Disk I/O는 유저 입출력보다 훨씬 많이 일어난다.
프로그램을 실행하다 보면 계속 Page Fault가 발생하는데 그럴 때마다 하드디스크에 가서 Page를 읽어와야 하기 때문이다.
OS가 I/O와 관련해서 중요하게 생각하는 2 가지
- System Efficiency : I/O는 프로세서/메인 메모리의 처리 속도보다 느리다.
- 입출력 Device/하드디스크 의 속도는 굉장히 느리다.
- Generality : 모든 I/O 디바이스는 uniform manner 방식으로 이루어져야 한다.
- 같은 명령을 사용해야 한다.
Disk Performance Parameters
하드 디스크에서 Page를 가져올 때 걸리는 시간은 개수는 상관이 없다.
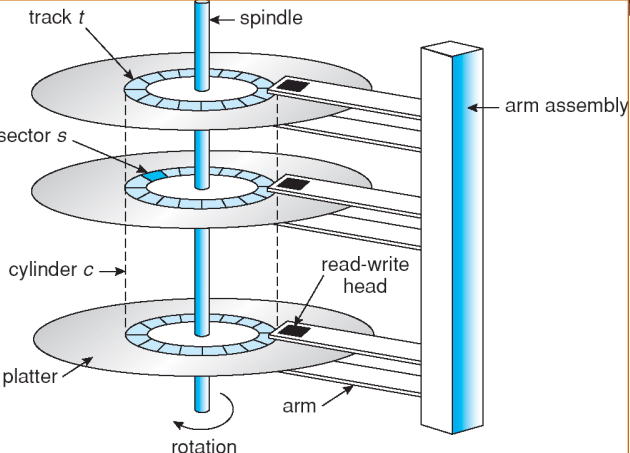
read-write head는 앞뒤로만 움직인다. ⇒ Track
Track 내에서 여러 등분으로 나뉜다. ⇒ Sector
X번 트랙에 있는 Page를 찾아가려면 arm을 움직여서 head가 원하는 Track 위치로 움직여야 한다.
원하는 Track 위치로 간 다음 원하는 Sector로 찾아가기 위해서 원판을 돌려야 한다.
- Seek Time : 원하는 페이지가 있는 하드디스크의 트랙을 찾아가는 데 걸리는 시간
- Rotational Latency : 원판을 돌려서 Page가 있는 Sector를 head에 위치시키는 데 걸리는 시간
- Transfer Time : Page를 읽는 데 걸리는 시간
데이터를 읽는데 걸리는 시간은 줄일 수 없고 Rotational Latency에 비해 Seek Time이 굉장히 크기 때문에 Seek Time을 줄이는 방식으로 디스크 스케쥴링을 진행한다.
Seek Time이 제일 오래 걸린다. head는 기계적으로 움직여야 하기 때문에 시간이 상당히 오래 걸린다. 그래서 Page 개수를 얼만큼 읽던 Seek Time이 굉장히 크기 때문에 Transfer Time은 2-3배가 돼도 시간이 별로 늘어나지 않는다.
따라서 Page가 연속된 공간에 있다면, 2-3 Page를 읽어도 시간이 똑같이 걸린다.
위의 세 가지 시간을 합치면 디스크에 접근하는 시간이 된다.
디스크의 속도를 높이기 위한 3가지
- 디스크 스케쥴링
- RAID
- Disk Caches
Disk Scheduling Policies
디스크 스케쥴링을 비교하려면 실제로 Disk Request가 어떤 순서로 도착했는지 가정해야 한다.
- 200개의 Track
- head는 100번 위치

Disk Queue에 있는 Request는 위와 같이 서있다. 숫자는 Track 번호를 뜻한다. 숫자에 해당하는 Track에 있는 데이터를 읽으려고 할 때, 어떤 Track에 있는 Request를 먼저 읽을지 결정하는 것이 Disk Scheduling 이다.
CPU 스케쥴링은 10~100 단위의 ns이지만, Disk Scheduling은 100 단위의 ms를 줄일 수 있기 때문에 더 큰 효과가 있다.
