2023.01.10(화) Westudy > Precourse > 공통세션 > Database
관계형 데이터베이스
- 관계형 데이터베이스 (RDBMS)
- 비관계형 데이터베이스 (Non-relational); 보통 NoSQL로 명칭됨
여기서 관계란, 데이터들 간의 관계를 뜻한다.
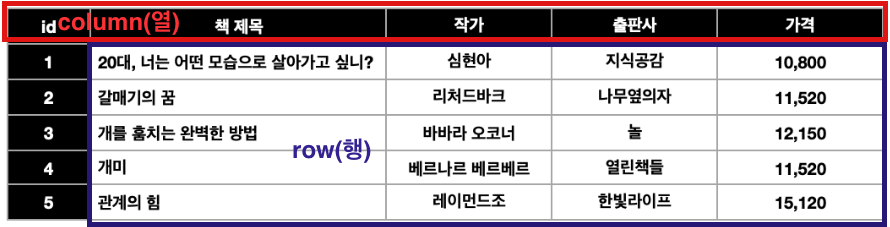
- column(열): 테이블의 각 항목 (
id,책 제목,작가,출판사,가격)
- row(행): 각 항목들의 실제 값
- 각 row(행)는 변하지 않는 고유의 키(primary key)를 보유하고 있다. 이와 같은pk(primary key)를 통해 특정 로우를 찾거나 인용하는 게 가능하다.
테이블 사이 관계의 종류
1. One to One(일대일)
- ex) 대한민국 사람은 주민등록번호를 오로지 단 한개만 가질 수 있다; 서로가 서로의 오로지 한 로우에만 연결될 수 있음.
2. One to Many(일대다)
- ex) 두 마리의 반려동물(다)을 기르고 있는 주인(일); 로우 하나에 다른 테이블의 로우 여러개가 연결될 수 있음.
3. Many to Many(다대다)
- ex) 한 작가는 여러 권의 책을 쓸 수 있다. + 한 책에도 작가는 여러명이 될 수 있다. 중복되는 데이터를 서로 다른 데이터로 인식하는 것을 방지하기 위해 다대다 관계가 필요함.
외래키(foreign key)란, 두 테이블을 서로 연결하는 데 사용되는 키를 뜻함.
테이블을 연결하는 이유
- 하나의 테이블에 모든 정보를 넣으면 불필요하게 중복되어 저장될 가능성이 큼
- 더 많은 디스크를 사용하게 되고 잘못된 데이터가 저장될 가능성이 높아짐
-> normalization(정규화)의 필요성이라고 볼 수 있다.
db.diagram 으로 스타벅스 음료 페이지 모델링
- 필수 구현 사항 :
음료,카테고리,영양 정보,알러지,음료 이미지,음료 설명,신상 여부
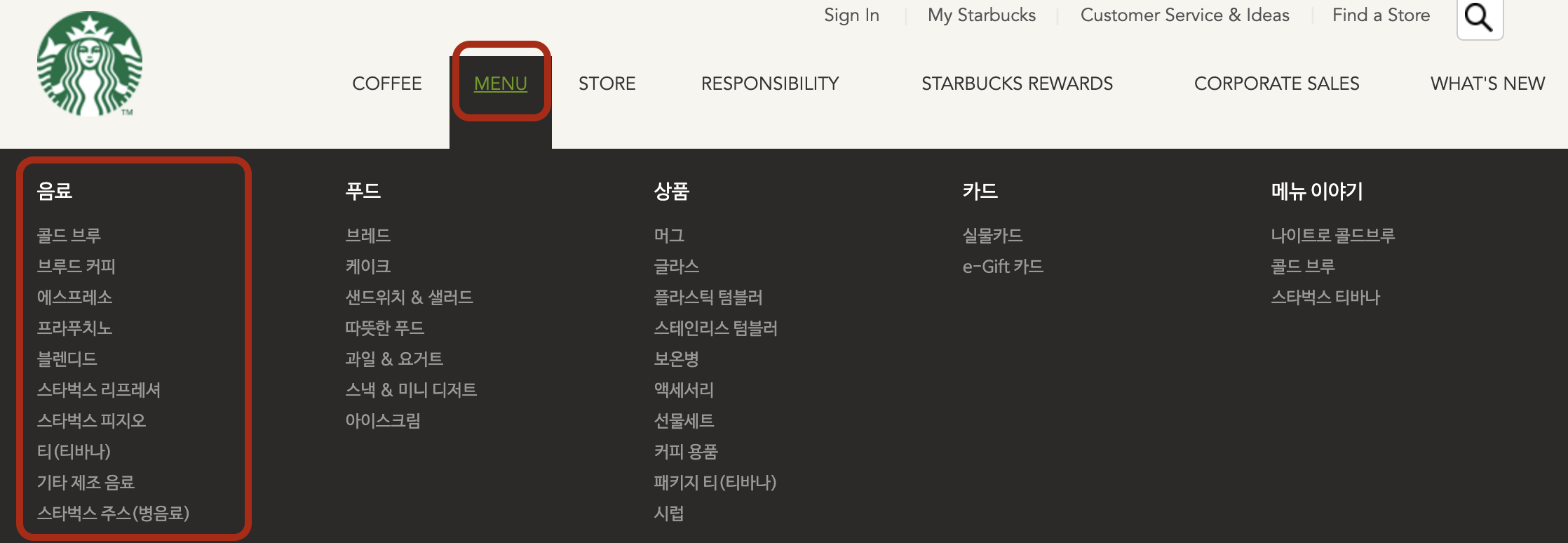
스타벅스 홈페이지에 들어가 음료 카테고리부터 찾았다. 처음에는 음료 카테고리 부분을 구현하기 위해 beverages라는 테이블을 만들고 눈에 보이는대로 무작정 콜드브루, 브루드 커피, 에스프레소 ... 를 전부 다 입력했다가 데이터를 입력하는 게 아니라는 피드백을 받고 싹 다 지웠다.
