Types of Memory
- Real Memory
- Main memory
- 전체 프로그램이 메모리에 들어간다.
- 프로그램이 점점 커지며 메모리에 들어갈 수 있는 프로그램의 수가 줄어들게 된다.
- Main memory
- Virtual Memory
- Main Memory + Memory on disk
- 프로그램 전체가 아니라, 일부만 메모리에 올라가고 나머지는 하드 디스크에 넣어놓는다.
- 메모리 공간 + 하드디스크 공간 전체를 메모리라고 생각하고 관리한다.
- 동시에 실행 가능한 프로세스가 증가한다.
- 효과적인 멀티프로그래밍을 가능하게 한다.
- 메인 메모리의 제약으로부터 벗어나게 한다.
- Main Memory + Memory on disk
Execution of a Program
- OS가 프로그램 전체가 아니라 2-3 페이지만 메모리에 올린다.
- Resident set = 메인 메모리에 있는 프로세스의 부분
- 메인 메모리에 있지 않은 주소가 필요할 때 인터럽트가 발생한다.
- OS places the process in a blocked state
Resident set
Resident set은 전체 프로그램 중 현재 메모리에 올라와 있는 부분이다.
- Paging system : 메모리에 있는 페이지의 번호
- Segment System : 메모리에 있는 세그먼트의 번호
일부 페이지를 가지고 프로세스를 실행하다가 A Function이 필요한데, A Function이 들어있는 페이지나 세그먼트의 번호가 메모리에 없으면 인터럽트(Page fault)가 발생한다.
Interrupt에 해당하는 프로세스는 Block되고, OS는 다른 프로세스를 실행시킨다. Block된 프로세스의 I/O 작업이 끝나면 I/O 인터럽트가 발생하고 block됐던 프로세스는 Ready Queue로 이동한다.
Thrashing & Locality
Virtual Memory의 가장 큰 걱정거리는 Thrashing이다. 프로세스마다 사용가능한 공간에 제한이 존재한다.
Paging System으로 Virtual Memory를 구현했는데, 한 프로세스당 3 페이지만 메모리에 있을 수 있다면, 3 페이지를 놓고 실행을 하다가 메모리에 없는 페이지가 필요하다면 현재 메모리에 있는 페이지 중에서 하나를 버려야 한다.
결국 실행을 1, 2 줄 하다가 Swap out을 하게되고 페이지를 버리고 가져오는데 시간을 상당 부분 소요할 수 있다. 이런 상황을 Thrashing 이라 한다.
Thrashing 때문에 시스템의 속도가 저하되면 Virtual Memory System은 사용할 수 없을 것 같지만 Reference Locality 덕분에 페이지 변경 횟수가 줄어들게 된다.
Code와 Data는 연속된 공간에 위치하기 때문이다.
Page가 없으면 프로세스가 하드디스크로 쫓겨날까?
프로세스의 Swap Out이 아니라, 프로세스가 가지고 있는 한 페이지가 Swap Out되고 나머지 부분은 메모리에 존재한다.
- Page : Swap Out
- 프로세스 : Running → Block → Ready, Suspend X
Paging
프로그램을 실행하기 위해서는 2가지 요소가 중요하다.
- Relocation
- Protection
Relocation은 Physical Address를 얻는 과정이다.
- Page Table 필요 → Frame 번호 필요 → Offset과 연결 → Physical Address
- Presence bit = 메모리에 있는지 확인하는 비트
- 0 ⇒ 메모리에 존재 X
- Intterupt → 프로세스 Block → 하드 디스크에서 page 가져옴 → page table update → Ready → Running
- 1 ⇒ 메모리에 존재 O
- page frame# 를 찾아서 offset과 연결하여 physical address를 완성해서 relocation
- 0 ⇒ 메모리에 존재 X
- Modify bit = 해당 페이지가 메모리에 올라온 이후, update 된 적이 있는지 확인하는 비트
- 0 ⇒ code 변경 X
- 1 ⇒ code 변경 O
code는 변경되지 않고, data는 변경되는 경우가 많다.
modify bit가 1인 페이지의 경우, 버릴 때 데이터를 하드 디스크에 적고 버린다.
각각의 프로세스마다 Page Table을 가지고 있다.
Page Table Entries
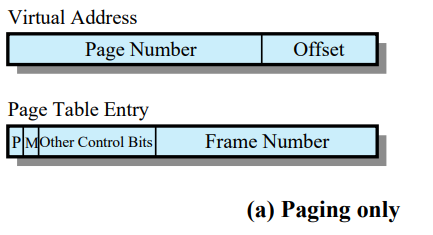
Page Table entry는 메인 메모리안의 해당하는 페이지의 frame#가 있다.
- Virtual Address
- Virtual Memory에서 사용하는 Logical Address
- Paging System 이므로 Page#와 Offset 으로 구성되어 있다.
- Page Table Entry
- 한 페이지마다 해당하는 페이지의 Presence bit, Modify bit, Other Control Bit, Frame # 로 구성되어 있다.
- 페이지마다 하나씩 존재하므로 구조체 배열로 관리된다.
Address Translation in a Paging System
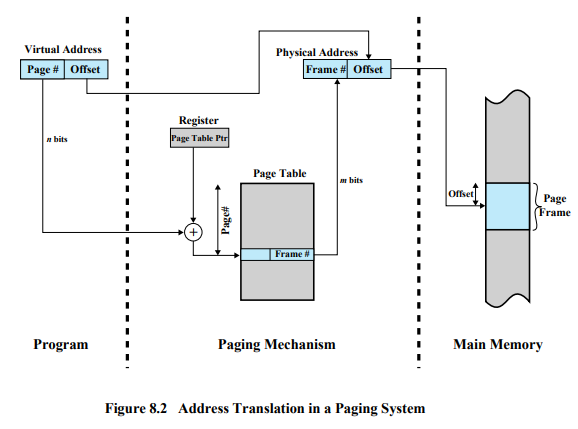
- Register : 실행중인 프로세스 페이지 테이블의 시작 주소값
- CPU는 한 번에 하나의 프로세스만 실행하기 때문에 1개만 존재
- Page Table의 시작 주소는 배열의 시작 주소
- Page # = 인덱스
하지만 이러한 경우는 운이 좋다고 할 수 있다.
페이지 테이블은 프로그램 크기가 커지면 크기가 상당히 커져서 한 페이지 안에 들어가지 못할 수도 있다. 위와 같은 상황은 페이지 테이블이 한 페이지보다 작은 경우이기에 가능하다.
만약 페이지 테이블이 한 페이지가 넘어가게 되면, 페이지 테이블 중 누구는 메모리에 있고 누구는 메모리에 있지 못하게 된다. 페이지 테이블의 각 페이지가 메모리에 있는지 없는지, 있다면 어떤 프레임에 있는지 알 수 있는 페이지 테이블이 필요하게 된다.
