Classifications of Multiprocessor Systems
- Loosely coupled or distributed multiprocess or or cluster
- 독립된 하나의 컴퓨터 시스템들을 네트워크로 연결한 후, 그 위에 OS를 덮어서 하나의 시스템처럼 사용하는 시스템
- Functionally speciallized processors
- 시스템 안에 여러가지 프로세서가 존재
- TIghtly coupled multiprocessor
- 시스템 안에 CPU가 여러 개 있는데, 프로세서들이 메인 메모리 공유
- OS 하나가 전체 시스템 컨트롤
Synchronization Granularity and Processes
프로그램들을 실행시킬 때 멀티 프로세서 시스템에서의 스케쥴링은 중요한 변수가 있다.
실행을 하는 프로세스들이 동기화를 얼마나 자주 하느냐이다.
멀티 프로세서 ⇒ 여러 개의 프로세스/쓰레드로 프로그램을 만든다 ⇒ 여러 개의 프로세스/쓰레드는 동기화를 해야한다.
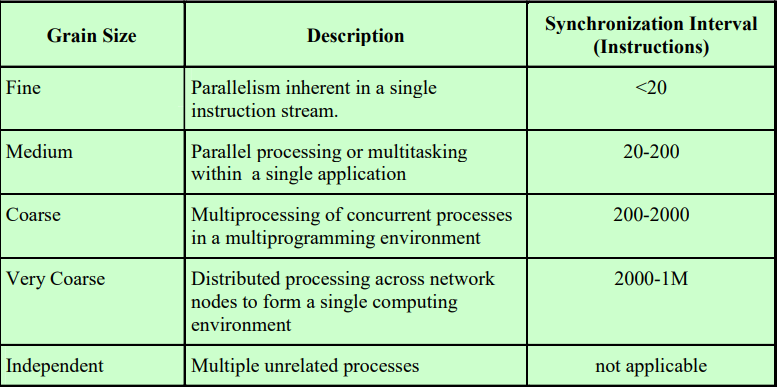
Independent는 각각의 프로세스들이 별개의 독립적인 프로세스라서 동기화, 통신을 할 필요가 없다.
Scheduling Design Issues
- 프로세스의 CPU 할당
- 멀티 프로그래밍 여부
- Ready Queue에 있는 프로세스 선택 순서
- 프로세스들의 동기화 빈도, 프로세서의 개수에 따라 결정이 달라진다.
Assignment of Prcesses to Processors
- CPU마다 Ready Queue 별도로 소유
- 어떤 큐에 실행시간이 짧거나 긴 프로세스가 몰릴 수도 있다 ⇒
Idle while busy
- 어떤 큐에 실행시간이 짧거나 긴 프로세스가 몰릴 수도 있다 ⇒
- Global Queue
- 구현이 어렵다.
- OS가 한 번에 한 명씩 글로벌 큐에 접근하도록
Critical Section으로 구현해야 한다. - Critical Section 진입하는 것 때문에 시간이 걸리는 코드가 될 수 있지만, 개별 Queue로 사용하는 경우 놀고 있는 CPU가 있을 수 있기 때문에 Global Queue 사용
- OS가 한 번에 한 명씩 글로벌 큐에 접근하도록
- 구현이 어렵다.
개별 큐의
Idle while Busy문제 때문에Crtical Section을 사용해서Global Queue를 사용한다.
The Use of Multiprogramming on Indivudal Processors
가장 중요한 이슈
- Independent, Very Coarse, Coarse 프로세스 ⇒ 동기화를 자주하지 않음 ⇒ 멀티 프로그래밍 OK
- Medium, Fine 프로세스 Block ⇒ 동기화 또는 메세지 작업일 확률이 높다.
만약 A 가 메세지를 받아야 하는데, 메세지가 안왔으면 Block 된다. 그런데 프로세스 또는 쓰레드를 OS가 스위칭 시킨다면, 스위칭이 끝나기도 전에 메세지가 도착할 수 있다.
그래서 동기화나 메세지를 주고받는 데에 있어서 Block은 금방 끝난다. 그래서 차라리 조금 기다리는 것이 낫다.
