[Tensorflow] 3. Natural Language Processing in TensorFlow (2 week Word Embeddings) : lecture
Tensorflow_certification(텐서플로우 자격증)
[Tensorflow] 3. Natural Language Processing in TensorFlow (2 week Word Embeddings) : lecture



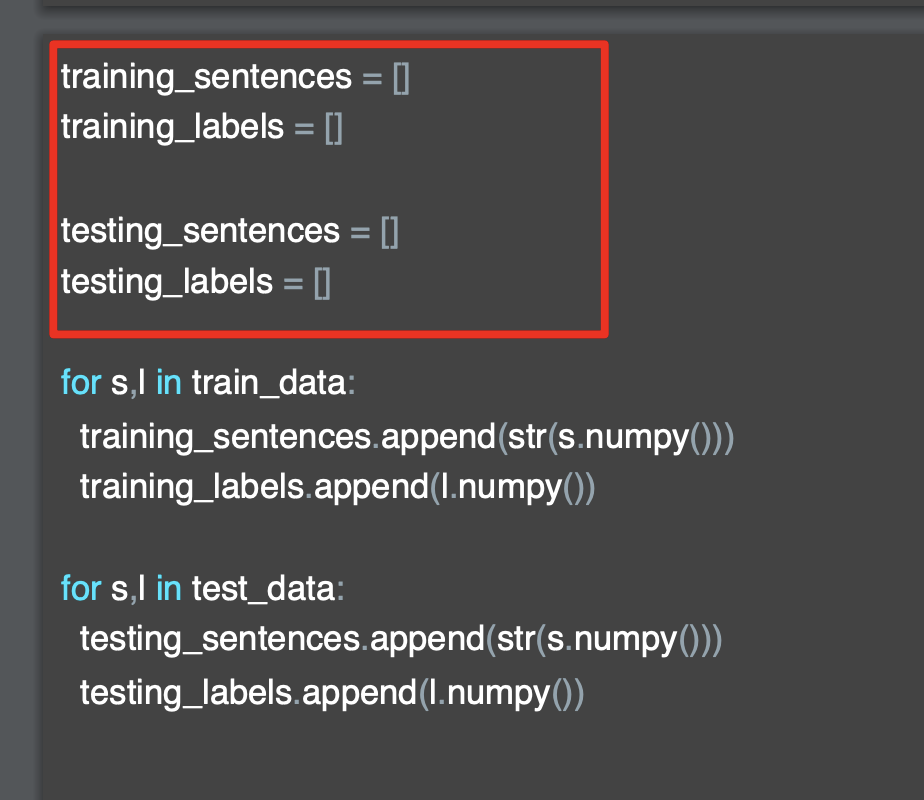
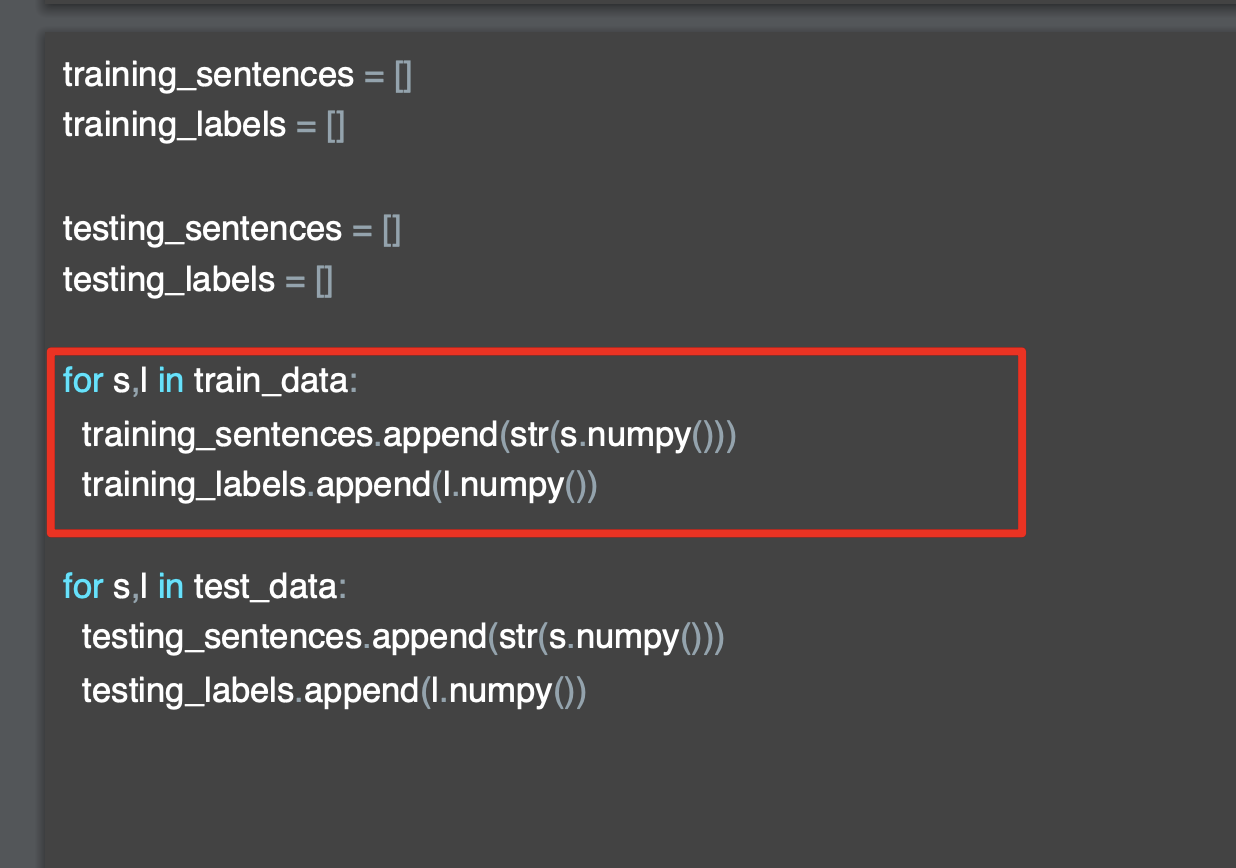
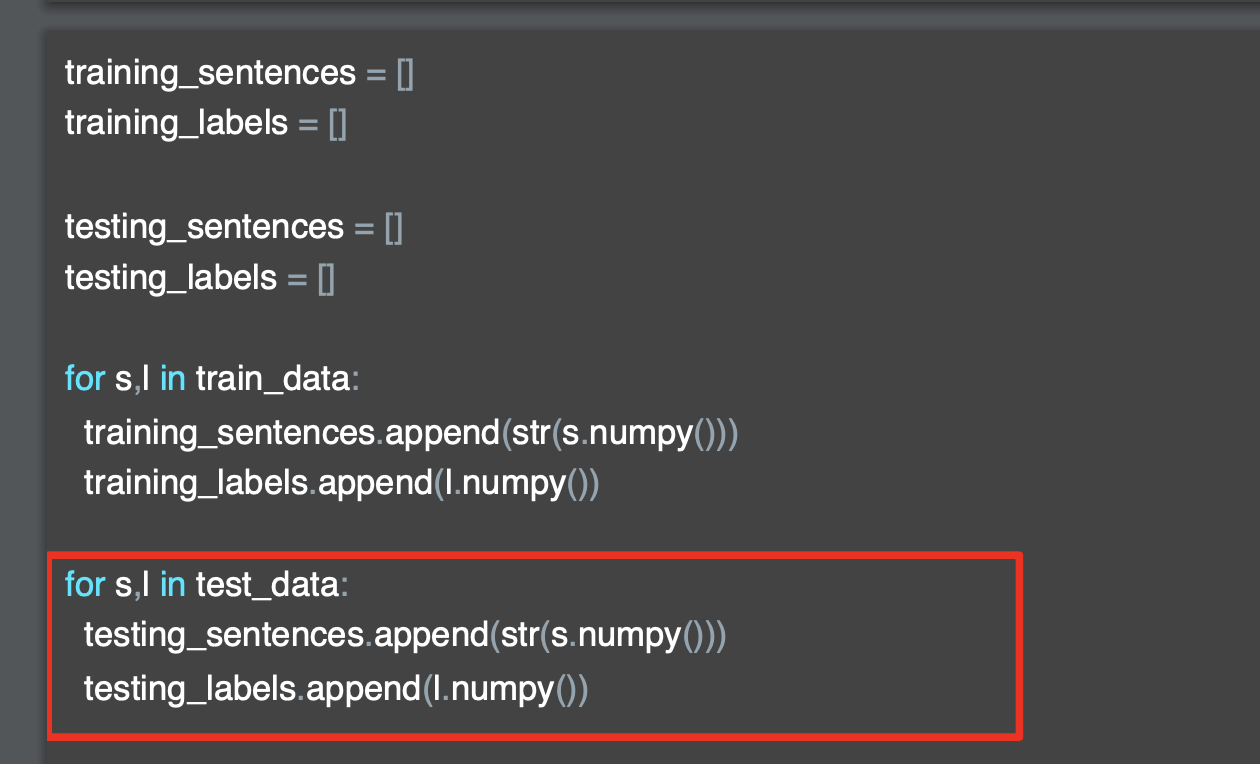



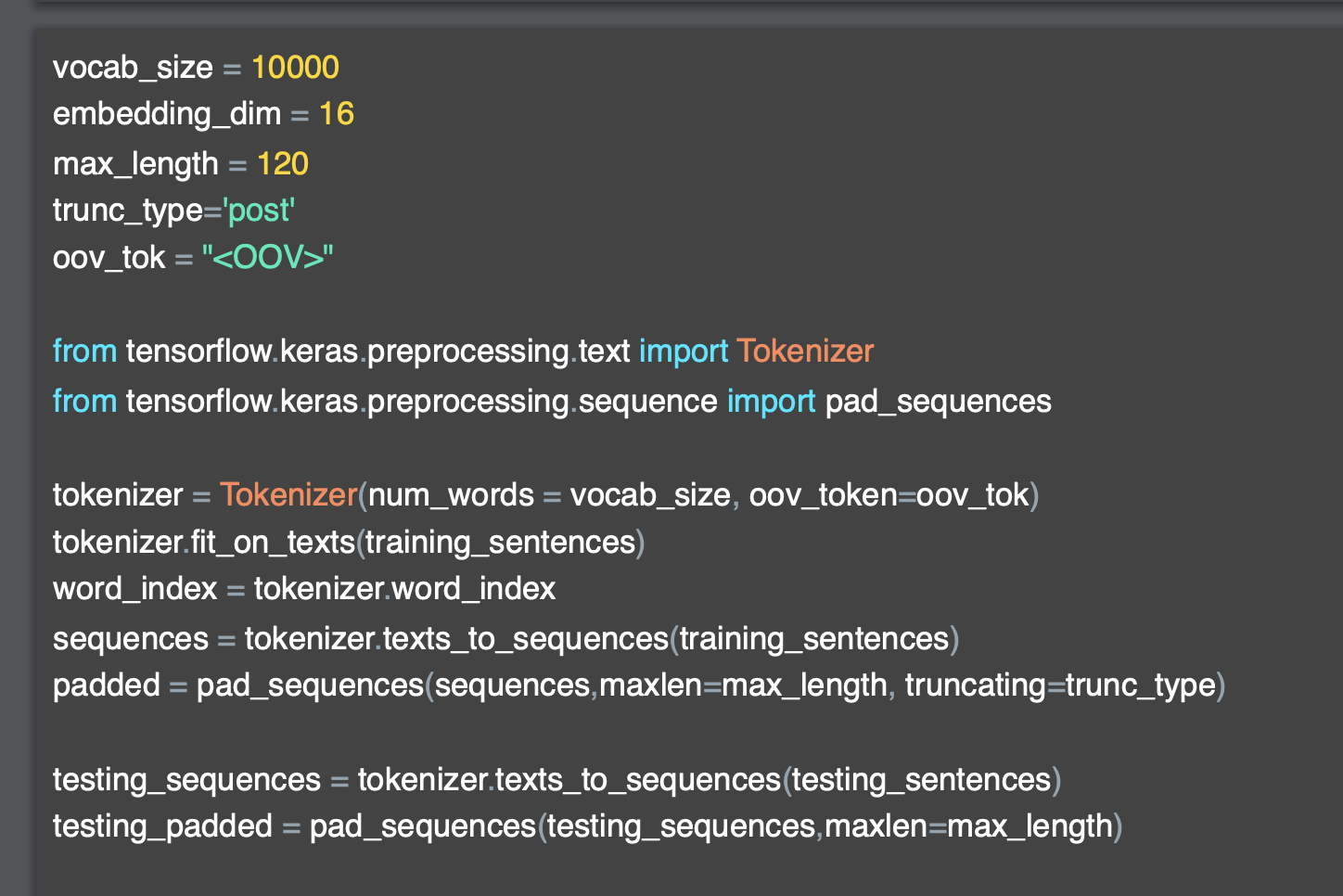



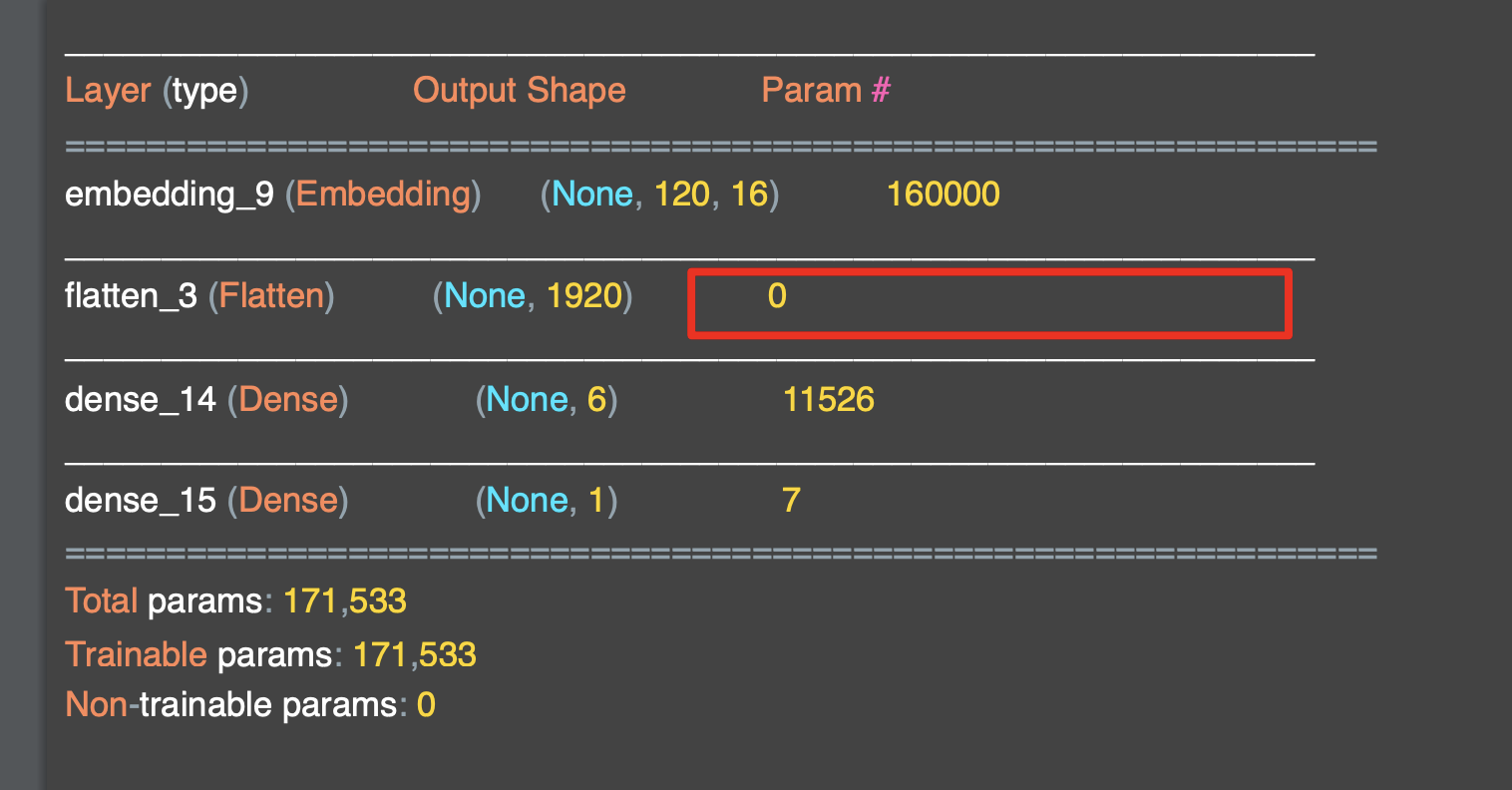
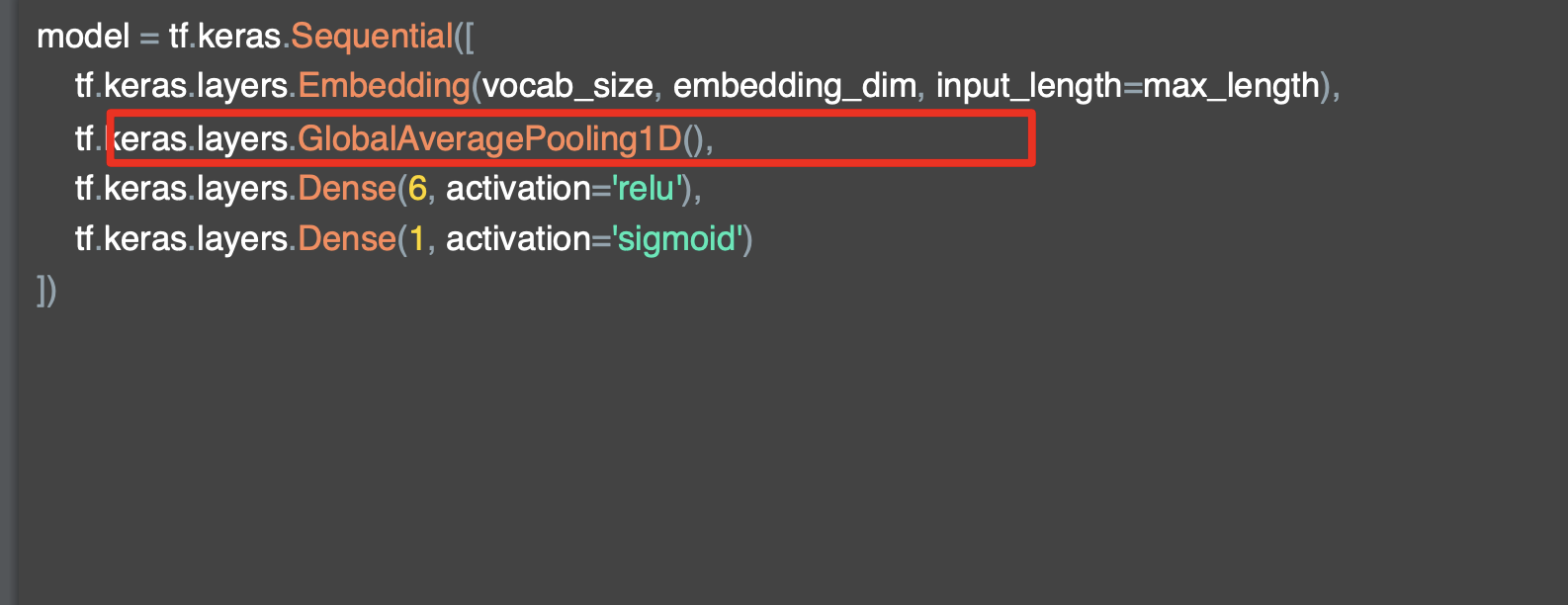
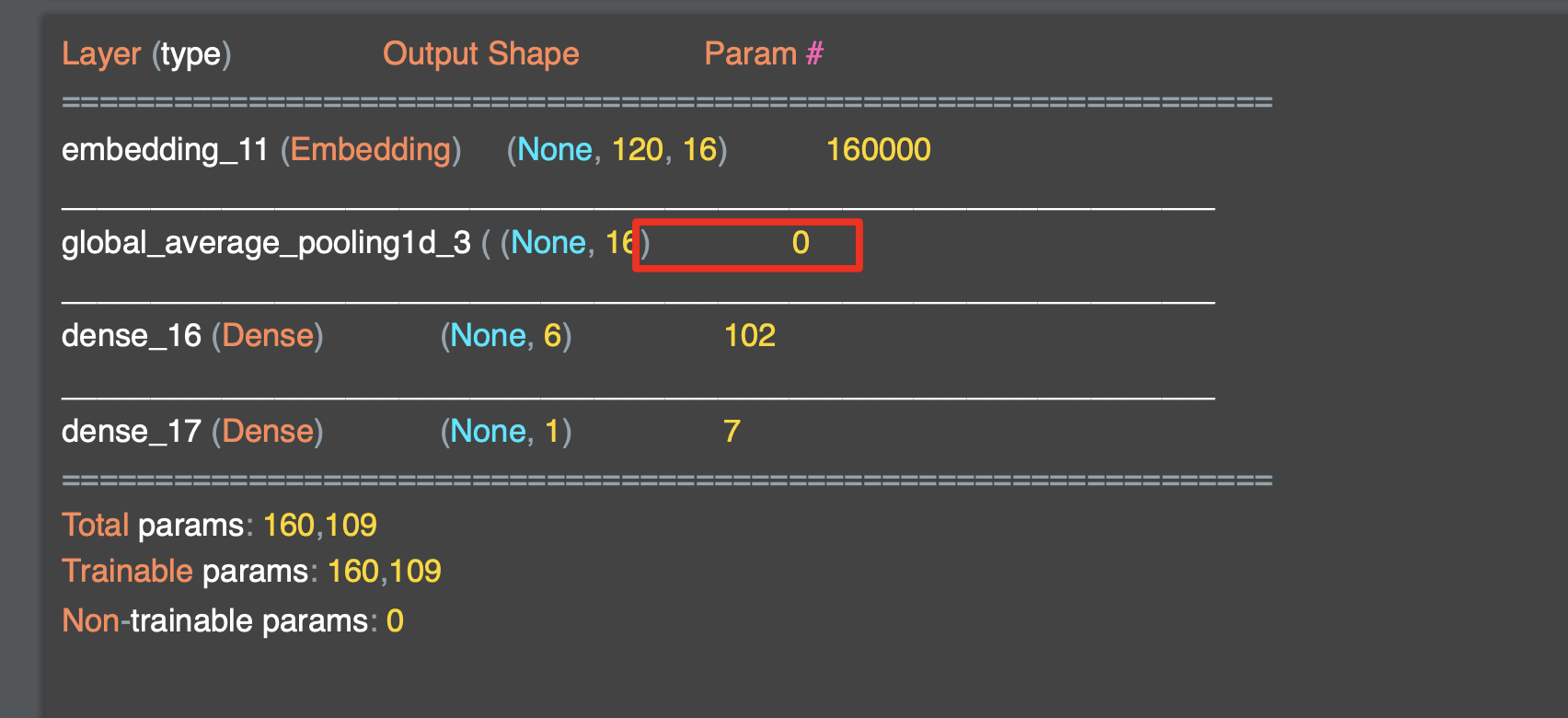
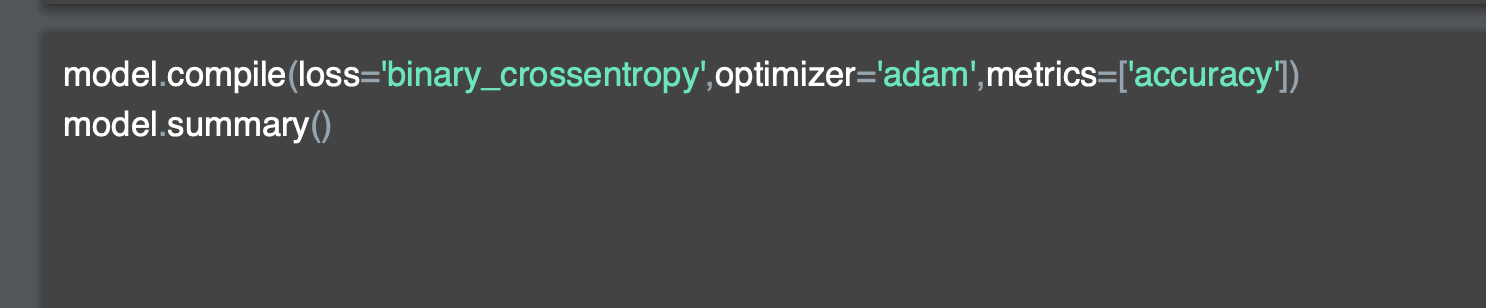




'
