[Tensorflow] 1. TensorFlow for Artificial Intelligence, Machine Learning, and Deep Learning Paradigm(3 week Enhancing Vision with Convolutional Neural Networks) - programming (1)
Tensorflow_certification(텐서플로우 자격증)
[Tensorflow] 1. TensorFlow for Artificial Intelligence, Machine Learning, and Deep Learning Paradigm(3 week Enhancing Vision with Convolutional Neural Networks) - programming
상단에 컨볼루션 레이어를 추가하고 원시 픽셀 대신 컨볼루션 결과에 대해 네트워크를 훈련시켜 심층 신경망을 컨볼루셔널 신경망으로 전환하는 방법을 살펴봤다. 이러한 과정을 단계별로 진행하여 이것이 어떻게 작동하는지 살펴보자.
컨볼루션을 사용하여 컴퓨터 비전 정확도 향상- Shallow Neural Network
[1] data load & data normalization
import tensorflow as tf
fmnist = tf.keras.datasets.fashion_mnist
(x_train, y_train), (x_test, y_test) = fmnist.load_data()
x_train = x_train/255.0
x_test = x_test/255.0
[2] model build & compile & fit & evaluate
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
test_loss = model.evaluate(x_test,y_test)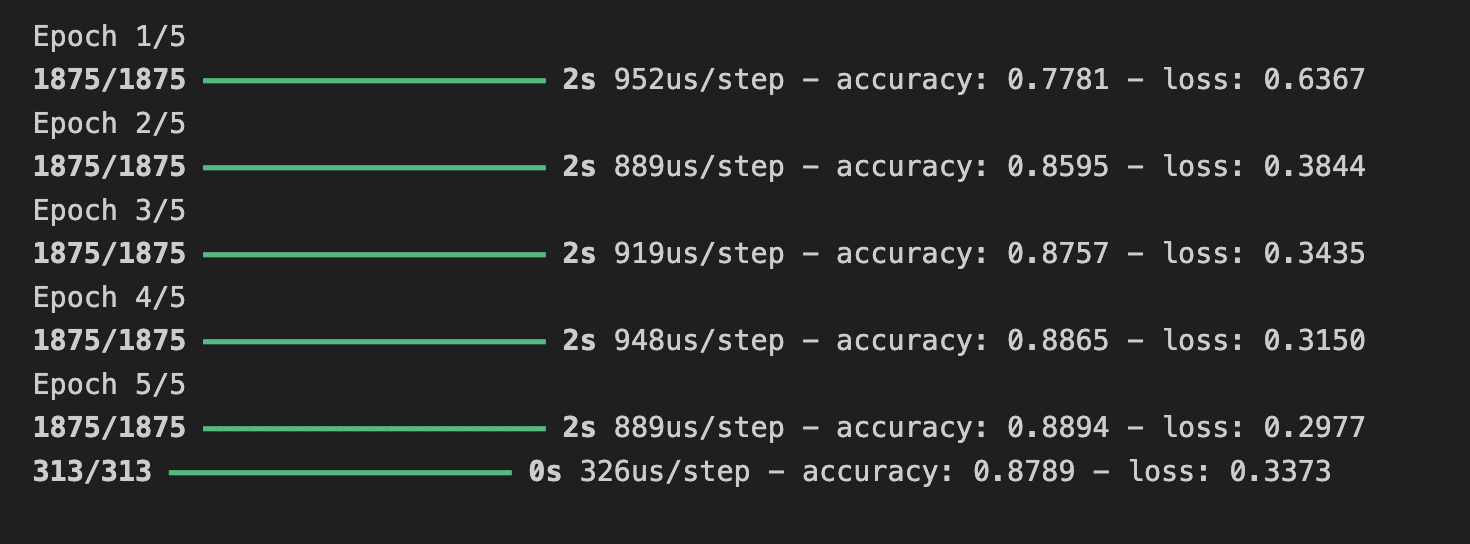
[3] Convolutional Neural Network 모델과의 비교
-
위 모델에서 정확도는 훈련 시 약 88.9%, 검증 시 약 87.8% 이 나왔다.
어떻게 하면 더 나은 결과를 얻을 수 있을까?
한 가지 방법은 컨볼루션이라는 것을 사용하는 것이다.
특정 부분에 초점을 맞추기 위해 이미지의 내용을 좁히고 모델 정확도를 향상시키는 과정이다. -
필터(이와 같은)를 사용하여 배열(보통 3x3 또는 5x5)을 가져와 전체 이미지에 걸쳐 스캔한다. 해당 행렬 내의 수식을 기반으로 기본 픽셀을 변경하면 가장자리 감지와 같은 작업을 수행할 수 있다. 예를 들어 위 링크를 보면 중간 셀이 8이고 모든 이웃 셀이 -1인 가장자리 감지를 위해 정의된 3x3 행렬을 볼 수 있다. 이 경우 각 픽셀에 대해 해당 값에 8을 곱한 다음 각 이웃의 값을 뺀다. 모든 픽셀에 대해 이 작업을 수행하면 가장자리가 강화된 새로운 이미지가 생성된다.
이는 한 항목을 다른 항목과 구별하는 기능을 강조하는 경우가 많기 때문에 컴퓨터 비전에 적합하다. 또한 강조 표시된 기능만 학습하므로 필요한 정보의 양이 훨씬 적다.
이것이 컨볼루셔널 신경망(Convolutional Neural Networks)의 개념이다. 조밀한 레이어를 갖기 전에 컨볼루션을 수행하기 위해 일부 레이어를 추가하면 밀도가 높은 레이어로 이동하는 정보가 더 집중되고 더 정확해질 수 있다.
아래의 과정은 Convolution 및 MaxPooling 레이어가 먼저 추가되었다.
시간은 더 오래 걸리지만 정확도에 미치는 영향을 살펴보자.
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.summary()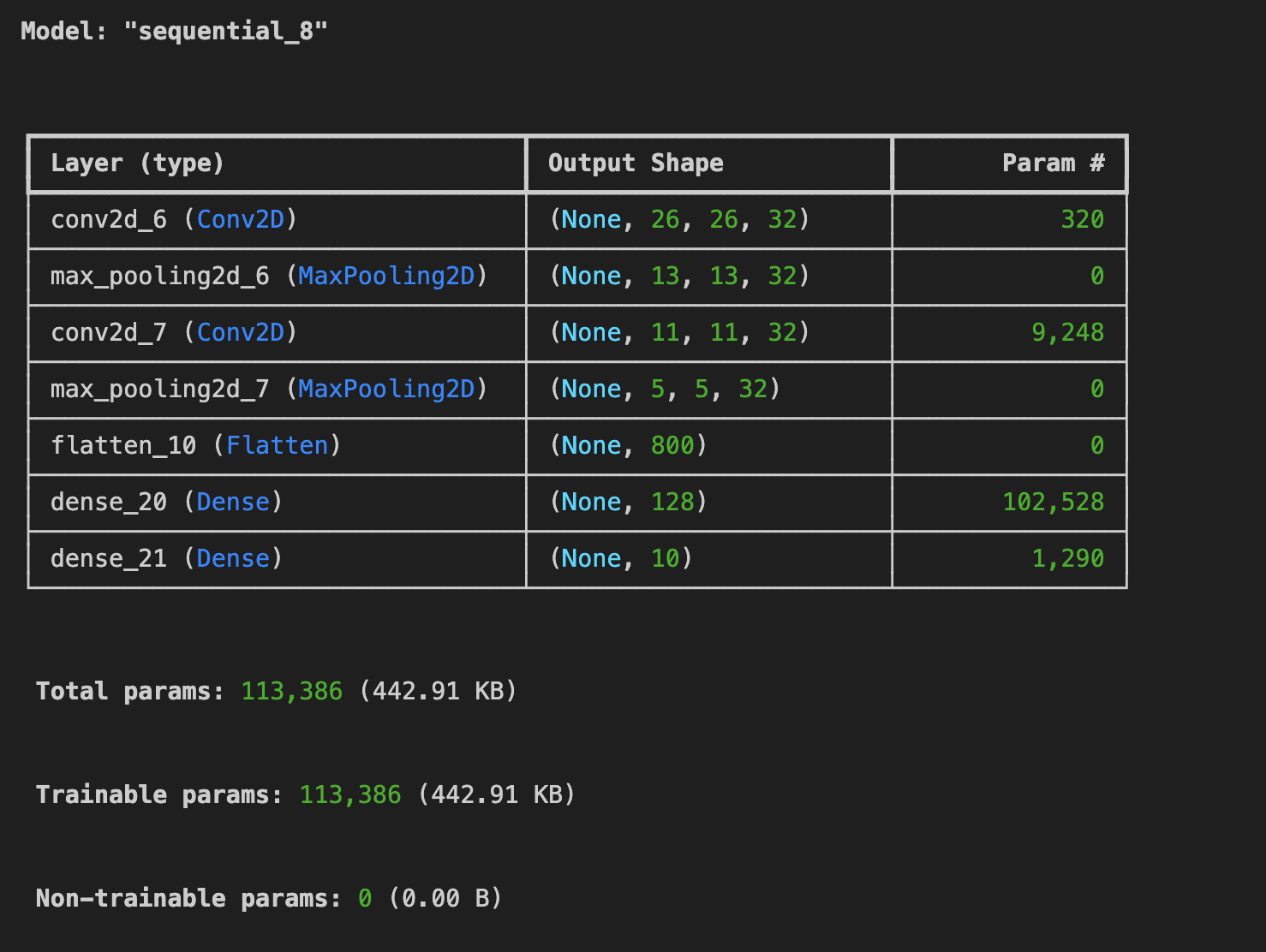
model.compile(loss='sparse_categorical_crossentropy',
metrics=['accuracy'],
optimizer='adam')
model.fit(x_train, y_train, epochs=5)
test_loss = model.evaluate(x_test, y_test)
훈련 데이터에서는 약 91.8%, 검증 데이터에서는 90.3%까지 올라갔다.
