[Tensorflow] 1. TensorFlow for Artificial Intelligence, Machine Learning, and Deep Learning Paradigm(3 week Enhancing Vision with Convolutional Neural Networks) - lecture
Tensorflow_certification(텐서플로우 자격증)
TensorFlow for Artificial Intelligence, Machine Learning, and Deep Learning Paradigm(3 week Enhancing Vision with Convolutional Neural Networks)
컨볼루션은 굉장히 직관적이고, 이미지를 통과시키는 필터로 그 결과로 이미지의 특징을 추출한다.
데이터와 레이블을 이용해서 신경망이 스스로 아이템의 특징을 어떻게 발견하는지를 학습하게 한다.
What are convolutions and pooling?
이전 예시에서 패션 아이템을 각각의 레이블에 맞게 분류해주는 DNN을 만들었다.
몇 분만에 훈련 데이터에서 꽤나 정확하게 분류하도록 훈련 시켰는데, 테스트 데이터에서는 그렇지 못했다.
이미지를 보면 꽤나 많은 공간이 낭비되고 있는 것을 볼 수 있다. 784 픽셀로 이루어져 있지만 신발 아니면 핸드백, 셔츠로 보이는 중요한 특징을 가질 수 있도록 이미지를 응축할 수 있는 방법을 알아보자.
여기에 Convolution이 적용된다.
이미지 프로세싱을 해봤다면 이미지에 변화를 주기 위해 이미지를 특정 필터에 통과시키는 것을 시도했을 것이다.
컨볼루션은 이 과정과 비슷하다.
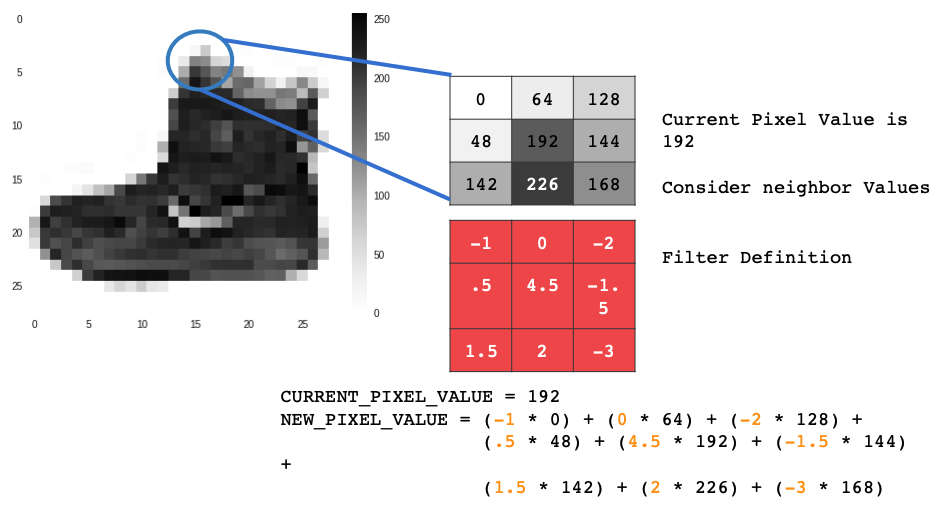
모든 픽셀에 대해서 자신의 값과 이웃 픽셀의 값을 이용한다.
3x3 필터를 이용하면 바로 옆에 있는 이웃 픽셀을 보면된다. 3x3에 대응하는 격차(grid)가 보이는데,
이 픽셀의 새로운 값을 얻기 위해 각각의 이웃 픽셀들을 필터에 대응하는 값들에 단순히 곱해주면 된다.
예를 들어 이 경우 픽셀의 값은 192, 왼쪽 위 픽셀은 0이다. 필터의 그 위치의 값은 -1 이므로 0*(-1)을 해주면 된다. 바로 위 픽셀도 같이 픽셀의 값은 64이고 대응하는 핉터는 0 이므로 두 값을 곱해준다. 이웃 픽셀과 모든 모든 필터의 값을 이용해 같은 연산을 반복한다.