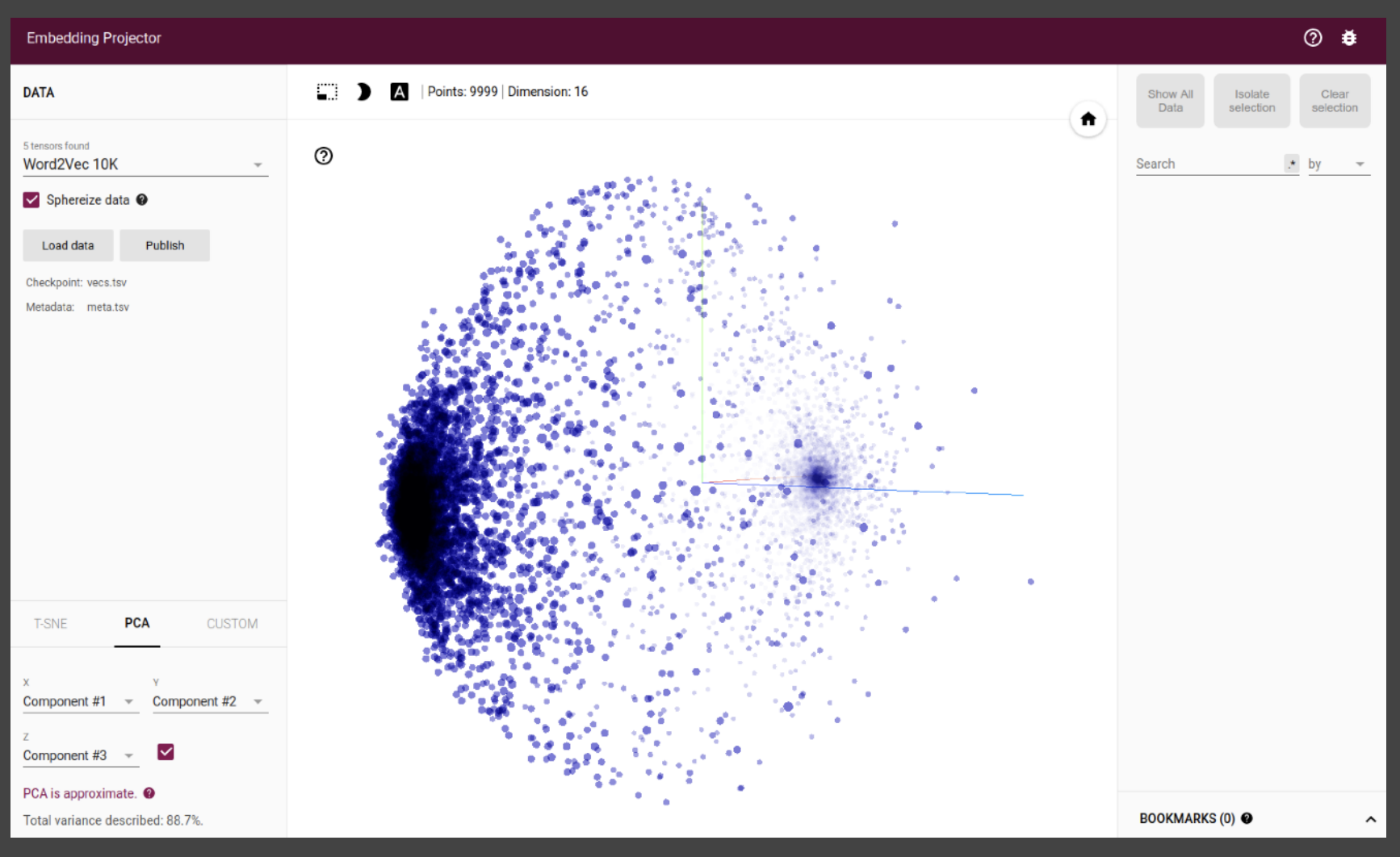












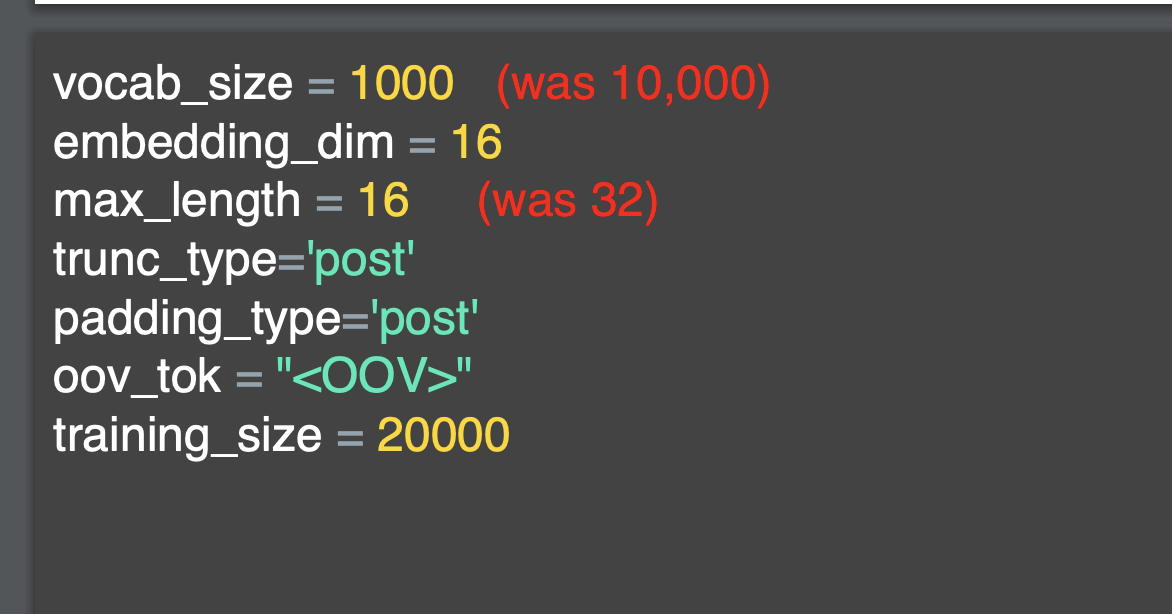



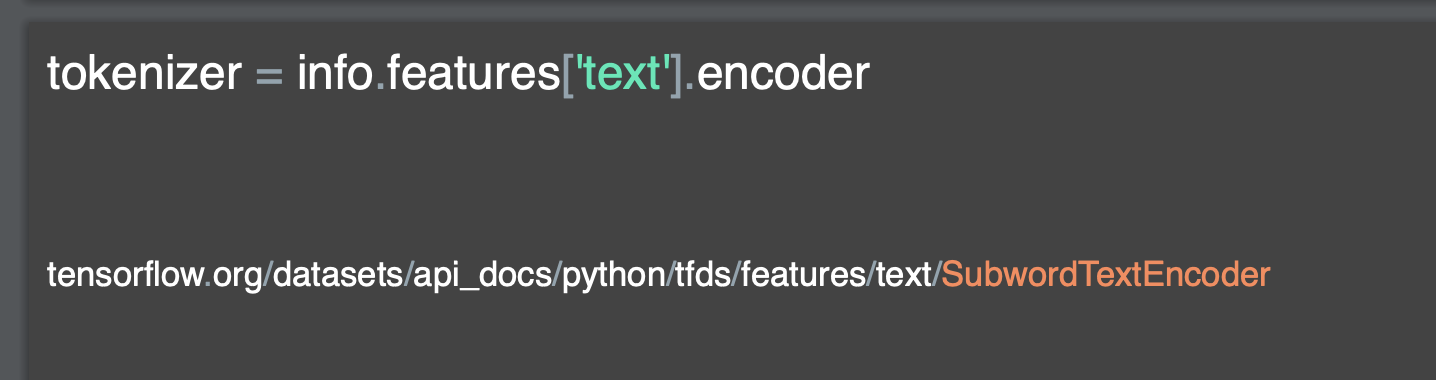







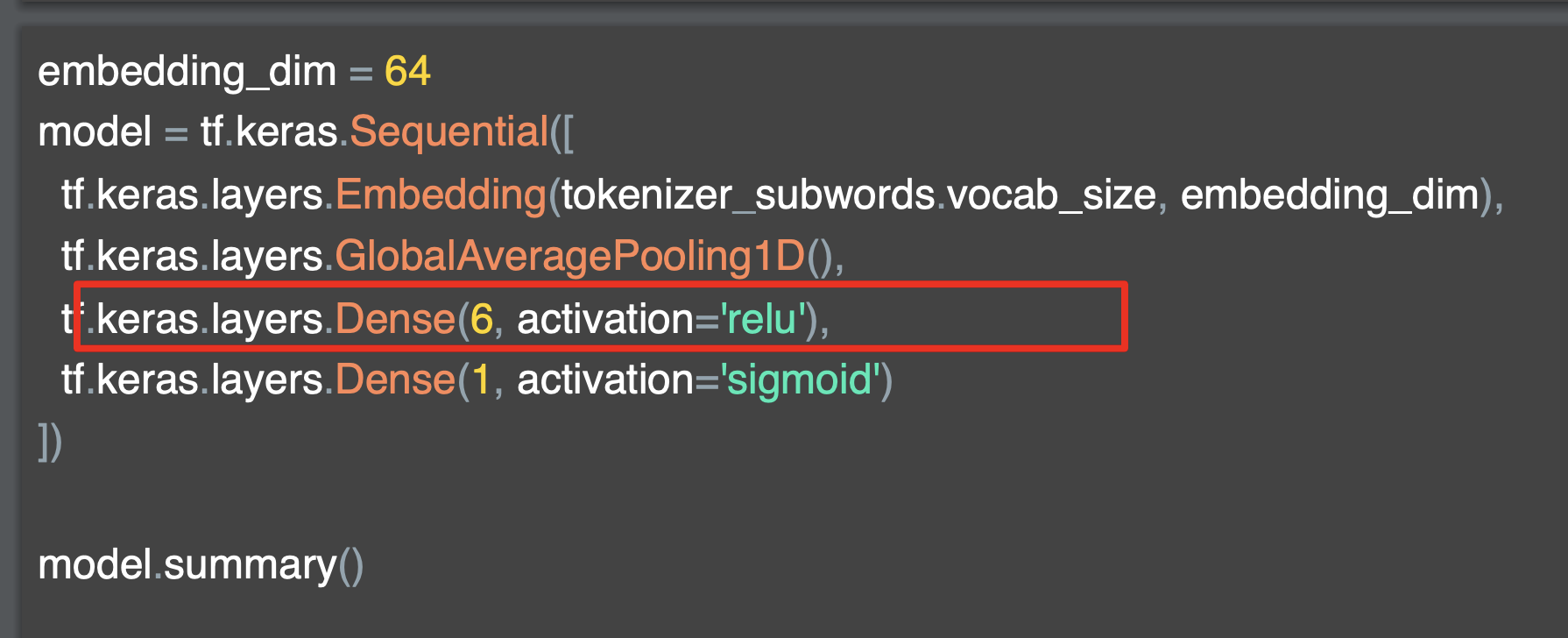
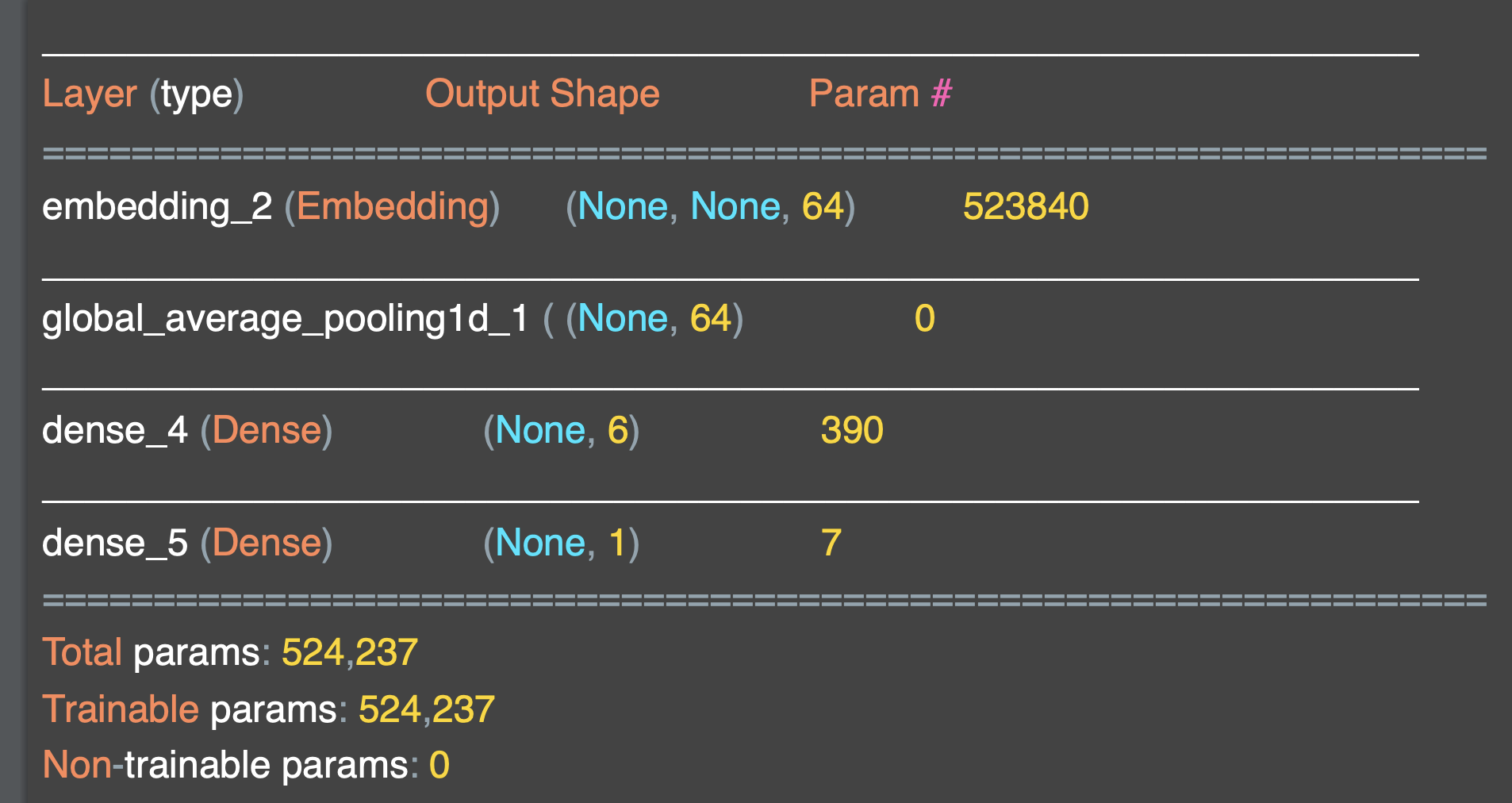


Tensorflow의 Tokenizer
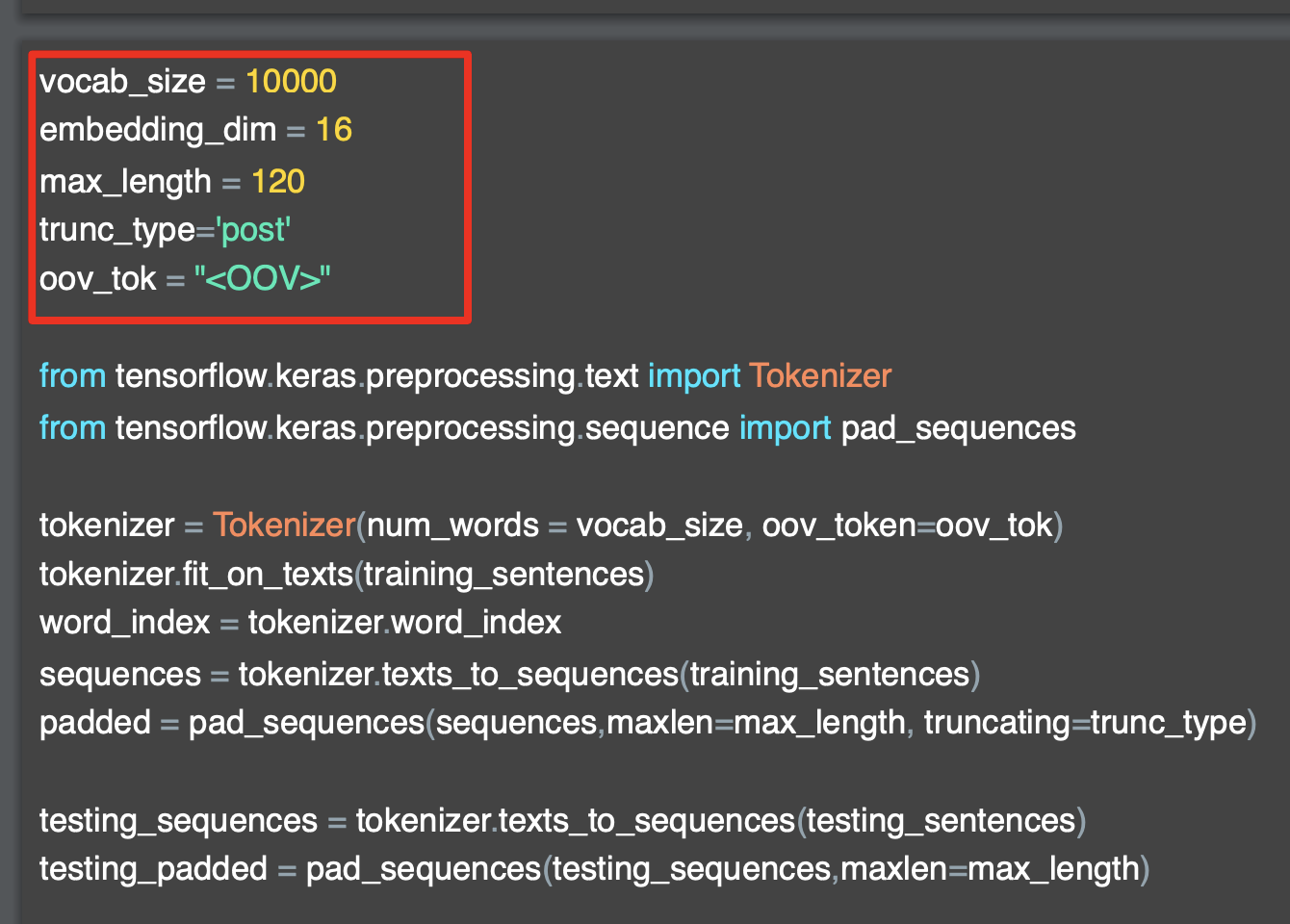
[1] Tokenizer의 parameter : num_words
Tensorflow의 Tokenizer를 이용해서
주어진 문장의 토큰에 따라 단어 사전을 만들고, 해당 단어들에 대해서 사전의 색인 (index)를 부여하기 위해서
from tensorflow.keras.preprocessing.text import Tokenizer Tokenzier를 사용해서 sentence를 토큰화하고 단어사전을 만든다.
이 때 Tokenizer를 초기화할 때 num_words 라는 인자를 정하게 된다.