위 코드에서 컨볼루션이 어떻게 구축되었는지 단계별로 살펴보면, 상단의 입력 레이어 대신 Conv2D 레이어를 추가했다.
위 모델의 매개변수는
(1) 생성하려는 컨볼루션 수
- 여기의 값은 순전히 임의적이지만 32부터 시작하여 2의 거듭제곱을 사용하는 것이 좋다.
(2) 컨볼루션의 크기 - 이 경우에는 3x3 그리드이다.
(3) 활성화함수 - 이 경우 ReLU를 사용했는데, 이는 x>0일 때 x를 반환하고 그렇지 않으면 0을 반환하는 것과 동일하다.
위 모델의 스트럭처에서의 첫 번째 레이어에서는 입력 데이터의 모양으로,
컨볼루션에 의해 강조된 기능의 내용을 유지하면서 이미지를 압축하도록 설계된 MaxPool2D 레이어를 사용하여 컨볼루션을 따라가게 된다.
MaxPooling에 (2,2)를 지정하면 이미지 크기가 4분의 1로 줄어드는 효과가 있다. 2x2 픽셀 배열을 생성하고 가장 큰 것을 선택한다는 아이디어이다. 따라서 4픽셀을 1픽셀로 바꿉니다. 이를 이미지 전체에 반복하여 수평 및 수직 픽셀 수를 절반으로 줄여 이미지를 원본 이미지의 25%로 효과적으로 줄인다.
model.summary()를 호출하여 네트워크의 크기와 모양을 확인할 수 있으며, 모든 최대 풀링 레이어 이후에 이미지 크기가 이런 방식으로 줄어드는 것을 확인할 수 있습다.
모델 = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3,3), 활성화='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2, 2),
그런 다음 또 다른 컨볼루션을 추가하고 출력을 평면화했습니다.
tf.keras.layers.Conv2D(64, (3,3), 활성화='relu'),
tf.keras.layers.MaxPooling2D(2,2)
tf.keras.layers.Flatten(),
그 후에는 비합성곱 버전과 동일한 DNN 구조를 갖게 된다. 128개의 뉴런이 있는 동일한 밀집 레이어와 사전 컨볼루션 예에서와 같이 10개의 뉴런이 있는 출력 레이어:
tf.keras.layers.Dense(128, 활성화='relu'),
tf.keras.layers.Dense(10, 활성화='softmax')
])
과적합
- 더 많은 에포크(약 20개) 동안 훈련을 실행하고 결과를 살펴보자.
그러나 결과가 정말 좋아 보일 수도 있지만 과적합이라는 현상으로 인해 검증 결과가 실제로 저하될 수도 있다.
간단히 말해서, 과적합은 네트워크가 훈련 세트에서 데이터를 매우 잘 학습하지만 해당 데이터에만 너무 특화되어 결과적으로 보이지 않는 다른 데이터를 해석하는 데 덜 효과적일 때 발생한다.
예를 들어, 평생 빨간 신발만 본다면 빨간 신발을 볼 때 그것을 식별하는 데 매우 능숙할 것이다. 하지만 파란색 스웨이드 신발은 잘 맞추지 못할 수 있다.
[4] Visualizing the Convolutions and Pooling
- 컨볼루션을 그래픽으로 표시하는 방법을 살펴보자.
아래 셀은 테스트 세트의 처음 100개 레이블을 인쇄하며 인덱스 0, 인덱스 23 및 인덱스 28의 레이블이 모두 동일한 값(예: 9)임을 확인할 수 있다.
모두 신발을 의미한다.
각각에 대해 컨볼루션을 실행한 결과를 살펴보면, 그러면 둘 사이의 공통적인 특징이 나타나는 것을 볼 수 있을 것이다.
이제 밀집 계층(Dense Layer)이 해당 데이터를 훈련할 때 훨씬 적은 양으로 작업하며 아마도 이 컨볼루션/풀링 조합을 기반으로 신발 간의 공통점을 찾는 것일 수 있다.
f, axarr = plt.subplots(3,4)
FIRST_IMAGE=0
SECOND_IMAGE=23
THIRD_IMAGE=28
CONVOLUTION_NUMBER = 1
layer_outputs = [layer.output for layer in model.layers]
print(layer_outputs)
print(model.inputs)
activation_model = tf.keras.models.Model(inputs = model.inputs, outputs = layer_outputs)
for x in range(0,4):
f1 = activation_model.predict(x_test[FIRST_IMAGE].reshape(1, 28, 28, 1))[x]
axarr[0,x].imshow(f1[0, : , :, CONVOLUTION_NUMBER], cmap='inferno')
axarr[0,x].grid(False)
f2 = activation_model.predict(x_test[SECOND_IMAGE].reshape(1, 28, 28, 1))[x]
axarr[1,x].imshow(f2[0, : , :, CONVOLUTION_NUMBER], cmap='inferno')
axarr[1,x].grid(False)
f3 = activation_model.predict(x_test[THIRD_IMAGE].reshape(1, 28, 28, 1))[x]
axarr[2,x].imshow(f3[0, : , :, CONVOLUTION_NUMBER], cmap='inferno')
axarr[2,x].grid(False)
# output
[<KerasTensor shape=(None, 26, 26, 32), dtype=float32, sparse=False, name=keras_tensor_41>, <KerasTensor shape=(None, 13, 13, 32), dtype=float32, sparse=False, name=keras_tensor_42>, <KerasTensor shape=(None, 11, 11, 32), dtype=float32, sparse=False, name=keras_tensor_43>, <KerasTensor shape=(None, 5, 5, 32), dtype=float32, sparse=False, name=keras_tensor_44>, <KerasTensor shape=(None, 800), dtype=float32, sparse=False, name=keras_tensor_45>, <KerasTensor shape=(None, 128), dtype=float32, sparse=False, name=keras_tensor_46>, <KerasTensor shape=(None, 10), dtype=float32, sparse=False, name=keras_tensor_47>]
[<KerasTensor shape=(None, 28, 28, 1), dtype=float32, sparse=None, name=keras_tensor_40>]

추가 학습
(1) 컨볼루션을 편집해 보세요. 32를 16 또는 64로 변경해보자.
이것이 정확도 및/또는 훈련 시간에 어떤 영향을 미칠까?
