
함수
fill()과 memset()
fill()과 memset()은 배열을 초기화 할 때 쓰인다.
fill()은 모든 값으로 초기화 할 수 있다. 0, 1, 100 등 모든 숫자로 초기화가 가능하다.memset()같은 경우 -1, 0 으로만 초기화가 가능하다.
c.f
memset()을 쓰다보면 0, -1 이외의 값으로 초기화하다 틀리는 경우가 있어 fill() 을 추천하지만 memset도 배워두는게 좋다.
작은 차이지만 0, -1로 초기화하는 경우 fill보다 memset이 더 빠르기때문에 이 때문에 시간적으로 더 최적화를 시킬 수도 있다.
fill()
fill()은 O(n)의 시간복잡도를 가지며 fill(시작값 - first, 끝값 -last, 초기화하는값 - val)로 배열에 들어가는 값을 초기화한다. 모든 값을 기반으로 초기화가 가능하며 [first,last)까지 val로 초기화 한다.
fill()로 배열의 모든 값이 아닌 일부값을 초기화하는 경우도 있지만 보통은 전체를 초기화하는게 좋다.
void fill (ForwardIterator first, ForwardIterator last, const T& val);#include <bits/stdc++.h>
using namespace std;
int a[10];
int b[10][10];
int main() {
fill(&a[0], &a[10], 100);
for (int i = 0; i < 10; i++) {
cout << a[i] << " ";
}
cout << '\n';
fill(&b[0][0], &b[9][10], 2);
for (int i = 0; i < 10; i++) {
for (int j = 0; j < 10; j++) {
cout << b[i][j] << " ";
}
cout << '\n';
}
return 0;
}앞의 코드를 보면 a[0]부터 a[9]까지 초기화하고 싶기 때문에 a[0], a[10] 두 개 인자를 fill() 함수의 인자로 집어넣는다.
다음처럼 배열의 이름을 기반으로 초기화 할 수 있다.
#include <bits/stdc++.h>
using namespace std;
int a[10];
int b[10][10];
int main() {
fill(a, a+10, 100);
for (int i = 0; i < 10; i++) {
cout << a[i] <, " ";
}
cout << '\n';
fill(&b[0][0], &b[0][0]+10*10, 2); //2차원 배열 초기화 방식 참고
for (int i = 0; i < 10; i++) {
for (int j = 0; j < 10; j++) {
cout << b[i][j] << " ";
}
cout << '\n';
}
return 0;
}왜 fill()로 (일부가 아닌) 전체초기화를 해야?
8 * 8 정사각형으로 초기화를 시키고 싶어서 다음처럼 초기화를 시키면 생각과는 다르게 초기화 된다.
#include <bits/stdc++.h>
using namespace std;
int a[10][10];
int main() {
cin.tie(NULL);
cout.tie(NULL);
fill(&a[0][0], &a[0][0] + 8*8, 4);
for (int i = 0; i < 10; i++) {
for (int j = 0; j < 10; j++) {
cout << a[i][j] << " ";
}
cout << '\n';
}
return 0;
}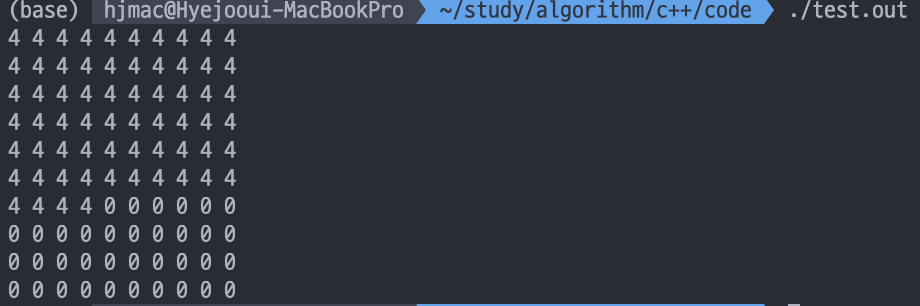
초기화 시킬 때 순차적으로 1행에 있는 요소를 초기화 하고 그 다음 행을 초기화하기 때문에 그렇다.