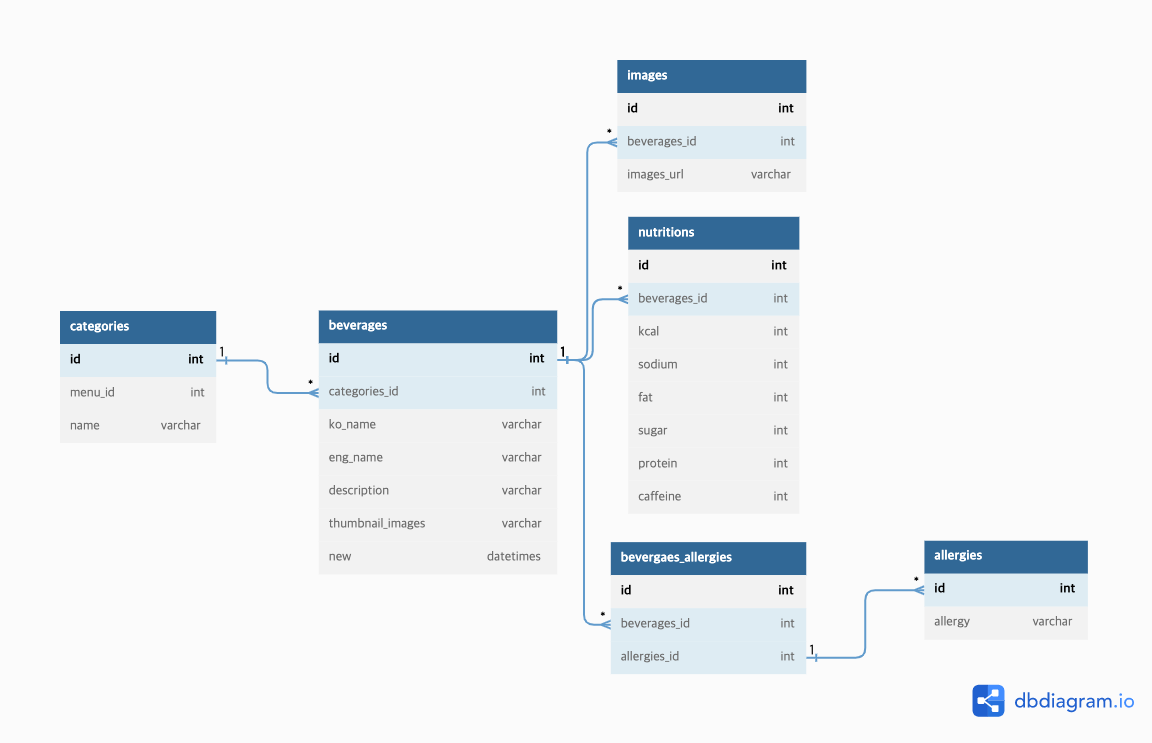
👥 팀원들과 함께 만들어본 ERD 도식도
- 내가 만든 데이터베이스는 위와 같은데, 테이블끼리 연결시키기 위해 각각 id 요소들(
id,categories_id,beverages_id등)을 생성해서 관계가 있는 테이블들끼리 링크를 걸어줬다. - 처음에는
description테이블도 따로 생성했다가 상세설명(description)같은 경우에는 음료마다 상세설명이 각기 다 다를 것이기 때문에 굳이 별도의 테이블로 빼지 않고beverages테이블 안에 포함시키는 것이 효율적일 것이라는 피드백을 받고description을beverages테이블 안으로 집어넣었다. allergies테이블 안에는우유,대두,우유, 대두와 같이 동일한 데이터를 갖고 있는 음료들이 많기 때문에 일대다 관계를 형성하는 것보다는 다대다 관계를 맺는 게 추후에 기능적인 부분을 구현하는 것을 포함한 유지보수가 용이하다는 설명을 듣고beverages와allergies테이블 사이에beverages_allergies테이블을 위치시켜 연결해주었다.ex)
우유알러지를 유발할 수 있는 음료들을 모두 모아주는 기능을 구현하고자 할 때,우유라는str을 파싱하여 한 곳에 집어넣고 도출하는 것보다는 다대다 관계로 데이터를 관리하여우유, 대두+우유데이터를 한번에 도출하는 것이 기능적인 면에서 훨씬 효율적임.신상여부를 알기 위해서는 해당 메뉴가 신상이 맞는지/아닌지를 가려내는boolean데이터를 사용하는 것보다는datetime데이터를 이용하여 특정 날짜를 기준으로 신상메뉴를 판별하는 게 더 논리적이다.