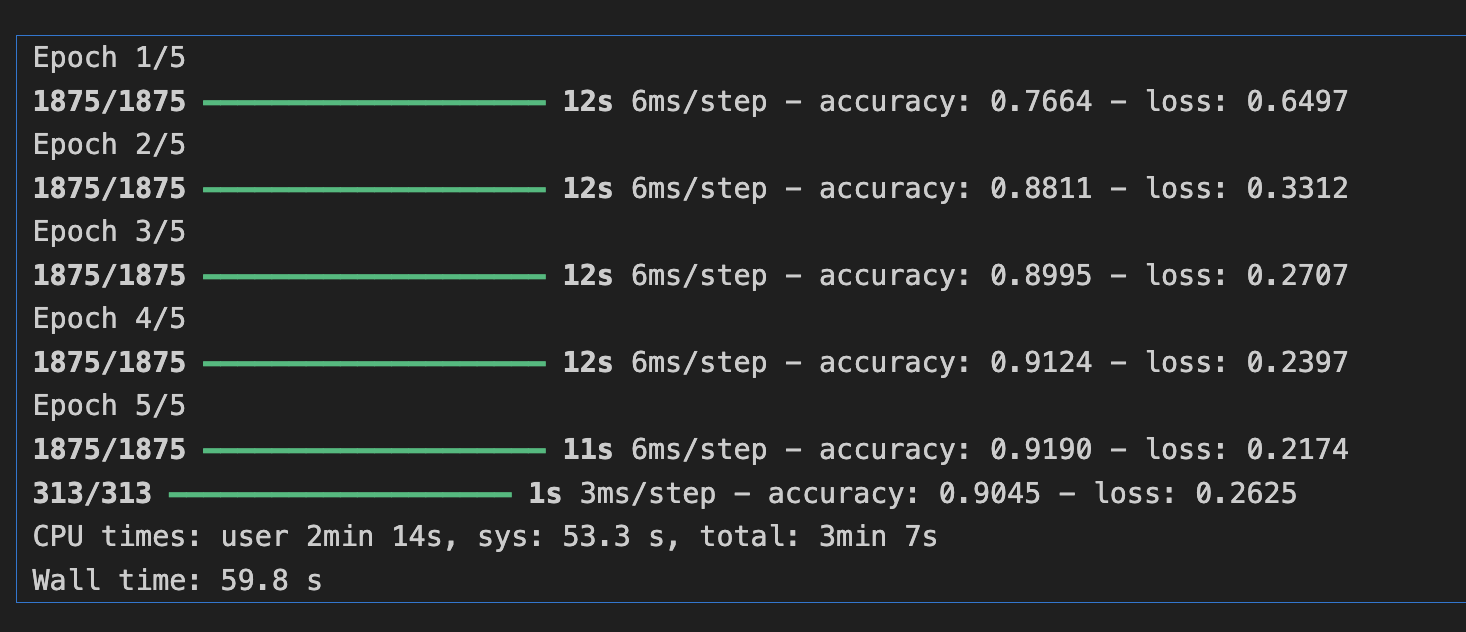
- 컨볼루션이 32 인경우
%%time
import tensorflow as tf
fmnist = tf.keras.datasets.fashion_mnist
(x_train, y_train), (x_test, y_test) = fmnist.load_data()
x_train = x_train/255.0
x_test = x_test/255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.summary()
model.compile(loss='sparse_categorical_crossentropy',
metrics=['accuracy'],
optimizer='adam')
model.fit(x_train, y_train, epochs=5)
test_loss = model.evaluate(x_test, y_test)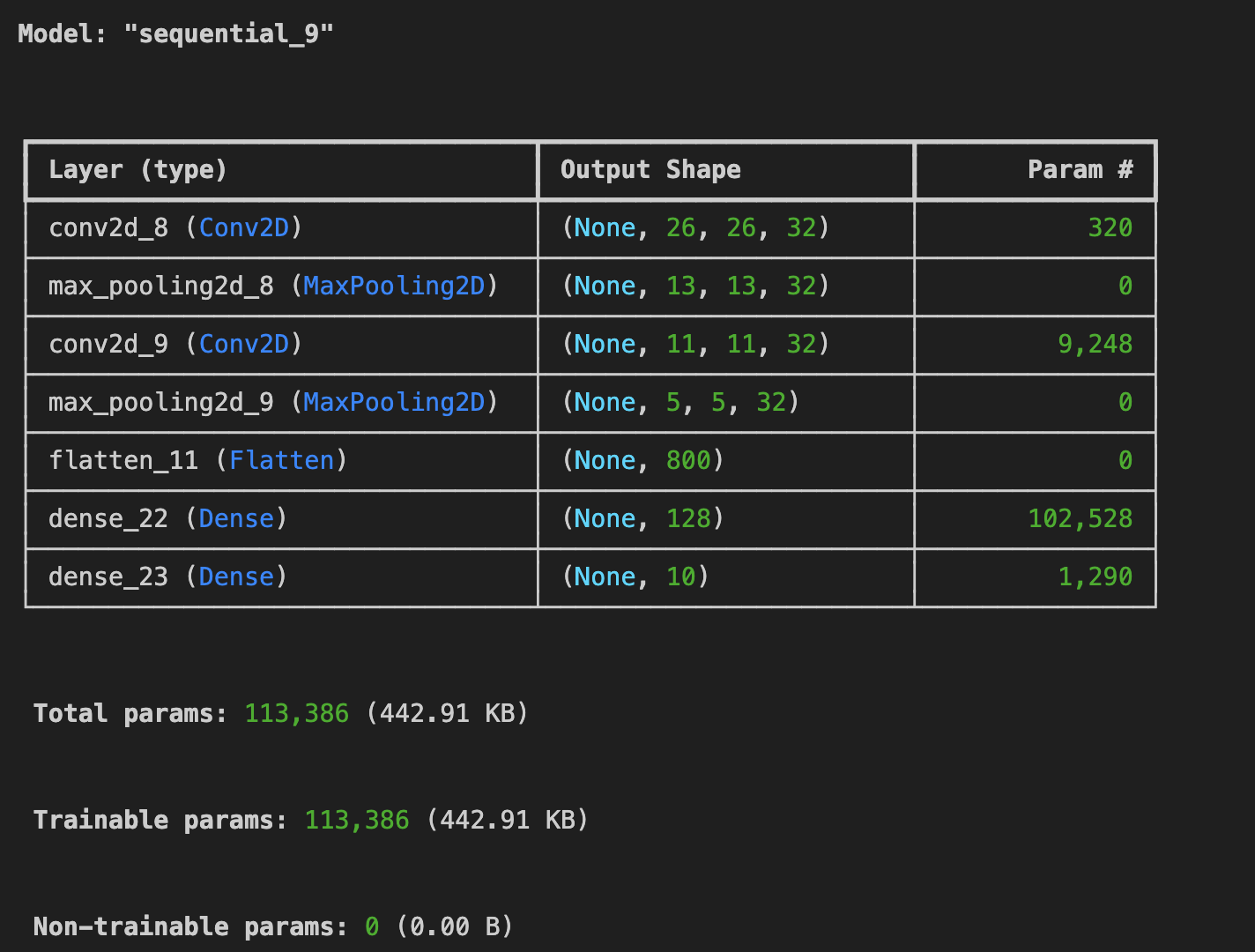
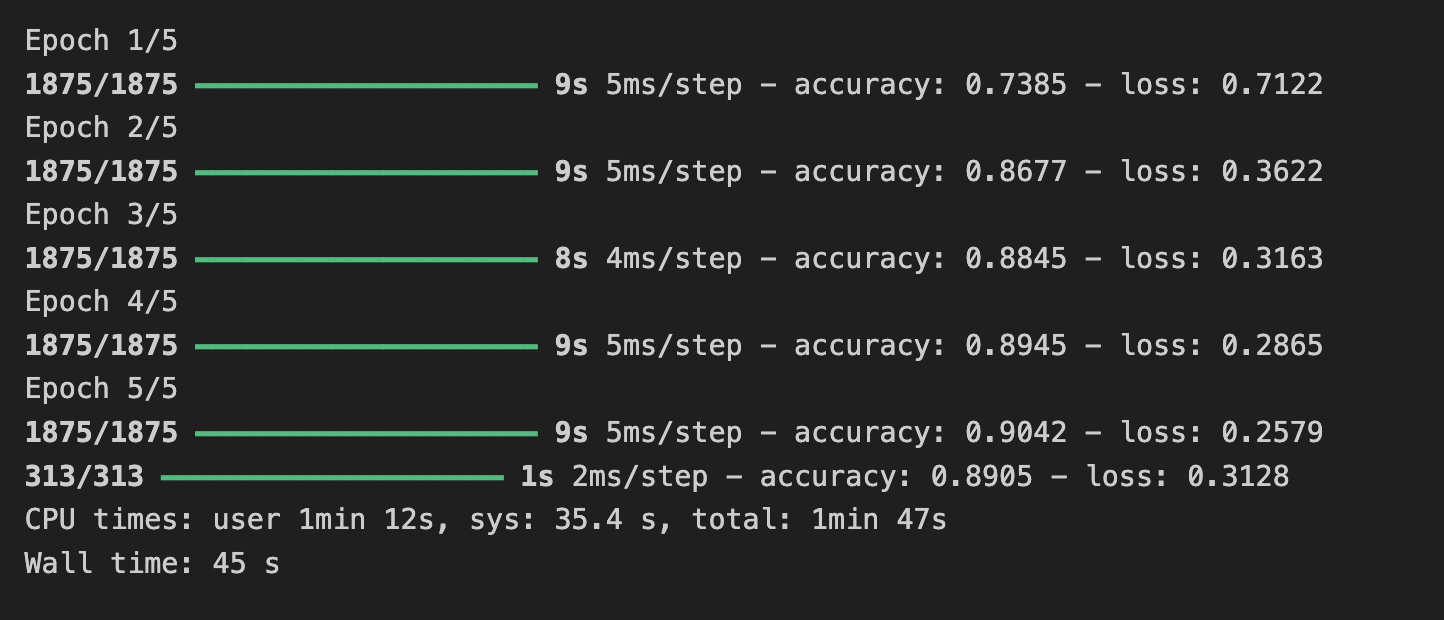
- 컨볼루션이 16인 경우
%%time
import tensorflow as tf
fmnist = tf.keras.datasets.fashion_mnist
(x_train, y_train), (x_test, y_test) = fmnist.load_data()
x_train = x_train/255.0
x_test = x_test/255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (3,3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(16, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.summary()
