, 7975]
This was an absolutely terrible movie. Don't be lured in by Christopher Walken or Michael Ironside. Both are great actors, but this must simply be their worst role in history. Even their great acting could not redeem this movie's ridiculous storyline. This movie is an early nineties US propaganda piece. The most pathetic scenes were those when the Columbian rebels were making their cases for revolutions. Maria Conchita Alonso appeared phony, and her pseudo-love affair with Walken was nothing but a pathetic emotional plug in a movie that was devoid of any real meaning. I am disappointed that there are movies like this, ruining actor's like Christopher Walken's good name. I could barely sit through it.하위 단어 인코딩은 영화 리뷰에서 흔히 볼 수 없는 단어에 대해서도 좋은 성능을 발휘할 수 있다. 일반 텍스트 토크나이저를 사용할 때 결과를 확인하면 예상대로 많은 OOV가 표시된다.
sample_string = 'TensorFlow, from basics to mastery'
tokenized_string = tokenizer_plaintext.texts_to_sequences([sample_string])
print(f"Tokenized string is {tokenized_string}")
original_string = tokenizer_plaintext.sequences_to_texts(tokenized_string)
print(f"The original string : {original_string}")
# output
Tokenized string is [[1, 37, 1, 6, 1]]
The original string : ['<OOV> from <OOV> to <OOV>']그런 다음 하위 단어 텍스트 인코더와 비교한다.
tokenized_string = tokenizer_subwords.encode(sample_string)
print(f"tokenized string is {tokenized_string}")
original_string = tokenizer_subwords.decode(tokenized_string)
print(f"The original string : {original_string}")
# output
tokenized string is [6307, 2327, 4043, 2120, 2, 48, 4249, 4429, 7, 2652, 8050]
The original string : TensorFlow, from basics to mastery보시다시피 문장이 올바르게 디코딩 되었다.
단점은 토큰 시퀀스가 훨씬 길다는 것이다.
단어 인코딩을 사용할 때 5개가 아닌 11개의 토큰이 생겼다. 이 문장의 매핑은 아래와 같다.
for ts in tokenized_string:
print(f"{ts} -> {tokenizer_subwords.decode([ts])}")
# output
6307 -> Ten
2327 -> sor
4043 -> Fl
2120 -> ow
2 -> ,
48 -> from
4249 -> basi
4429 -> cs
7 -> to
2652 -> master
8050 -> y[4] Training the model
- 사전 토큰화된 데이터세트를 사용하여 모델을 학습시킨다.
이미 시퀀스로 저장되어 있으므로 열차 및 테스트 세트에 대해 균일한 크기의 배열을 만드는 작업으로 바로 진행한다.
tf.data.Dataset 유형으로 저장되므로 padded_batch() 메서드를 사용하여 배치를 생성하고 훈련을 위해 배열을 균일한 크기로 채울 수 있다.
BUFFER_SIZE = 10000
BATCH_SIZE = 64
# Get the train and test splits
train_data, test_data = imdb_subwords['train'], imdb_subwords['test'],
# Shuffle the training data
train_dataset = train_data.shuffle(BUFFER_SIZE)
train_dataset = train_dataset.padded_batch(BATCH_SIZE)
test_dataset = test_data.padded_batch(BATCH_SIZE)모델을 빌드한다.
import tensorflow as tf
embedding_dim = 64
# Build the model
model = tf.keras.Sequential([
tf.keras.layers.Embedding(tokenizer_subwords.vocab_size, embedding_dim),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(6, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy',
optimizer= 'adam',
metrics= ['accuracy'])
model.summary()
모델 학습
history = model.fit(train_dataset, epochs=10, validation_data=test_dataset)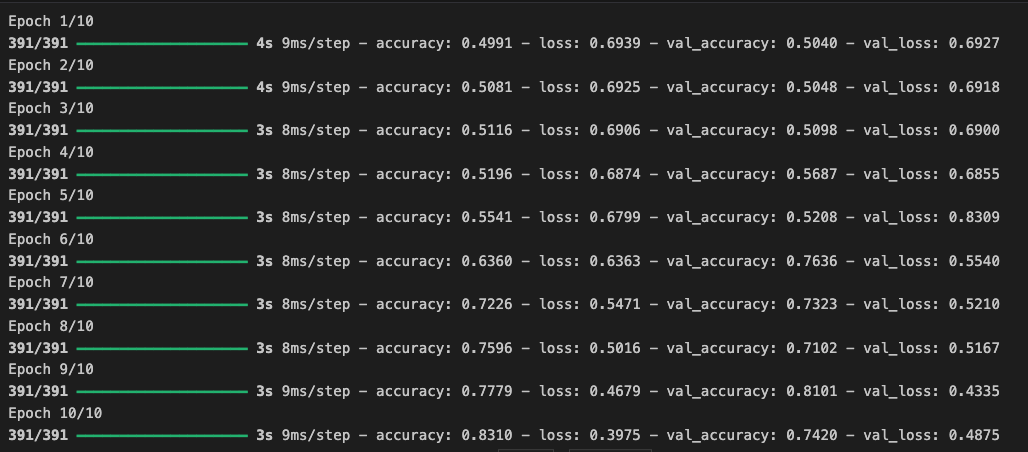
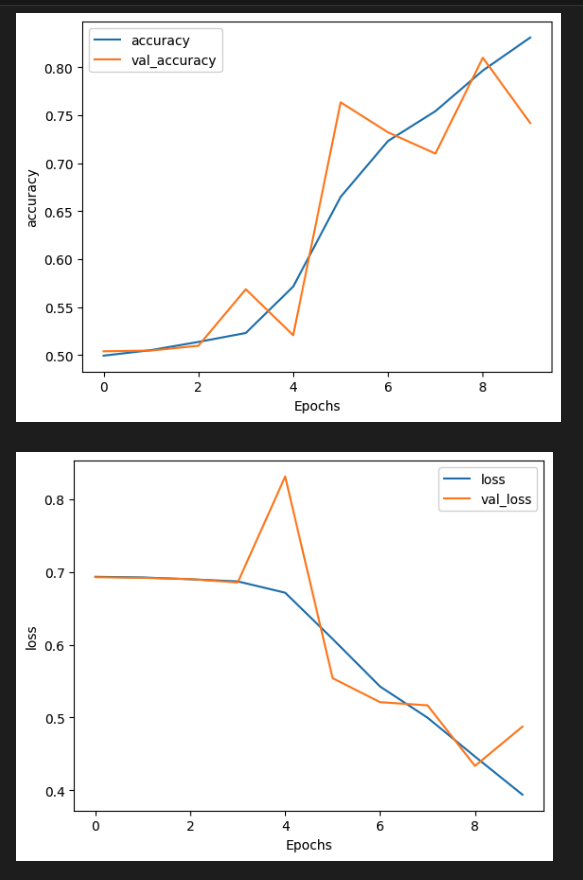
마찬가지로 훈련에도 동일한 매개변수를 사용할 수 있다. 에포크당 약 20초가 걸리며 약 83%의 학습 정확도와 74%의 검증 정확도에 도달했다.
[5] Visualize the results
임베딩 크기, 에포크 수와 같은 매개변수를 조정하여 이를 개선할 수 있다.
import matplotlib.pyplot as plt
# Plot utility
def plot_graphs(history, string):
plt.plot(history.history[string])
plt.plot(history.history['val_'+string])
plt.xlabel("Epochs")
plt.ylabel(string)
plt.legend([string, 'val_'+string])
plt.show()
# Plot the accuracy and results
plot_graphs(history, "accuracy")
plot_graphs(history, "loss")