하드디스크의 큐는 항상 줄이 길다. CPU가 워낙 빠르기 때문에 하드디스크 큐에 멈춰있다 ⇒ Performance의 bottleneck
First-in, First-out (FIFO)
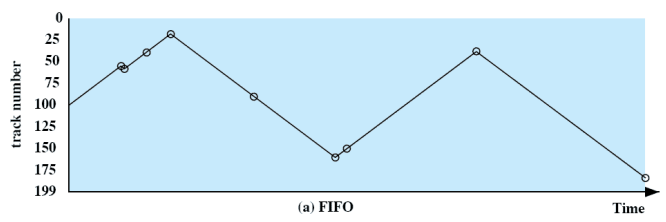
- 순서대로 작업 ⇒ Fair
- 시간은 오래걸린다.
- 모두한테 Fair 하지만 시간이 오래 걸림 ⇒ random scheduling
- 성능면에서는 좋은 방법 X
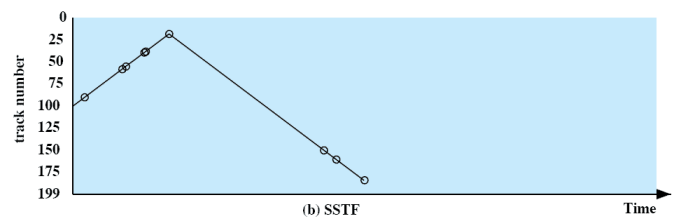
Shortest Service Time First
- 움직이는 거리가 짧은 것부터 처리 = Seek time이 최소인 것을 고른다.
- 100번을 기준으로 가장 가까운 것 부터 처리
- 헤드를 가장 적게 움직여서 service 할 수 있는 것부터 처리
- 가장 짧은 시간 소요 ⇒ 가장 성능이 좋다.
- Starvation 발생 가능
- 0 ↔ 199 : 가능성이 낮음
- Fairness와 Efficiency 둘 다 고려하는 기법 필요
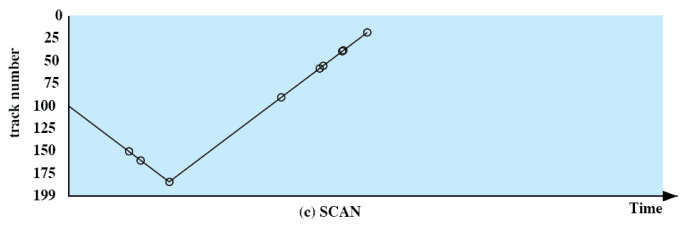
SCAN
- 헤드가 한쪽 방향으로 움직이다가 한쪽 방향에 끝에 다다르면 반대방향으로 움직인다.
- 안 → 밖
- 밖 → 안
- 150 → 160 → 184 → 90 → 58 → 50 …
- SSTF 보다는 시간이 오래 걸린다.
- Request는 계속해서 들어오기 때문에 Performance 차이는 날 수 밖에 없다.
- 하지만 Starvation 가능성이 거의 없기 때문에 많이 사용되는 방법
- Track은 많은 Sector를 가지고 있는데, Sector에서만 계속 처리하는 경우 starvation 가능
SCAN 기법은 다양하게 응용해서 사용한다.
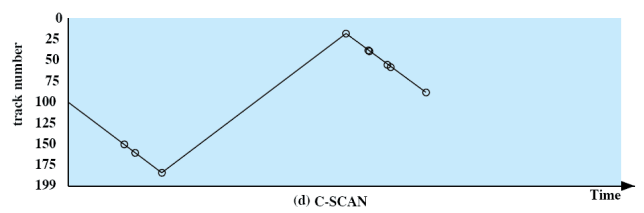
C-SCAN
- SCAN을 한방향으로만 한다.
- 0 → 199/199 → 0 : Service O
- 199 → 0/0 → 199 : Service X
- 전체적인 Request를 처리하는데 걸리는 시간은 SCAN 기법보다 오래 걸린다.
- C-SCAN의 목적
- Efficiency X
- 완벽한 Fairness ⇒ 예측가능성을 높인다.
- SCAN : Request마다 최대 기다리는 시간이 다르다.
- C-SCAN : Request가 service될 때 까지 기다리는 최대 시간이 일정하다.
N-step-SCAN
N값이 주어졌을 때 어떤 순서로 스케쥴링 되는지 알아야 한다. N=5이면, 5개씩 잘라서 Queue에 집어넣고 한 번에 5개씩 스캔 기법으로 처리한다.