따라서 동기화나 메세지를 주고받는 작업처럼 굉장히 짧게 Block이 되는 경우라면 그 시간에 프로세스 스위칭을 끝마치기도 전에 이벤트가 발생한다. 그러므로 동기화 정도에 따라 멀티 프로그래밍을 하는 것이 나을 수도 있고, 아닐 수도 있다.
물론 Uniprocessor 시스템에서는 동기화나 메세지 문제로 Block이 되면 당연히 중단시키고 프로세스 스위칭을 해야한다. 프로세스를 바꿔야 메세지를 보낼 사람이 실행되기 때문이다.
그래서 어떤 이유로 Block이 됐는지에 따라 멀티 프로그래밍을 해야 될 필요가 달라진다.
Process Dispatching
시스템 안에 CPU가 여러 개라면 어떤식으로 스케쥴링하는지 중요하지 않다.
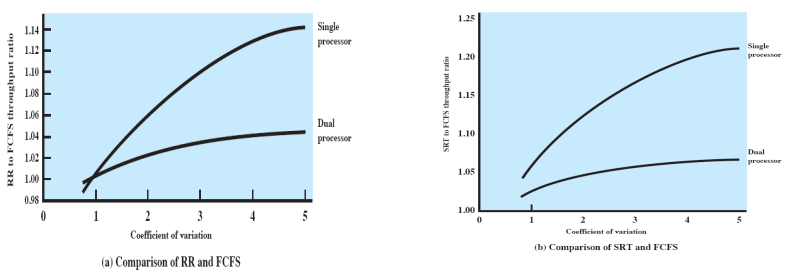
- X축 = 프로세스 별 실행 시간의 차이
- X 값이 커질수록 실행 시간이 짧은 프로세스를 먼저 실행시키면 Response Time이 줄어들게 된다.
- 싱글 프로세서인 경우 어떤 순서로 실행 시키는지가 중요하기 때문에 Throughput 차이가 많이 난다.
- 듀얼 프로세서인 경우 큰 차이가 나지 않는다.
Thread Scheduling
멀티 프로세서 시스템에서 실행되는 어플리케이션은 여러 개의 프로세스/쓰레드로 구현되어 있다. 이 프로세스/쓰레드들은 굉장히 긴밀하게 서로 데이터를 주고받거나 동기화를 하면서 실행한다.
그래서 이 쓰레드들을 동시에 실행시키는 것이 제일 중요하다.
예를 들어, 두 프로세스/쓰레드가 메세지를 주고받을 때 한 쓰레드만 실행된다면 계속 Block 상태일 것이다. 이럴 때 두 프로세스/쓰레드를 동시에 실행시키면 계속 실행시킬 수 있다.
따라서 쓰레드 스케쥴링에서 가장 중요한 부분은 한 어플리케이션에서 나온 여러 쓰레드들을 동시에 실행시키는 것이다.
그런데 어플리케이션에서 필요한 쓰레드 개수와 가지고 있는 CPU의 개수가 다를 수 있다.
- Load Sharing
- 동시에 실행시키는 것이 불가능한 경우
- Gang scheduling
- CPU의 개수가 상당히 많은 경우
- Dedicated processor assignment
- CPU의 개수가 많은 경우
- Dynamic scheduling
- 어중간한 경우 ⇒ 최대한 동시에 실행을 시킨다.
| 쓰레드 개수와 CPU 개수 비교 | |
|---|---|
| Load Sharing | 쓰레드 개수 > CPU 개수 |
| Gang Scheduling | 쓰레드 개수 < CPU 개수 |
| Dedicated Processor Assignment | 쓰레드 개수 <<< CPU 개수 |
| Dynamic Scheduling | 쓰레드 개수와 CPU 개수가 비슷한 경우 |
동기화나 메세지를 주고받는 작업을 자주할 때 좋은 순위
- Dedicated Processor Assignment
- Gang Scheduling
- Load Sharing
Load Sharing
여러 개의 CPU를 가지고 있지만, CPU의 개수가 부족한 상황이다.
각각의 CPU가 실행을 하다가 작업을 끝마치면 Global Queue에 가서 다음 쓰레드를 선택한다. 그런데 어떤 프로세서가 선택하는지는 고려하지 않는다. 따라서 CPU들이 놀지 않고 계속 일을 하게 된다.
