
자료구조
자료구조란 데이터들과의 관계, 함수, 명령 등의 집합을 의미하며 데이터에 대해 효율적으로 접근, 수정 등 데이터의 처리를 효율적으로 할 수 있게 만든 구조를 의미한다.

- 선형 자료구조 : Array, Stack, Queue, Linked_list
- 비선형 자료구조 : Graph, Tree
vector
- vector는 동적으로 요소를 할당할 수 있는 동적 배열이다.
- 만약 컴파일 시점에 사용해야 할 요소들의 개수를 모른다면 vector를 써야 한다.
- 연속된 메모리 공간에 위치한 같은 타입의 요소들의 모음이며 숫자인덱스를 기반으로 랜덤접근이 가능하며 중복을 허용합니다.
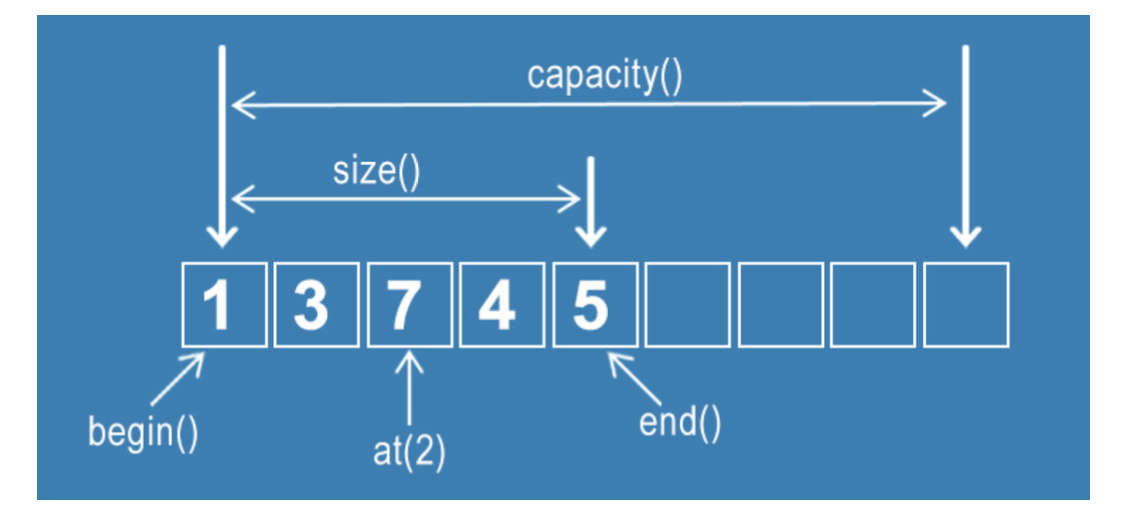
탐색과 맨 뒤의 요소를 삭제하거나 삽입하는 데 O(1)이 걸리며,맨 뒤나 맨 앞이 아닌 요소를 삭제하고 삽입하는 데 O(n)의 시간이 걸린다.
vector<타입> 변수명;int형 vector를 정의하고 싶다면 vector<int> 로 정의해야 한다.
#include <bits/stdc++.h>
using namespace std;
vector<int> v;
int main(){
for(int i = 1; i <= 10; i++)v.push_back(i);
for(int a : v) cout << a << " ";
cout << "\n";
v.pop_back();
for(int a : v) cout << a << " ";
cout << "\n";
v.erase(v.begin(), v.begin() + 3);
for(int a : v) cout << a << " ";
cout << "\n";
auto a = find(v.begin(), v.end(), 100);
if(a == v.end()) cout << "not found" << "\n";
fill(v.begin(), v.end(), 10);
for (int a : v) cout << a << " ";
cout << "\n";
v.clear();
cout << "아무것도 없을까?\n";
for (int a : v) cout << a << " ";
cout << "\n";
return 0;
}
push_back()
vector의 뒤에서부터 요소를 더한다.
c.f 참고로 push_back()과 같은 기능을 하는 emplace_back()도 있다.(이게 더 빠르지만 시간 차이 별로 안 남)
pop_back()
vector의 맨 뒤의 요소를 지운다.
erase()
iterator erase (const_iterator position);
iterator erase (const_iterator first, const_iterator last);한 요소만을 지우면 erase(위치)로 쓰고, [from, to)로 지우고 싶다면 erase[from, to)를 쓴다.
find(from, to, value)
vector의 메서드가 아닌 STL 함수이다.
vector 내의 요소들을 찾고 싶을 때, [from, to) 에서 value를 찾는다.
O(n)의 시간복잡도를 가진다.
clear()
vector의 모든 요소를 지운다.
fill(from, to, value)
vector 내의 value로 값을 할당하고 싶다면 fill을 써서 채운다.
보통 이를 '~~한 값으로 초기화'라고 부른다. [from, to) 구간에 value를 초기화 합니다.
범위기반 for 루프
C++11부터 범위기반 for 루프가 추가되어서 이를 쓸 수 있다. (vector만 쓸 수 있는 것은 아니고 순회할 수 있는 컨테이너인 vector, Array, map 등도 사용가능)
for ( range_declaration : range_expression )
loop_statementfor(<해당 컨테이너에 들어있는 타입> 임시변수명 : 컨테이너)#include <bits/stdc++.h>
using namespace std;
vector<int> v{1, 2, 3};
int main(){
for (int a : v) cout << a << " ";
cout << "\n";
for (int i = 0; i < v.size(); i++) cout << v[i] << ' ';
cout << "\n";
vector<pair<int, int>> v2 = {{1, 2,}, {3, 4}};
for(pair<int, int> a : v2) cout << a.first << " ";
return 0;
}만약 vector 안에 pair가 들어간다면 pair을 써서 범위기반 for루프를 써야 한다.
아래 두 코드는 vector<int>내의 요소를 탐색한다는 같은 의미이다.
for(int a : v)for(int i = 0; i < v.size(); i++) v[i]vector의 정적할당
vector라고 해서 무조건 크기가 0인 빈 vector를 만들어 동적할당으로 요소를 추가하는 것은 아니다.
미리 크기를 정해놓거나 해당 크기에 대해 어떠한 값으로 초기화 해놓고 시작할 수도 있다.
다음은 5개의 요소를 담을 수 있는 vector를 선언하고 모든 값을 100으로 채운 코드이다.
#include <bits/stdc++.h>
using namespace std;
vector<int> v(5, 100);
int main(){
for (int a : v) cout << a << " ";
cout << "\n";
return 0;
}아래처럼도 가능하다.
#include <bits/stdc++.h>
using namespace std;
vector<int> v{10, 20, 30, 40, 50};
int main(){
ios_base::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
for (int i : v) {
cout << i << " ";
}
return 0;
}2차원 배열
vector를 이용한 2차원 배열을 만드는 3가지 방법이 있다.