model.compile(loss='sparse_categorical_crossentropy',
metrics=['accuracy'],
optimizer='adam')
model.fit(x_train, y_train, epochs=5)
test_loss = model.evaluate(x_test, y_test)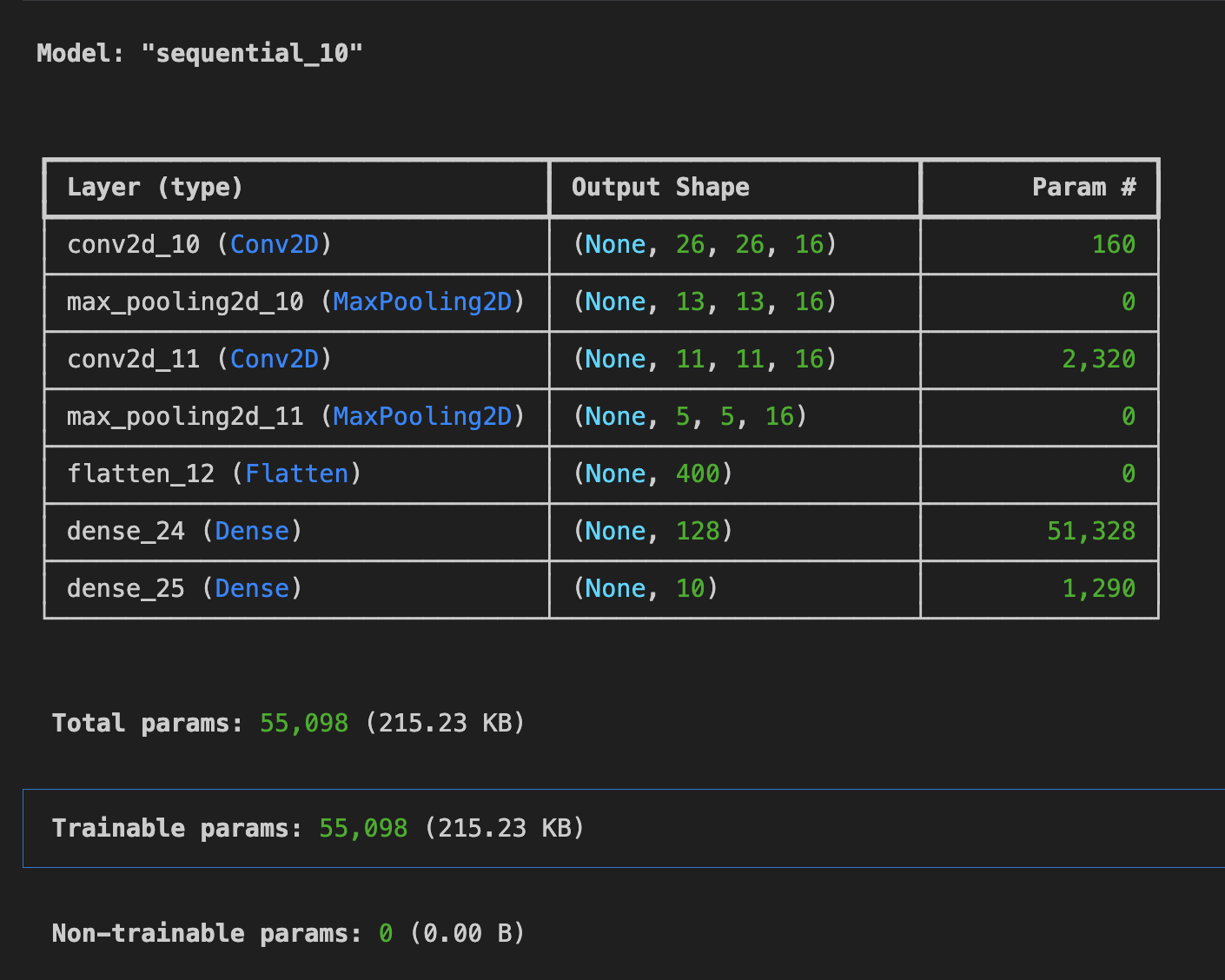
- 컨볼루션이 64인 경우
%%time
import tensorflow as tf
fmnist = tf.keras.datasets.fashion_mnist
(x_train, y_train), (x_test, y_test) = fmnist.load_data()
x_train = x_train/255.0
x_test = x_test/255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(64, (3,3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.summary()
model.compile(loss='sparse_categorical_crossentropy',
metrics=['accuracy'],
optimizer='adam')
model.fit(x_train, y_train, epochs=5)
test_loss = model.evaluate(x_test, y_test)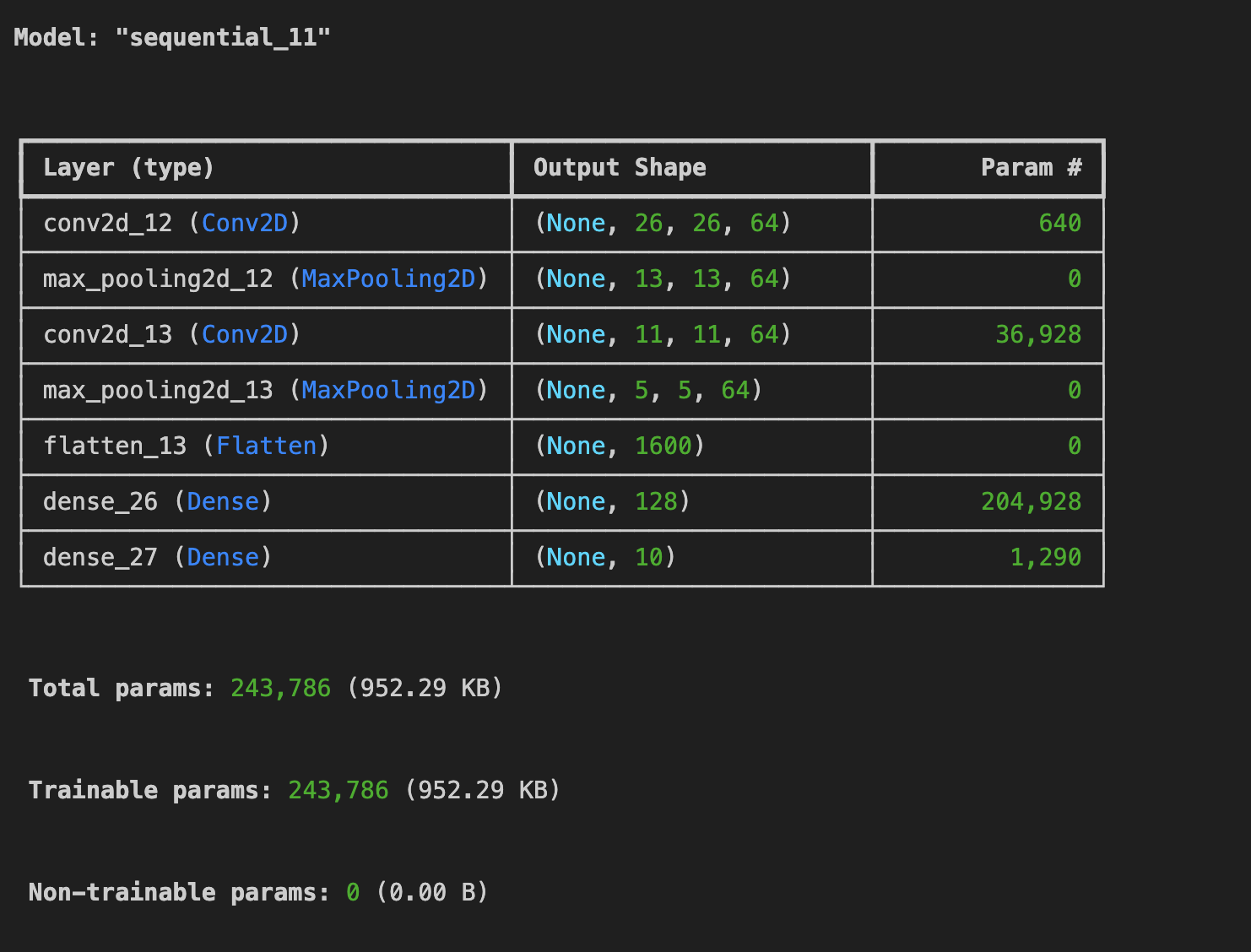