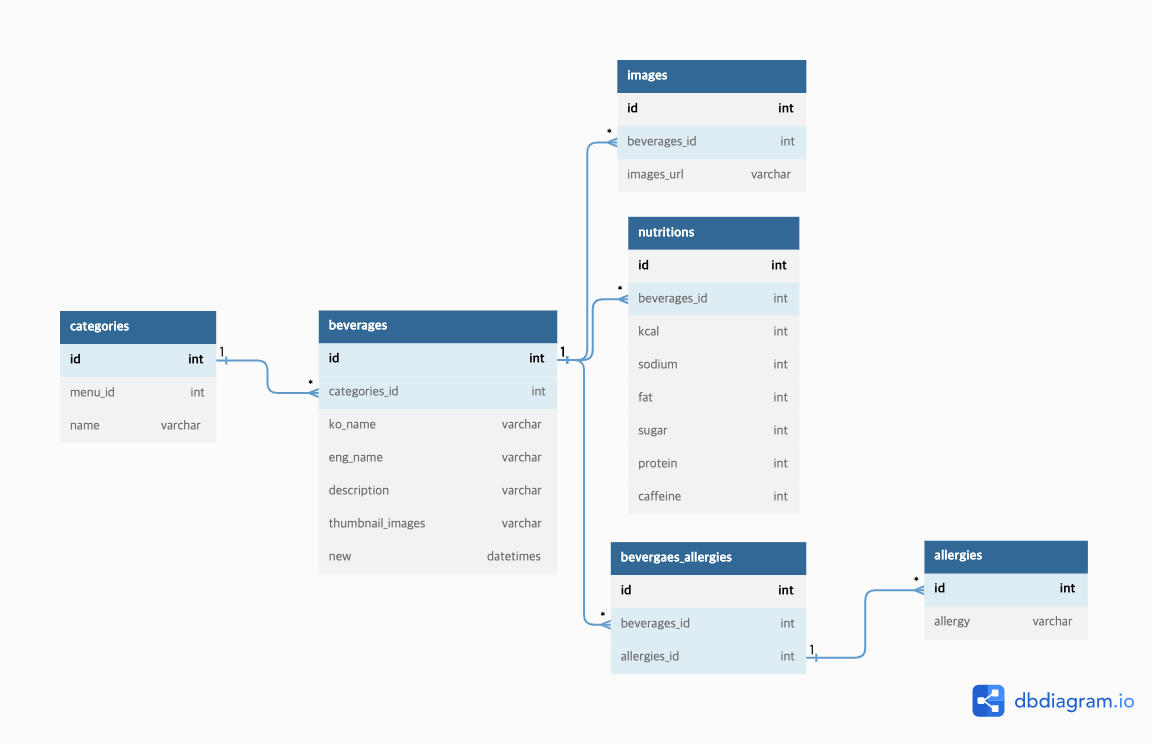
🧑🏻💻 호준님이 만드신 ERD 도식도 참고

drink_images 테이블 안의 sequence는 몇번째 사진을 썸네일로 할지 고정시키기 위함이다. (썸네일은 생각도 못했는데(!))
💬 데이터베이스 수업을 들은 후,
주로 백엔드 쪽에서 다루는 부분이긴 하지만 그래도 함께 이해하고 있는 게 나중에 프론트 작업을 할 때 용이하겠다는 생각이 들었다. 그리고 알고는 있었지만 생각보다 훨씬 더 논리적인 사고를 요구하는 분야라는 것을 다시 느꼈다... 어려워🥲
foreign key의 사용 이유?는 아직 이해가 잘 가지 않는다. 조금 더 찾아봐야 할 듯.