#include <bits/stdc++.h>
using namespace std;
vector<vector<int>> v; //1
vector<vector<int>> v2(10, vector<int>(10, 0)); //2
vector<int> v3[10]; //3
int main(){
for (int i = 0; i < 10; i++) {
vector<int> temp;
v.push_back(temp);
}
return 0;
}-
v는 vector안에 vector가 들어가 있는 2차원 배열 타입을 선언한다.
그 이후v에temp라는 vector를 push_back해서 2차원 배열을 만든다. -
v2는 10 * 10 짜리 크기의 2차원배열을 바로 만든다. 0으로 초기화까지 한다. -
v3는 10개 짜리 배열을 선언한다. 이것도 v와 똑같은 2차원배열이다.

Array
- 정적배열이다. 선언 시 크기를 설정해서 연산을 진행한다.
- 연속된 메모리 공간에 위치한 같은 타입의 요소들의 모음이며, 숫자 인덱스를 기반으로 랜덤 접근이 가능하고 중복을 허용한다.

2차원 배열과 탐색을 빠르게 하는 Tip
2차원 배열은 단순히 차원을 늘려서 만들면 된다.
#include <bits/stdc++.h>
using namespace std;
const int mxy = 3;
const int mxx = 4;
int a[mxy][mxx];
int main(){
for (int i = 0; i < mxy; i++) {
for (int j = 0; j < mxx; j++) {
a[i][j] = ( i + j );
}
}
//good
for (int i = 0; i < mxy; i++) {
for (int j = 0; j < mxx; j++) {
cout << a[i][j] << ' ';
}
cout << '\n';
}
//bad
for (int i = 0; i < mxx; i++) {
for (int j = 0; j < mxy; j++) {
cout << a[j][i] << ' ';
}
cout << '\n';
}
return 0;
}
위 good, bad 코드를 참고해라.
첫번째 차원 >> 2번째 차원 순으로 탐색하는게 성능이 좋다.
c.f
이는 C++에서 캐시를 첫번째 차원(여기서는 mxy)을 기준으로 하기 때문에 캐시관련 효율성 때문에 탐색을 하더라도 순서를 지켜가며 해주는게 좋다.
list
- 연결리스트(linked list)이다.
- 요소가 인접한 메모리 위치에 저장되지 않는(연속되지 않은 메모리 공간에 저장되는) 선형 자료 구조이다.
- 랜덤접근은 불가능하며 오로지 순차적 접근만 가능하다.
- 요소들은
next,prev라는 포인터로 연결되어 이루어지며 중복을 허용한다.

-
데이터를 감싼 노드를 포인터로 연결해서 공간적인 효율성을 극대화시킨 자료구조이다.
-
삽입과 삭제가 O(1)이 걸리며 k번째 요소를 참조한다 했을 때는 O(k)가 걸린다.
-
노드의 구성 : 싱글연결리스트 기준
data+next(포인터, 노드와 노드를 잇게 만드는)
class Node{
public:
int data;
Node* next;
Node() {
data = 0;
next = NULL;
}
Node(int data) {
this->data = data;
this->next = NULL;
}
}연결리스트에는 싱글연결리스트, 이중연결리스트, 원형연결리스트 3가지가 있다.
싱글연결리스트
싱글연결리스트(Singly Linked List)는 next 포인터밖에 존재하지 않으며 한 방향으로만 데이터가 연결된다.
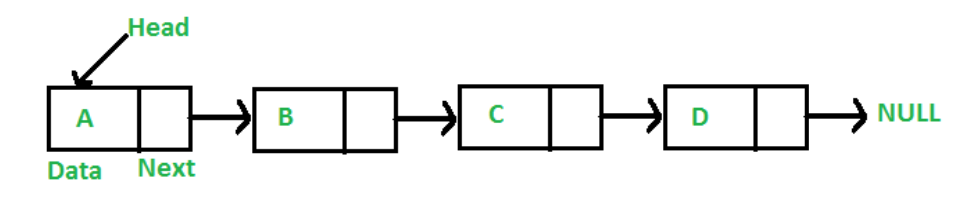
이중연결리스트
이중연결리스트(Doubly Linked List)는 prev, next 두개의 포인터로 양방향으로 데이터가 연결된다.

원형연결리스트
원형연결리스트(Circular Linked List)는 마지막 노드와 첫번째 노드가 연결되어 원을 형성한다.
싱글연결리스트, 이중영ㄴ결리스트로 이뤄진 2가지 타입이 있다.
원형싱글연결리스트

원형이중연결리스트

C++에서는 list로 이중연결리스트를 쉽게 구현할 수 있다.
#include <bits/stdc++.h>
using namespace std;
list<int> a;
void print(list <int> a) {
for (auto it : a) cout << it << " ";
cout << '\n';
}
int main(){
for (int i = 1; i <= 3; i++) a.push_back(i);
for (int i = 1; i <= 3; i++) a.push_front(i);
auto it = a.begin();
it++;
a.insert(it, 1000);
print(a);
it = a.begin();
it++;
a.erase(it);
print(a);
a.pop_front();
a.pop_back();
print(a);
cout << a.front() << " : " << a.back() << '\n';
a.clear();
return 0;
}push_front(value)
리스트의 앞에서부터 value를 넣는다.
push_back(value)
리스트의 뒤에서부터 value를 넣는다.
insert(idx, value)
iterator insert (const_iterator position, const value_type& val);요소를 몇번째에 삽입한다.
erase(idx)
iterator erase (const_iterator position);리스트의 idx번째 요소를 지운다.
pop_front()
첫번째 요소를 지운다.
pop_back()
맨 끝 요소를 지운다.
front()
맨 앞 요소를 참조한다.
back()
맨 뒤 요소를 참조한다.
clear()
모든 요소를 지운다.
c.f 랜덤접근과 순차적 접근
직접 접근이라고 하는 랜덤 접근(random access)은 동일한 시간에 배열과 같은 순차적인 데이터가 있을 때 임의의 인덱스에 해당하는 데이터에 접근할 수 있는 기능이다. 이는 데이터를 저장된 순서대로 검색해야 하는 순차적 접근(sequential access)과는 반대이다.