그래서 Load가 똑같이 distribution이 됐다고 말할 수 있다. 따라서 모든 CPU가 똑같은만큼 일을 하고 Idle-while-Busy 상태가 발생하지 않는다.
각각의 CPU에서 OS를 돌려서 자신이 원하는 쓰레드를 선택한다.
Load Sharing을 구현할 때, Global Queue를 사용하는 FCFS, 쓰레드 개수가 적은 순, 쓰레드 개수가 적은 걸 preemptive하게 골라봤지만 별로 상관이 없다.
문제점
- Global Queue는 Critical Section으로 구현되어야 하므로 한 OS가 Critical Sectino에 들어가면 다른 OS들은 기다려야 한다. ⇒ performance bottleneck
- 캐시가 의미없어질 수 있다.
- 동시 실행 고려 X
- 한 어플리케이션의 쓰레드들이 동시 실행되는 것을 보장하지 않음
이러한 문제점이 있음에도 불구하고 Load Sharing 기법은 많이 사용되고 있다.
- 구현이 간단하다.
- 멀티 프로세서이지만 CPU 개수가 많아야 8개 정도이다.
Gang Scheduling
한 어플리케이션에서 나온 쓰레드들을 동시에 실행시킨다.
- 어플리케이션 단위 스케쥴링
- 프로세스가 Ready Queue 진입
1번 프로세스가 CPU를 차지한다고 하면 1번 프로세스의 쓰레드들이 동시에 n개의 CPU에서 실행된다.
만약 각각의 프로세스들이 Independent 한 프로세스라면 Gang Scheduling을 사용할 이유가 없다. Medium이나 Fine 정도의 동기화를 가지는 경우 이 쓰레드들 중 하나라도 동시에 실행되지 않으면 전체적으로 퍼포먼스가 떨어지는 상황이 존재한다. 이럴 때 적용이 가능하다.
- 쓰레드의 개수 <<< 프로세서의 개수
- 어플리케이션 단위의 Round-Robin
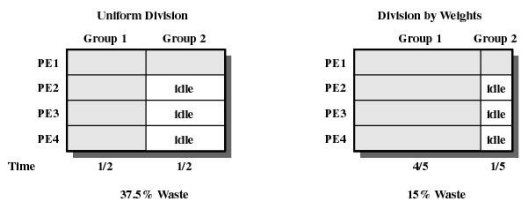
PE = Processing unit Element = CPU
- 어플리케이션들의 쓰레드 개수는 동일하지 않음
- 2번 그룹의 쓰레드는 1개
- 3개의 CPU가 놀게 됨
- 놀고있는 CPU에 다른 어플리케이션을 끼워넣을 수 없음
- CPU 중 일부가 놀더라도 한 어플리케이션의 쓰레드들을 동시 실행 시키는 것이 시스템 성능에 도움 된다고 생각
- 3개의 CPU가 놀게 됨
- 대신 타임아웃 간격 조정
- 1번 어플리케이션 쓰레드 : 4개
- 2번 어플리케이션 쓰레드 : 1개
- 전체 시간의 4/5 ⇒ 1번 어플리케이션
- 전체 시간의 1/5 ⇒ 2번 어플리케이션
- Gang Scheduling의 조건
- CPU 개수 > 쓰레드 개수 (CPU 개수가 더 적을시 사용 불가능)
- 놀고 있는 CPU 발생 가능 ⇒ 어플리케이션 안에 있는 쓰레드나 프로세스들이 굉장히 자주 동기화/메세지 작업을 하기 때문에, 쓰레드가 Block되고 스위칭 되는 것 보다 잠깐씩 CPU가 노는게 더 효과적
- 프로세스가 Block 되어도 스위칭 X
- 타임아웃이 끝나기 전에는 스위칭하지 않고 기다린다.
- 조금만 기다리면 다른 사람이 semSignal을 줄 것
Dedicated Processor Assignment
어플리케이션별로 스케쥴링하는데, Round-Robin 없이 끝까지 실행
- 쓰레드 개수 ≤ 프로세서 개수
- 어플리케이션 별로 Ready Queue에서 기다린다.