➡️ 따라서 전체 초기화 하는 게 깔끔하다.
memset()
memset()은 바이트단위로 초기화 하며 0, -1, char형의 하나의 문자(a, b, c, 등..)으로 초기화를 할 때만 사용한다.
void * memset ( void * ptr, int value, size_t num );
//memset(배열의 이름, k, 배열의 크기)#include <bits/stdc++.h>
using namespace std;
const int max_n = 1004;
int a[max_n];
int b[max_n][max_n];
int main() {
memset(a, -1, sizeof(a));
memset(b, 0, sizeof(b));
for(int i = 0; i < 10; i++)
cout << a[i] << " ";
return 0;
}위 코드처럼 fill() 보다는 간편하게 초기화할 수 있다. (특히 2차원배열)
0, -1 이외의 숫자는 절대 이 memset()으로 초기화 못하니 주의하기!!
쓰지 말아야 할 초기화 방법 {0, }
int a[5] = {0, };T myarray[N] = {0, };이렇게 초기화하는 것은 초반에 한 번 하는 정적초기화로써만 유효하다. 동적초기화로써는 동작하지 않는다.
#include <bits/stdc++.h>
using namespace std;
int main() {
int cnt = 0;
int a[5] = {0, };
while(++cnt != 10){
for(int i = 0; i < 5; i++) a[i] = i;
a[5] = {0, };
for(int i : a) cout << i << ' ';
cnt++;
}
return 0;
}위 코드 실행하면 0으로 초기화 되지 않는 것을 볼 수 있다.
이런 실수 방지 위해 memset() 혹은 fill()을 쓰는 게 좋다.
memcpy()와 copy()
- 어떤 변수를 깊은 복사할 때
memcpy()와copy()를 쓴다. memcpy()는 Array끼리 복사할 때 쓰고copy()는 Array, vector에 모두 쓰인다.
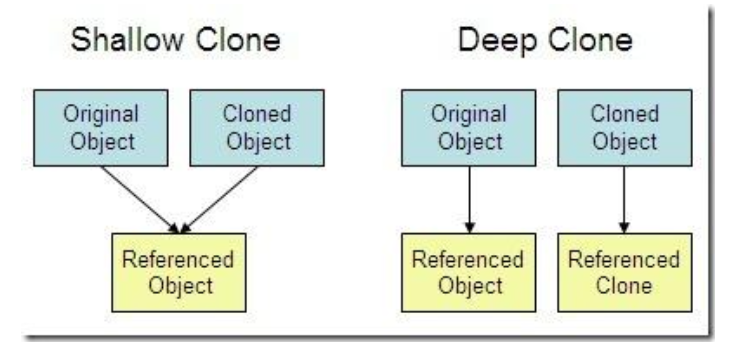
c.f 얕은 복사와 깊은 복사
- 얕은 복사(Shallow copy)는 메모리 주소값을 복사한 것이라 복사한 배열을 수정하면 원본 배열이 수정되는 복사방법
- 깊은 복사(Deep copy)는 새로운 메모리 공간을 확보해 완전히 복사해 복사한 배열을 수정하면 원본 배열은 수정되는 않는 복사방법
memcpy()
memcpy()는 어떤 변수의 메모리에 있는 값들을 다른 변수의 “특정 메모리값”으로 복사할 때 사용한다.- Array를 깊은 복사할 때 쓰인다.
void * memcpy ( void * destination, const void * source, size_t num );아래는 v라는 Array를 ret에다가 복사하는 것을 볼 수 있다.
깊은 복사가 되어 ret을 수정하더라도 vector v는 수정되지 않는 것을 볼 수 있다.
#include <bits/stdc++.h>
using namespace std;
int main() {
int v[3] = {1, 2, 3};
int ret[3];
memcpy(ret, v, sizeof(v));
cout << ret[1] << "\n";
ret[1] = 100;
cout << ret[1] << "\n";
cout << v[1] << "\n";
return 0;
}a라는 원본배열이 수정되는 로직이 있다. 그 다음에 이 원본배열이 수정되지 않은 상태값을 기반으로 또 어떠한 로직이 필요할 때가 있다. 그럴 때 memcpy()를 주로 쓴다.
#include <bits/stdc++.h>
using namespace std;
int a[5], temp[5];
int main() {
for (int i = 0; i < 5; i++) a[i] = i;
memcpy(temp, a, sizeof(a));
for (int i : temp) cout << i << ' ';
cout << '\n';
// 원본 배열을 수정해서 출력
// a 수정 작업
a[4] = 1000;
for (int i : a) cout << i << ' ' ;
cout << '\n';
// 다시 원본 배열이 복사된 temp를 가져와 a를 원본으로 만들기
memcpy(a, temp, sizeof(temp));
for (int i : a) cout << i << ' ';
cout << '\n';
return 0;
}주의할 점 !!! memcpy()는 vector에서는 깊은 복사가 되지 않는다.