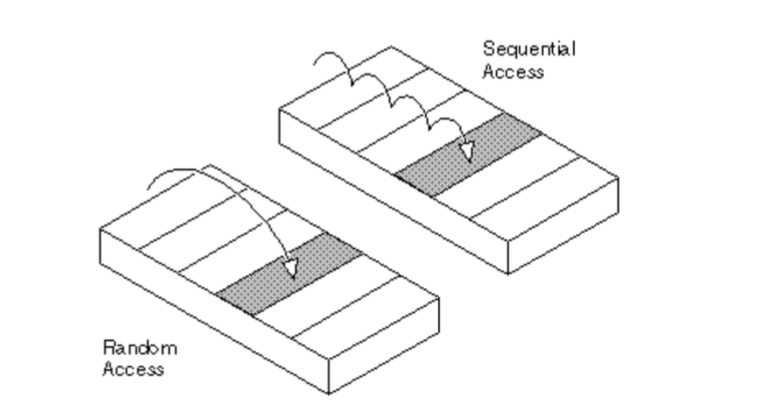
vector, Array와 같은 배열은 랜덤접근이 가능해서 k번째 요소에 접근할 때 O(1)이 걸린다.
연결리스트, 스택, 큐는 순차적 접근만이 가능해서 k번째 요소에 접근할 때 O(k)이 걸린다.
c.f 배열과 연결리스트 비교 (면접에서 자주 나옴)

- 배열은 연속된 메모리 공간에 데이터를 저장하고 연결리스트는 연속되지 않은 메모리 공간에 데이터를 저장한다.
- 배열은 삽입과 삭제에는 O(n)이 걸리고 참조에는 O(1)이 걸린다. 연결리스트는 삽입과 삭제에 O(1)이 걸리고 참조에는 O(n)이 걸린다.
- 따라서 데이터추가와 삭제를 많이 하는 것은 연결 리스트, 참조를 많이 하는 것은 배열로 하는 것이 좋다.
map
- map은 고유한 키를 기반으로 키 - 값(key - value) 쌍으로 이루어져 있는 정렬된(삽입할 때마다 자동 정렬된) 연관 컨테이너이다.
- 레드 - 블랙트리로 구현된다.
- 레드 - 블랙 트리로 구현되어있기 때문에 삽입, 삭제, 수정, 탐색이 O(logN)의 시간복잡도를 가진다.
c.f 레드 - 블랙트리
레드블랙트리는 균형 이진 검색 트리이며 삽입, 삭제, 수정, 탐색에 O(logN)의 시간복잡도가 보장된다.

- 고유한 키를 갖기 때문에 하나의 키에 중복된 값이 들어갈 수 없다.
- 자동으로 오름차순 정렬되기 때문에 넣은 순서대로 map을 탐색할 수 있는 것이 아닌 아스키코드순으로 정렬된 값들을 기반으로 탐색하게 된다.
- 또한 대괄호 연산자
[]로 해당 키로 직접 참조할 수 있다.
#include <bits/stdc++.h>
using namespace std;
map<string, int> mp;
string a[] = {"주홍철", "이승철", "박종선"};
int main(){
for (int i = 0; i < 3; i++) {
mp.insert({a[i], i+1});
mp[a[i]] = i + 1;
}
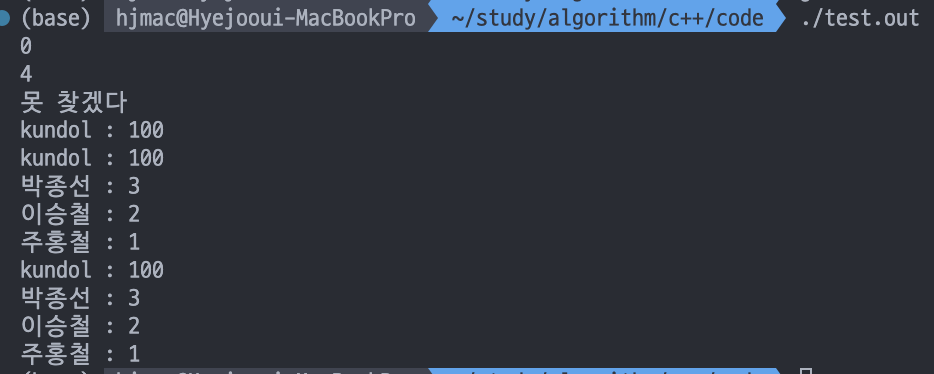
cout << mp["kundol"] << '\n';
mp["kundol"] = 4;
cout << mp.size() << '\n';
mp.erase("kundol");
auto it = mp.find("kundol");
if (it == mp.end()) {
cout << "못 찾겠다\n";
}
mp["kundol"] = 100;
it = mp.find("kundol");
if(it != mp.end()) {
cout << (*it).first << " : " << (*it).second<< '\n';
}
for (auto it :mp) {
cout << (it).first << " : " << (it).second << '\n';
}
for (auto it = mp.begin(); it != mp.end(); it++) {
cout << (*it).first << " : " << (*it).second << '\n';
}
mp.clear();
return 0;
}
insert({key, value})
map에다 {key, value}를 집어 넣는다.
[key] = value
대괄호[]를 통해 key에 해당하는 value를 할당한다.
[key]
대괄호[]를 통해 key를 기반으로 map에 있는 요소를 참조한다.
size()
map에 있는 요소들의 개수를 반환한다.
erase(key);
해당 키에 해당하는 요소를 지운다.
find(key)
map에서 해당 key를 가진 요소를 찾아 해당 이터레이터를 반환한다. 만약 못찾을 경우 mp.end(), 해당 map의 end() 이터레이터를 반환한다.
for(auto it : mp)
범위기반 for루프로 map에 있는 요소들을 순회한다. map을 순회할 때는 key는 first, value는 second로 참조가 가능하다.
for (auto it = mp.begin(); it != mp.end(); it++)
map에 있는 요소들을 이터레이터로 순회할 수 있다.
mp.claer();
map에 있는 요소들을 다 제거한다.
map 쓸 때 주의할 점
다음 코드처럼 map의 경우 해당 인덱스에 참조만 해도 맵의 요소가 생기게 된다.
만약 map에 해당 키에 해당하는 요소가 없다면 0 또는 빈문자열로 초기화가 되어 할당된다. (int는 0, string이나 char은 빈 문자열로 할당됩니다.)
할당하고 싶지 않아도 대괄호([])로 참조할 경우 자동으로 요소가 추가가 되기 때문에 조심해야 한다.
#include <bits/stdc++.h>
using namespace std;
map<int, int> mp;
map<string, string> mp2;
int main(){
ios_base::sync_with_stdio(false);
cin.tie(NULL); cout.tie(NULL);
cout << mp[1] << '\n';
cout << mp2["aaa"] << '\n';
for(auto i : mp) cout << i.first << " " << i.second;
cout << '\n';
for(auto i : mp2) cout << i.first << " " << i.second;
return 0;
}
/*
0
1 0
aaa %
*/맵에 요소가 있는지 없는지를 확인하고 맵에 요소를 할당하는 로직은 다음처럼 구축 가능하다.