tokenizer = Tokenizer(num_words=100)위의 Tokenizer(num_words=100)에서 num_words 는
num_words : 토큰화된 단어를 사전화할 때 사용되는 최대 단어의 수
라고 보면된다.
나는 여기서 혼용했던 것이 Tokenizer에 num_words=1 을 주었는데,
print로 word_index를 출력했을 때
{'love': 1, 'my': 2, 'i': 3, 'dog': 4, 'cat': 5, 'you': 6} 라고 주어진 sentence에 모든 토큰에 대해 인덱싱이 되어 있는 것을 보고 의아했었다.
sentences = [
'i love my dog',
'I, love my cat',
'You love my dog!'
]
tokenizer = Tokenizer(num_words = 1)
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
print(word_index)
# {'love': 1, 'my': 2, 'i': 3, 'dog': 4, 'cat': 5, 'you': 6}- Tokenizer의 num_words 매개변수는 토큰화된 단어들을 사전화할 때 사용되는 최대 단어 수를 지정하는 것. 즉 "단어 사전의 크기를 조절"하는 것이지, 실제로 텍스트에서 처리되는 단어의 수를 조절하는 것은 아니다.
따라서 num_words=1을 설정하더라도 fit_on_texts 메서드는 여전히 모든 단어를 처리하고, 각 단어에 대한 인덱스를 생성한다.
하지만 이 경우, 실제로 단어 사전에 포함될 수 있는 단어는 오직 하나뿐이며, 이는 가장 빈도가 높은 단어일 것이다.
- 그래서 word_index에는 모든 단어에 대한 인덱스가 포함되지만, 이 인덱스는 사용자가 지정한 num_words의 값에 따라 제한된다.
출력된 word_index에는 모든 단어에 대한 인덱스가 포함되어 있지만, 이 중 실제로 사용되는 단어는 하나뿐일 것이다.
실제로 단어사전에 이용되는 단어가 1개 여서 핸들링하는 과정이 무의미해지므로,
아래에서 부터는 num_word의 인자값을 100으로 주면서 진행하겠다!
[2] Tokenizer의 fit_on_texts
sentences = [
'i love my dog',
'I, love my cat',
'You love my dog!'
]
tokenizer = Tokenizer(num_words = 1)