Two-Level Hierarchical Page Table

- 프로그램 전체 크기 = 4G bytes =
- 페이지의 크기 = bytes
- 한 프로그램이 포함하는 페이지의 최대 개수 = (페이지 하나의 크기 = )
- 페이지 테이블의 한 entry의 크기(각 페이지에 대한 정보) = 4 bytes
- 전체 페이지 테이블 크기(2단계 페이지 테이블) =
- 전체 페이지 테이블(2단계 페이지 테이블)이 포함하는 페이지의 최대 개수 =
- 루트 페이지 테이블(페이지 테이블의 각 페이지가 어디에 있는지를 알려주는 페이지 테이블)의 크기= (페이지 하나에 대한 정보가 4byte, = 페이지 하나의 크기)
전체 프로그램 중에서 어떤 코드를 실행하고 있다. 그 코드에 대한 페이지 정보가 2번 페이지에 있다면, 2번 페이지만 메모리에 집어넣으면 된다.
페이지가 메모리에 있는지 없는지, 어디에 있는지도 알아야 한다. 그래서 결국 페이지 테이블의 페이지 개수가 상당히 많기 때문에 페이지 테이블의 각 페이지가 메모리에 있는지 없는지, 있다면 어느 프레임에 있는지 알려주는 페이지 테이블이 필요하다.
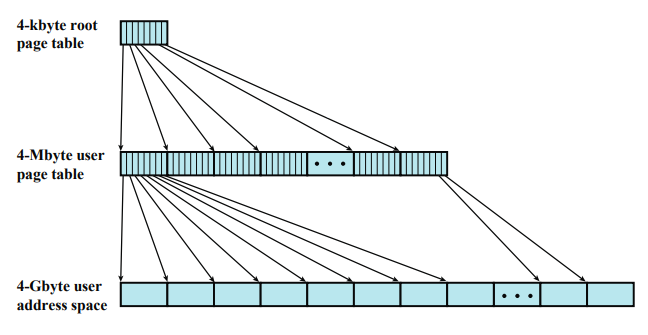
이 페이지 테이블은 페이지 테이블이 어디에 있는지 알려주는 테이블이다. 이 페이지 테이블의 크기는 = 4K 인데, 페이지 하나의 크기와 같다. 이 페이지를 root page table 이라 한다.
root page table 에는 페이지 테이블에 대한 정보가 있다. 각각의 페이지 테이블에 가면 실제 프로그램의 각 페이지에 대한 정보가 있다.
위 계산은 프로그램의 크기와 페이지의 크기가 가정한 계산이다. 만약 프로그램 크기가 더 크거나 페이지가 더 작다면, 페이지 개수가 더 많아진다. 페이지 개수가 많아지면 페이지 테이블의 크기가 커진다. 그러면 페이지 테이블을 포함하는 페이지의 개수도 많아지고, 루트 페이지 테이블이 한 페이지 안에 안들어온다.
따라서 루트 페이지 테이블 - 1단계 페이지 테이블 - 2단계 페이지 테이블 같은 식으로 전개가 된다.
위 이미지는 계산이 맞아 떨어지기 때문에 루트 페이지 테이블은 4K, 다음 단계 페이지 테이블의 크기는 4M, 프로그램의 크기는 4G이다.
프로그램이 더 크거나 페이지의 크기가 작으면 단계가 하나 더 늘어날 수 있다.
Address Translation for Hierarchical page table
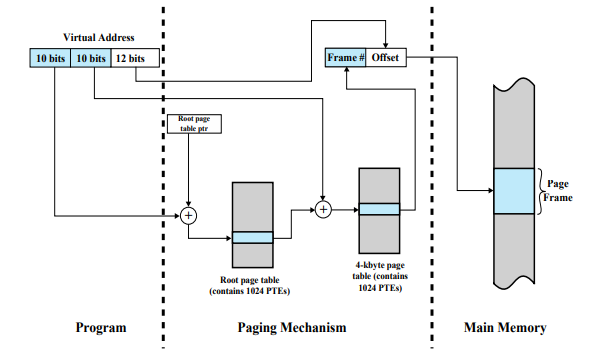
- 프로그램을 실행할 때 루트 페이지 테이블부터 찾아간다.
- 첫 번째 10비트는 루트 페이지 테이블안에 내가 원하는 정보가 들어있는 페이지 테이블에 관한 정보가 몇 번째 entry에 있는지를 나타낸다.
- 루트 페이지 테이블에 대한 포인터 사용
- 루트 페이지 테이블 포인터 = 루트 페이지 테이블의 시작 주소
- 몇 번째 엔트리인지를 더해주면 해당하는 엔트리의 주소가 된다.
- 페이지 크기 =
- 개의 entry
- entry 하나의 크기 = 4 bytes
- 2단계 페이지 테이블 = 내가 원하는 정보가 들어있는 페이지 테이블
- 처음 10 bit : 2단계 페이지 테이블에서 원하는 정보가 몇 번째 엔트리에 있는지를 나타내는 숫자
- Root Page Table을 통해 찾은 결과값은 다음 페이지 테이블의 시작 주소이다.
해당 부분이 내가 원하는 페이지 테이블의 시작주소이다. 그 후 Virtual Address의 두번째 페이지 테이블에서 몇번째 entry인지 번호를 더하면 그 페이지 테이블 안에서 해당하는 데이터가 들어있는 프레임 정보의 엔트리의 주소가 계산이 된다. 그 프레임 정보를 가져다가 오프셋을 붙이면 내가 원하는 데이터의 주소가 된다.
데이터를 읽으러갈 때 루트 페이지 테이블을 읽고, 2단계 페이지 테이블을 읽고, 그 다음 데이터를 읽는다.
- 공간문제
페이지 테이블의 크기가 상당히 크다. 프로그램에 대한 페이지 테이블의 크기가 커지고, 여러 단계의 페이지 테이블을 가지게 된다.
4G의 프로그램은 개의 페이지 개수를 가진다. 그럼 전체 페이지 테이블의 엔트리가 개이다.
1M개의 엔트리가 있다. 그런데 동시에 실행시킬 수 있는 프로그램이 100개라고 한다면, 100 * 개의 페이지 테이블 엔트리가 필요하게 된다.
그런데 만약에 메모리 상에 동시에 여러 프로그램이 들어갈 수 있고 이 시스템이 한 프로세스 당 페이지 3개씩 메모리에 넣고 시작한다고 하자. 페이지 3개만 메모리에 들어있을 것이다. 개의 엔트리 중에서 3개만 presence bit가 1이다. 이는 상당한 공간 낭비이다. 어차피 메모리에 없기 때문이다. presence bit가 1인 메모리에 있는 페이지만 올려놓으면 페이지 테이블의 크기가 상당히 줄어든다.
Inverted Page Table
위의 상황에서 메모리에 있는 페이지 엔트리만 골라서 만든 페이지 테이블이다.
Page table의 k번째 entry에는 k번째 page frame에 저장된 page에 대한 정보가 저장
각각의 페이지가 어디에 있는지를 찾아가는게 아니라, 메모리에 있는 페이지 테이블이 무엇인지 시작한다.
Inverted Page Table을 사용하게 되면, 실제 시스템안에 프로세스가 몇개가 동시에 실행되는지, 한 프로세스의 크기가 얼만큼이 되어서 페이지 테이블의 크기가 얼만큼이 필요한지가 전혀 중요하지 않다. 메모리에 있는것만 기록하기 때문이다. 실제 real 메모리 안에 프레임이 100개가 있다면 페이지 테이블의 엔트리는 100개이다. 만약 프레임 개수가 400이면 페이지 테이블 엔트리는 400개이다.