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> v {1, 2, 3};
vector<int> ret(3);
memcpy( &ret, &v, 3*sizeof(int) );
cout << ret[1] << "\n";
ret[1] = 100;
cout << ret[1] << "\n";
cout << v[1] << "\n";
return 0;
}ret[1]을 수정했더니 v[1]도 수정되는 것을 볼 수 있다.
memcpy()는 TriviallyCopyable인 타입이 아닌 경우 함수자체가 제대로 동작하지 않는다.
c.f memcpy()의 TriviallyCopyable
Copies count bytes from the object pointed to by src to the object pointed to by dest.
If the objects overlap, the behavior is undefined. If the objects are not trivially copyable (e.g. scalars, arrays, C-compatible structs), the behavior is undefined.
is_trivial를 통해 해당 타입이`TriviallyCopyable한지 확인할 수 있는데 vector는 그렇지 않다.
#include <bits/stdc++.h>
using namespace std;
int main() {
if (is_trivial<vector<int>>())
cout << "Hello !\n";
return 0;
}
// 결과값이 출력되지 않음➡️ memcpy()는 Array에서만 동작한다!!
copy()
memcpy()와 똑같은 동작을 하는 함수이다.- vector와 Array 모두 쓸 수 있다.
vector v를 ret에다 옮기고 싶다면
v: 복사 당하는 , ret : 복사하는
copy(v.begin(), v.end(), ret.begin());#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> v {1, 2, 3};
vector<int> ret(3);
copy(v.begin(), v.end(), ret.begin());
cout << ret[1] << "\n";
ret[1] = 100;
cout << ret[1] << "\n";
cout << v[1] << "\n";
return 0;
}복사하는 vector와 복사당하는 vector의 크기를 맞춰주는 것이 중요하다. v의 크기는 3이며, ret의 크기도 3으로 설정돼있다. 그리고 깊은 복사가 되어 ret을 수정하더라도 v에는 아무런 영향을 미치지 않는 것을 볼 수 있다.
Array에서도 사용 가능하다.
#include <bits/stdc++.h>
using namespace std;
int n = 3;
int main() {
int v[n] = {1, 2, 3};
int ret[n];
copy(v, v + n, ret);
cout << ret[1] << endl;
ret[1] = 100;
cout << ret[1] << endl;
cout << v[1] << endl;
return 0;
}만약 Array v의 크기가 5라면 copy(v, v + 5, ret) 이런식의 코드가 된다.
sort()
sort()는 배열 등 컨테이너들의 요소를 정렬하는 함수이다. 보통 array나 vector를 정렬할 때 쓰이며 O(nlogn)의 시간복잡도를 가진다.sort()에 들어가는 매개변수로는 3가지가 있으며 2개는 필수로 넣어야 하고, 한개는 선택이며 커스텀 정렬하고 싶을 때 넣는다.
sort(first, last, *커스텀비교함수)- first는 정렬하고 싶은 배열의 첫번째 이터레이터
- last는 정렬하고 싶은 배열의 마지막 이터레이터를 넣으면 된다.
[first,last)라는 범위를 갖는다 sort()의 세번째 매개변수, 커스텀비교함수를 넣지 않으면 기본적으로 오름차순이고, 커스텀비교함수에greater<타입>()를 넣어 내림차순으로 변경할 수 있다.less<타입>()으로 오름차순으로 정렬할 수도 있다.