tokenizer.fit_on_texts(sentences) ##### 이부분 !
word_index = tokenizer.word_index
print(word_index)
# {'love': 1, 'my': 2, 'i': 3, 'dog': 4, 'cat': 5, 'you': 6}위에서 차용한 코드를 그대로 가져오자면, Tokenizer 인스턴스를 생성할때 num_words 인자를 주고 초기화를 한다음 fit_on_text 으로 주어진 텍스트 문장들이 담긴 sentences 배열을 넣는다.
여기서 Tokenizer의 fit_on_text의 역할이다.
Tokenizer의
fit_on_text: 텍스트 데이터를 기반으로 단어 사전을 만듦
input으로는 토큰화할 텍스트 데이터로 구성된 리스트들이 들어가고,
주어진 텍스트 데이터에서 단어의 빈도를 계산하고, 각 단어에 고유한 인덱스를 할당하여 단어 사전을 구축한다.
구체적으로 해당 과정을 리스트업 해보자면
- 주어진 텍스트 데이터에서 공백을 기준으로 단어들을 토큰화한다.
- 각 단어의 등장 빈도를 계산하여 단어별로 빈도수를 기록한다.
- 빈도순으로 정렬된 단어들에게 고유한 인덱스를 할당하여 단어 사전을 생성한다.