이와같은 페이지 테이블을 만드려고 할 때 어떤 정보를 넣어야 할까?
- Page number
- 전에는 페이지 넘버를 인덱스로 사용했다. 하지만 여기서는 프레임 번호를 인덱스로 사용한다. 페이지 테이블의 k번째 엔트리에는 k번째 페이지 프레임에 저장된 페이지에 대한 정보가 저장
- Process identifier
- 어떤 프로세스의 몇번 페이지가 들어있는지 구분하기 위해
- Control bits
- 컨트롤 비트는 나중에 Page Replacement할 때 이야기한다.
- Chain pointer
Page number와 Process identifer가 페이지 내용으로 들어가고 인덱스로 프레임 번호가 사용한다.
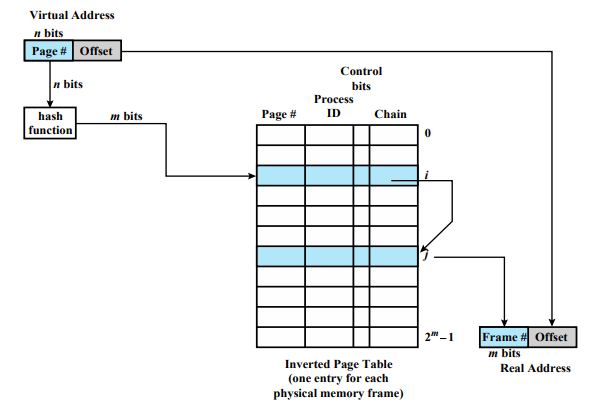
4번 엔트리안에는 페이지 프레임 4번에 들어있는 프로세스는 어떤 프로세스의 어떤 페이지다 하는 정보가 들어있다. 그런데 문제는 원하는 페이지가 어떤 프레임에 들어있는지 알아보려면 어떻게 찾아갈까?
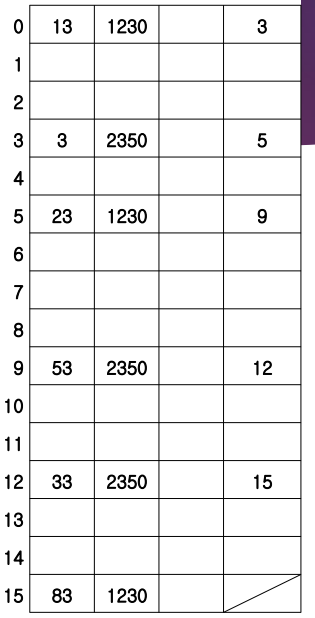
예를 들어, 2350번 프로세스의 33번 페이지에 접근하려고 한다. 문제는 인덱스만 보고는 알 수 없다. 하나씩 살펴봐야 하는데 이는 결국 다 읽어봐야 한다. 공간적인 면에서는 상당히 save했지만, 시간적인 면에서 보면 다 찾아봐야 한다. 따라서 빨리 찾아가는 방법이 필요하다.
- hash function
- chain pointer
Chain pointer는 같은 hash function의 결과를 갖는 엔트리들 끼리 링크로 연결한다. 링크의 다음번 원소에 위치를 적어놓는다.
만약에 hash function으로 %10을 사용한다고 하자. 메모리에 들어있는 모든 페이지의 번호 % 10 이 같은 페이지들끼리 링크로 연결한다.
위의 페이지 번호 % 10 하면 3으로 같다. hash function을 적용시켰을 때 %10 한 나머지가 3인 페이지들의 첫번째 출발점은 인덱스 0이다. 그 다음은 인덱스 3이다. 오른쪽 끝의 값이 다음 인덱스를 가리키고 있다.
만약 2350번 프로세스의 33번 페이지를 찾는다면, 모두 탐색하는 것이 아니라 33번 이라는 페이지 번호를 hash function의 입력으로 준다. 그러면 출력값은 hash functon의 결과값인 3을 출력하는게 아니다. 나머지가 3인 페이지들이 전부 저장된 장소가 링크로 연결되어 있다. 이 링크의 첫번째 출발점을 출력한다.
여기서는 0번 엔트리를 찾아간다. 링크를 따라 내려가다 12번에 가면 원하는 엔트리이다. 프레임 번호는 사실 이전의 9번의 chain 안에 들어있다. 따라서 이 값을 프레임 번호에 집어 넣는다.
- virtual address의 페이지 넘버를 hash function에 적용시키면 페이지 넘버에 해당하는 hash value를 알려준다.
- hash function의 결과값은 같은 hash function의 결과를 가지는 페이지 엔트리들의 링크 리스트의 시작점을 알려준다.
Translation Lookaside Buffer
- Hierachical
공간이 상당히 많이 소요된다.
- inverted
공간이 최소화되지만 찾으러가는데 링크를 따라가야 하기 때문에 시간이 걸린다.
어떤 방법을 사용하던지 간에 최소 2개 이상은 필요하다.
- 페이지 테이블 읽기
- 단계에 따라 다르다. 2단계면 2번, 3단계면 3번, Inverted Page Table은 알 수 없다.
- 데이터 읽기
여러 번 메모리에 접근하는 것은 CPU에 비해 상당히 느리다. 그래서 캐시를 사용하는 것처럼 페이지 테이블을 위한 캐시를 사용한다. 이를 Translation Lookaside Buffer 라고 한다. 페이지 테이블 엔트리 중에서 자주 사용하는 엔트리를 TLB에 넣어둔다.
TLB에 저장된 정보 : 실행중인 process가 access하려고 하는 명령 또는 데이터가 들어있는 page가 적재된 page frame 번호를 포함하는 page table entry
TLB안에는 몇 번 페이지가 몇 번 프레임에 있고 관련된 정보가 어떤지 들어있다. 그 다음부터는 메모리에 가지 않고 TLB에서 찾으면 된다. 그런데 여기서 몇 번에 한 번씩 메모리에 가야할까?
페이지 크기가 4K이고 명령어 하나가 4 bytes라고 할 때, 1024개의 명령 또는 데이터가 들어있다. 이 페이지의 A라는 함수를 시작한다고 한다면, 함수가 잘 짜여진 경우 이 페이지 안 1000개의 명령을 실행할 동안 다른 페이지에 갈 일이 없다. 그러다 1000번에 한 번 페이지가 바뀌게 되는데 그 때 TLB를 다시 세팅하면 된다. TLB를 사용하면 훨씬 효과적으로 페이지 테이블 서치가 가능하다.