한 어플리케이션을 끝까지 실행시킨다. 중간에 I/O 작업을 하든 동기화를 하든 프로세스 스위칭을 하지 않는다.
그래서 중간중간 CPU가 노는 시간이 많이 나올 수 있어도 성능이 더 좋다.
- 조건
- CPU 개수 > 쓰레드 개수
- 어플리케이션 안의 쓰레드들은 굉장히 긴밀하게 데이터를 주고받거나 동기화 해야한다.
- 한 번에 한 어플리케이션만 사용 ⇒ 시스템 안에 CPU가 굉장히 많아야 한다.
CPU를 각각의 어플리케이션에 할당하는 방식이다. 할당된 CPU를 가지고 어플리케이션은 프로세스 스위칭 없이 끝까지 실행한다.
그런데 Processor fragmentation problem 이 생길 수 있다. CPU를 할당하다가 1-2개가 남으면 이 CPU는 놀게되는 상황을 말한다. 할당을 잘 해야 CPU 100% 활용
Dynamic Scheduling
그런데 실제로 쓰레드 개수가 CPU 개수보다 많은지 적은지 미리 알기가 어렵다.
Dynamic Scheduling은 할 수 있는 한 최대한 할당한다.
OS는 프로세스들한테 CPU를 나눠주는 작업을 한다. 어떤 CPU가 작업을 시작하고 싶어한다면, CPU를 1번, 3번, 5번을 주는 것처럼 CPU를 나눠준다.
그런데 어플리케이션에 실제로 쓰레드가 10개 들어있다면, 3개의 CPU에서 10개의 쓰레드를 번갈아가면서 스케쥴링하는 것은 어플리케이션 레벨에서 진행한다.
어플리케이션 레벨의 스케쥴러가 알아서 CPU 개수에 맞춰서 실제 스케쥴링을 진행한다. 그래서 OS는 CPU를 나눠주는 작업만 한다. 그런데 나눠주는 작업도 필요하다고 다 줄 수는 없다.
만약 놀고있는 CPU가 없다면 지금 실행하고 있는 프로세스들 중에서 2개 이상의 CPU를 차지하고 있는 프로세스들의 CPU를 뺏어서 새로 도착한 프로세스한테 나눠준다. 그런데 모든 어플리케이션이 CPU를 하나씩만 가지고 있다면 Ready Queue에서 기다리게 한다.
어떤 프로세스가 실행을 마쳐서 CPU를 반납하고, 현재 실행하고 있는 프로세스가 5개라고 해보자. 그러면 5개 이상을 반납받았다면, 5명한테 하나씩 나눠주고 나머지 CPU는 FCFS 순서로 어플리케이션한테 나눠준다.
그래서 Dynamic Scheduling 에서는 OS의 역할이 각각의 어플리케이션에 몇 개의 CPU를 할당하는지 나눠주는 역할이고, 실제로 이 CPU를 사용해서 어떤 순서로 스케쥴링할지 정하는 것은 어플리케이션 레벨에서 결정된다.
- CPU의 개수가 어느정도는 있어야 한다.
- 2개밖에 없다면 Dynamic Scheduling을 사용할 수 없다. 프로세스들이 와서 몇 개를 달라고 하면 줄 수 있을 만큼의 능력이 있어야 한다.
- 단, Bang Scheduling이나 Dedicated Processor Assignment 처럼 쓰레드의 개수보다 CPU의 개수가 더 많을 필요는 없다.
Real-Time Scheduling
원하는 계산 결과가 맞으면 되는 것이 아니라, 맞는 계산 결과를 정해진 시간 안에 답을 내야한다.
모든 task/프로세스가 deadline을 가지고 있다. deadline을 가지는있는 것을 Real-time computing 이라 한다.
- deadline이 지난다면?
- Hard real-time task : 시스템에 큰 해를 끼치는 일이 발생한다.
- Soft real-time task : deadline을 맞추면 좋고 맞추지 못하면 어쩔 수 없다. 단, deadline을 맞추지 못한 경우는 작업을 안한 것과 같다. 따라서 deadline을 못맞춘다면 throughput이 떨어지게 된다.
- 실행 결과가 시스템에 반영되지는 않는다.