- SCAN의 적은 가능성의 Starvation도 제거
- Request를 길이가 N인 SubQueue로 나눈다. (Queue의 개수가 아니라 Queue의 길이)
- SubQueue에 있는 Request에 SCAN을 사용한다.
- 새로 들어온 Request는 가장 아래쪽 Queue로 들어온다.
- Starvation 발생 가능성이 완벽하게 없다.
- 추가로 도착하는 request는 나중에 처리하게 된다 ⇒ 가깝다는 이유로 땡겨쓰지 않게 된다.
- N 값을 결정하는 것이 구현의 문제점
- N = 1 ⇒ 들어온 순서대로 처리
- N 이 너무 커지면 SCAN 방식과 유사
FSCAN
시간 t에 다른 쪽 방향으로 작업 시작한다고 가정.
t 전에 도착한 Request는 움직이면서 처리하고, t 이후에 도착한 Request는 다른쪽 Queue에 저장
각각의 Request에 도착시간이 주어지고, 몇 시에 어떤 방향으로 움직이는지 주어졌을 때, 처리 순서를 계산할 수 있어야 한다.
- 2개의 SubQueue
- 0 → 199 (0번 Queue Request 처리)
- 새로 들어온 Request ⇒ 1번 Queue에 저장
- 199 (0번 Queue Request 모두 처리)
- 0번 Queue를 비운다.
- 1번 Queue를 0번 Queue로 만들고, 0번 Queue를 1번 Queue로 만든다.
- 199 → 0 (0번 Queue 처리)
- 0번 Queue에 새로운 Request가 들어오지 않는다.
- 처리해야하는 Request는 정해져 있고 이를 SCAN으로 작업한다.
- 반대편 끝까지가면 전부 처리
- Starvation X
- N-step-SCAN에 비해 N 값을 걱정할 필요가 없다.
그 밖의 Disk Scheduling Policies
- Priority scheduling
- 리퀘스트가 real-time 또는 오래동안 실행하는 batch request일 수도 있다. real-time이면 빨리 처리해야하고 batch는 천천히해도 상관없다.
- task의 우선순위에 따라서 작업순서를 결정
- Track의 위치를 고려하지 않기 때문에 Seek Time은 안좋을 수 있다.
- Last in First out
- starvation 발생 가능성이 높다.
- 지금 request가 여러 개 도착하면, 도착하는 request들은 같은 track에 있는 request라고 생각 ⇒ 헤드를 많이 움직이지 않고 적은 Seek Time으로 해결
- 프로그램의 locality를 기반으로 하는 스케쥴링 방법
RAID(Redundant Array of Independent Disks)
- 여러 개의 DISK를 사용하는 방법
- 디스크가 1개일 때랑 n개일 때랑 같은 시간의 읽을 수 있는 데이터 양은 n배 차이 ⇒ 많으면 많을수록 빠르게 데이터를 읽는다.
- 여러 개의 독립적인 DISK를 묶어서 하나의 하드디스크처럼 OS가 관리하게 한다.
- 데이터를 RAID안에 들어있는 Physical Hard Disk에 나눠서 저장한다.
- 속도 + Failure에 대처할 수 있는 능력 향상
- DISK가 여러개 있으므로 복사하거나 코드를 사용해서 Recovery를 쉽게할 수 있게 한다.
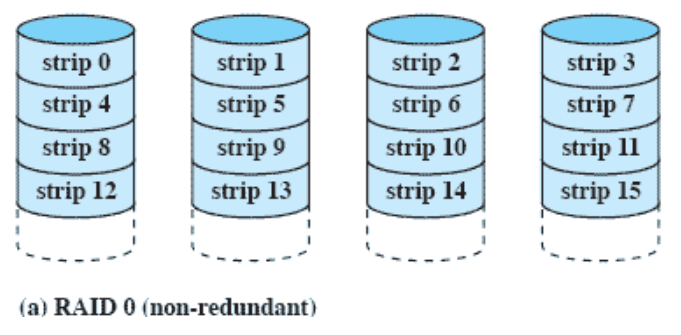
RAID 0 (non-redundant)
- 하드 디스크가 여러개 있다.
- 필요한 데이터들을 strip 단위로 나눈다.