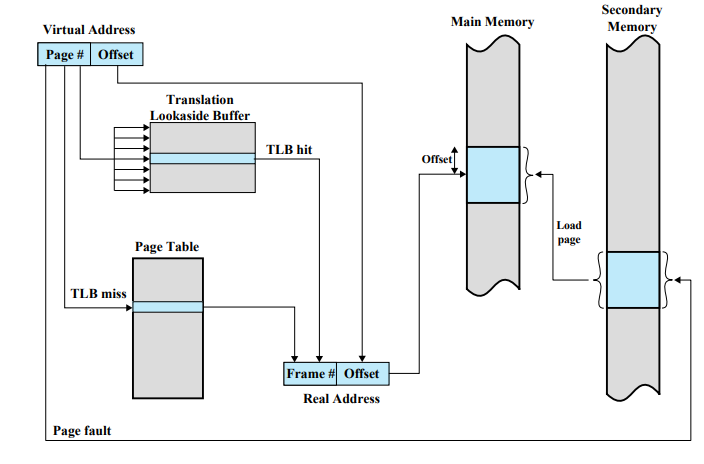
Virtual Address의 페이지 번호가 주어지면 TLB를 찾아본다. TLB에 원하는 정보가 있으면(TLB hit) 프레임 번호를 붙인다. 만약 TLB에 없으면(TLB miss) 페이지 테이블을 찾는다. 찾은 정보로 주소를 만들고, 테이블을 TLB에 옮겨놓는다. 페이지 테이블까지 가봤는데 없으면(page fault) 하드 디스크까지 가서 원하는 페이지를 가지고 와야 한다.
대부분 같이 사용하는 코드가 한 곳에 모여있기 때문에(Locality) 자주 하드 디스크에 가지는 않는다.
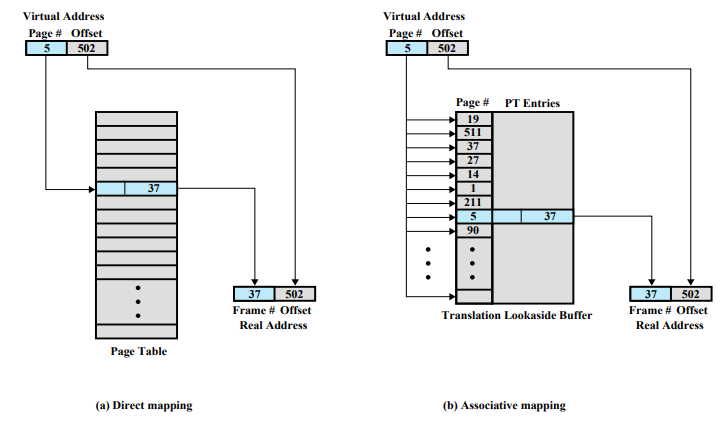
일반적인 페이지 테이블의 경우 인덱스로 찾아간다. 그런데 TLB는 associative mapping을 사용하는데 찾으려고 하는 데이터가 아예 원소안에 들어있다. 그래서 한꺼번에 내용을 비교한다.
Page Size
- 작은 페이지 크기 ⇒ 페이지 수 증가 ⇒ 페이지 테이블 크기 증가
- 큰 페이지 크기 ⇒ Page Fault 수 증가
페이지 크기가 굉장히 작으면, 똑같은 프로그램도 더 잘게 나눠진다. 페이지 수가 많아지게 되면 페이지 테이블이 커지게 된다. 페이지 테이블이 커질수록 더 많은 공간을 차지하게 된다. 따라서 페이지의 크기는 너무 작으면 안된다.
그런데 페이지의 크기가 작으면 작을수록 page fault가 발생할 가능성이 작다. 페이지 크기가 크면 page fault가 발생할 가능성이 크다. 페이지 크기가 작으면 내가 원하는 페이지가 메모리에 있을 확률이 크다.
만약 한 프로세스한테 각 프로세스마다 동일한 크기의 공간을 할당한다고 하자. 이 공간에는 2개의 페이지가 들어갈 수 있는 이 프로세스는 3개의 페이지의 코드 부분을 실행해야 한다. 그런데 2개밖에 넣을 수 없다. 그러면 계속해서 page fault가 발생한다.
그런데 반대로 메모리 공간은 똑같이 할당이 됐지만 프로그램이 페이지 크기를 잘게 나눴다고 해보자. 페이지 크기가 작아졌기 때문에 각 부분이 들어있는 페이지가 공간에 들어올 수 있게 된다. 원하는 부분들만 골라서 넣을 수 있게 된다. 따라서 페이지 크기가 작을수록 원하는 부분들만 메모리에 집어넣을 수 있다. 그래서 page fault가 발생하지 않는다.
위의 두 가지 결론이 상반된다. 페이지 크기는 너무 작아도 안되고 너무 커도 안된다. 최적의 페이지 크기를 구해낼 수가 없다. 그래서 실제 시스템마다 페이지 크기가 다르다.
Segmentation
어떠한 코드를 의미있는 단위로 나눈다. 관련된 함수들을 묶어서 하나의 segment로 만들거나, 관련된 데이터가 저장된 곳을 segment로 만드는 것처럼 의미있는 단위로 만든다.
- 크기가 제각각이다. paging 시스템처럼 간단하게 메모리에 집어넣을 수 없다. dynamic partioning처럼 메모리 할당을 할 수밖에 없다. 그러면 external fragmentation이 발생하게 된다. 따라서 compaction같은 방법이 필요해서 시간 소모가 발생한다.
- sharing
- PCB나 데이터 영역은 share가 안되지만 코드 부분은 share할 수 있다.
- protection
Segment Tables
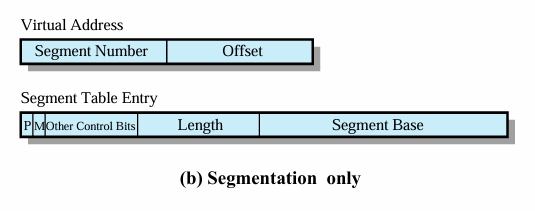
세그먼트 테이블에 length와 base가 포함이 되어야 한다. length는 세그먼트의 길이이고 base는 세그먼트의 시작주소이다.
이외에도 세그먼트가 메모리에 있는지 없는지를 나타내는 presence bit가 필요하다.
세그먼트가 메모리에 올라와서 업데이트 됐는지를 나타내는 modify bit가 필요하다.
Address Translation in Segmentation
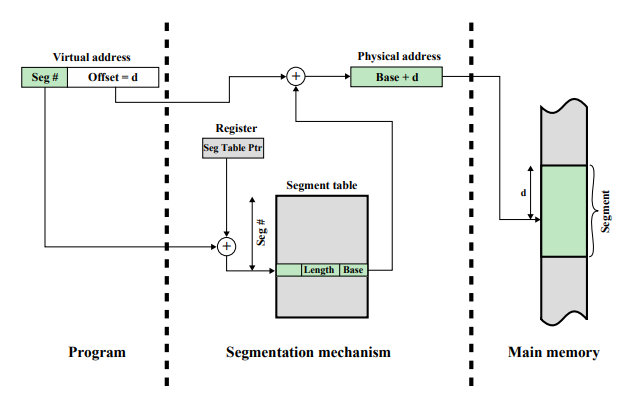
- Virtual Address = Seg # + Offset
- Register = Segment Table의 시작 주소
- Register + Seg# ⇒ 원하는 엔트리
- presence bit, modify bit, other control bits
- Length : 해당 Segment의 길이
- Offset ≥ length : 프로그램 중단
- Base : 해당 Segment의 시작 위치
- Base + Offset = Physical Address
그러나 segmentation으로 virtual memory를 구현하는 것은 굉장히 비효율적이다. 그래서 실제로는 segmentation 기법으로 virtual memory 시스템을 구현하지 않는다.