이웃 픽셀들과 필터 값의 곱들의 합을 통해서 이 픽셀의 새로운 값을 얻게 된다.
이러한 연산을 컨볼루션이라고 한다.
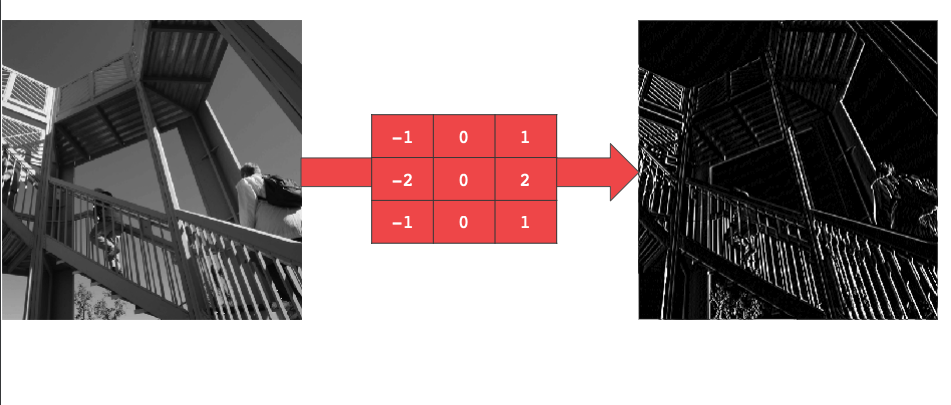
컨볼루션은 그 이미지의 특징점을 강조할 수 있도록 이미지를 변형하는 것이다.
예를 들어 이 필터는 이미지의 수직 경계선을 강조한다.
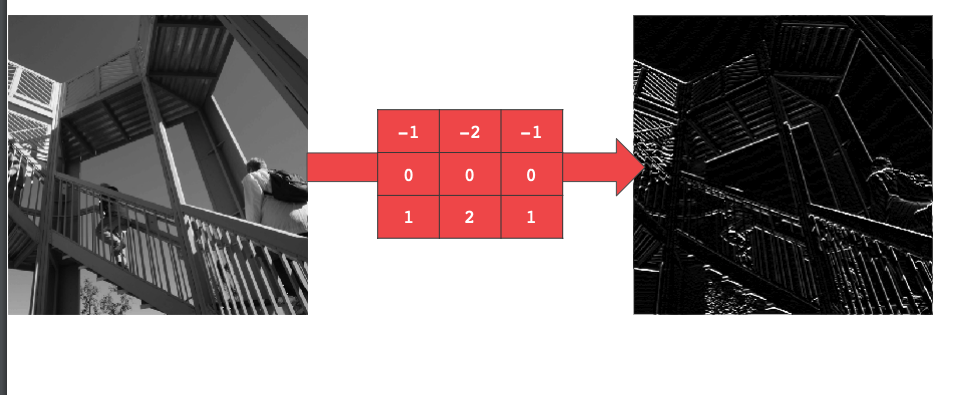
이 필터는 수평 경계선을 강조한다.
이것이 컨볼루션이 무엇인지에 대한 매우 기본적인 설명이다. 풀링(Pooling) 이라는 과정과 합쳐지면 굉장한 효과를 나타낸다.
풀링은 이미지를 압축시키는 것이다.
간단하게 풀링을 하려면 현재 픽셀과 그 아래 오른쪽 그리고 오른쪽 아래에 있는 4개의 픽셀들 중에서 가장 큰 값을 뽑고 나머지는 지우는 것이다.