#include <bits/stdc++.h>
using namespace std;
vector<int> a;
int b[5];
int main() {
for (int i = 5; i >= 1; i--) b[i-1] = i;
for (int i = 5; i >= 1; i--) a.push_back(i);
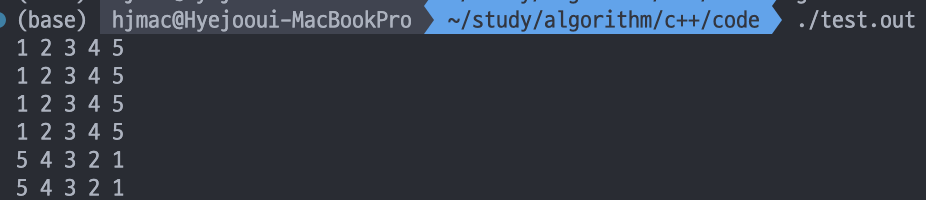
//오름차순
sort(b, b + 5);
sort(a.begin(), a.end());
for (int i : b) cout << i << ' ';
cout << '\n';
for (int i : a) cout << i << ' ';
cout << '\n';
sort(b, b + 5, less<int>());
sort(a.begin(), a.end(), less<int>());
for(int i : b) cout << i << ' ';
cout << '\n';
for (int i : a) cout << i << ' ';
cout << '\n';
//내림차순
sort(b, b+5, greater<int>());
sort(a.begin(), a.end(), greater<int>());
for (int i : b) cout << i << ' ';
cout << '\n';
for (int i : a) cout << i << ' ';
cout << '\n';
return 0;
}
pair을 기반으로 만들어진 vector의 경우 따로 설정하지 않으면 first, second 순으로 차례차례 오름차순으로 정렬된다.
#include <bits/stdc++.h>
using namespace std;
vector<pair<int, int>> v;
int main() {
for (int i = 10; i >= 1; i--) {
v.push_back({i, 10 - i});
}
sort(v.begin(), v.end());
for(auto it : v)
cout << it.first << " : " << it.second << "\n";
return 0;
}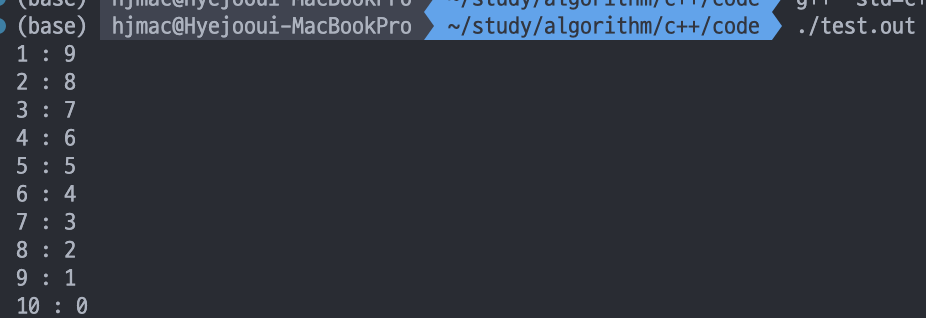
위 코드처럼 오름차순 정렬될 것을 볼 수 있다.
여기서 for(auto it : v) cout << it.first << " : " << it.second << "\n"; 이 부분은 for(pair<int,int> it : v로 할 수도 있다. vector v에 있는 “요소”들을 끄집어내서 순회한다는 의미이다. v[0], v[1] 따위로 접근한다는 뜻.
cmp 함수
first는 내림차순, second는 오름차순으로 정렬하고 싶다면? 커스텀 비교함수 cmp를 만들어 매개변수로 넣으면 된다.(보통 cmp라는 함수명을 많이 쓴다.)
#include <bits/stdc++.h>
using namespace std;
vector<pair<int, int>> v;
bool cmp(pair<int, int> a, pair<int, int> b) {
return a.first > b.first;
}
int main() {
for (int i = 10; i >= 1; i--) {
v.push_back({i, 10-i});
}
sort(v.begin(), v.end(), cmp);
for (auto it : v)
cout << it.first << " : " << it.second << "\n";
return 0;
}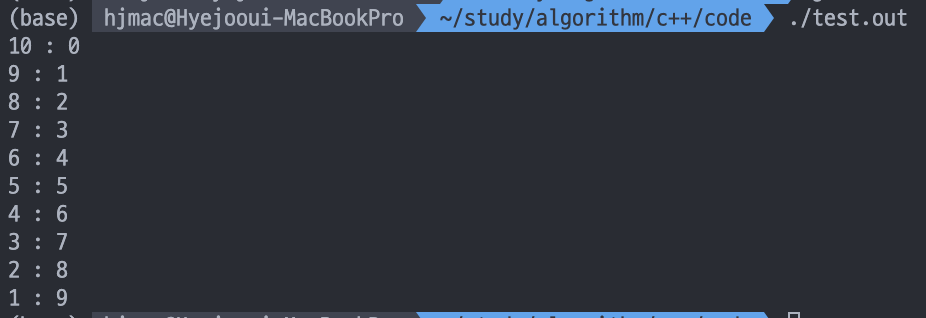
원래는 sort()를 하면 first가 오름차순으로 정렬되지만 first를 기준으로 내림차순으로 정렬된 것을 볼 수 있다.