[3] Tokenizer의 word_index
Tokenizer 인스턴스를 생성하고, num_word의 파라미터를 설정하고,
fit_on_texts 로 텍스트 리스트를 넣어 단어사전을 구축한 다음
word_index를 사용하는 부분이 나오는데,
sentences = [
'i love my dog',
'I, love my cat',
'You love my dog!'
]
tokenizer = Tokenizer(num_words = 100)
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index ##### 이부분 !
print(word_index)
# {'love': 1, 'my': 2, 'i': 3, 'dog': 4, 'cat': 5, 'you': 6}Tokenizer의
word_index: 텍스트 데이터를 기반으로 생성된 단어 사전
위에서 fit_on_texts로 구축한 단어사전을 불러올 수 있다.
각 단어를 해당하는 고유한 정수 인덱스로 매핑한 딕셔너리 형태로 구성되어 있다.
위에 보면 key로 'love', 'my', 'i', 등이 있고 각각 매핑된 value가 1, 2, 3으로 구성되어 있다.
- word_index를 사용하면 단어를 인덱스로 변환하거나 인덱스를 단어로 변환할 수 있게 되고, 추후 모델에 입력 데이터를 제공할 때 단어를 정수로 변환하거나 정수를 단어로 변환하는 데 유용하다.
[4] Tokenizer의 texts_to_sequences
from tensorflow.keras.preprocessing.text import Tokenizer
sentences = [
'i love my dog',
'I, love my cat',
'You love my dog!'
]
tokenizer = Tokenizer(num_words=100)
tokenizer.fit_on_texts(sentences)
word_index= tokenizer.word_index
print(word_index)
# {'love': 1, 'my': 2, 'i': 3, 'dog': 4, 'cat': 5, 'you': 6}
test_sentences = [
'i really love my dog',
'my dog loves my manatee'
]
test_sequences = tokenizer.texts_to_sequences(test_sentences)
print(test_seqeunces)
# [[3, 1, 2, 4], [2, 4, 2]]
위 코드에서 test_sentences 까지의 로직은 같다.
주어진 문장을 토큰화 해서, 해당 토큰에 대한 단어사전을 구축하고
구축된 단어사전을 출력했다.
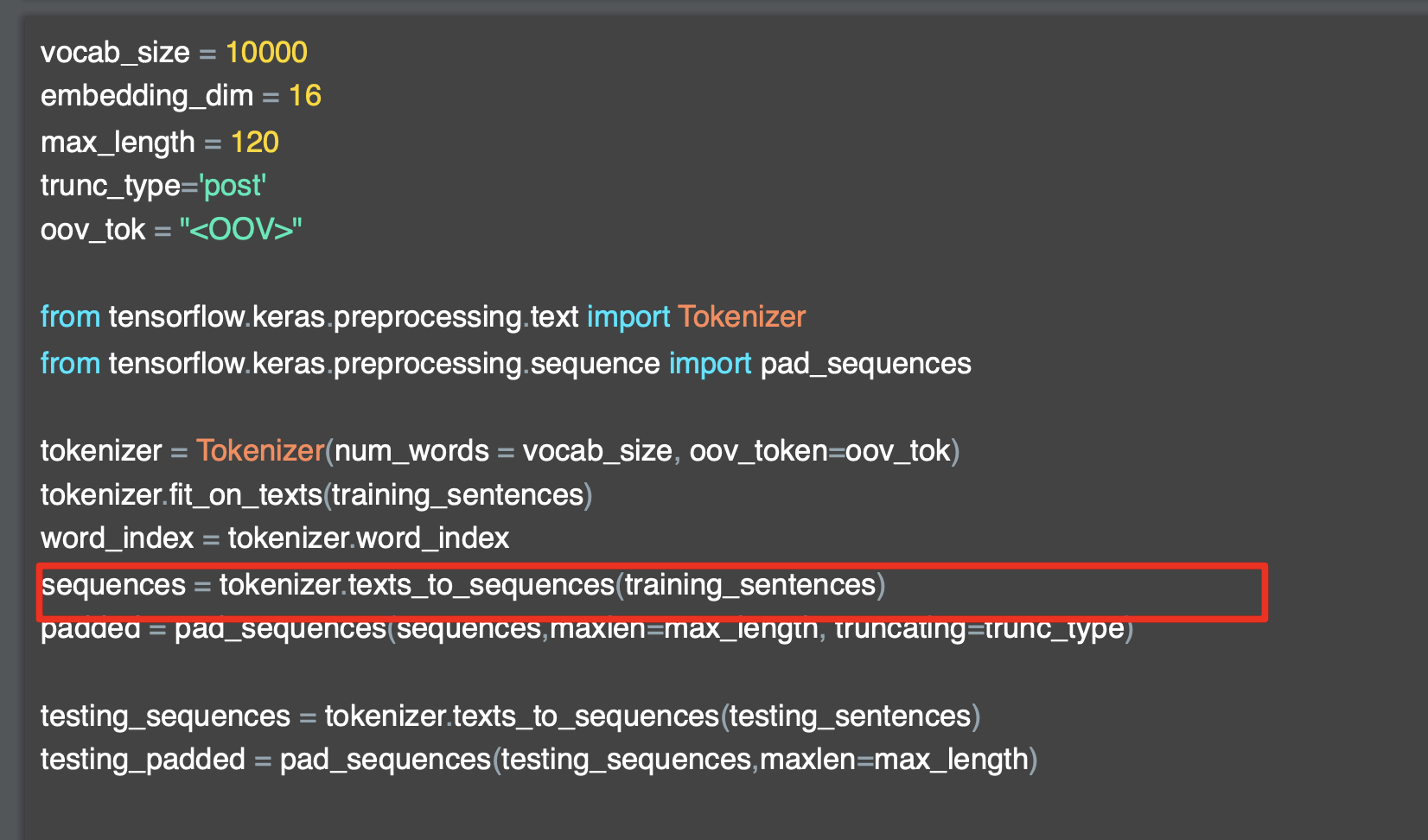
그 뒤로 새로운 텍스트 문장을 담은 test_sentences 라는 리스트가 등장하고, tokenizer의 texts_to_sequences 를 사용해 새로운 텍스트 문장을 넣는다.
Tokenizer의
texts_to_sequences: 텍스트 데이터를 정수 시퀀스로 변환함
texts_to_sequences메서드는 주어진 텍스트 데이터의 각 문장을 토큰화하고, 각 단어를 해당하는 정수 인덱스로 매핑하여 시퀀스로 변환한다.
위에서는 test_sentences가 아니라 sentences에 있는 문장에 있는 토큰을 기반으로 단어 사전이 구축됐기 때문에
test_sentences에서는 단어사전에 없는 'really', 'loves', 'manatee'가 등장한다.
그래서 tokenizer의 texts_to_sequences에 test_sentences를 넣어서 각 텍스트를 정수 시퀀스로 매핑한 결과를 보면
'i really love my dog' 의 토큰은
i/relly/love/my/dog로 총 5개의 토큰을 가지고 있어야 하는데
[3,1,2,4] 인 i(3), love(1), my(2), dog(4) 만 존재하고
'my dog loves my manatee' 에서도
my/dog/loves/my/manatee 총 5개의 토큰을 가지고 있지 않고
[2,4,2]로 my(2), dog(4), my(2) 만 가지고 있다.
여기서 중요한 지점이 나오는데,
texts_to_sequences메서드에서는 각 토큰이 기존의 단어 사전에 없다면 해당 단어는 무시되고 시퀀스에는 포함되지 않는다.
즉, 기존에 학습된 단어 사전에 없는 단어가 있는 경우, 그 단어는 시퀀스에 포함되지 않으며 무시되기 때문에, 단어사전에 있는 토큰만 시퀀스로 나오게 되어 해당 아웃풋인 [[3,1,2,4], [2,4,2]] 이 나오는 것이다.
이러한 문제를 해결하는 방법은
(1) Tokenzier를 적절하게 초기화하고 훈련 데이터로 학습시키기
(2) OOV (Out-of-Vocabulary) 토큰 사용하기
가 있다.
(1)번의 방법처럼 Tokenizer 를 적절하게 초기화하고 훈련 데이터로 학습시키기 위해서는 모든 텍스트 데이터를 Tokenizer에 학습시키는 것이 중요하고, 따라서 훈련 데이터와 테스트 데이터를 함께 고려하여 Tokenizer를 초기화하고 학습시키는 것이다.
(2)번의 OOV (Out-of-Vocabulary) 토큰 사용은 테스트 데이터에는 훈련 데이터에 없는 단어가 포함될 수 있으므로, 테스트 데이터에서 발견된 이러한 단어들을 무시하지 않고 새로운 인덱스로 추가하여 처리하는 것이다.
이를 위해 Tokenizer의 oov_token 매개변수를 사용한다.
사실 (1)번의 방법이 좋긴하지만 모든 텍스트 데이터를 Tokenizer에 학습 시키는 것은 어렵다. 그래서 (2)번 방법인 Tokenizer의 OOV(Out-of-Vocabulary)를 사용해보겠다.
[5] Tokenizer의 oov_token
위에서 테스트 텍스트 데이터에서 존재하지 않는 단어들도 핸들링하기 위해서는 Tokenizer 의 parameter 중 oov_token 를 사용한다고 했는데,
Tokenizer
oov_token: "Out-of-Vocabulary"의 약어
- Tokenizer에 의해 학습되지 않은 단어(즉, 훈련 데이터에 없는 단어)를 나타내는 데 사용됨.