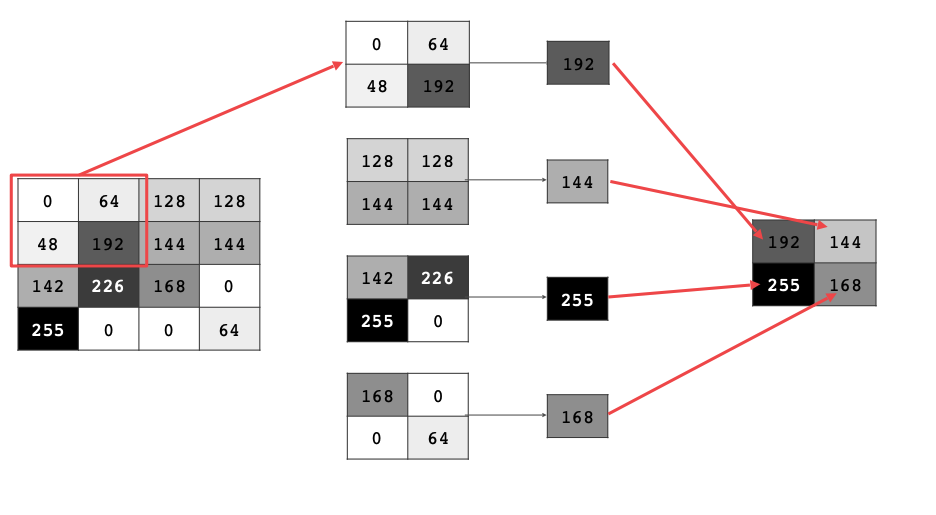
위 그림에서 보면 왼쪽에 16개의 픽셀이 2x2 격자에 의해서 오른쪽에 있는 4개의 픽셀로 바뀌었다.
풀링을 해서 이미지가 1/4가 되더라도 컨볼루션을 통해 추출된 수평, 수직 경계선과 같은 특징들은 유지될 것이다.
coding convolutions and pooling layers
Conv2D : https://www.tensorflow.org/api_docs/python/tf/keras/layers/Conv2D
MaxPooling2D
https://www.tensorflow.org/api_docs/python/tf/keras/layers/MaxPool2D
Implementing convolutional layers
코드로부터 컨볼루션과 풀링에 대해 살펴보자.
이전 예시의 코드를 보면 데이터의 입력 레이어와 정의하고자 하는 카테고리 숫자의 출력 레이어, 그리고 중간의 히든 레이어의 신경망을 정의했다.
Flatten 레이어는 28x28 이미지를 받아 그것을 1차원 array 로 변환했다.

여기에 컨볼루션을 추가하기 위해 아래와 같은 코드를 작성한다.

아래 세줄인 Flatten 레이어와 128개의 뉴런의 Dense 히든 레이어, 10개의 뉴런을 가진 Dense 출력 레이어는 동일하지만, 이 코드의 윗부분이 추가된 것을 볼 수 있다.
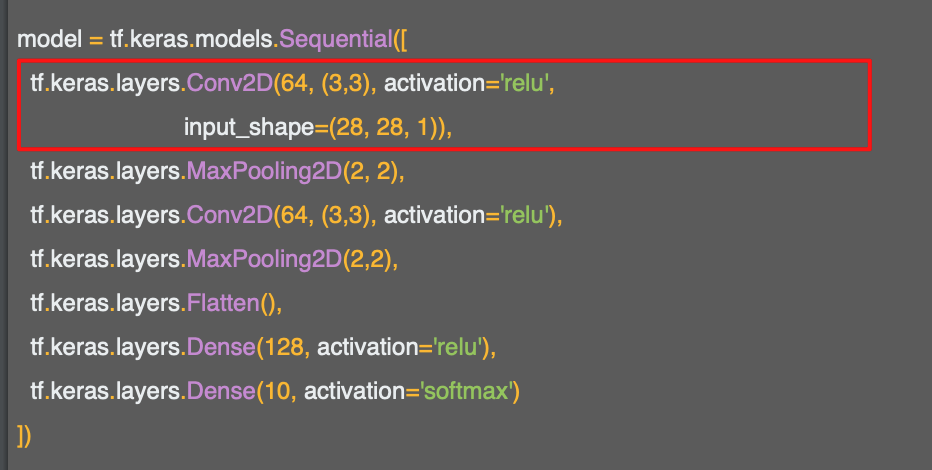
첫 번째 컨볼루션 레이어를 구체화한것으로
keras에게 64개의 필터를 생성하라고 요청한다.
필터들은 3x3 크기를 가지고 활성화 함수로는 ReLU를 사용한다.