unique()
<강의참고✔️> 중복 제거하는 방법 2가지 - map, unique()
map
#include <bits/stdc++.h>
using namespace std;
map<int, int> mp;
int main() {
vector<int> v{1, 1, 2, 2, 3, 3};
for (int i : v) {
if (mp[i]) {
continue; // mp[i]가 있다면
} else {
mp[i] = 1;
}
}
vector<int> ret;
for (auto it : mp) {
ret.push_back(it.first);
}
for (int i : ret) cout << i << '\n';
return 0;
}
cnt 배열을 만들어서 map과 비슷한 역할을 하도록 구현할 수도 있다.
unique()
unique()는 범위안의 있는 요소 중 앞에서부터 서로를 비교해가며 중복되는 요소를 제거하고 나머지 요소들은 삭제하지 않고 그대로 두는 함수이다. O(n)의 시간복잡도를 가진다.
#include <bits/stdc++.h>
using namespace std;
vector<int> v;
int main () {
for(int i = 1; i <= 5; i++){
v.push_back(i);
v.push_back(i); // 1 1 2 2 3 3 4 4 5 5
// 1 2 3 4 5 3 4 4 5 5 여기서 중복되지 않은 배열은 0~4 번째. unique()함수는 5번째 이터레이터를 반환한다.
}
for(int i : v) cout << i << " ";
cout << '\n';
// 중복되지 않은 요소로 채운 후, 그 다음 이터레이터를 반환한다.
auto it = unique(v.begin(), v.end());
cout << it - v.begin() << '\n'; // 5번째 이터레이터를 반환한다.
//앞에서 부터 중복되지 않게 채운 후 나머지 요소들은 그대로 둔다.
for(int i : v) cout << i << " ";
cout << '\n';
return 0;
}#include <bits/stdc++.h>
using namespace std;
vector<int> v {1, 1, 2, 2, 3, 3, 5, 6, 7, 8, 9};
// 1 2 3 5 6 7 8 9 7 8 9
int main () {
auto it = unique(v.begin(), v.end());
for(int i : v) cout << i << " ";
cout << '\n';
return 0;
}#include <bits/stdc++.h>
using namespace std;
vector<int> v {2, 2, 1, 1, 2, 2, 3, 3, 5, 6, 7, 8, 9};
// 2 1 2 3 5 6 7 8 9 6 7 8 9
int main () {
auto it = unique(v.begin(), v.end());
for(int i : v) cout << i << " ";
cout << '\n';
return 0;
}앞에서부터 차근차근 중복되는 것을 찾아서 비교하기 때문에 unique()를 쓸 경우 꼭 sort()와 같이 써야한다.
sort()를 써야 “우리가 예상하는 로직”인 중복된 수를 제거한 배열이 나오게 된다.
다음 코드와 같이 unique()는 sort(), erase(unique()) 와 함께 쓰는 것이 좋다.
#include <bits/stdc++.h>
using namespace std;
vector<int> v {2, 2, 1, 1, 2, 2, 3, 3, 5, 6, 7, 8, 9};
// 1 2 3 4 5 6 7 8 9
int main () {
sort(v.begin(), v.end());
auto it = v.erase(unique(v.begin(), v.end()), v.end()); // unique가 정렬 된 다음 요소의 이터레이터 반환하기 때문에 거기부터 끝까지를 지워야 함.
for(int i : v) cout << i << " ";
cout << '\n';
return 0;
}lower_bound()와 upeer_bound()
정렬된 배열에서 어떤 값이 나오는 첫번째 지점 또는 초과하는 지점의 위치를 찾으려면?
이분탐색을 쉽게 함수로 구현하려면?
➡️lower_bound()와 upper_bound() 사용!
이 함수들은 꼭 정렬된 배열에서만 써야 한다. 정렬되지 않은 배열을 기반으로 하게 되면 예상하지 못한 결과가 나오게 된다.