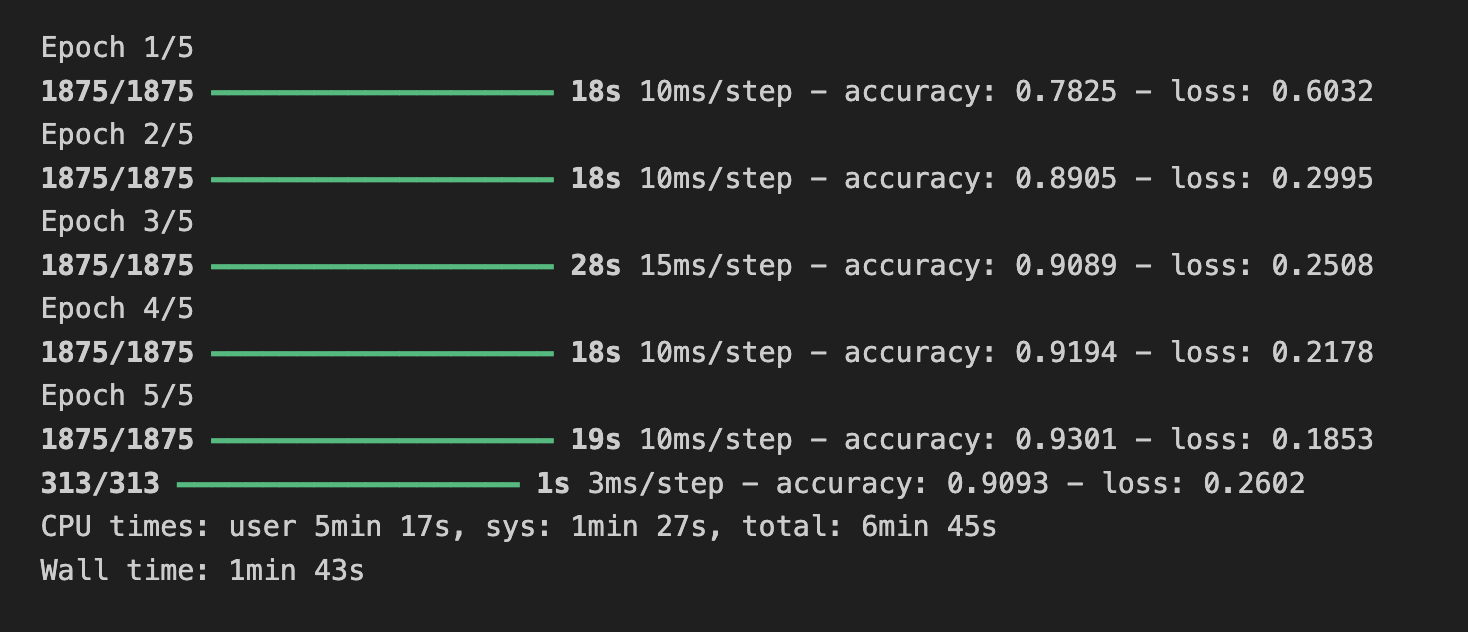
-> 필터를 64로 변경했을 때 시간은 6분 45초 소요 학습 정확도 93.0%, 검증 정확도 90.9%
필터가 32일때 시간은 3분 7초, 학습 정확도 91.0%, 검증 정확도 90.4%,
필터 16일때 시간은 1분 47초, 학습 정확도 90.0%, 검증 정확도 89.0%
즉 필터가 증가할 수록 학습 소요 시간은 증가하고 정확도가 증가하는 모습을 보였다.
(2) 최종 컨볼루션을 제거해보자. 이것이 정확성이나 훈련 시간에 어떤 영향을 미칠까?
%%time
import tensorflow as tf
fmnist = tf.keras.datasets.fashion_mnist
(x_train, y_train), (x_test, y_test) = fmnist.load_data()
x_train = x_train/255.0
x_test = x_test/255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2, 2),
# tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
# tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.summary()
model.compile(loss='sparse_categorical_crossentropy',
metrics=['accuracy'],
optimizer='adam')
model.fit(x_train, y_train, epochs=5)