즉, 모든 음수의 값은 0으로 변환된다.
입력 이미지는 28x28 이다.
마지막 1은 하나의 바이트를 color depth로 사용한다는 의미이다.
사용하는 이미지는 흑백이기 때문에 1바이트만을 사용한다.
64개의 필터는 이미 알려진 좋은 필터들의 세트로 시작해서 이전에 봤던 패턴에 맞는 유사한 방법으로 시간이 지날수록 학습된다.
컨볼루션과 그 역할에 대한 더 많은 정보는 위의 링크를 참고하면 된다.
Learn more about convolutions
Implementing pooling layers
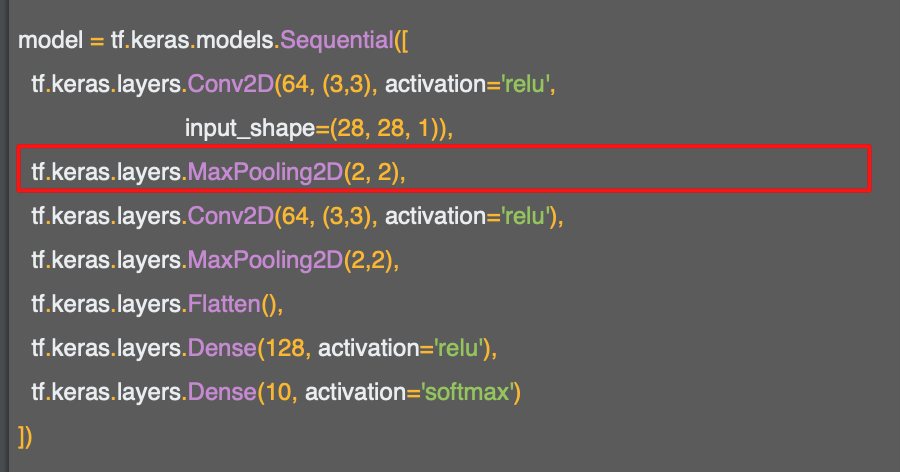
이 코드는 풀링 레이어를 생성한다.
맥스 풀링(max Pooling)이라고 하는데 그 이유는 최대값을 취하기 때문이다.
2x2 pooling으로 4개의 픽셀 중에서 가장 큰 값만 살아남는 것이다.
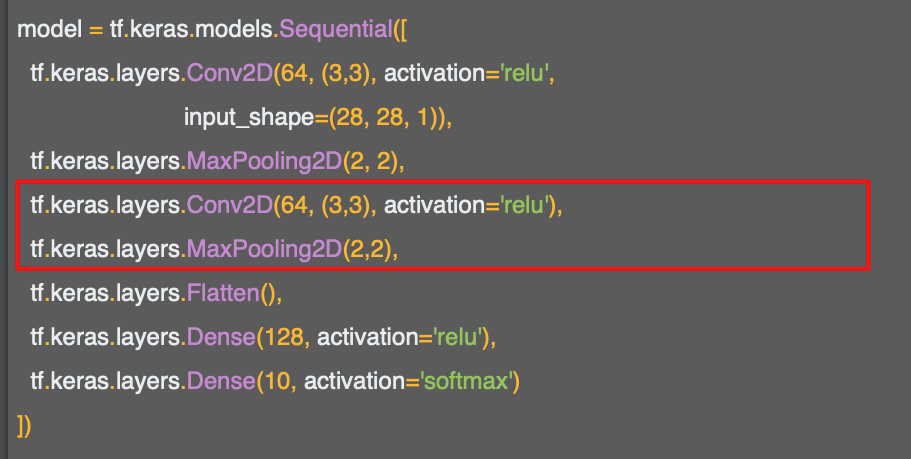
다음 또 다른 컨볼루션 레이어와 맥스 풀링 레이어를 추가하여 네트워크가 기존 컨볼루션 위에 또 다른 컨볼루션 세트를 학습한 다음 사이즈를 줄이기 위해 풀링을 적용한다.