- 이 매개변수를 설정하면 Tokenizer는 훈련 과정에서 보지 못한 단어가 발견될 때 이를 특별한 토큰으로 대체함
즉 새로운 텍스트 데이터가 있을 때, 기존의 단어사전에 없는 단어(토큰)을 사용자가 정의한 토큰으로 지정할 수 있게 해준다.
oov_token의 매개변수 값을 <OOV> 라고 지정해주는 것이 보편적이다.
sentences = [
'i love my dog',
'I, love my cat',
'You love my dog!'
]
tokenizer = Tokenizer(num_words = 100, oov_token='<OOV>')
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
print(word_index)
# {'<OOV>': 1, 'love': 2, 'my': 3, 'i': 4, 'dog': 5, 'cat': 6, 'you': 7}
test_sentences = [
'i really love my dog',
'my dog loves my manatee'
]
test_sequences = tokenizer.texts_to_sequences(test_sentences)
print(test_sequences)
# [[4, 1, 2, 3, 5], [3, 5, 1, 3, 1]]Tokenizer 인스턴스를 불러와서 초기화할 때 num_words 와 함께
oov_token으로 설정해준다. <OOV> 라고 설정했다.
위에서 봤을 때 word_index를 출력해보면 <OOV> 가 인덱스 1로 지정된다.
그리고 아래의 test_sentences들의 텍스트들을 texts_to_sequences로 넣어 텍스트 데이터를 정수 시퀀스로 변환하면
'i really love my dog'은 [4,1,2,3,5]
'my dog loves my manatee'는 [3,5,1,3,1]로 변환되는데,
위에서 무시되었던 새로운 단어들이 다 1인 oov로 매핑되어 총 5개의 시퀀스로 잘 나타나고 있다.
<OOV>토큰을 사용하는 이유는 먼저 희귀한 단어 처리가 가능하다는 점이다. 학습 데이터에 없는 단어는 모델이 무시하거나 잘못 처리할 수 있다. 따라서 이러한 단어를 특별한 토큰으로 대체하여 모델이 이를 무시하지 않도록 한다.- 또한, 테스트 데이터 처리 측면에서 유용하다. 모델을 훈련한 후에는 테스트 데이터에 대해 일반화되도록 해야 하는데, 테스트 데이터에는 훈련 데이터에 없는 단어가 포함될 수 있기 때문에 이를 무시하지 않고 처리하기 위해 OOV 토큰을 사용한다.
즉, 단어 사전에 없는 단어들을 무시하지 않도록 하기 위해 OOV 토큰을 사용한다고 보면 되겠다.
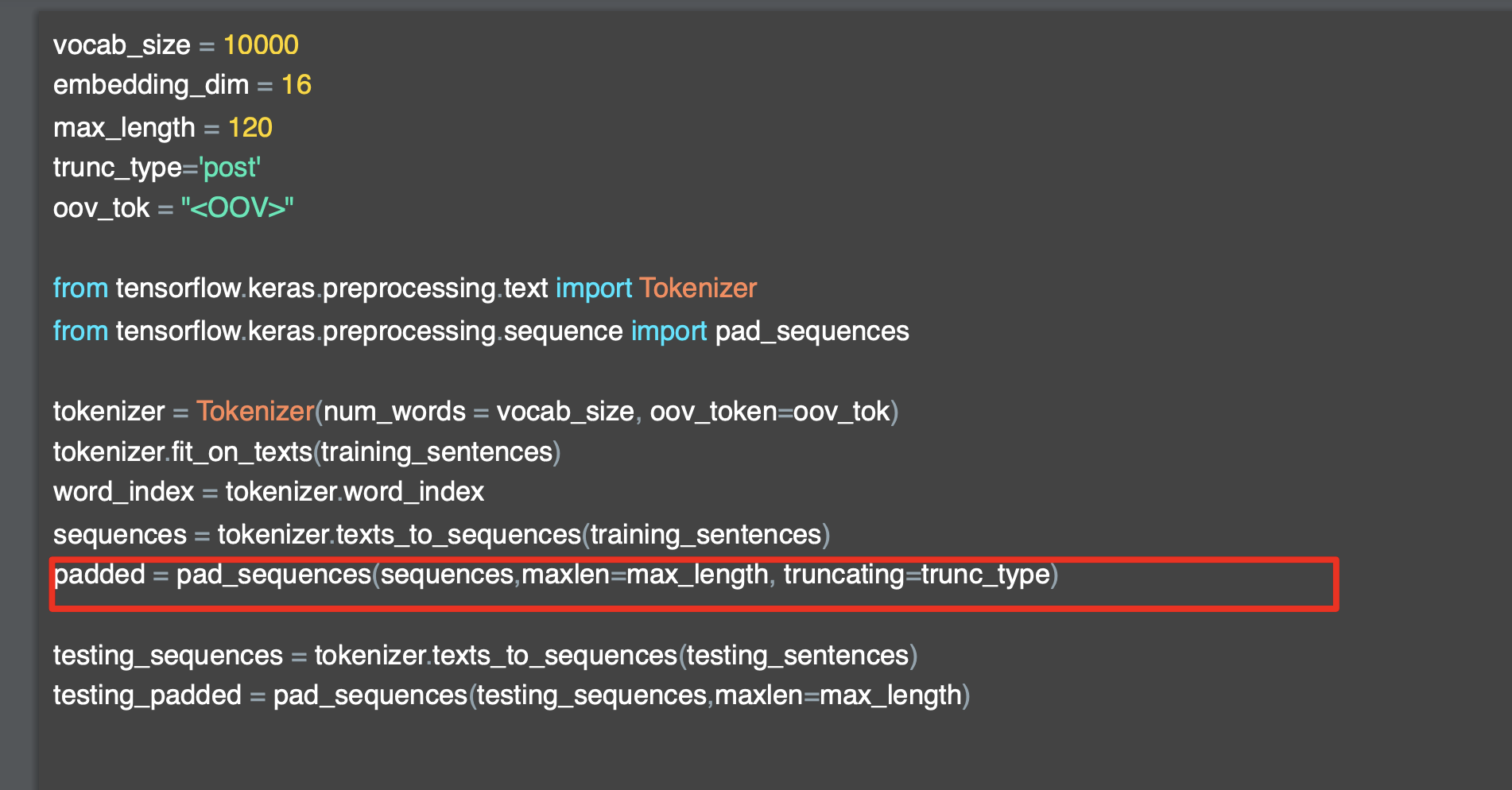
[5] tensorflow의 pad_sequences
자연어처리를 하다보면 전처리 과정 중에 패딩(padding) 이라는 용어가 등장한다.
padding(패딩) : 시퀀스의 길이를 맞추는 작업
간략하게 말하면 패딩은 시퀀스의 길이를 맞추는 작업이다.
텍스트 데이터는 일반적으로 단어도 있지만 문장, 문서등의 형태로 구성되고
각각의 문장돠 문서들은 단어의 시퀀스로 표현된다. 그러나 해당 문장들의 길이는 모두 다양하다.
컴퓨터비전(CV)나, 일반 ML을 다룰 때도 모델에 인풋값을 넣을 때는 모두 일정한 크기의 shape을 넣게 되는데, 텍스트 모델도 마찬가지로 일정한 input size 로 맞춰서 넣어 주어야 한다.
- 즉 패딩 작업은 모델에 입력으로 제공하기 위해 모든 문장의 길이를 동일하게 맞추는 작업이다.
위에서 간략하게 언급했지만 패딩은
(1) 모델의 고정된 크기 입력을 기대하는 특성으로 입력 데이터의 형태를 표준화해서 모든 샘플이 동일한 크기로 구성되게 하고,
(2) 패딩을 통해 입력 데이터를 행렬로 표현해 효율적인 행렬 연산을 가능하게 한다.
(3) 문장의 길이를 맞추지 않고 입력 데이터를 제공하면 모델은 긴 문장에 대한 정보를 학습시키지 못하고, 긴 문장의 정보는 유실될 수 있다. 패딩을 사용하면 모든 샘플에 대한 정보가 유지된다.
- 일반적으로 padding은 문장의 끝에 특정한 토큰(예: 0)을 삽입해 시퀀스의 길이를 맞춘다.
"post-padding"방법과 "pre-padding" 방법이 있는데,
뒷부분에 특정 토큰을 추가하면 "post-padding", 앞부분에 특정 토큰을 추가하면 "pre-padding" 이다.
먼저, padding을 위해서는 tensorflow의 pad_sentences를 import 한다.
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sentence import pad_sentences
sentences = [
'I love my dog',
'I love my cat',
'You love my dog!',
'Do you think my dog is amazing?'
]
tokenizer = Tokenizer(num_words=100, oov_token='<OOV>')
tokenizer.fit_on_texts(sentences)
word_index= tokenizer.word_index
sequences = tokenizer.texts_to_sequences(sentences)
print(word_index)
# {'<OOV>': 1, 'my': 2, 'love': 3, 'dog': 4,
# 'i': 5, 'you': 6, 'cat': 7, 'do': 8, 'think':
# 9, 'is': 10, 'amazing': 11}
print(sequences)
# [[5, 3, 2, 4], [5, 3, 2, 7],
# [6, 3, 2, 4], [8, 6, 9, 2, 4, 10, 11]]
차용했던 예시에서 2개를 더 추가해서 새로운 sentences 배열을 가지고 왔는데, 위에서 했던 방식대로 Tokenizer 인스턴스에 num_words 와 <oov_token> 매개변수를 지정하고 fit_on_texts 과정을 거쳐 단어사전을 만든다.
sentences 배열에서 가장 짧은 문장에 속하는
'I love my dog'와 가장 긴 문장에 속하는 'Do you think my dog is amazing?'을 비교해보자.