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
int main(){
vector<int> a {1, 2, 3, 3, 3, 4};
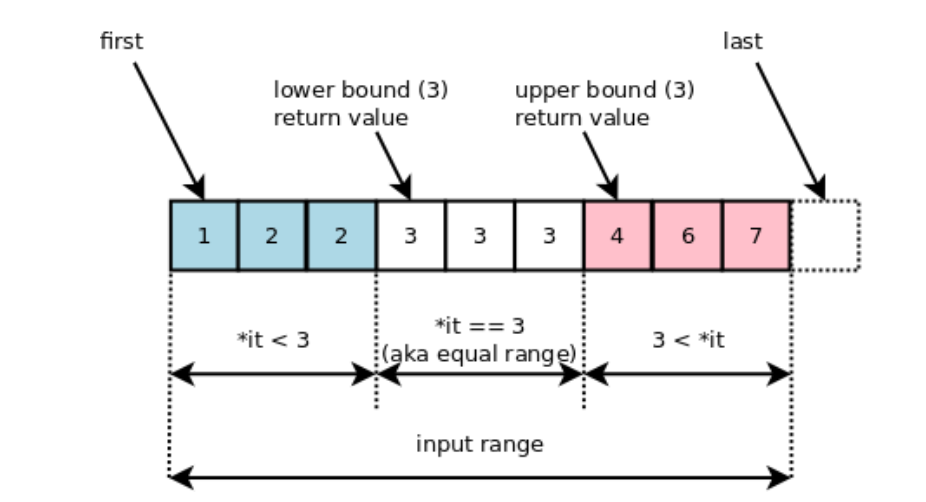
cout << lower_bound(a.begin(), a.end(), 3) - a.begin() << "\n"; // 2
cout << upper_bound(a.begin(), a.end(), 3) - a.begin() << "\n"; // 5
return 0;
}숫자 3을 찾는다고 했을 때 lower_bound()는 2, upper_bound()는 5를 반환하고 있다.
3이 시작되는 최소 시작점은 lower_bound(), 이를 초과하는 지점은 upper_bound()로 찾을 수가 있다.
a.begin()을 빼는 이유
lower_bound(), upper_bound()는 해당 자료형으로부터 이터레이터를 반환한다. 따라서 몇번째를 추려내려면 이 이터레이터에서 begin()을 빼주어야 한다.
lower_bound()로 나오는 이터레이터가 어떤 값을 갖는지 &*를 통해 확인해보자.
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
int main(){
vector<int> a {1, 2, 3, 3, 3, 4};
cout << &*lower_bound(a.begin(), a.end(), 3)<< "\n";
cout << &*a.begin()<< "\n";
cout << &*(a.begin() + 1)<< "\n";
return 0;
}
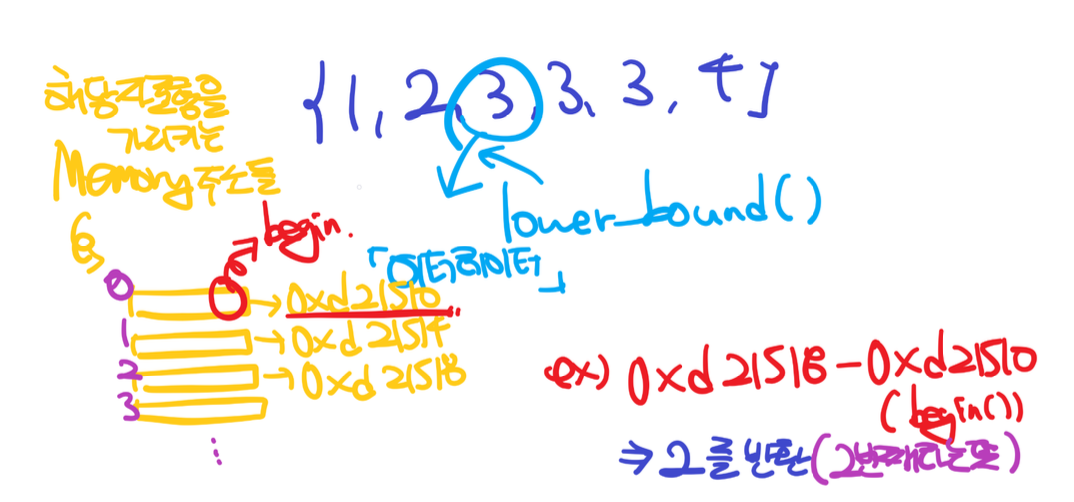
주소값끼리 '-' 하게 되면 해당 주소값에서 몇 번째에 이 요소가 들어있는지 반환하게 된다.