따라서 이미지가 1차원으로 변환된 후 Dense 레이어로 들어가게 된다.
이미 많은 데이터가 줄어든 뒤로 이것이 1/4로 줄어들고 또 다시 1/4로 줄어든다.
결과적으로 데이터는 굉장히 단순화 된다.
이러한 것의 목적은 컨볼루션 레이어들이 결과를 결정하는데 필요한 특징만 걸러내도록 하는 것이다.
굉장히 유용한 모델의 메서드는 model.summary() 이다.
이는 모델의 레이어들을 살펴볼 수 있도록 해주고, 또 이미지가 컨볼루션 레이어들을 거치는 과정을 볼 수 있다.

이것은 레이어를 보여주는 훌룡한 표이다.
결과 형태를 포함한 여러 세부 사항을 보여준다.
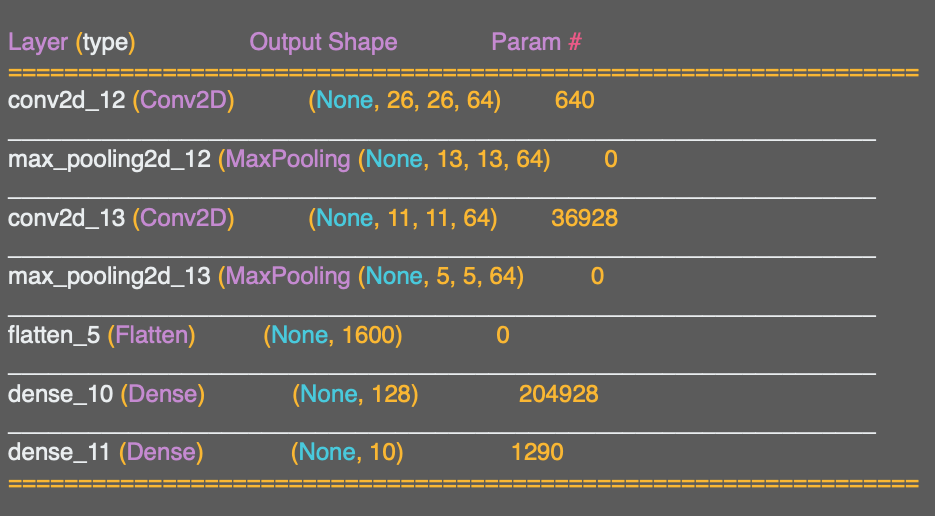
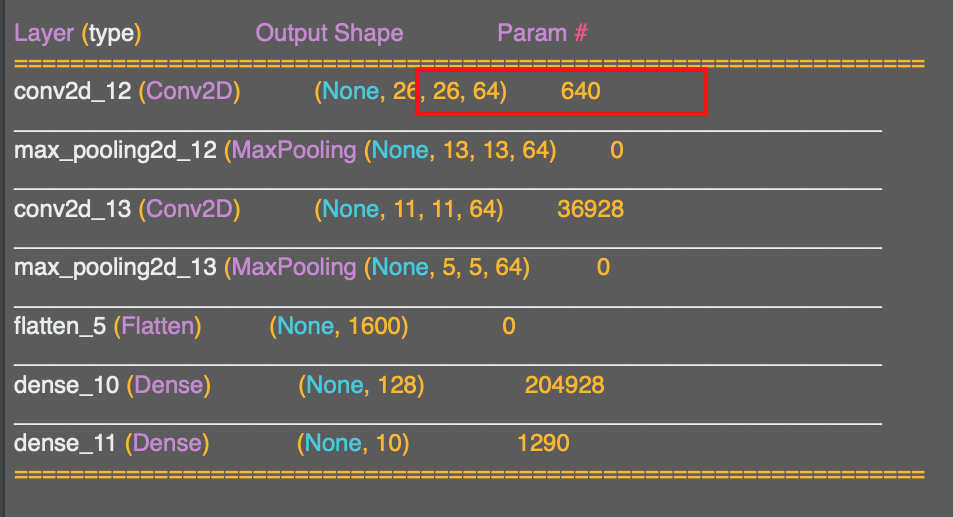