- 파일을 strip 단위로 나눠서 여러개 하드디스크에 저장
- 여러 곳에서 동시에 읽는다.
- 4배까지는 아니지만 그만큼 빨라진다.
- 파일 하나를 잘라서 여러 곳에 넣는다.
- 하나만 문제가 발생해도 파일을 못읽음
- Recovery 필요
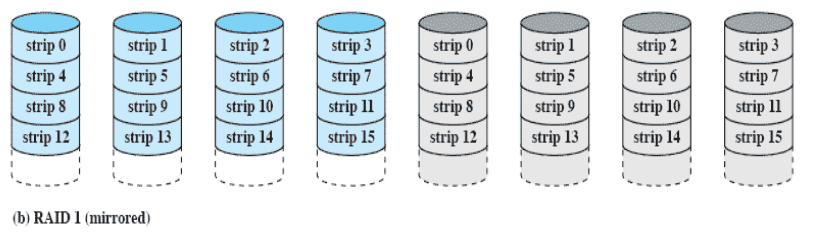
RAID 1 (mirrored)
- 데이터를 한 세트 copy
- 동시에 하드 디스크 2개가 고장나는 것은 확률적으로 굉장히 낮다.
- 디스크가 너무 많이 필요
- 속도를 4배 높이기 위해 8배 만큼의 가격 지불
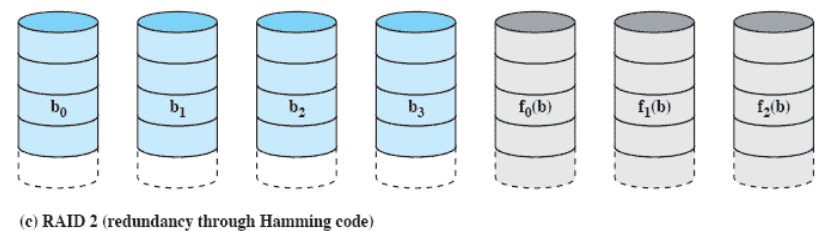
RAID 2 (redundancy through Hamming code)
- strip 단위가 아닌 bit 단위로 저장
- n 번째 비트들에 대한 n번째 코드비트 3개
- 4개의 데이터를 위해서 3개의 코드비트를 저장할 하드디스크 사용
- Hamming code 사용
Hamming code
데이터 디스크의 숫자를 준다 ⇒ code disk가 몇개가 필요한지 계산 ⇒ code 값을 계산할 수 있어야 한다.
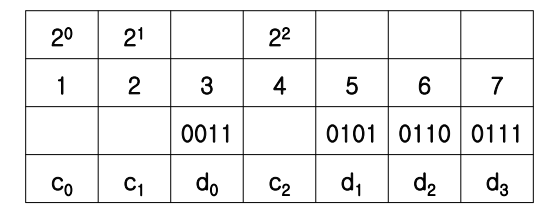
- 1, 2, 3, 4, 5, 6, 7 작성
- 2의 제곱인 숫자 표기
- 2의 제곱에 해당하는 숫자는 Code ⇒ C0, C1, C2, 해당하지 않는 숫자는 Data ⇒ d0, d1, d2, d3
- 데이터 디스크는 4개이고 bit 단위로 저장 ⇒ 4개의 데이터 디스크에 있는 첫번째 비트 ⇒ 4개의 비트 ⇒ d0,d1,d2,d3
- 4개의 데이터 디스크에 대해서 3개의 코드 디스크가 필요 ⇒ c0,c1,c2
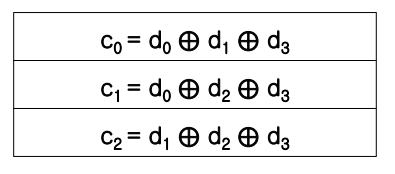
- c0 = d0 XOR d1 XOR d3 : 가장 아랫자리가 1인 3명
- c1 : 끝에서 2번째 자리가 1인 3개
- c2 : 3번째 자리가 1인 3개
- 4비트의 데이터 코드를 주고 해당하는 3개의 hamming code를 만들 수 있어야 한다.
- 데이터 디스크 1개 고장 ⇒ 코드 디스크를 보면 원래 값을 알 수 있다.