- Real-time task의 종류
- periodic task
- 주기적으로 시스템에 도착하는 task
- ex) 주기적으로 시스템의 상태를 점검하는 프로세스
- 도착 주기, service time, deadline이 정해져 있다.
- 미리 스케쥴링 O
- 주기적으로 시스템에 도착하는 task
- aperiodic task
- 주기적이지 않은 task
- 갑자기 도착해서 실행시간과 deadline을 말한다.
- deadline을 맞추기 어렵다. 도착했을 때 시스템 상황이 어떤지 알 수 없기 때문
- 미리 스케쥴링하기 어렵다.
- 주기적이지 않은 task
- periodic task
Real-time task는 우선순위가 제일 높다.
Earliest-deadline Scheduling
- 무조건 deadline이 빠른 task를 먼저 스케쥴링 하는 방식
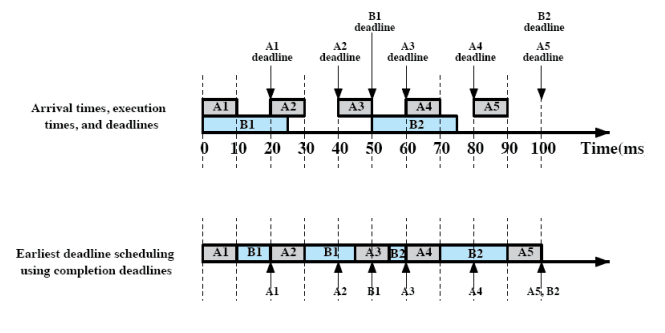
- 0시 : A1, B1 동시 도착 ⇒ A1의 deadline이 빠르기 때문에 A1 작업
- A1 작업을 마치고 B1 작업
- 20시 : A2 도착 ⇒ A2 먼저 작업 (preempt)
- A2 작업을 마치고 B1 작업
- 40시 : A3 도착 ⇒ B1의 deadline이 더 빠르기 때문에 B1 마저 실행
- B1을 마치고 A3 작업
- 50시 : B2 도착 ⇒ A3 마저 실행
- A3를 마치고 B2 실행
- 60시 : A4 도착 ⇒ A4 실행
- A4를 마치고 B2 실행
- 80시 : A5 도착 ⇒ B2, A5 데드라인 동일 ⇒ 먼저 도착한 프로세스 스케쥴링 ⇒ B2 실행
데드라인을 맞출 수 있는 최대한으로 데드라인을 맞춘다. 따라서 deadline을 맞춘 task 개수를 따질 때는 이 방법이 optimal한 방법이다.
그런데 이 방법이 가지는 문제점이 있다. 실제 Task 자체의 우선순위를 따질 수 없다. Task는 어떤 일을 하는 Task 인지에 따라서 Task 자체의 우선순위가 정해진다.
실제로 Earlist-deadline Scheduling을 사용하더라도 deadline을 맞추지 못하는 Task가 생길 수 있다. 그런데 deadline을 맞추지 못한 Task가 더 중요한 Task일 수도 있다.
Rate Monotonic Scheduling
모든 Task가 시스템에 도착하는 주기가 있다 ⇒ 주기가 짧은 Task가 더 우선순위가 높다고 판단 ⇒ 시스템이 자주 나타나서 작업을 해야 한다.