'I love my dog'는 token 4개로 구성된 I/love/my/dog에 해당하는 [5, 3, 2, 4] 시퀀스로 구성되어있다.
'Do you think my dog is amazing'은 7개로 구성된 Do/you/think/my/dog/is/amazing 이라는 [8, 6, 9, 2, 4, 10, 11]로 시퀀스로 구성되어있다.
해당 시퀀스의 길이는 4, 7로 다른데 이 다른 시퀀스들을 모델에 넣기 위해서 패딩 작업을 해보자.
padded = pad_sequences(sequences)
print(padded)
# output
[[ 0 0 0 5 3 2 4]
[ 0 0 0 5 3 2 7]
[ 0 0 0 6 3 2 4]
[ 8 6 9 2 4 10 11]]각 텍스트들의 시퀀스 앞에 '0' 이 붙었고 크기고 7로 동일해졌다.
pad_sequence : 시퀀스의 길이를 맞추기 위해 사용됨
이 함수는 주어진 시퀀스들의 길이를 동일하게 맞추고, 필요한 경우 패딩을 추가함
pad_sequences는 인자로 패딩할 시퀀스 배열, 맞추고 싶은 시퀀스의 길이를 조절하는 maxlen, 패딩의 위치를 지정하는 padding 옵션이 있다.
maxlen 인자를 주지 않으면, 주어진 시퀀스 중에서 가장 큰 길이에 맞춰서 시퀀스의 앞에 0이 붙는 것이 기본형이다.
- pad_sequences 함수는 입력 시퀀스의 길이를 최대 시퀀스 길이에 맞추어 패딩을 적용한다.
maxlen을 조절해 본다면
padded = pad_sequences(sequences, maxlen=5)
print("\nPadded Sequences:")
print(padded)
# Padded Sequences:
[[ 0 5 3 2 4]
[ 0 5 3 2 7]
[ 0 6 3 2 4]
[ 9 2 4 10 11]]padded = pad_sequences(sequences, maxlen=3)
print("\nPadded Sequences:")
print(padded)
# Padded Sequences:
[[ 3 2 4]
[ 3 2 7]
[ 3 2 4]
[ 4 10 11]]maxlen의 인자를 어떻게 주느냐에 따라 최종 패딩된 시퀀스의 길이가 달라진다.
다음 옵션인 padding을 'post'혹은 'pre'를 줄 수 있는데
padding='post'로 설정하면 패딩이 시퀀스의 뒤에 추가된다.
padded = pad_sequences(sequences, maxlen=7, padding='post')
print("\nPadded Sequences:")
print(padded)
# Padded Sequences:
[[ 5 3 2 4 0 0 0]
[ 5 3 2 7 0 0 0]
[ 6 3 2 4 0 0 0]
[ 8 6 9 2 4 10 11]]
반대로 padding='pre'로 설정하면 패딩이 시퀀스의 앞에 추가된다.
padded = pad_sequences(sequences, maxlen=7, padding='pre')
print("\nPadded Sequences:")
print(padded)
# Padded Sequences:
[[ 0 0 0 5 3 2 4]
[ 0 0 0 5 3 2 7]
[ 0 0 0 6 3 2 4]
[ 8 6 9 2 4 10 11]]사실 padding 옵션을 주지 않으면 기본으로 pre-padding으로 수행된다.
padded = pad_sequences(sequences, maxlen=7)
print("\nPadded Sequences:")
print(padded)
# Padded Sequences:
[[ 0 0 0 5 3 2 4]
[ 0 0 0 5 3 2 7]
[ 0 0 0 6 3 2 4]
[ 8 6 9 2 4 10 11]]padding vs truncating
pad_sequences의 인자로 padding, maxlen 외에도 truncating 인자가 있다.
padding과 truncating 모두 pad_sequenced 함수에서 시퀀스를 처리할 때 사용되는데, 각각의 역할이 다르기 때문에 구분된다.
padding : 시퀀스 길이를 맞출 때 사용.
길이가 짧은 시퀀스에 대해 padding 값을 추가하여 시퀀스의 길이를 늘림
보통 0 또는 다른 값을 사용해 padding을 채움
시퀀스 끝 부분에 padding을 추가하거나 앞부분에 추가함
truncating : 시퀀스의 길이를 맞출 때 사용.
길이가 긴 시퀀스에 대해 maxlen으로 지정한 길이로 자르는 작업을 함
truncating 옵션에 따라 자르는 위치를 지정할 수 있음
요약하자면 padding은 길이가 짧은 시퀀스를 채우는 역할이고,
truncating은 길이가 긴 시퀀스를 자르는 역할이다.
post-padding vs pre-padding
- 패딩의 방식인 post-padding과 pre-padding을 비교해보자.
주로 사용되는 방식은 데이터나 모델의 특성에 따라 다르다.
(1) post-padding
- 장점 : 시퀀스의 실제 내용은 시퀀스의 시작 부분에 위치하고 있기 때문에 원래의 의미를 보존할 수 있다. 대부분의 경우 사용하기 간편한다.
- 단점 : 모델 학습 과정에서 패딩된 부분이 무시되고 실제 시퀀스 데이터만을 학습하게 되고, 모델이 패딩된 부분의 정보를 무시하고 훈련할 수 있다.
(2) pre-padding
- 장점: 패딩된 부분의 정보를 모델에 포함시킬 수 있다.
일부 모델 구조에서는 pre-padding이 더 나은 결과를 가져오기도 하는데 RNN(순환 신경망)에서는 시간적 순서를 고려할 때, pre-padding이 유리할 수 있다. - 단점: 데이터를 다루는 과정이 약간 불편할 수 있는데, 데이터를 반대로 정렬해야 할 경우가 생기기도 하다.
여기서, 패딩은 어차피 무의미한 값으로 구성되어 있는데
패딩의 값이 무시되는 것이 왜 단점이냐고 생각할 수 있다.(나만?)
찾아보니, 패딩된 값은 유용한 정보를 제공할 수도 있는데
예를 들어, 패딩된 부분에는 문장이 끝난 것을 나타내는 특정 토큰이 사용될 수 있다. 이 경우 모델은 이 특별한 토큰을 활용하여 문장의 끝을 인식할 수 있다.
또한 패딩된 부분에는 데이터가 없는 영역이므로 이 영역이 중요한 정보를 가지고 있지는 않지만, 패딩된 영역의 길이는 시퀀스의 길이 정보를 제공할 수 있다.
즉, 패딩된 부분이 무의미한 값으로 구성되어 있더라도 시퀀스의 길이 정보를 제공하고, 문장이 끝났다는 정보를 가지고 있으므로 패딩이 무시되면 정보의 유실이라고도 볼 수 있다.
대부분의 경우 보통 문장의 끝에 특정한 토큰(예: 0)을 삽입하여 시퀀스의 길이를 맞추는 post-padding을 일반적으로 사용한다고 한다.
위에서 pre-padding은 RNN 같은 순환신경망에서 더 효율적이라고 했는데,
그 이유를 찾아본 결과 섹션을 더 파야할 같아서 아래에 후술한다.
[6] RNN(순환신경망)과 pre-padding
대부분 자연어 처리에서 패딩을 수행할 때 post-padding을 수행하지만,
모델 및 데이터의 특성에 따라 pre-padding을 수행할 경우가 있다.
대표적으로 RNN과 같은 순환신경망은 pre-pading이 더 효율적이라고 한다.
간단하게 그 이유를 정리하자면
(1) Gradient Vanishing/Exploding 방지
- RNN은 입력 시퀀스를 순차적으로 처리하면서 각 시점의 출력을 계산한다.
이때 역전파 알고리즘을 사용하여 그래디언트를 계산하는데, RNN은 긴 시퀀스에 대해 학습하기 어려운 경향이 있다.
특히 역전파 과정에서 그래디언트가 시간에 따라 지수적으로 증가하거나 감소할 수 있는데, 우리가 자주 들어본 기울기 소실 혹은 폭주가 나타난다.(gradient vanishing 과 gradient exploding) - pre-padding을 사용하면 실제 데이터가 나중에 등장하므로 RNN이 초기에 패딩된 부분에 집중하여 gradient vanishing 문제를 완화할 수 있다.
(2) Long-term Dependency 처리
- RNN은 시퀀스의 이전 상태를 기억하여 현재 상태를 예측하는 데 사용된다. 따라서 긴 시퀀스에 대해 더 긴 상태를 유지하기 위해서는 장기 의존성(long-term dependency)을 처리할 수 있어야 한다.
- pre-padding을 사용하면 실제 데이터가 나중에 등장하므로 RNN이 초기에 패딩된 부분에 집중하여 장기 의존성을 더 잘 처리할 수 있다.
(3) Computational Efficiency
- RNN은 입력 시퀀스의 각 요소를 순차적으로 처리하기 때문에, pre-padding을 사용하면 입력 데이터를 반대로 처리할 필요가 없기 때문에 이는 계산의 효율성을 높일 수 있.
(4) Attention 메커니즘을 고려할 때
- attention 메커니즘은 입력 시퀀스의 각 요소에 가중치를 할당하여 모델이 특정 부분에 더 집중하도록 한다.
- pre-padding을 사용하면 실제 데이터가 나중에 등장하므로 모델이 입력 시퀀스의 중요한 부분에 더 집중할 수 있다.
즉, 정리하자면 긴 시퀀스를 처리하거나 장기 의존성을 처리해야 하는 경우에 pre-padding이 유용할 수 있고, 실제 데이터가 나중에 등장해야 하는 경우에 더 적합하므로 이때 pre-padding 을 사용한다고 보면 되겠다.