- d0 고장 → c0, d1, d3를 보면 저장된 값을 알 수 있다.
- 해밍코드로 데이터 디스크 1개가 고장났을 때 나머지 코드 디스크 값을 보고 원래 있었던 값을 찾을 수 있다.

- 데이터 디스크가 4개 ⇒ 3, 5, 6, 7 / 코드는 3개
- 데이터 디스크가 6개 ⇒ 3, 5, 6, 7, 9, 10 / 코드는 4개 필요
- 데이터 디스크가 12개 ⇒ ,3, 5, 6, 7, 9, 10, 11, 12, 13, 14, 15, 17 / 코드 디스크는 5개 필요
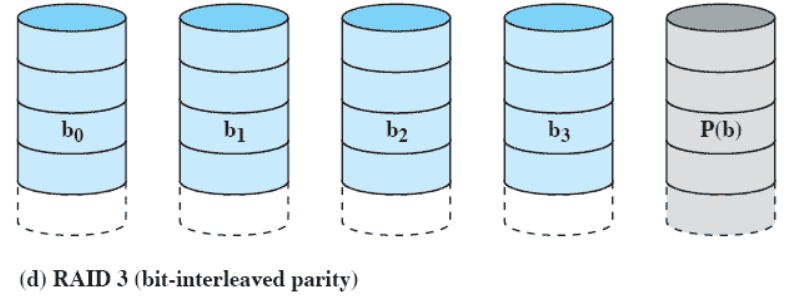
RAID 3 (bit-interleaved parity)
- 데이터 디스크가 4개, 첫번째 비트가 0001
- 홀수 parity : 0 (1의 개수를 홀수로 만듬)
- 짝수 parity : 1 (1의 개수를 짝수로 만듬)
- 1개만 추가로 사용하면 된다.
- 필요한 디스크가 최소
- 디스크 1개가 고장났을 때 나머지 값들을 통해 추측이 가능하다.
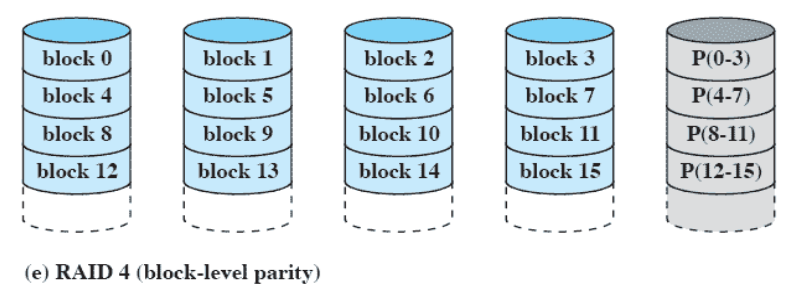
RAID 4 (block-level parity)
RAID 4와 5의 차이를 알아야 한다.
- Block 단위(≥ 512 byte) 의 parity
- 한 Block씩 저장하고 Block 단위의 parity 비트 저장한다.
- 프로그램 파일의 경우 업데이트 자주 X
- 데이터 파일은 계속 읽고 쓴다.
- block 0~3 이 파일 1개라 가정, block 1 수정
- block 1에 대해 쓰기 작업 ⇒ parity도 쓰기 작업
- block 4~7이 파일 1개라 가정, block 6 수정
- block 6에 대해 쓰기 작업 ⇒ parity도 쓰기 작업
- 다른 block 에서는 1번씩 쓰기를 하는데 parity block은 4번 쓰기작업
- 5개의 디스크 중에 parity code가 들어있는 디스크에서 쓰기가 너무 많이 발생 ⇒ bottleneck
- Parity Disk에 4배의 Request가 몰리게 된다.
RAID 5 (block-level distributed parity)
- 하나의 디스크에다가 parity 코드를 저장하는 것이 아니라 나눈다.
- 하나의 block에서 업데이트 ⇒ 쓰기 Request가 분산 = 다들 같은만큼의 쓰기가 가능해진다.