test_loss = model.evaluate(x_test, y_test)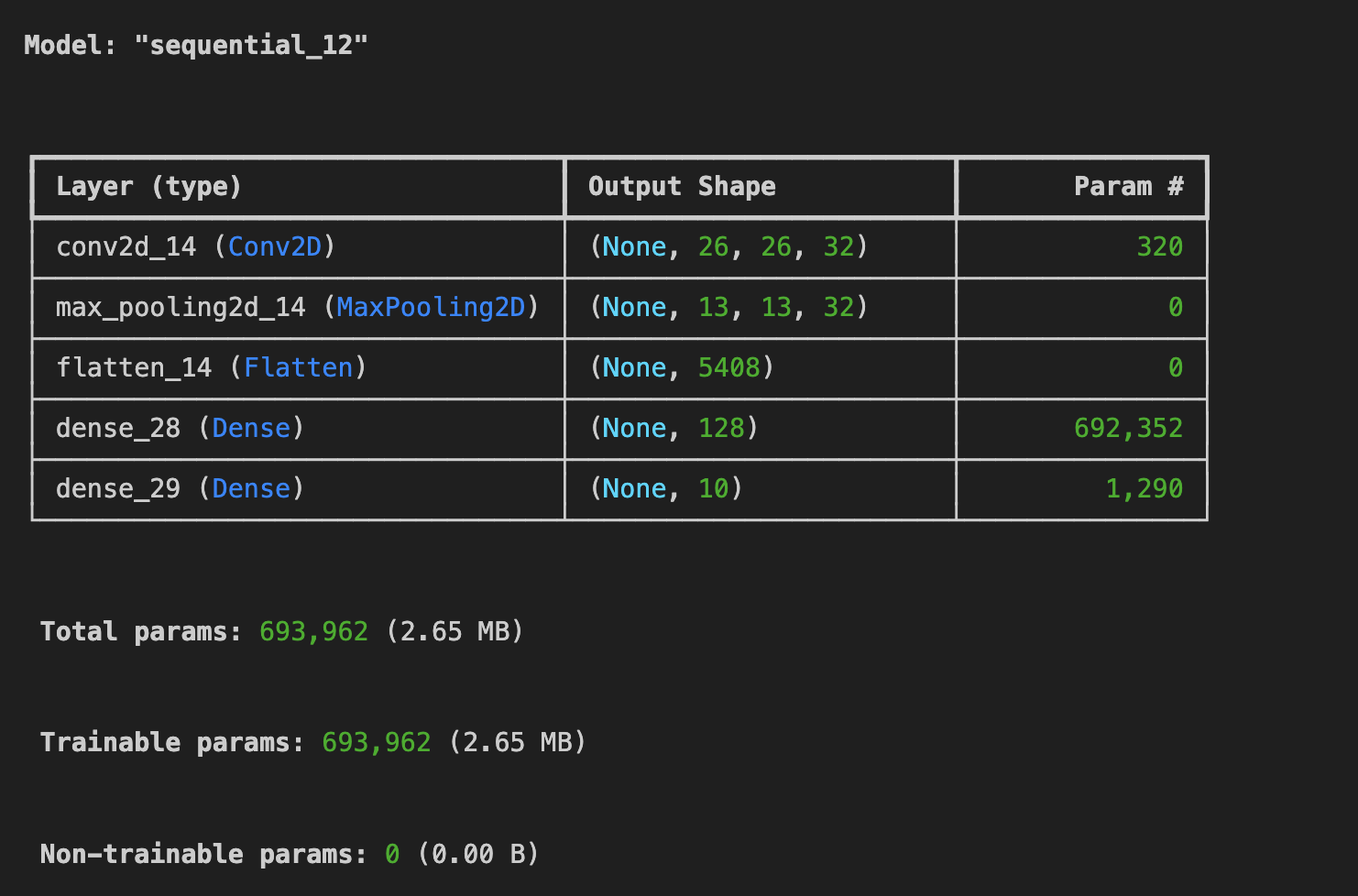
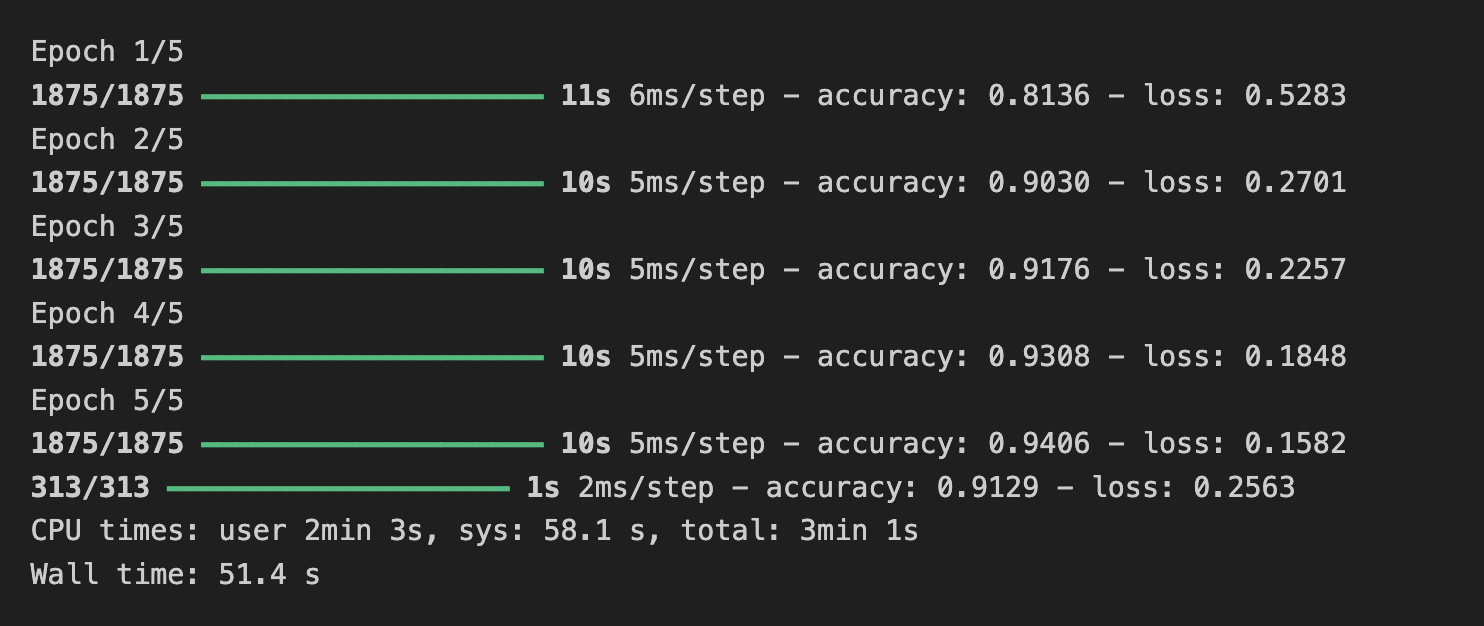
-> 최종 컨볼루션을 하나 삭제해보니,
학습 정확도 94%, 검증 정확도가 91%로 컨볼루션이 2개 인 것보다 더 좋은 정확도를 보인다.
(3) Convolution을 더 추가하면 이것이 어떤 영향을 미칠까?
%%time
import tensorflow as tf
fmnist = tf.keras.datasets.fashion_mnist
(x_train, y_train), (x_test, y_test) = fmnist.load_data()
x_train = x_train/255.0
x_test = x_test/255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# convolution 추가
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.summary()
model.compile(loss='sparse_categorical_crossentropy',
metrics=['accuracy'],
optimizer='adam')
model.fit(x_train, y_train, epochs=5)
test_loss = model.evaluate(x_test, y_test)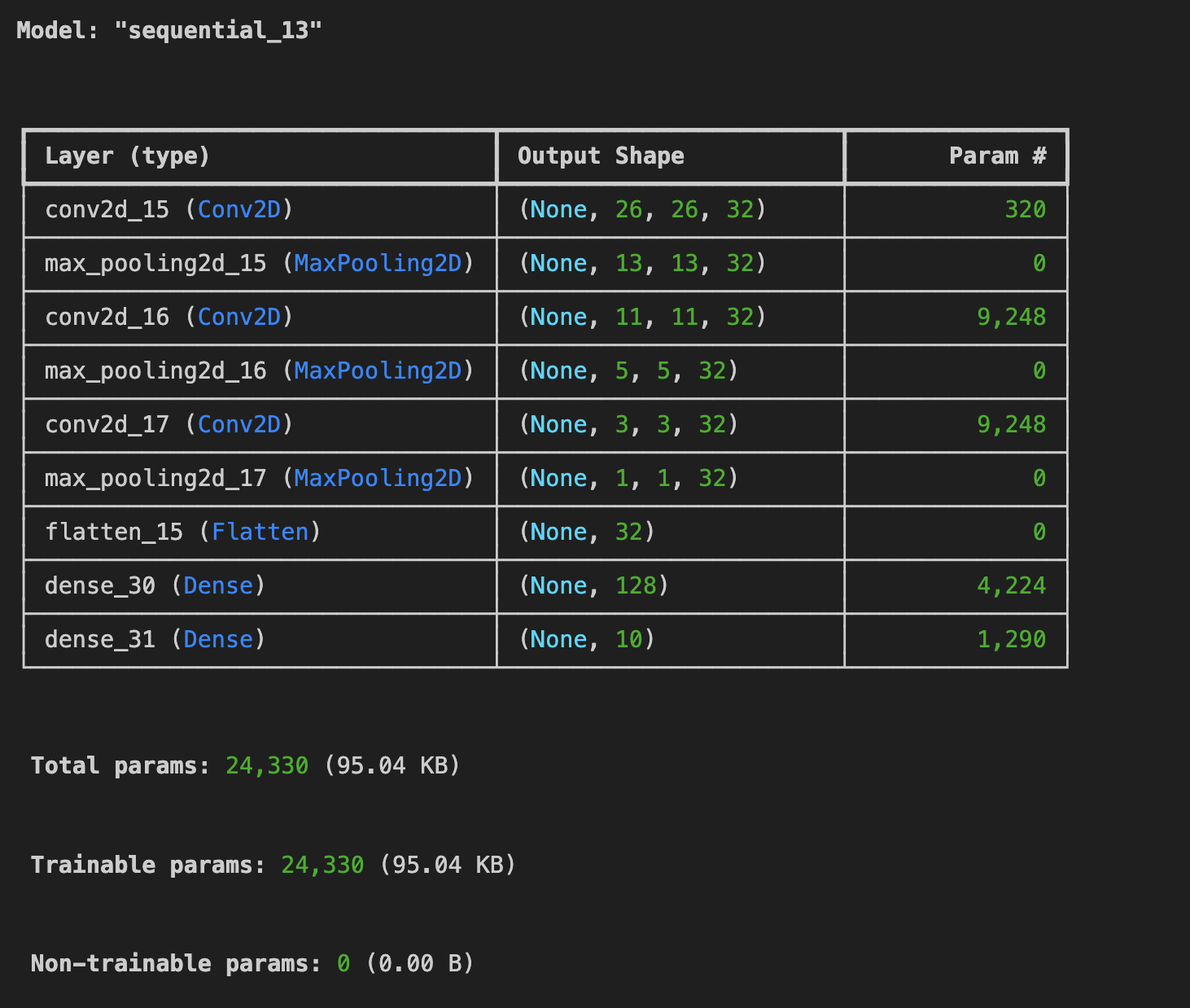
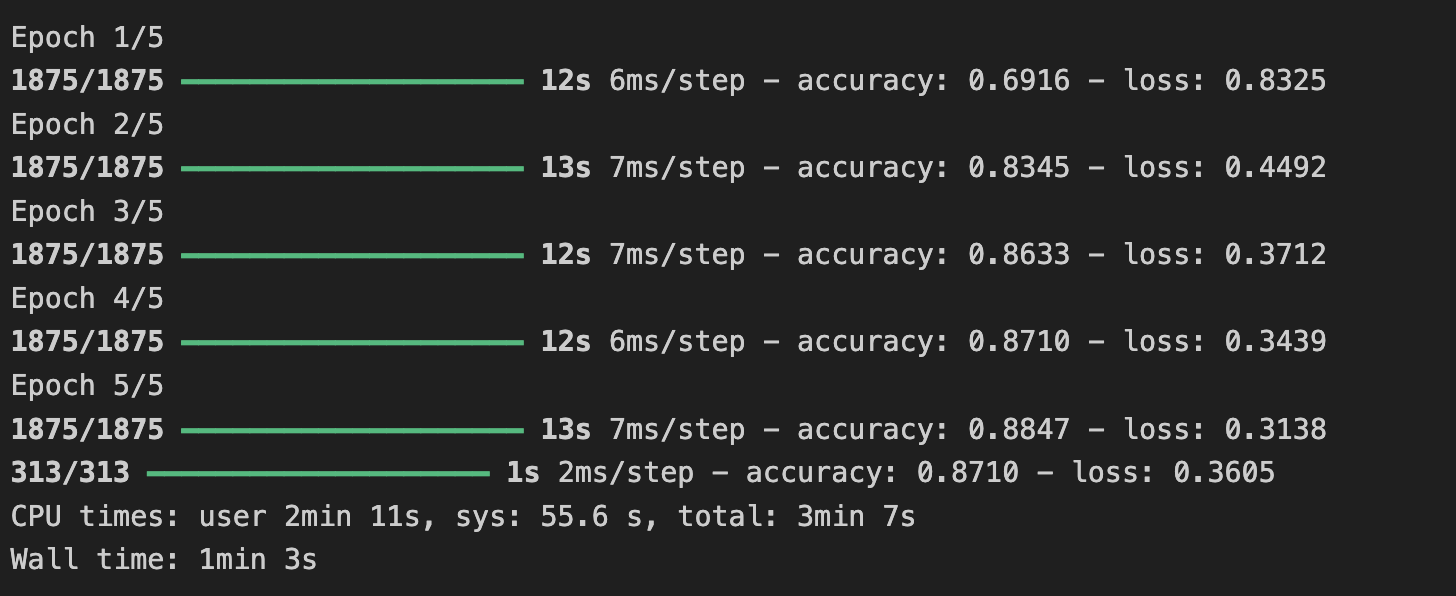
-> 컨볼루션을 1층 더 추가했으나 학습 및 검증 데이터 정확도가 더 떨어졌다.