#include <bits/stdc++.h>
using namespace std;
map<int, int> mp;
map<string, string> mp2;
int main(){
ios_base::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
if(mp[1] == 0){
mp[1] = 2;
}
for(auto i : mp) cout << i.first << " " << i.second;
return 0;
}
/*
1 2
*/다만 앞의 코드는 문제에서 해당 키에 0이 아닌 값이 들어갈 때 활용이 가능하다.
이미 if문 안에 mp[1] == 0을 해버린 순간 mp[1] = 0이 할당되어버리기 때문이다.
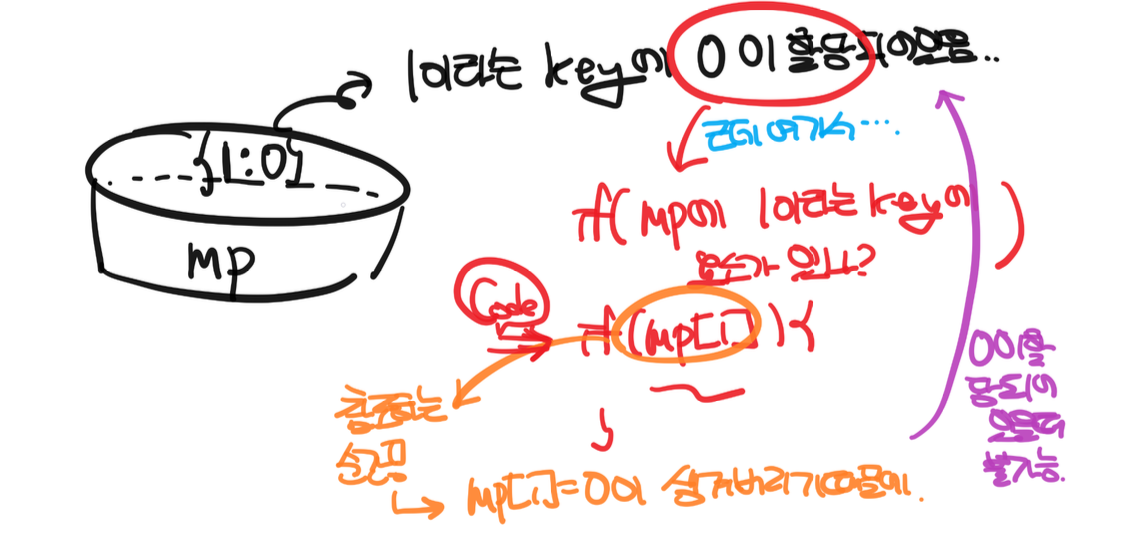
만약 문제에서 0이 들어가는 것을 비교하기 귀찮다면 다음 코드를 기반으로 작성해라.
#include <bits/stdc++.h>
using namespace std;
map<int, int> mp;
map<string, string> mp2;
int main(){
ios_base::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
if(mp.find(1) == mp.end()){
mp[1] = 2;
}
for(auto i : mp) cout << i.first << " " << i.second;
return 0;
}
/*
1
2
*/unordered_map
map은 정렬이 되는 반면 unordered_map은 정렬이 되지 않은 map이며 메서드는 map과 동일하다.
map vs unordered_map
- map : 정렬이 됨 / 레드블랙트리기반 / 탐색, 삽입, 삭제에 O(logN)이 걸림
- unordered_map : 정렬이 안됨 / 해시테이블 기반 / 탐색, 삽입, 삭제에 평균적으로
O(1), 가장 최악의 경우 O(N)
#include<bits/stdc++.h>
using namespace std;
unordered_map<string, int> umap;
int main(){
umap["bcd"] = 1;
umap["aaa"] = 1;
umap["aba"] = 1;
for(auto it : umap){
cout << it.first << " : " << it.second << '\n';
}
return 0;
}
/*
aba : 1
aaa : 1
bcd : 1
*/문제에 정렬이 필요로 하지 않은 문제에는 unordered_map을 써도 될 것 같지만 제출해보면 시간초과가 나기도 한다. (가장 최악의 경우 O(N)이기 때문)
➡️ 되도록 map을 쓰는 것을 권장한다.
set
- 셋(set)은 고유한 요소만을 저장하는 컨테이너이다.
- 중복을 허용하지 않는다.
- map처럼 {key, value}로 집어넣지 않아도 되며 pair나 int형을 집어넣어서 만들 수 있다.(다음 코드 참고)
- 중복된 값은 제거 되며 map과 같이 자동 정렬된다.
- 메서드는 map과 같다.
#include <bits/stdc++.h>
using namespace std;
int main(){
set<pair<string, int>> st;
st.insert({"test", 1});
st.insert({"test", 1});
st.insert({"test", 1});
st.insert({"test", 1});
cout <<st.size() <<"\n";
set<int> st2;
st2.insert(2);
st2.insert(1);
st2.insert(2);
for(auto it : st2){
cout << it << '\n';
}
return 0;
}
/*
1
1
2
*/(중복 제거) set과 unique 중 어떤 것을 써야 할까?
어떤 것을 사용하는게 더 좋은가? set을 사용해도 되고, unique와 erase를 사용해도 된다.
vector에다가 담아야 하는 로직이 있다고 가정.
set을 사용할 경우,
1. 중복된 배열 vector 생성됨
2. set을 사용해서 중복 제거
3. 다시 새로운 vector를 만들어 요소를 집어넣음
➡️ 새로운 vector, set 2개의 자료구조가 '더' 만들어진다.
➡️ u nique()와 erase()를 사용한다면 그냥 해당 중복된 배열 vector를 기반으로 재탕해서 사용해도 된다.
두 개의 로직을 C++ 벤치마크로 테스팅
https://perfbench.com/
#include <bits/stdc++.h>
using namespace std;
void A(){
vector<int> v;
int n = 1e5;
for(int i = 1; i < n; i++){
v.push_back(i);
v.push_back(n - i);
}
sort(v.begin(), v.end());
v.erase(unique(v.begin(),v.end()),v.end());
}
void B(){
vector<int> v;
int n = 1e5;
for(int i = 1; i < n; i++){
v.push_back(i);
v.push_back(n - i);
}
set<int> st;
for(int i : v){
st.insert(i);
}
vector<int> nv;
for (int i : st) {
nv.push_back(i);
}
}
void test_latency(size_t iteration) {
PROFILE_START("A");
A();
PROFILE_STOP("A");
PROFILE_START("B");
B();
PROFILE_STOP("B");
}
int main() {
const size_t warmups = 1000;
const size_t tests = 100;
PROFILE_RUN_ALL(warmups, tests, test_latency(__loop);)
return 0;
}
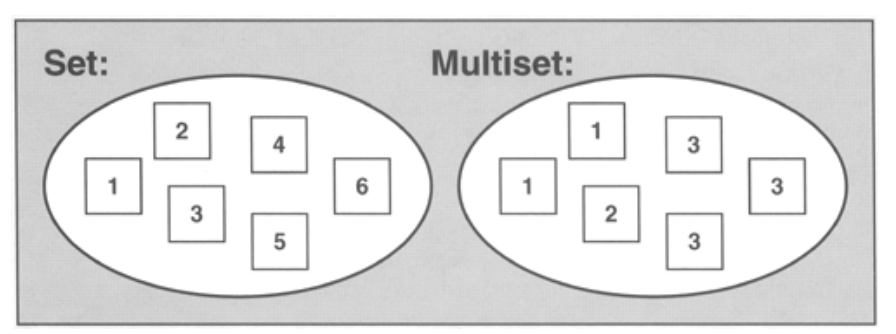
multiset
- multiset은 중복되는 요소도 집어넣을 수 있는 자료구조이다.