다음 코드처럼도 할 수 있다.(보통 사용되지는 않음)
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
int main(){
vector<int> a {1, 2, 3, 3, 3, 4};
cout << &*lower_bound(a.begin(), a.end(), 3) - &*a.begin()<< "\n";
vector<int> b {0, 0, 0, 0};
cout << &*(b.begin() + 3) - &*b.begin() << '\n';
return 0;
}
/*
2
3
*/다음 코드를 통해 lower_bound()가 가리키는 요소를 출력할 수도 있다.
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
vector<int> a {1, 2, 3, 3, 4, 100};
int main(){
cout << *lower_bound(a.begin(), a.end(), 100)<< "\n";
return 0;
}
/* 100 */응용해서 숫자 3이 몇 개 들어가있는지도 확인할 수 있다.(upper_bound()-lower_bound())
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
vector<int> a {1, 2, 3, 3, 3, 3, 4, 100};
int main(){
cout << upper_bound(a.begin(), a.end(), 3) - lower_bound(a.begin(), a.end(),3)<< "\n";
return 0;
}
/* 4 */만약 해당 요소가 없을 경우 다음코드처럼 그 근방 지점을 반환한다.
#include <bits/stdc++.h>
using namespace std;
vector<int> v;
int main(){
for(int i = 2; i <= 5; i++)v.push_back(i);
v.push_back(7);
// 2 3 4 5 7
cout << upper_bound(v.begin(), v.end(), 6) - v.begin() << "\n";
// 2 3 4 5 7
// 0 1 2 3 4에서 근방지점인4번째(7보다6이 더 작으므로)
cout << lower_bound(v.begin(), v.end(), 6) - v.begin() << "\n";
// 2 3 4 5 7
// 0 1 2 3 4에서 근방지점인4번째(7보다6이 더 작으므로)
cout << upper_bound(v.begin(), v.end(), 9) - v.begin() << "\n";
// 2 3 4 5 7
// 0 1 2 3 4에서 근방지점인5번째(7보다9가 더 크므로)
cout << lower_bound(v.begin(), v.end(), 9) - v.begin() << "\n";
// 2 3 4 5 7
// 0 1 2 3 4에서 근방지점인5번째(7보다9가 더 크므로)
cout << upper_bound(v.begin(), v.end(), 0) - v.begin() << "\n";
// 2 3 4 5 7
// 0 1 2 3 4에서 근방지점인0번째(0보다2가 더 크므로)
cout << lower_bound(v.begin(), v.end(), 0) - v.begin() << "\n";
// 2 3 4 5 7
// 0 1 2 3 4에서 근방지점인0번째(0보다2가 더 크므로)
return 0;
}
/*
4
4
5
5
0
0 */accumulate()
배열의 합을 쉽고 빠르게 구해주는 함수로는 accumulate()가 있다.
#include <bits/stdc++.h>
using namespace std;
int main(){
vector<int> v = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int sum = accumulate(v.begin(), v.end(), 0);
cout << sum << '\n'; // 55
return 0;
}max_element()
배열 중 가장 큰 요소를 추출하는 함수이다.
이 함수는 이터레이터를 반환하기 때문에 *를 통해 값을 끄집어낼 수 있고, 이를 기반으로 해당 최댓값의 인덱스 또한 뽑아낼 수 있다.
#include <bits/stdc++.h>
using namespace std;
int main(){
vector<int> v = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int a = *max_element(v.begin(), v.end());
auto b = max_element(v.begin(), v.end());
cout << a << '\n'; // 10
cout << (int)(b - v.begin()) << '\n'; // 9
return 0;
}max_element()의 implement
template <class ForwardIterator>
ForwardIterator max_element ( ForwardIterator first, ForwardIterator last )
{
if (first==last) return last;
ForwardIterator largest = first;
while (++first!=last)
if (*largest<*first)
largest=first;
return largest;
}min_element()
배열 중 가장 작은 요소를 추출하는 함수이다.
이터레이터를 반환하기 때문에 *를 통해 값을 끄집어낼 수 있고 이를 기반으로 해당 최솟값의 인덱스 또한 뽑아낼 수 있다.
#include <bits/stdc++.h>
using namespace std;
int main(){
vector<int> v = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int a = *min_element(v.begin(), v.end());
auto b = min_element(v.begin(), v.end());
cout << a << '\n'; // 1
cout << (int)(b - v.begin()) << '\n'; // 0
return 0;
}📝 큰돌의터전 <10주 완성 C++ 코딩테스트>