(4) 첫 번째 컨볼루션을 제외한 모든 컨볼루션을 제거해보자. 이것이 어떤 영향을 미칠까?
%%time
import tensorflow as tf
fmnist = tf.keras.datasets.fashion_mnist
(x_train, y_train), (x_test, y_test) = fmnist.load_data()
x_train = x_train/255.0
x_test = x_test/255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.summary()
model.compile(loss='sparse_categorical_crossentropy',
metrics=['accuracy'],
optimizer='adam')
model.fit(x_train, y_train, epochs=5, callbacks=callbacks)
test_loss = model.evaluate(x_test, y_test)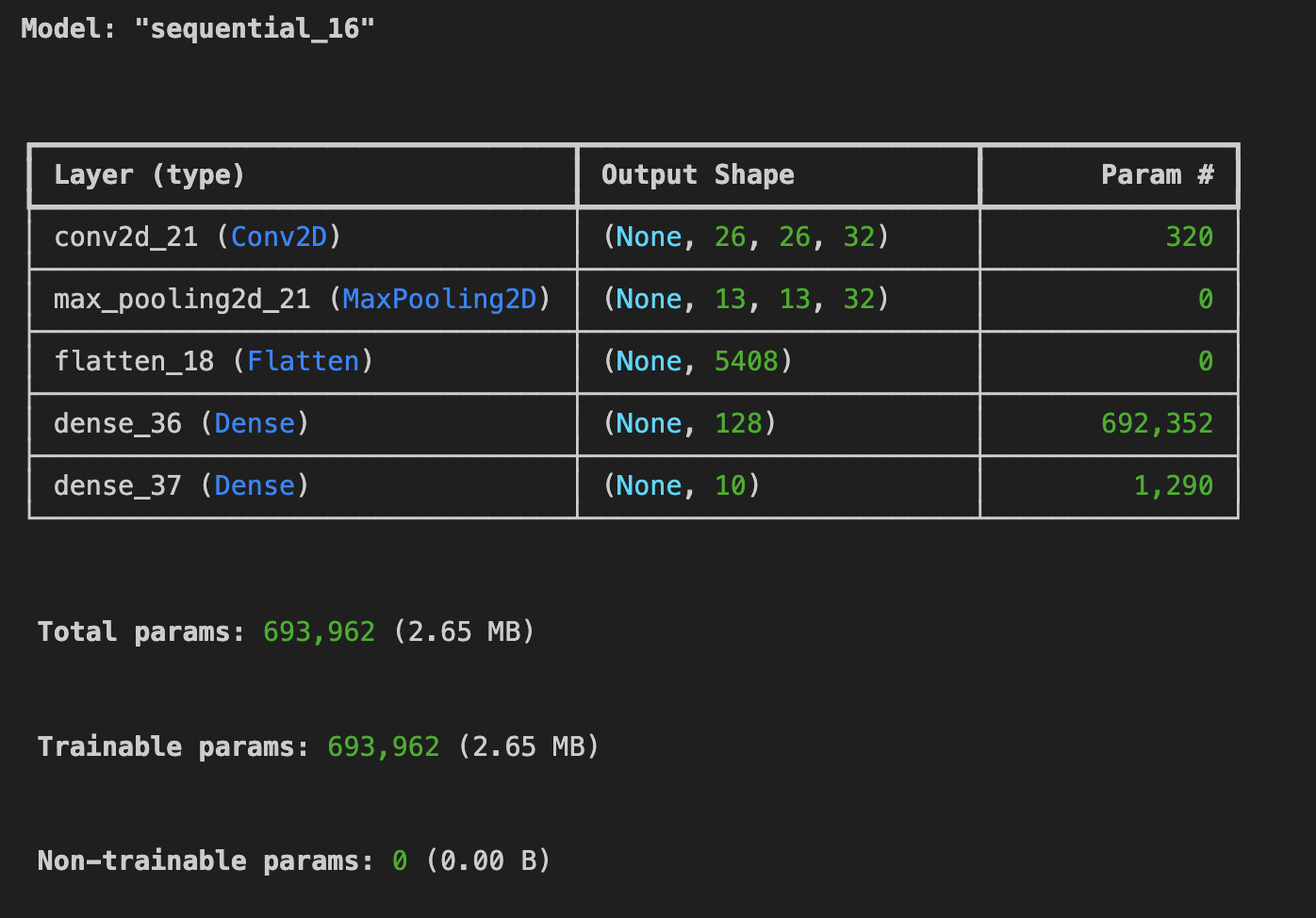
표현력의 감소: 두 번째 컨볼루션 레이어와 맥스 풀링 레이어가 제거되었기 때문에, 모델이 이미지의 공간적인 구조를 학습하는 능력이 감소할 것으로 예상된다. 두 번째 컨볼루션 레이어는 더 고수준의 특징을 추출하는 데 도움을 주는 경향이 있다.
파라미터 수 감소: 레이어가 제거되었기 때문에 모델의 총 파라미터 수가 감소했다. 이는 모델의 복잡성을 줄이고, 학습 데이터에 더 적합한 모델로 만들 수 있다.
그러나 이는 이미지 분류와 같은 복잡한 작업에는 모델의 성능을 향상시키는 데 도움이 되지 않을 수 있다.
학습 시간 감소: 레이어 수가 감소했기 때문에 모델을 학습하는 데 필요한 시간이 감소 한다. 더 적은 레이어는 학습 및 추론 과정에서 연산량을 줄여준다.
결론적으로, 첫 번째 컨볼루션을 제외한 모든 컨볼루션을 제거하면 모델의 표현력이 감소하고, 모델의 파라미터 수와 학습 시간이 감소한다. 이로 인해 모델의 성능은 데이터셋과 작업에 따라 달라질 수 있다.