- key, value 형태로 집어넣을 필요도 없고 넣으면 자동적으로 정렬된다.
- 메서드는 map과 같다.
#include <bits/stdc++.h>
using namespace std;
multiset<int> s;
int main() {
for(int i = 5; i >= 1; i--){
s.insert(i);
s.insert(i);
}
for(int it : s) cout << it << " ";
cout << '\n';
return 0;
}
/* 1 1 2 2 3 3 4 4 5 5 */stack
- 스택은 가장 마지막으로 들어간 데이터가 가장 첫 번째로 나오는 성질인 후입선출(LIFO, Last In First Out)을 가진 자료 구조이다.
- 재귀적인 함수, 알고리즘에 사용되며 웹 브라우저 방문 기록 등에 쓰인다.
- 삽입 및 삭제에 O(1), 탐색에 O(n)이 걸린다.
- 탐색에 O(n)이 걸리는 이유는 n번째 요소를 찾는다고 가정하면 계속해서 앞에 있는 요소를 끄집어내는 과정을 n 번 반복해야 찾을 수 있기 때문이다.
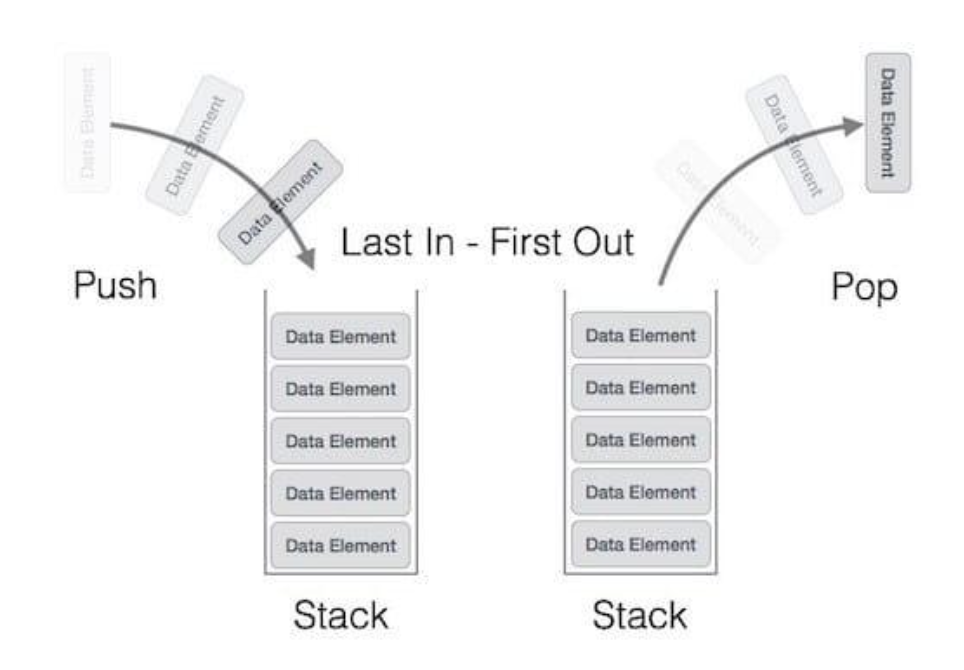
스택은 주로 문자열 폭발, 아름다운 괄호만들기, 짝찾기 키워드를 기반으로 이루어진 문제에서 쓰일 수 있다.
또한, “교차하지 않고” 라는 문장이 나오면 스택을 사용해야 하는 것은 아닐까? 염두해야 함
#include<bits/stdc++.h>
using namespace std;
stack<string> stk;
int main() {
ios_base::sync_with_stdio(false);
cin.tie(NULL);
stk.push("김");
stk.push("혜");
stk.push("주");
stk.push("화");
stk.push("이");
stk.push("팅");
while(stk.size()) {
cout << stk.top() << "\n";
stk.pop();
}
return 0;
}
/*
팅
이
화
주
혜
김
*/push(value)
해당 value를 스택에 추가한다.
pop()
가장 마지막에 추가한(가장 위에 있는) 요소를 지운다.
top()
가장 마지막에 있는(가장 위에 있는) 요소를 참조한다.
size()
스택의 크기
queue
- 큐(queue)는 먼저 집어넣은 데이터가 먼저 나오는 성질인 선입선출(FIFO, First In First Out)을 지닌 자료 구조이다.(스택과는 반대되는 개념)
- 삽입 및 삭제에 O(1), 탐색에 O(n)이 걸린다.
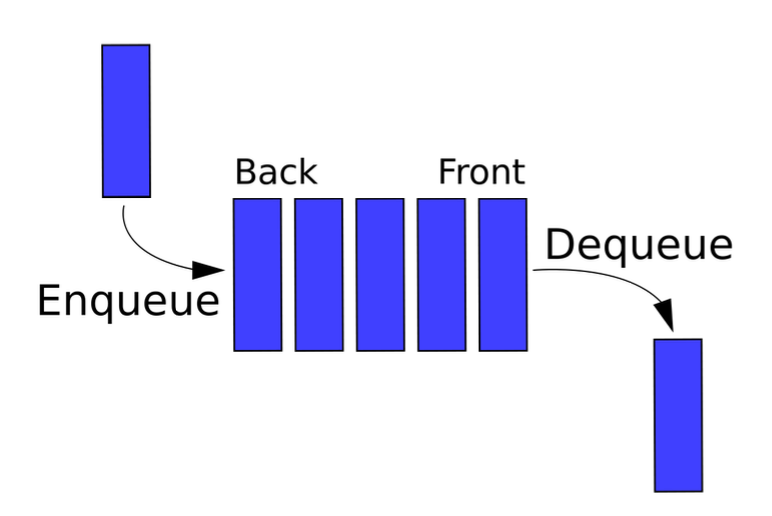
#include <bits/stdc++.h>
using namespace std;
queue<int> q;
int main(){
for(int i = 1; i <= 10; i++) q.push(i);
while(q.size()){
cout << q.front() << ' ';
q.pop();
}
return 0;
}
/*
1 2 3 4 5 6 7 8 9 10
*/push(value)
value를 큐에 추가한다.
pop()
가장 앞에 있는 요소를 제거한다.
size()
큐의 크기
front()
가장 앞에 있는 요소를 참조한다.
deque
queue는 앞에서만 끄집어낼 수 있다면 deque은 앞뒤로 삽입, 삭제, 참조가 가능한 자료구조입니다.