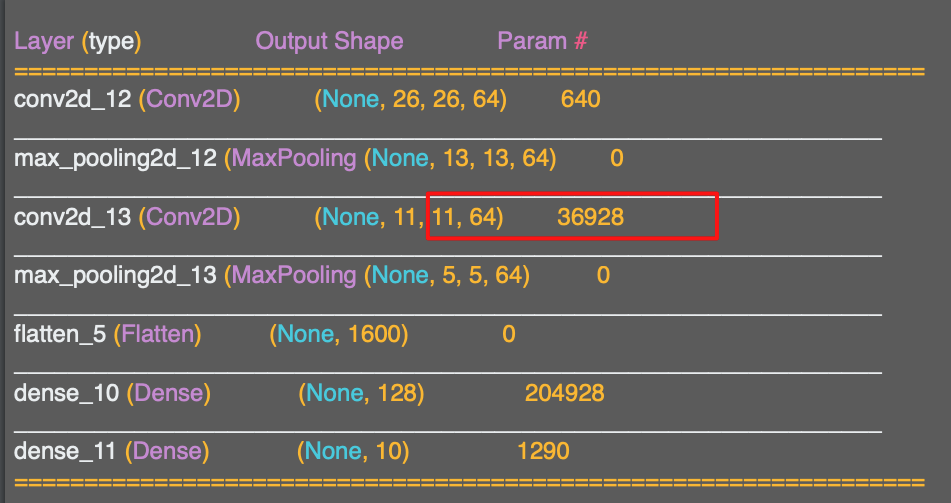
output shape에 집중해서 보면 다소 어색하고 느껴질 수 있다. 일단 데이터가 28x28이 아니다.
y가 결과이므로 26x26이다.
기억해야 하는 점은 필터가 3x3 필터라는 것이다.
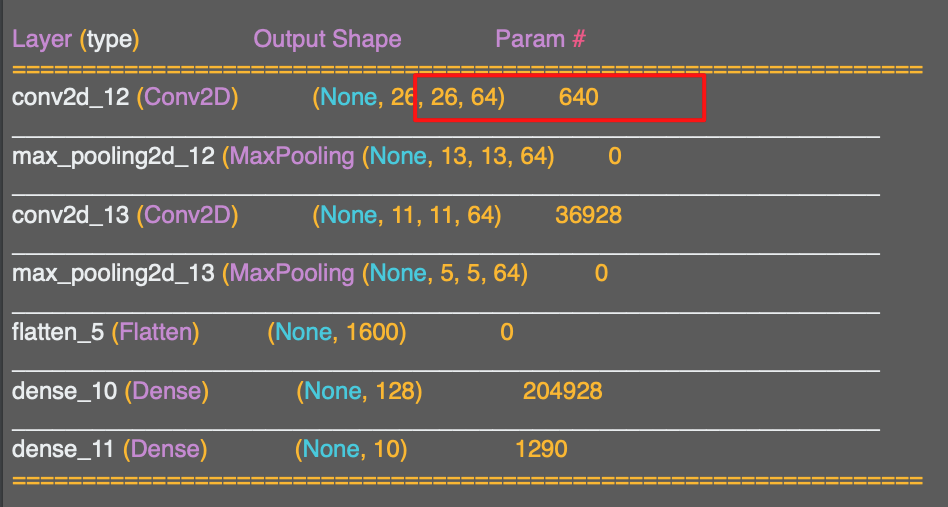
이미지의 좌측 상단부터 전체 이미지를 스캔한다고 했을 때, 예를 들어 오른쪽의 개 이미지는 이미지 좌측 상단의 픽셀을 확대해서 볼 수 있다.

좌측 상단에 있는 픽셀의 필터들은 계산할 수 없다.
왜냐하면 이 픽셀의 위쪽이나 왼쪽에 픽셀이 존재하지 않기 때문이다.
비슷한 관점에서 좌측 상단 픽셀의 오른쪽 픽셀에도 필터를 적용할 수 없다. 마찬가지로 위쪽에 아무 필터가 없기 때문이다.