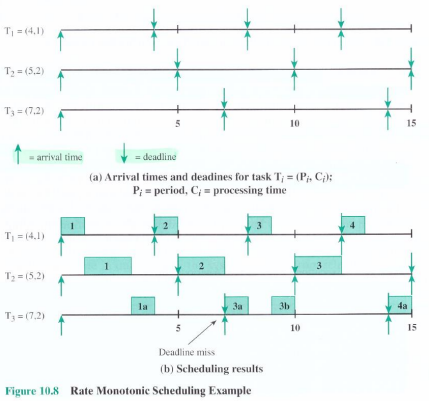
- 우선순위 : T1 > T2 > T3
- T1(1) 실행 → T2(1) 실행 → T3(1a) 실행 중 preempt → T1(2) 실행 → T2(2) 실행 → T3(1) deadline → T3(2a) 실행 → T1(3) 실행 → T3(2b) 실행 → T2(3) 실행 → T1(4) 실행 → T3(3a) 실행
- 주기가 짧은 Task가 나타나면 짧은 주기의 Task한테 CPU 양보 ⇒ Preemptive
- Task에 따른 우선순위 부여 가능 ⇒ Rate Monotonic Sceduling 기법을 더 많이 사용
Priority Inversion
- 우선순위 : T1 > T2> T3
- Task 작업 중 동기화 ⇒ locking 사용 = Critical Section과 유사
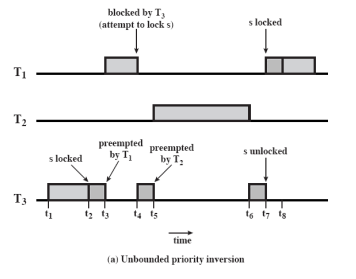
- T3 작업 중 S lock ⇒ T1이 도착해서 preempt (데드라인이 빠르거나 주기가 짧거나 등)
- T1도 S lock 시도 ⇒ 이미 lock 상태이기 때문에 T1 Block ⇒ 다시 T3 실행
- T3 실행 중 T2 등장 ⇒ T3는 T2한테 CPU 양보
- T2가 작업을 다 마친 후 T3가 CPU를 차지해서 작업을 마친 다음에야 T1이 S lock 후 작업
T3가 먼저 작업해서 S lock을 거는 상황은 맞는 상황이다. 하지만 T2는 T1보다 우선순위도 낮고, Lock도 걸지 않는데 T2가 T1 보다 먼저 작업하게 된다.
위 상황을 Priority Inversion 이라 한다.
만약 위 상황에서 T1과 T3 사이의 우선순위를 가진 Task 들이 계속 도착한다면 T3가 계속 뒤로 밀리고 T1도 같이 뒤로 밀린다. 이 현상을 Unbounded Priority Inversion 이라 한다.
이러한 문제를 해결하기 위해 Priority Inheritance 를 사용한다. Priority Inheritance 는 우선순위가 높은 Task가 우선순위가 낮은 Task에 동기화 작업 때문에 대기를 하고있다면 우선순위가 낮은 Task에게 우선순위가 높은 Task의 우선순위를 물려준다.
즉, 우선순위가 낮은 Task는 우선순위가 높은 Task의 우선순위를 상속받는다.
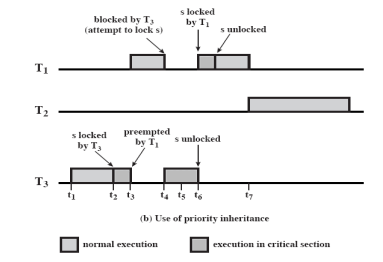
- T1이 S lock을 시도할 때 T3에게 T1의 우선순위를 물려준다.
- T2보다 T3의 우선순위가 높아지기 때문에 T3를 먼저 작업하게 된다.
Windows Scheduling
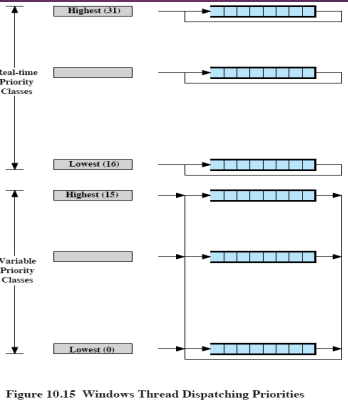
- Multi-level Priority Queue
- Real-time Priority Queues (16개)
- Real-time Task
- Variable Priority Queues (16개) = non real-time
- 일반적인 유저 프로세스
- Real-time Priority Queues (16개)
- Jobs in Real-time Priority Queues
- Fixed Priority = 우선순위가 변하지 않는다.
- RR within a Queue = 같은 큐 안에서 Round-Robin
- 큐에 Task 1개 ⇒ FCFS, 타임아웃 X, Block 되기 전까지 실행
- 큐에 Task 여러 개 ⇒ Round-Robin
- Jobs in Variable Priority Queues
- Feedback Queue
- i 번째 Queue로부터 나와서 CPU를 잡고 실행하다가 타임아웃 ⇒ i-1 번째 Queue
- Feedback Queue
Windows의 스케쥴링은 우선순위 기반의 Preemptive Scheduling 이다. CPU를 잡고 실행하다가 우선순위가 높은 Queue에 새로운 Task가 들어오면 CPU를 뺏기게 된다.