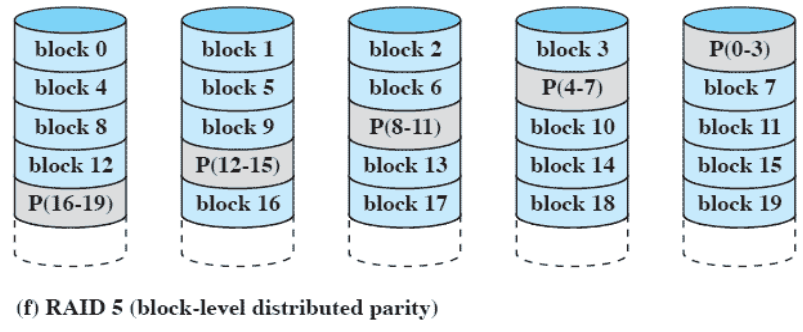
기본적으로 하나의 하드디스크를 가지고 있는게 아니라 여러 개의 하드디스크를 사용해서 access 속도도 높이고 fail이 발생했을 때 복구 가능성도 높인다.
Disk Cache
파일에서 정수 하나를 읽어온다 ⇒ 정수가 포함되어 있는 Block이 움직인다.
Block 통째로 유저 프로그램에 넘겨주는 것이 아니다. Block을 메인 메모리 안에 버퍼 공간에 저장하고, 버퍼 공간에서 정수 하나를 꺼내서 유저 프로세스의 공간으로 넘겨준다.
메인 메모리안에 모여있는 버퍼 공간 = Disk Cache
Block들이 모여었을텐데, 대부분의 경우 정수를 읽으면 다음 정수를 계속 읽는다. 두번째 정수를 읽을 때 다시 하드디스크에서 Block을 가져오는 것이 아니라 가져왔던 Block에서 읽는다.
당분간은 계속 재사용. 어떤 Block은 굉장히 오래 재사용된다 = 시스템 관리 프로세스가 사용하는 데이터
더 이상 사용되지 않을 것 같은 Block은 버린다.
하드 디스크에 접근하는 횟수를 줄인다.
Least Recently Used
- 최근에 사용한 Block을 남겨두고 오랫동안 사용하지 않은 Block을 버린다.
- Block을 Stack 형태로 관리한다.
Least Frequently Used
- 얼마나 자주 사용되었는지
- 여러 프로세스가 공통으로 사용하는 Block도 있다.
- 각각의 Block마다 Counter 사용
- Block이 사용될 때 마다 count 값 증가
- count 값이 제일 작은 것을 버린다.
- 방금 하드디스크에서 올라온 경우 count = 0 ⇒ 방금 올라온 걸 버리는 상황 발생 가능
Frequency-based Replacement
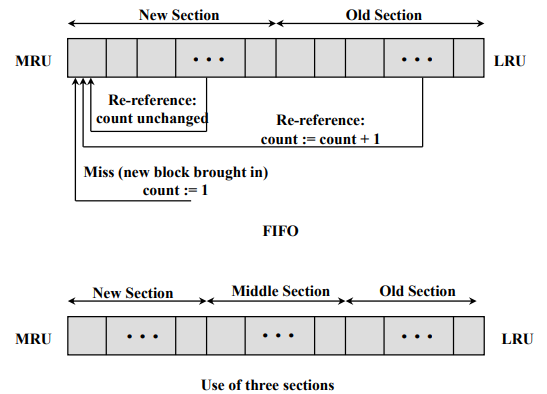
- 스택을 눕혀놓은 그림
- 왼편이 스택 Top
- New Section - Old Section
- 하드디스크 → New : count = 1, stack의 top으로 간다.
- New → New : count 값을 올리진 않고, stack의 top으로 간다. 최근에 집중적으로 사용되는 Block
- Old → New : Count값을 증가시키면서 stack의 top으로 간다.
- Old Section에 있는 Block을 버린다.
- count 값이 가장 작은 것을 버린다.
위 쪽의 그림은 문제가 있다. Old Section에 한번도 안간 Block이 New→Old로 간 직후에서 count = 0이기 때문에 버려질 수 있다. 따라서 아래쪽처럼 Section을 3개로 나눠서 사용할 수 있다.
- New
- 방금 올라온 경우 top
- New → New : top으로 올라가면서 count 유지
- Middle → New : top으로 올라가면서 count+1
- Old → New : top으로 올라가면서 count값+1
- Middle : 장기적으로 사용되는지 판단하는 단계
- New, Middle 에서는 버리지 않는다.
- Old에서 count값이 가장 작은 것을 버린다.