논리적으로 계산할 수 있는 첫번째 픽셀은 바로 아래 그림이다.

3x3 필터에 필요한 여덟 개의 픽셀이 모두 있기 때문이다.
이를 생각해보면 이미지의 모든 부분에서 한 픽셀은 사용할 수 없다는 것을 의미한다.
따라서 컨볼루션의 결과는 보다 2픽셀, y보다도 2픽셀 작을 것이다.
비슷한 이유로 5x5 필터를 적용하면 x보다는 4픽셀, y보다는 4픽셀 작을 것이다

따라서 3x3 필터를 28x28 이미지에 적용한 결과는 26x26이 되는 것이다.
x와 y의 경계에 존재하는 한 픽셀을 제거한 것이다.
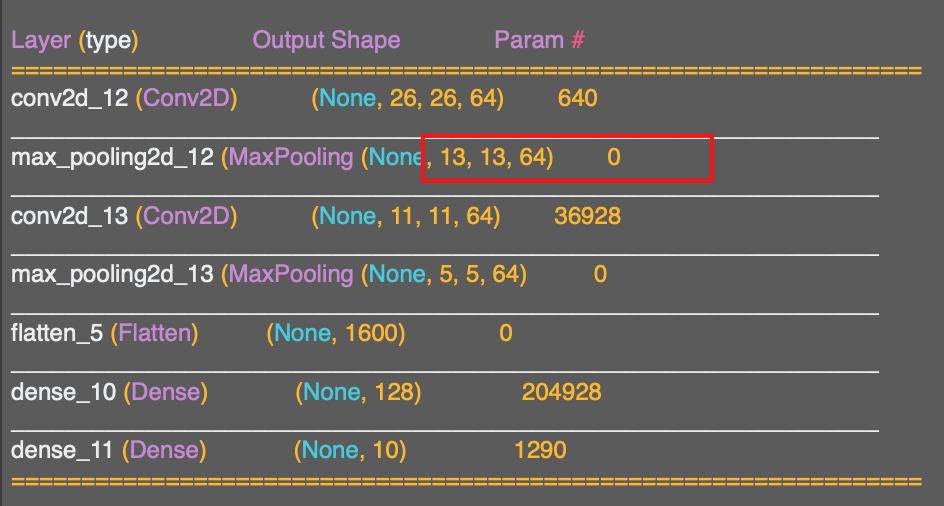
그 다음은 첫번째 맥스 풀링 레이어이다.
2x2로 지정했기 때문에 따라서 4개의 픽셀이 하나의 픽셀로 적용된다.
x와 y에 적용하면 26x26에서 13x13으로 줄어즌다.
그러면 컨볼루션이 그 결과에 적용되고,
물론 이전에 그랬듯 한 픽셀 잃게 되고 11x11 까지 내려간다.
또한 이것을 줄이기 위해 또 다른 2x2 맥스 풀링을 추가함으로써 이미지는 계속 줄어 들어 5x5 이미지까지 축소된다.
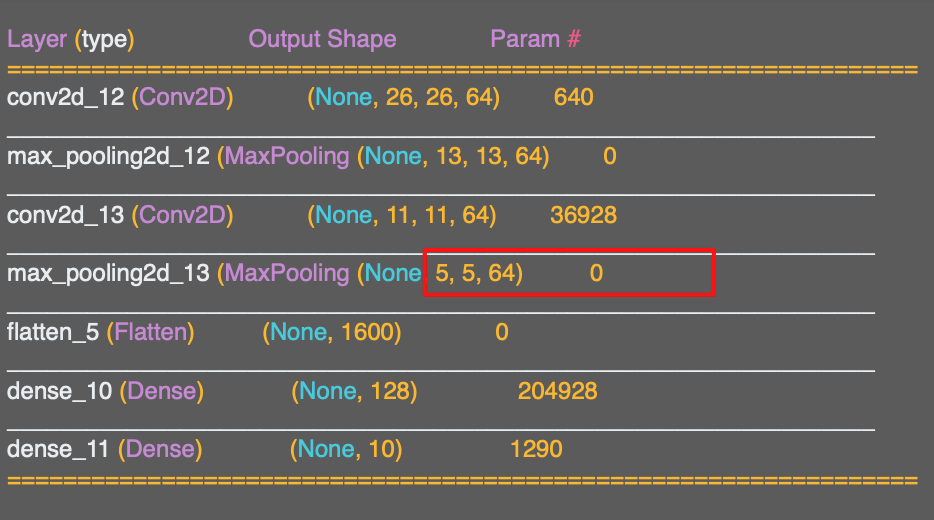
Dense 신경망은 이전과 같지만 28x28 이미지가 아니라 5x5 이미지가 주어질 것이다.