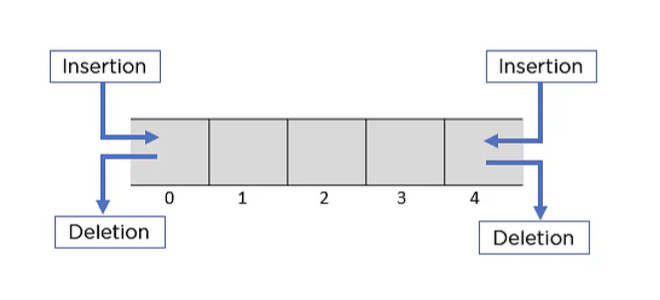
using namespace std;
int main(){
deque<int> dq;
dq.push_front(1);
dq.push_back(2);
dq.push_back(3);
cout << dq.front() << "\n";
cout << dq.back() << "\n";
cout << dq.size() << "\n";
dq.pop_back();
dq.pop_front();
cout << dq.size() << "\n";
return 0;
}
/*
1
3
3
1
*/struct(구조체)
구조체라 불리는 struct는 C++에서 제공하는 자료구조가 아닌 개발자의 커스텀한 자료구조를 의미한다.
커스텀하게 정렬을 추가하고 싶거나 문제에서 여러개의 변수(ex - a, b, c, d, e)가 들어간 자료구조가 필요하다면 struct를 사용해야 한다.
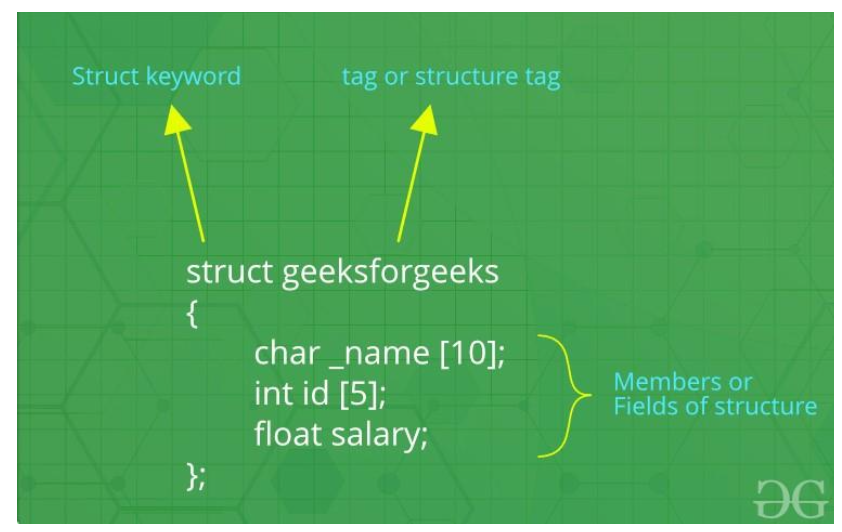
예를 들어 int 타입의 2개의 멤버변수, double 타입의 3개의 멤버 변수가 필요하다고 하자.
c.f 멤버변수란 클래스 또는 구조체 내부의 변수이자 메소드 밖에 있는 변수를 뜻함
랄로 구조체 정의하기
- 다음 코드를 보면
Ralo라는 int 타입의 2개의 멤버변수, double 타입의 3개의 멤버 변수를 가진 간단한 구조체를 형성한 것을 볼 수 있다. - 정해지지 않고 커스텀하게 만든 것을 볼 수 있으며 vector에도 집어넣은 모습을 볼 수 있다.
- 만약 값을 집어넣지 않은 경우 0으로 초기화된다.
- char 또는 string으로 선언한 경우 값을 집어넣지 않게 되면 빈문자열이 들어간다.
#include<bits/stdc++.h>
using namespace std;
struct Ralo{
int a, b;
double c, d, e;
};
void print(Ralo ralo){
cout << ralo.a << " " << ralo.b << " " << ralo.c << " " << ralo.d << " " << ralo.e << '\n';
}
int main(){
Ralo ralo = {1, 1, 1, 1, 1};
print(ralo);
vector<Ralo> ret;
ret.push_back({1, 2, 3, 4, 5});
ret.push_back({1, 2, 3, 4, 6});
ret.push_back({});
ret.push_back({1, 3});
for(Ralo ralo : ret){
print(ralo);
}
return 0;
}
/*
1 1 1 1 1
1 2 3 4 5
1 2 3 4 6
0 0 0 0 0
1 3 0 0 0
*/간단한 구조체를 집어넣은 vector를 정렬한다면 어떻게?
a를 1순위로, b를 2순위로 오름차순으로 정렬하고 싶다?
지금은 아무것도 집어넣지 않을 경우 0 또는 빈 문자열이 들어가게 되는데 초기값을 설정하고 싶다면?
➡️ 요구사항이 많아지게 되면 조금은 복잡하게 구조체를 구축해야 한다.
Point 구조체 정의하기
다음 코드는 조금은 복잡한 Point라는 구조체를 정의한다.
구조체를 기반으로 정렬하는 연산, 그리고 초기값 설정이 필요하다면 다음과 같은 형태로 구조체를 정의해야 한다.
struct Point{
int y, x;
Point(int y, int x) : y(y), x(x){}
Point(){y = -1; x = -1; }
bool operator < (const Point & a) const{
if(x == a.x) return y < a.y;
return x < a.x;
}
};하나씩 살펴보자.
- 구조체 멤버변수 y, x를 정의한다.
int y, x;- y, x를 받아 멤버변수를 생성한다.
Point(int y, int x) : y(y), x(x){}c.f java의 constructor 매직메서드
class의 constructor라는 매직메서드를 생각하면 된다. 이 구조체를 기반으로 객체를 생성할 때 y, x를 받아 생성한다라는 의미이다.
- 초기값 설정 부분이다. 만약 y, x가 정해지지 않은 경우 기본값으로 -1, -1을 설정한다는 의미이다.