- Priority Feedback for Jobs in Variable Priority Queues
-
Processor-bound thread down : 타임아웃 ⇒ 우선순위 낮춤
-
I/O-bound threads up : 시간을 다 쓰기전에 I/O 작업에 의해 Block ⇒ Blocked Queue에 있다가 다시 Ready Queue ⇒ i+1 번째 Queue
-
CPU를 많이 사용하는 프로세스는 우선순위를 낮추고, I/O 작업을 많이 하는 프로세스는 우선순위를 높인다.
Preempt된 프로세스의 우선순위는 그대로 유지된다.
-
특정 범위 내에서 우선순위를 조정한다.
-
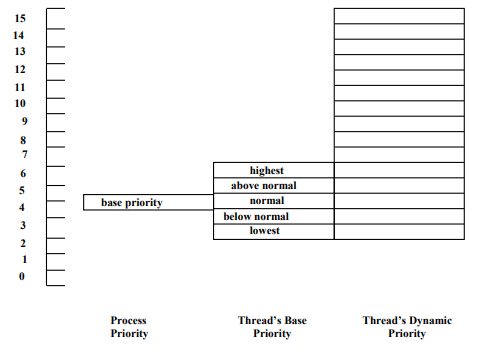
- Process Priority : 프로세스가 어떤 일을 하는 프로세스인지에 따라 결정 (traditional UNIX의 Base와 유사)
- Thread`s Base Priority : 실행 시작 전 갖는 우선순위 (traditional UNIX의 nice와 유사)
Process Priority+-2- OS가 결정하는 것이 아닌, 쓰레드를 만들어내는 프로세스가 결정
- Thread`s Dynamic Priority : 실제 실행할 때 OS가 조정하는 우선순위
- CPU 많이 사용 ⇒ 우선순위 ↓. 최소
base priority - 2까지 - CPU 적게 사용 ⇒ 우선순위 ↑. 최대 15까지
- CPU 많이 사용 ⇒ 우선순위 ↓. 최소
- Windows 시스템은 멀티 프로세서를 가정하고 설계된 OS
- N개의 프로세서가 있다고 가정하고 스케쥴링
- 프로세서가 몇 개 있든 상관없이 항상 우선순위가 제일 높은 큐에서부터 Task를 가져간다.
- Load Sharing 스케쥴링
- CPU가 놀고 있으면 제일 우선순위가 높은 Task를 가져간다.
- 문제 : 캐싱
- Soft affinity : 작업했던 CPU 기록 ⇒ 가급적 작업했던 CPU에서 작업하도록 한다.
UNIX SVR4 Scheduling
Traditional UNIX는 uni-processor를 가정하고 스케쥴링한다. 그래서 Fairness가 중요했다.
UNIX SVR4는 Windows와 비슷한 스케쥴링 방식을 사용한다.
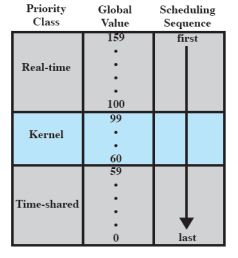
- Multi-level Feedback Queue
- 100-159 : Real-time Task
- 60-99 : Kernel-mode 프로세스
- 0-59 : User-mode 프로세스
160개의 Queue마다 Task가 들어있다는 보장이 없다.
Real-time Task는 어느정도 긴 주기로 잠깐와서 작업을 한다. 따라서 어쩌다 하나씩 Task가 들어와있다.
주로 아래쪽에 있는 Queue에서 유저 프로세스가 실행되고, 이에 맞춰서 Kernel 작업이 진행된다.
UNIX SVR4는 Windows 스케쥴링과 마찬가지로 우선순위가 제일 높은 Queue 부터 선택한다.