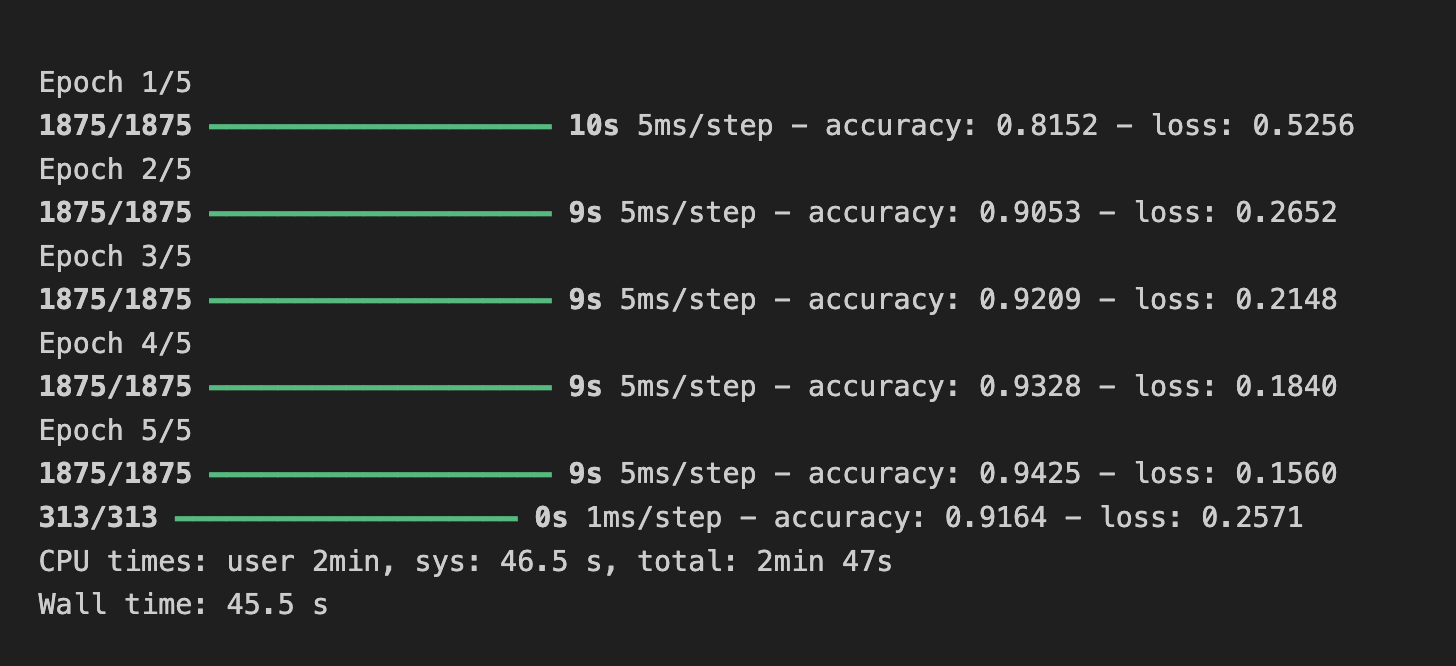
(5) 이전 강의에서는 손실 함수를 확인하고 특정 양에 도달하면 훈련을 취소하는 콜백을 구현했다. 여기서 이를 구현해보자.
class myCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self,epoch,logs={}):
if logs.get('loss') < 0.3:
self.mode.stop_training = True
callbacks = myCallback()%%time
import tensorflow as tf
fmnist = tf.keras.datasets.fashion_mnist
(x_train, y_train), (x_test, y_test) = fmnist.load_data()
x_train = x_train/255.0
x_test = x_test/255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.summary()
model.compile(loss='sparse_categorical_crossentropy',
metrics=['accuracy'],
optimizer='adam')
model.fit(x_train, y_train, epochs=5, callbacks=callbacks)
test_loss = model.evaluate(x_test, y_test)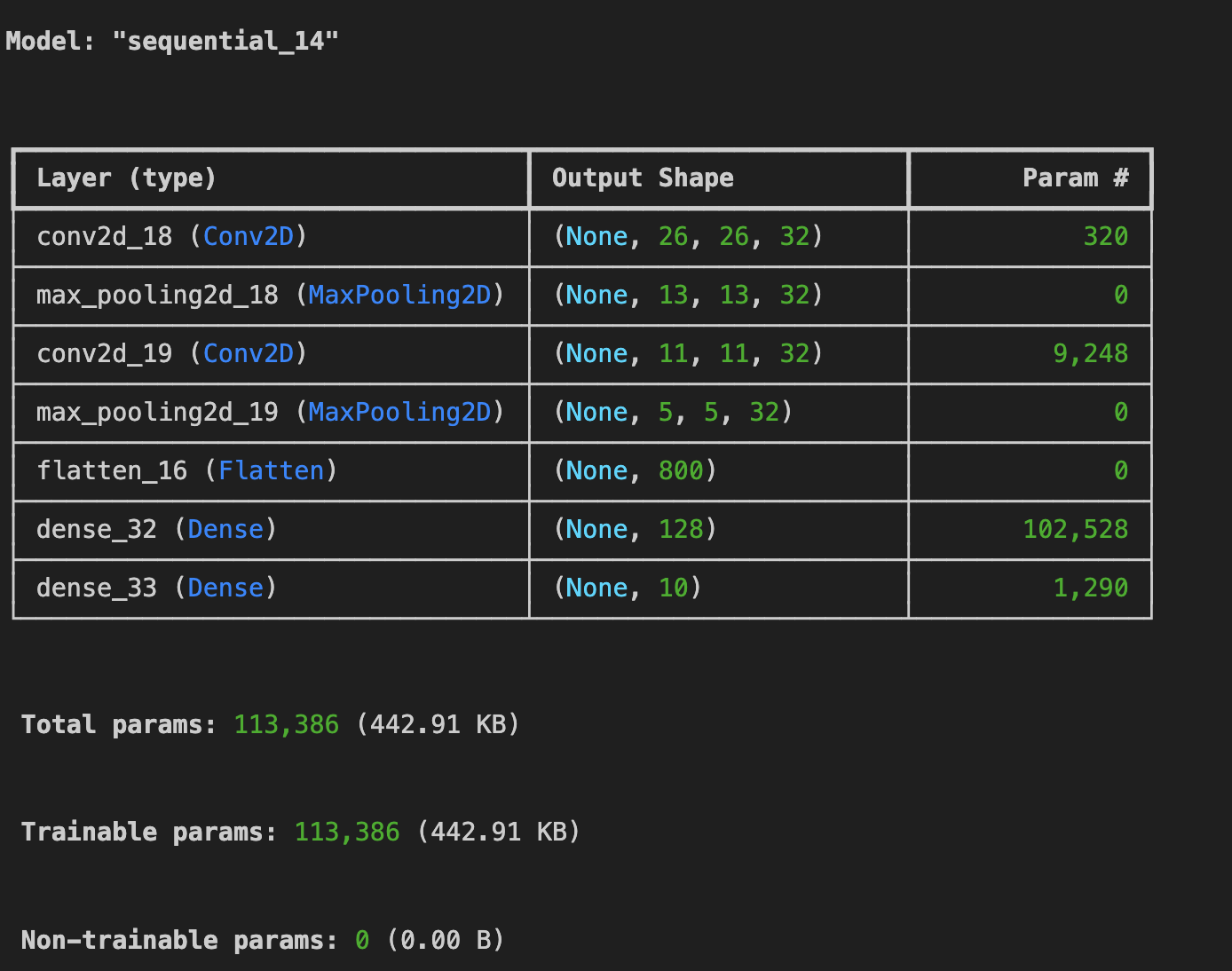
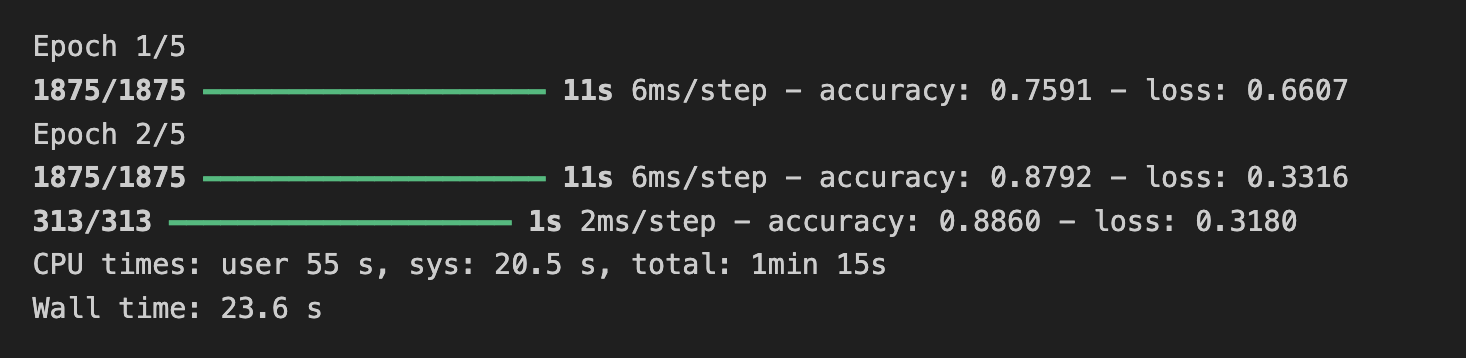
=> callback 함수에서 loss가 0.3 미만이라면 학습을 멈추게 했는데 epoch 2가 끝나고 3회에서 학습이 종료 되었다.