Point(){y = -1; x = -1; }- 연산자(Operator) 오버로딩이다. 말 그대로 연산자를 오버로딩(하위 클래스에서 재정의)하는 것이다. 연산자는 <, > 등이 있고 이를 오버로딩 한다는 말이다.
bool operator < (const Point & a) const{
if(x == a.x) return y < a.y;
return x < a.x;
}구조체를 기반으로 만들어진 객체들끼리 비교해야 하는 경우가 있다.(ex : PointA < PointB) 이 때 비교하는 "기준"을 잡는다. 1순위는 x, 2순위는 y를 기반으로 크고 작음을 판단하는 코드이다.
이 비교는 단순하게 if문으로 비교할 때도 정의해야하지만 정렬할 때도 정의해야 한다. 정렬이란 요소들을 비교해가며 정렬하는 것이기 때문이다. 앞의 코드를 기반으로 정렬하면 x가 1순위, y가 2순위로 “오름차순"으로 정렬된다.
만약 {1, 2}, {2, 3}이 만나면 어떻게 되는가? x는 서로 같지 않기 대문에 바로 밑의 return문으로 내려가게 되고 x를 비교해서 {1, 2}가 더 작기 때문에 {1, 2}와 {2, 3}을 비교했을 때 {1, 2}가 더 작다는 결론을 내리게 된다. 만약 x가 같다면 이와 같은 논리로 y를 기반으로 비교해서 해당 요소가 더 작다는 결론을 내릴 것이다.
if(x == a.x) return y < a.y;
return x < a.x;구조체끼리도 크고 작음을 비교할 때는 이렇게 어떠한 멤버변수를 기준으로 할 것인지 등을 정해야 한다.
왜 오버라이딩 아니라 오버로딩?
왜냐하면 operator +, -, *, / 등의 의미를 변경하지 않으며 그저 오퍼레이터의 대상이 바뀌는 것 뿐이기 때문이다. 교안에서는 <라는 연산자를 오버로딩하는데 이는 그냥 int, float의 기본타입이 아니라 좀 더 복잡한 어떠한 객체 struct 를 기반으로 확장하는 것 뿐이기 때문이다.
구조체 기반 sort를 사용할 때 주의할 점
앞의 코드를 보면 < 오퍼레이터를 기준으로 struct를 구축된 것을 볼 수 있다. 이를 기반으로 이러한 struct를 구현한 변수들을 sort를 하는 상황이 생긴다. 이 때문에 저 struct의 오퍼레이터는 >가 아니라 < 오퍼레이터를 기준으로 설정되어야 한다.
sort()함수 자체가 < 오퍼레이터를 기준으로 정렬하기 때문이다.
c.f 참고로 struct 내의 오퍼레이터 오버로딩 하지 않고 compare 함수를 만들어서 할 수도 있다. 이 때 sort를 사용한다면 동일하게 < 오퍼레이터를 기준으로 compare함수를 정의해야 한다.
string으로 이뤄진 배열을 정렬한 코드
#include <bits/stdc++.h>
using namespace std;
bool compare(string a, string b){
if(a.size() == b.size()) return a < b;
return a.size() < b.size();
}
int main(){
ios::sync_with_stdio(0); cin.tie(0);
string a[3] = {"111", "222", "33"};
sort(a, a + 3, compare);
for(string b : a) cout << b << " ";
return 0;
}
/*
33 111 222
*/숫자를 담고 있지만 string으로 설정된 변수들을 정렬할 때 앞의 코드와 같은 compare()함수를 써야 한다.
string은 서로 비교할 때 왼쪽에서부터 아스키코드순으로 비교한다.
왼쪽에서부터 아스키코드순으로 비교하기 때문에 “33”이 “111”보다 더 크다고 인식해버린다. 그래서 항상 숫자로 이루어진 문자열을 비교할 때는 사이즈확인 로직을 넣는게 중요합니다.
Ralo struct를 compare 함수를 통해 정렬한 코드
#include <bits/stdc++.h>
using namespace std;
struct Ralo{
int a, b;
};
bool compare(Ralo A, Ralo B){
if(A.a == B.a) return A.b < B.b;
return A.a < B.a;
}
int main(){
ios::sync_with_stdio(0); cin.tie(0);
Ralo a[3] = {{1, 2}, {1, 3}, {0, 4}};
sort(a, a + 3, compare);
for(Ralo A : a) cout << A.a << " : " << A.b << "\n";
return 0;
}
/*
0 : 4
1 : 2
1 : 3
*/1순위로 Ralo의 a를 오름차순으로, 2순위로 Ralo의 b를 오름차순으로 정렬되는 코드이다.
3개의 멤버변수 정렬하기
자, 이제 3개의 멤버변수인 y, x, z가 필요하다고 해보자.
x를 1순위로 오름차순으로 정렬하고, y가 2순위로 내림차순, z가 3순위로 오름차순 정렬이라는 문제가 있다면?
struct Point{
int y, x, z;
Point(int y, int x, int z) : y(y), x(x), z(z){}
Point(){y = -1; x = -1; z = -1; }
bool operator < (const Point & a) const{
if(x == a.x) {
if(y == a.y) return z < a.z;
return y > a.y;
}
return x < a.x;
}
};이렇게 위와 같이 구조체를 구축한다. 참고로 초기값은 -1이 아니라 달느 수를 집어넣어도 된다.
vector에다 struct 넣고 정렬하기
vector에다 Point라는 struct를 넣어서 정렬하는 모습이다.
#include <bits/stdc++.h>
using namespace std;
struct Point {
int y, x;
};
bool cmp(const Point &a, const Point &b) {
return a.x > b.x;
}
vector<Point> v;
int main(){
for (int i = 10; i >= 1; i--) {
v.push_back({i, 10 - i});
}
sort(v.begin(), v.end(), cmp);
for (auto it : v) cout << it.y << " : " << it.x << "\n";
return 0;
}
/*
1 : 9
2 : 8
3 : 7
4 : 6
5 : 5
6 : 4
7 : 3
8 : 2
9 : 1
10 : 0
*/c.f
커스텀한 자료구조를 만들 때 보통 class와 struct를 쓰지만 코딩테스트에서는 struct만 알아도 충분하다. 둘의 차이는 struct의 멤버변수는 기본적으로 public이며 상속이 안되고, class의 멤버변수는 기본적으로 private이며 상속이 된다.
priority queue
- 우선순위 큐(priority queue)는 각 요소에 어떠한 우선순위가 추가로 부여되어있는 컨테이너를 말한다.