- bitmap : Queue 확인 작업을 간단하게 하기 위해 사용
- 160개의 Queue에 누가 있는지 없는지를 표현하는 1 비트 사용
- 0 ⇒ 비어있음, 1 ⇒ 들어있음
- 160 bit ⇒ 정수 1개 = 4byte = 4 * 8bit = 32bit ⇒ 정수 5개 이용 ⇒ 한 번에 32 bit씩 검사
- Priority-Driven Preemptive Scheduling
- RR for the Jobs w/ the Same Priority (real-time class)
- fixed priority and a fixed time quantum
- Queue에 혼자면 FCFS, 여러 개면 RR, but Queue의 time quantum이 같다.
- fixed priority and a fixed time quantum
- Priority Feedback (time-sharing class)
- Processor-bound threads down
- I/O-bound threads up
- 어느 Queue 에서 나와서 스케쥴링하는지에 따라 타임 퀀텀이 달라진다.
- 0번 큐 ⇒ 100ms
- 59번 큐 ⇒ 10ms
- starvation 발생 가능성을 낮추기 위함 (Windows는 아예 고려 X)
Linux Scheduling
Real-time Task와 non-Real-time Task로 구분한다.
- 140개의 우선순위
- 0-99 : Real-time Task
- 스케쥴링 선택
- 100-139 : non-Real-time Task
- 0-99 : Real-time Task
- Scheduling classes
- SCHED_FIFO (0-99) : Block 될 때까지 작업
- 같은 우선순위인 Queue에 여러 개의 Task가 있어도 FCFS 가능
- SCHED_RR (0-99) : Round-Robin
- SCHED_OTHER (100-139) : non-real-time threads
- SCHED_FIFO (0-99) : Block 될 때까지 작업
Real-time Task는 굉장히 실행 시간이 짧은 Task이다. 타임아웃으로 스위칭 하는 시간에 작업이 끝날 수도 있다.
Real-time Task는 주기, service time이 알려져있는 Task다. 따라서 실행 시간이 길면 Round-Robin을 하고, 그렇지 않으면 FIFO로 작업한다.
- FIFO 기법으로 Real-time Task 스케쥴링
- 우선순위가 더 높은 FIFO 클래스의 쓰레드가 나타나면 중단
- FIFO 클래스의 쓰레드가 Block 되면 중단
- 시스템 콜 사용으로 Block 되면 중단
- 그러나 타임아웃 X
- 우선순위가 같은 쓰레드가 여러 개 ⇒ 더 오래 기다린 쓰레드 먼저 스케쥴링
- RR 기법으로 Real-time Task 스케쥴링
- 타임아웃 사용해서 Time sharing
- 우선순위가 더 높은 쓰레드가 나타나면 중단
Linux Scheduling Data Structures
- bitmap 사용
- 비어있지 않은 Queue에서 가장 우선순위가 높은 Queue를 선택하기 위해 사용
- Ready Queue
- 타임아웃이 있는 Multi-level Feedback Queue
- Active Queue에 있는 프로세스 스케쥴링
- Active Queue
- 프로세스가 처음 Ready Queue로 들어갈 때
- non-real-time Task가 타임아웃 전에 우선순위가 더 높은 프로세스가 나타나서 CPU를 뺏긴 경우, Active Queue로 들어간 다음 원래 우선순위 Queue로 들어간다.
- Expired Queue
- 타임아웃까지 다 쓴 경우, Expired Queue로 들어간 다음 우선순위를 낮춰서 Queue로 들어간다.
- 어느 순간 Active Queue가 비는 순간 발생 ⇒ Active ↔ Expired
💡위와 같은 작업을 하는 이유?
제일 밑에 있는 non-real-time Task가 들어있고 제일 높은 Queue에 프로세스가 존재한다고 가정해보자. non-real-time Task는 언제 CPU를 차지할 수 있을까?
우선순위 순서대로 모든 Task가 한 번씩 수행한다. 그래서 우선순위가 낮은 Task도 무조건 스케쥴링을 받게된다. 즉, Active Queue 내에서 우선순위가 높은 Task가 먼저 CPU를 사용하지만, 한 번 사용한 후, 우선순위가 낮은 Task 모두가 한 번 사용할 때까지 기다려야 한다. ⇒ Starvation X
위의 상황으로 인해 Windows나 UNIX SVR4에서 고려하지 않았던 부분이 LINUX에서 고려한다.