하지만 28x28이 5x5가 되는 과정은 한번에 이뤄진 것이 아니라 설정한 여러가지 컨볼루션이 이미지에 적용된 결과라는 것을 기억해야 한다.
이 경우에는 64개의 필터이다.
이제 5x5의 크기를 가진 64개의 이미지가 입력된다.
이걸 1차원으로 변환하면 25x64= 1,600개의 값을 가진다. 새로운 Flatten 레이어가 1,600개의 값을 가진 것을 확인할 수 있다.(이전에는 784개의 값이었다)
이 숫자는 정의한 컨볼루션 2D 레이어의 파라미터 값의 영향을 받는다.
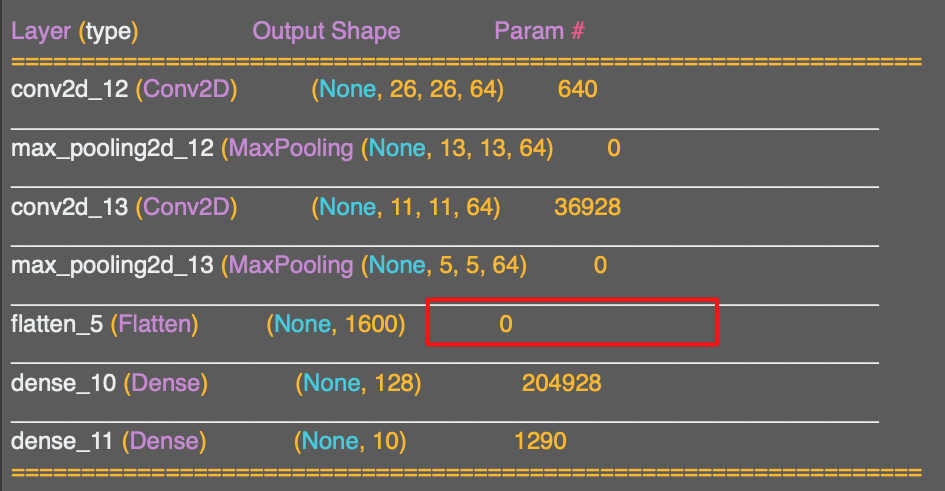
추후에 여러 변수들의 영향을 확인할 수 있는데, 컨볼루션 레이어의 개수와 같은 것들이다.
784개의 픽셀보다 더 적은 픽셀을 입력으로 사용할 경우 학습 과정은 빨라지지만 더 정확한 결과를 얻을 수 있을까? 이러한 부분을 프로그래밍으로 확인할 수 있다.
Improving the Fashion classifier with convolutions
컨볼루션으로 필터를 통과시킴으로써 이미지의 정보량을 줄였다.
이를 통해 신경망이 효과적으로 특징을 추출할 수 있게 하여 속성들을 잘 분류할 수 있게 됐다. 또한 풀링을 통해서 정보를 다루기 쉽도록 압축했다.
풀링은 인지 성능을 향상시키는 좋은 방법이다.
Walking through convolutions
이전 장에서는 신경망의 효율성과 학습에 컨볼루션과 풀링의 영향력을 봤지만 이론적인 학습이 대부분이었다.
코드를 같이 보면서 실제로 컨볼루션이 어떻게 움직이는지 확인해보고, 풀링 알고리즘을 생성해보면서 그 영향을 눈으로 확인해볼 수 있다.