Combined Paging and Segmentation
프로그램을 의미있는 단위로 나눈다. 그 다음 각각의 세그먼트를 다시 페이지로 나눈다.
하나의 세그먼트가 몇 개의 페이지로 나뉘고 실제 메모리 안에는 페이지 프레임안에 페이지가 들어간다. 따라서 external fragmentation이 없다.
하지만 세그먼트로 먼저 나눴기 때문에 코드 부분의 마지막 페이지도 코드만 들어있다. 어떤 페이지도 코드와 데이터 영역에 걸쳐져 있지 않는다. 따라서 sharing과 protection이 쉽다.
만약 어떤 페이지가 반은 코드, 반은 데이터라면 share/protection을 해야할지 말아야할지 정할 수 없다.
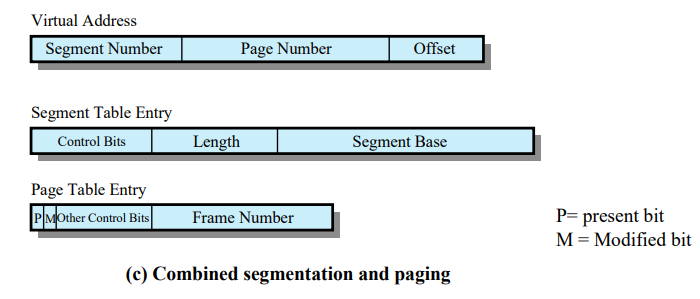
- Virtual Address
- Seg #
- Page #
- 세그먼트 안에서 몇 번 페이지에 해당하는지
- Offset
- Segment Table Entry
- Other Conntrol Bits
- length
- segment base
- Page Table Entry
- prensence bit
- modified bit
- Other Control Bits
- Frame #
세그먼트 테이블에서 length는 무엇을 나타낼까?
세그먼트로 나눈다음 각각의 세그먼트를 페이지로 나눈다. 실제로 메모리에 들어갈 때는 페이지 단위로 들어간다. 그러면 메모리에 들어가있는 한 페이지들은 길이가 일정하다. 여기서 세그먼트 base는 뭘 나타낼까?
length : 세그먼트에 속하는 마지막 페이지의 번호
base : 세그먼트에 속하는 페이지 테이블의 시작 주소
Address Translation
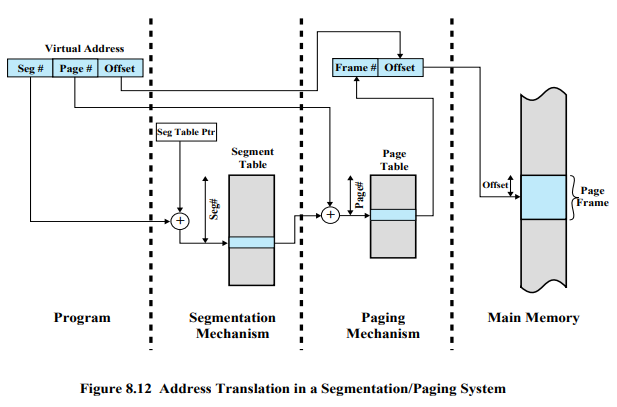
어떻게 주소변환 되는지를 보면 앞의 두가지가 어떤 의미인지 알 수 있다.
Virtual Address는 세그먼트 번호, 페이지 번호, 오프셋이 있다.
메인 메모리에 데이터에 접근하기 위해서는 오프셋은 그대로 가져다쓰고 프레임 번호만 붙여지면 된다.
페이지 테이블안에 내가 원하는 프레임 번호가 들어있다. 이 페이지 테이블안에서 몇 번째 엔트리인지는 Virtual Address의 페이지 번호에 들어있다. 이 페이지 테이블은 세그먼트마다 있다.
세그먼트의 크기는 동일하지 않다. 따라서 페이지 테이블마다 페이지 테이블 크기도 제각각이다. 따라서 기본적으로 페이지 테이블도 당연히 메모리에 들어가지만 어디에 들어가는지 알 수 없다.
그래서 세그먼트 테이블의 base값은 내가 원하는 주소나 데이터가 들어있는 페이지의 시작주소가 아니라, 페이지에 관한 정보를 담고 있는 페이지 테이블의 시작주소이다.
base에다가 페이지 번호를 더하게 되면 해당하는 페이지 테이블의 k 번째 엔트리 값을 알 수 있다. 거기에 가면 해당하는 프레임 번호를 찾을 수 있다.
length 값은 페이지의 길이가 아니다. 페이지의 개수이다.
만약 virtual adress에서 세그먼트 번호는 3이고, 페이지 번호는 15라고 해보자. 3번 세그먼트를 보니 length값이 5라면, 15번 페이지는 존재하지 않는다.
레지스터 안에는 세그먼트 테이블의 시작주소를 가지고 있다. 이 값에다가 세그먼트 번호를 더해서 원하는 엔트리를 찾아간다.
Fetch Policy
페이지 시스템을 사용할 때 고려사항이 있다. 어떤 페이지를 가져와야 하는 상황에서 해당 페이지만 가져올 것인지, 아니면 해당 페이지 다음에 있는 페이지도 같이 가져올 것인지 고민해야 한다.
하드디스크에서 무언가를 가져오는 데에는 시간이 굉장히 오래 걸린다. 그런데 가서 얼만큼 가져오는지는 상관이 없다.
Fetch= 하드디스크에 가서 내가 원하는 페이지를 가져오는 것
- Demand paging
- 내가 필요할 때 필요한 페이지만 가져오는 것
- Pre-paging
- 필요한 페이지 다음 페이지까지 같이 가져온다.
- 별일이 없으면 프로그램을 sequencial하게 사용하기 때문에 다음 페이지 내용을 미리 가져다 놓는다.
Demand paging 이 더 좋다.
Virtual Memory를 사용하는 이유는 공간이 부족하기 때문이다. 공간이 부족한데 당장 필요한 페이지가 아니라 필요한 페이지를 미리 가져다 놓는 것은 공간을 낭비하게 된다. 따라서 전체 공간의 일부분은 지금 사용하지 않는 페이지로 채워지게 되는 상황이다.
Replacement Policy
새로운 페이지를 가져오려면 결국 한 페이지를 버려야 한다. 이때, 어떤 페이지를 버릴 것인지 정해야 한다.
한 페이지를 버릴 때 가장 좋은 방법은 버린 페이지를 다시 사용하지 않는 것이다. 또는 다시 사용하게 되더라도 아주 오랫동안 사용하지 않으면 좋다. 그래서 가장 오랫동안 사용하지 않을 페이지를 버리는 것이 좋은데, 문제는 이 것을 알 수가 없다. 그래서 시스템들은 가장 오랫동안 사용하지 않을 페이지들을 예측해야 한다. 이때 Reference Locality를 이용하여 예측한다.
Examples

페이지 번호는 1~5번이 존재하고 프로세스한테 할당된 page frame은 3개밖에 없는 상황이다.
page fault가 발생하면 하드디스크에서 페이지를 가져올 때까지 멈춰있어야 하므로 Block 상태가 된다. 그래서 page fault가 많이 발생한다는 말 자체가 프로그램 실행이 느려진다는 뜻이다.
이 때 여러가지 방법들을 사용했을 때 page fault가 몇 번 발생하는지 확인해보자.