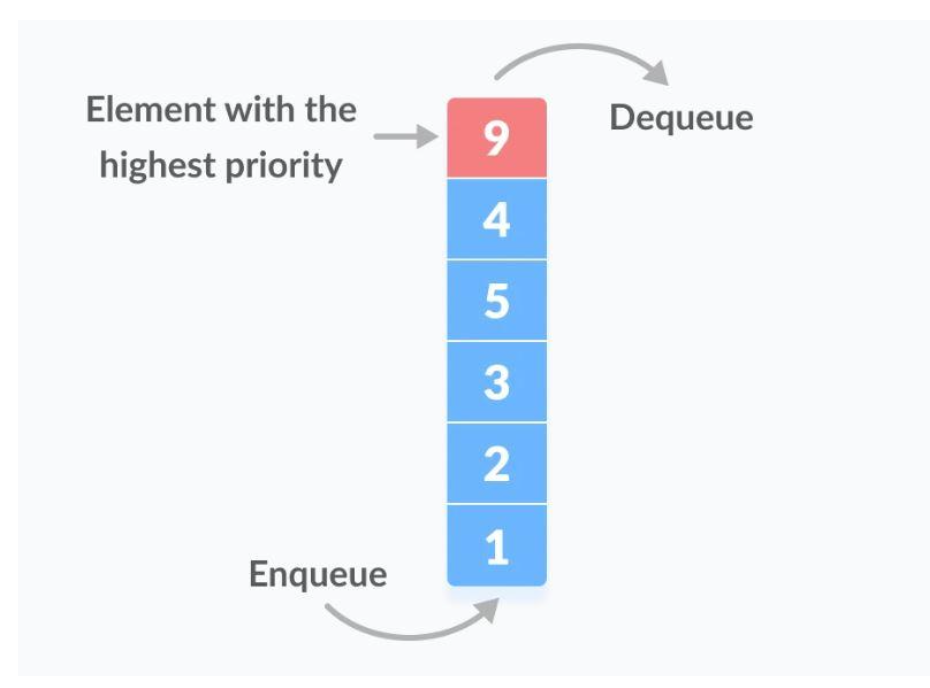
- 우선순위 큐에서 우선순위가 높은 요소는 우선순위가 낮은 요소보다 먼저 제공된다.
- 일부 구현에서 두 요소의 우선 순위가 같으면 대기열에 포함된 순서에 따라 제공된다.
- 다른 구현에서 동일한 우선 순위를 가진 요소의 순서는 정의되지 않은 상태로 유지된다.
c.f
힙은 완전이진트리로 최소힙 또는 최대힙이 있으며 삽입, 삭제, 탐색, 수정에 대해 O(logN)의 시간복잡도를 갖는다. 최대 힙은 루트 노드에 최대값이 있고, 최소 힙은 루트 노드에 최소값이 있는 힙을 말한다.

int형 우선순위큐
- 단순하게 int형 우선순위큐는 다음 코드 처럼
greater<타입>을 써서 오름차순,less<타입>을 써서 내림차순으로 바꿀 수 있다. - 기본값은 내림차순이라 단순하게
priority_queue<타입>을 쓰면 해당 타입에 대한 내림차순으로 설정된다. - 메서드는 stack과 같다.
size(),top(),pop(),push()가 있다.
#include <bits/stdc++.h>
using namespace std;
priority_queue<int, vector<int>, greater<int> > pq; //오름차순
priority_queue<int> pq2; // 내림차순
priority_queue<int, vector<int>, less<int> > pq3; // 내림차순
int main(){
for(int i = 5; i >= 1; i--){
pq.push(i); pq2.push(i); pq3.push(i);
}
while(pq.size()){
cout << pq.top() << " : " << pq2.top() << " : " << pq3.top() << '\n';
pq.pop(); pq2.pop(); pq3.pop();
}
return 0;
}
/*
1 : 5 : 5
2 : 4 : 4
3 : 3 : 3
4 : 2 : 2
5 : 1 : 1
*/구조체를 담은 우선순위 큐
int 뿐만 아니라 구조체(struct) 등 다른 자료구조를 넣어서 할 수 있다.
#include <bits/stdc++.h>
using namespace std;
struct Point {
int y, x;
Point(int y, int x) : y(y), x(x) {}
Point() {y = -1; x = -1;}
bool operator < (const Point & a) const {
return x > a.x;
}
};
priority_queue<Point> pq;
int main(){
pq.push({1, 1});
pq.push({2, 2});
pq.push({3, 3});
pq.push({4, 4});
pq.push({5, 5});
pq.push({6, 6});
cout << pq.top().x << "\n";
return 0;
}
/*
1
*/앞의 코드를 보면 분명 < 연산자에 x > a.x를 했기 때문에 분명 내림차순으로 정렬되어 6이 출력이 되어야 하는데 1이 출력된다.
➡️ 이는 우선순위큐에 커스텀 정렬을 넣을 때 반대로 넣어야 하는 특징 때문이다.
반대로 해보자.
#include <bits/stdc++.h>
using namespace std;
struct Point {
int y, x;
Point(int y, int x) : y(y), x(x) {}
Point() {y = -1; x = -1;}
bool operator < (const Point & a) const {
return x < a.x;
}
};
priority_queue<Point> pq;
int main(){
pq.push({1, 1});
pq.push({2, 2});
pq.push({3, 3});
pq.push({4, 4});
pq.push({5, 5});
pq.push({6, 6});
cout << pq.top().x << "\n";
return 0;
}
/*
6
*/x > a.x가 x < a.x로 바뀐 모습이다. 우선순위큐에 커스텀 정렬을 넣을 때는 반대라고 생각하면 된다. 가장 최소를 끄집어 내고 싶은 로직이라면 >, 최대라면 < 이런식으로 설정하면 된다.
다음 코드처럼도 가능하다.
#include <bits/stdc++.h>
using namespace std;
struct Point {
int y, x;
};
struct cmp {
bool operator() (Point a, Point b) {
return a.x < b.x;
}
};
priority_queue<Point, vector<Point>, cmp> pq;
int main(){
pq.push({1, 1});
pq.push({2, 2});
pq.push({3, 3});
pq.push({4, 4});
pq.push({5, 5});
pq.push({6, 6});
cout << pq.top().x << "\n";
return 0;
}
/*
6
*/자료구조 시간복잡도 정리
지금까지 다룬 자료구조의 최악의 시간복잡도를 정리한다.
| 자료구조 | 참조 | 탐색 | 삽입 | 삭제 |
|---|---|---|---|---|
| 배열 | O(1) | O(n) | O(n) | O(n) |
| 스택 | O(n) | O(n) | O(1) | O(1) |
| 큐 | O(n) | O(n) | O(1) | O(1) |
| 연결리스트 | O(n) | O(n) | O(1) | O(1) |
| 맵 | O(logn) | O(logn) | O(logn) | O(logn) |
- 스택과 큐 같은 경우 가장 앞에 있는 요소를 참조한다고 생각하면 O(1)이지만, 중간에 있는 요소를 참조한다고 했을 때 랜덤접근이 아닌 순차접근만 되기 때문에 O(n)의 시간이 걸린다.