Optimal Policy
- 미래에 사용하지 않거나 가장 늦게 사용할 페이지 버림
- 내가 어떤 페이지를 어떻게 접근할지 다 알고있어야 가능한 방법
- 실제 구현 X
- 어떤 식으로 페이지를 사용한다는 것을 알고 있을 때 최적의 방법이지만 구현 불가능 ⇒ 기준점으로 사용
- Optimal Policy의 page fault수와 가까울수록 최적의 방법
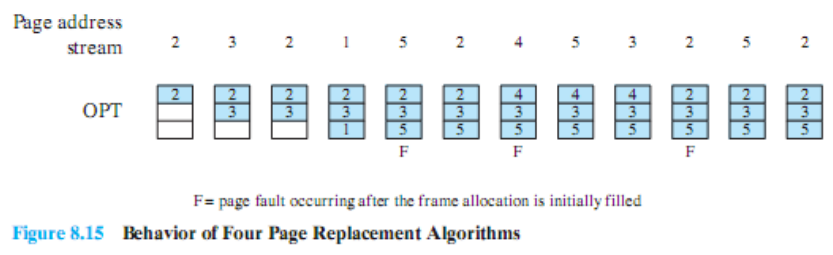
5번 페이지가 필요한 시점에서 어떤 페이지를 버릴지 결정해야 한다. Optimal Policy는 앞으로의 사용을 다 알고있기 때문에 앞으로 사용되지 않는 1번 페이지를 버린다. 이때 page fault가 발생한다.
그 다음 4번 페이지를 가져오기 위해서 버릴 페이지를 찾는다. 4-5-3-2 순서로 사용되는데 2번을 제일 나중에 사용하기 때문에 2번 페이지를 버리고 4번 페이지를 가져온다. 이때 page fault가 발생한다.
그 다음 2번 페이지가 필요할 때 3, 4 번 페이지를 버려도 된다. 이처럼 여러 개를 버릴 수 있는 상황에서 결국 for 문을 사용하기 때문에 첫번째 위치에 있는 4번 페이지를 버린다. 이때 page fault가 발생한다.
Least Recently Used (LRU)
- 미래를 알 수 없음 ⇒ 과거의 행동으로 미래를 예측
- 지금 사용되는 페이지들은 앞으로도 계속 사용되고 지금 사용되지 않는 페이지들은 앞으로도 사용되지 않는다는 기준으로 결정
- 버릴 페이지 : 최근에 가장 오래 사용되지 않은 페이지 선택 ⇒ Reference of Locality
가장 적게 사용된 페이지를 찾아야 하기 때문에 모든 페이지를 다 조사해야 한다. 실제 시스템에 적용하려면 시스템 안의 page frame 숫자만큼 비교해야 한다.
이 때 두 가지 문제점이 있다.
- 가장 오랫동안 사용되지 않은 페이지를 찾는 데 상당 시간 소요
- 가장 마지막으로 사용된 시간을 알기 위해 이 시간을 저장하는 데 사용되는 공간적인 낭비 = 약 4 bytes
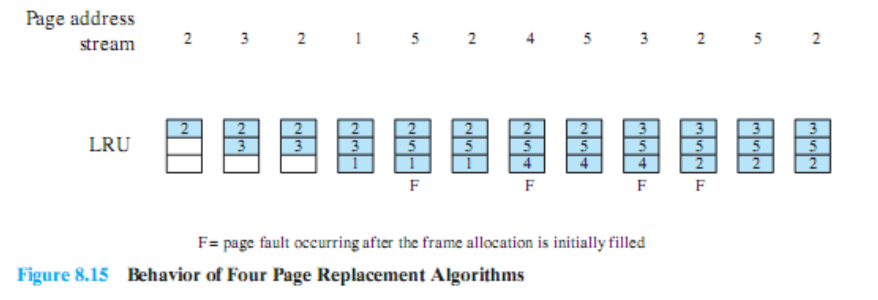
5번 페이지를 교체하는 시점에 1, 2, 3 중 제일 오랫동안 사용되지 않은 3번 페이지를 버리고 5번 페이지를 넣는다. 이때 page fault가 발생한다.
4번 페이지로 교체하는 시점에 가장 오랫동안 사용되지 않은 1번 페이지를 버리고 4번 페이지가 들어간다. 이때 page fault가 발생한다.
3번 페이지가 필요한 시점에 가장 오랫동안 사용되지 않은 2번 페이지를 버리고 3번 페이지가 들어간다. 이때 page fault가 발생한다.
2번 페이지로 교체하는 시점에 가장 오랫동안 사용되지 않은 4번 페이지를 버리고 2번 페이지가 들어간다. 이때 page fault가 발생한다.
FIFO
- 페이지 프레임 ⇒ Circular Buffer
- 먼저 들어온 페이지가 먼저 교체
- 마지막으로 몇 번 프레임을 교체했는지 나타내는 포인터만 필요
- 페이지 찾을 필요 X
- 시간적인 오버헤드 X
- 공간적인 오버헤드 X
- 대신 page fault가 자주 발생 ⇒ 프로세스 Block ⇒ 하드디스크에서 필요한 부분을 가져와야 한다 ⇒ 예측한 실행 시간보다 훨씬 더 소요될 수 있다.
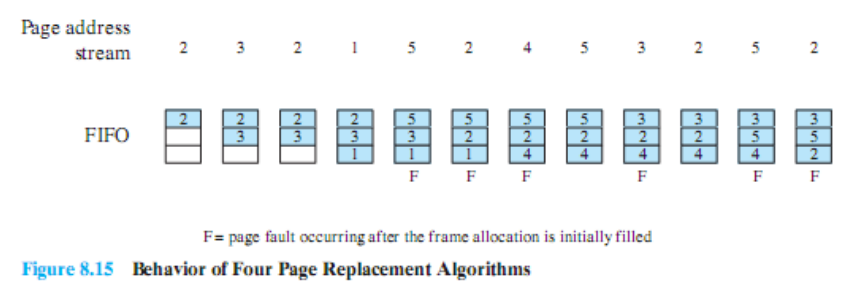
5번 페이지로 교체하는 시점에 첫 번째 프레임에 있는 2번 페이지를 버리고 5번 페이지를 넣는다.
바꾸자마자 2번 페이지가 필요해서 두 번째 프레임에 있는 3번 페이지를 버리고 2번 페이지를 넣는다.
4번 페이지가 필요해서 세 번째 프레임에 있는 1번 페이지를 버리고 4번 페이지를 넣는다.
이처럼 진행하면 6번의 page fault가 발생한다.
- 프레임 안에 있는 페이지가 얼마나 자주 사용되는 페이지인지 고려하지 않고 순차적으로 교체
- page fault가 많이 발생
- 페이지 교체를 하는 데 있어서 가장 안좋은 방법
- FIFO Anomaly
- 페이지 프레임 수를 늘려도 page fault가 늘어나는 경우 발생
Clock Policy
LRU를 구현하는 데에 시간적, 공간적 오버헤드가 크고 FIFO는 시간적, 공간적 오버헤드는 거의 없지만 page fault 횟수가 너무 많다.
따라서 적절한 중간 지점인 Clock Policy 존재
- 페이지마다 1 bit(use bit) 사용
- LRU(4 bytes)에 비해 1/32 감소
- 처음 메모리에 올라오면 use bit = 0
- 페이지가 사용되면 use bit = 1
- 페이지 교체 시,
- 찾는 과정에서 use bit = 1 이면, 0으로 교체
- 찾는 과정에서 use bit = 0이면, 해당 페이지 교체
- use bit = 0 : 찾는 과정에서 0으로 만들고 지나간 페이지. 즉, 한 바퀴를 돌 동안 사용되지 않은 페이지
- 방금 메모리에 올라와서 0일 수 있지만, 대부분 메모리로 올라오면 금방 사용되기 때문에 그런 경우는 거의 없다.
- 시계 바늘이 한 바퀴 도는 데 걸리는 시간은 정해져있지 않음
- 사용되지 않은 페이지 = 한바퀴 도는데 걸리는 시간만큼 사용되지 않음
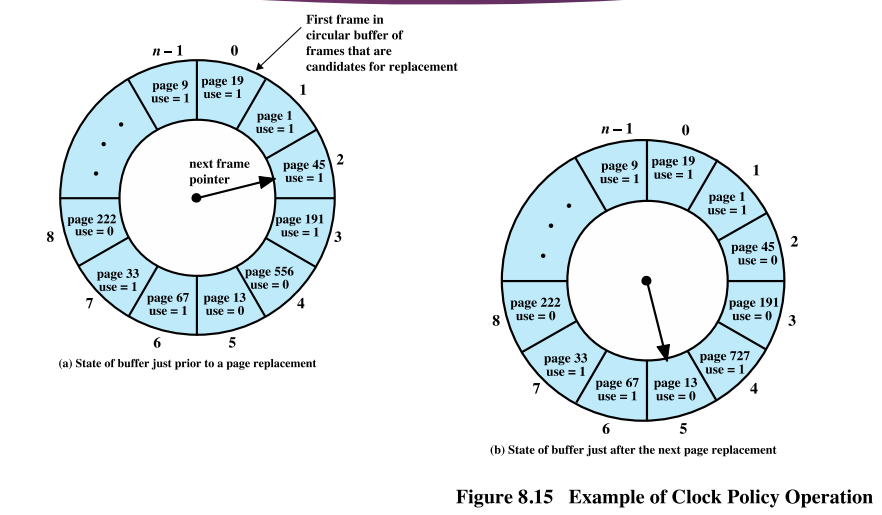
현재 시계바늘이 2번 프레임을 가리키고 있는데, 페이지를 교체해야 하는 상황이 왔다. 교체할 페이지를 찾으러 가야하는데 2번은 use 비트가 1이다. 그래서 2번의 use 비트를 0으로 만들고 지나간다. 3번 또한 use 비트를 0으로 만들고 지나간다.
그 다음 4번 프레임에 있는 페이지의 use 비트는 0이다. 그래서 4번 프레임에 있는 페이지를 교체한다.
Clock Policy는 LRU의 오버헤드를 둘 다 해결했다고 볼 수 있다.
- 공간적 오버헤드 ⇒ 시간을 표현하기 위해서 4 bytes 씩 필요한 걸 1 bit로 표현
- LRU에서 전체 프레임을 비교 ⇒ 전체를 비교하지 않고 찾아낸다.
Example
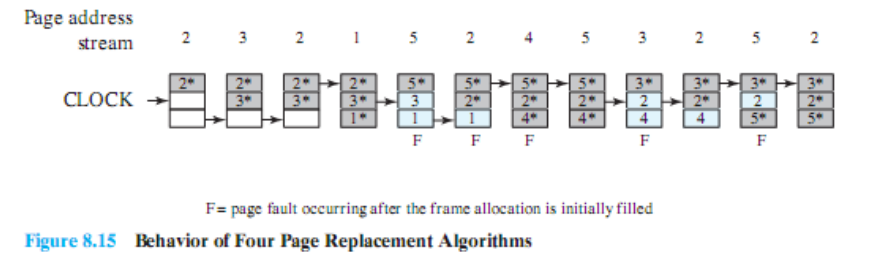
- = use 비트가 1
- 화살표 = 시계 바늘
5번 페이지로 교체하는 시점하려고 할 때 바늘은 2번 페이지를 가리키고 있다. 이때 시계 바늘이 움직이면서 use 비트를 0으로 만들고 움직인다. 그러다 한 바퀴를 다 돈 다음 2번 페이지의 use 비트가 0이므로 2번 페이지를 교체한다.
이 상황에서 2번 페이지가 필요한데 바늘이 가리키고 있는 위치의 페이지의 use 비트는 0이다. 따라서 바로 교체한다. 이와 같은 방법으로 페이지를 교체하게 된다.
그런데 페이지 프레임에 이미 있는 페이지가 필요할 때는 어떻게 될까? 이 때는 page fault가 발생한 것이 아니라, 해당 페이지의 use 비트만 1로 바꿔준다.
바늘이 움직이는 것은 페이지가 메모리에 없어서 새로운 페이지를 가져와야 하는데, 어디서 가져올지를 찾기 위해 움직인다. 그래서 지금처럼 해당 페이지가 메모리에 있는 상황에서는 바늘이 움직이지 않는다.
Optimal에 가장 가까운 방법이 LRU이고, 가장 안좋은 방법은 FIFO이다.
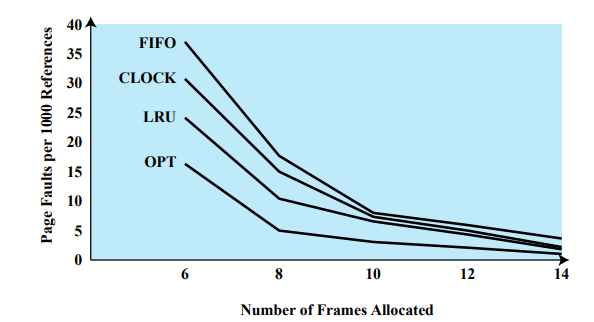
Clock 기법은 프레임 숫자가 10개가 되기 전까지는 LRU와 FIFO의 중간 정도이지만, 10개가 넘어가면 거의 LRU와 비슷하게 좋다.
Resident Set Size
각각의 프로세스마다 프레임을 할당받는 사이즈가 다르다.
Resident Set = 메모리안에 들어있는 페이지 집합
사이즈가 고정될 수도, 변동할 수도 있다.
- Fixed-allocation
- 프로세스마다 해당되는 페이지 프레임 숫자가 정해져있다.
- 실행을 시작할 때부터 끝날 때까지 동일한 개수의 페이지 프레임을 할당한다.
- Variable-allocation
- 프로세스가 실행을 시작하면서 끝날 때까지 페이지 프레임 숫자를 바꿔준다.
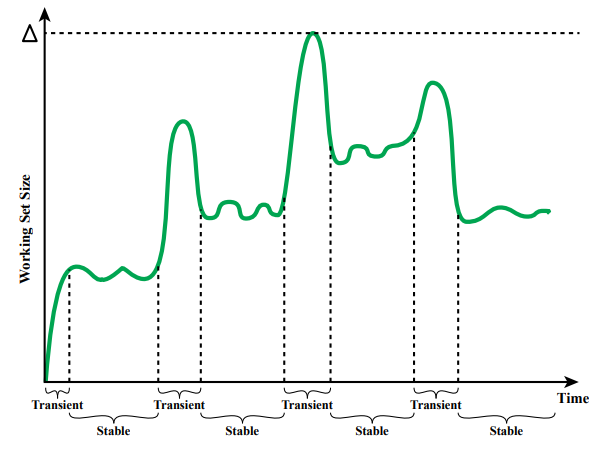
Working Set- 어떤 프로세스가 page fault 없이 실행을 하려면 들어있어야 하는 페이지 집합
- 실행을 할 때 지금 사용하고 있는 페이지들의 집합
Resident Set- 실제로 메모리에 들어있는 집합
- Working Set = Resident Set ⇒ Page Fault X
- 궁극적인 목표 : Working Set이 전부 다 Resident Set이 되도록 한다.
- 페이지를 새로 필요로 하거나 버리기 때문에 Working Set은 늘어나거나 줄어듬
- 시시각각 변하지 않고 변하는 구간이 존재 ⇒ 필요한 페이지가 다 메모리에 존재하면 해당 페이지들로 한동안 계속 작업
- Fixed Allocation이
- Working Set보다 페이지 많게 할당 ⇒ 필요없는 페이지 메모리에 존재
- Working Set보다 페이지 적게 할당 ⇒ Page Fault 발생
Fixed Allocation 과 Variable Allocation 중 Variable Allocation 방법이 더 효과적이다.
그런데 어떤 페이지가 필요하면 기존에 있던 페이지 중에 하나를 버려야 한다. 이때 자신한테 할당된 페이지 중에서 하나를 버릴지, 다른 프로세스의 페이지를 버릴지 결정해야 한다.
- Local Scope = 자신의 페이지를 버린다.
- Global Scope = 다른 프로세스의 페이지를 버릴 수 있다.
Fixed Allocation, Local Scope
- 프레임 5개 할당 = 프로그램이 끝날 때까지 5개
- 고정된 크기의 페이지 프레임이 waking set 보다 크면 낭비되는 공간 발생
- 고정된 크기의 페이지 프레임이 walking set 보다 작으면 계속해서 page fault 발생
Fixed Allocation은 자기한테 주어진 공간이 정해져 있으므로 local scope 밖에 사용할 수 없다.
Variable Allocation
Variable Allocation은 Local Scope, Global Scope 다 가능하다.
Global Scope
Clock 기법 사용한다.
메모리 안에 있는 모든 페이지를 보면서 use bit가 0인지 확인한다. use bit가 0이라는 뜻은 사용하지 않는 페이지다. Working Set이 큰 프로세스는 점점 더 많은 프레임을 할당받게 된다. 반면 Working Set이 작은 프로세스는 점점 더 작아진다.
물론, 시스템안에 있는 모든 프로세스가 Working Set이 커지는 구간을 지난다면 Page Fault가 자주 발생할 수 있다. 그러나 그렇지 않은 경우에는 저절로 Working Set이 맞춰진다.
- LRU 사용 불가
- global scope에서의 페이지 교체 ⇒ 페이지 전체의 사용시간 비교 ⇒ page fault가 오히려 시간이 적게 걸림
Local Scope
local scope는 자신의 페이지를 버리기 때문에 프레임 개수가 일정하다. 하지만 Variable Allocation이므로 Working Set에 맞춰서 계속 변화시킨다.
Page Fault가 얼마나 자주 발생하냐에 따라 페이지 프레임 수를 조정한다.
- page fault수가 많으면, 할당된 페이지 프레임수를 늘려준다.
- page fault가 너무 적으면 프레임 수를 줄인다.
- LRU를 사용할 수 있다.
- 자신한테 할당된 페이지 공간만 비교하기 때문
- 시간적, 공간적 오버헤드를 줄일 수 있다.
- 전체를 확인할 필요 X
- 4 bytes 가 아니라 2-3 비트면 10 페이지 중 제일 오랫동안 사용되지 않은 페이지 확인 가능
Allocation을 정하고, global, local을 정한다.
UNIX Memory Management
두 가지 방식을 같이 사용한다.
- page 기반의 virtual memory 시스템
- 페이지 테이블 사용
- TLB를 사용해서 속도를 높인다.
- 유저 프로세스를 실행시킬 때 사용
- Dynamic Partitioning
- 변형된 형태의 buddy 시스템
- 커널한테 메모리를 할당할 때 사용
커널과 유저 프로세스의 메모리 할당 방식이 다르다.
메모리 교체 시 Clock 기법 사용 ⇒ Variable Allocation-Global Scope
But, 변형된 Two-handed 기법을 사용
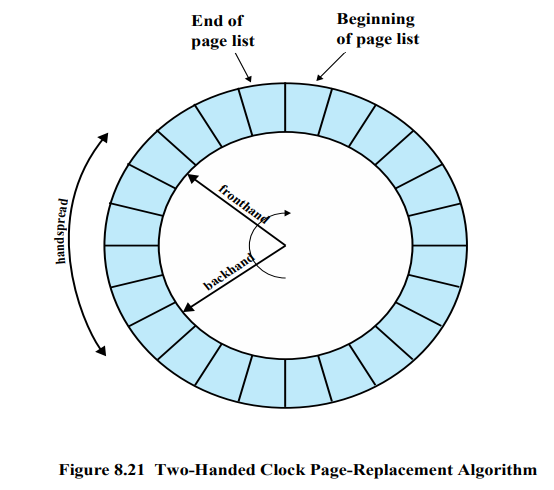
- Reference Bit = Use bit
- Fronthand = 지나가면서 reference bit를 0으로 만든다.
- Backhand = 교체할 페이지를 찾는다.
유닉스에서는 페이지를 교체하는 시점에서 바늘이 움직이는 것이 아니라 평상시에 OS가 할 일이 없을 때 바늘을 움직인다. 그래서 reference bit가 0인 페이지를 미리 찾아서 Paged-out 리스트를 만든다.
리스트를 만들어놓으면 두 가지 장점이 있다.
- 교체시점의 시간적 오버헤드는 0
- Page-out 리스트를 만들어놓고 한번에 하드디스크에 쓴다.
- Page-out 리스트에서 modify bit가 1인 리스트들을 다 쓴다.
- 하나씩 쓰려면 상당히 오래걸리기 때문에, 한번에 쓴다. 덮어쓰기만 하면 된다.
그런데 가끔 Paged-out 리스트에서 페이지가 사용이 되는 경우가 있다. 그럴 때는 reference bit를 1로 만들고 다시 사용한다.
Paged-out이 길어진다 ⇒ 두 바늘이 가깝게 붙어있다.
두 바늘의 속도를 OS가 조절한다.
Windows Memory Management
Variable allocation - Local Scope 사용 ⇒ LRU
모든 프로세스들은 실행을 시작할 때 Fixed된 공간을 할당받는다.
page fault가 많이 일어나면 프레임을 늘려주고 적게 일어나면 프레임을 줄여준다.
Working Set이 전부 다 Resident Set이 되게 하려고 한다.
Working-set based memory management
LRU-Local Scope ⇒ 시간, 공간적으로 소모가 적다.
